打破RL“单峰”魔咒!清华提出首个双扩散强化学习框架,重塑自动驾驶复杂决策

打破RL“单峰”魔咒!清华提出首个双扩散强化学习框架,重塑自动驾驶复杂决策

AI生成未来
发布于 2026-03-05 15:10:13
发布于 2026-03-05 15:10:13
转自:极市平台
作者丨王以诺
来源丨清华大学智能驾驶课题组
本文介绍清华大学智能驾驶课题组(iDLab)在 IEEE ITSC 2025(最佳学生论文奖提名)发表的最新研究成果《Distributional Soft Actor-Critic with Diffusion Policy》。该研究工作由清华大学研究生刘童、王以诺、宋绪杰在李升波教授指导下完成。

图片
arXiv:https://arxiv.org/abs/2507.01381
单位:清华大学车辆与运载学院、清华大学人工智能学院
01 一个根深蒂固的错误假设
强化学习(Reinforcement Learning, RL)在机器人控制、自动驾驶等领域已经展现出惊人的能力。但在这一片繁荣之下,几乎所有主流算法都悄悄共享着同一个假设——值函数的分布是单峰的。
什么叫单峰?
想象你问一个AI"这个动作值多少分",它给你的答案是一条漂亮的钟形曲线,一个山峰,最高点就是它认为最可能的得分。
无论是来自 UC Berkeley 与 Google Brain 的经典 SAC 算法,还是来自 DeepMind 的分布式强化学习系列(C51、IQN、QR-DQN,Bellemare、Dabney、Silver 等)以及 OpenAI 广泛使用的 PPO,这些顶级团队的工作在对值分布建模时,都选择了单峰假设。
但现实世界并不单峰。
以自动驾驶路口会车为例:
自车做出同一个动作(保持当前速度直行),但周围车辆的驾驶风格是随机的——遇到保守型司机时顺利通过,累积收益很高;遇到激进型司机时被迫紧急制动,累积收益很低。两种结果都有相当概率发生,真实的回报分布就是双峰的。
强行用一个单峰高斯去拟合这条双峰曲线,就像用均值代替整张分布——大量关键信息被抹平,值估计产生系统性偏差,策略学习也因此跑偏。
清华大学李升波教授团队提出 DSAC-D(Distributional Soft Actor-Critic with Diffusion Policy),从根本上突破了这一枷锁。
02 为什么单峰假设是个"原罪"?
这个问题并非新鲜。
分布式强化学习这条赛道,正是因为对值分布建模更精准而备受关注。
DeepMind 的 C51 用 51 个原子值离散近似分布,QR-DQN 用分位数回归扩大灵活性,IQN 进一步实现连续建模。但无论形式如何变化,它们本质上都只能表征单峰或近似单峰的分布,在连续控制任务中尤为突出。
单峰假设带来个问题:值估计偏差。 当真实的回报分布有多个山峰,用一个高斯分布去拟合,就必然高估或低估某些区域的价值。以 TD3 算法为例,在 Ant-v3 任务中其值估计偏差高达 -327.33;而 DSAC-D 在同一任务的偏差仅为 -3.55——相差近百倍。
核心创新:双扩散架构
扩散模型(Diffusion Model)是近年来生成式 AI 领域的明星技术——Stable Diffusion、DALL-E 3 背后都是它的身影。
其核心能力正在于能够精确建模复杂的多峰分布:给图像加噪声,再一步步去噪还原,这个过程天然能捕捉数据分布的多样性。
DSAC-D 的核心洞察是:把扩散模型同时引入强化学习的"评判员"(Critic)和"演员"(Actor),构成业界首个双扩散分布式强化学习框架。
这是与此前工作(包括本课题组的前作 DACER[1])的本质区别:DACER 仅在策略网络侧使用了扩散模型;DSAC-D 则在值网络和策略网络两侧同时引入,并首次在连续控制任务中实现了真正的多峰值分布建模。
扩散值网络(DVN)——让评判员学会"多角度打分"
传统值网络输出一个实数(Q值),或至多一个单峰分布。DSAC-D 的扩散值网络(Diffusion Value Network, DVN)则把值函数建模为一个完整的多峰概率分布:从纯噪声出发,经过多步去噪,最终采样出一组回报样本,共同构成对当前动作价值的精细刻画。
受到分布式贝尔曼方程启发 ,值分布学习的训练目标继承自 DDPM。
Critic 的核心训练损失函数为:
公式的直觉很清晰:给真实的 Q 值回报样本 加上指定程度的噪声,然后让噪声预测网络 猜测这个噪声是什么——猜得越准,网络就越懂得真实回报的分布形状。
这与图像生成中扩散模型的训练范式在数学上完全一致,同时将当前状态 和动作 作为条件输入,使得值网络能够对不同的状态-动作对学习出各异的多峰分布。
扩散策略网络(DACER)——让演员"一心多用"
策略网络同样采用扩散模型实现:给定当前状态,网络不再输出单一动作,而是通过反向去噪过程采样出多个动作候选。这使得智能体面对同一场景时,可以自然地生成"从左绕行"和"从右绕行"两种轨迹——而非被迫折中。
两个扩散模块——DVN 与 DACER——交替优化,形成完整的多峰分布策略迭代(MDPI)框架,并可被证明收敛到最优策略。
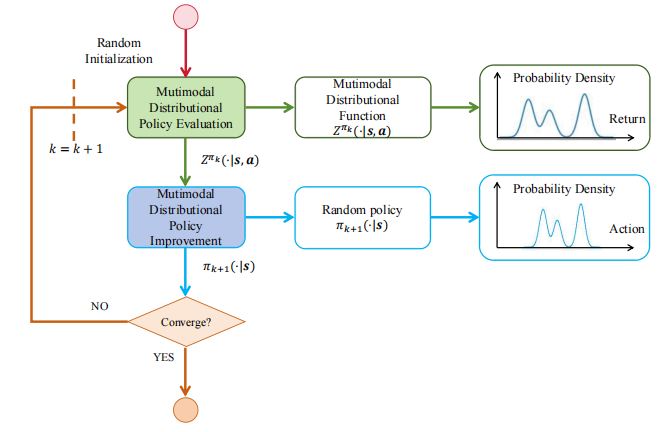
图1 多模态分布式策略迭代框架
图1 多模态分布式策略迭代框架
实验:9战9胜,从仿真到真车
MuJoCo 全面 SOTA
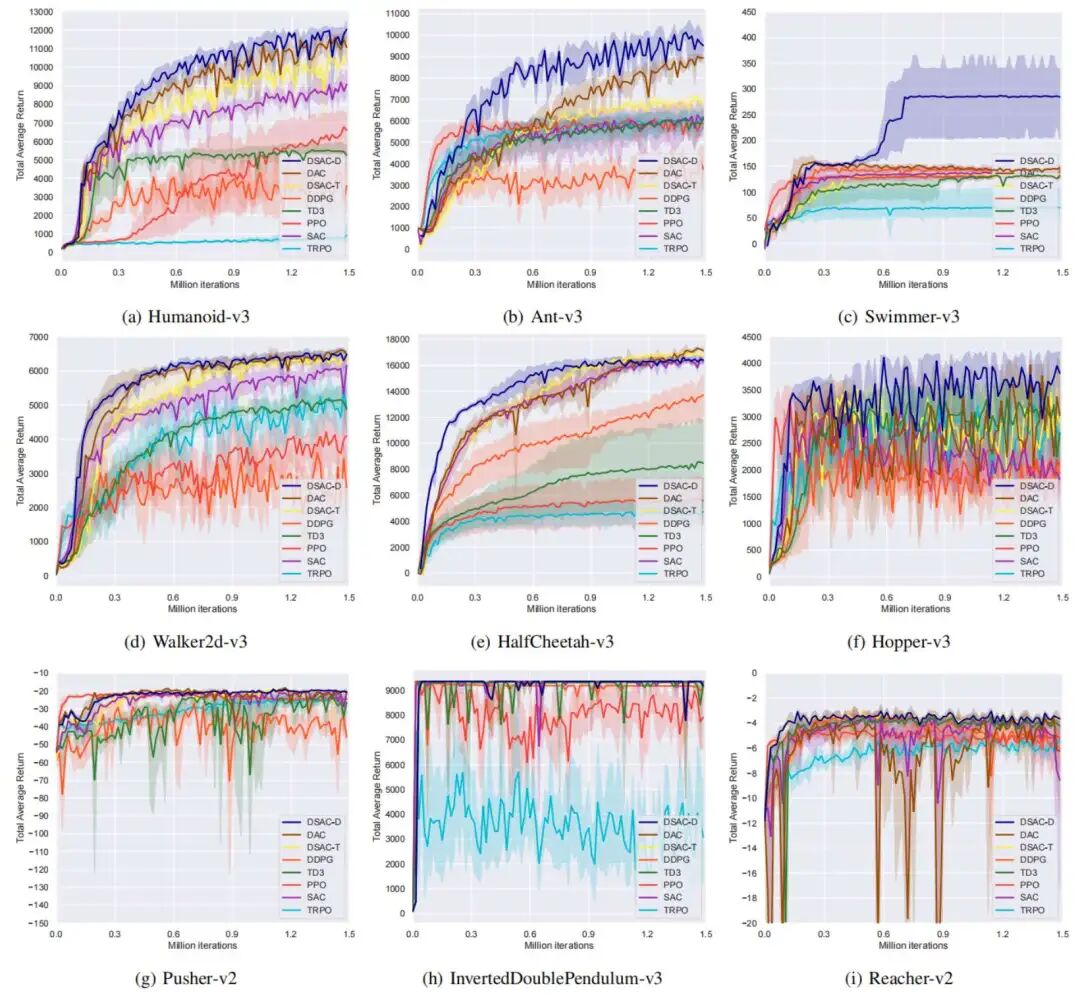
图2 实验结果
图2 实验结果
在 MuJoCo 基准上,DSAC-D 在全部 9 个控制任务中均超越所有对比算法,包括 SAC、TD3、DDPG、PPO、TRPO、 DSAC-T[2]和 DACER。
总平均回报提升超过 10% 。部分典型任务提升幅度如下:
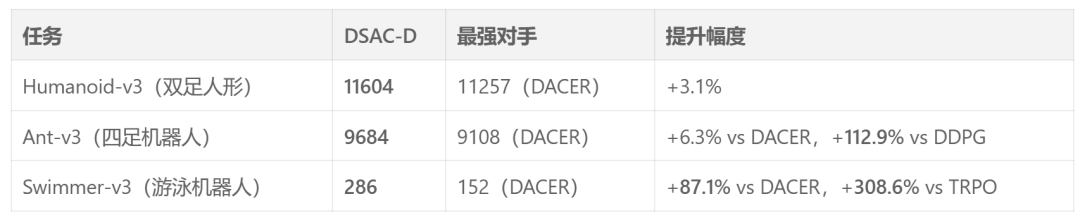
图片
值估计偏差的压制同样显著:Ant-v3 任务中,TD3 的平均估计偏差为 -327.33,DSAC-D 仅为 -3.55;DDPG 的偏差高达 89.36(严重高估),DSAC-D 几乎归零。
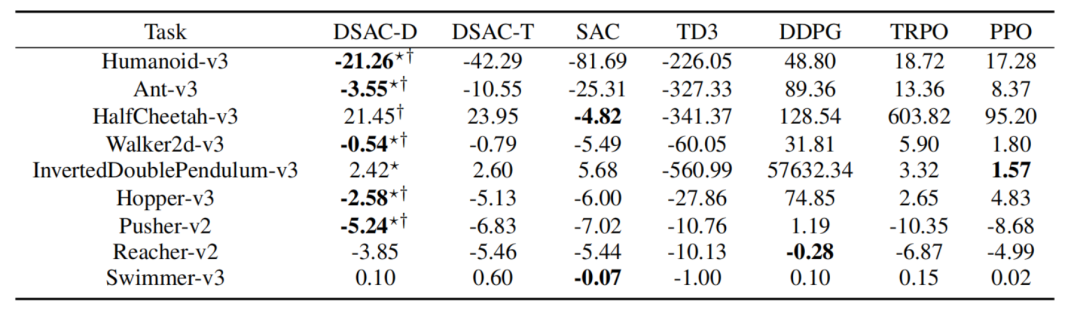
图3 平均相对值估计偏差
图3 平均相对值估计偏差
多峰策略的"可见"证据
DSAC-D 不只是数字上的提升——它真实地学到了多样化行为。
在 Ant-v3 任务中,DSAC-D 训练出的四足机器人呈现出两种截然不同的步态:四腿小步快跑和三腿大步跨越,两种步态并存;而对比算法 DSAC-T 只学会了单一步态。
在 Humanoid-v3 中,DSAC-D 的人形机器人展现出自然的手臂摆动姿态,而 DSAC-T 的机器人则上身后倾、步伐局促,明显次优。

图4 不同动作模态
图4 不同动作模态
真实车辆验证:跟踪误差低于 5 cm
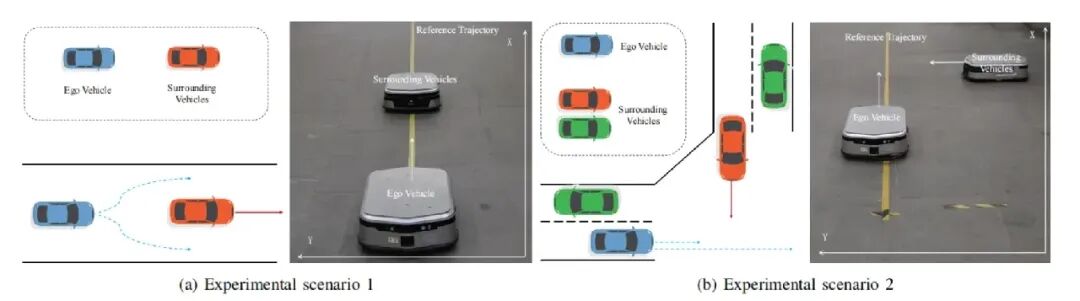
图5 实验环境设定
图5 实验环境设定
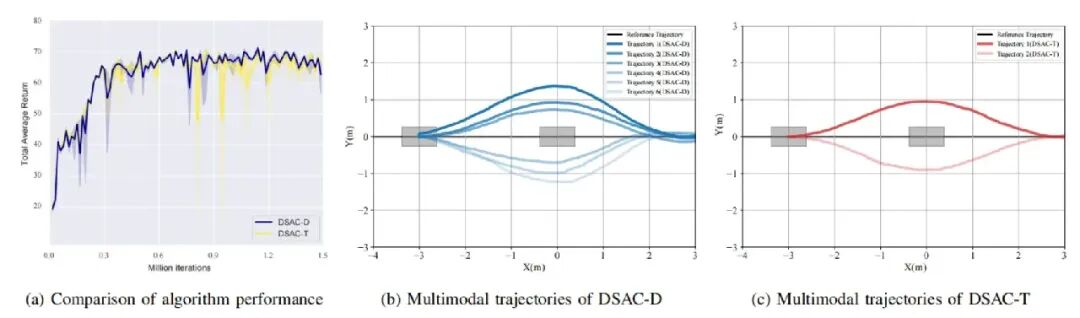
图6 行为风格实验结果
图6 行为风格实验结果
算法最终落地于真实 AGV 小车的路口会车实验。在十字路口随机出现的周围车辆会以激进、正常、保守三种不同驾驶风格行驶,形成随机多峰场景。
结果表明,DSAC-D 对三种驾驶风格的轨迹跟踪误差分别为:
- 保守风格:2.66 cm
- 正常风格:3.53 cm
- 激进风格:4.98 cm
三种风格全部低于 5 cm,充分验证了算法在真实物理世界中的精准性与鲁棒性。
更重要的是,扩散策略网络能够在同一场景下输出多条不同的避障轨迹(从左绕行/从右绕行),而对比方法 DSAC-T 只能输出单一轨迹。
总结
DSAC-D 提供了一个简洁而深刻的视角:强化学习中长期被忽视的"单峰偏见",是制约算法在复杂真实场景中发挥潜力的根本瓶颈之一。
通过将扩散模型同时引入值网络和策略网络,DSAC-D 构建了首个双扩散分布式强化学习框架,在理论上建立了可收敛的多峰分布策略迭代框架,在实践中实现了仿真与真实场景的双重验证。
这一工作也表明,生成式 AI 与强化学习的深度融合,远不止于"用扩散模型生成动作"这一层面——重新审视值函数本身的分布假设,或许才是下一个值得深耕的方向。
参考文献
[1] Wang Y, Wang L, Jiang Y, et al. Diffusion actor-critic with entropy regulator[J]. Advances in Neural Information Processing Systems, 2024, 37: 54183-54204.
[2] Duan J, Wang W, Xiao L, et al. Distributional soft actor-critic with three refinements[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号