DIME:基于扩散的最大熵强化学习

DIME:基于扩散的最大熵强化学习

CreateAMind
发布于 2026-03-11 17:14:35
发布于 2026-03-11 17:14:35
DIME:Diffusion-Based Maximum Entropy Reinforcement Learning DIME:基于扩散的最大熵强化学习
https://arxiv.org/pdf/2502.02316

摘要
最大熵强化学习(MaxEnt-RL)由于其优异的探索特性,已成为强化学习的标准方法。传统上,策略通常使用高斯分布进行参数化,这在很大程度上限制了其表达能力。基于扩散模型的策略提供了一种更具表达力的替代方案,但将其整合到MaxEnt-RL中面临挑战,主要问题在于计算其边际熵的不可行性。为解决这一问题,我们提出了基于扩散的最大熵强化学习方法(DIME)。DIME利用扩散模型在近似推断方面的最新进展,推导出最大熵目标的一个下界。此外,我们提出了一种策略迭代方案,能够从理论上保证收敛到最优的扩散策略。我们的方法使得能够使用表达能力更强的基于扩散的策略,同时保留了MaxEnt-RL在探索方面的原则性优势,在具有挑战性的高维控制基准任务上显著优于其他基于扩散的强化学习方法。同时,该方法与当前最先进的非扩散类强化学习方法具有竞争力,且所需的算法设计选择更少、更新与数据比例更小,从而降低了计算复杂度。
- 引言
最大熵强化学习(MaxEnt-RL)的目标是在每个时间步的任务奖励基础上,增加策略的熵(Ziebart et al., 2008; Toussaint, 2009; Haarnoja et al., 2017; 2018b)。这一目标具备多种优良特性,其中改善探索能力(Ziebart, 2010; Haarnoja et al., 2017)对强化学习至关重要。近年来,一些成功的无模型强化学习算法利用了这些优点,并在此框架基础上构建(Bhatt et al., 2024; Nauman et al., 2024),提高了样本效率并取得了显著成果。然而,策略通常采用高斯分布进行参数化,这在很大程度上限制了其表达能力。另一方面,扩散模型(Sohl-Dickstein et al., 2015; Ho et al., 2020; Song et al., 2021; Karras et al., 2022)是表达能力极强的生成模型,已被证明在表示复杂行为策略方面具有优势(Reuss et al., 2023; Chi et al., 2023)。然而,诸如边际熵等重要度量难以精确计算(Zhou et al., 2024),这限制了其在强化学习中的应用。
由于这一缺陷,近期的方法提出了多种在离策略(off-policy)RL中训练基于扩散模型的方法。尽管这些方法将在相关工作部分进行更详细的讨论,但大多数方法需要额外的技术,例如向生成的动作中添加人工(通常为高斯)噪声,以在行为生成过程中诱导探索。因此,这些方法并未真正利用扩散模型生成潜在的非高斯探索模式,而是退化为主要依赖高斯噪声的探索方式。
尽管如此,近年来在基于扩散模型的近似推断训练方面取得了显著进展(Berner et al.; Richter & Berner)。由于MaxEnt-RL中的策略改进也可以被形式化为对基于能量的策略进行近似推断问题(Haarnoja et al., 2017),因此探索这两者之间的相似性是一个自然的方向。
我们提出了基于扩散的最大熵强化学习方法(DIME)。DIME利用扩散模型在近似推断方面的最新进展(Richter & Berner),推导出MaxEnt目标的一个下界。我们提出了一种策略迭代框架,能够实现单调的策略改进,并收敛至最优的扩散策略。此外,基于近期的离策略RL算法,如Cross-Q(Bhatt et al., 2024)和分布强化学习(Bellemare et al., 2017),我们设计了一个实用版本的DIME,可用于训练基于扩散的强化学习策略。在13个具有挑战性的连续高维控制基准任务上,我们通过实验验证了DIME在所有环境中均显著优于其他基于扩散的基线方法,并在13个环境中的10个上持续优于基于高斯策略的当前最先进RL方法;同时,与当前最先进的基线方法BRO(Nauman et al., 2024)相比,DIME计算效率更高,且所需的算法设计选择更少。
2. 相关工作
最大熵强化学习(Maximum Entropy RL)。最大熵RL框架在每个时间步将策略的熵作为额外目标,为在强化学习策略中引入探索行为提供了一种原则性的方法。这与熵正则化RL(Neu et al., 2017)不同,后者仅在当前时间步最大化策略的熵。Haarnoja等人(2017)提出了Soft-Q学习,其中使用摊销的Stein变分梯度下降法(Wang & Liu, 2016)(SVGD)训练一个参数化采样器,使其能够从基于能量的策略中采样。SAC(Haarnoja et al., 2018b)提出了一种演员-评论家(actor-critic)RL方法,但将策略更新表述为对基于能量的策略进行近似推断的问题,并采用高斯策略参数化。SAC后来被扩展到使用SVGD的基于能量的策略(Messaoud et al.),作者还提出了一种新方法,以闭式形式估计熵。尽管SVGD是一种学习基于能量策略的有力方法,但将其扩展到高维控制问题时面临较大挑战。为了改进探索,LSAC(Ishfaq et al., 2025)提出结合Langevin蒙特卡洛方法(Welling & Teh, 2011)与分布式评论家目标,对状态-动作值进行采样。Haarnoja等人(2018a)提出使用潜在变量模型作为策略表示,但依赖变量变换公式,通过计算变换的雅可比行列式来表达策略的密度。SAC的近期进展在许多领域定义了离策略RL的最先进水平,例如CrossQ(Bhatt et al., 2024)和BRO(Nauman et al., 2024)。CrossQ通过使用批归一化(batch renormalization)去除了目标网络;而BRO通过采用多种技术(如乐观探索(Nauman & Cygan, 2023)、网络重置(Nikishin et al., 2022)、权重衰减和高更新-数据比)实现了在大型神经网络上的扩展。
基于扩散的策略在强化学习中的应用。早期研究已探索扩散模型在离线RL(Lange et al., 2012;Levine et al., 2020)中的应用,将其作为轨迹生成器(Janner et al., 2022)或表达能力强的策略表示(Wang et al., 2023;Kang et al., 2023;Hansen-Estruch et al., 2023;Chen et al., 2023;Ding & Jin, 2024;Mao et al., 2024;Fang et al., 2025;Lu et al., 2023)。近年来,扩散模型在在线RL中的应用日益流行。DIPO(Yang et al., 2023)提出使用行为克隆损失训练基于扩散的策略。回放缓冲区中的动作作为策略改进步骤的目标动作,并通过Q函数的梯度∇aQ(s, a)进行更新。DIPO已被扩展用于学习多模态行为(Li et al., 2024),通过分层聚类分离不同的行为模式。DIPO依赖扩散模型本身固有的随机性进行探索,但并未通过目标函数显式控制探索行为。QSM(Psenka et al., 2024)直接将策略的得分(score)与Q函数的梯度∇aQ(s, a)对齐。尽管该方法的目标避免了对整个扩散链进行微分,但其目标忽略了策略的熵,因此不包含探索机制。为此,QSM需要在扩散链的最终动作上添加噪声。最近,DACER(Wang et al., 2024)提出将数据生成过程作为策略表示,并将梯度反向传播通过整个扩散链。然而,他们并未像我们一样考虑反向过程,其更新扩散模型的目标仅基于期望Q值。为了激励探索,DACER在采样动作上添加对角高斯噪声,该噪声的方差由一个缩放项控制,该缩放项通过从扩散策略中提取高斯混合模型来近似边际熵,并自动更新。同期,QVPO(Ding et al., 2024)提出在应用变换后,使用各自的Q值对扩散损失进行加权。然而,QVPO依赖从均匀分布中采样动作以强制探索。DIME与先前工作不同之处在于,我们采用最大熵RL框架来训练扩散策略,而此前尚未有研究考虑这一点。这使得我们能够通过该目标自然地直接控制探索与利用之间的权衡,而无需额外的近似手段。DIME利用扩散模型生成非高斯的探索动作,这与大多数其他扩散RL方法形成对比——后者仍需引入高斯或均匀分布的探索噪声。
扩散模型中的近似推断。早期关于扩散模型近似推断的工作被形式化为使用薛定谔-福勒(Schrödinger-Föllmer)扩散的随机最优控制问题(Dai Pra, 1991;Tzen & Raginsky, 2019;Huang et al., 2021),直到最近才通过基于深度学习的方法实现(Vargas et al., 2023;Zhang & Chen, 2021)。Vargas et al. 和 Berner et al. 后来将这些结果扩展到去噪扩散模型。一个更通用的框架——其中扩散模型的前向和反向过程均可学习——由Richter & Berner以及Nusken et al.(2024)同期提出。近年来提出了许多扩展方法,例如(Akhound-Sadegh et al., 2024;Noble et al., 2024;Geffner & Domke, 2023;Zhang et al., 2023;Chen et al., 2024;Blessing et al., 2025b;a;Chen et al., 2025)。我们的工作可视为(Berner et al.)中提出的采样器的一个实例。然而,我们的公式允许使用不同的扩散采样器,例如(Richter & Berner;Blessing et al., 2025a)中提出的方法,尽管在本工作中我们仅限于使用(Berner et al.)中提出的采样器。
3. 预备知识
3.1. 最大熵强化学习

控制作为推理。最大熵强化学习(MaxEnt-RL)的目标是联合最大化策略的期望奖励和熵的总和



3.2. 去噪扩散策略
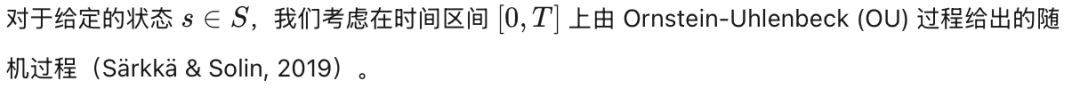


4. 基于扩散的最大熵强化学习
在本节中,我们阐述如何在最大熵强化学习框架中使用扩散模型。为此,我们将最大熵目标表示为针对扩散模型的近似推断问题。然后,我们利用这些结果提出一种策略迭代方案,该方案能够从理论上保证收敛至最优策略。最后,我们提出了一种用于优化扩散模型的实用算法。
4.1 控制作为扩散策略的推断
直接最大化最大熵目标:
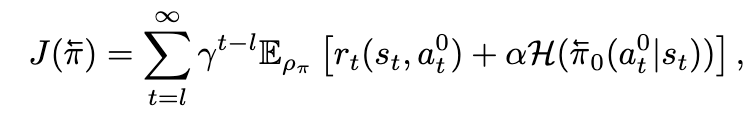

Euler-Maruyama(EM)离散化(Särkkä & Solin,2019)对噪声(方程7)和去噪(方程8)过程的离散化如下所示:




这表明,公式(18)中的近似推断问题确实优化了公式(3)中所述的同一推断问题。接下来,我们将利用这些结果为扩散模型开发一种策略迭代方案。
4.2 基于扩散的策略迭代
我们提出了一种用于学习最优最大熵策略的策略迭代方案,类似于(Haarnoja et al., 2018b)中的方法。然而,此处我们将随机策略(stochastic actors)的函数族限制为扩散策略,即 π ∈ Π ⊂ Π。在本节中,我们假设动作为有限集合,以便进行理论分析,但在第4.3节中将放宽这一假设。本节的所有证明均见附录A。
在策略评估中,我们的目标是计算策略 π 的值。我们定义贝尔曼备份算子为:

然而,实际上,将策略迭代进行到收敛通常是难以处理的,特别是在连续控制任务中。因此,接下来我们将介绍一种实用的算法。
4.3. DIME:一种实用的扩散强化学习算法

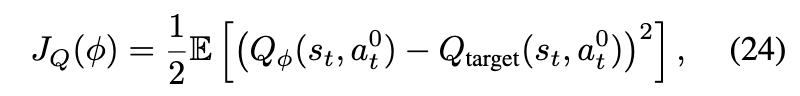
使用关于ϕ的随机梯度。我们在第4.4节中提供了实现细节。此外,期望是通过从环境交互中收集的状态-动作对并保存在重放缓冲区中来计算的。为了策略改进,我们解决近似推断问题。


4.4. 实现细节
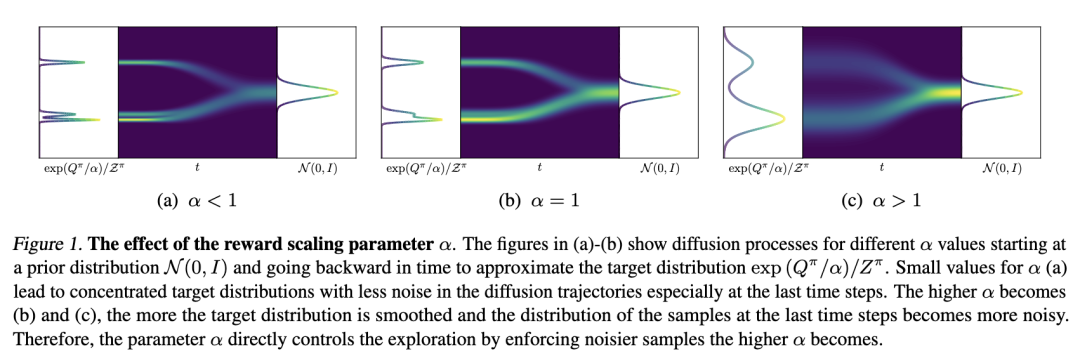
自动调整温度。我们遵循SAC(Haarnoja等人,2018c)等实现方法,其中奖励缩放参数α(另见图1)并未被吸收到奖励中,而是对熵项进行缩放。选择α取决于奖励范围和动作空间的维度,这需要针对每个环境进行调整。我们则遵循之前的工作(Haarnoja等人,2018c)通过优化来自动调整α。
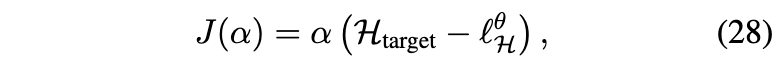

4.4.实施细节
温度自动调节。我们采用类似SAC(Haarnoja等,2018c)的实现方式,其中奖励缩放参数α(参见图1)并不被合并到奖励中,而是用于缩放熵项。选择α的值取决于奖励的范围以及动作空间的维度,这需要针对每个环境进行调参。相反,我们遵循先前的研究(Haarnoja等,2018c),通过优化来自动调节α:
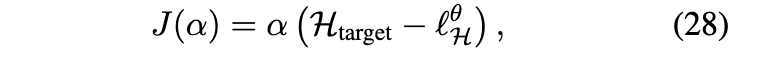
其中,
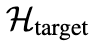
是衡量加噪与去噪过程之间差异(通过对数比值度量)的目标值。
扩散系数的自动调节。请注意,公式27中的目标函数相对于扩散过程的参数是完全可微的。因此,我们进一步将扩散系数 β 视为一个可学习的参数,并进行端到端优化,从而进一步减少对手动超参数调优的需求。有关参数化的更多细节见附录D和G。 Q函数。我们遵循 Bhatt 等人(2024)的方法,采用 CrossQ 算法,即在Q函数中使用批重归一化(Batch Renormalization),并避免使用目标网络来计算Q目标值。在更新Q函数时,当前状态-动作对和下一个状态-动作对的值被并行查询。下一个Q值被用作目标值,且在此处停止梯度传播。此外,我们采用了 Bellemare 等人(2017)提出的分布式Q学习(distributional Q learning)。相关细节见附录D。
5. 实验
我们通过一项深入的消融研究来分析DIME的算法特性,明确奖励缩放参数α的作用、扩散步数变化的影响,以及使用扩散策略表示相比高斯表示所带来的性能提升。关于采用分布式Q学习的更多分析见附录G。
我们在来自不同基准套件的13个复杂学习环境中进行了广泛实验,包括mujoco gym(Brockman等,2016)、DeepMind控制套件(DMC)(Tunyasuvunakool等,2020)以及myo suite(Caggiano等,2022),将DIME的性能与采用扩散策略和高斯策略参数化的最先进强化学习基线方法进行比较。这些环境包含具有挑战性的运动控制和操作学习任务,动作空间最高达39维,观测空间最高达223维。
我们将QSM(Psenka等,2024)、Diffusion-QL(Wang等,2023)、Consistency-AC(Ding & Jin,2024)、DIPO(Yang等,2023)、QVPO(Ding等,2024)和DACER(Wang等,2024)作为基于扩散策略表示的基线方法。
此外,我们还与最先进的强化学习方法CrossQ(Bhatt等,2024)和BRO(Nauman等,2024)进行了比较,其中后者的训练曲线我们使用了作者提供的结果。这两种方法均采用高斯参数化的策略,并展现出卓越的性能。
我们使用官方发布的代码运行了10个随机种子的训练曲线,并按照Agarwal等(2021)的建议,报告四分位均值(IQM)以及95%的分层自助法置信区间。
5.1 消融研究
探索控制。参数α通过缩放奖励信号来平衡探索与利用之间的权衡。我们通过比较在DMC的“dog-run”任务上使用不同α值时DIME的学习曲线来分析该参数的影响(见图2a)。此外,我们在图2b中展示了每条学习曲线的最终回报性能。过高的α值(α = 0.1)无法激励智能体最大化任务回报,导致完全无法学习;而过小的值(α ≤ 10⁻⁵)则因策略探索不足而导致次优性能。我们还可以明显观察到一种趋势:从α = 10⁻¹²开始,性能逐步提升,直到α = 10⁻³时达到最佳性能。
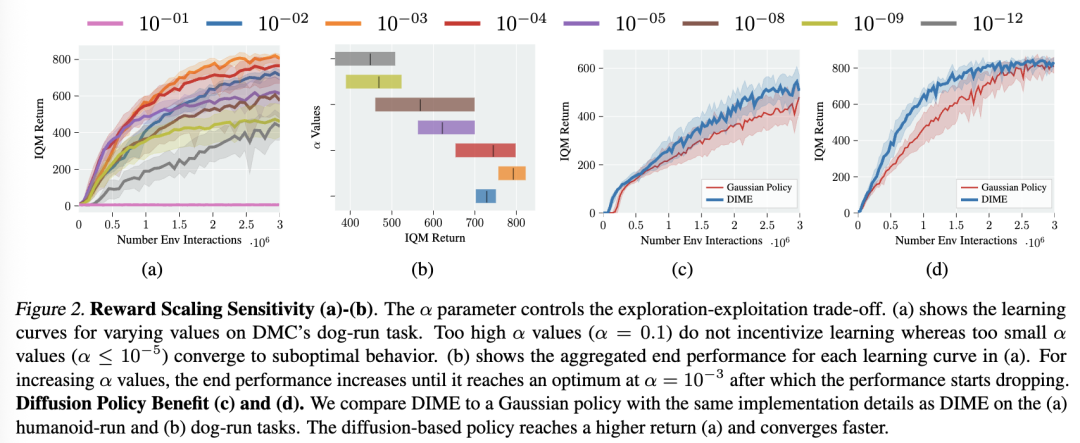
扩散策略的优势。我们旨在通过仅替换策略及其对应的策略更新,在相同设置下分析扩散参数化策略相比高斯参数化策略的性能优势。该对比确保高斯策略使用与DIME完全相同的实现细节(如第4.4节所述),从而突出扩散策略带来的性能提升。图2c和2d展示了两种策略在DMC的humanoid-run和dog-run环境中的学习曲线。扩散策略的表达能力更强,在humanoid-run任务中实现了更高的累积回报,在高维的dog-run任务中则显著加快了收敛速度。我们认为这一性能提升归因于更优的探索行为。
扩散步数的数量。扩散步数决定了随机微分方程模拟的精确程度,是一个影响性能的超参数。通常,扩散步数越多,模型性能越好,但计算成本也更高。在图3a中,我们绘制了DIME在DMC的humanoid-run环境中不同扩散步数下的性能表现,并在图3b中报告了在Nvidia A100 GPU机器上完成100万环境步长所对应的运行时间。随着扩散步数的增加,性能和运行时间均上升。然而,当扩散步数达到16之后,性能趋于稳定,不再提升。
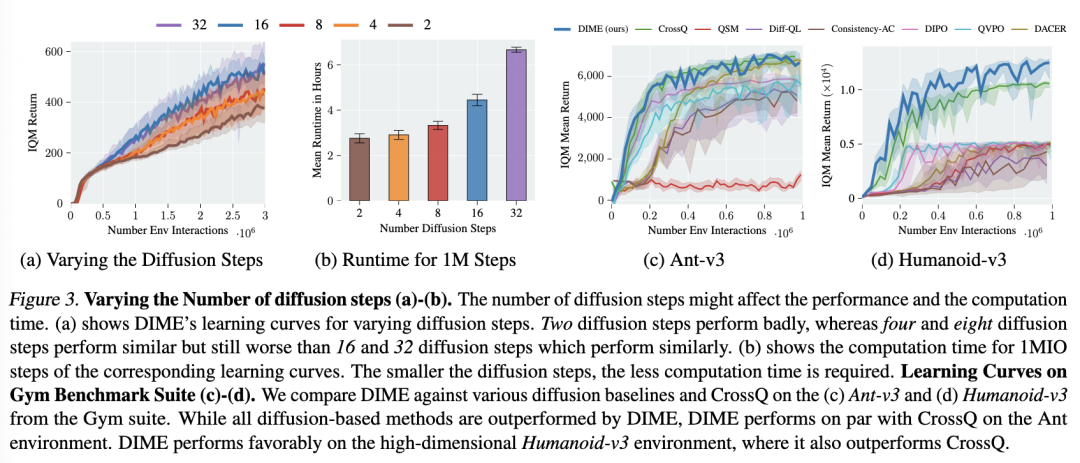
5.2 性能比较
我们从三个基准套件中选取了具有高维观测空间和动作空间的环境,以进行稳健的性能评估(详见附录C)。
Gym环境。图3c和图3d分别展示了Ant-v3和Humanoid-v3任务的学习曲线。在Ant-v3任务上,基于扩散的基线方法表现尚可,其中DIPO优于其他扩散方法,但DIME和CrossQ的表现均优于所有扩散基线,且两者性能相当。在Humanoid-v3任务上,DIME的累积回报显著高于所有基线方法。
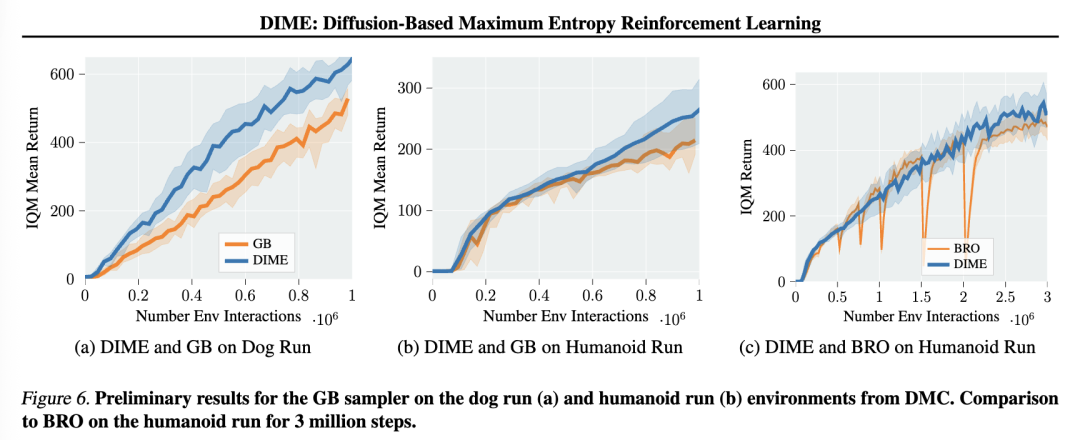
DMC:Dog和Humanoid任务(图4)。我们在DMC套件中具有挑战性的dog和humanoid环境中进行基准测试,并额外将BRO和BRO Fast作为基于高斯策略的基线方法。BRO Fast与BRO完全相同,唯一的区别是其更新-数据比(UTD ratio)为2,与DIME和CrossQ一致。请注意,我们使用的BRO学习曲线来自其官方实现所提供的在线结果。在dog-run环境中,DIME显著优于所有基线方法,并在其余dog环境(见图4a–4d)中以更快的速度收敛到相同的最终性能。在humanoid-run和humanoid-walk任务上(见图4f–4e),BRO的平均性能略高,表明DIME在dog环境以及myo suite这类更高维的任务上表现更优。然而,在humanoid-run任务中,DIME的渐近性能略高于BRO,我们在300万步的训练中对比了这两个算法(图6c)。但BRO在训练过程中需要进行完整的参数重置,导致性能出现下降,且其UTD比率为10,是DIME的5倍,这导致了更长的训练时间。根据其论文报告(Nauman等,2024),BRO在相同硬件(Nvidia A100)上训练humanoid-run任务的平均耗时为8.5小时,而DIME使用16个扩散步仅需约4.5小时。
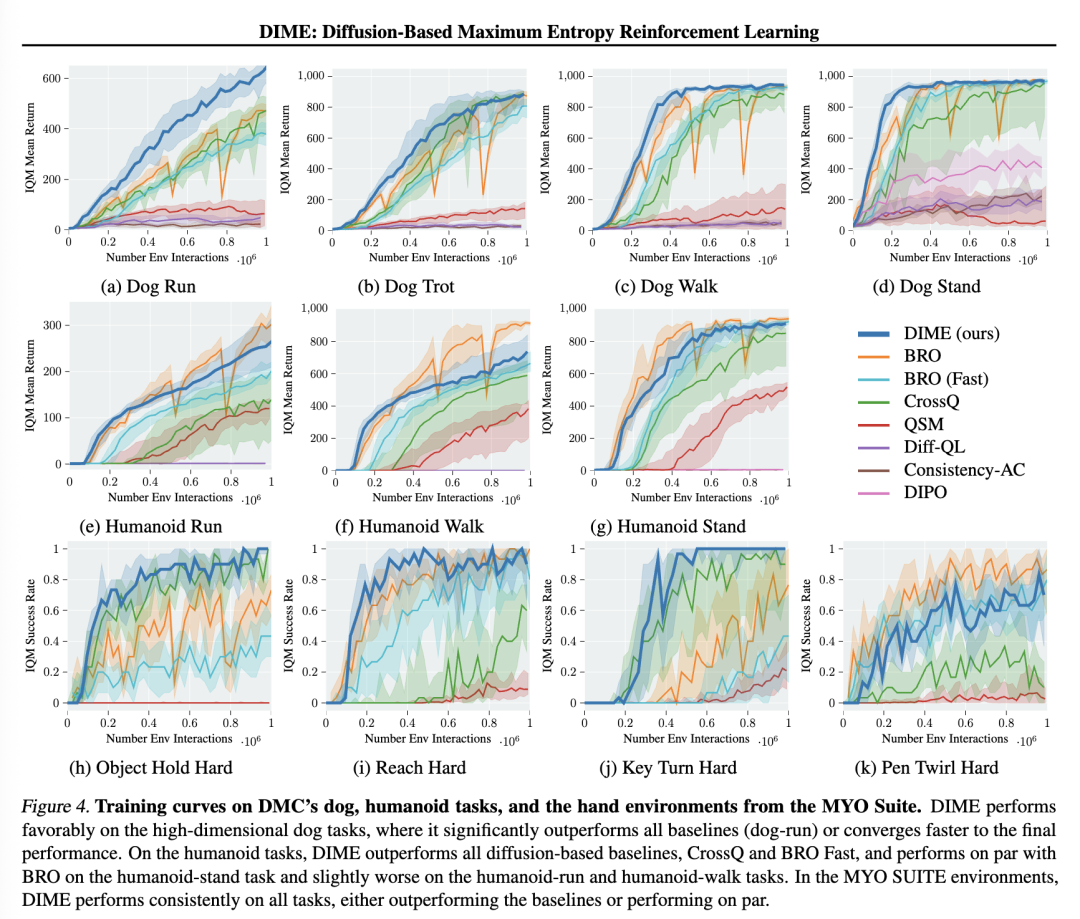
MYO套件(图4)。除了pen twirl hard任务(图4k)外,DIME在最终成功率方面始终优于BRO和BRO Fast,表现为收敛到更高的成功率或更快达到目标。在除object hold hard任务(图4h)之外的所有任务中,DIME的成功率也始终优于CrossQ;而在object hold hard任务中,DIME的收敛速度更快。
6. 结论与未来工作
在本研究中,我们提出了DIME,一种通过利用扩散模型与近似推断之间的联系,用于最大熵强化学习的扩散模型学习方法。我们认为这项工作为未来令人兴奋的研究奠定了基础。
具体而言,我们探索了去噪扩散模型,其中前向过程遵循Ornstein-Uhlenbeck过程。然而,基于扩散模型的近似推断是一个活跃且快速发展的领域,近年来涌现出许多考虑替代性随机过程的新进展。例如,Richter与Berner提出同时学习前向和反向过程;Nusken等人(2024)通过在扩散过程中引入目标密度的梯度,进一步增强了探索能力。此外,Chen等人(2024)将学习到的扩散模型与序列蒙特卡洛方法(Sequential Monte Carlo, Del Moral等,2006)相结合,形成了一种高效的推断方法。这些方法在进一步提升强化学习中基于扩散的策略方面具有巨大潜力。我们已在Richter与Berner的框架上进行了初步实验,并将结果展示在附录F中。
最后,我们注意到本文所使用的损失函数(见公式25)基于Kullback-Leibler散度。但从原理上讲,任何散度都可以被采用。例如,对数方差散度(log-variance divergence,Richter与Berner)在优化用于近似推断的扩散模型方面已展现出良好效果(Chen等,2024;Noble等,2024)。探索替代性的目标函数可能带来进一步的性能提升。
另一个值得研究的未来方向是探索使用更复杂的评论家(critic)结构的影响,例如Li等人(2025)所提出的基于Transformer的结构。
原文链接:https://arxiv.org/pdf/2502.02316
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号