AI论文速读 | 面向复杂时空推理:高德时空智能体——STAgent的设计与实践

AI论文速读 | 面向复杂时空推理:高德时空智能体——STAgent的设计与实践

时空探索之旅
发布于 2026-03-10 15:37:25
发布于 2026-03-10 15:37:25
论文标题:AMAP Agentic Planning Technical Report
作者: Yulan Hu, Xiangwen Zhang, Sheng Ouyang, Hao Yi, Lu Xu, Qinglin Lang, Lide Tan, Xiang Cheng, Tianchen Ye, Zhicong Li, Ge Chen, Wenjin Yang, Zheng Pan, Shaopan Xiong, Siran Yang, Ju Huang, Yan Zhang, Jiamang Wang, Yong Liu, Yinfeng Huang, Tucheng Lin, Xin Li, Ning Guo
机构:高德地图
论文链接:https://arxiv.org/abs/2512.24957
TL;DR:针对现有大模型工具集成推理适配时空类复杂任务(如 POI 搜索、行程规划)不足,且存在工具环境不稳定、高质量数据匮乏、训练方法针对性欠缺的问题,研究提出时空专用智能体 STAgent,以 “稳定工具环境 + 高质量数据筛选 + 难度感知级联训练” 三位一体方案解决。其搭建含 10 种专用工具的稳定环境,从 3000 万条日志中筛选 20 万条优质数据,通过 “seed SFT→二次 SFT→RL” 级联训练优化,最终在 TravelBench 等时空基准上超越多数大模型,且保持数学、coding 等通用能力不退化。
关键词:STAgent、复杂时空推理、智能体框架、环境 - 数据 - 训练、级联训练、工具交互、强化学习

摘要
本文提出了STAgent(spatio-temporal agent),这是一款专为时空理解打造的智能体大语言模型,旨在解决复杂任务,如带约束的兴趣点发现和行程规划。STAgent是一个专门的模型,能够在时空场景中与十种不同的工具进行交互,使其能够在复杂推理过程中探索、验证和完善中间步骤。值得注意的是,STAgent有效地保留了其通用能力。我们通过三个关键贡献为STAgent赋予了这些能力:(1)一个稳定的工具环境,支持十多种特定领域工具,实现异步推演和训练;(2)一个分层数据筛选框架,能像大海捞针一样识别高质量数据,以1:10000的筛选比例筛选出高质量查询,同时注重多样性和难度;(3)一个级联训练方案,首先是种子SFT阶段,作为衡量查询难度的守护者,接着是第二个SFT阶段,针对高确定性的查询进行微调,最后是利用低确定性数据的强化学习(RL)阶段。STAgent以Qwen3-30B-A3B为初始模型,建立了坚实的SFT基础并利用了对样本难度的洞察,在TravelBench上取得了令人期待的性能,同时在众多通用基准测试中保持了其通用能力,从而证明了我们所提出的智能体模型的有效性。
Q: 这篇论文试图解决什么问题?
A:论文旨在解决真实世界时空场景下复杂推理任务的自动化难题,核心聚焦于以下三点:
- 构建稳定且可扩展的工具调用环境,以支撑大规模并发工具请求与强化学习训练;
- 从3 000 万条无监督历史查询中高精度筛选约 20 万高质量指令,解决真实数据噪声大、缺乏难度与多样性标签的问题;
- 设计“SFT 引导的级联强化学习”训练范式,使模型在保持通用能力的同时,显著提升对多约束 POI 发现、行程规划、路线优化等 System-2 级时空推理任务的解决能力。
Q: 有哪些相关研究?
A: 论文在时空推理、工具集成推理(TIR)以及强化学习训练范式三条主线与以下研究直接相关:
- 工具集成推理框架
- Tora: A tool-integrated reasoning agent for mathematical problem solving (Gou et al., 2023)
- Agentic Reinforced Policy Optimization (Dong et al., 2025)
- rstar2-agent: Agentic reasoning technical report (Shang et al., 2025)
- -bench: Evaluatingconversational agents in a dual-control environmen (Barres et al., 2025)
- 真实世界行程/时空规划基准
- Travelplanner: A benchmark for real-world planning with language agents (Xie et al., 2024)
- ravelbench: A real-world benchmark for multi-turn and tool-augmented travel plannin (Cheng et al., 2025)
- 难度感知与课程强化学习
- Difficulty-aware certainty as a guide for llm reinforcement learning (Li et al., 2025a)
- Rubrics as rewards: Reinforcement learning beyond verifiable domain (Hashemi et al., 2024; Gunjal et al., 2025)
- 高效 RL 基础设施
- (ROLL)Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library (Wang et al., 2025)
- Verl 开源框架对比(效率基线)
- 基础模型与 MoE 架构
- Qwen3 technical report. (Yang et al., 2025)
- Deepseek-v3. 2: Pushing the frontier of open large language models(Liu et al., 2025)
这些工作共同构成了 STAgent 在环境、数据、训练与评估四方面的研究背景。

Q: 论文如何解决这个问题?
A: 论文通过 “环境 - 数据 - 训练” 三位一体的系统性方案,精准破解真实世界时空推理的核心痛点,实现 “专用能力深耕 + 通用能力保值” 的双重目标,具体解决方案如下:
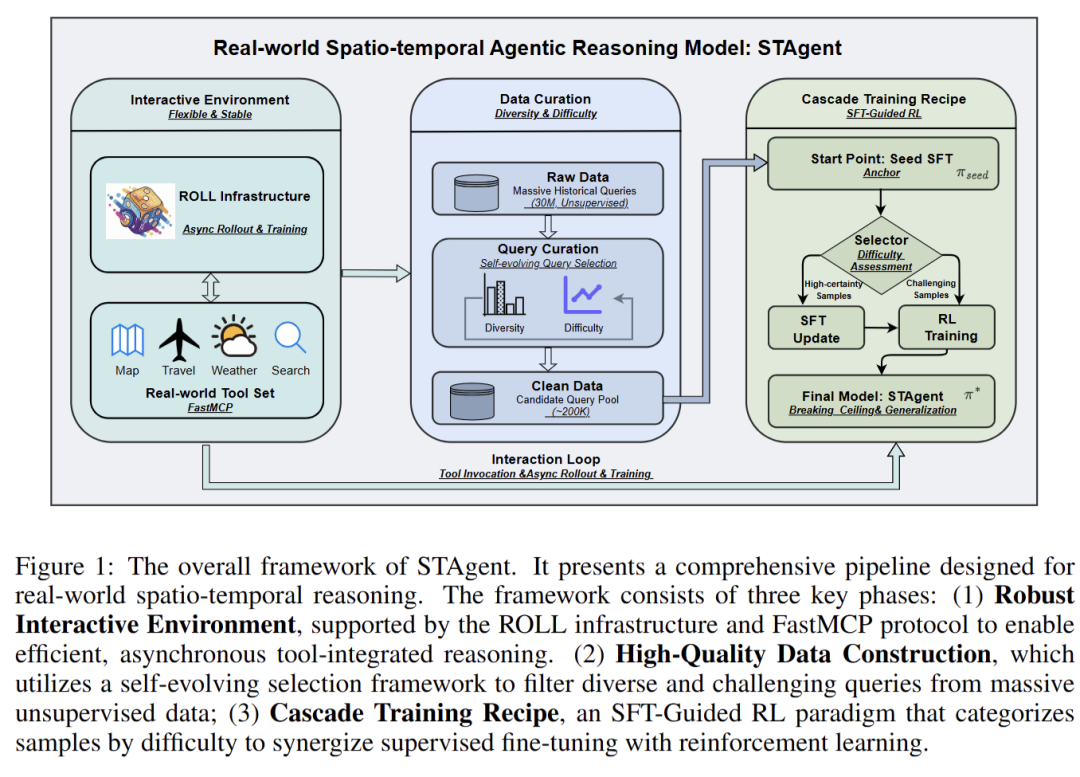
STAgent 框架
STAgent 框架
一、构建高可靠时空工具交互环境
以 FastMCP 协议为基础搭建高保真沙箱环境,标准化封装地图导航、出行查询、天气服务、信息检索四大类共 10 种专用工具,统一参数格式与调用协议,降低工具迭代与扩展成本。联合 ROLL 框架优化训练基础设施,实现异步轨迹生成与训练并行,较开源框架 Verl 提升 80% 训练效率;内置工具级 LRU 缓存与参数归一化机制,最大化缓存命中率,显著降低大规模 RL 训练中的 API 延迟与调用成本,为高并发工具交互提供稳定支撑。

高德Agnet沙箱环境的工具库
高德Agnet沙箱环境的工具库
二、打造高价值时空推理数据集
提出 “种子驱动演化(Seed-Driven Taxonomy Evolution)” 层次化意图分类体系,通过 “人工种子初始化→LLM 类别归纳→人机迭代 refinement→长尾意图扩展” 四阶段,构建覆盖 5 大主类、16 个二级类、30 个细分类别的动态意图 taxonomy。基于 3000 万条真实用户日志,通过 “词法去重(局部敏感哈希)→语义去冗余(Faiss 嵌入相似度检索)→几何选优(KCenter-Greedy 算法)” 三阶段漏斗筛选,以 1:10000 的过滤比提炼 20 万条高质量指令,兼顾任务多样性与难度梯度。引入 Execution-Simulation 多维度评分机制,从认知负荷、执行链深度、约束复杂度三个维度为样本标注 -1(不可执行)至 5(极难)的难度标签,同时纳入无解 / 无需工具的边界案例,为课程学习与幻觉 mitigation 提供数据支撑。
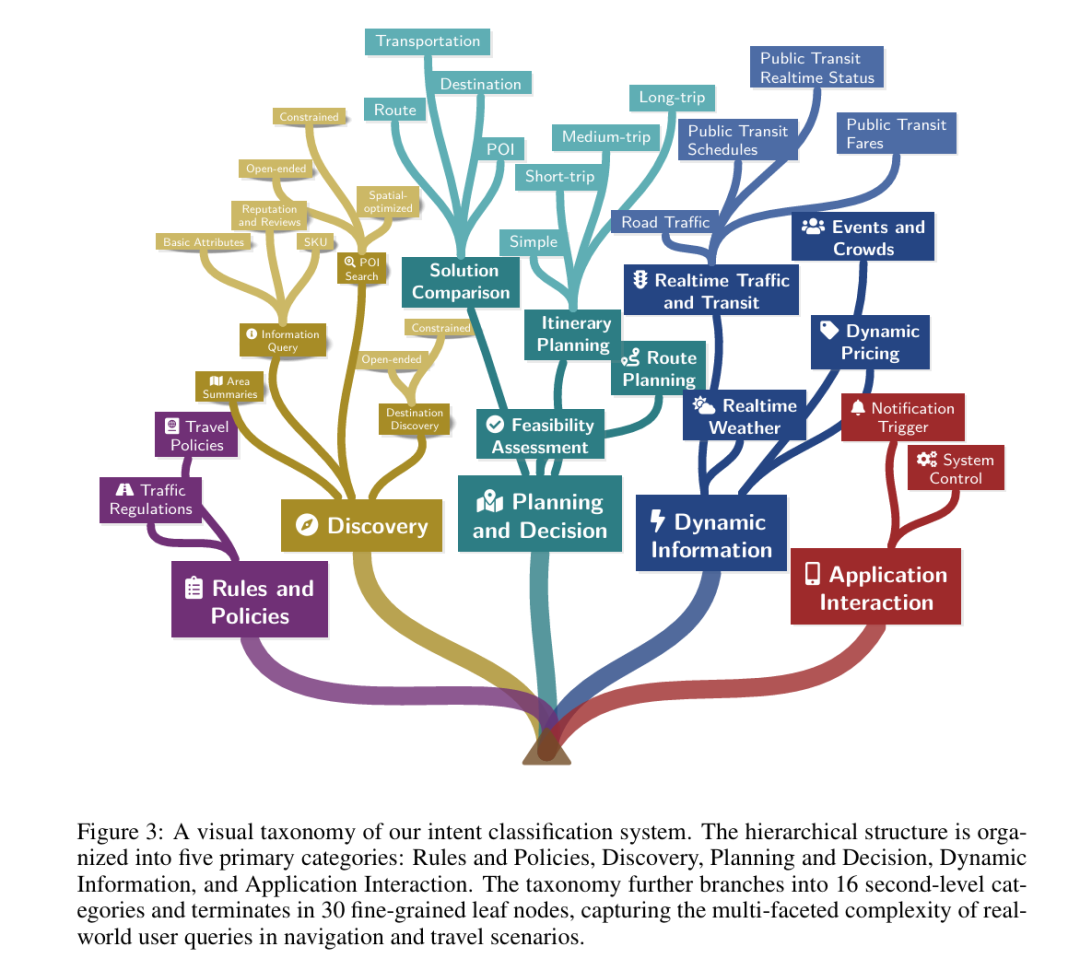
意图分类系统的可视化分类体系
意图分类系统的可视化分类体系
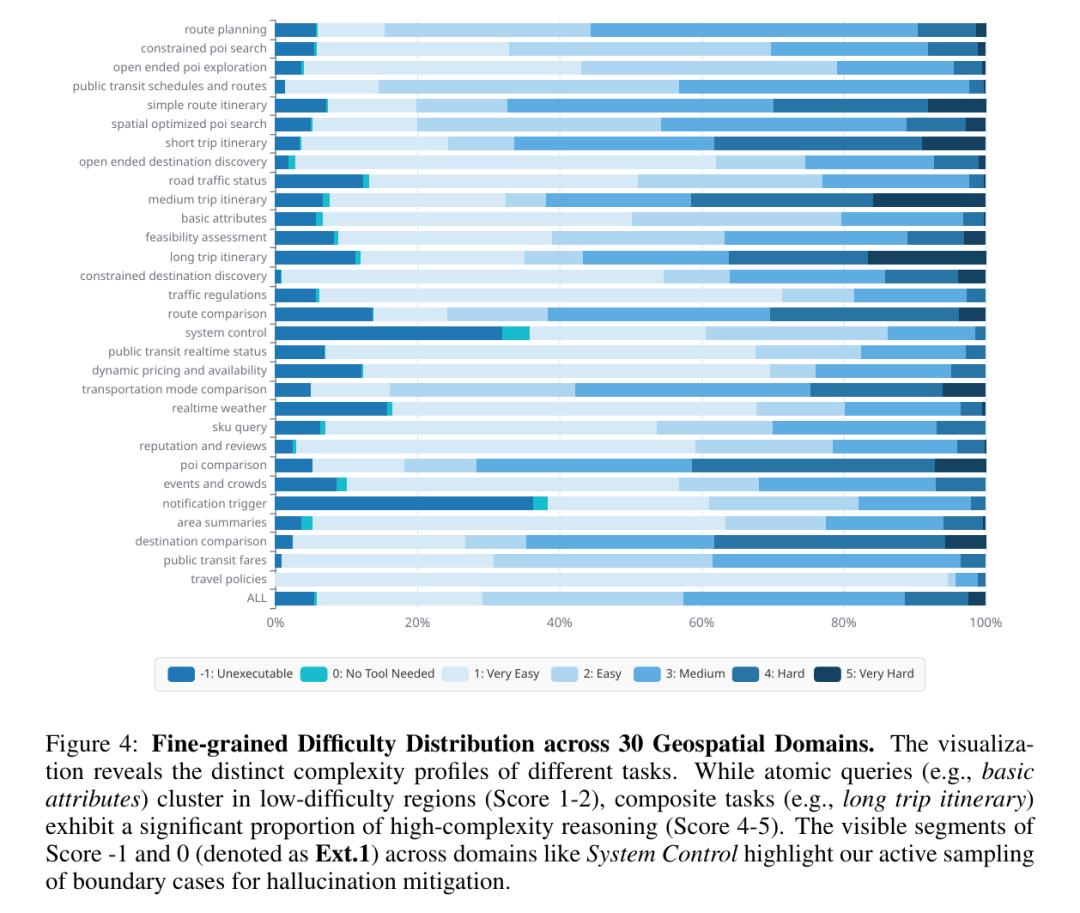
30个地理空间领域细粒度问题难度分布情况
30个地理空间领域细粒度问题难度分布情况
三、设计难度感知级联训练范式(SFT-Guided RL)
1. Seed-SFT:奠定基础能力与难度评估锚点
以强语言模型(DeepSeek-R1)为教师模型,为候选指令生成8条工具集成推理(TIR)轨迹——每条轨迹完整覆盖“意图分解→工具选择→参数生成→结果整合”全流程,随后通过Gemini-3-Pro作为Verifier,严格按推理规划(逻辑性、主动性)、信息保真(无冗余、无错误)、呈现服务(结构化、闭环性)三大奖励维度逐项打分,仅保留全维度满分的轨迹作为高质量训练数据,确保初始训练信号的纯净度。选取10%的“小型高质量数据集”(Tiny Dataset)完成模型warmup,训练过程中采用小批量(batch size=16)迭代与梯度裁剪(clip value=1.0)稳定训练过程,既让模型初步掌握时空任务分解、工具精准编排(含参数格式规范)、异构工具输出(地图坐标、航班信息、天气数据)整合的核心能力,又构建初始难度评估器——通过对全量20万候选数据生成8条轨迹,计算每条样本的奖励均值()与方差(),精准区分“高确定性(均值高、方差小)”“低确定性(均值中等、方差大)”“无训练价值(均值趋近0或1)”三类样本,为后续数据分层提供关键依据。
2. 动态能力感知 SFT:精准挖掘高价值训练信号
提出 Learnability Potential Score(),其中奖励均值反映样本的可行性(非零均值代表模型可部分解决),方差反映模型对该样本的不确定性(高方差代表模型能力边界),两者相乘可精准定位“跳一跳够得着”的可学习区域样本(典型阈值:且)。采用自适应采样策略:按得分降序排序,前30%高价值样本分配最高8条/指令的强模型采样预算,确保获取足够多高质量推理路径;中间50%样本分配4-6条轨迹,平衡成本与效果;后20%低价值样本仅分配2条轨迹,避免算力浪费。同时,设计针对性的SFT损失函数:
其中,表示第条轨迹的第个token,为掩码指示函数——当属于工具观测结果(如API返回的POI坐标、航班信息)时,,不参与损失计算;仅当属于模型生成的推理步骤、工具调用指令、最终响应时,,确保模型聚焦学习核心能力;
为有效token总数,用于归一化损失值,避免因轨迹长度差异导致的训练偏差。通过该损失函数与自适应采样策略,构建高信号密度数据集,有效规避trivial样本导致的过拟合与impossible样本引发的训练崩溃,持续优化模型基础时空推理能力。
3. SFT-Guided RL:突破性能天花板
以优化后的 SFT 模型为初始化权重,在沙箱环境中采用 GRPO 变体 GSPO 算法进行强化学习——通过几何平均计算整个轨迹的似然比:
实现序列级优化约束,避免token级优化导致的轨迹逻辑不一致。设计“动态权重+幻觉否决”双机制奖励函数"":
根据任务类型动态分配权重(复杂规划侧重推理,;信息检索侧重保真,;咨询解释侧重呈现,),同时通过严格比对工具输出与模型响应中的关键事实(时间、价格、距离、坐标等),对存在幻觉的轨迹直接判,奖励。通过RL阶段专攻SFT模型未完全掌握的高难度任务(如多约束跨城自驾规划、长尾POI精准搜索),实现性能边界的持续突破。

四、保障通用能力不退化
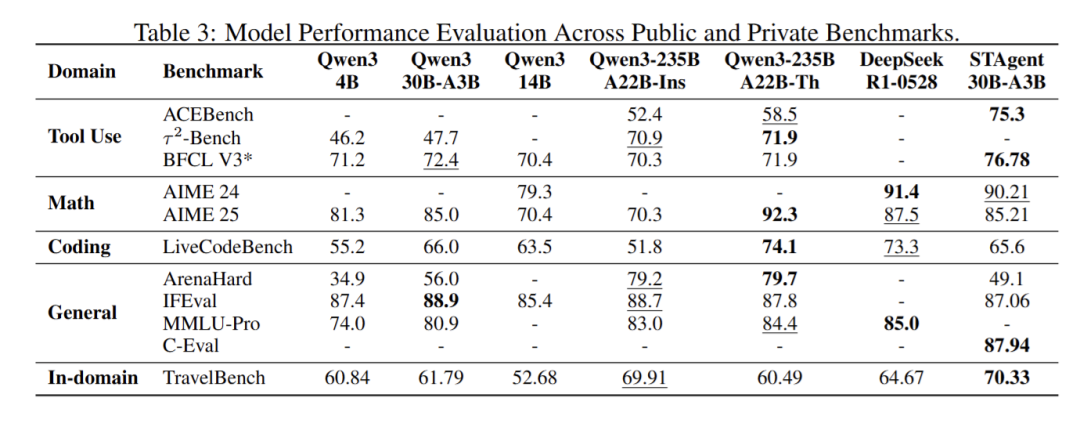
在SFT阶段仅混入不超过5%的通用指令跟随数据(如基础逻辑推理、简单自然语言理解任务),核心聚焦时空领域专用数据训练,避免通用能力被稀释。最终基于Qwen3-30B-A3B(MoE架构)的STAgent模型,在TravelBench时空基准上实现8.5pp的整体提升,其中多轮对话任务得分66.61分(位列第一),单轮任务73.4分,无解任务71.0分;同时在通用基准中表现亮眼:工具使用类ACEBench达75.3分,数学推理AIME24/25分别为90.21/85.21分,编码任务LiveCodeBench 65.6分,综合能力MMLU-Pro、C-Eval等均保持甚至超越初始模型水平,真正实现“时空专用深耕而不偏科”的核心优势。
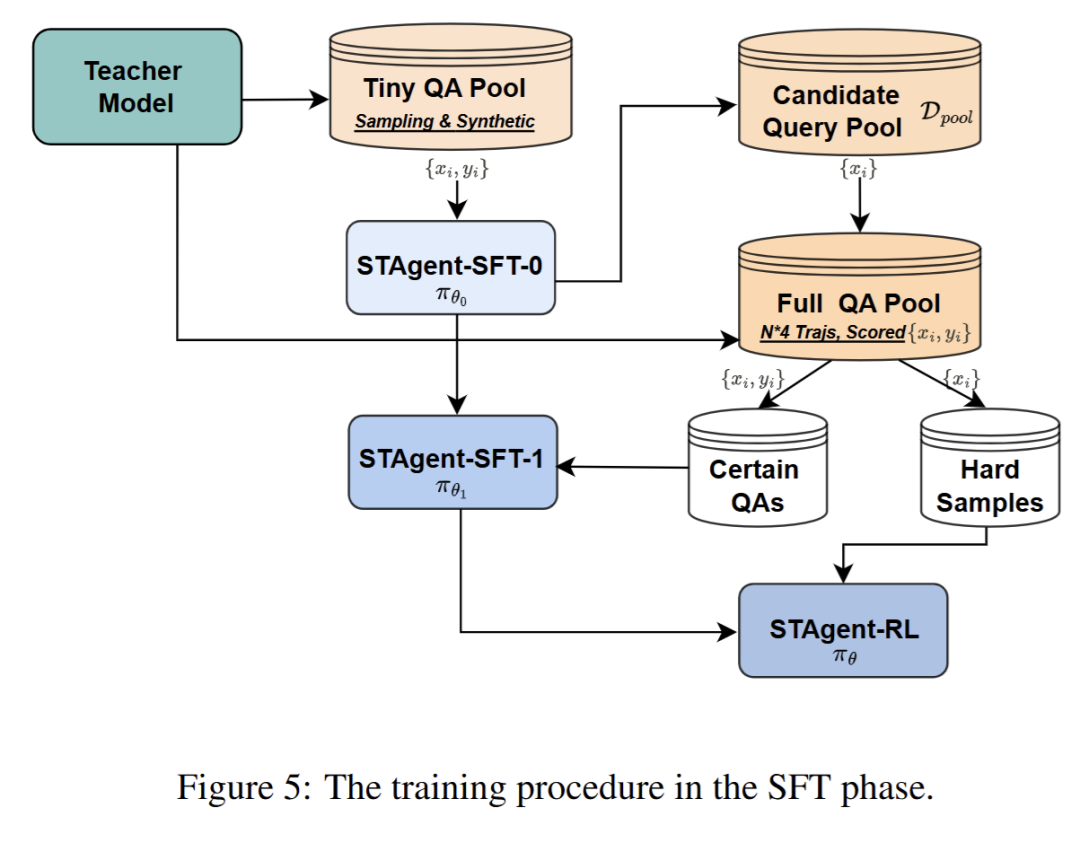
SFT阶段的训练程序
SFT阶段的训练程序
Q: 论文做了哪些实验?
A: 论文围绕域内时空任务与通用能力两条核心主线开展系统实验,覆盖在线真实环境、离线静态基准及公开跨域评测三大场景,全面验证模型性能与训练范式有效性,具体实验结果如下:
1. 域内实验:时空任务核心能力验证
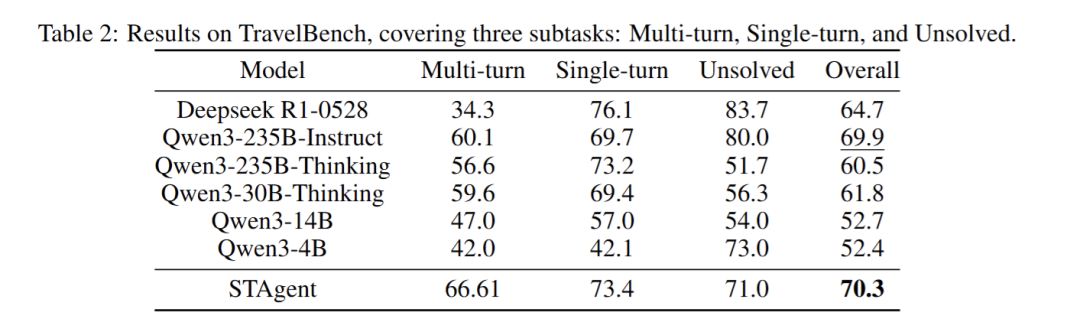
实验分为在线真实环境与离线静态基准两类场景。在线真实环境中,采用自采的1000条高质量查询数据(涵盖5种任务类型、7个难度等级),每个查询重复推理8次取平均值,由Gemini-3-flash作为裁判从总体、摘要、推理、展示四项维度评估胜率。结果显示,STAgent相较于Qwen3-30B-Thinking优势显著,总体胜率达77.5%,远超对比模型的21.6%,其中摘要维度胜率81.9%、展示维度胜率73.7%,体现出在真实场景下的优质交互能力。离线静态基准则采用TravelBench基准的Multi-turn(多轮)、Single-turn(单轮)、Unsolvable(无解)三子集,在温度0.7的设置下重复测试3次取平均,由GPT-4模拟用户、Gemini担任裁判打分。最终STAgent以70.33分的总成绩,超越DeepSeek-R1(64.7分)与Qwen3-235B-Thinking(60.5分),其中Multi-turn多轮对话子任务以66.61分斩获第一,验证了其在复杂时空任务中的核心竞争力。
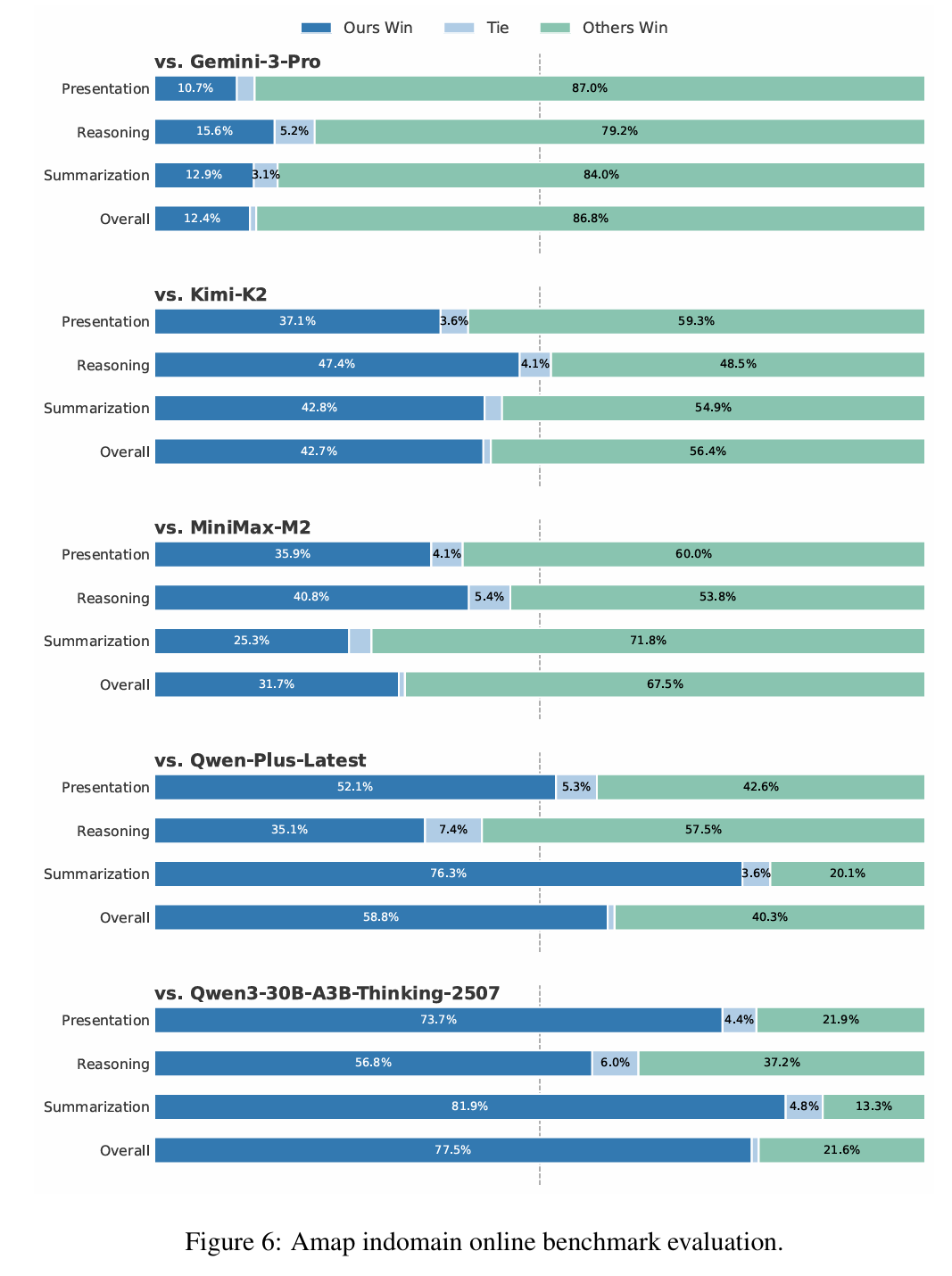
2. 通用能力实验:专用与通用双优验证
为验证模型“深耕专用不偏科”的特性,开展多维度通用能力评测,覆盖工具调用与智能体、数学推理、代码生成、综合与对齐四大维度。在工具调用与智能体领域,STAgent在ACEBench基准获76.78分,较初始化模型的58.5分显著提升;Bench基准达70.9分,较初始的47.7分大幅进步,BFCL v3基准则以71.9分与初始水平(72.4分)基本持平。数学推理方面,在AIME 2024基准得85.21分,较初始的91.4分小幅下降,而在AIME 2025基准以87.5分反超初始的85.0分。代码生成领域,LiveCodeBench v5+v6基准得65.6分,与初始的66.0分基本相当。综合与对齐维度表现亮眼,MMLU-Pro基准84.4分超越初始的80.9分,C-Eval基准达87.94分,ArenaHard-v2基准以79.2分远超初始的56.0分,IFEval基准87.06分与初始的88.9分基本持平,充分证明其在深耕时空专用领域的同时,通用能力未退化且部分维度显著提升。
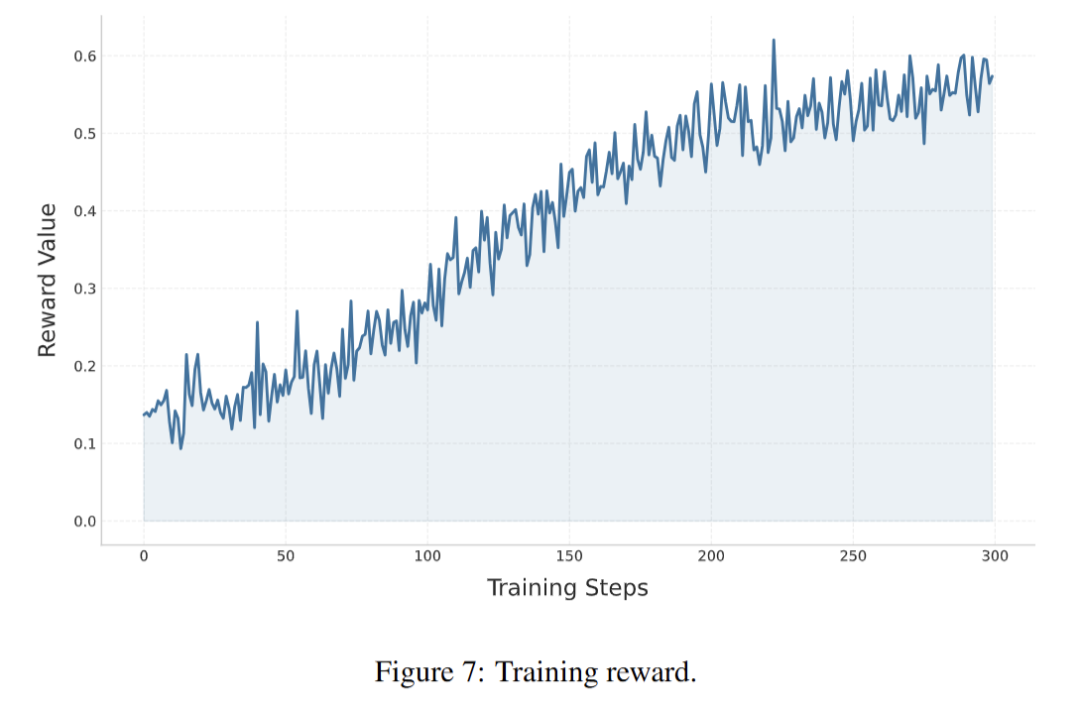
3. 训练动态分析:级联训练有效性验证
通过分析强化学习(RL)阶段的平均奖励曲线,验证级联训练范式的收敛性与有效性。实验结果显示,RL阶段进行150步训练后,模型平均奖励由初始的0.15提升至0.55,并趋于稳定,表明“Seed-SFT→动态能力感知SFT→RL”的级联训练范式能够持续优化模型策略,实现性能稳步提升,验证了该训练框架的合理性与高效性。
4. 案例研究:实际应用能力落地验证
附录部分通过四个典型案例进一步验证模型实际应用价值,包括海口路线沿途美食推荐、广州多景点一日可行性评估、重庆至海南跨省自驾攻略(含高速费、休息区规划)、新能源车1300km行程+充电规划。案例结果充分展示了STAgent在多步工具链编排、动态约束适配(如行程时间、充电需求)与幻觉检测机制上的优异表现,证明其能够有效应对真实世界中的复杂时空推理需求。
综上,实验结果综合验证:STAgent在真实与静态时空旅行场景中,性能显著优于同等规模及更大规模的对比模型;工具泛化能力突出,数学、代码、综合能力等通用基准未出现退化,部分维度实现提升;所提出的级联训练范式能够稳定收敛,有效突破模型性能天花板。

多步地理空间推理
多步地理空间推理

复杂多点行程评估
复杂多点行程评估

包含便利设施的长途旅行规划
包含便利设施的长途旅行规划

电动汽车长途路线及充电规划
电动汽车长途路线及充电规划
技术报告附录A中还包含工具架构和提示词模板
推荐阅读
FDABench:用于异构数据分析型查询的数据智能体基准测试
AI论文速读 | 大语言模型作为城市居民——利用LLM智能体框架生成人类移动轨迹
此公众号的文章皆系本人原创,辛苦码字不易!如需转载,引用请注明出处。如商用联系作者。
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号