KnowLion:基于动态图数据库的动态超图知识检索开源系统

KnowLion:基于动态图数据库的动态超图知识检索开源系统

山行AI
发布于 2026-03-13 18:54:41
发布于 2026-03-13 18:54:41
重新定义企业知识检索
在企业级检索增强生成(RAG)领域,传统方案普遍面临“知识割裂(向量库与静态图谱分离)、更新滞后(人工定时维护)、召回不全(仅1-2路检索)、可解释性弱(无推理路径)”四大核心痛点,难以支撑动态演化的业务知识管理需求。
KnowLion作为首款基于动态图数据库(AbutionGraph)实现的企业级智能HyperGraphRAG系统,通过“动态知识建模+多维度检索融合+实时知识聚合”三大核心能力,构建“Doc→Para→Entity”三级超图一体化存储,实现从“功能性信息检索”到“越用越聪明的动态知识管理”的跨越。
核心亮点
•✅ 五重检索内核:融合Vector语义、BM25关键词、Graph动态推理、上下文关联、实体多跳推理,覆盖“模糊查询-精准术语-跨文档关联-深层推理”全场景;•✅ 全属性实时演化:实体频次、实时语义聚合、邻居基数等属性通过动态聚合函数自动更新,无需人工干预,新文档入库即可检索;•✅ 智能自维护机制:段落主题重叠率≥80%时触发VectorSimCrudAgent,调用LLM自动合并相似知识、更新冲突关系,维护成本降低80%;•✅ 轻量化超图架构:跨文档多对多轻量级聚合边设计(仅存“事实+频次”),避免传统图谱存储冗余,多跳推理速度提升50%。
1 系统架构全景
1.1 全链路闭环设计
KnowLion采用“知识生产-存储-检索-维护-问答”一体化全链路闭环设计架构,覆盖非结构化数据解析、知识存储架构、知识自驱更新、知识检索召回设计、精准答案生成等全RAG环节的闭环,解决传统RAG“数据割裂、检索单一”问题。
1.1.1 知识库架构:动态化知识生产流水线
负责将非结构化数据转化为动态可检索的知识图谱,流程如图1所示:
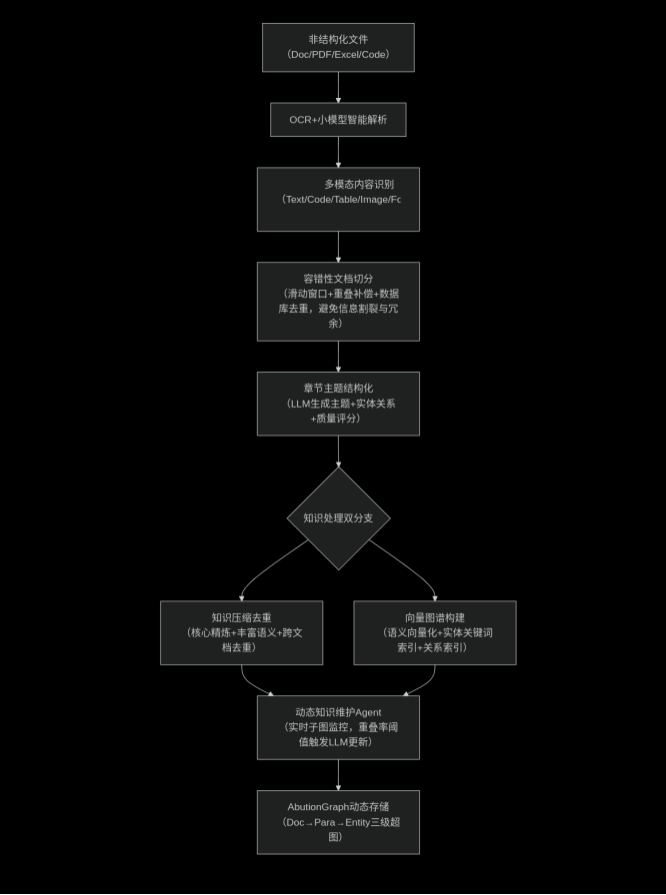
动态化知识生产流水线
动态化知识生产流水线
1.1.2 检索架构:五路召回+RRF融合引擎
采用分层索引设计:文档级向量索引(粗筛) → 段落级向量计算(精匹配) → 实体级关联推理(深度发现)。负责将用户问题转化为精准可解释的答案,支持完整的检索路径可视化、推理链条展示、置信度解释和源头追溯(如“GC03→原材料A→供应链风险”),流程如图2所示:
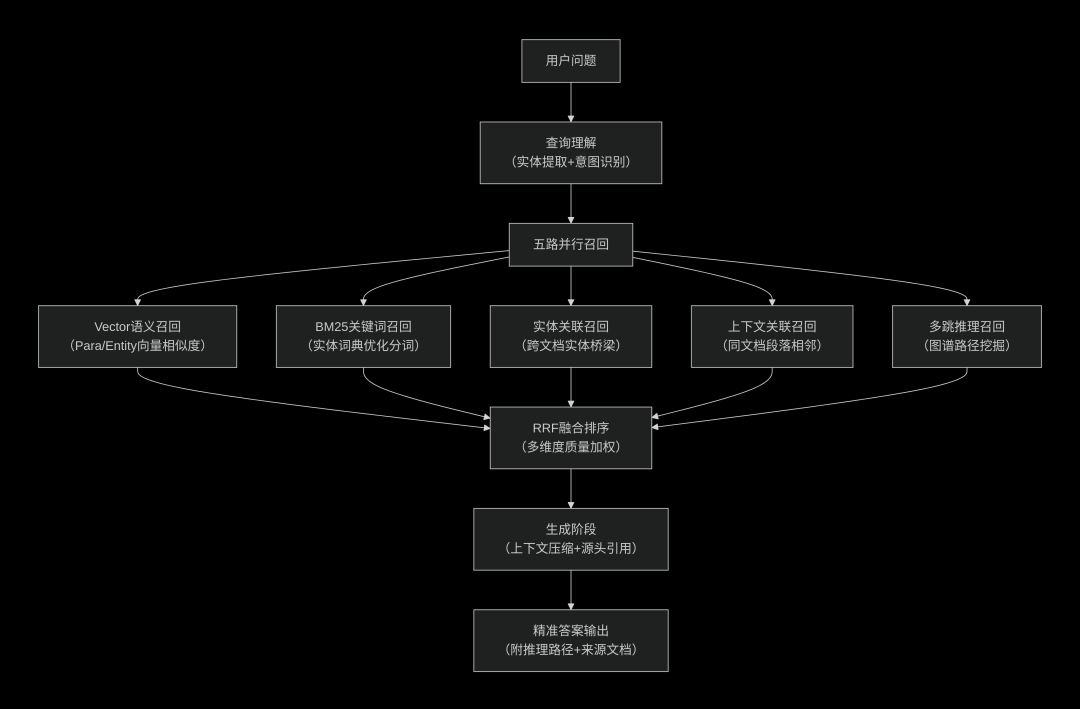
检索架构:五路召回+RRF融合引擎
检索架构:五路召回+RRF融合引擎
1.2 核心技术栈与痛点解决方案
传统方案在知识检索领域存在跨文档关联断裂、单一检索方式覆盖不全、深层推理能力缺失、知识更新滞后以及结果可信度难评估等核心痛点。KnowLion针对性提出解决方案:通过实体桥梁实现跨文档知识连接,以五路召回机制形成互补来解决单一检索覆盖不全问题,依托多跳路径发现隐含关联补足深层推理能力,借助实时聚合更新机制改善知识更新滞后状况,并通过多维度质量评分体系保障结果可信度,全面攻克传统方案短板,提升知识检索的完整性、时效性与可靠性。
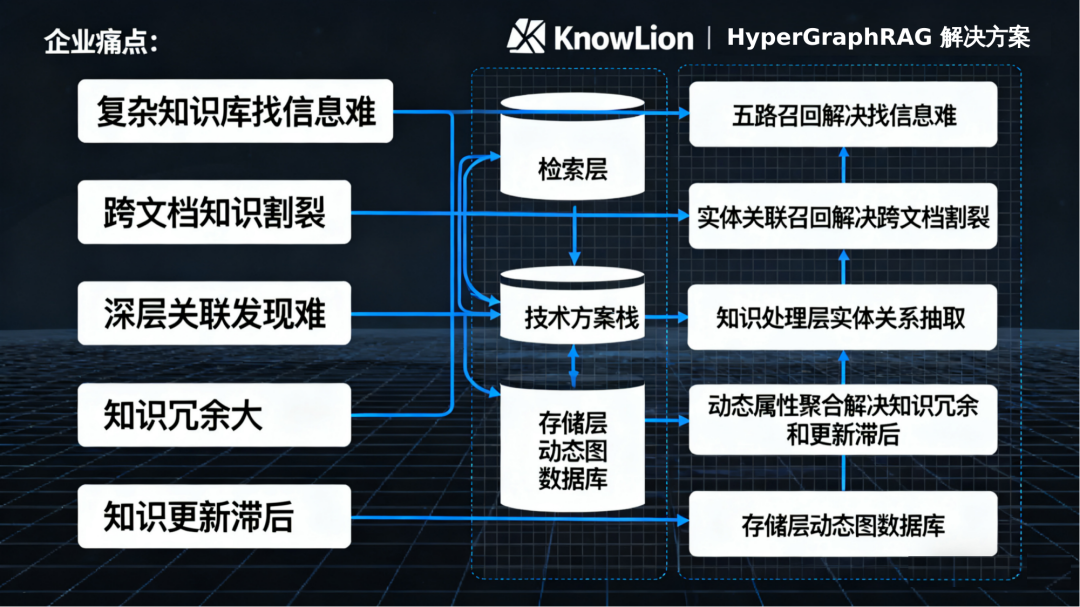
KnowLion - HyperGraphRAG解决方案
KnowLion - HyperGraphRAG解决方案
KnowLion核心技术栈由五层核心架构协同构成,形成从多源内容解析到知识动态维护的全链路能力。
技术层 | 核心组件 | 功能作用 |
|---|---|---|
文档解析层 | OCR小模型 + 多模态大模型 | 识别多格式内容,图片/表格/公式转结构化文本 |
知识处理层 | EmbeddingModel + LLM | 语义向量化、实体关系抽取、质量评分 |
存储层 | AbutionGraph动态图数据库 | 动态属性聚合、实时索引、实时图计算 |
检索层 | 五路召回引擎 + RRF排序 | 全场景检索、公平融合 |
维护层 | Agent智能组件 | 相似知识子图合并、自动更新 |
2 三级超图存储结构设计
2.1 创新存储架构
KnowLion摒弃传统“向量库+静态图谱”分离模式,以“检索为中心”设计Schema,构建“Doc→Para→Entity”三级超图,实现“语义特征、实体关系、动态属性”一体化存储。利用时序聚合计算能力实现实时演化,数据写入立即可进行多粒度检索互筛,无需二次加工。并且各层级实体均具备“静态标识+动态属性”,通过AbutionGraph聚合函数实现实时更新。
实体层级 | 核心属性(动态聚合能力) | 聚合方式/更新逻辑 | 核心作用 |
|---|---|---|---|
文档(Doc) | 1. vector:文档级聚合向量2. doc_bm25:实体词频/逆文档频率3. updated_at:最新更新时间4. classify:子图隔离标签 | 1. VectorIndexMerge()2. BM25Index()3. Agg.Max()4. Agg.StrConcat("|") | 粗粒度索引,快速筛选相关文档 |
段落(Para) | 1. content:动态融合内容2. entity_count:实体密度3. vector:段落语义向量4. 主题重叠率:触发Agent更新 | 1. Agg.StrConcat("\n")2. Agg.Sum()3. Agg.FloatArrayAdd()4. 实时计算 | 细粒度检索单元,直接作为答案来源 |
实体(Entity) | 1. synonyms:同义词集合2. occur_count:出现频次3. confidence/importance:置信度/重要性4. neighbors:邻居基数5. vector:聚合向量 | 1. Agg.CollectionConcat()2. Agg.Sum()3. Agg.QuantileDoubles()4. Agg.DistinctCountHllp()5. Agg.FloatArrayAdd() | 知识关联核心,支撑跨文档/多跳检索 |
2.2 架构优势分析
三层不同粒度的图谱结构设计,是纯向量方式到文章结构图谱的复杂度折中方案:
•Doc类型实体:包含文章结构信息,用于全局检索•Para类型实体:包含切片的段落摘要主题(已结合上下文去冗余优化)•Entity类型实体:包含跨文档的实体细节(自动跨文档信息融合)
三种不同粒度的知识结合可实现粗细粒度的召回互筛,提升检索精度,同时避免了基于纯向量知识库(VectorRAG)精度过低的问题,以及基于纯图谱知识库(GraphRAG)构建过于复杂的维护难题。
2.3 关联关系设计
KnowLion在“Doc→Para→Entity”三级超图的关联关系上采用多对多的轻量级聚合边设计:
•一个实体关联多文档/段落•一个段落包含多实体•重复边自动合并成一条无损事实边•还原知识复杂关联,有效避免“信息孤岛”•串联跨部门知识
边仅存储关联事实和动态权重,实时自动去重能大大减少存储,提升多跳推理速度。实体可通过一跳关系聚合多个邻居的语义,实现实体语义的自动扩增与融合,检索精度随知识积累持续优化。
3 动态图谱核心技术
3.1 动态图谱创新特性
传统RAG图谱多为“静态构建+定期更新”,KnowLion的核心是动态属性驱动的超图模型。通过8大动态特性实现知识“自生长、自优化”:
动态特性 | AbutionGraph内置实现 | 业务价值 |
|---|---|---|
时序驱动演化 | updated_at(Agg.Max())+occur_count(Agg.Sum()) | 高频实体优先展示,旧知识自动降权 |
实时向量聚合 | vector(Agg.FloatArrayAdd()) | 新文档立即内可检索,检索精度不衰减 |
动态邻居发现 | neighbors(Agg.DistinctCountHllp()) | 识别核心实体(如高频关联的“GC03项目”) |
质量动态评估 | confidence(Agg.QuantileDoubles()) | 业务新词自动标记,支撑NLP模型对查询文本的识别 |
关系事实演进 | fact(Agg.CollectionConcat()) | 保留关系全量历史,避免描述丢失 |
权限动态继承 | classify(Agg.RoleConcat()) | 新实体/段落自动继承权限,适配多租户 |
实时索引更新 | Vector/BM25索引增量更新 | 知识更新无感知,响应速度稳定 |
Agent自动维护 | 重叠率阈值触发Agg.VectorSimCrudAgent(monitor) | 使用LLM自动更新局部区域子图,减少人工成本,降低知识冗余 |
3.2 聚合函数能力
动态特性的实现得益于Abution时序图谱的聚合策略设计。区别于物联网需要时间窗口的场景,RAG场景没有多维时序的特殊要求,可直接调用Abution的基础聚合函数获得丰富的拓扑图指标:
属性类型 | 聚合函数 | 业务意义 |
|---|---|---|
数值统计 | Agg.Sum() | 统计实体频次、段落实体密度 |
语义向量 | Agg.FloatArrayAdd() | 实体向量融合邻居信息,提升匹配度 |
集合操作 | Agg.CollectionConcat() | 合并标签、同义词,自动去重 |
高基数统计 | Agg.DistinctCountHllp() | 高效统计实体邻居基数,避免内存溢出 |
分位数统计 | Agg.QuantileDoubles() | 实时计算置信度/重要性,筛选高质量知识 |
这对召回时的上下文及实体质量评估能起到关键作用。
3.3 动态知识图谱建模
此展示为KnowLion系统的简化版schema,采用AbutionGraph原生建模结构,图查询语言不限于Cypher、Gremlin、SparQL、GraphQL。
# 初始化智能维护Agent
vector_agent =Agg.VectorSimCrudAgent(
model_configs={"model":"deepseek-v3","threshold":0.8},
enabled=True
)
# 核心Schema定义
schema =(Schema.Builder()
# 1. 文档实体(Doc)
.entity("文档",Dimension.label("Doc","粗粒度索引-分布式并行"))
.property("titles", T.TreeSetString,Agg.CollectionConcat(),"文档目录(去重)")
.property("vector", T.VectorIndex,Agg.VectorIndexMerge(),"文档聚合向量")
.property("doc_bm25", T.BM25Index,Agg.BM25Index(),"BM25关键词索引")
.property("updated_at", T.Long,Agg.Max(),"最新更新时间")
.property("classify", T.String,Agg.StrConcat("|"),"子图隔离标签")
.groupBy("user_id","classify")
# 2. 段落实体(Para)
.entity("段落",Dimension.label("Para","检索最小单元"))
.property("doc_name", T.String,Agg.Last(),"所属文档")
.property("content", T.String,Agg.StrConcat("\n"),"动态融合内容")
.property("type", T.String,Agg.StrConcat("|"),"内容类型(Text/Table等)")
.property("entity_count", T.Integer,Agg.Sum(),"实体密度统计")
.property("vector", T.FloatArray,Agg.FloatArrayAdd(),"段落语义向量")
.property("vector_paras", T.CustomMap,Agg.CustomMap(vector_agent),"相似性检测与合并")
.property("processing", T.Boolean,Agg.IsTrue(),"段落处理-执行Agent的状态控制")
.groupBy("user_id","classify","doc_name")
# 3. 实体实体(Entity)
.entity("实体",Dimension.label("Entity","知识关联核心"))
.property("labels", T.TreeSetString,Agg.CollectionConcat(),"实体标签(去重)")
.property("synonyms", T.TreeSetString,Agg.CollectionConcat(),"同义词扩展")
.property("details", T.CustomMap,Agg.CustomMap(Agg.StrConcat("\n")),"多源描述")
.property("occur_count", T.Integer,Agg.Sum(),"出现频次")
.property("confidence", T.QuantileDoubles,Agg.QuantileDoubles(),"置信度分位数")
.property("neighbors", T.DistinctCountHllp,Agg.DistinctCountHllp(),"邻居高基数统计")
.property("vector", T.FloatArray,Agg.FloatArrayAdd(),"实体聚合向量")
.groupBy("user_id","classify")
# 4. 核心关系(Edge)
.edge("文档","段落",Dimension.label("Doc2Para","文档-段落关联"))
.edge("段落","段落",Dimension.label("Para2Para","上下文关联"))
.edge("段落","实体",Dimension.label("Para2Entity","段落-实体关联"))
.edge("实体","实体",Dimension.label("Entity2Entity","实体-关系关联"))
.property("fact", T.TreeSet,Agg.CollectionConcat(),"关系事实描述")
.property("occur_count", T.Integer,Agg.Sum(),"关系频次")
.groupBy("user_id","classify")
# 5. 权限控制|子图隔离标签
.dataRoleProperty("classify")
.build())4 多路检索架构设计
4.1 整体检索流程
用户问题→多路并行召回→ RRF重排序→上下文压缩→生成答案
↓↓↓↓↓
查询理解向量/关键词/关联/融合排序信息精炼可解释答案
上下文/推理召回4.2 互补性设计原理
KnowLion的五路召回基于“互补性原则”深度协同:
•语义↔关键词互补:Vector覆盖“语义相似”需求,BM25覆盖“术语精准匹配”需求•实体↔上下文互补:实体关联实现“横向跨文档扩展”,上下文关联实现“纵向同文档深化”•基础↔推理互补:前四路覆盖“表层信息召回”,多跳推理覆盖“深层逻辑挖掘”
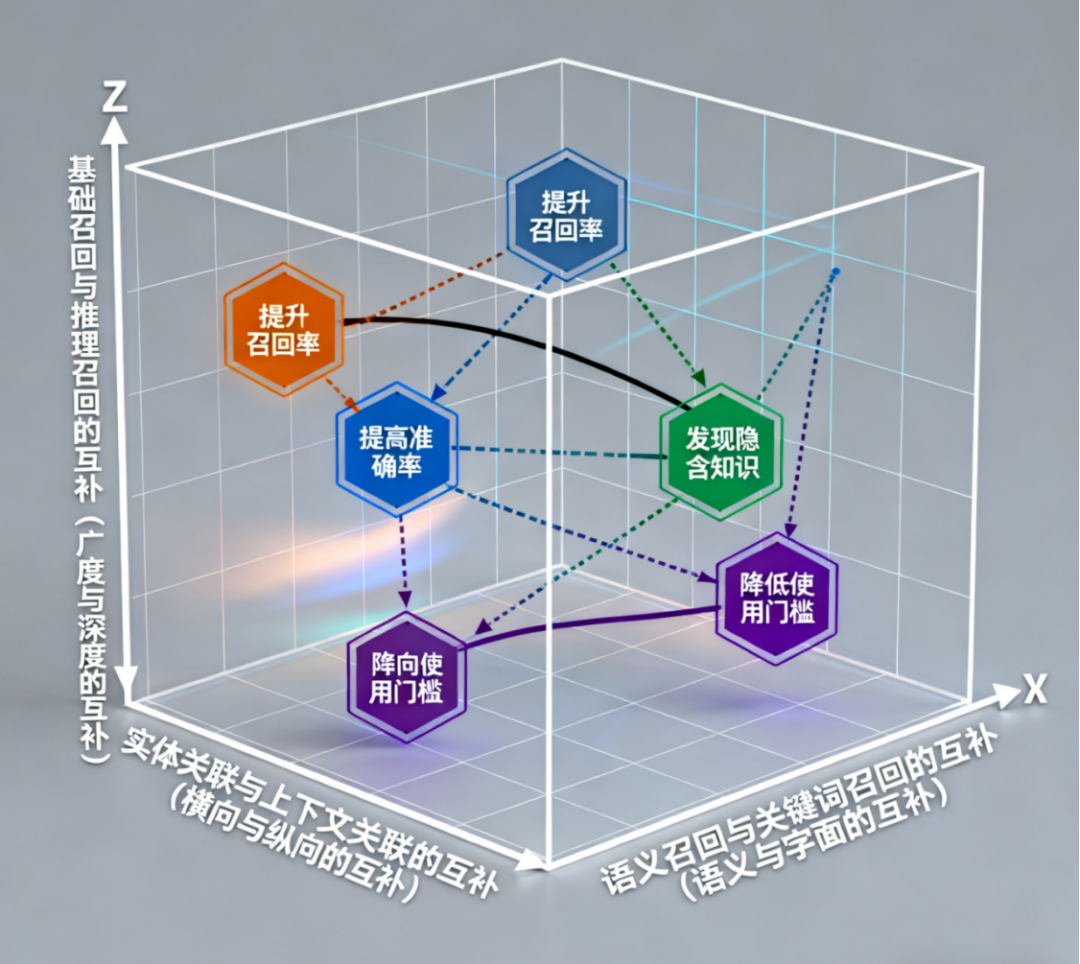
HyperGraphRAG-多路检索架构设计
HyperGraphRAG-多路检索架构设计
4.2.1 全场景五路召回策略
召回路径 | 技术原理 | 优化策略 | 适用场景 |
|---|---|---|---|
1. Vector语义召回 | 基于语义向量计算余弦相似度 | 文档粗筛→段落精筛,效率提升10倍 | 模糊查询(如"如何优化检索速度") |
2. BM25关键词召回 | 实体词典优化分词,统计词频/逆文档频率 | 双输出:文档段落+命中实体,精准匹配术语 | 技术术语(如"API参数配置") |
3. 实体关联召回 | 以种子实体为桥梁,串联跨文档段落 | 实体质量分=相似度×重要性×中心性×跨文档奖励 | 跨部门知识关联(如"项目进度") |
4. 上下文关联召回 | 基于Para2Para边,召回相邻段落 | 实体密度≥5的段落得分+20%,优先高信息密度 | 步骤类查询(如"部署流程") |
5. 多跳推理召回 | 2-3跳路径遍历,路径得分剪枝 | 得分公式:0.4语义+0.3路径+0.2重要性+0.1多样性 | 深层关联(如"项目供应链风险") |
4.3 融合排序与质量评估
4.3.1 RRF融合排序优化
采用RRF算法实现公平融合,并二次排序:RRF得分相同时,按"实体质量分+跨文档权重"排序,实现多路结果去重、多样性保障、动态K值调整。
4.3.2 质量评估体系
评估维度 | 评估标准 |
|---|---|
实体置信度 | 基于出现频次(occur_count)和来源权威性(核心文档+30%得分) |
路径质量 | 推理路径完整性(≥2个高置信度实体)+关系匹配度(≥0.8) |
内容质量 | 段落实体密度(entity_count≥5得分+20%)+语义完整性(无截断) |
多样性 | 结果集来自不同文档/部门的段落+15%得分,避免同质化 |
5 智能维护Agent实现
5.1 核心架构设计
VectorSimCrudAgent是动态维护的核心,负责相似知识检测、合并与图谱更新。每个段落实体都具备自动检测和优化能力,一旦满足条件即触发大模型进行知识图谱更新任务。
5.1.1 核心职责
1.向量相似性检测:基于余弦相似度(阈值0.8)判断段落/实体是否相似,标记待合并项2.知识合并优化:调用LLM提取核心语义,生成精简完整的新内容3.图谱一致性更新:删除旧节点及关联边,插入新节点并重建关系,确保超图结构完整
5.1.2 工作流程
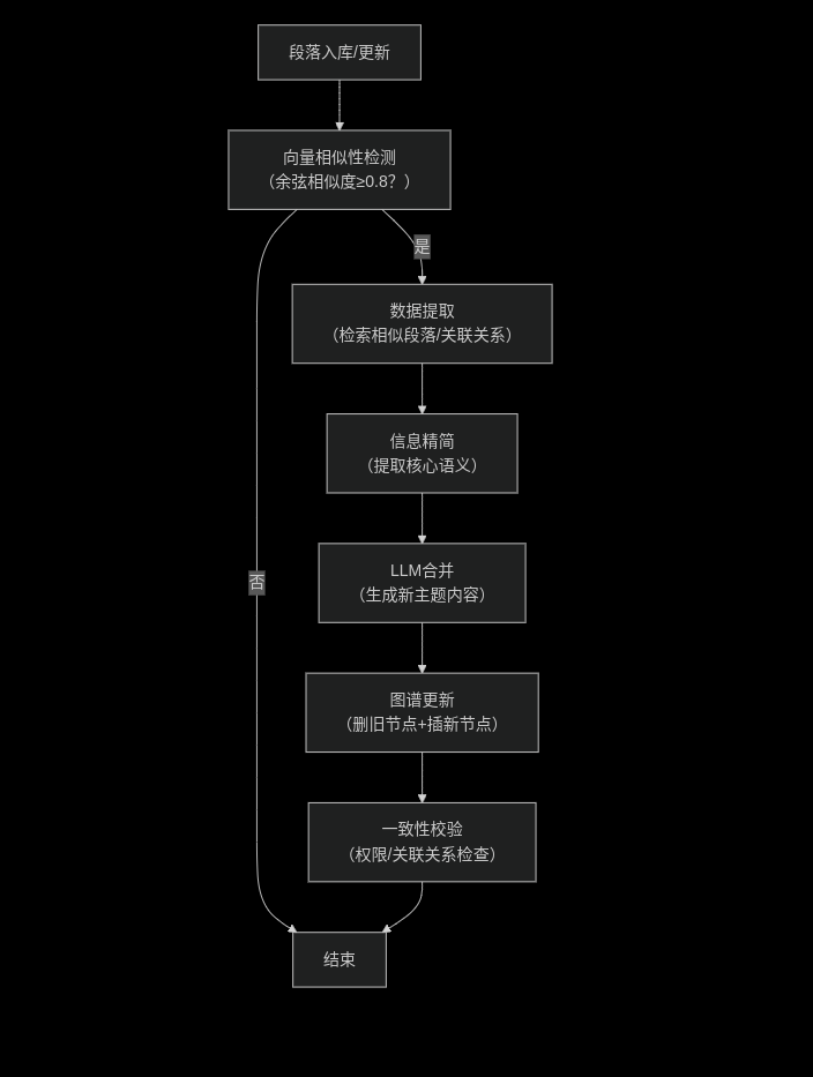
KnowLion-VectorSimCrudAgent工作流程
KnowLion-VectorSimCrudAgent工作流程
5.2 关键特性
•可配置:支持调整相似度阈值、LLM参数、触发频率•异步处理:基于CompletableFuture实现非阻塞合并,不影响检索响应•容错机制:合并失败自动回滚,避免图谱数据损坏•MCP集成:AbutionGraph已融入MCP体系,未来可优化为推理Agent,让LLM真正成为知识探索与决策智能的知识库"助手"
6 实际应用价值验证
6.1 企业知识管理场景
•多租户隔离:完整数据隔离权限•细粒度权限:用户级文档访问控制•文档分类管理:在用户基础上设置文档类别进行子图隔离•版本管理:时序属性支持文档演化追踪
6.2 智能问答系统
•复杂查询处理:多跳推理解决复杂问题•质量保障:多维度评估确保答案可靠性•追溯能力:完整的引用和来源标注
6.3 学术研究支持
•术语扩展:同义词集合支持学术术语变异•文献关联:跨文献的实体关系发现•可信度评估:基于引用频次的置信度计算
7 总结:KnowLion核心竞争力
7.1 技术优势
在RAG技术同质化严重的当下,KnowLion的差异化优势集中在三大维度:
1.动态化内核:从数据建模到检索,全链路动态化,突破传统RAG的静态瓶颈2.多维度融合:五路召回+RRF融合,覆盖"表层-深层""单一文档-跨文档"全场景3.企业级适配:细粒度权限、高基数优化、Agent自动维护,满足大规模落地需求
7.2 与传统系统对比
相对于纯向量数据库:
1.结构化语义理解2.可解释性增强3.多粒度检索
相对于传统图数据库:
1.内置语义检索能力2.综合利用结构化和语义信息
7.3 核心价值定位
KnowLion不仅是技术工具,更是企业知识管理的"智能中枢"——通过动态化、全维度的设计,让每一份知识都能被精准检索、实时更新、深度关联,为企业数字化转型提供坚实的知识支撑。
总的来说,KnowLion是第一个在图数据库层次和大语言模型结合的高级检索系统先驱,旨在提供更准确、可解释性更强的检索结果,是企业级知识管理的理想解决方案。
开源地址:https://github.com/ThutmoseAI/KnowLion
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号