企业中落地AI Agent的难点


下图是一个企业Agent落地的标准架构。
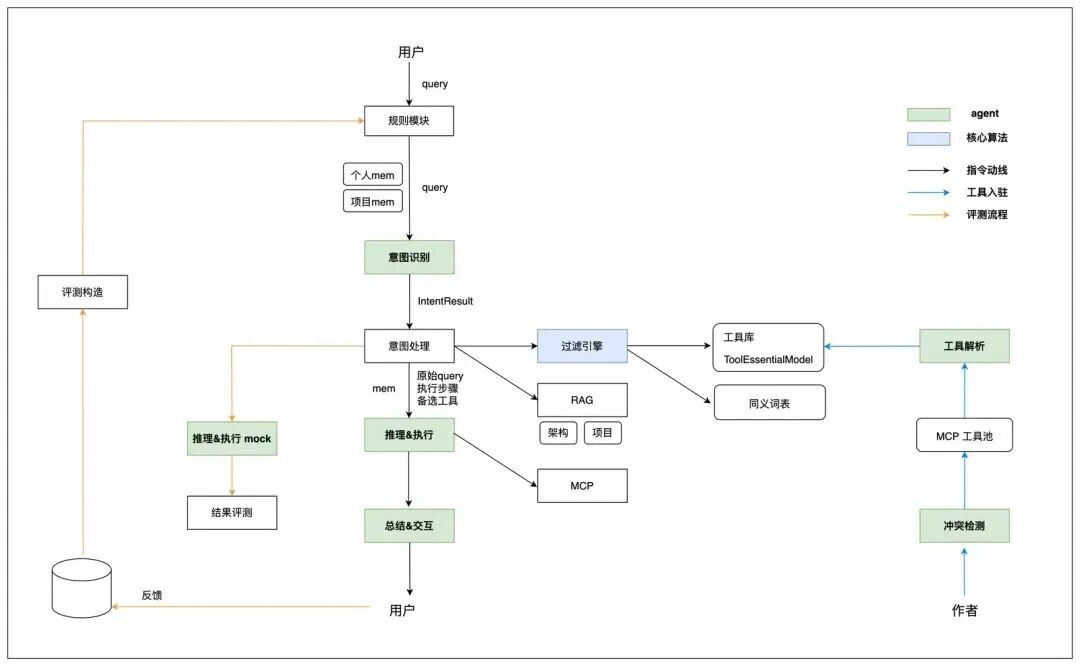
在Query动线上,包括规则模块、意图识别模块、意图处理模块、过滤引擎、推理执行、总结整理。
意图识别主要是解决两个问题:抽象出意图类型、抽象出意图模型(IntentResult)。
前者决定了问题空间,后者(IntentResult)统一了意图解析的范式(辅助LLM判断指令的合法性,是否有阻断性的参数缺失可以回问用户填充)。
借助意图模型(IntentResult)可以映射出待使用的工具集(工具之间依赖顺序要体现在工具描述上),提升了工具的召回准确率。
在评测动线上,包括评测构造模块、推理执行mock、结果评测。
整个架构你会发现主要由两部分能力组成。
一部分是模型能力:它决定了整个Agent架构智力的上限。
一部分是软件工程能力:它决定了Agent架构的扩展性和可靠性。
企业中落地Agent普遍的难点不是模型不够智能(因为大概率用的模型就那几家)。
难点是围绕模型的脚手架不到位,比如上下文工程、安全性、记忆系统等。
而且Agent架构越成熟,软件工程的重要性越高。

有人给我发了一篇脉脉上的有人吐槽自家AI落地的文章,相信也是遇到了同样的问题。

大多数AI Agent系统,打造的无非是上下文选择系统。
Fine-tuning模型的需求会少于设计一个完善的RAG系统,但大多数的RAG系统设计的比较初级。
比如将所有内容放入RAG,反而迷惑模型。
内容向量化缺少有效信息,无法提供高质量回答。
混合结构化和非结构化的数据,破坏向量语义,导致信息丢失。
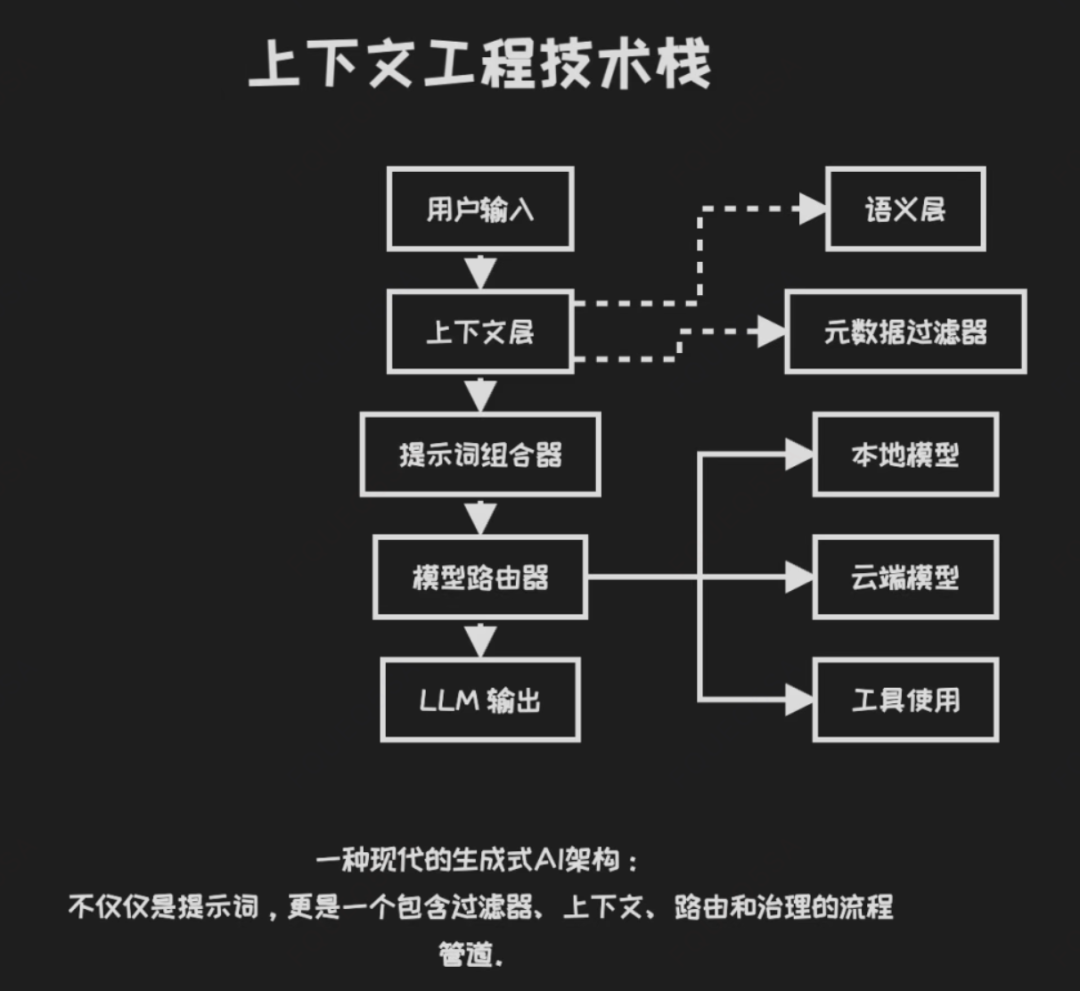
对上下文进行修剪,构造特征工程。
验证上下文中的数据结构、类型、时效性。
追踪上下文中哪些输入削弱或提升了输出质量。
不要将上下文视为一团文本,而是要想管理代码一样管理上下文。
RAG系统包含两层,一层是基于语义搜索向量,另一层是基于文档类型、时间戳、访问权限实现特定领域文本的过滤。
这样可以确保检索到的不仅仅是相似内容,更是高度相关的结构化知识。
记忆系统不是存储系统,它应该涉及到用户体验、隐私层面的设计。
记忆分层包括:个人偏好记忆、高频功能记忆、规范知识记忆。
需要注意,过度记忆会触及隐私红线,记忆共享则可能破坏权限。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号