ISSCC 2026 Nvidia报告:低延迟DWDM光互连技术



AI大模型的快速迭代与规模化部署,正推动数据中心向超高算力、超高带宽、超低延迟方向演进,传统电互连技术在带宽密度、功耗、传输延迟等方面的瓶颈日益凸显。高密度波分复用(DWDM)与硅光子集成技术的融合,成为突破400G+级互连需求的关键路径。本文基于ISSCC 2026上Nvidia相关技术分享,从AI数据中心的互连挑战出发,深入解析DWDM技术的技术原理、设计权衡、性能优势,以及光IO集成的发展趋势,展现低延迟光互连技术在支撑下一代AI数据中心中的核心价值。

一、AI数据中心的互连困境:算力、功耗与延迟的三重挑战
AI数据中心与传统云数据中心的架构差异,使其对互连技术提出了远超以往的要求,而电互连技术的固有特性,正成为算力释放的核心瓶颈,主要体现在三个维度。
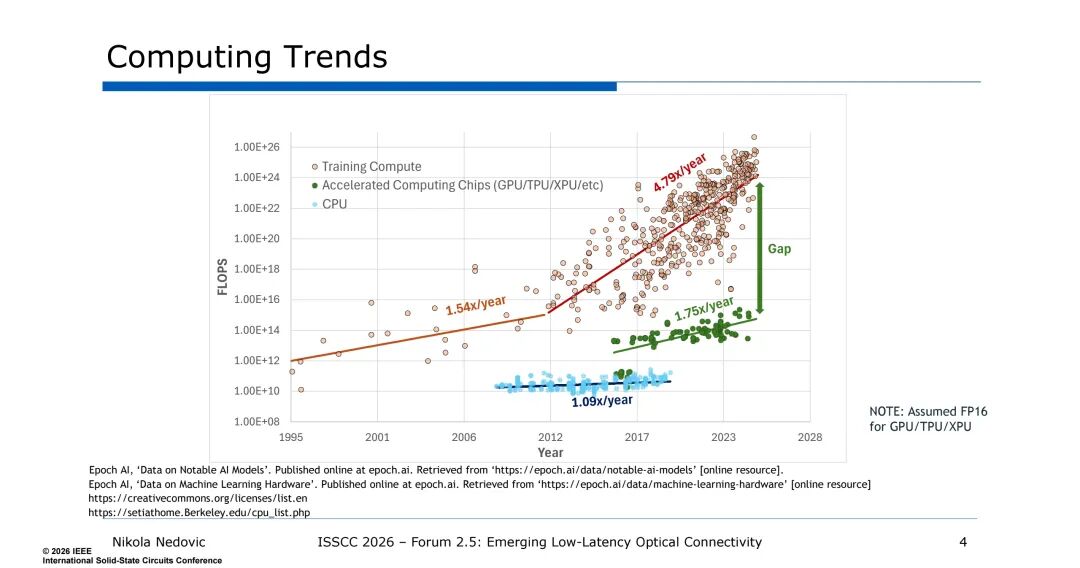
从算力需求来看,AI训练与推理的算力需求以每年4.79倍的速度增长,GPU/TPU等加速芯片的算力提升速度远超CPU,算力鸿沟的持续扩大,要求互连链路具备足够的带宽密度以匹配算力扩展,实现多芯片间的高效数据交互。而传统电互连的IO带宽虽以每2年翻倍的速度增长,但仍难以跟上AI算力的扩张节奏。
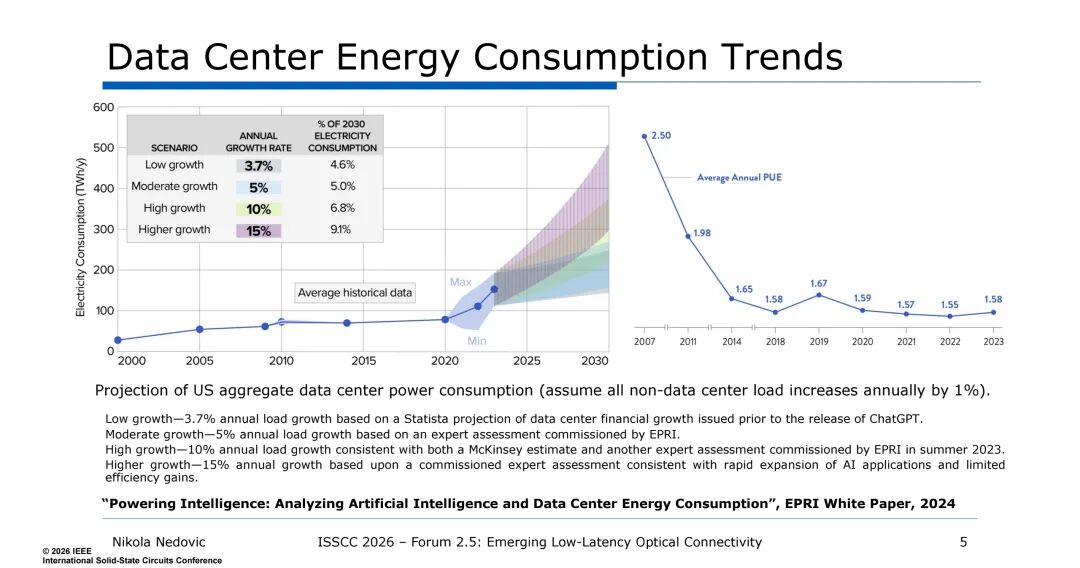
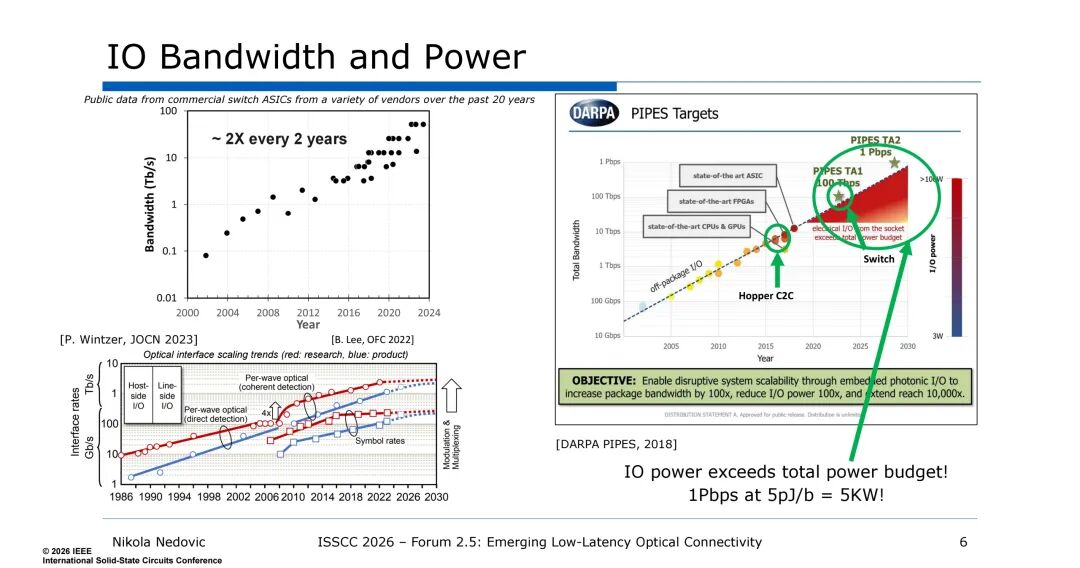
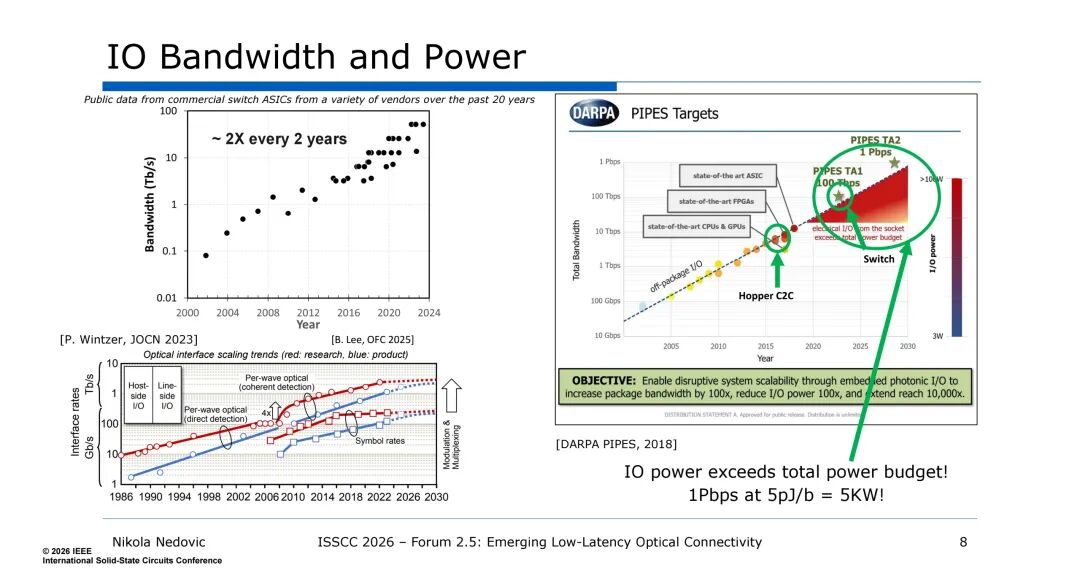
功耗方面,数据中心整体能耗呈持续增长趋势,高增长场景下年能耗增速可达15%,而IO功耗的攀升尤为显著——电互连的IO功耗已逐步超出芯片总功耗预算。同时,传统电互连的带宽提升依赖于单通道速率提升,这一方式会进一步推高电路功耗,形成“带宽-功耗”的恶性循环。

延迟层面,AI数据中心的训练与推理均为延迟敏感型工作负载。训练过程中的梯度聚合、权重更新需要多GPU保持严格的同步性,延迟和抖动会直接导致计算资源利用率下降;推理过程的解码阶段为串行执行,单条IO链路的延迟会因GPU-交换机跳数被成倍放大,成为大模型实时推理的核心瓶颈。而传统电互连的PHY层、FEC、交换机端口转发等环节累计产生数百纳秒的延迟,已无法满足AI工作负载的低延迟需求。
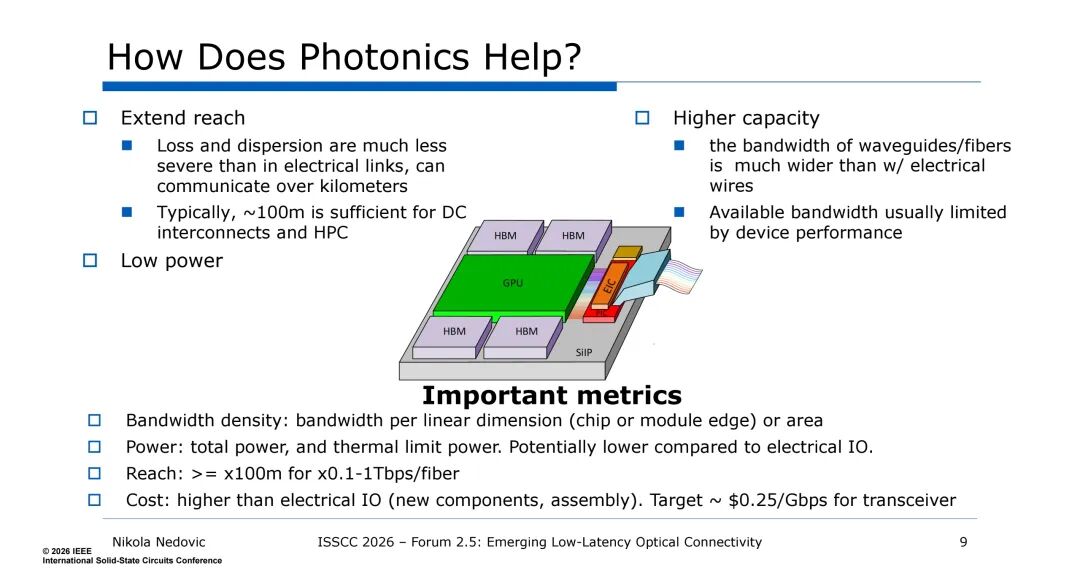
相较于电互连,光互连凭借传输损耗低、色散小、带宽资源丰富的特性,可实现千米级传输,且在带宽密度、功耗控制上具备先天优势,成为解决AI数据中心互连困境的核心技术方向。其核心优势体现在四方面:一是传输距离可轻松覆盖数据中心与高性能计算场景的100m需求;二是波导/光纤的可用带宽远大于电线,带宽上限仅受器件性能限制;三是功耗显著低于电IO,且具备更高的带宽密度;四是通过技术优化可实现低延迟传输,匹配AI工作负载的需求,当前光收发器的成本目标已降至0.25美元/Gbps,为规模化应用奠定基础。
二、速率缩放的技术约束:光互连单通道提速的固有局限
光互连的带宽提升若采用与电互连相同的“单通道速率缩放”思路,将面临一系列技术约束,这也是DWDM技术未来成为重要方向的核心原因。
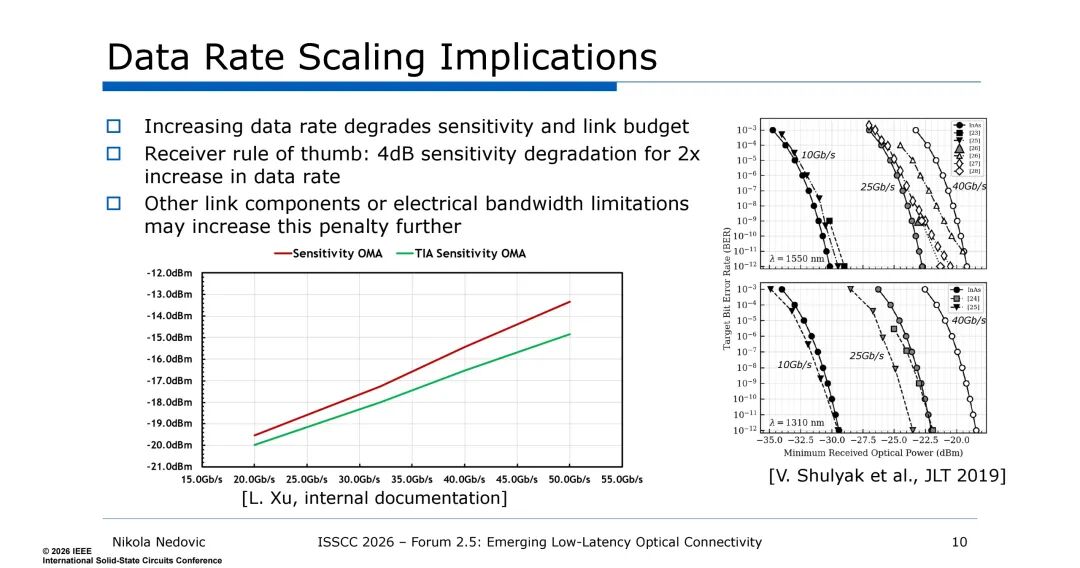
数据速率的提升会直接导致接收机灵敏度和链路预算的劣化,这是光互连的固有规律——接收机灵敏度每提升2倍数据速率会下降4dB,而链路中的其他组件或电带宽限制会进一步放大这一损耗。在低数据速率下(约为器件特征频率fT/4以下),采用NRZ调制格式即可实现1e-12的低原始误码率(BER),电路设计高效且无需复杂均衡;而当数据速率接近或超过器件fT时,需采用PAM4、QPSK等复杂调制格式,接收机灵敏度会降至-10dBm以上,且原始BER大幅升高(约1e-4),必须依赖前向纠错(FEC)才能满足系统误码要求,而FEC的引入会显著增加传输延迟。
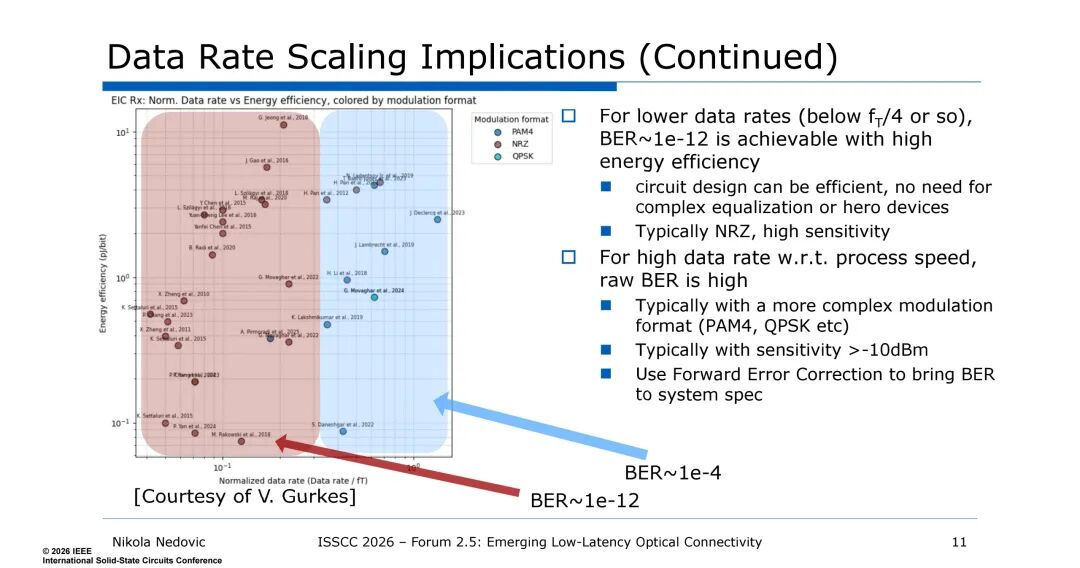
同时,单通道速率提升会推高电路设计的复杂度,要求配备高性能的DSP、均衡器、数模/模数转换器件,这些组件不仅会增加功耗,还会进一步引入延迟,与AI数据中心的低延迟需求相悖。因此,光互连的带宽提升亟需跳出“单通道提速”的思路,转向多维度的吞吐量缩放,而波长域的复用技术成为最优选择。
三、AI数据中心的架构和时延

数据中心架构核心分为传统云数据中心和AI专用数据中心两类,且AI数据中心对低延迟光互连提出了特殊需求,核心内容如下:
1. 传统云数据中心
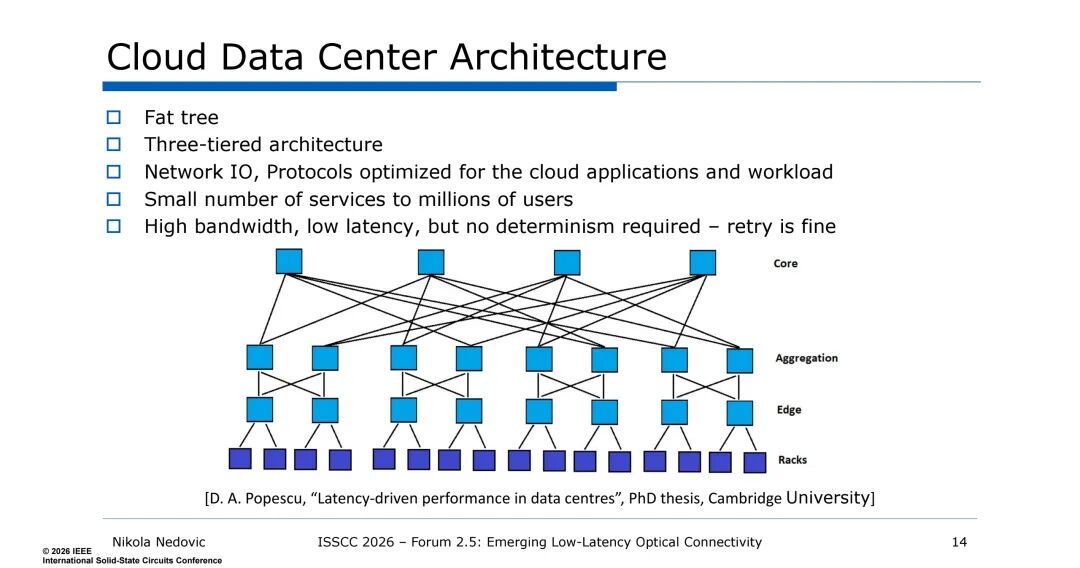
- 采用三层胖树架构(核心-汇聚-边缘),网络IO和协议针对云应用优化,面向“少量服务对接数百万用户”的场景。
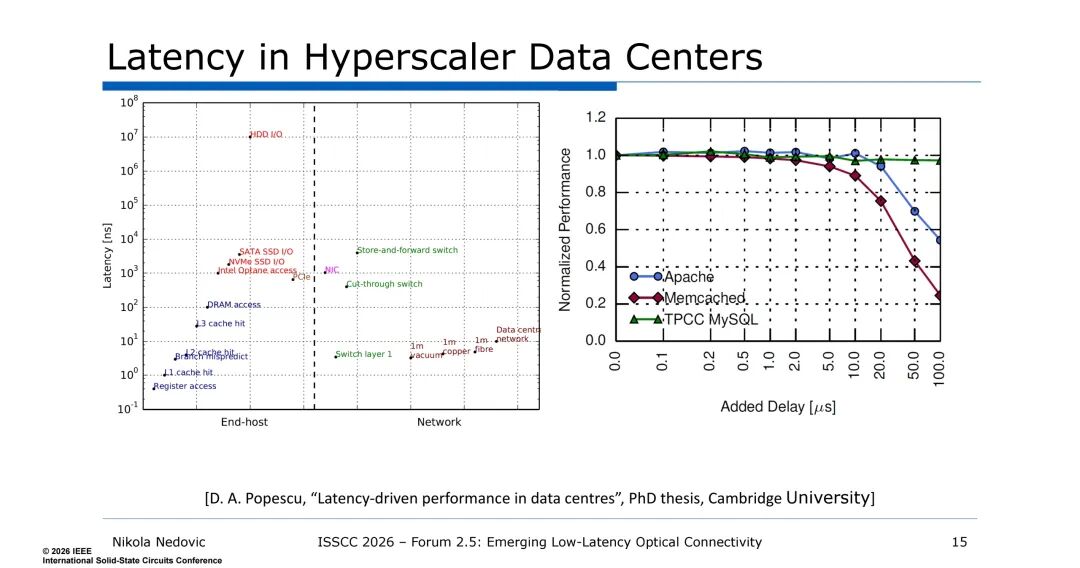
- 需求为高带宽、低延迟,无需确定性,传输出错可重试,单中心约100K服务器,光模块功耗2.3 MW。
2. AI数据中心(AI Factory)
- 架构分前端+后端:前端复用传统云数据中心架构(CPU计算、存储、广域网接入);后端为AI训练/推理核心,由GPU/xPU组成,单中心可达512K GPU,光模块功耗达40 MW。
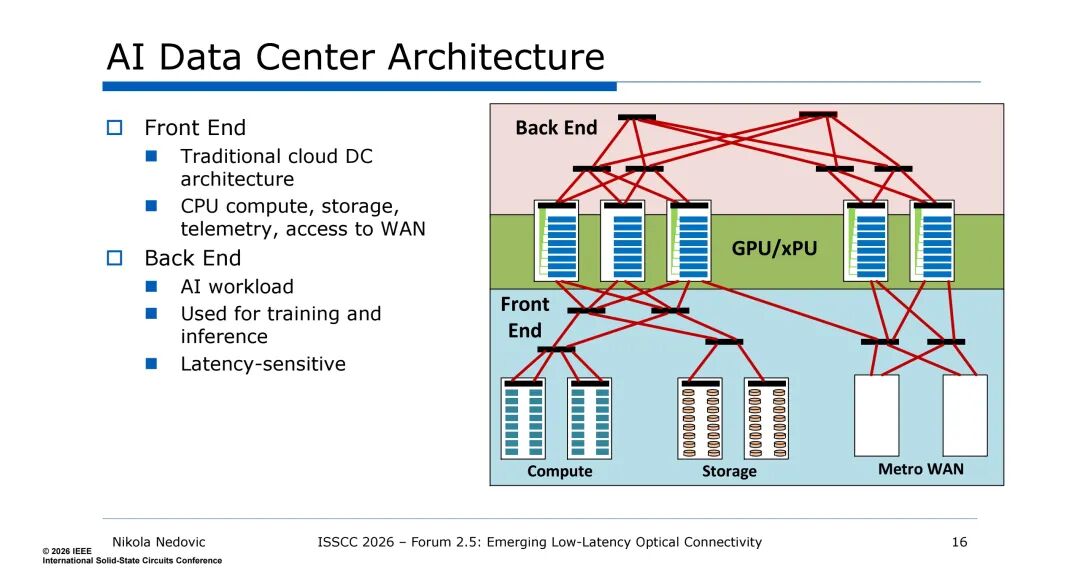
- 后端又分两个域:纵向扩展域(Scale up)为紧耦合GPU/xPU集群,采用NVLink/UALink等私有互连,物理紧邻、低延迟要求极高;横向扩展域(Scale out)采用InfiniBand/Ethernet等传统标准IO,为分组交换模式。
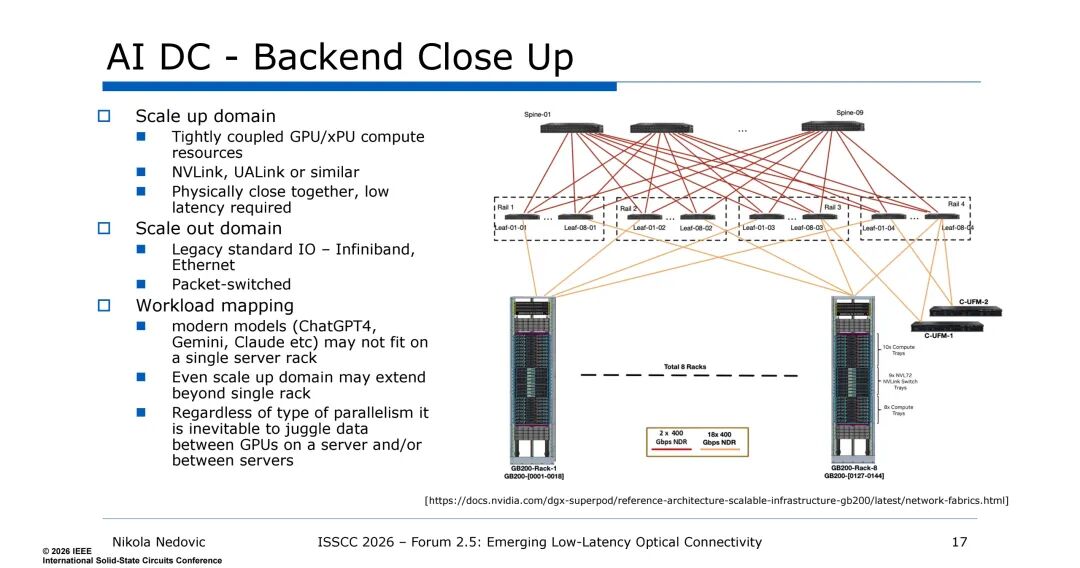
- 现代大模型(ChatGPT4、Gemini等)无法单机架部署,即使纵向扩展域也会跨机架,GPU间的数据交互成为必然需求。
3. AI数据中心的低延迟核心诉求
- 训练场景:包含前向传播、反向传播、梯度聚合等阶段,需保持同步避免计算停滞,延迟和抖动会导致计算资源利用率下降。

- 推理场景:预填充阶段为并行计算受限,解码阶段为串行(逐token生成)、存储/通信受限,跨机架部署时IO延迟会被放大,成为性能瓶颈,也因此成为延迟优化的核心驱动。
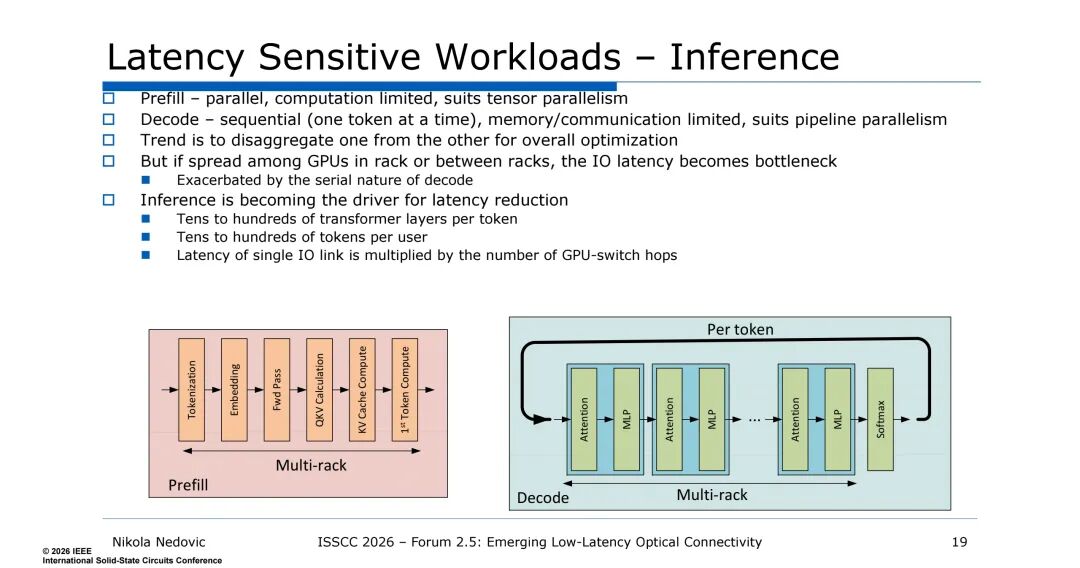
- 现有Scale up场景的延迟拆解:PHY(SerDes/DSP/AFE~50ns+传输时延~5ns/m)、FEC~50-100ns、交换机端口间~100-200ns为主要组成,需从架构和硬件层多维度优化。

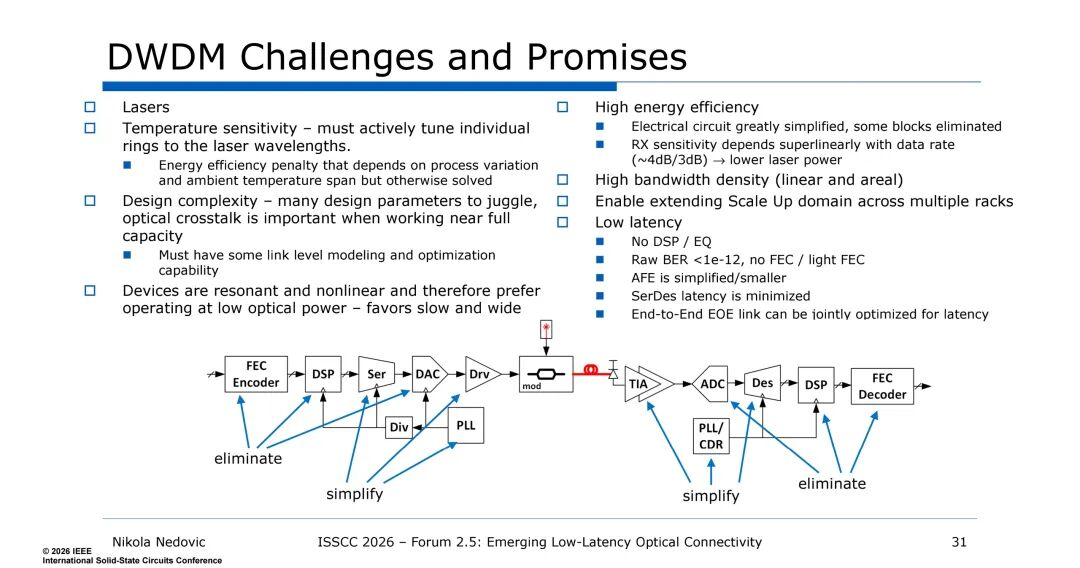
为最小化延迟,可从架构、IO和硬件集成三个层面入手: ① 架构层面 - 限制数据中心层级深度,扩大交换机端口数(Scale switch radix)。 - 优化机架内IO,如NVIDIA GB200将整个机架(72个GPU,电连接)视为一个“大型GPU”。 ② 组件层面 - 开发低延迟FEC码,减少编码/解码开销。 - 采用固有的低延迟IO链路,如WDM(波分复用),在不提高数据速率的情况下扩展吞吐量。 ③ 硬件集成层面 - 推动电光(EO)集成,向CPO(共封装光学)或中介层上光学方向发展。 - 最小化核心与EO引擎间的电IO延迟,优化EO接口寄生参数,简化AFE设计,提高接收灵敏度。

四、DWDM技术:光互连吞吐量缩放的核心路径
密集波分复用(DWDM)通过在单根光纤中复用多个波长的光信号实现吞吐量提升,将电域的高频率复杂度转移至光域,成为光互连实现400G+带宽且兼顾低延迟、低功耗的核心技术,其技术原理、核心器件、设计权衡与性能优势构成了技术落地的关键。
1. 光互连的吞吐量缩放维度:波长域复用的独特价值
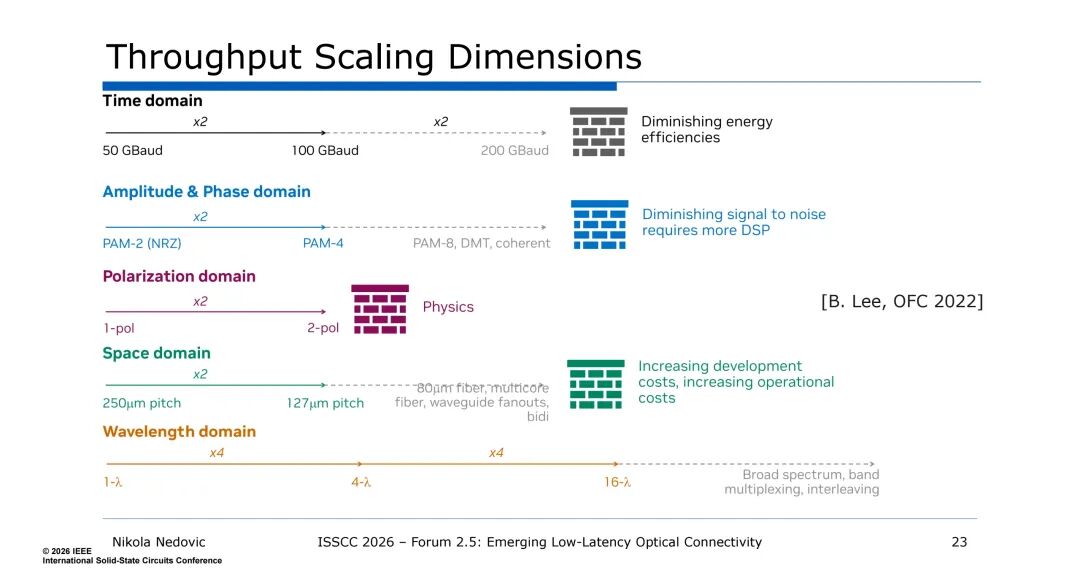
光互连的吞吐量缩放可从时间、幅相、偏振、空间、波长五个维度实现,各维度均存在相应的技术局限:时间域提速会导致能效下降,幅相域调制需要复杂DSP支撑,偏振域仅能实现2倍缩放,空间域复用会推高研发与运营成本。而波长域复用可实现4倍及以上的吞吐量提升,借助宽光谱、波段复用、交错复用等技术,还可进一步提升复用倍数,且能在不提升单通道速率的前提下实现带宽扩展,从根源上规避了单通道提速带来的灵敏度劣化、电路复杂度提升、延迟增加等问题。
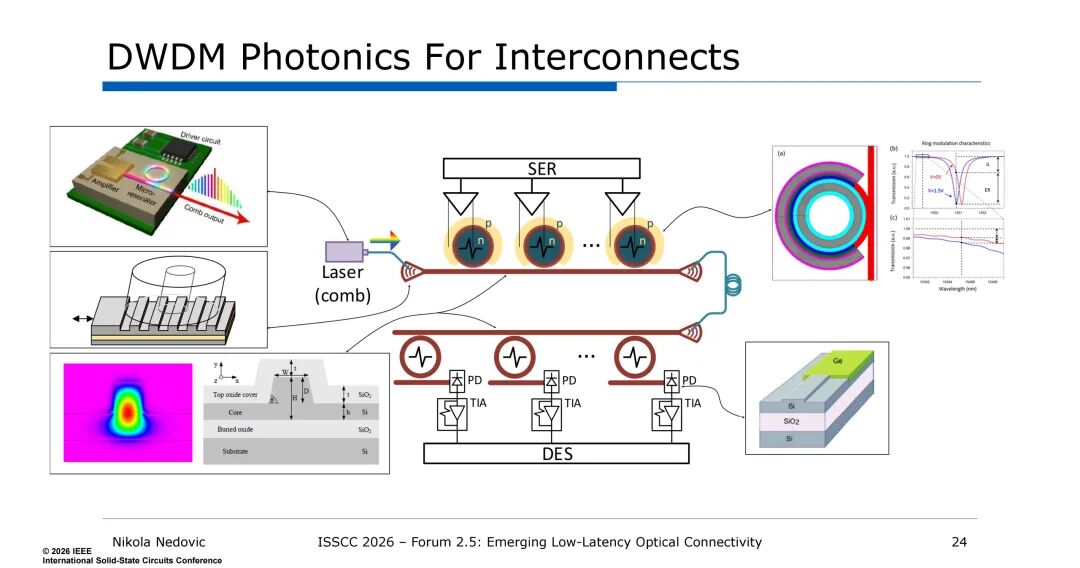
2. DWDM的核心器件与工作原理
DWDM的核心支撑器件为硅光子基的微环谐振器,这也是DWDM技术的关键,其具备高Q值谐振特性,波长选择性强,可同时实现调制、复用/解复用、滤波功能,且器件尺寸小,可由CMOS电路驱动,功耗极低。环形谐振器的核心结构包含横向PN结、垂直L型PN结、叉指型PN结等类型,通过谐振效应实现光信号的选通与调制,单个器件即可完成多波长信号的处理,大幅提升了集成度。

DWDM的光链路核心由激光源、环形谐振器调制器/滤波器、光电探测器(PD)、跨阻放大器(TIA)等组件构成,激光源可采用DFB激光器阵列或微环激光器(MLL),通过材料非线性从单泵浦源生成多个波长的光信号,单通道光功率需求约为0dBm,各波长信号经环形谐振器调制后耦合至单根光纤,接收端再通过环形谐振器解复用,由PD完成光电转换后经TIA放大输出。

3. DWDM的核心设计挑战与权衡
DWDM技术的设计存在多维度的约束与权衡,设计空间广阔,需通过精准的链路建模实现参数优化。
一是微环谐振器的固有局限,其对工艺和温度高度敏感,需集成加热器与热控制环路进行主动热稳定,且高功率下会出现自热与非线性效应,同时谐振效应导致光调制幅度(OMA)受限,通常需要高于核心电源的电压摆幅才能实现可接受的光幅度。
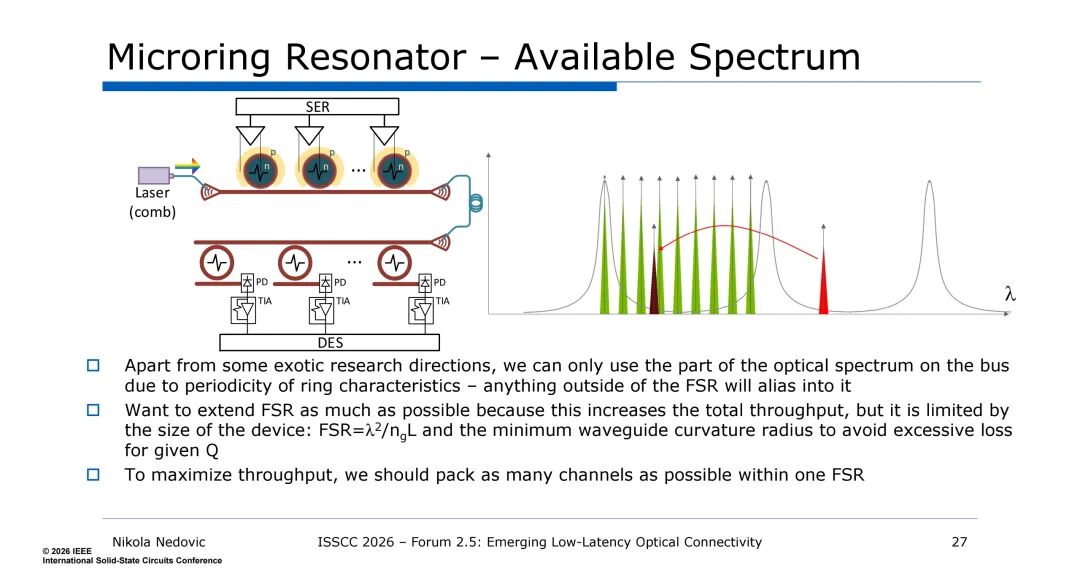
二是自由光谱范围(FSR)的限制,环形谐振器的FSR由公式FSR=λ²/ngL决定,受器件尺寸与波导曲率半径约束,FSR的大小直接决定了单根光纤可复用的波长通道数,超出FSR的光谱会产生混叠,因此需在FSR与器件损耗、集成度之间做权衡,尽可能在单个FSR内封装更多通道以提升吞吐量。
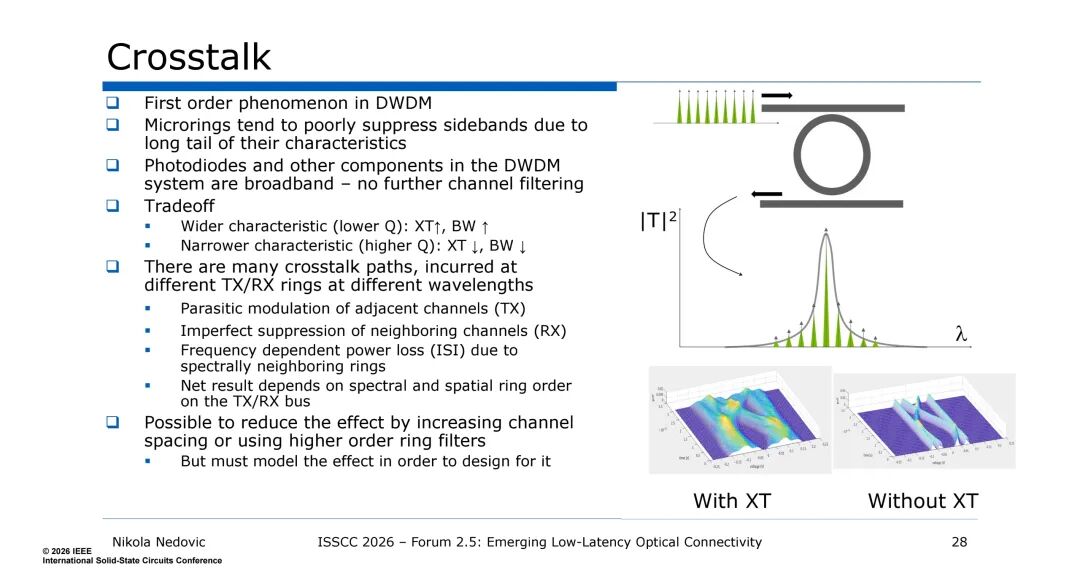
三是串扰问题,串扰是DWDM的一阶效应,微环谐振器的特性尾部长,对边带的抑制能力弱,而光电探测器为宽带器件,无法实现额外的通道滤波。串扰与环形谐振器的Q值相关:低Q值对应宽特性,串扰增加但带宽提升;高Q值对应窄特性,串扰降低但带宽收缩。同时,串扰存在多种路径,包括发射端相邻通道的寄生调制、接收端对邻道的不完全抑制、光谱邻道导致的频率相关功率损耗,需通过增加通道间距或采用高阶环形滤波器降低串扰,且需结合TX/RX总线上的光谱与空间环序进行建模。
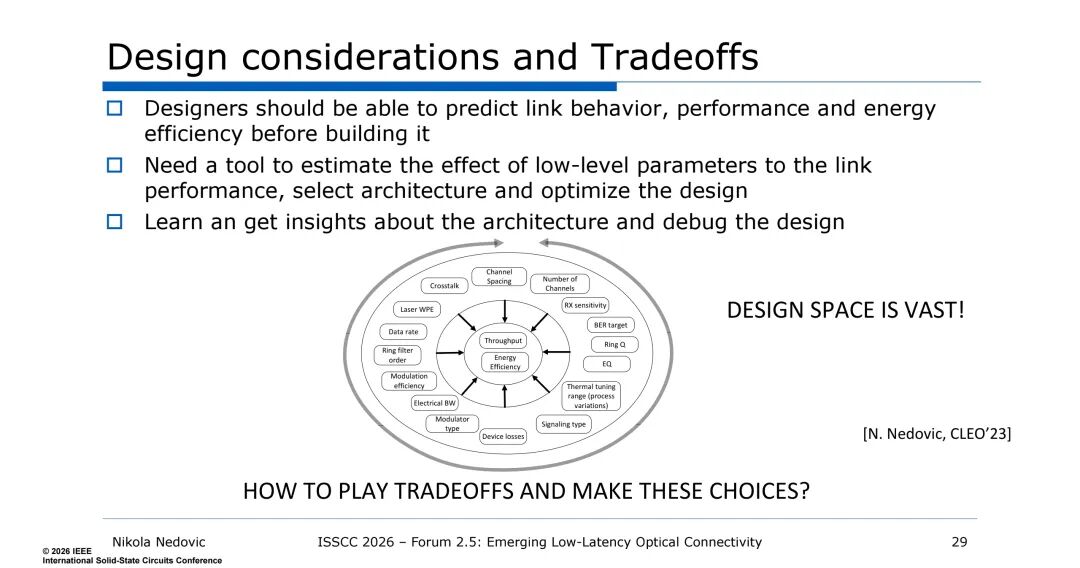
四是多参数的协同权衡,DWDM的设计需兼顾通道间距、通道数、串扰、接收机灵敏度、激光器壁插效率(WPE)、BER目标、数据速率、环形谐振器Q值、滤波器阶数、能效等多个参数,各参数相互耦合,例如接收机灵敏度与数据速率呈超线性关系,激光器功率与调制效率、器件损耗密切相关,需通过系统化的链路建模工具,实现低层级器件与电路参数对链路性能的精准预估。
4. DWDM的链路建模与性能验证
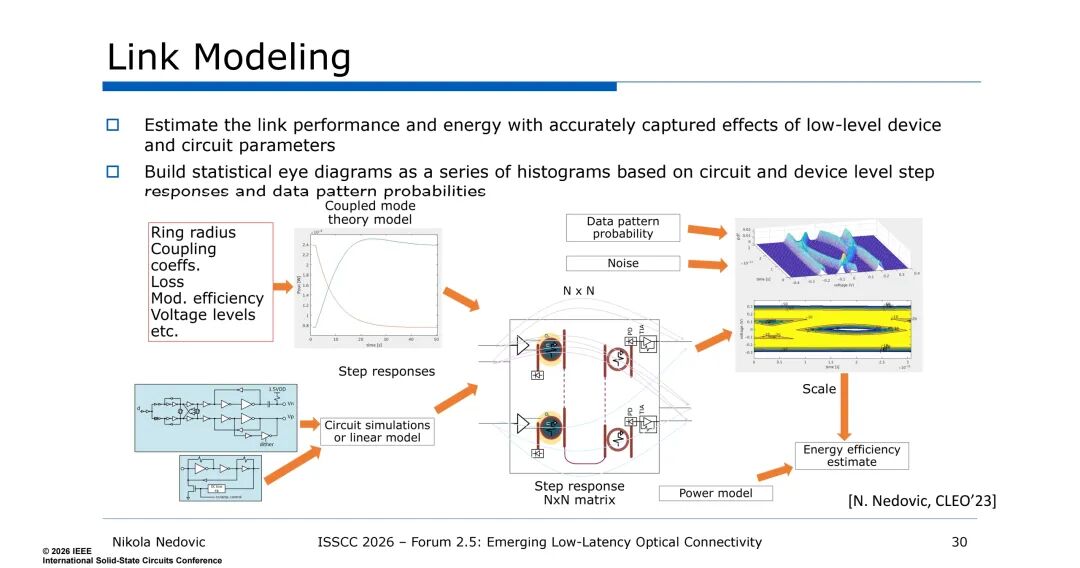
为解决多参数权衡的问题,DWDM链路需建立精准的建模体系,核心是基于电路与器件级的阶跃响应、数据模式概率,构建统计眼图,实现链路性能与能效的量化评估。建模过程需融合耦合模理论、器件参数(环半径、耦合系数、调制效率)、电路仿真结果(阶跃响应、电压电平)、噪声模型、数据模式概率等多维度信息,生成N×N阶跃响应矩阵与功率模型,最终实现对链路BER、能效、吞吐量的精准预测,为架构选择与设计优化提供依据。
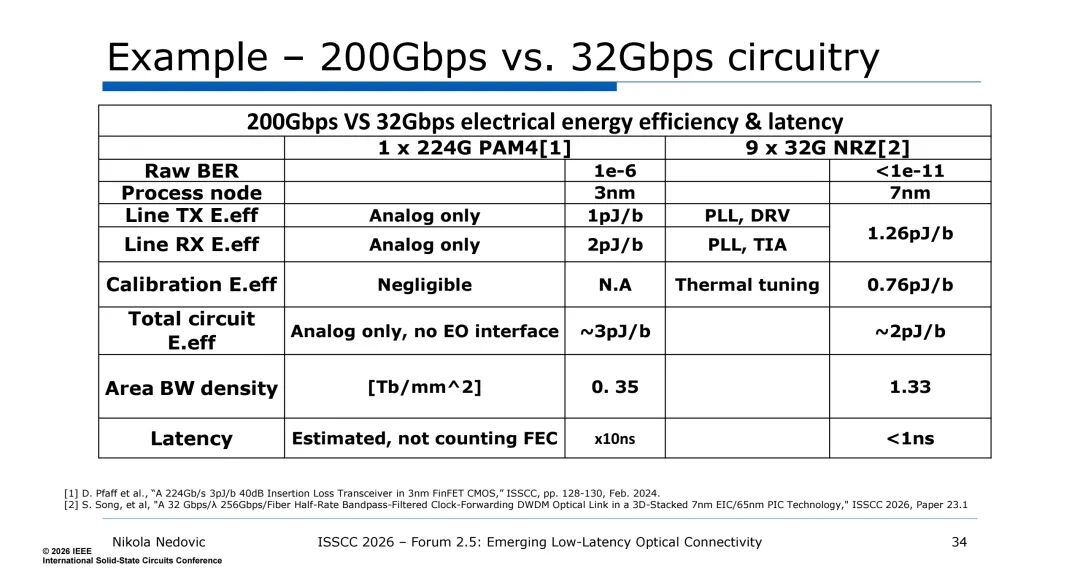
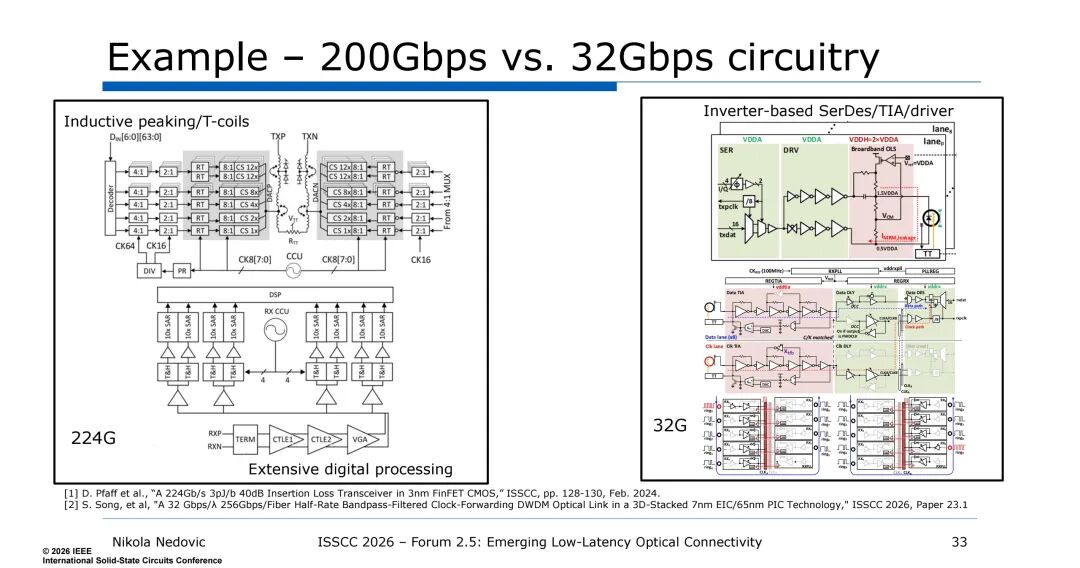
实际性能验证中,32Gbps/λ的DWDM光链路展现出显著优势:基于7nm电集成电路(EIC)与65nm光子集成电路(PIC)的3D堆叠技术,实现了9×32G NRZ的传输,原始BER低于1e-11,无需复杂FEC;电路总能效约2pJ/b,面积带宽密度达1.33Tb/mm²,延迟低于1ns,远优于3nm工艺下224G PAM4的电互连链路(延迟约10ns,面积带宽密度0.35Tb/mm²)。
ISSCC 2026:Nvidia展示7nm EIC+65nm PIC混合键合的256Gb/s DWDM 3D堆叠CPO光互连芯片
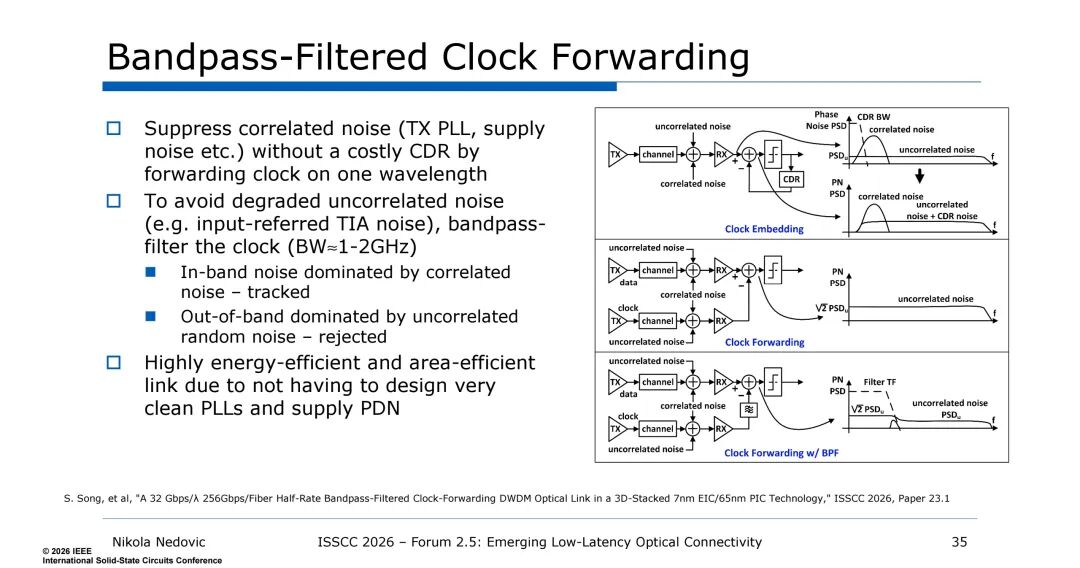
同时,带通滤波时钟转发技术的引入,通过在一个波长上转发时钟,抑制了TX PLL、电源噪声等相关噪声,且带通滤波(带宽1-2GHz)可拒绝输入参考TIA噪声等非相关噪声,无需设计高成本的时钟数据恢复(CDR)电路,大幅提升了链路的能效与集成度,该技术实现了0.46UI@1e-11的浴缸曲线性能,接收机数据OMA灵敏度可达-18.9dBm,为低延迟传输提供了保障。
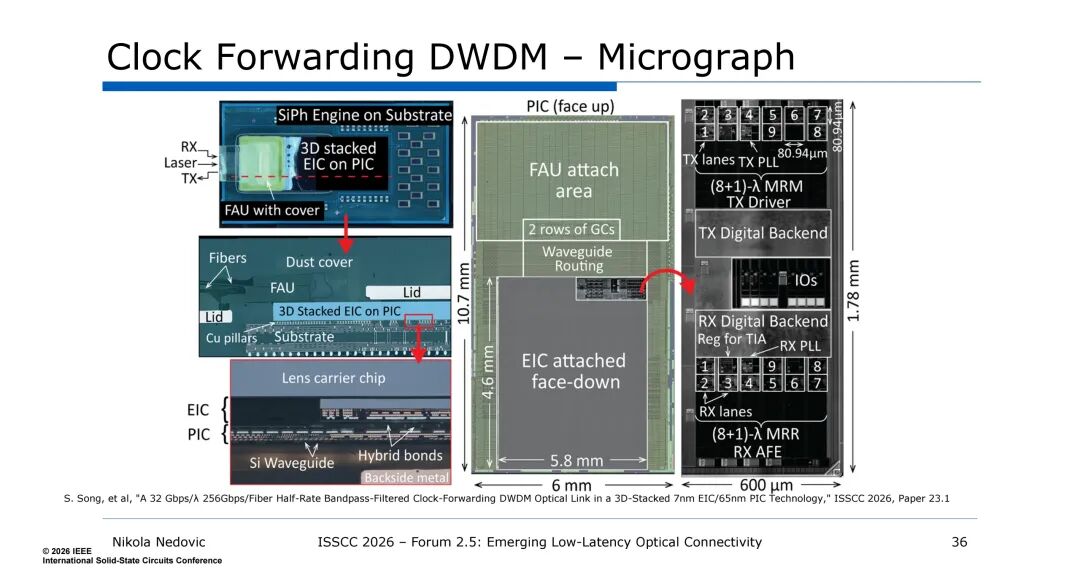
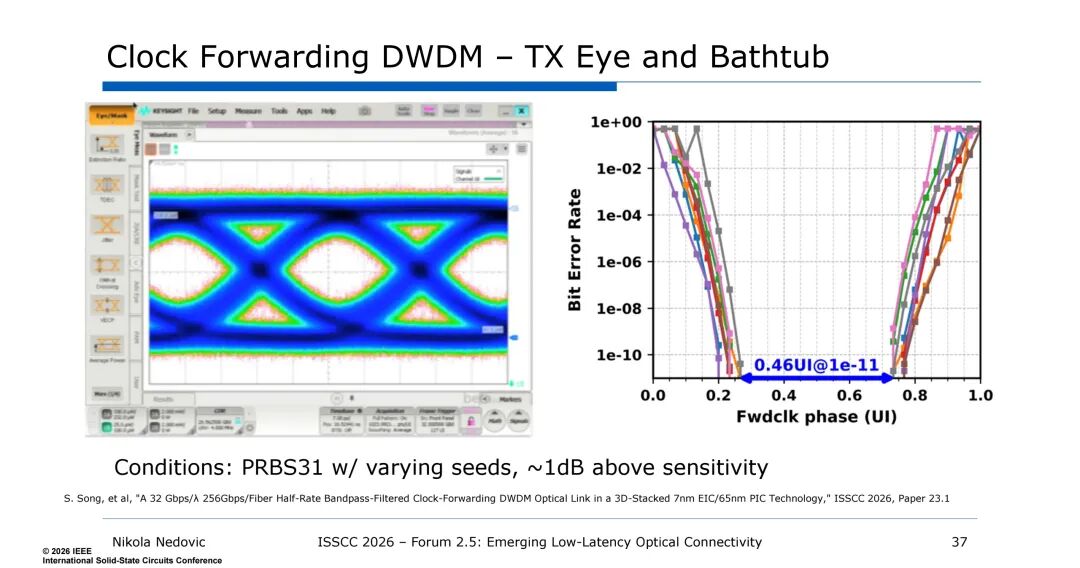
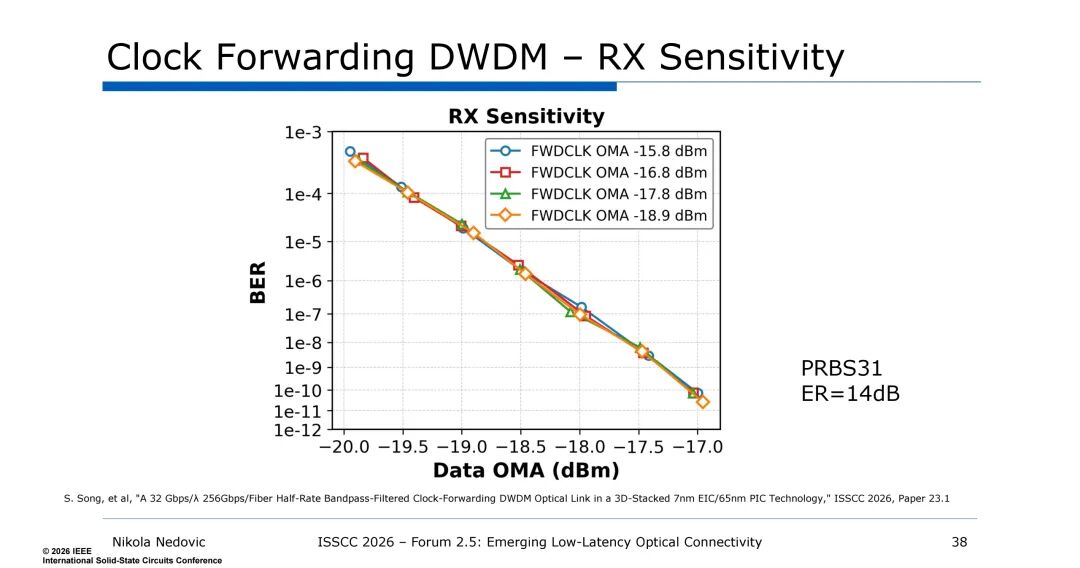
5. DWDM的能效与延迟优势:慢而宽的设计思路
DWDM的核心设计思路为“慢而宽”,即通过增加波长通道数实现带宽扩展,而非提升单通道速率,这一思路使其在能效与延迟上具备显著优势。

能效方面,对比8λ×25Gbps与2λ×100Gbps的光链路,前者总能效为3.4pJ/b,优于后者的4.7pJ/b。虽DWDM因激光器合束器存在一定的激光功率损耗,但单通道低速率带来的接收机灵敏度超线性提升,可有效降低激光器功率需求,若采用MLL或有源合束器,激光能效将进一步优化。同时,“慢而宽”的设计简化了电电路,消除了DSP、DAC/ADC等高能耗组件,仅保留简单的SerDes、TIA与驱动电路,电路功耗大幅降低。
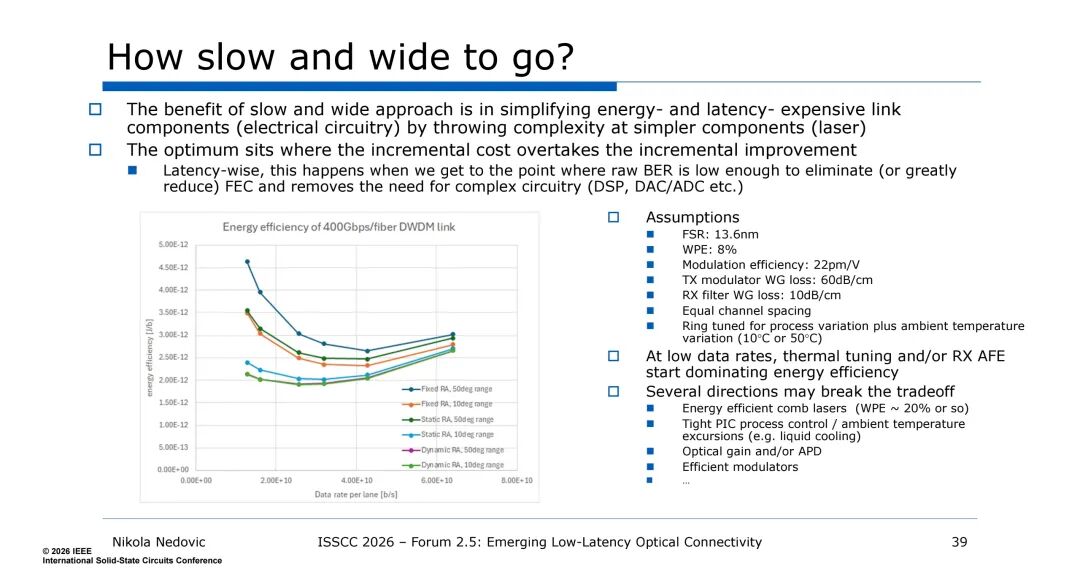
延迟方面,DWDM因单通道速率低,可实现1e-12以下的低原始BER,无需或仅需轻量级FEC,消除了FEC带来的50-100ns延迟;同时,电电路的简化使PHY层延迟大幅降低,无需复杂的均衡与ML解码,端到端的电-光-电(EOE)链路可进行联合延迟优化,仅存在不可避免的光速传播延迟(约5ns/m)。
此外,DWDM的能效并非随单通道速率降低持续提升,当速率过低时,热调谐与接收端模拟前端(AFE)的功耗会成为主导,因此存在最优的单通道速率区间,其临界点为原始BER低至可消除FEC且无需复杂电路的速率水平。针对400Gbps/光纤的DWDM链路,假设FSR为13.6nm、WPE为8%时,需结合热调谐范围、激光器技术、工艺控制水平进行速率优化,而高能效梳状激光器、液冷散热、APD探测器、高效调制器等技术,将进一步突破这一权衡约束。
五、光IO的集成趋势:从CPO到中介层集成,突破带宽瓶颈
AI数据中心对超高带宽密度的需求,推动光IO从传统的板级集成向更高级别的异构集成演进,共封装光学(CPO)成为当前主流,而中介层上的光集成正成为下一代技术前沿,核心目标是消除ASIC与光引擎之间的带宽瓶颈,实现更高密度的互连。
1. 集成的核心挑战

光IO高级别集成面临三大核心挑战:一是功耗与散热,光模块的功耗已达千瓦级,需采用垂直供电、集成稳压器、液冷、微通道散热等技术,同时需保证封装组装的光学耦合透明度;二是良率与测试,需在量产吞吐量下保证组装良率,且建立完善的光器件测试体系;三是温度控制,光器件对温度高度敏感,而封装内存在未知的热干扰源,需实现光芯片的精准温度控制,并兼顾封装冷却、器件发热与链路能效的相互作用。
2. 从CPO到中介层集成的技术演进
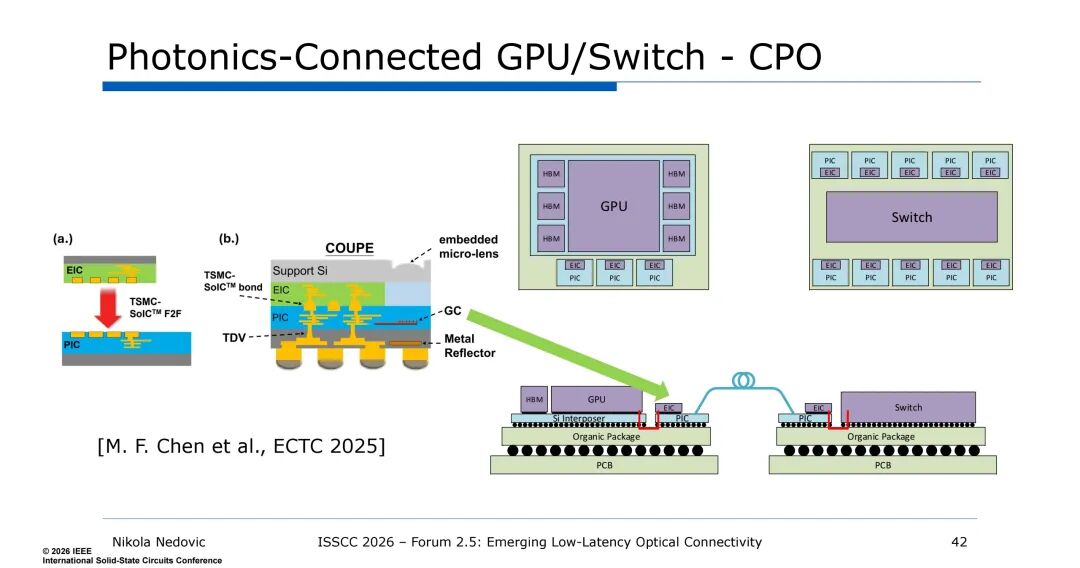
共封装光学(CPO)将光引擎与GPU/交换机芯片封装在同一有机基板上,通过硅中介层、键合技术实现光引擎与ASIC的紧密集成,消除了板级电互连的带宽损耗,当前已实现基于SoIC面对面键合、COUPE嵌入式微透镜的CPO架构,光引擎与GPU/交换机的集成度大幅提升。
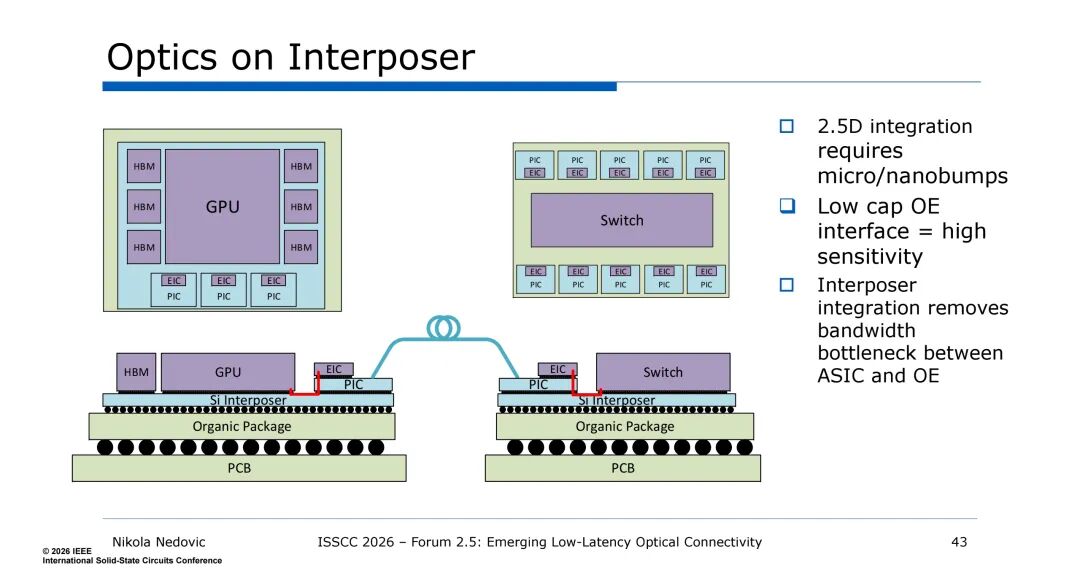
而中介层上的光集成是CPO技术的进一步升级,将光引擎直接集成在硅中介层上,通过2.5D集成技术实现微/纳米凸点互连,电-光(OE)接口的电容大幅降低,接收机灵敏度显著提升,从根本上消除了ASIC与光引擎之间的带宽瓶颈。该架构下,PIC与EIC通过3D堆叠集成在硅中介层,与GPU/交换机芯片、高带宽存储器(HBM)形成一体化封装,单中介层可实现多光引擎、多芯片的互连,带宽密度进一步提升。
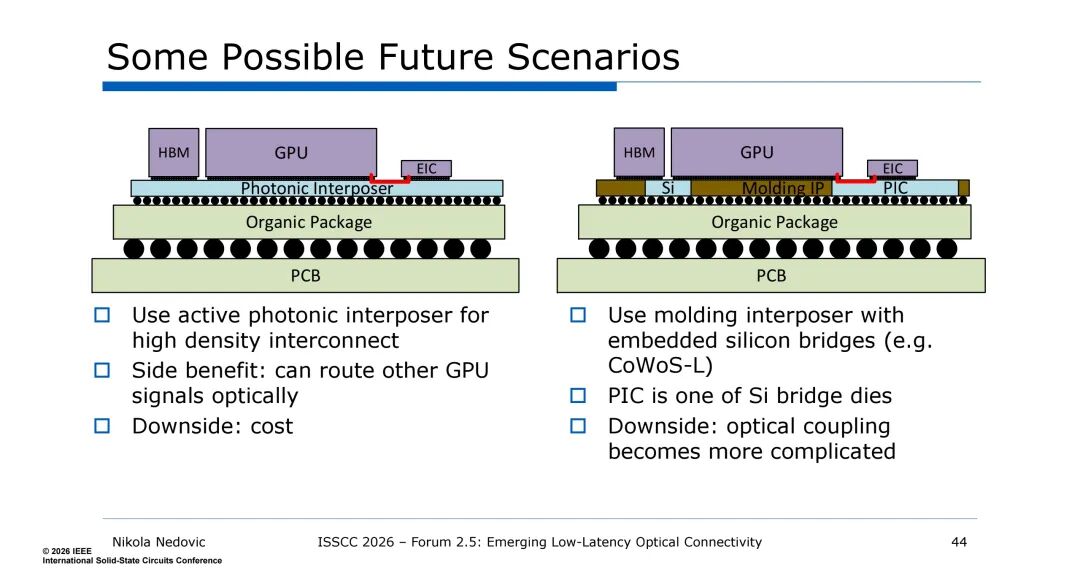
未来,光互连的集成还将向有源光子中介层、模塑中介层演进:有源光子中介层将光子器件直接制作在中介层上,实现超高密度互连,还可通过光学路由实现GPU信号的直接交互;模塑中介层则将硅桥与PIC集成,借助CoWoS-L等技术提升集成度,虽面临光学耦合复杂度提升、成本增加的问题,但为超大规模光互连提供了新路径。
3. 光-电IO的匹配设计
光互连的性能发挥,需配套匹配的“轻量级”高带宽电IO,实现端到端的性能优化,核心思路是将主机到主机的互连视为“电链路-光链路-电链路”的整体,避免冗余的链路开销。
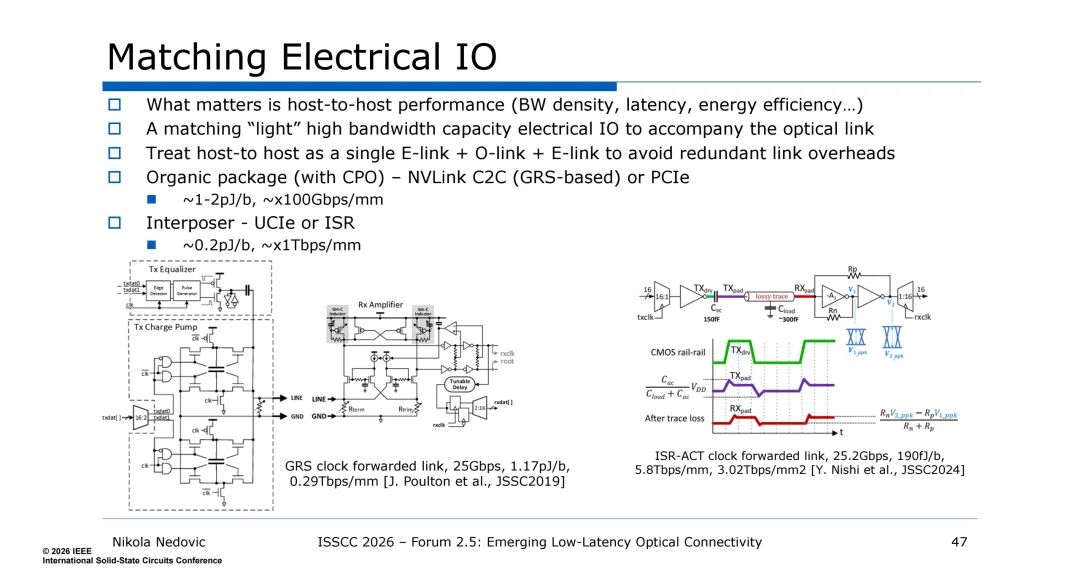
针对不同的集成级别,需采用不同的电IO技术:CPO基于有机封装,可采用NVLink片间互连(GRS)或PCIe,能效约1-2pJ/b,带宽密度约100Gbps/mm;中介层集成则采用UCIe或ISR技术,能效可低至0.2pJ/b,带宽密度达1Tbps/mm以上,其中ISR时钟转发链路的能效可达190fJ/b,带宽密度5.8Tbps/mm,为光互连提供了高效的电域配套。
六、结论:DWDM与硅光子集成,定义下一代AI数据中心互连
AI数据中心带来的海量IO吞吐量需求,正在重构数据中心的互连技术体系,传统电互连技术已无法匹配算力、带宽、延迟、功耗的综合需求,而以DWDM为核心的硅光子光互连技术,成为支撑400G+级互连的核心基石。

DWDM技术将电域的高频率复杂度完全转移至光域,通过波长域复用实现吞吐量的线性扩展,在不提升单通道速率的前提下,兼顾了高带宽密度、高能效与低延迟;其依托硅光子技术,可充分利用硅基制造的基础设施,控制成本,且谐振结构的应用保证了器件的小尺寸与高集成度,为规模化集成奠定基础。同时,光IO从CPO向中介层集成的演进,进一步消除了芯片与光引擎之间的带宽瓶颈,实现了光-电器件的深度异构集成,匹配了AI数据中心的超高密度互连需求。
未来,随着高能效梳状激光器、高效调制器、液冷散热、先进键合技术的持续突破,DWDM与硅光子集成技术将进一步优化能效与延迟性能,推动AI数据中心的“扩域扩展”从单机架延伸至多机架,实现算力与互连的协同扩展。光互连技术不仅是解决当前AI数据中心互连困境的关键,更将定义下一代数据中心的架构体系,成为人工智能、高性能计算等领域算力释放的核心支撑。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号