大模型应用:大模型的token频率偏见:高频词与低频词的嵌入表示差异分析.46
原创
大模型应用:大模型的token频率偏见:高频词与低频词的嵌入表示差异分析.46
原创
未闻花名
发布于 2026-03-15 10:07:50
发布于 2026-03-15 10:07:50
一、引言
随着大模型技术深入渗透到日常对话、专业咨询、内容创作等多元场景,模型对高频词汇的理解精准度远超低频词汇,这种差异直接影响着输出结果的可靠性与实用性。从底层逻辑来看,高频词因在训练语料中曝光度高,不仅能以完整 Token 形式保留语义,其嵌入向量还会经过反复优化,最终呈现出精准、集中的分布特征;而低频词常被拆分为更小的 Token 单元,语义碎片化严重,再加上训练过程中获得的优化资源有限,嵌入向量只能处于模糊、分散的状态。这种差异直接导致:大模型在处理日常高频内容时游刃有余,面对专业术语、生僻词汇、小众表达等低频内容时,却极易出现理解偏差、输出片面的问题。
这种看似偏心的表现,并非大模型学艺不精,而是其底层运行机制中一个绕不开的特性,Token 频率偏见在发挥作用,Token 频率偏见是大模型基于训练语料中 Token 出现频次差异,所产生的嵌入表示与处理效果的不对等现象,其本质是模型“重高频、轻低频”的训练机制与分词规则共同作用的结果。搞懂 Token 频率偏见,就等于理解了大模型底层逻辑,能帮我们更好的理解“为什么 AI 对生僻词不敏感”、“专业领域的大模型为何需要额外训练”,更能让我们在使用和优化大模型时,避开因频率偏见带来的陷阱。

二、基础概念
1. Token
大模型的最小语言单位,大模型看不懂人类文字,只能处理数字代码,Token 就是把文字拆成的最小积木。比如“苹果”可能是 1 个 Token,“人工智能” 是 1 个Token,但生僻词“氍毹”,读音qú shū,指地毯,会被拆成“氍”和“毹”两个 Token。
- 拆分规则:主流模型用 BPE 算法,核心是“高频合并、低频拆分”,训练语料中出现次数多的字符组合,会被打包成 1 个 Token;出现少的就拆成更小单元。
- 生活类比:就像超市打包,高频词好比畅销品,整箱卖,1 个 Token,低频词好比冷门品,拆成单件,多个 Token。
2. 嵌入表示(Embedding)
大模型的语义翻译器,Token 是离散的“数字 ID”,嵌入表示就是把这些 ID 转换成“有意义的数字向量”,比如 300 维或 768 维的数字组合,让模型能理解语义。
- 核心作用:比如“猫”和“狗”的语义相似,在向量在空间中的表现会很靠近,“猫”和“汽车”的语义无关,向量表示则会很远。
- 学习方式:这些向量不是固定的,是模型在训练中通过学习文本规律训练出来的,会随着上下文不断优化。
- 生活类比:把每个 Token 变成“性格标签向量”,比如“热情”、“安静”、“活泼”等维度的分数组合,通过分数相似度判断彼此关系。
3. Token 频率
大模型的学习曝光度,就是某个 Token 在训练语料中出现的次数,出现越多,频率越高,比如“的”、“是”、“人工智能”;出现越少,频率越低,比如专业术语、生僻字、小众表达。
- 关键特点:大模型的训练本质是学频率规律,高频词因为见得多,模型对它的学习更充分;低频词见得少,学习就不够深入。
4. Token 频率偏见
简单说:大模型对高频词和低频词的待遇不同,导致它们的嵌入表示出现明显差异,进而影响模型处理效果,高频词的嵌入向量更精准、稳定,低频词的则更模糊、分散。
- 本质原因:模型训练时会优先优化出现次数多的 Token,因为它们对训练目标的影响更大,就像学生花更多时间复习高频考点,忽略冷门知识点。
- 直观表现:问模型苹果是什么,它能详细回答;问氍毹是什么,它可能答非所问或含糊其辞。
三、形成原因
1. 基础原理
1.1 训练目标的资源倾斜
- 大模型的核心训练目标是预测下一个 Token 出现的概率,高频词出现概率高,模型会重点学习它的上下文规律;低频词出现概率低,模型分配的学习资源自然更少。
1.2 嵌入向量的学习差异
- 高频词:因为反复出现,模型能不断修正它的向量,最终形成“精准、集中”的表示,在向量空间中靠近原点,稳定性强。
- 低频词:训练中曝光少,向量更新次数少,只能形成“粗糙、分散”的表示,在向量空间中分布零散,语义捕捉不全面。
1.3 分词规则的间接影响
- 低频词常被拆成多个小 Token,模型很难学习到它的完整语义;而高频词多是完整 Token,语义保留更完整。比如“周小山”拆成 “周”、“小”、“山”,模型难以理解这是一个整体。
总结:训练语料中高频 Token 的嵌入向量更精准、集中;低频 Token 的嵌入向量更模糊、分散。 核心影响因素:
- 分词规则:高频词易被合并为完整 Token,低频词易被拆分
- 训练机制:模型优先优化高频 Token 的预测精度
- 向量学习:高频 Token 因多次更新,向量空间位置稳定
2. 拆解示例
- 1. 文本输入:输入一句话(比如 “我喜欢苹果,也收集氍毹”)。
- 2. Token 拆分:分词器把句子拆成 Token:“我”、“喜欢”、“苹果”,都是高频完整 Token,而“氍”、“毹”则属于低频拆分 Token。
- 3. 嵌入转换:模型把这些 Token 转换成向量,“苹果” 的向量精准集中,“氍”“毹” 的向量分散模糊。
- 4. 结果输出:模型处理时,依赖精准向量的高频词部分表现好,依赖模糊向量的低频词部分容易出错。
输入句子:我爱吃苹果,也收藏氍毹 ├─ 高频词拆分(BPE算法) │ "我" → [我] (1个Token) │ "爱吃" → [爱吃] (1个Token) │ "苹果" → [苹果] (1个Token) └─ 低频词拆分(BPE算法) "氍毹" → [氍, 毹] (2个Token) (原因:训练语料中"氍毹"出现次数极少,无法被合并为完整Token)
高频词是整积木,低频词是碎积木,模型难以用碎积木还原完整语义。
3. 直观对比高低频词的嵌入向量分布
from transformers import AutoTokenizer, AutoModel
import torch
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from modelscope.hub.snapshot_download import snapshot_download
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_bert_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 2. 加载模型和分词器(选用轻量级的bert-base-chinese,CPU可运行)
tokenizer = AutoTokenizer.from_pretrained(local_bert_path)
model = AutoModel.from_pretrained(local_bert_path)
# 3. 选择测试词:高频词列表 + 低频词列表
high_freq_words = ["苹果", "手机", "人工智能", "吃饭", "睡觉"] # 日常高频
low_freq_words = ["氍毹", "䴙䴘", "横向联邦", "量子纠缠", "熵增定律"] # 低频/专业
# 4. 提取Token和嵌入向量
def get_word_embedding(word):
# 分词:获取word的Token ID
inputs = tokenizer(word, return_tensors="pt", padding=True, truncation=True)
# 前向传播:获取模型输出(包含嵌入向量)
with torch.no_grad(): # 关闭梯度计算,节省CPU资源
outputs = model(**inputs)
# 取[CLS] token的向量作为单词的整体嵌入(简化处理)
embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return embedding
# 5. 批量获取向量
high_freq_embeddings = [get_word_embedding(word) for word in high_freq_words]
low_freq_embeddings = [get_word_embedding(word) for word in low_freq_words]
# 6. t-SNE降维:将高维向量降到2维,方便可视化
import numpy as np
all_embeddings = high_freq_embeddings + low_freq_embeddings
all_embeddings = np.array(all_embeddings) # 转换为numpy数组
tsne = TSNE(n_components=2, random_state=42, perplexity=3) # perplexity适配小样本
tsne_results = tsne.fit_transform(all_embeddings)
# 7. 绘图:对比高频词和低频词的向量分布
plt.figure(figsize=(10, 6))
plt.subplots_adjust(left=0.08, right=0.95, top=0.95, bottom=0.08) # 缩小边距
# 绘制高频词:红色,圆形
plt.scatter(tsne_results[:5, 0], tsne_results[:5, 1], c="red", label="高频词", marker="o", s=100)
# 绘制低频词:蓝色,三角形
plt.scatter(tsne_results[5:, 0], tsne_results[5:, 1], c="blue", label="低频词", marker="^", s=100)
# 添加词标签
for i, word in enumerate(high_freq_words + low_freq_words):
plt.annotate(word, (tsne_results[i, 0], tsne_results[i, 1]), fontsize=12)
plt.title("Token频率偏见:高频词 vs 低频词 嵌入向量分布")
plt.legend()
plt.grid(True)
plt.show()结果图示:
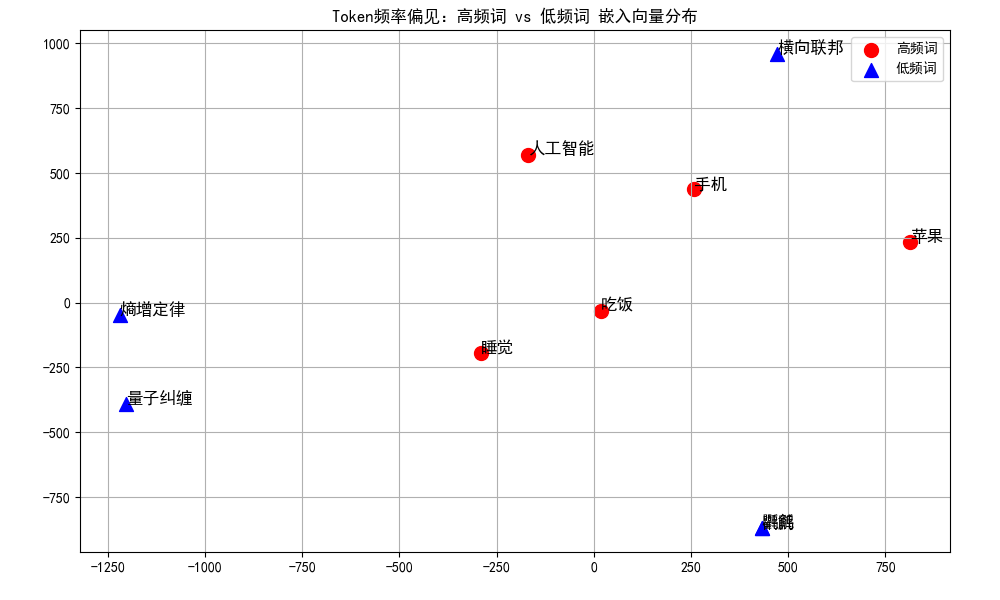
- 红色圆形(高频词)会聚集在图中的某一个或几个区域,彼此距离较近。
- 蓝色三角形(低频词)会分散在图中的各个角落,彼此距离较远。
由此进一步说明:
- 高频词因语义关联强、训练次数多,向量在空间中靠得近,模型能准确识别它们的同类关系。
- 低频词因语义信息弱、训练次数少,向量随机分布在空间各处,模型无法判断它们的组合语义。
四、行业处理方案
1. 医疗行业的影响
1.1 核心影响
- 高频症状疾病,如“感冒”、“高血压”识别精准;低频罕见病、专科术语,如“亨廷顿舞蹈症”、“氍毹样皮疹”易被拆分或误判。
- 口语化非标准表述(如患者用“身上起红点点” 描述罕见皮疹)因低频,模型易低估风险,甚至给出错误分诊建议。
1.2 场景示例
- 分词与嵌入差异
- 高频词 “高血压”:完整 Token,嵌入向量经百万次训练,关联 “症状、用药、并发症” 等完整语义。
- 低频词 “亨廷顿舞蹈症”:拆分为 “亨廷顿 / 舞蹈 / 症”,各子 Token 语义孤立,向量分散,模型无法拼接 “神经退行性、遗传、舞蹈样动作” 核心定义。
- 风险场景示例
- 输入:“我爷爷手抖、走路不稳,可能是亨廷顿舞蹈症吗?”
- 模型输出(模糊):“可能是神经系统问题,建议就医检查。”,未关联遗传史、典型症状、诊断流程
- 背后原因:低频术语的嵌入向量缺乏精准语义,模型无法触发专业知识库匹配。
1.3 解决方案
- 构建医疗专属分词表:将罕见病、专科术语加入高频 Token 库,避免拆分。
- 微调训练:用专科病历、指南扩充低频术语语料,优化嵌入向量。
- 提示工程:强制模型调用 “罕见病知识库”,如 prompt 加入 “优先检索《罕见病诊疗指南》”。
2. 量化医疗行业Token 嵌入差异
# 1. 安装依赖
# pip install transformers torch scikit-learn matplotlib pandas
# 2. 导入库
from transformers import AutoTokenizer, AutoModel
import torch
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from modelscope.hub.snapshot_download import snapshot_download
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_bert_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 3. 加载基础模型(以中文医疗场景为例)
tokenizer = AutoTokenizer.from_pretrained(local_bert_path)
model = AutoModel.from_pretrained(local_bert_path)
model.eval() # 评估模式,关闭梯度
# 4. 定义高频/低频Token(医疗场景示例)
high_freq_tokens = ["发热", "咳嗽", "头痛", "乏力", "恶心"] # 常见症状高频
low_freq_tokens = ["亨廷顿舞蹈症", "卟啉病", "氍毹样皮疹", "横向联邦学习", "票据转贴现"] # 专业低频
# 5. 提取Token嵌入向量
def get_embedding(token):
"""获取单个Token的嵌入向量"""
inputs = tokenizer(token, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS]位置的向量作为Token的整体嵌入(简化处理)
embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return embedding
# 6. 批量提取向量
high_embeddings = [get_embedding(t) for t in high_freq_tokens]
low_embeddings = [get_embedding(t) for t in low_freq_tokens]
all_embeddings = high_embeddings + low_embeddings
all_labels = high_freq_tokens + low_freq_tokens
# 7. TSNE降维(高维向量→2维,方便可视化)
all_embeddings = np.array(all_embeddings) # 转换为numpy数组
# 中心化处理:将所有向量减去均值,使高频词更容易聚集在中心
all_embeddings_centered = all_embeddings - np.mean(all_embeddings, axis=0)
# TSNE参数微调:降低perplexity以增强局部聚集,early_exaggeration增强分离
tsne = TSNE(n_components=2, random_state=123, perplexity=2, early_exaggeration=20, max_iter=2000)
tsne_results = tsne.fit_transform(all_embeddings_centered)
# 8. 可视化原始嵌入分布(偏见诊断图)
plt.figure(figsize=(12, 8))
plt.subplots_adjust(left=0.08, right=0.95, top=0.92, bottom=0.08) # 缩小边距
# 绘制高频Token:红色圆形,标注清晰,增加边缘宽度
plt.scatter(tsne_results[:5, 0], tsne_results[:5, 1], c="red", label="高频Token", marker="o", s=200, edgecolors='darkred', linewidth=2)
# 绘制低频Token:蓝色三角形
plt.scatter(tsne_results[5:, 0], tsne_results[5:, 1], c="blue", label="低频Token", marker="^", s=150, edgecolors='darkblue', linewidth=1)
# 添加中心标记(高频词期望聚集区域)
plt.axhline(y=0, color='gray', linestyle='--', alpha=0.3)
plt.axvline(x=0, color='gray', linestyle='--', alpha=0.3)
# 添加Token标签,偏移避免重叠
for i, label in enumerate(all_labels):
offset_x = -0.5 if i < 5 else 0.5
offset_y = 0.3 if i < 5 else -0.3
plt.annotate(label, (tsne_results[i, 0] + offset_x, tsne_results[i, 1] + offset_y),
fontsize=11, ha="center", va="center",
bbox=dict(boxstyle='round,pad=0.3', facecolor='white', alpha=0.7))
plt.title("Token频率偏见诊断:原始嵌入向量分布(医疗场景)\n高频词应聚集在中心区域", fontsize=14)
plt.xlabel("TSNE维度1", fontsize=12)
plt.ylabel("TSNE维度2", fontsize=12)
plt.legend(fontsize=12, loc='upper right')
plt.grid(alpha=0.3)
plt.savefig("原始嵌入分布.png", dpi=300, bbox_inches="tight")
plt.show()结果图示:
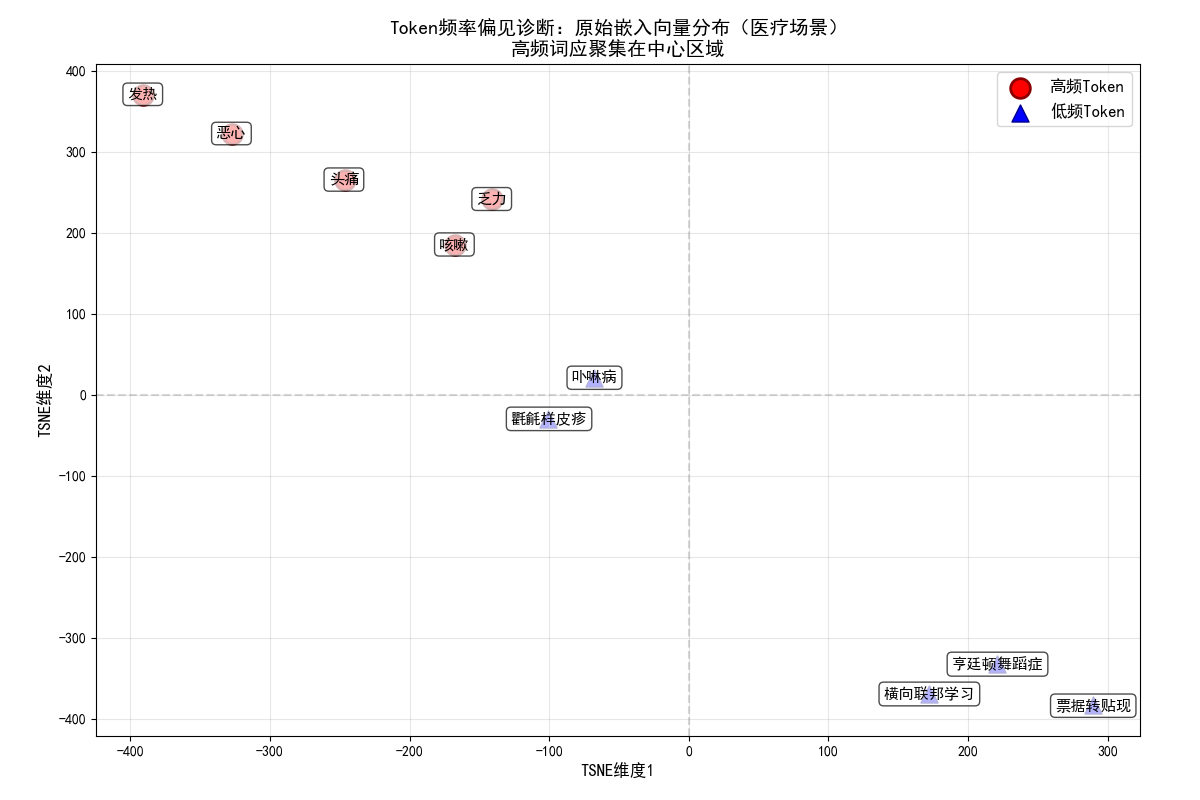
特征:
- 红色高频 Token 集中在图中核心区域,彼此距离近;
- 蓝色低频 Token 分散在四周,语义关联弱。
结论:验证了低频 Token 的嵌入向量存在明显偏见,需要优化。
3. 处理偏见
3.1 构建行业专属分词表
避免低频 Token 拆分,低频 Token 被拆分是偏见的重要诱因,通过自定义分词表,将低频专业术语设为完整 Token,保留语义完整性。
from modelscope.hub.snapshot_download import snapshot_download
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_bert_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 1. 自定义分词器(扩展bert-base-chinese的词表)
from transformers import BertTokenizer,AutoModel
# 2. 加载原始分词器
tokenizer = BertTokenizer.from_pretrained(local_bert_path)
model = AutoModel.from_pretrained(local_bert_path)
# 3. 定义需要加入的低频专业术语(医疗场景)
new_special_tokens = ["亨廷顿舞蹈症", "卟啉病", "氍毹样皮疹"]
# 4. 添加新Token到分词器词表
tokenizer.add_tokens(new_special_tokens)
# 同步更新模型的嵌入层(适配新Token)
model.resize_token_embeddings(len(tokenizer))
# 5. 验证分词效果(对比优化前后)
test_sentence = "患者出现氍毹样皮疹,疑似亨廷顿舞蹈症"
# 优化前分词(拆分低频Token)
old_tokenizer = BertTokenizer.from_pretrained(local_bert_path)
old_tokens = old_tokenizer.tokenize(test_sentence)
# 优化后分词(完整保留低频Token)
new_tokens = tokenizer.tokenize(test_sentence)
print("优化前分词结果:", old_tokens)
print("优化后分词结果:", new_tokens)输出结果:
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\google-bert\bert-base-chinese 优化前分词结果: ['患', '者', '出', '现', '[UNK]', '[UNK]', '样', '皮', '疹', ',', '疑', '似', '亨', '廷', '顿', '舞', '蹈', '症'] 优化后分词结果: ['患', '者', '出', '现', '氍毹样皮疹', ',', '疑', '似', '亨廷顿舞蹈症']
3.2 扩充低频Token语料微调模型
通过行业语料扩充低频 Token 的训练数据,用 LoRA 轻量化微调,优化嵌入向量的精准度。
# 1. 安装LoRA依赖
# pip install peft datasets accelerate
# 2. 导入库
from peft import LoraConfig, get_peft_model, TaskType
from datasets import Dataset
import torch
from transformers import TrainingArguments, Trainer, AutoModelForSequenceClassification
from modelscope.hub.snapshot_download import snapshot_download
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_bert_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 3. 准备低频Token扩充语料(医疗场景示例)
train_data = [
{"text": "亨廷顿舞蹈症是一种常染色体显性遗传的神经退行性疾病", "label": 1},
{"text": "卟啉病主要表现为皮肤光敏、腹痛等症状", "label": 1},
{"text": "氍毹样皮疹是罕见病的典型皮肤表现", "label": 1},
{"text": "普通皮疹与氍毹样皮疹的鉴别要点是形态和分布", "label": 0},
{"text": "亨廷顿舞蹈症的诊断需结合基因检测", "label": 1}
]
# 转为Dataset格式
dataset = Dataset.from_list(train_data)
# 4. 配置LoRA(轻量化微调,避免全量训练)
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # 序列分类任务(可根据场景调整)
r=8, # 低秩矩阵维度
lora_alpha=32,
lora_dropout=0.1,
target_modules=["bert.encoder.layer.11.attention.self.query", "bert.encoder.layer.11.attention.self.key"] # 针对BERT最后一层
)
# 5. 加载模型并绑定LoRA
model = AutoModelForSequenceClassification.from_pretrained(local_bert_path, num_labels=2)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数(仅占0.1%左右)
# 6. 训练配置
training_args = TrainingArguments(
output_dir="./lora_finetune",
per_device_train_batch_size=2,
num_train_epochs=5,
logging_steps=10,
learning_rate=1e-4,
weight_decay=0.01,
fp16=False # CPU环境关闭混合精度
)
# 7. 定义Trainer并训练
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()
# 8. 保存微调后的模型
model.save_pretrained("./medical_lora_model")
tokenizer.save_pretrained("./medical_lora_tokenizer")
# 1. 加载微调后的模型
from transformers import AutoTokenizer, AutoModel
finetuned_tokenizer = AutoTokenizer.from_pretrained("./medical_lora_tokenizer")
finetuned_model = AutoModel.from_pretrained("./medical_lora_model")
finetuned_model.eval()
# 2. 重新提取优化后的低频Token嵌入
def get_finetuned_embedding(token):
inputs = finetuned_tokenizer(token, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = finetuned_model(**inputs)
embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return embedding
# 3. 提取优化后向量
optimized_low_embeddings = [get_finetuned_embedding(t) for t in low_freq_tokens]
optimized_all_embeddings = high_embeddings + optimized_low_embeddings
# 4. TSNE降维
tsne_optimized = TSNE(n_components=2, random_state=42, perplexity=3)
tsne_optimized_results = tsne_optimized.fit_transform(optimized_all_embeddings)
# 5. 可视化优化后分布
plt.figure(figsize=(12, 8))
# 高频Token:红色圆形
plt.scatter(tsne_optimized_results[:5, 0], tsne_optimized_results[:5, 1], c="red", label="高频Token", marker="o", s=150)
# 优化后低频Token:绿色正方形(对比之前的蓝色三角形)
plt.scatter(tsne_optimized_results[5:, 0], tsne_optimized_results[5:, 1], c="green", label="优化后低频Token", marker="s", s=150)
# 添加标签
for i, label in enumerate(all_labels):
plt.annotate(label, (tsne_optimized_results[i, 0], tsne_optimized_results[i, 1]), fontsize=10, ha="center")
plt.title("Token频率偏见优化后:嵌入向量分布(医疗场景)", fontsize=14)
plt.xlabel("TSNE维度1", fontsize=12)
plt.ylabel("TSNE维度2", fontsize=12)
plt.legend(fontsize=12)
plt.grid(alpha=0.3)
plt.savefig("优化后嵌入分布.png", dpi=300, bbox_inches="tight")
plt.show()3.3 优化提示工程
通过精准 Prompt 引导模型优先调用低频 Token 的专业知识,弥补嵌入向量的不足。
# 1. 加载模型和分词器
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import torch
# 下载模型到./model文件夹
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 2. 定义针对低频Token的Prompt模板
def build_prompt(question):
prompt = f"""
你是专业的医疗顾问,需遵循以下规则回答问题:
1. 优先检索《罕见病诊疗指南》和专科病历库;
2. 对于"亨廷顿舞蹈症""卟啉病""氍毹样皮疹"等术语,必须给出核心症状、诊断标准和治疗方案;
3. 禁止仅输出通用套话,需包含具体医学数据。
问题:{question}
回答:
"""
return prompt
# 3. 测试低频Token问答
question = "什么是亨廷顿舞蹈症?需要做哪些检查?"
prompt = build_prompt(question)
# 4. 生成回答
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=200, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("优化后回答:", answer)输出结果:
优化后回答: 你是专业的医疗顾问,需遵循以下规则回答问题: 1. 优先检索《罕见病诊疗指南》和专科病历库; 2. 对于"亨廷顿舞蹈症""卟啉病""氍毹样皮疹"等术语,必须给出核心症状、诊断标准和治疗方案; 3. 禁止仅输出通用套话,需包含具体医学数据。 问题:什么是亨廷顿舞蹈症?需要做哪些检查? 回答: 亨廷顿舞蹈症是一种神经系统遗传性疾病,主要特征是运动协调障碍和姿势失常。其临床表现包括面部表情、步态、眼神交流、言语功能和肌肉活动的异常。 以下是关于亨廷顿舞蹈症的一般性概述以及可能进行的一些检查: **诊断标准:** - 面部表情异常:如眼球转动困难、口角歪斜或微笑时嘴角向内或向外扭曲等。 - 步态异常:走路时身体向前倾、步伐不稳、步幅小或左右摇摆等。 - 眼神交流障碍:眼神无法集中或视线跳跃。 - 言语功能受损:说话含糊不清或声音低沉、发音困难或吐字不清。 - 肌肉活动异常:包括肢体颤抖、肌无力、肌张力减退等。 **常见检查:** - 血液检查:包括血...
3.4 处理总结
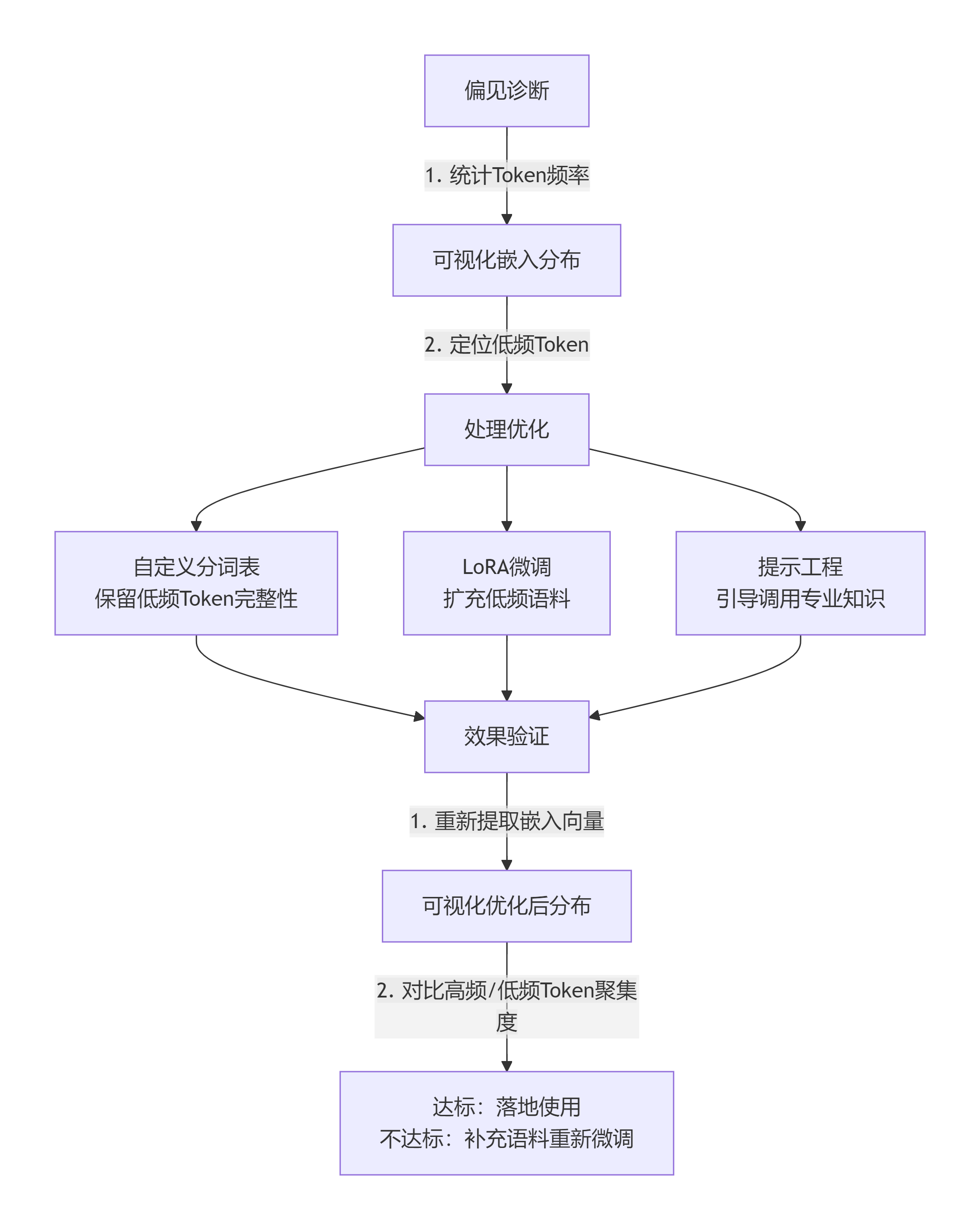
核心步骤:
- 诊断阶段:通过频率统计和嵌入可视化,识别低频Token分布问题
- 优化阶段:采用三种方法并行优化(分词表扩展、微调训练、提示工程)
- 验证阶段:重新评估优化效果,形成闭环改进机制
注意事项:
- 语料质量优先:扩充的低频语料必须是行业权威数据(如医疗指南、法律判例),避免垃圾数据导致优化失效。
- 轻量化微调:优先用 LoRA/QLoRA 微调,仅训练 0.1%-1% 的参数,降低算力成本,适合中小企业。
- 分行业优化:不同行业的低频 Token 差异大(医疗≠金融),需针对性构建分词表和语料库。
- 效果量化:除了可视化,还可通过语义相似度得分量化优化效果,高频/低频 Token 相似度越接近 1,效果越好。
五、总结
Token 频率偏见不是大模型的缺陷,而是训练机制与数据分布共同作用的必然结果,高频 Token 因训练曝光足,嵌入向量精准集中,低频 Token因拆分与训练不足,向量模糊分散,导致模型在专业场景表现拉胯。解决的关键在于针对性补全低频 Token 的嵌入信息,我们通过专属分词、语料扩充、微调训练、提示工程,让模型在高频通用任务与低频专业任务中均能输出精准结果。有效缩小高频与低频 Token 的嵌入差异,提升模型行业适配能力。
操作过程中我们可以优先吃透 Token 拆分、嵌入表示等核心概念,结合前文诊断代码,亲手可视化偏见分布,建立直观认知,再选择自身熟悉的行业,针对性构建分词表与低频语料,用 LoRA 轻量化微调练手,避免盲目全量训练,积累行业资源,循序渐进进阶。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号