MER 2025:当情感计算遇见大语言模型

MER 2025:当情感计算遇见大语言模型

CreateAMind
发布于 2026-03-11 17:13:28
发布于 2026-03-11 17:13:28
MER 2025:当情感计算遇见大语言模型
MER 2025: When Affective Computing Meets Large Language Models
https://arxiv.org/pdf/2504.19423


摘要
MER2025 是我们 MER 系列挑战赛的第三年,旨在汇聚情感计算领域的研究人员,共同探索该领域的新兴趋势和未来发展方向。此前,MER2023 主要关注多标签学习、噪声鲁棒性以及半监督学习,而 MER2024 引入了一个新的赛道,专注于开放词汇情感识别。今年,MER2025 的主题为“当情感计算遇见大语言模型(LLMs)”。我们的目标是从依赖预定义情感分类体系的传统分类框架,转向由大语言模型驱动的生成式方法,为更准确、更可靠的情感理解提供创新性解决方案。本次挑战赛包含四个赛道:MER-SEMI 赛道聚焦于通过半监督学习增强的固定类别情感识别;MER-FG 赛道探索细粒度情感,将情感识别从基本情绪扩展到更细微的情感状态;MER-DES 赛道将多模态线索(超越情感词汇本身)纳入预测过程,以增强模型的可解释性;MER-PR 赛道探究情感预测结果是否能够提升个性识别的性能。前三个赛道的基线代码可在 MERTools 平台上获取,数据集可通过 Hugging Face 访问。最后一个赛道的数据集和基线代码则可在 GitHub 上获得。
CCS 概念• 以人为本的计算 → 人机交互(HCI)
关键词 MER2025,半监督学习,细粒度情感识别,描述性情感理解,情感增强的个性识别
1 引言 情感在人机交互中扮演着至关重要的角色 [24, 33],在人工智能领域正受到越来越多的关注。如今,人类与人工智能系统的互动频率已经超过了直接的人与人之间的交流,而这一趋势预计在未来几年将变得更加显著。具备情感感知能力的交互系统在医疗、金融、交通和教育等多个领域都具有巨大的应用潜力 [7, 8]。
人类的情感表达是一个复杂的过程,通常涉及多种模态,包括面部表情、语音语调、身体动作、手势,甚至生理信号 [12]。这种复杂性推动了多模态情感识别(Multimodal Emotion Recognition, MER)的发展,该任务旨在融合跨模态线索来识别人类情感。近年来,MER 研究朝着两个关键方向演进:a)从粗粒度情感识别 [18] 发展到细粒度情感识别 [16];b)从分类方法 [14] 转向描述性情感理解 [4, 13],旨在提升预测的准确性与模型的可解释性。顺应这些发展趋势,MER2025@ACM Multimedia 推出了四个赛道,与当前的研究重点保持一致:
赛道 1. MER-SEMI。近期研究表明,在大规模无标签数据上进行预训练 [22],尤其是使用与有标签数据同域的数据,能够显著提升模型性能 [5, 18, 29]。本赛道提供了大量与有标签数据来自相同领域的无标签样本。鼓励参赛者利用半监督学习技术,例如掩码自编码器(masked auto-encoders)[30] 或对比学习(contrastive learning)[26],以取得更优的结果。
赛道 2. MER-FG。当前的框架主要关注基本情绪,往往难以捕捉人类情感的复杂性和细微差别。本赛道将重点转向细粒度多模态情感识别(fine-grained MER),旨在预测更广泛的情感类别。参考以往研究 [13, 16],鼓励参赛者利用大语言模型(LLMs)来实现这一目标。由于大语言模型具备庞大的词汇量,它们有望生成超越基本情感标签的更多样化的情感类别。
赛道 3. MER-DES。前两个赛道主要关注情感词汇,忽略了在推理过程中融合多模态线索。这一疏漏导致预测结果缺乏可解释性。此外,情感词汇难以充分捕捉人类情感的动态性、多样性以及某些情况下的模糊性。本赛道旨在利用自由形式的自然语言描述来表征情感 [13, 19],从而提供更大的灵活性,以实现更准确的情感表征,并增强模型的可解释性。
赛道 4. MER-PR。个性与情感在人类行为和社会互动中紧密交织,然而当前的研究通常将它们视为独立的任务,忽视了二者之间固有的相关性。本赛道旨在研究情感与个性之间的相互关系,探索情感识别是否能够提升个性预测的准确性。鼓励参赛者采用多任务学习等技术,分析情感对个性预测的影响。
图1展示了这些赛道之间的差异。MER2025 建立在 MER 2023@ACM Multimedia [15] 和 MER 2024@IJCAI [17] 成功举办的基础之上。在历届挑战赛中,参赛队伍数量稳步增长,从 MER2023 的76支队伍增加到 MER2024 的94支队伍。今年,我们希望吸引更多团队参与本次挑战。通过MER系列挑战赛,我们致力于建立一个统一的平台,用于比较不同系统,进一步推动多模态情感识别(MER)领域的发展。

2 MER-SEMI 2.1 数据集 MER-SEMI 跨越了连续三届的 MER 挑战赛,旨在通过半监督学习和无标签数据来提升分类情感识别算法的性能。今年,我们通过增加更多有标签和无标签样本,进一步扩展了数据集。我们的原始数据来自两个来源:a)对话情感数据集 MC-EIU [20] 和 M3ED [31],已获得数据集所有者的明确授权;b)从公开平台获取的19部中文电视剧。随后,我们沿用以往 MER 挑战赛中使用的视频分割与筛选流程 [15, 17],确保每个视频片段主要包含一名说话者,且语音内容相对完整。与 MER2024(12万样本)相比,我们在 MER2025 中将数据集规模扩大至13.2万样本,引入了更丰富的话题多样性和更多角色。详细的数据集统计信息见表1。
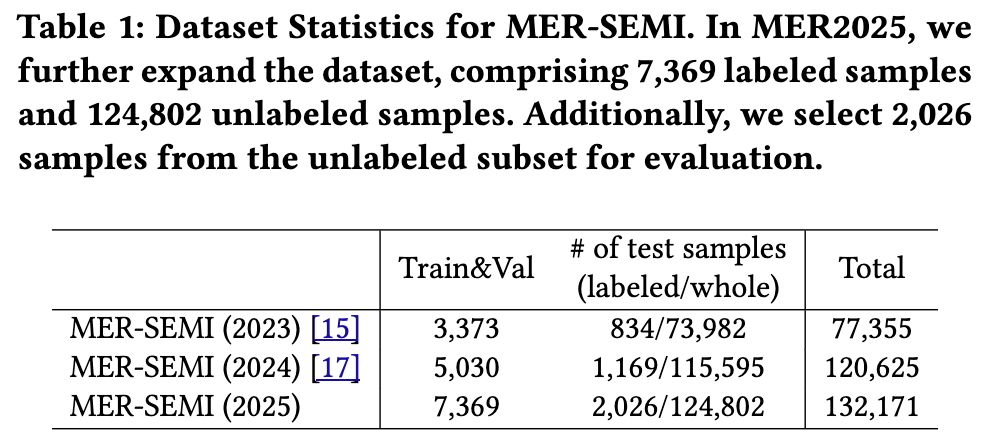
出于评估目的,由于时间和经济成本巨大,对12.4万无标签数据进行人工标注是不现实的。因此,我们从无标签数据中选取一个子集用于性能评估。为确保标注的可靠性,我们招募了九名标注人员,并进行初步测试,以评估他们与情感领域专家的一致性。在此过程中,有两名标注人员因一致性不足被剔除,最终由七名标注人员执行标注任务。随后,我们从无标签子集中随机抽取1万个样本,要求标注人员从八个类别中选择最可能的标签:中性(neutral)、高兴(happy)、愤怒(angry)、悲伤(sad)、惊讶(surprise)、担忧(worry)、其他(others)、未知(unknown)。在此过程中,我们将这1万个样本分派给不同的标注人员,以减少每个人的标注负担。同时,我们确保每个样本至少由五名标注人员标注。只有当某个样本获得至少80%的标注者一致同意,且多数票不属于“其他”或“未知”类别时,该样本才会被纳入测试集。通过这一流程,我们最终获得2,026个高质量的测试样本,确保了较高的标注者间一致性以及可靠的排序结果。
2.2 评估指标 本赛道的目标是从六个候选情感类别中识别出最可能的标签:中性(neutral)、高兴(happy)、愤怒(angry)、悲伤(sad)、惊讶(surprise)和担忧(worry)。在评估方面,我们采用与之前MER挑战赛相同的指标 [15, 17]:准确率(accuracy)和加权平均F1分数(WAF)。鉴于数据集中存在固有的类别不平衡问题,我们将WAF作为最终排名的主要评估指标。
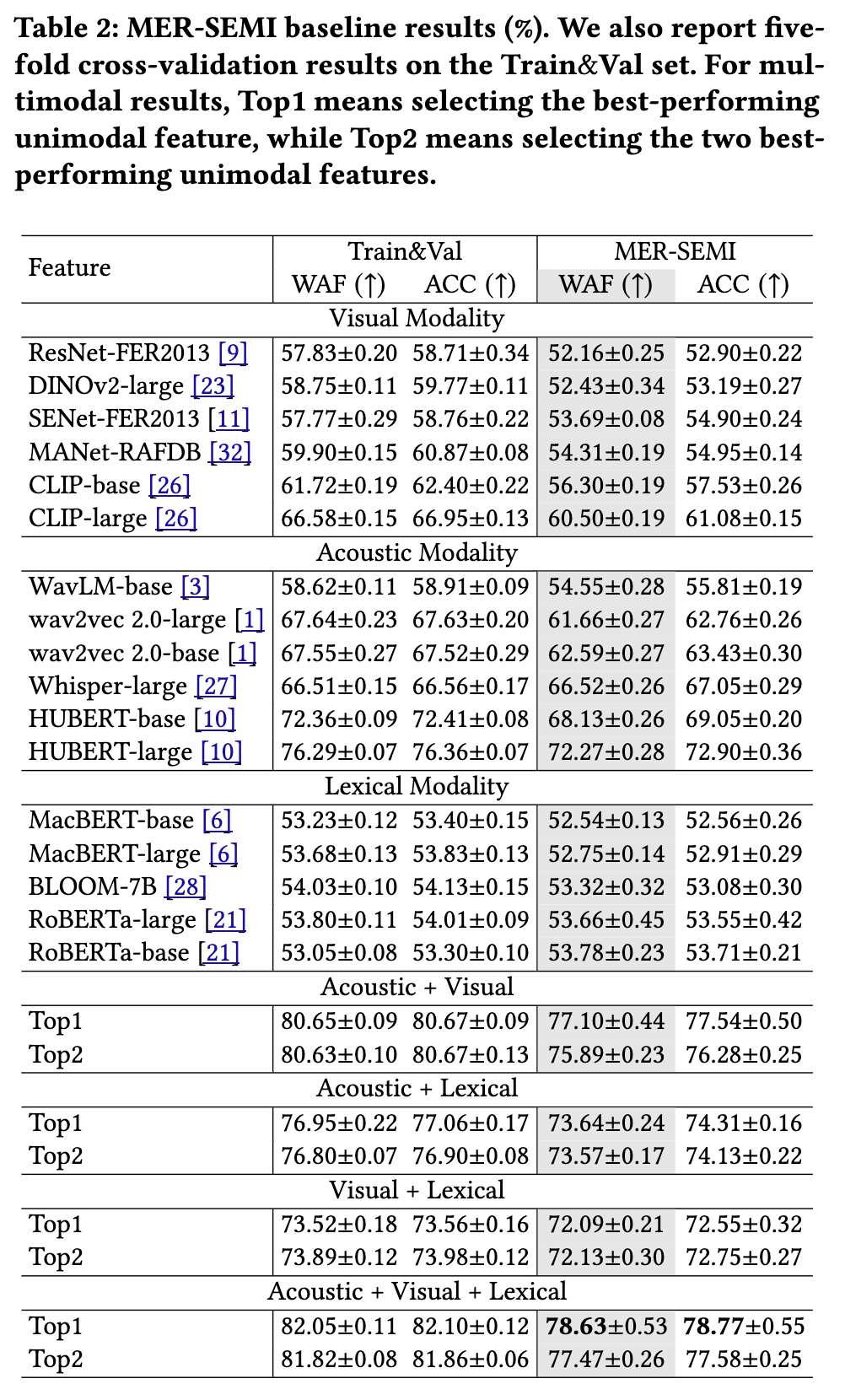
2.3 基线框架 分类模型主要依赖于两个关键组成部分:特征选择和模型架构。在特征选择方面,我们评估了手工设计特征和模型驱动特征的性能。在模型架构方面,MERBench指出,一种简单的注意力机制——将不同单模态特征映射到相同维度,然后通过注意力权重进行融合——已经能够取得良好的性能 [18]。相比之下,更复杂的融合架构可能导致过拟合问题,而由于MER任务中通常有标签数据有限,这类复杂结构并不适用。具体实现细节请参考MERBench及我们的基线代码。
2.4 基线结果 我们的基线代码设计为自动并随机选择超参数。在实际操作中,我们对每条命令执行50次,从中确定最优的超参数组合,然后在该配置下再运行6次,报告平均结果及其标准差。表2总结了MER-SEMI的基线性能。为确保可复现性,我们在基线代码中包含了所有特征提取代码和预训练权重。从表2可以看出,在Train&Val集上的五折交叉验证结果与测试集性能之间存在很强的相关性。这表明参赛者可以将Train&Val集的结果作为模型选择的可靠依据。值得注意的是,三模态融合取得了最高的性能,凸显了各模态在情感识别中的互补价值。然而,对于多模态结果而言,Top2的性能并未优于Top1。这是因为融合过程可能无意中引入了与情感无关的特征,从而可能降低整体性能。
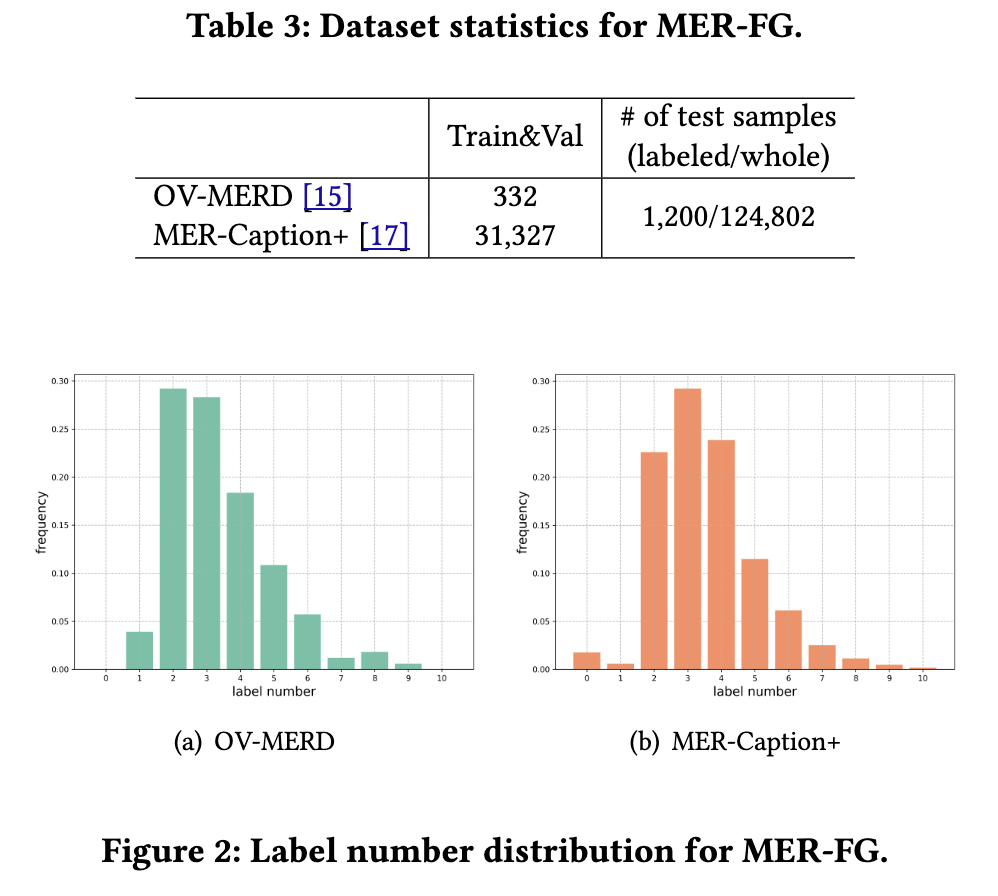
3 MER-FG 3.1 数据集 与MER-SEMI将预测范围限制在六个候选类别不同,MER-FG不限定标签空间,允许对每个样本预测任意数量和任意类别的感情标签。在本赛道中,我们采用两个近期发布的数据集OV-MERD [16] 和MER-Caption+ [13] 作为训练数据集。它们的统计信息汇总于表3。具体而言,OV-MERD采用“人工主导、模型辅助”的标注策略,即首先由多模态大语言模型(MLLMs)提取初步的多模态线索,随后高度依赖人工验证以确保标签质量。相比之下,MER-Caption+采用“人工辅助、模型主导”的标注策略,利用人类先验知识指导描述生成和样本筛选,最终实现自动化的标注流程。因此,OV-MERD提供的是小规模但高质量的标签,而MER-Caption+则提供大规模但情感标注中可能包含部分错误的标签。图2总结了这两个数据集按样本的标签数量分布情况。我们观察到,它们为每个样本提供了丰富的感情标签,为复杂情感建模提供了潜力。
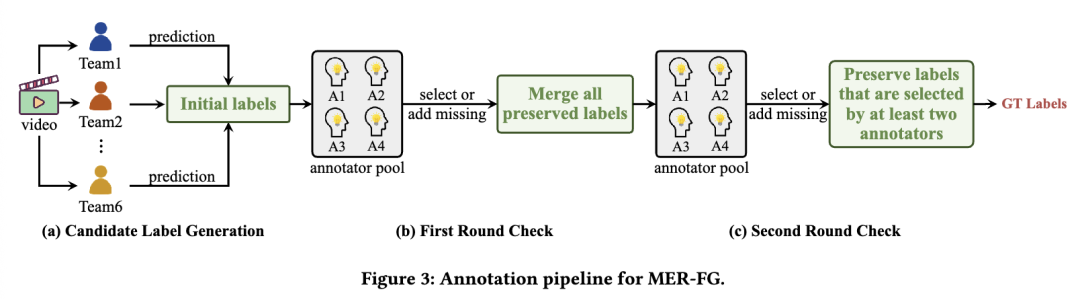
在评估方面,我们从MER-SEMI的无标签数据集中随机选取了1,200个样本,并邀请了四名标注人员进行标注。这些标注人员与参与MER-SEMI数据集标注的人员不同,且同样通过了MER-SEMI中描述的初步资格测试。图3展示了详细的标注流程。具体而言,我们首先汇总了去年MER-OV赛道中排名前六支队伍的提交结果,生成初始候选标签列表。然后,每位标注人员的任务是:从候选列表中选择他们认为正确的标签,或添加他们认为合适但未包含在候选列表中的其他标签。这种方法相比直接要求标注人员从零开始提供标签,能够获得更丰富的情感标注。我们的手动验证过程分为两轮:第一轮中,我们保留所有不同标注人员选择的标签,以确保标注的全面性;第二轮中,我们仅保留至少被两名标注人员确认的标签,以确保准确性。通过这一两步验证流程,每个最终标签至少被验证三次,从而确保了标注结果的全面性与准确性。
3.2 评估指标 本赛道在预测时不限制标签的数量和类别。因此,传统的准确率等指标不适用于MER-FG。在评估方面,我们参考先前的工作 [16],采用两阶段的评估方式。
3.2.1 分组(Grouping)。首先,我们采用三级分组策略,以减少同义词带来的影响:
M1. 我们将情感词的不同形式归一化为其基本形式。例如,将happier和happiness映射为happy。该函数记为𝐹(·)。
M2. 我们将同义词映射到统一的标签。例如,将happy和joyful映射为happy。该函数记为𝐺(·)。
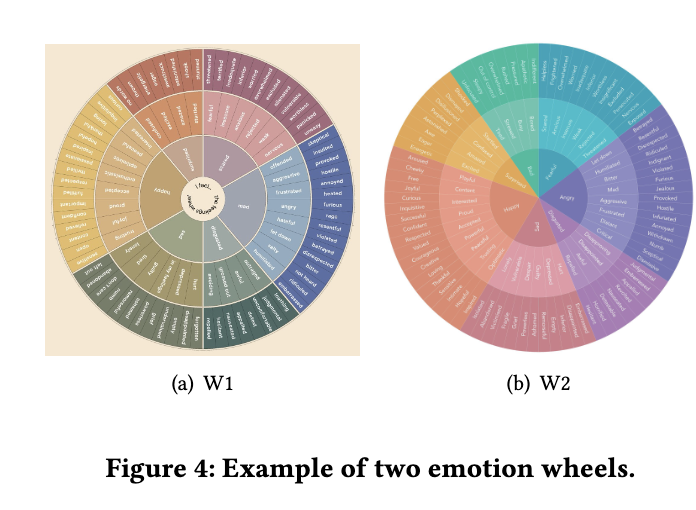
M3. 情感轮(emotion wheel)提供了自然的层次化分组结构,基本情绪位于最内层,更细微的情绪标签分布在外层 [25]。图4展示了两个情感轮。首先,我们将标签从最内层到最外层按层级分组为𝐿1𝑤、𝐿2𝑤 和 𝐿3𝑤。接着,我们定义一个映射函数𝑚𝑖→𝑗𝑤(·),用于将第𝐿𝑖𝑤层的标签映射到第𝐿𝑗𝑤层对应的标签。然后,我们引入两个分组函数𝑊1和𝑊2。对于𝑊1,所有标签均被映射到其在𝐿1𝑤层对应的标签:
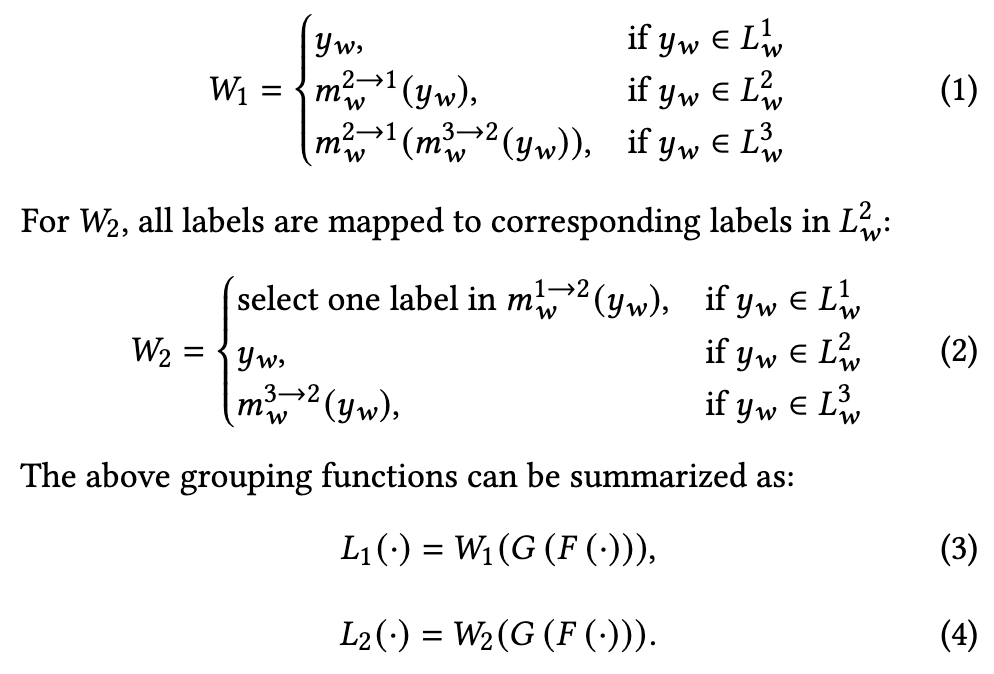


3.3 基线框架 3.3.1 零样本基线(Zero-shot Baselines)。MER-FG 的主要目标是为给定样本生成适当的情感标签,而不受预定义情感分类体系的限制。因此,由大语言模型(LLM)驱动的基线方法非常适合该任务,因为它们拥有庞大的词汇量,能够生成细粒度的情感标签。鉴于情感通常通过多模态线索表达,我们主要选择多模态大语言模型(MLLMs)作为基线,包括代表性框架如 SALMONN 和 Chat-UniVi。为了提取与情感相关的线索,我们使用以下提示语(prompt):
“作为一名情感领域的专家,请重点关注视频中的面部表情、身体动作、环境、声学信息、字幕内容等,以识别与人物情绪相关的线索。请提供详细描述,并最终预测视频中人物的情绪状态。”
接下来,我们使用 Qwen2.5 从上述描述中提取情感标签,所用提示语如下:
“请扮演一位情感领域的专家。我们提供了一些可能与人物情绪相关的线索。请根据这些线索,识别出主要人物的情绪状态。请用逗号分隔不同的情绪类别,并仅以列表形式输出可以明确识别的情绪类别。如果无法识别任何情绪,请输出空列表。”
最终,我们得到 MER-FG 的情感预测结果。该过程不涉及任何训练,属于零样本(zero-shot)设置。对于 MLLMs,我们默认使用其 70亿(7B)参数的模型权重。所有模型均基于 PyTorch 实现,推理过程均在 A100 GPU 上完成。此外,我们使用 vLLM 工具包来加速推理过程。
3.3.2 AffectGPT。我们还评估了一种面向情感任务的专用 MLLM——AffectGPT [13] 的性能。该框架采用预融合机制以增强多模态信息的整合。在实验中,我们在两个数据集上对该模型进行训练:OV-MERD 和 MER-Caption+。所有预训练模型均可在我们的官方基线代码仓库中获取。具体实现说明请参考基线代码。
3.4 基线结果 表4展示了所有基线模型的结果。从表4可以看出,AffectGPT优于零样本基线模型,在粗粒度得分𝑆1和细粒度得分𝑆2上均取得了更高的分数。此外,在MER-Caption+数据集上训练的模型表现优于在OV-MERD数据集上训练的模型。这些结果表明,尽管OV-MERD的标签质量较高,但其数据集规模有限,不足以支持有效的模型训练。相比之下,MER-Caption+提供了更多的样本且标签相对准确,因此在MER-FG任务上表现更优。
4 MER-DES
4.1 数据集
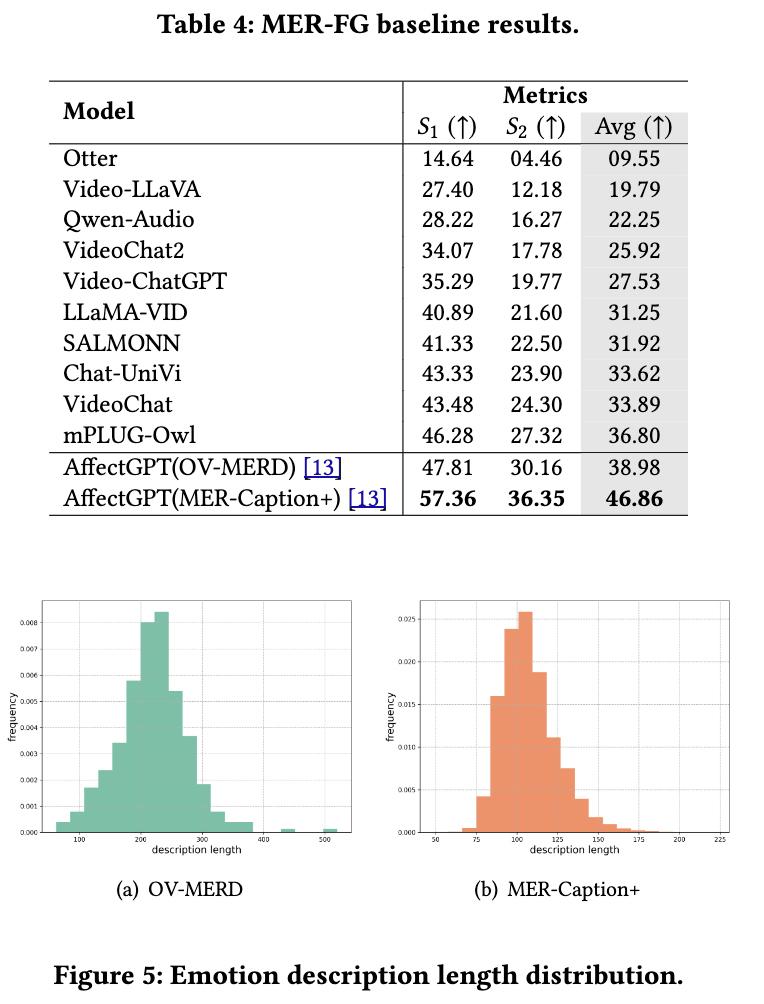
MER-SEMI 和 MER-FG 聚焦于情感词汇的预测,而 MER-DES 则进一步超越情感词汇,通过融合多模态线索来增强每个情感标签的可解释性。图1展示了这些赛道之间的任务差异。由于在MER-FG中使用的数据集OV-MERD和MER-Caption+也提供了情感描述,因此它们被用作MER-DES的训练集。图5展示了这两个数据集中描述文本的长度分布情况。我们观察到,两个数据集都为每个样本提供了详细的情感描述。
4.2 评估指标
MER-DES 利用多模态线索来增强每个情感标签的可解释性。由于可解释性本身是一个相对主观的指标,我们计划招募标注人员对情感描述的质量进行人工评估。同时,我们将邀请每个团队的两名成员协助评分过程。评估将从两个维度进行:
第一,评估提交结果是否包含可解释的线索。这一标准将MER-DES与MER-SEMI和MER-FG区分开来,确保参赛者不仅仅提供情感标签,还需提供支持性证据。
第二,从两个方面评估情感描述的质量:1)所提供的感情线索是否真实存在于视频中;2)所识别的情感与其相关线索之间是否存在逻辑关联。
最初,我们计划提供真实描述,并像EMER [19] 那样计算真实描述与预测描述之间的相似性得分。然而,人类的情感表达十分复杂,很难完整捕捉所有与情感相关的视觉和声学线索。因此,我们转而采用人工评估方式。在排名过程中,每个团队都需参与标注工作。我们将剔除与其他标注者一致性较低的标注人员,以确保标注质量。此外,我们将对样本名称进行匿名处理,并要求参赛者以英文提交结果,但使用其翻译后的中文版本进行排名。这一做法可防止参赛者识别出自己的提交内容,并故意给出过高评分。最终排名将基于这些人工标注结果确定。
4.3 基线框架 4.3.1 零样本基线(Zero-shot Baselines)。你也可以使用多模态大语言模型(MLLMs)作为基线。具体而言,你可以使用以下指令向MLLMs发出提示: “作为一名情感领域的专家,请重点关注视频中的面部表情、身体动作、环境、声学信息、字幕内容等,以识别与人物情绪相关的线索。请提供详细描述,并最终预测视频中人物的情绪状态。”
4.3.2 AffectGPT。你也可以使用OV-MERD和MER-Caption+数据集中的情感描述对AffectGPT进行微调。 该赛道的官方GitHub仓库中已包含基线代码和预训练权重。
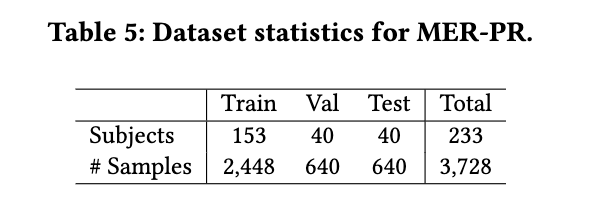
5 MER-PR 5.1 数据集 本赛道旨在探究情感预测结果是否能够提升个性识别的性能。为此,我们使用了MDPE数据集 [2],该数据集同时提供了情感和个性特质的标注。该数据集及基线代码可在GitHub上获取6。表5列出了数据集的统计信息。
在个性特质方面,我们采用包含60个题项的大五人格问卷(Big Five personality questionnaire)。通过受访者的回答,我们计算出五个个性维度的得分:开放性(openness)、尽责性(conscientiousness)、外向性(extraversion)、宜人性(agreeableness)和神经质(neuroticism),每个维度以0到1之间的浮点数值表示。该数据集共包含233名参与者,均为来自不同背景的中文母语者。
在情感标签方面,每位参与者观看了16段情绪诱导视频,其中包括为诱发八种目标情绪而设计的各两个视频,这八种情绪分别为:悲伤、高兴、放松、惊讶、恐惧、厌恶、愤怒和中性。观看后,参与者描述了自己的情绪反应,并完成了一份自评情绪量表,以1–5分的李克特量表(1 = 无情绪,5 = 情绪最强)量化每种情绪的强度。该过程为每位参与者收集了16个样本,总共获得3,728个样本。
5.2 评估指标 本赛道聚焦于个性识别。在数据集中,个性特质通过五个浮点数值进行量化。在评估时,我们采用均方根误差(Root Mean Square Error, RMSE)作为指标,用于衡量真实个性得分与预测得分之间的差异。RMSE 的计算公式如下:
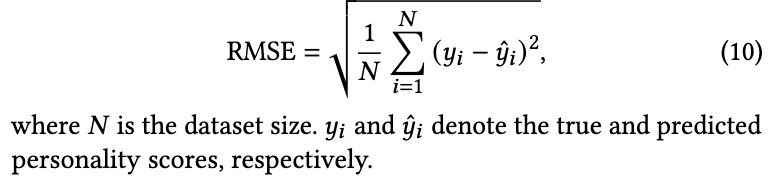
5.3 基线框架 对于单模态特征,我们采用全连接层来提取隐层表示并预测个性得分:

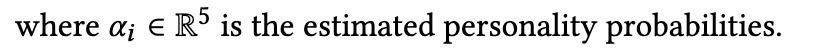
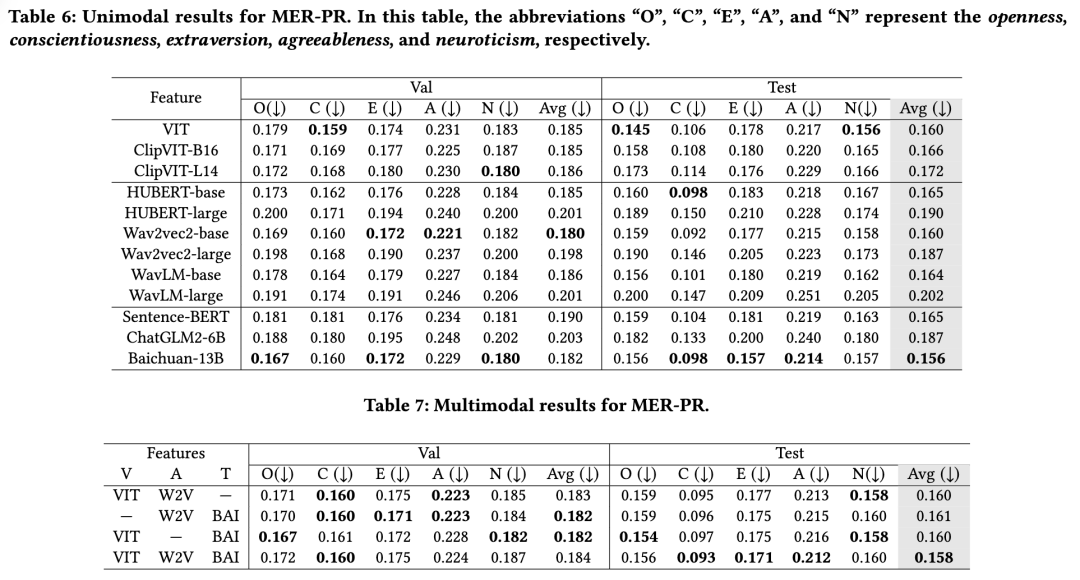
5.4 基线结果 5.4.1 单模态结果。我们建立了针对视觉、声学和文本三种模态的个性特质预测单模态基准(见表6)。在视觉模态中,ViT 特征表现具有竞争力,尤其在预测尽责性(conscientiousness)方面效果突出。在声学特征中,Wav2Vec2-base 取得了最高的平均结果。文本模态的表现优于所有其他单模态特征,其中 Baichuan-13B 在测试集上取得了最佳的平均得分(0.156),在外向性(0.157)、宜人性(0.214)和神经质(0.157)方面表现尤为出色。同时,尽管文本线索提供的信息最丰富,视觉和声学信号仍能提供与特定个性特质相关的互补性洞察。例如,ViT 特征对尽责性的预测特别有效,而 Wav2Vec2-base 在宜人性预测上表现良好。
5.4.2 多模态结果。在表7中,我们展示了基于若干表现最佳的单模态特征的多模态融合结果。尽管多模态融合在平均测试得分上并未持续优于单一模态,但在某些特定个性特质上实现了性能提升。这凸显了针对不同个性特质定制融合策略的潜在优势。
6 挑战赛规则 对于 MER-SEMI、MER-FG 和 MER-DES 赛道,参赛者需在 Hugging Face 上签署《最终用户许可协议》(End User License Agreement, EULA)7 后方可下载数据集。该协议明确规定,数据集仅限用于学术研究,禁止任何修改或上传至互联网。我们强调,严禁对 MER2025 的样本进行人工标注。这些赛道的测试样本选自 12.4 万无标签样本(见表 1)。为降低任务难度,我们将评估范围从 12.4 万缩减至 2 万个样本。参赛者需提交这 2 万个样本的预测结果,这些样本涵盖了上述各赛道的全部测试样本。如图 1 所示,每个赛道具有不同的目标:对于 MER-SEMI,参赛者必须从六个预定义类别中预测最可能的标签:担忧(worried)、高兴(happy)、中性(neutral)、愤怒(angry)、惊讶(surprised)和悲伤(sad);对于 MER-FG,参赛者可自由预测任意数量和任意类别的感情标签,不受类别或数量限制;对于 MER-DES,参赛者需同时提交多模态证据及相应的情感标签,以提升模型的可解释性。
对于 MER-PR 赛道,数据集和基线代码可在 GitHub 上获取8。我们提供了一个官方测试集,参赛者可直接提交该测试集的预测结果。
7 结论 今年的 MER2025 聚焦于“当情感计算遇见大语言模型”这一主题,包含四个不同的赛道。本文介绍了所有赛道的数据集、基线方法、评估指标和实验结果。在 MER-SEMI 赛道中,我们评估了多种单模态特征和多模态融合方法,为在固定分类体系下的分类情感识别提供了强有力的基线。在 MER-FG 和 MER-DES 赛道中,我们采用基于大语言模型(LLM)的基线方法,生成带有相应多模态线索的细粒度情感标签,从而实现更准确且可解释的情感理解。在 MER-PR 赛道中,我们测试了多种单模态特征在个性识别中的表现。为促进研究的可复现性,我们已在官方 GitHub 仓库中开源了全部代码和预训练模型。希望所有参赛者享受今年的挑战赛!你们的持续支持与积极参与,使本次挑战赛真正具有意义。
原文链接:https://arxiv.org/pdf/2504.19423
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号