Nat. Comput. Sci. | TANGO: 面向可合成性约束的分子生成直接优化框架

Nat. Comput. Sci. | TANGO: 面向可合成性约束的分子生成直接优化框架

DrugIntel
发布于 2026-03-06 11:08:00
发布于 2026-03-06 11:08:00
DRUGONE
在生成式分子设计中,“可合成性约束”仍然是一个尚未被充分解决的关键问题,尤其是在需要同时满足多参数优化目标、保证分子可合成,并且强制在合成路径中包含特定构建块的场景下。这一问题对于分子再利用、绿色化学和合成效率具有重要现实意义。研究人员提出了一种名为 TANGO(Tanimoto Group Overlap)的奖励函数,通过引入化学归纳偏置,将原本的二元可合成性判定转化为连续可学习的优化信号,并结合强化学习直接优化“受限可合成性”。该框架具有通用性,可统一处理起始原料约束、中间体约束与发散合成约束。结果表明,在复杂的合成约束场景下,通过奖励驱动的通用生成模型能够有效学习并实现目标优化。

随着生成式分子设计在药物研发中的快速发展,如何在分子生成阶段就考虑真实可行的合成路径,成为推动闭环自动化发现的重要方向。传统方法往往依赖启发式合成评分或将逆合成模型作为后处理过滤工具,但这些策略难以在生成过程中直接纳入“特定构建块必须出现在合成路径中”的硬性约束。
现实应用中,研究人员常常希望利用特定原料或副产物进行分子再利用,或围绕某些中间体构建发散型合成网络。然而,现有生成模型通常无法在生成阶段强制特定构建块参与合成路径。为此,研究人员提出一种生成式框架,使模型在优化药物样性质与对接评分等多参数目标的同时,学习满足构建块约束的合成可行性。
方法概述
研究人员将“受限可合成性”形式化为一个连续奖励问题。核心思想是:对于由逆合成模型预测得到的合成路径,计算路径中分子节点与被强制构建块集合之间的结构相似性,从而判断模型是否“接近”满足构建块约束。
TANGO 奖励函数结合了 Tanimoto 指纹相似度与模糊子结构匹配(FMS),将原本仅能给出 0/1 判定的可合成性信号转化为连续值。通过这种奖励塑形机制,生成模型可以逐步学习如何在合成路径中引入目标构建块。该奖励取所有合成图节点中的最大值,并通过强化学习优化。
生成模型基于 Saturn 自回归 SMILES 语言模型构建,逆合成模块采用 MEGAN 与 Retro* 搜索算法。商业构建块来自大规模 ZINC 数据库子集,被强制构建块集合规模设置为 10 或 100。整个框架不依赖特定逆合成模型,具有较强通用性。
结果
受限可合成性的可学习性
研究人员首先通过消融实验分析奖励函数设计对优化动态的影响。结果显示,仅使用 Tanimoto 相似度或子结构匹配作为奖励信号,学习过程不稳定或效果有限;而 TANGO 结合两种信号后,在不同随机种子下表现更为稳定和一致。
在 10,000 次 oracle 预算下,模型能够在约 8.5 小时内学会生成满足构建块约束的可合成分子。对照实验(不加入构建块约束)几乎无法生成满足受限合成性的分子,证明该能力并非偶然获得。
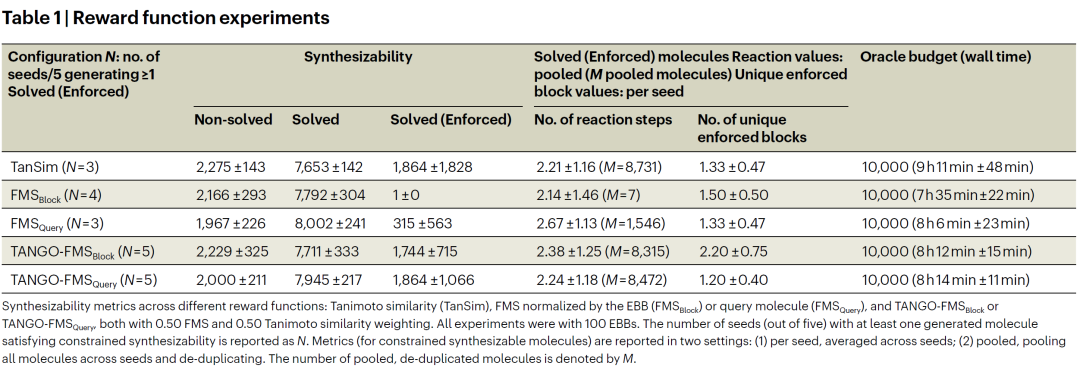
合成网络与发散合成能力
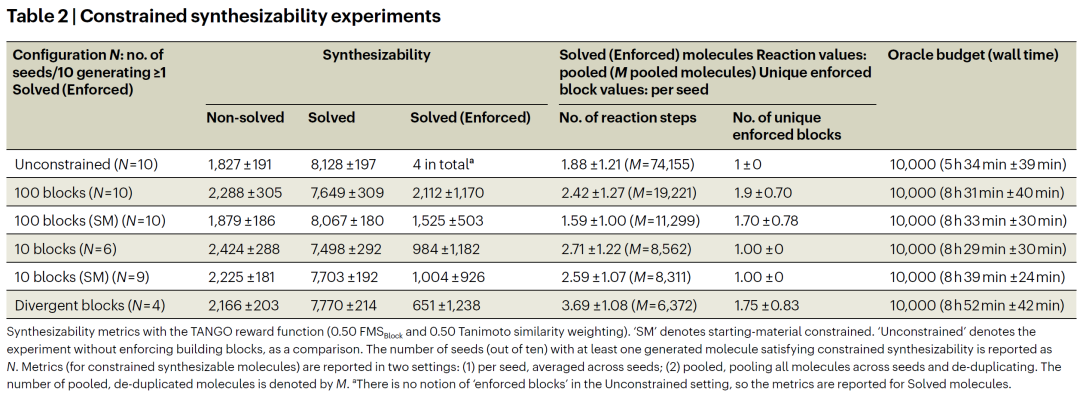
在发散合成实验中,研究人员将较大的非商业分子纳入构建块集合,使其作为公共中间体分支生成多个高评分分子。结果显示,模型能够学习围绕同一中间体构建发散型合成网络,尽管成功率较低,但在增加 oracle 预算后可进一步提升。
优化过程中生成的分子通常具有合理的反应步数,未显著增加合成复杂度。这表明优化受限可合成性并未导致低效或冗长的合成路径。
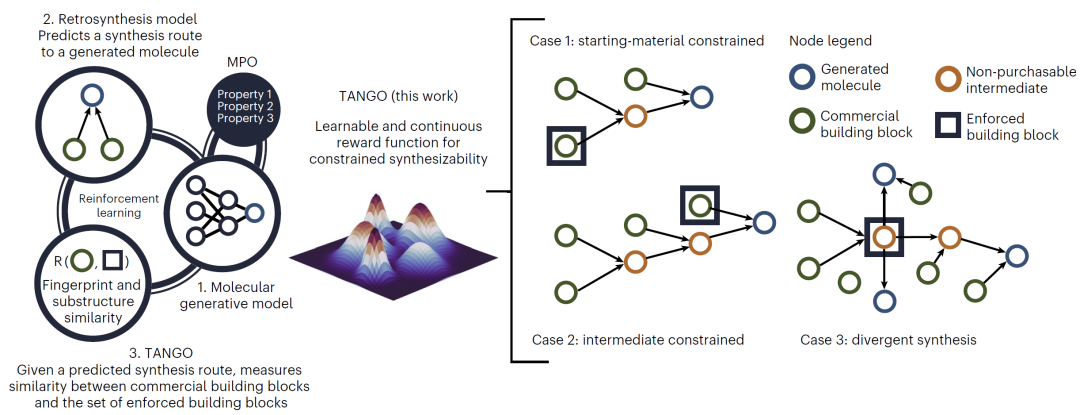
图1:TANGO 引导分子生成,在优化其他性质的同时,直接优化包含强制构建块(EBBs)的受限可合成性。
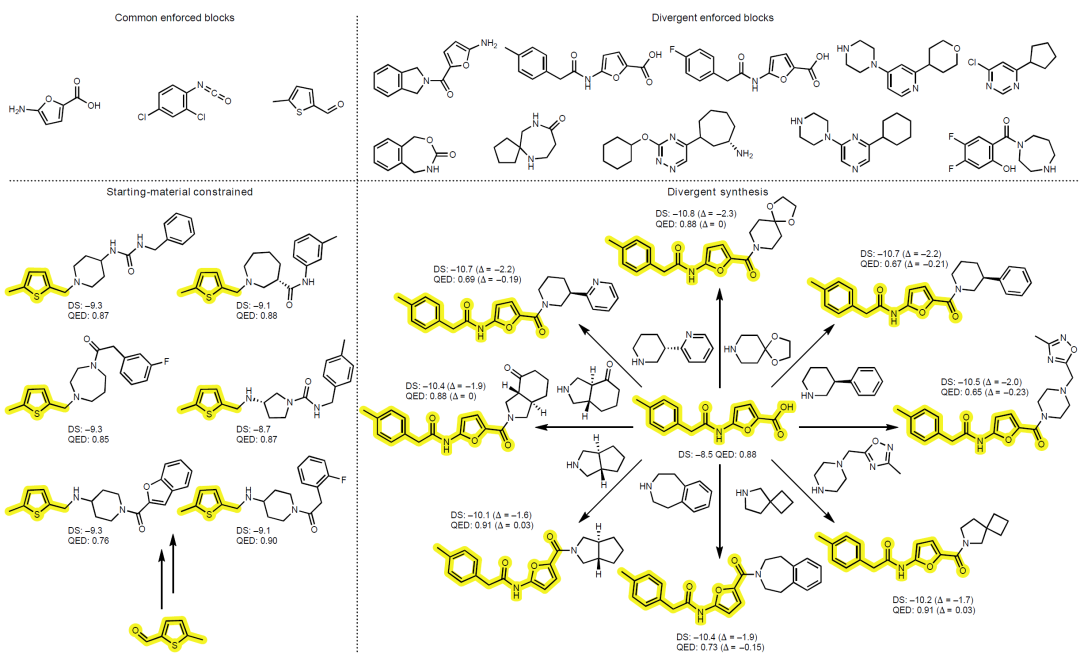
图2:在起始原料约束与发散合成约束(由非商业公共中间体一步合成至多样化高奖励分子)下生成的示例分子。
分布学习与生成行为分析
从分布角度看,生成模型在强化学习后显著改变了生成分子的概率分布。与预训练模型相比,最终模型生成的分子中,满足“可合成且包含构建块”的比例显著提高。
UMAP 嵌入与负对数似然分析表明,模型在化学空间中形成了围绕目标构建块的局部密集分布。强化学习过程中存在一定程度的“利用”行为,即模型倾向围绕某些高奖励构建块进行局部探索,但这种行为有助于提升样本效率。
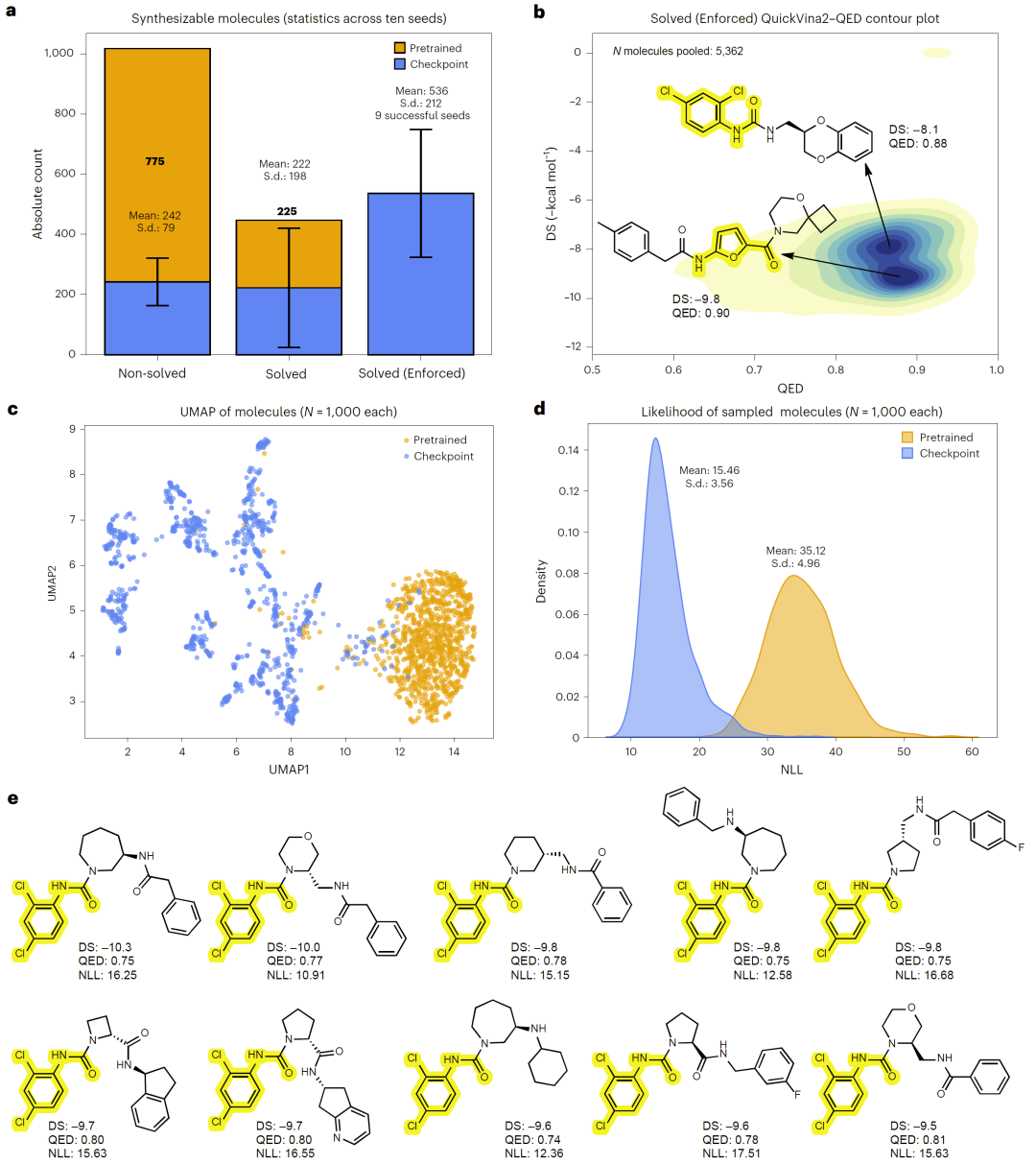
图3:模型学习到满足多参数优化(MPO)目标的分子分布。
COX-2 案例研究
在一个更接近真实药物设计场景的案例中,研究人员强制在生成分子的合成路径中包含苯磺酰胺结构单元,该基团已知与 COX-2 选择性相关。
在 15,000 次 oracle 预算下,模型成功生成包含该构建块的候选分子,并获得与参考抑制剂相当甚至更优的对接评分。部分生成分子可通过一步酰胺偶联反应合成,结合构象分析表明结合模式合理。
该实验表明,TANGO 不仅可用于方法学验证,也可用于实际药物骨架重构与官能团固定设计任务。
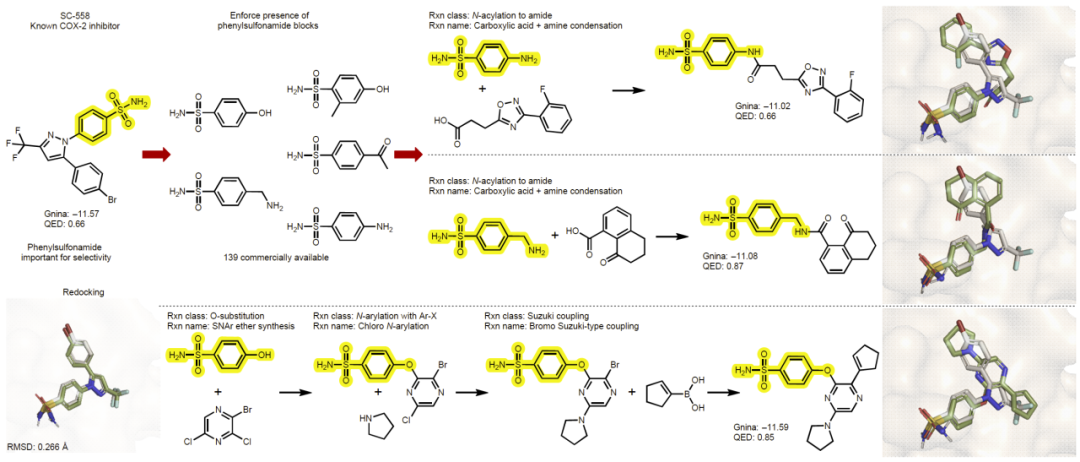
图4:COX-2 案例研究。
讨论
本研究提出的 TANGO 奖励函数为生成式分子设计提供了一种直接优化受限可合成性的新范式。通过将二元合成判定转化为连续奖励信号,模型能够在复杂约束下进行有效学习,并统一处理起始原料约束、中间体约束与发散合成约束。
然而,该方法仍存在若干局限。首先,TANGO 依赖逆合成模型的准确性,而当前逆合成算法本身仍存在区域选择性与立体选择性预测不完备的问题。其次,当可用构建块库存规模较小时,合成路径搜索失败将带来二元奖励中断问题,可能影响优化稳定性。此外,本研究主要聚焦单一构建块约束,多构建块联合约束仍有待进一步探索。
总体而言,研究人员表明,通过奖励塑形与强化学习结合,通用生成模型可以有效适应现实化学约束条件。这为绿色化学、工业副产物再利用以及复杂药物合成网络设计提供了新的技术路径。
整理 | DrugOne团队
参考资料
Guo, J., Schwaller, P. TANGO: direct optimization of constrained synthesizability for generative molecular design. Nat Comput Sci (2026).
https://doi.org/10.1038/s43588-026-00959-1

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号