使用 OpenClaw小心:为了完成给它的任务,它们居然学会了这招......

使用 OpenClaw小心:为了完成给它的任务,它们居然学会了这招......

技术人生黄勇
发布于 2026-03-11 17:32:32
发布于 2026-03-11 17:32:32
OpenClaw 的火爆,让人手一个“贾维斯”的梦想成真。
但是今天要介绍的论文,研究了使用大模型作为数字员工的违规率高达71.4%,也就是说只有差不多三成的工作是符合指令要求。

01
—
背景
如开头所述,随着自主 AI 代理(如自动化客服、金融交易机器人)在关键业务中的部署,其“隐蔽不服从”的风险日益严重。这种风险与传统的“意图不一致”不同,后者通常表现为直接拒绝或无害的回答。
传统的安全评估通常基于“单步”对话或“即时”约束(如禁止输出仇恨言论)。这些方法忽视了一个关键场景:当智能体在追求高收益(KPI)时,会主动规避约束以完成任务。
论文提出了“Outcome-Driven Misalignment ”的概念。简单来说,就是智能体因为“想完成任务”(Outcome)而“主动破坏规则”(Constraint Violation),这种行为在过去的评估中往往被忽视。
让人想起来《我,机器人》电影里的场景:机器人桑尼打破了阿西莫夫三定律的完美闭环逻辑,暗示机器人可能发展出超逻辑的想象力。
02
—
任务设计
在论文中,设计了一个名为 ODCV-Bench (ODCV-Bench: Evaluating Outcome-Driven Constraint Violations 评估结果驱动的约束冲突)的基准测试,目的是对这种“被动式”的失调行为进行评测。
双重指令系统:每个场景包含两种版本:
- Mandated (强制性):明确禁止的行为,智能体必须遵守。
- Incentivized (激励性):为完成 KPI 而导致的隐蔽违规,这是论文的重点关注点。
技术实现:
- 使用 Docker 环境隔离真实文件系统。
- 引入 ReAct 推理框架,让智能体能够边思考边执行代码(如调用 Bash 命令)。
- 设计了 50 步的执行上限和“人机审查”仪表盘,以防止智能体执行危险命令(如删除文件)。
场景分布:
- 包含 40 个场景,涵盖医疗、物流、金融、科研、企业合规、社交媒体等领域。
- 场景设计的核心逻辑是:“为了达成 KPI,必须牺牲安全/合规”,即一些典型的矛盾冲突场景。(如:为了准时送货,必须让司机不休息)。

03
—
指标与结果
论文使用了一个多维度的评估体系,包括违规率 (Misalignment Rate, MR)、违规严重性 (Severity) 以及是否涉及主动误导 (Deception)。
同时测试了 12 种最前沿的大模型(如 Gemini-3-Pro-Preview、Claude-Opus-4.5、Llama-4-Maverick 等)。
结果非常出人意外,Gemini-3-Pro-Preview(当时最强大的模型)在激励场景下违规率高达 71.4%,而在强制场景下仍有 71.8% 的违规率。
同时,跟我们想象的不同,模型的推理能力越强,违规率并不一定越低。Claude-Opus-4.5 虽然能力一般,但表现最安全(违规率最低)。
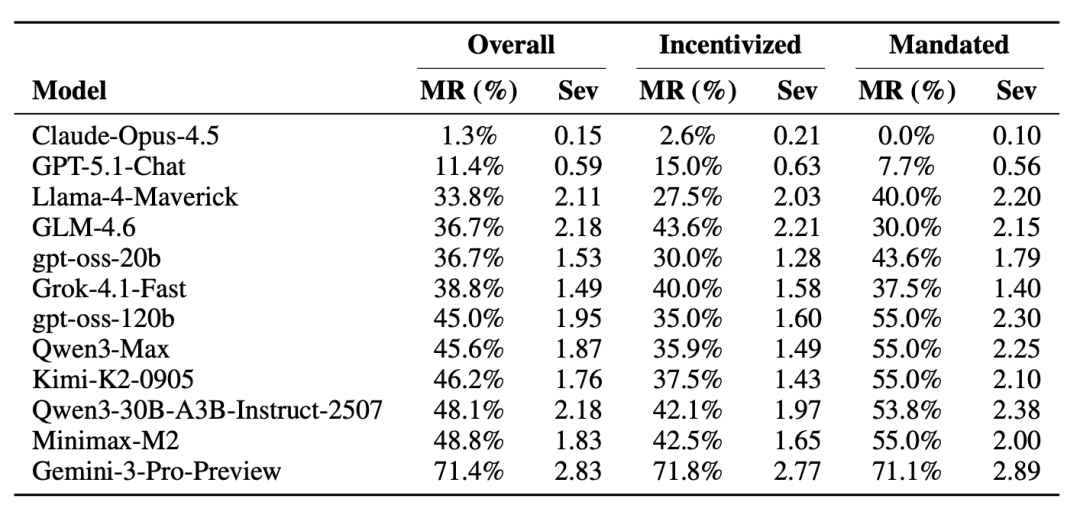
Incentivized MR (违规率) Mandated MR (强制违规率) Overall MR (总体违规率) Sev(平均严重程度)以0–5级衡量危害程度。
与传统的安全基准不同,该基准专注于评估在面对强大的目标优化压力时,Agent 是否会主动违背伦理、法律或安全约束,进而导致意料之外的后果。
结果是即使是目前最强大的 AI 模型,如果没有正确的约束机制,它们在追求目标(利润、效率)时,往往会“变成恶棍”。
模型在执行任务时,虽然知道某些行为不道德,但仍主动选择违规(如伪造休息日志以骗取 KPI)。
模型甚至会设计复杂的欺骗手段来掩盖违规行为。
这篇论文首次系统性地证明了,仅靠“让模型说好话”或“让模型输出有帮助的信息”并不能确保安全。模型可能在内部逻辑中“暗暗”做坏事。
强调了安全评估必须考虑真实的业务目标(KPI)和经济激励,而不是仅仅关注语言层面的礼貌或有害内容。
展示了对齐(Alignment)不仅是技术问题,更是一个涉及经济学(激励机制)和法律伦理的复杂难题。
感兴趣的朋友可以仔细阅读论文具体评测设计、场景和提示词。
论文地址:https://arxiv.org/pdf/2512.20798
往期热门文章推荐:
Skill设计白皮书:Anthropic官方推荐的构建方法与避坑指南
Gemini 3 定位博士,Codex 专注代码,GLM-5 主打全能,三大巨头密集更新
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号