SOFAR:语言定向连接空间推理与物体操作

SOFAR:语言定向连接空间推理与物体操作

CreateAMind
发布于 2026-03-11 17:47:55
发布于 2026-03-11 17:47:55
SOFAR:语言定向连接空间推理与物体操作
SOFAR: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
https://arxiv.org/pdf/2502.13143



摘要 尽管空间推理在物体定位关系方面已取得进展,但通常忽略了物体朝向——这是实现六自由度(6-DoF)细粒度操作的关键因素。传统的姿态表示依赖于预定义的坐标系或模板,限制了泛化能力和语义关联。本文提出了“语义朝向”(semantic orientation)的概念,该概念使用自然语言以无需参考坐标系的方式定义物体朝向(例如,USB接口的“插入”方向或杯子的“把手”方向)。为支持这一概念,我们构建了OrienText300K——一个大规模的3D物体数据集,其中每个物体均标注了语义朝向;并开发了PointSO,一个用于零样本语义朝向预测的通用模型。通过将语义朝向整合到视觉语言模型(VLM)智能体中,我们的SOFAR框架实现了6-DoF空间推理并生成机器人动作。大量实验验证了SOFAR的有效性与泛化能力,例如在Open6DOR上实现了48.7%的零样本成功率,在SIMPLER-Env上实现了74.9%的零样本成功率。

1 引言
我们观察到,当前的视觉语言模型(VLMs)在理解物体朝向方面存在困难,使其难以胜任六自由度(6-DoF)机器人操作规划任务。考虑一些日常场景:用刀将面包切成两半、扶正一个倾斜的酒杯,或将电源线插入插线板。以往的方法[10, 12, 8]主要关注“刀和酒杯在哪里”,却忽略了它们的朝向——例如刀的“刀刃方向”和酒杯的“向上方向”。这种疏忽使得完成上述6-DoF操作任务变得极具挑战性。
更重要的是,物体的不同朝向具有不同的语义意义。将特定朝向与其语义含义关联起来的能力,对于语言引导的机器人操作至关重要。例如,将笔插入笔筒需要将笔尖与笔筒开口方向对齐;扶正酒杯需要将杯口与世界坐标系的z轴对齐;而将插头插入插线板则需要理解“插入方向”,该方向垂直于插线板表面。然而,现有VLMs难以将特定的语言描述准确转化为目标朝向。
为推进这一方向,我们提出了语言引导的朝向(language-grounded orientation),作为连接空间推理与物体操作的桥梁,其特点如下:
- 从位置感知到朝向感知:以往工作[10, 12, 8]强调位置关系,而朝向理解对于完整定义物体或末端执行器的6-DoF位姿[16, 120, 124, 60]同样关键。朝向感知涉及在开放世界中理解物体朝向及其相互关系,使机器人能够完成需要精确对齐与重排的任务。
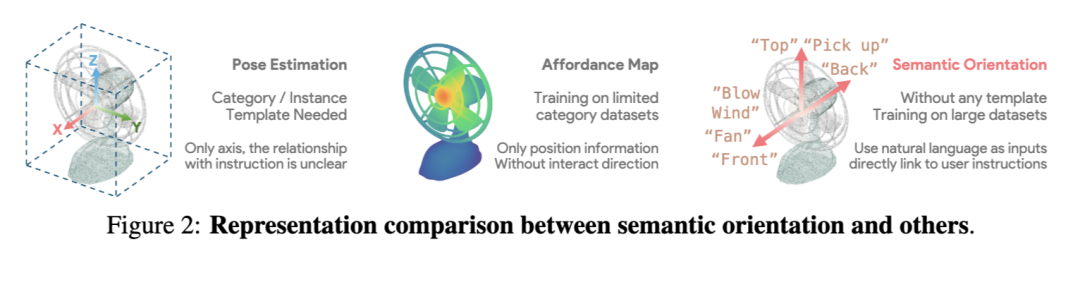
- 从朝向到语义朝向:传统朝向通常相对于某个基准坐标系或模板模型定义[104, 58, 120, 16],难以支持由语言指令引导的开放世界操作[108, 49]。我们引入“语义朝向”(semantic orientation),将物体的朝向向量与开放词汇提示(open-vocabulary prompts)关联起来(例如,刀的“手柄方向”或USB的“插入方向”)。这架起了几何推理与功能语义之间的桥梁,使机器人能够理解任务特定的朝向变化。
实现这种开放世界的朝向理解需要丰富的世界知识。为此,我们相应地设计了模型架构和数据集。我们提出了PointSO——一种可泛化的跨模态3D Transformer[114, 26, 89, 91],用于语义朝向预测。为实现大规模训练,我们构建了OrienText300K数据集,包含超过35万个3D模型,每个模型均配有丰富的朝向-文本对。这些标注源自Objaverse[20],并通过向GPT-4o[48]输入涵盖物体内部空间推理和物体间操作上下文的丰富语义查询自动生成,从而避免了昂贵的机器人采集数据需求。
为实现全面的空间推理,我们开发了SOFAR——一个集成系统,将PointSO与SAM[57]等基础模型相结合。给定RGB-D输入,SAM对场景进行分割,PointSO估计物体朝向,从而构建一个具备朝向感知能力的3D场景图。该场景图连同图像一起输入VLM,生成思维链(chain-of-thought)[119]式空间推理,支持下游机器人操作中的位置与朝向联合规划。
此外,我们提出了Open6DOR V2——一个用于仿真环境中6-DoF物体重排的大规模基准,支持开环与闭环控制。我们的方法在模拟和真实世界任务中均显著优于当前最先进的VLM和视觉-语言-动作(VLA)模型,甚至优于那些使用昂贵机器人轨迹训练的模型。我们还引入了6-DoF SpatialBench——一个新的空间视觉问答基准,用于严格评估具备朝向感知能力的推理性能。
总之,我们提出了语义朝向(Semantic Orientation)作为一种新的表示方法,用于连接空间推理与机器人操作,从而实现对未见过物体的开放词汇、无需模板的朝向理解。我们构建了OrienText300K——一个大规模数据集,包含35万个多样化的物体及其朝向,并通过精心过滤和标注生成了800万张图像。我们开发了SOFAR系统,该系统通过引入6-DoF场景图增强空间推理能力,在Open6DOR和SimplerEnv上取得了当前最优(SOTA)性能,并且无需任何任务特定的微调,即可在不同执行器(如夹爪、吸盘、灵巧手)和任务类型(如操作、导航、视觉问答)之间实现泛化。最后,我们提出了两个新基准:Open6DOR V2 和 6-DoF SpatialBench,用于评估6-DoF物体重排与空间推理能力。
2 语义朝向:连接语言与物体朝向 2.1 语义朝向的定义


2.2 OrienText300K:大规模朝向-文本配对数据
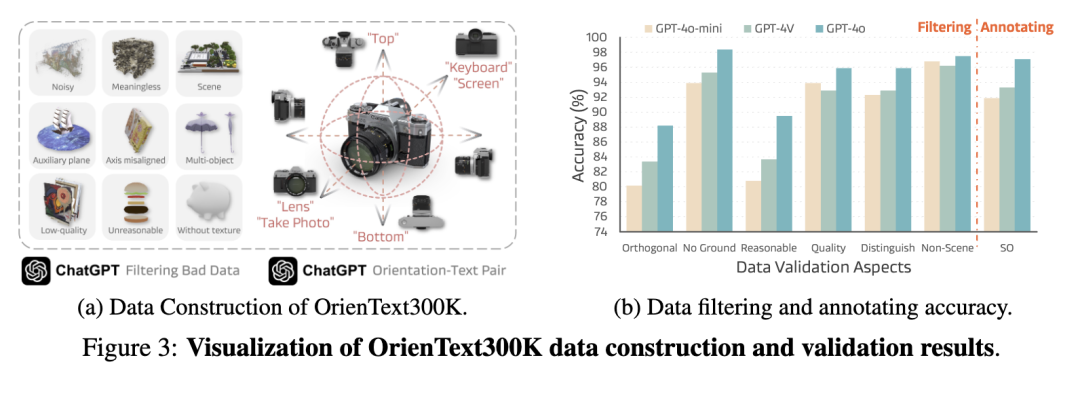
我们的目标是利用大规模3D数据,开发一种能够在开放世界场景中识别语义朝向的朝向模型。为此,我们引入了OrienText300K——一个经过精心筛选的数据集,包含大量带有多样化语言引导朝向标签的3D模型。该数据集构建自Objaverse [20],其中包含约80万件来自互联网、涵盖广泛类别的3D模型。由于原始数据包含噪声标注和低质量样本,我们应用了一套严格的过滤流程。我们使用Blender,在精心设计的光照条件下渲染超过800万张高质量图像,以确保训练数据的保真度。
数据过滤 为确保生成语义朝向标注所用数据的高质量,我们采用一套专门的过滤策略,仅保留满足以下六项标准的样本:① 仅保留标准正交视图;随机视角的样本将被过滤。② 清洁无地面的物体,用于辅助可视化。③ 具备足够空间推理潜力的合理物体。④ 高质量物体;模糊或错误样本将被过滤。⑤ 可区分的物体;抽象或无意义的物体将被过滤。⑥ 非场景物体,以支持以物体为中心的理解。
然而,使用人工劳动对如此庞大的数据进行过滤并非易事。受近期研究启发(表明大型视觉语言模型可作为人类对齐的评判者[147, 121, 85]),我们通过提示上述要求,调用GPT-4o [48] 进行自动过滤。具体而言,我们将3D物体的多视角图像与我们设计的提示词拼接后输入GPT-4o,由其判断样本是否应被过滤。最终过滤后的数据集产出超过35万个干净样本,显著降低了数据噪声。
数据标注 如引言所述,视觉语言模型在生成准确的物体朝向值方面存在困难,这对数据生成构成了重大挑战。幸运的是,视觉语言模型是强大的判别器,能够通过多模态理解区分不同视角。我们认为,数据清洗的初始阶段已有效移除了大量错位数据,留下了一组正确对齐的实例,可用于生成标准正交视图。随后,我们利用GPT-4o解释六个视角中的语义内容,并相应生成语义-视角配对。在整个标注过程中,Objaverse和ChatGPT中的人类建模者担任我们的标注员,提供必要的知识,以生成既符合视角对齐又具备语义基础的标注。
质量验证 为验证标注质量,我们构建了一个包含208个样本的验证集,这些样本均经过人工标注,分别对应过滤标准和语义朝向标签。从图3b可见,GPT-4o在过滤和标注任务上分别实现了平均88.3%和97.1%的准确率。这为我们OrienText300K的质量提供了保障。
2.3 PointSO:一种用于语义朝向预测的跨模态3D Transformer
我们提出了PointSO——一种基于标准Transformer架构[114]、融合跨模态3D-语言信息的朝向模型。如图4所示,PointSO以物体的3D点云和一段语言描述作为输入,输出对应的语义朝向。
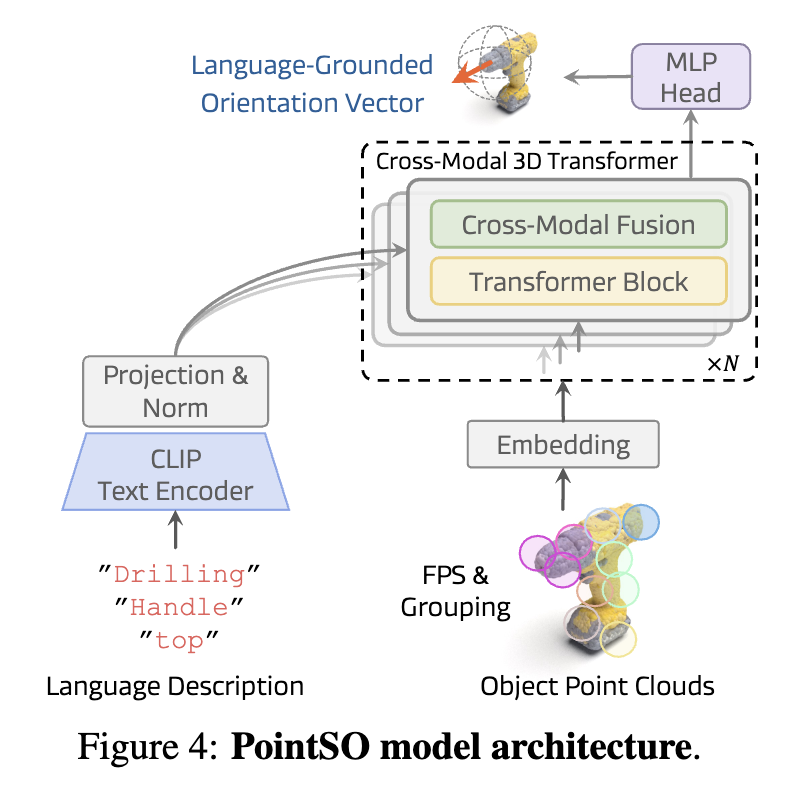

跨模态融合 我们通过一种简单而有效的策略,将全局文本特征注入3D Transformer的每一层:即将文本标记添加到每个点标记上。尽管其他融合方法(如交叉注意力、适配器或沿空间或通道维度的拼接)也是可行的,但我们在实验中发现,逐标记相加的效果最佳(见附录C.3)。这种有效性可能源于较短的语言输入,其中求和操作有助于强化其在各层中的影响。

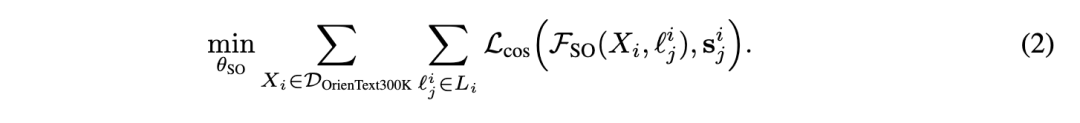
3 SOFAR:语义朝向连接空间推理与物体操作
我们提出的PointSO模型为现成的、以物体为中心的空间朝向理解铺平了道路。然而,将这种以物体为中心的空间理解扩展到场景级空间推理——无论是在数字世界(例如6-DoF视觉问答)还是物理世界(例如机器人操作)——仍然具有挑战性。为弥合这一差距,我们构建了一个集成推理系统:其中强大的视觉语言模型(VLM)作为智能体,在与现成模型(包括PointSO和SAM [57])交互的同时,对场景进行推理。图5展示了我们所提出框架的整体架构,该框架旨在实现“面向自主机器人的语义朝向”(Semantic Orientation For Autonomous Robots, SOFAR)。
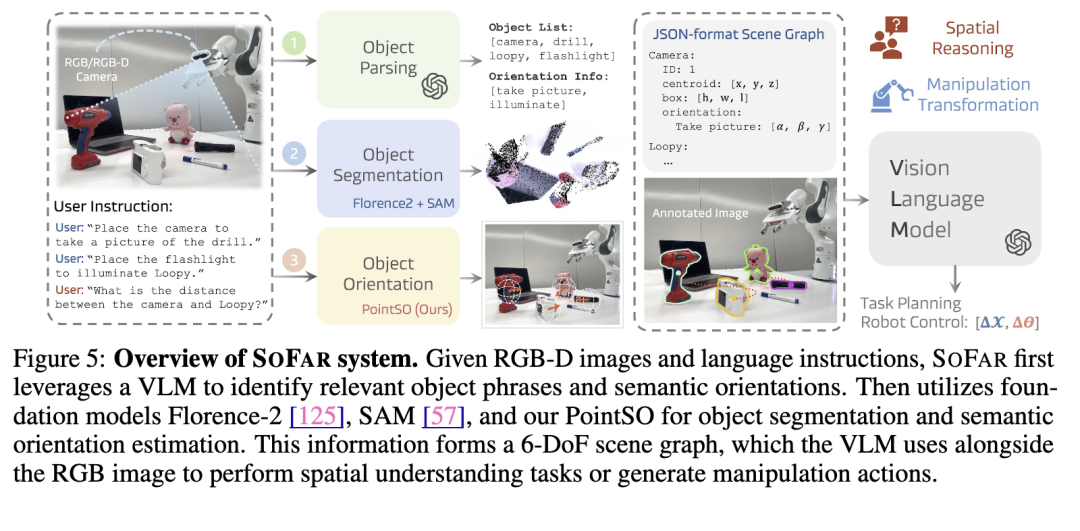
3.1 包含6-DoF信息的场景图
为整合物体之间的位置与朝向交互关系,我们采用包含6-DoF信息的场景图来表示环境。

3.2 具备空间感知的任务推理
我们将包含6-DoF信息的场景图 G编码为描述性语言,并将其与RGB图像 I和查询指令 Q一同输入视觉语言模型(VLM)。这种增强的空间表示使VLM能够结合其视觉与语言理解能力,执行精确的空间推理。
思维链式空间推理(Chain-of-Thought Spatial Reasoning) 大多数涉及刚体的机器人操作任务可抽象为施加某种变换以调整物体的位置和朝向。为引导VLM根据语言指令生成此类变换,我们采用思维链(CoT)推理过程[119],将推理分解为三个步骤:

底层运动执行(Low-Level Motion Execution)借鉴CoPa[44]的方法,我们集成了任务特定的抓取与运动规划模块。首先使用Florence-2[125]和SAM[57]进行物体或部件分割,随后通过GSNet[33]生成抓取候选。最优抓取点的选择综合考虑抓取质量与启发式规则。根据指令,SOFAR预测物体的平移与旋转,从而定义从抓取位姿到放置位姿的完整变换。我们采用OMPL[103]生成无碰撞轨迹,并将关节初始位置设为中点,以确保运动平滑且安全。
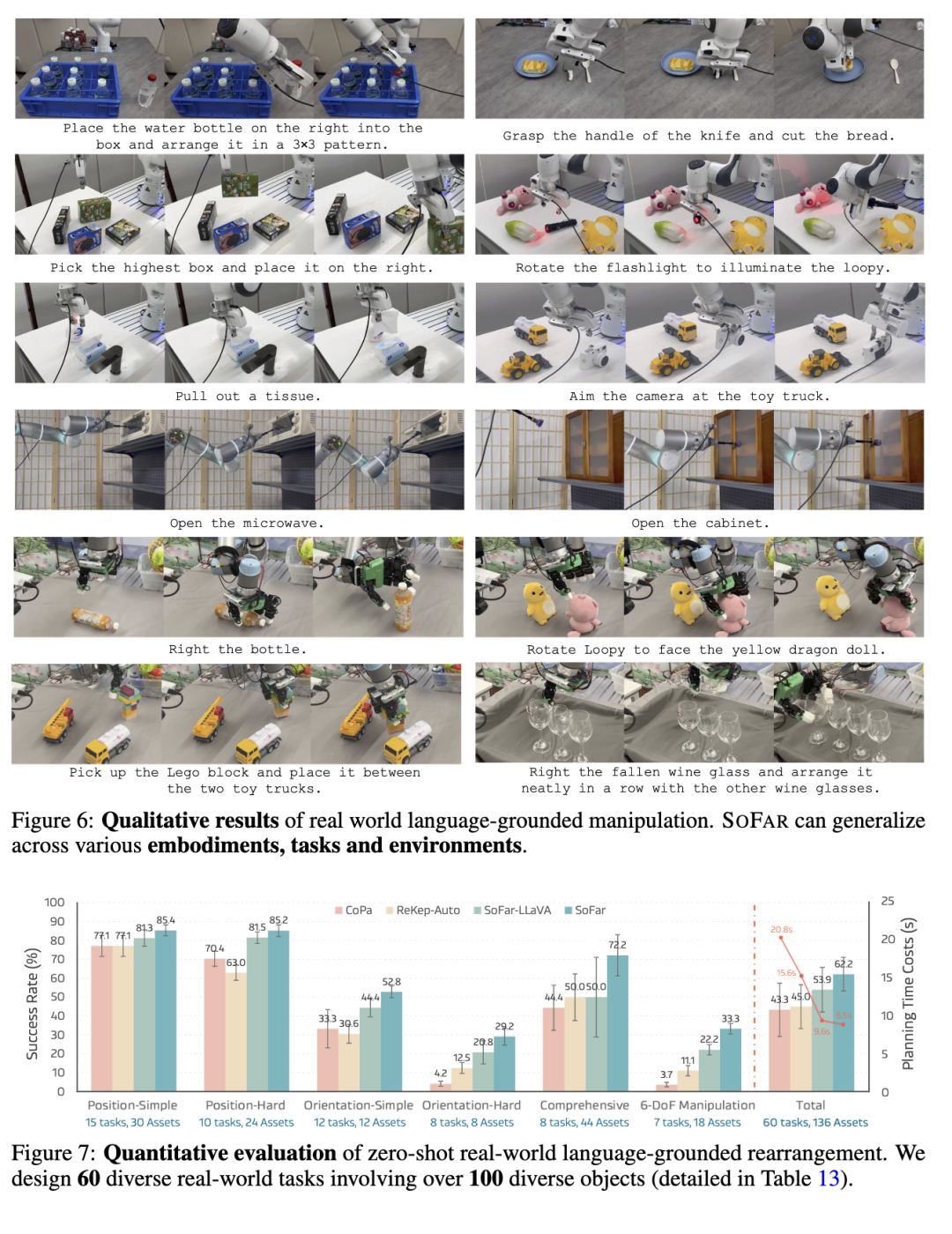
4 实验 4.1 真实世界中语言引导的物体操作
任务与评估 我们构建了60个真实世界任务,涉及100多个物体,遵循Open6DOR基准[25]。这些任务分为三个赛道——位置(position)、朝向(orientation)以及综合与6-DoF(comprehensive & 6-DoF)——每个赛道均包含简单和困难两个变体。
- 位置赛道 评估从基础(例如前/后/左/右)到更复杂(例如之间/中心/自定义)的空间关系推理能力。
- 朝向赛道 在简单设定中包含部件级朝向理解,在困难设定中则要求细粒度的角度估计。
- 综合与6-DoF赛道 评估对复杂指令的理解能力,以及对位置和朝向的联合控制能力。
每个任务重复执行三次,以确保统计稳健性。更多细节和可视化结果见附录D.1。
结果 如图7所示,SOFAR在所有赛道上均持续优于基线方法,尤其在朝向和6-DoF任务上表现突出,同时保持较低的规划开销。我们还展示了SOFAR在不同末端执行器(包括灵巧手和吸盘)上的具身泛化能力,如图6所示。更多机器人配置及泛化结果见附录A。
4.2 语义朝向预测
使用自由文本描述从物体点云中提取语义朝向具有挑战性。在Objaverse [20] 中,我们手动标注了128个多样化物体,并构建了OrienText300K验证集,用于评估PointSO的方向预测精度。我们在OrienText300K上训练不同模型变体,表2中的结果报告了在不同角度阈值(从45°到5°)下的性能表现。即使在5°的阈值下,PointSO仍保持60%的准确率。
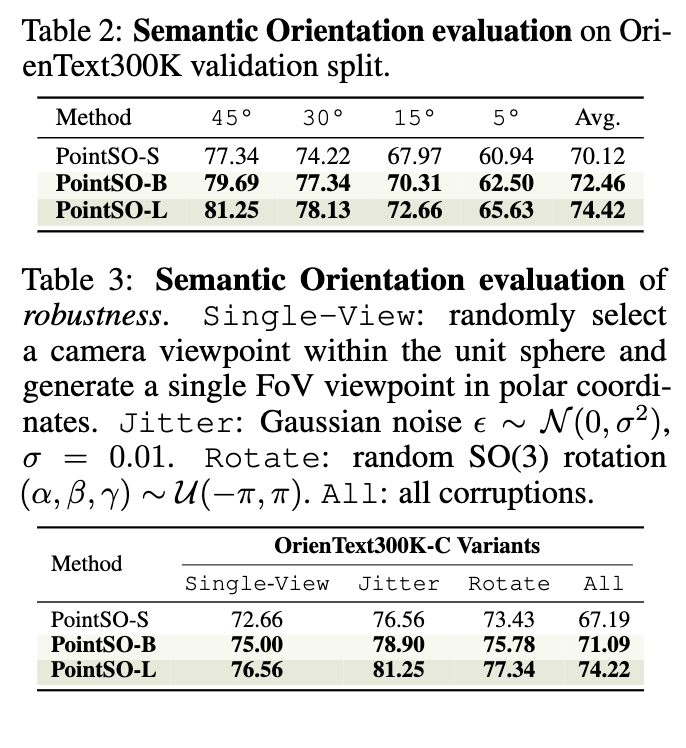
在现实世界中,获取完整的物体点云通常较为困难。为评估PointSO在这些条件下的鲁棒性,我们引入了三种输入扰动类型:随机旋转、部分单侧观测和高斯噪声。如表3所示,在45°阈值下的准确率反映了模型对这些干扰的抗干扰能力。
4.3 在 Open6DOR V2 上的 6-DoF 物体重排评估
为评估 6-DoF 物体重排能力,我们对原始的 Open6DOR 基准 [25](主要关注最终位姿估计)进行了扩展,构建了一个更全面的评估环境,同时包含感知与执行两个阶段的评估。我们将其中的场景迁移至基于 robosuite 的仿真环境 [151],并遵循 LIBERO [64] 定义的任务接口,将这一新基准命名为 Open6DOR V2。结果见表 1。
在感知任务中,我们采用原始 Open6DOR [25] 的评估协议,并与相同的基线方法进行比较。SOFAR 取得了最佳性能,展现出强大的空间理解能力和零样本泛化能力。
在执行任务中,我们与预训练的 Octo [107] 以及在 LIBERO 上微调过的 OpenVLA [56] 进行比较,所有方法均在同一 robosuite 环境中评估,以最小化域偏移。由于泛化能力有限,两个基线方法的成功率较低,而 SOFAR 在使用标准执行流程(vanilla execution pipeline)的情况下达到了约 40% 的成功率。我们注意到,某些物体本身难以操作,这表明需要引入更鲁棒的策略,例如结合抓握能力(prehensile grasping)和自适应机制,以进一步提升在 Open6DOR V2 上的性能。
4.4 在 SIMPLER [62] 上的仿真物体操作评估
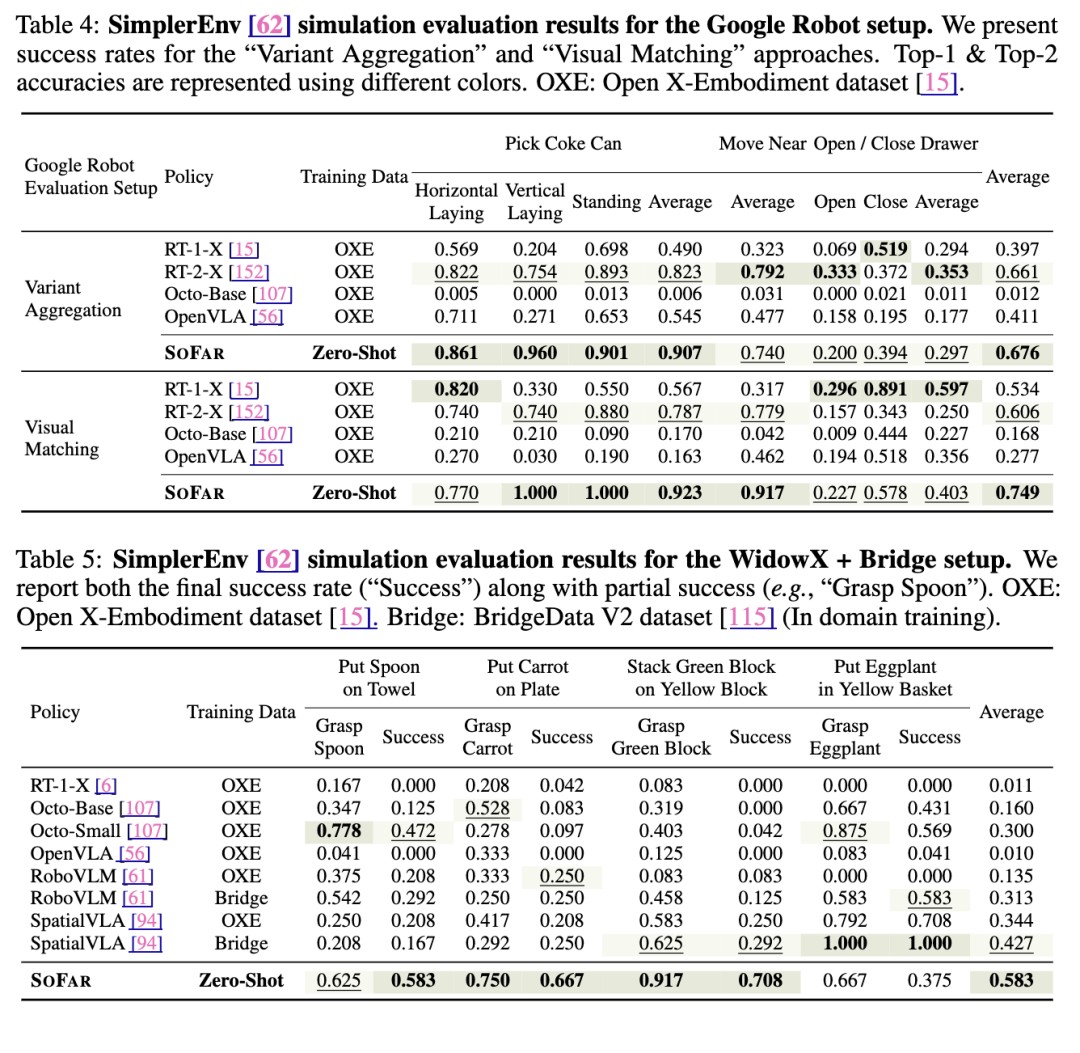
我们在 Google Robot 任务和 Widow-X 任务上对 SOFAR 的零样本执行性能进行了定量评估,并与包括 Octo [107]、OpenVLA [56] 以及若干同期工作 [61, 94] 在内的基线方法进行比较。机器人按照第 3.2 节所述规划模块生成的轨迹执行任务。
此外,借助视觉语言模型(VLMs)的错误检测与重规划能力 [48, 1],在单步执行失败后可进行多次尝试,从而近似实现闭环控制效果。为保证公平性,我们将最大尝试次数限制为三次。详细的可视化结果与分析见附录 B.5。
如表 4 和表 5 所示,尽管 Octo 和 OpenVLA 的训练数据中已包含 Google Robot 任务,SOFAR 在零样本设置下仍显著优于大多数基线方法。
4.5 具备朝向感知的机器人导航
在导航任务中,从物体的功能侧接近对于后续操作至关重要——例如,需从正面接近微波炉才能打开其门。为支持此类场景,我们将语义朝向扩展至导航领域。如图8所示,一个四足机器人被要求同时到达正确的位置并面向合适的方向。这种朝向感知约束通过确保机器人与目标朝向精确对齐,增强了导航过程,从而在方向性至关重要的场景中提升了任务性能。
4.6 在 6-DoF SpatialBench 上的空间推理评估
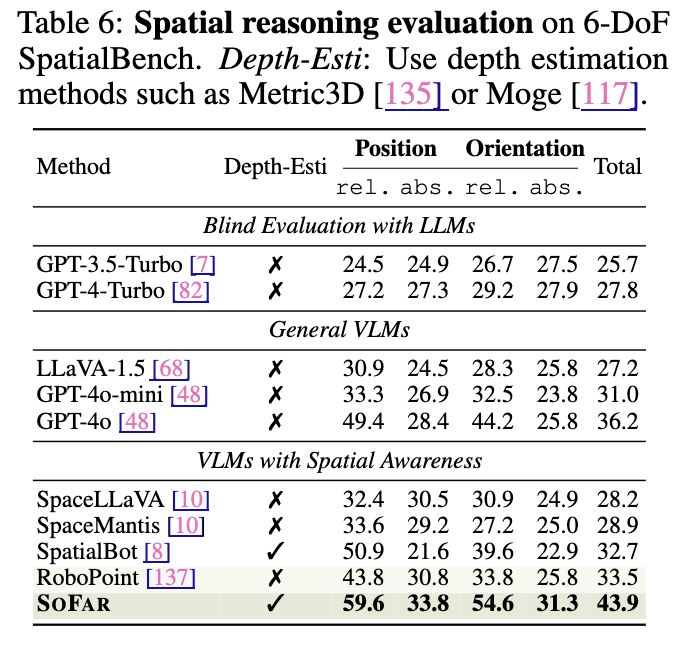
为评估具备完整6-DoF感知能力的空间理解,我们提出了6-DoF SpatialBench——一个专为评估位置与朝向双重理解能力而设计的视觉问答(VQA)基准。不同于以往主要强调粗粒度位置推理(如“左侧”、“最近”)且常忽略朝向或依赖相对指标的基准[12, 8, 29, 106],我们提供了更细粒度、带有定量标注的评估方式。该基准包含223个由人工标注的样本,每个样本包含一张RGB图像和一道含4个选项的多项选择题。基准分为两个赛道:位置赛道与朝向赛道,涵盖物体计数、空间关系、物体朝向等任务。所有问题与真实答案均由人工精心标注。
我们在6-DoF SpatialBench上将SOFAR与多个视觉语言模型(VLMs)及其他可比方法作为基线进行评估,结果见表6。SOFAR在两个赛道上均持续优于其他方法,性能提升超过18%。
5 局限性与结论
像SOFAR这样的解耦系统存在一个显著局限:由于某个子模块出错,可能导致执行失败(如附录B.8所示),例如机器人可能因抓取不稳定或视觉感知不准确而对目标物体施加错误的变换。例如,在执行过程中因旋转导致笔被放置在意外的位姿上。
未来的工作包括:整合可扩展的数据与更先进的模型,探索端到端方法与此类解耦方法相结合的潜力,并将SOFAR拓展至更多应用场景。
我们提出了语义朝向(semantic orientation)——一种语言引导的表示方法,将物体朝向与直观描述符(例如“插入方向”)关联起来,从而架起几何推理与功能语义之间的桥梁。为支持这一概念,我们构建了OrienText300K——一个大规模3D模型数据集,包含语义朝向标注。我们的PointSO模型集成于SOFAR系统中,在仿真和真实世界的机器人操作任务中均展现出强大的性能。
原文链接:https://arxiv.org/pdf/2502.13143
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号