用文件系统思路设计Agent记忆系统


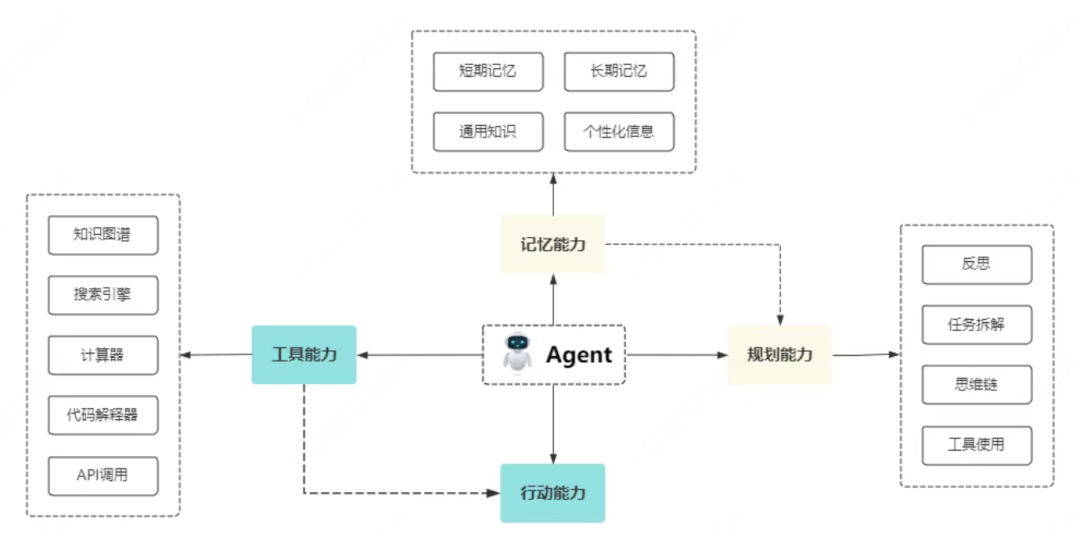
智能体中[记忆模块]很重要。
如果想让智能体更好的服务用户,精准的记住用户的偏好和历史交互细节等信息就非常重要。
智能体记忆简单来说分为两类:短期记忆(会话级记忆)、长期记忆(跨会话的记忆)。
用户与Agent的多轮对话过程中会出现很多记忆,包括用户原始的意图、诉求、关键词,还包括Agent的推理、规划、工具调用的执行结果及模型最终的响应。
这些信息记录好了,有助于维持多轮对话的连贯性,提升用户体验。
每轮对话背后,都由一个智能体记忆模块会进行会话信息提炼和通用信息整理,不断抽取用户偏好、画像、核心事实、个性化信息等,用于辅助Agent在后续对话中进行推理。
当然也有人将智能体记忆区分的更细,比如分为聊天历史、用户画像、知识图谱等类型。
智能体毕竟是一个软件系统,所以越来越多人用软件设计的思想实现[记忆模块]。
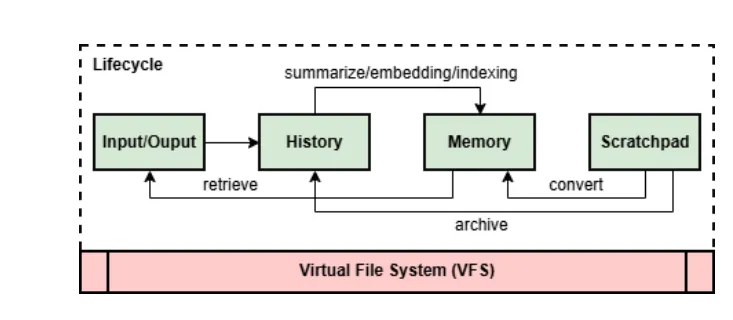
我们将智能体类比于一台计算机,文件系统就是计算机的记忆模块。
关键的即时可用的记忆,放到内存中,必要但不即时的记忆,可以放在文件系统中。
比如这个记忆模块会按照文件类型来组织文件,有文档、图片、视频、音频、应用程序等。类比到智能体,这些记忆就是文档、图片、视频、音频、工具。
为了更好的管理这些记忆资源,上一层可以抽象一个上下文层,用于加载、淘汰、删除、重构记忆资源。过程中涉及到加载、构造、评估等上下文操作(召回->粗排->精排)。
就像CPU不断调度各种任务、分配各种资源、管理内存淘汰、多核协作等操作。可以将其视为一个编排层,负责整体的协同。
图片
首先是抽象,无论底层是知识图谱、向量数据库、还是文件系统、分布式存储,都抽象出一个标准化的文件接口,这样你就对底层记忆的文件类型屏蔽了,降低了操作成本。
如果哪天底层切换存储组件,Agent层完全不需要感知,切换很灵活。
因为在接口层面做了抽象,所以可以很好的面向功能进行接口涉及,而无需关注这个功能接口究竟是用了一个文件系统还是多个类型的文件系统。
可以借助分布式数据库的思路,对所有的记忆读写过程进行日志记录,记录推理过程,对阶段性建设summary快照和事务性控制很有帮助。
记忆没办法全量数据存储,也没有意义,必然涉及到压缩,而压缩往往是有损的。
所以需要考虑尽可能的通过摘要、总结、过滤、合并、整理的方式,即保留核心观点,同时可以减少信息体量。
长期记忆召回,也需要考虑召回策略,比如可以按照时间远近召回,这样可以确保召回的信息与当前对话具有相关性,远期历史信息逐步展开的方法。
回过头来,我们看一下从用户提出问题,到最终Agent给出回答的整个流程如下。
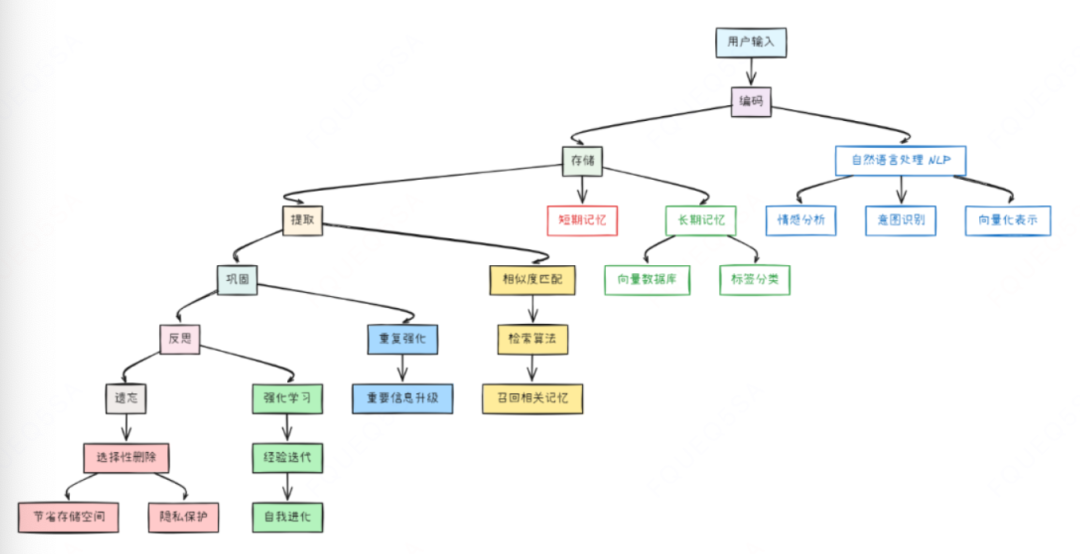
首先是对用户输入进行编码,将信息结构化,从用户输入中提取谁、在什么情景下、做了什么、这件事对谁重要、标准和约束条件是什么。
这些信息可以提取标签,包括主题、时间、清晰、权重、优先级、隐私敏感度等。
以上被编码结构化的信息,将会分门别类的方式放进工作台或对应的仓库里面进行存储,比如识别到短期可能需要用到的要点信息放入短期记忆,一些关键但不会即时用到的高价值信息存入长期记忆。
基于用户输入的标签,依托于相关性+相近性+重要性综合打分,从短期+长期存储中做召回。
如果信息被用户采纳了,那么这些被采纳的信息,将从可能有用变为长期有用,被进一步打标整理,放到优先级较高的存储区域。
总之,这些信息是不断被打标、整理、提取、再排优先级的过程,相关性或优先级较低的记忆,会被逐渐弱化,有用且价值高的信息将会放在前面被快速召回。
最终实现类似于操作系统的文件系统能力,让智能体的记忆可追溯(每一步有据可查)、可审计(所有操作都有日志)、可演化(新组件无缝接入),整个Agent的记忆历史都是可以回溯的,而不是黑盒了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号