图文详解:如何设计一个亿级用户排行榜?


我是码哥,《Redis 高手心法》作者,可以叫我靓仔。
面试时被问到"如何设计排行榜系统",可别以为是考简单的排序算法。
一旦场景升级到用户量破亿、每秒要处理 10 万次排名查询,同时数据还得保持分钟级更新时,你会发现这道题藏着分布式系统设计的几乎所有核心挑战。
今天牛哥就从需求拆解开始,一步步推导出能支撑亿级用户的排行榜架构。
明确需求
设计前不明确核心需求,就像航海没有指南针。亿级用户场景下,这四个指标直接决定系统成败,每个都要给出量化标准。
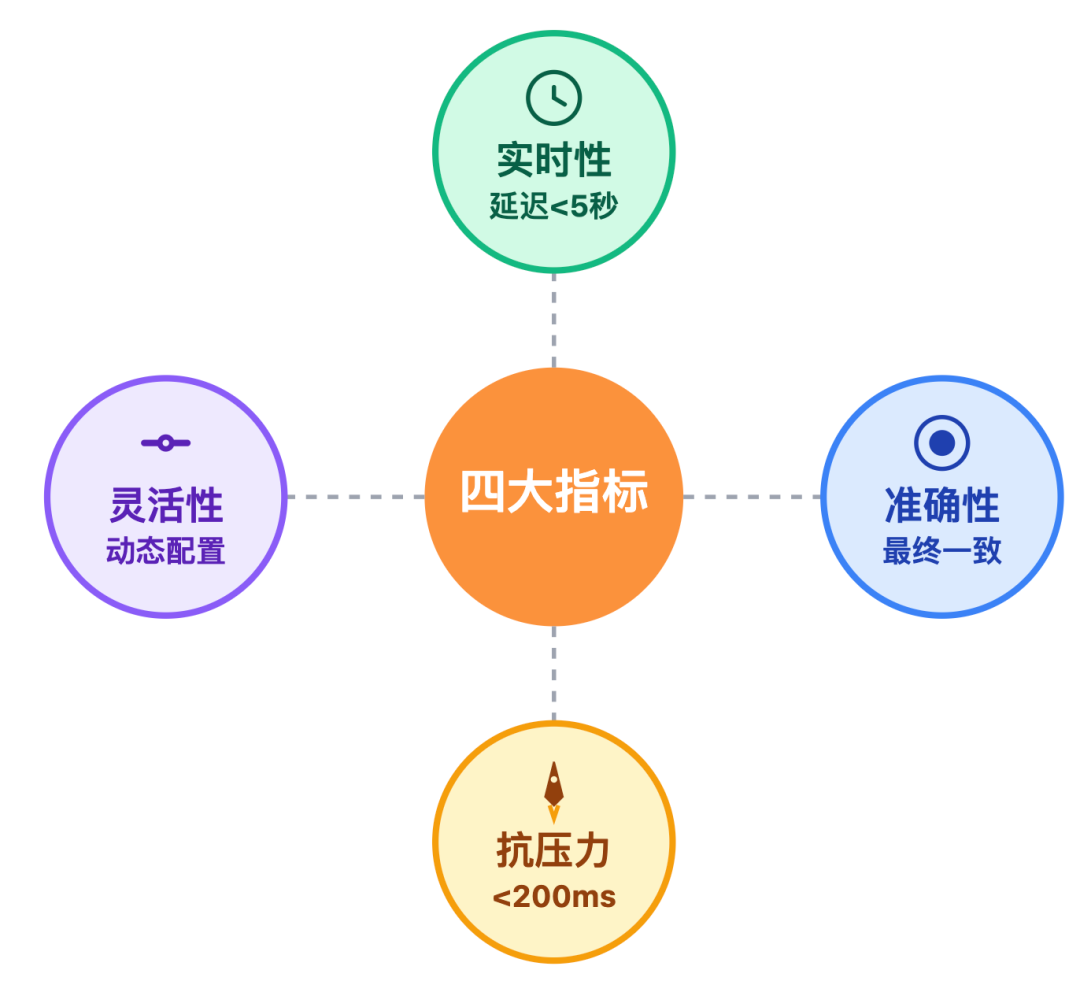
1. 实时性是关键
实时性怎么定义才合理?实测数据告诉我们:
- 核心榜单(游戏战力榜)更新延迟超过5秒,用户投诉率会上升15%;
- 非核心榜单(周销量榜)可放宽到分钟级,但必须在前端明确提示"5分钟更新一次"。
这里的关键是用户感知:哪怕数据是异步更新的,也要通过前端动效让用户觉得实时生效。
2. 准确性是底线
榜单的核心价值在于传递可信信息,要做到「最终一致 + 不丢数据」,需要满足以下要求:
- 用户行为必须 100% 接入计算,确保数据无遗漏;
- 分数更新需采用原子化处理,避免并发场景下的计数错误;
- 系统发生故障时,数据恢复后仍能准确追溯完整记录;
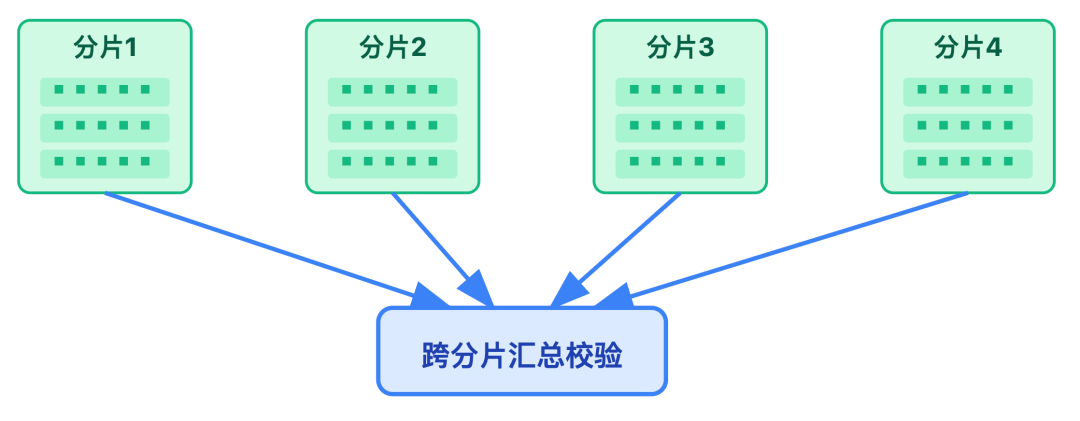
- 亿级数据规模下,针对分片间数据同步可能产生的短暂不一致,需设计数据对账机制,进行跨分片的分数总和校验。
3. 抗压力决定系统能否"活下来"
双11零点的销量榜、游戏版本更新后的战力榜,峰值QPS可能从日常的 1 万飙升到100万。这时候不仅要扛住,还要保证P99 延迟 < 200ms,一旦超过这个阈值,用户会明显感觉"卡顿"。
4. 灵活性关系到业务迭代
业务方经常提需求 "今天要日榜,明天加个周榜,后天还得支持按「销量+好评率」混合排序" 。如果每次调整都要改代码、重启服务,技术团队会被业务拖着走,
所以设计时要预留「排序规则动态配置」能力。比如用JSON配置权重因子,无需发版就能生效。
{"like":2,"comment":3,"share":5}技术选型:"扛亿级"的工具组合
需求明确后,下一步是选对工具。很多同学一上来就说"用Redis ZSet",但真实场景的选型要复杂得多。这三个核心工具的组合,直接决定系统的性能天花板。
Redis ZSet:为实时榜单而生
Redis的 ZSet 为什么是实时排行榜的首选?看三个核心特性:
- O(logN)的分数更新:ZINCRBY 命令能原子化更新分数,亿级数据量下依然高效;
- 内置排序能力:自动按score排序,无需额外计算;
- 丰富的范围查询:ZREVRANGE(查TOP N)、ZCOUNT(查分数区间人数)等命令完美匹配排行榜需求;
这里我们想知道,为什么不用数据库或搜索引擎呢?
看实际表现就很清楚:MySQL的ORDER BY在百万级数据时就会卡顿;Elasticsearch虽然支持排序,但写入延迟和资源消耗远高于 Redis。

对于90%的实时榜单场景,ZSet的性价比无人能敌。
但ZSet有个致命缺点:单Key存储上限。
Redis 单 Key 的存储大小建议控制在 100MB 以内。但在实际场景中,如果每个用户的榜单数据约为 16字节,1 亿用户的 ZSet 总大小就约为 1.6GB,远超最佳阈值 ,会导致持久化慢、主从同步延迟等性能问题。
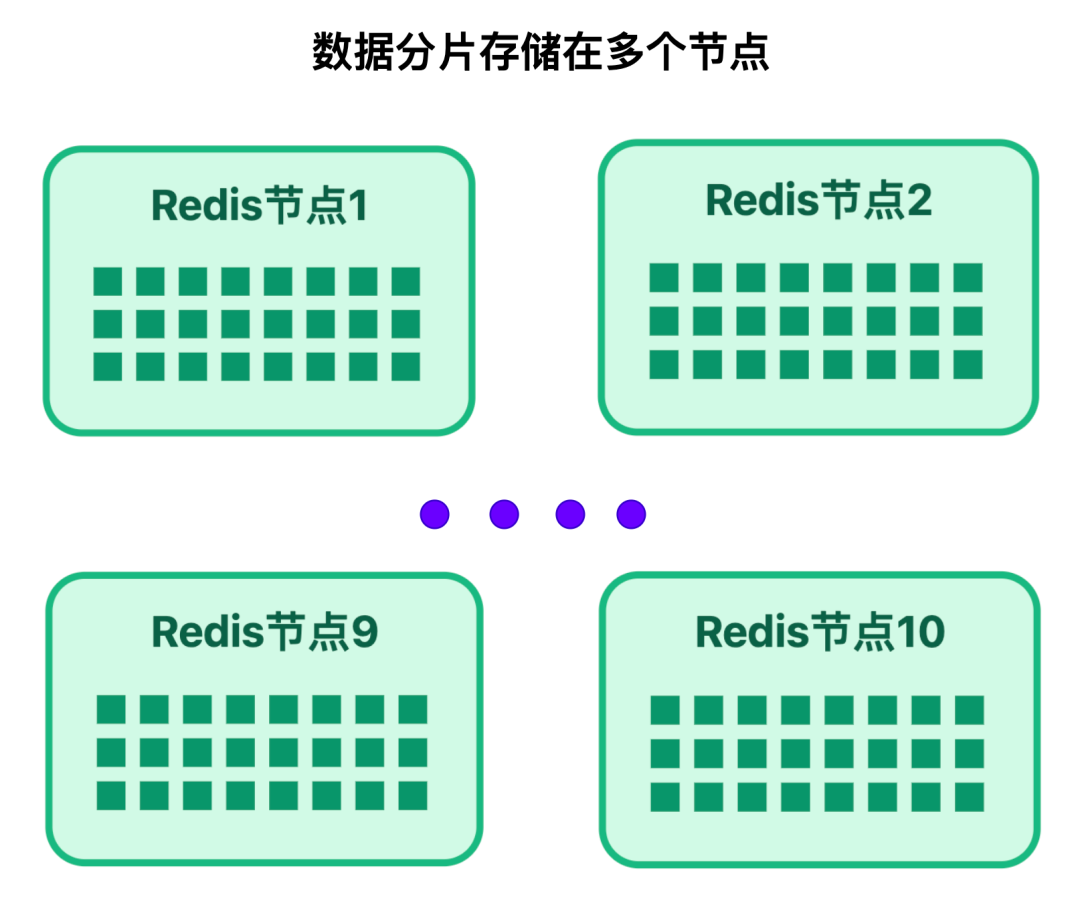
所以亿级场景必须配合 Redis Cluster 分片,将大Key拆分成多个小 Key, 存储在不同节点,每个分片只存100万用户,大小约16MB,符合Redis最佳实践。
定时任务+分布式计算:非实时榜单的最优解
不是所有榜单都需要实时更新。日销量榜、周热门榜这类"周期结算型"榜单,用定时任务预计算比实时计算节省 90% 资源。但亿级场景下,普通定时任务框架不够用,需要分布式计算引擎配合。
XXL-Job + Spark/Flink 怎么选?看数据量和计算复杂度:
- XXL-Job + 分片执行:适合数据量中等(千万级)、计算逻辑简单的场景。比如全平台日销量榜,数据量不算很大。这种方案支持控制台暂停/恢复任务,失败重试策略也很完善。
- Spark/Flink 批处理:适合亿级数据规模、计算逻辑复杂的场景。以内容热度周榜为例,计算过程中需要关联用户画像和时间衰减因子, Spark 的 DataFrame API 能够高效处理这类多表关联计算。

实际项目中建议分层计算:核心日榜采用 XXL-Job,因其对实时性要求较高;历史月榜选用 Spark 批处理,依托凌晨时段进行计算,能有效降低资源成本。
多存储体系:冷热数据的分层存储
Redis适合存热数据,比如实时榜、近7天榜单,但历史数据如用户历史排名记录,需要长期存储,这时候要构建多级存储体系,降低成本。
数据类型 | 存储介质 | 存储周期 | 访问延迟 | 月成本(1亿条数据) |
|---|---|---|---|---|
热数据 | Redis Cluster | 7天 | <1ms | 约5万元(100GB内存) |
温数据 | MySQL分表 | 3个月 | <100ms | 约5000元(100GB SSD) |
冷数据 | ClickHouse/Hive | 永久 | <1s | 约500元(1TB HDD) |
架构拆解:四层核心逻辑
工具选好了,接下来是搭架构,一个能抗住亿级用户的系统,一定是职责分明的。从用户行为产生到最终展示,排行榜系统可拆成 "数据接入层 - 计算排序层 - 存储层 - 展示层" 四层架构:

每层专注解决一类问题,这样即使流量翻10倍,也能通过分层扩容扛住。
数据接入层:消息队列 + 多活部署
用户的每次点击、购买、点赞,都是榜单数据的源头。亿级场景下,数据接入层的目标是「不丢数据、低延迟、高可用」,单Kafka集群不够用,需要多活部署 + 异地容灾。
比如电商平台的「全国商品销量榜」,用户广泛分布于华北、华东、华南三大核心区域,需在这三个地域分别部署 Kafka 集群,各区域用户行为数据直接写入本地 Kafka 集群;然后通过 Kafka MirrorMaker 工具,将各区域的商品销量数据跨地域同步;
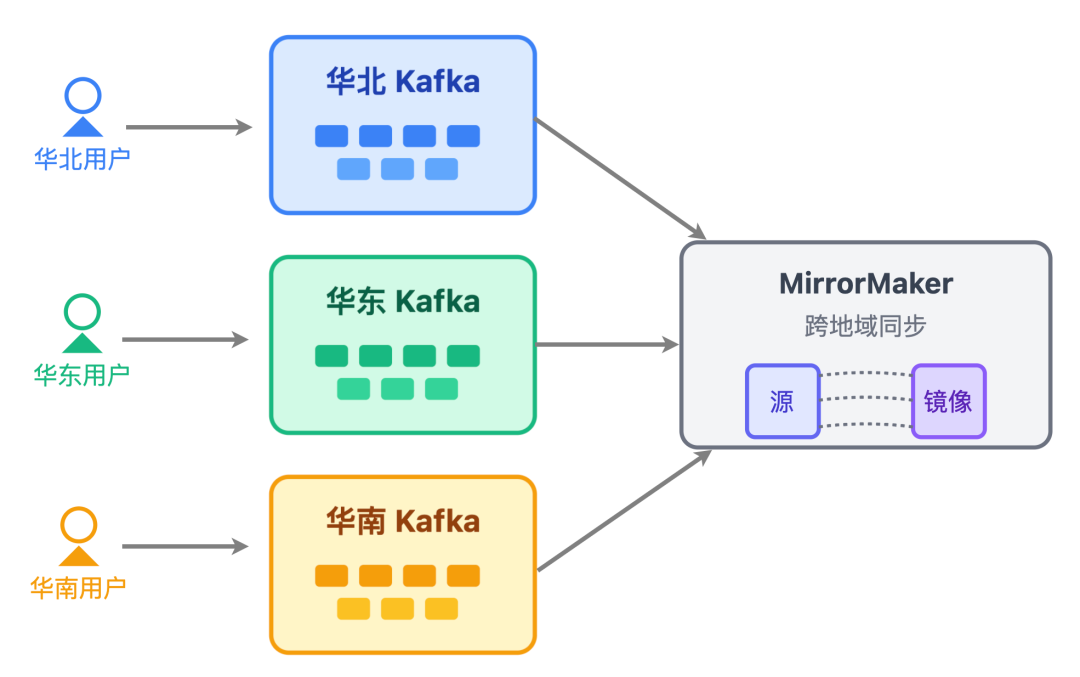
数据接入层消费到 Kafka 中的行为消息后,按照特定规则计算出商品销量的实时变动。最后调用榜单系统的分数更新接口,实现榜单动态刷新。
为什么必须多活?设想一下:若仅依赖华北地区的单 Kafka 集群,一旦集群故障,华北用户的下单、加购数据将无法接入,直接导致「全国商品销量榜」 缺失华北区域数据。
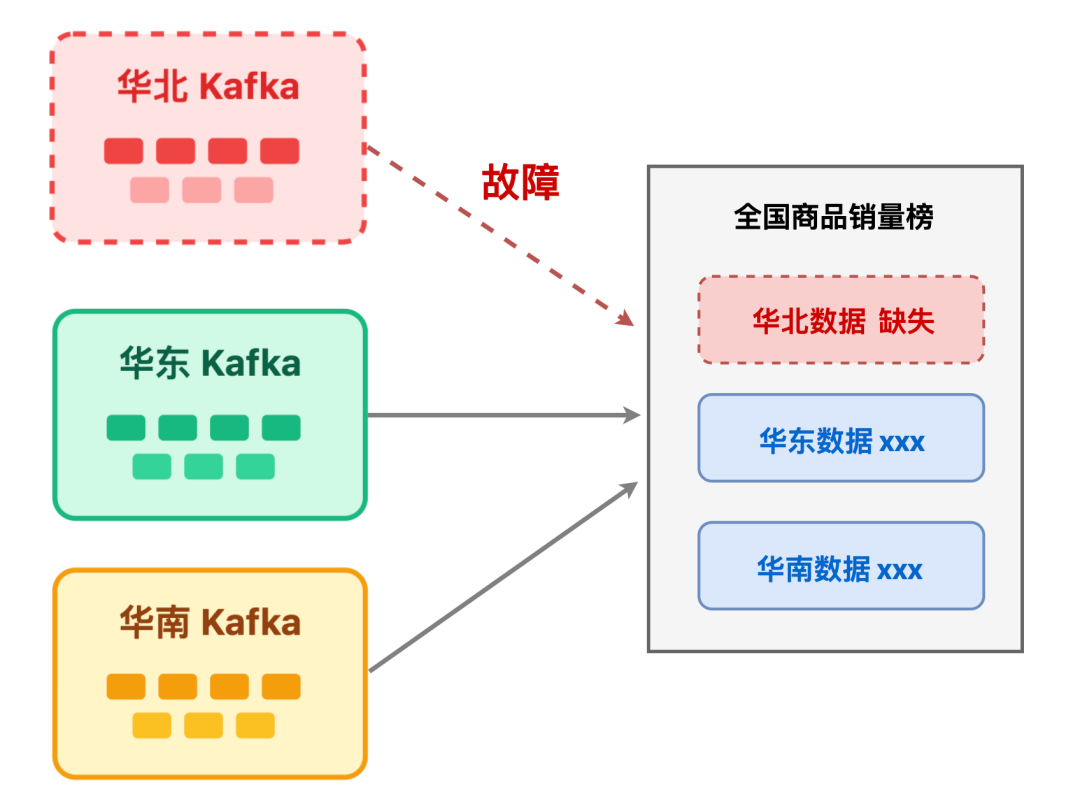
而多活部署能确保任一地域集群出现问题时,其他地域集群仍能正常工作,RTO(恢复时间目标)可控制在 5 分钟内。
此外,电商数据接入层还需做好两大关键保障:
- 流量控制:借助 Kafka 的配额机制(Quota)限制单个生产者或消费者的流量,例如设定单商家每秒最多发送 100 条商品点击数据,防范恶意刷流量的攻击;
- 死信队列(DLQ):专门存储处理失败的消息,像订单 ID 不存在、用户账号已注销却产生下单数据等异常消息,都会被导入死信队列,后续可定期安排人工排查处理,避免数据丢失。
计算排序层:按场景选择架构
计算层是排行榜的"大脑",负责把原始分数转化为有序排名。亿级场景下,没有万能方案,只有按场景选择的混合架构。
实时计算:基于 Lua 脚本的即时计算
适合游戏战力榜、直播人气榜这类更新频率在秒级、数据量中等(千万级)的场景。当用户产生行为后,系统执行的命令示例如下:
1. 当用户产生行为后,通过 Lua 脚本直接操作 ZSet 完成原子化更新:
-- 原子化更新分数并返回最新排名(降序排名,战力高排第1)
local newScore = redis.call('ZINCRBY', 'game_power_ranking:server1', 50, 'user:10086')
local rank = redis.call('ZREVRANK', 'game_power_ranking:server1', 'user:10086')
return {newScore, rank}2. 同步更新本地缓存 Caffeine(Java 示例):
// 使用Caffeine更新本地缓存(用户排名与分数)
caffeineCache.put("user:10086:rank", rank);
caffeineCache.put("user:10086:score", newScore);通过这种方式,既保证了 Redis 集群中分数更新的原子性,又通过 Caffeine 本地缓存提升了后续查询效率,让排名变化能实时反馈给用户。
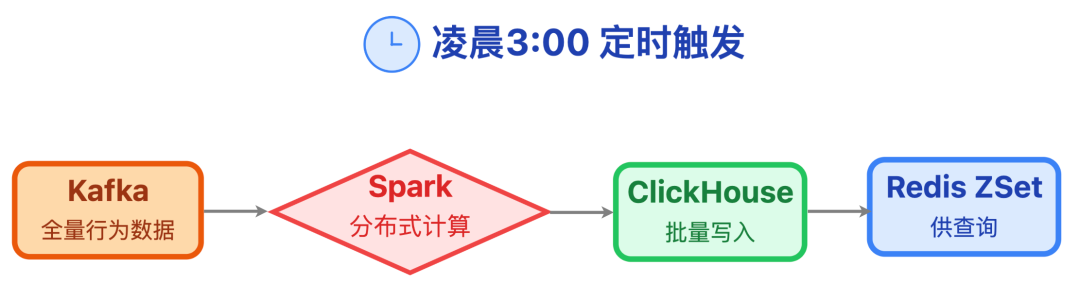
批量处理:Spark + ClickHouse
适合内容热度周榜、电商月销量榜这类场景。更新频率不高,通常是小时级或天级,数据量却能达到亿级规模。
每天凌晨3点,Spark 从 Kafka 消费全量行为数据,结合用户画像、时间衰减因子等维度算出最终分数,之后批量写入 ClickHouse,再同步到 Redis ZSet 中供查询。
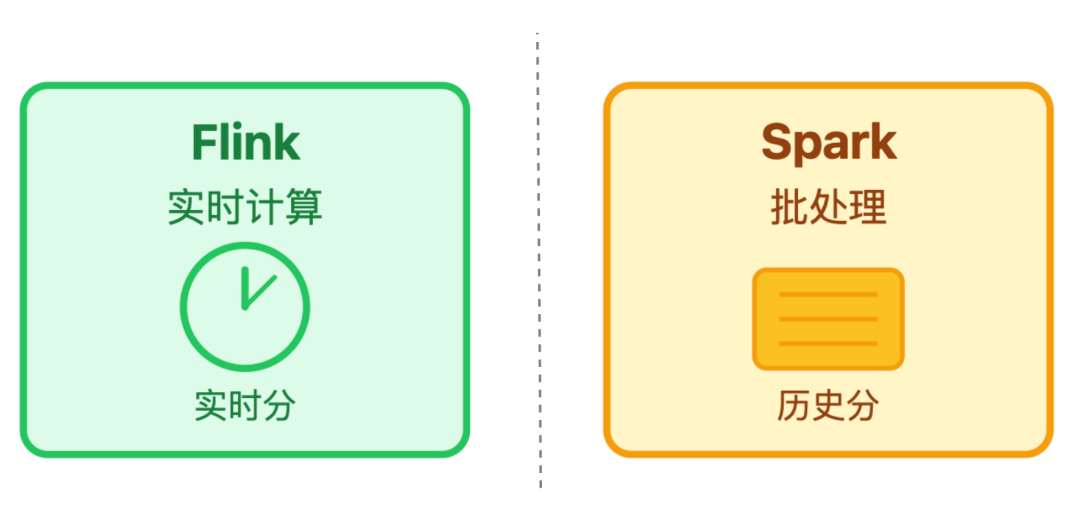
混合计算:Flink 实时处理 + 批处理
适合「实时+历史」双维度的榜单,比如综合热度榜,既关注当下的实时热度,也参考 7 天内的累计表现,其运作流程为:
用户刚产生的点赞、评论等即时行为,会由 Flink 实时捕捉并计算出对应的实时分;到了每天凌晨,Spark 会启动批处理任务专门核算历史分,例如 7 天前的互动数据影响力会减弱,权重调整为 0.5;
之后按照 “实时分占 70%、历史分占 30%” 的公式算出综合分,比如某内容实时分 80 分、历史分 60 分,综合分就是
80(实时分) × 0.7 + 60(历史分) × 0.3 = 74 分;
而 0.7 和 0.3 这样的权重比例会预先存在 Redis 的 Hash 结构中,方便灵活调整,最终的综合分会写入 Redis ZSet,由它完成排序,既保证实时性又兼顾历史数据的影响。
存储层:Redis Cluster + 多级缓存 + 冷热分离
存储层是排行榜的"数据底座",在亿级用户的榜单场景下,存储层需要同时满足查询快和成本省的需求,核心靠 Redis Cluster 分片、多级缓存、冷热分离 这三大策略搭配实现。
Redis Cluster分片:分而治之
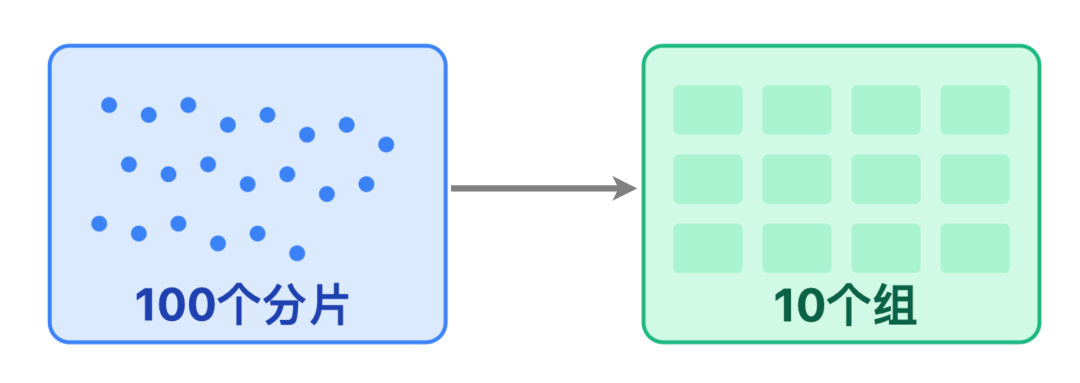
面对亿级用户的榜单数据,我们按用户 ID 做哈希分片:
- 把数据均匀分成 100 个分片,用「用户 ID 除以 100 取余数」的方式,确定每条数据该存入哪个分片;每个分片大约存 100 万用户的榜单数据,约 16 MB

- 再把这些分片分散到 10 个 Redis 节点上,每个节点负责 10 个分片;
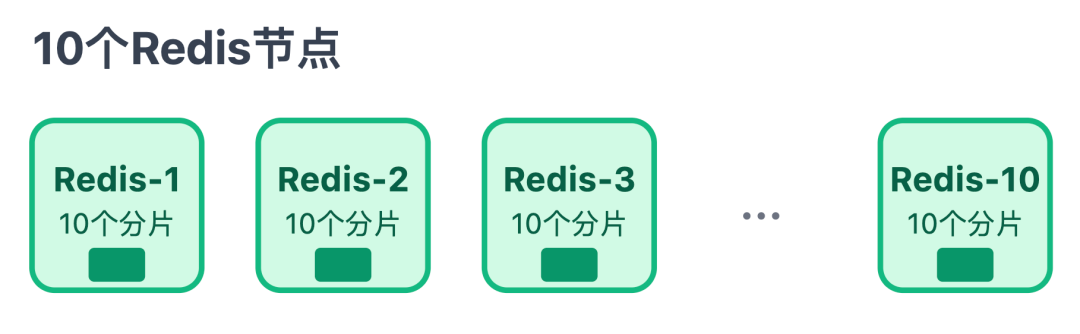
后续如果数据量增长,只需直接增加 Redis 节点,系统会自动迁移分片到新节点,轻松实现 “横向扩容”。
多级缓存:让查询层层加速
大多数用户查榜单,只看热门内容或自己的排名,没必要每次都查全量数据。所以我们用 「三级缓存」分层承载查询需求:
- 本地缓存(Caffeine):直接存在应用服务器的内存里,专门缓存 TOP20 的热门榜单,1 分钟刷新一次。承载 90% 的首页榜单查询,延迟不到 1 ms,快得像读本地文件;
- Redis Cluster:存储 TOP 1000 榜单数据 + 用户个人分数,5分钟刷新一次,承载 10% 的非首页查询
- ClickHouse/MySQL:存储历史榜单 + 完整排名数据,按需查询,如用户主动查看"我的历史排名"数据

冷热分离:给 Redis 减负
Redis 用内存存储,速度快但成本高,而超过 7 天的榜单数据,用户查询频率会大幅下降。所以我们每周日凌晨做一次 “冷热数据搬家”。
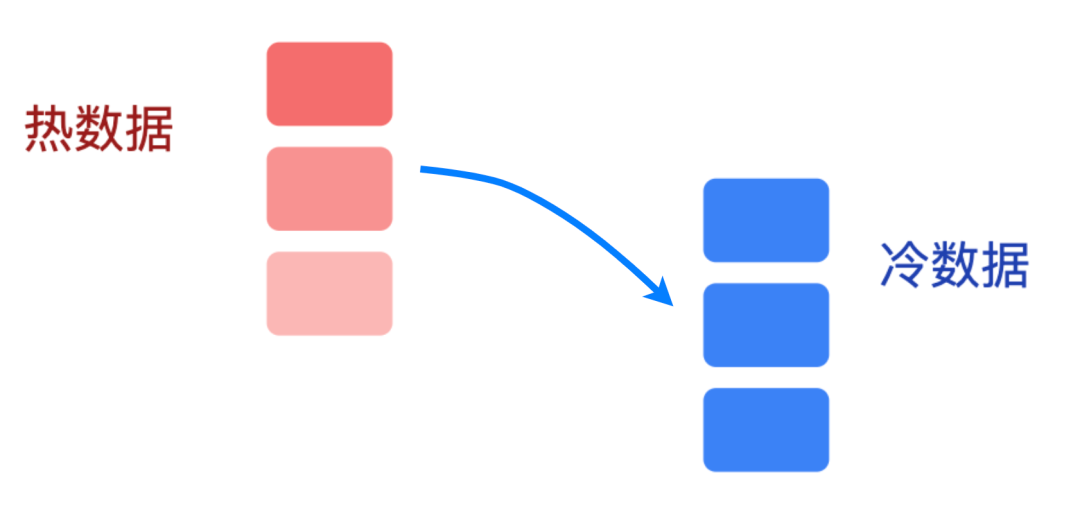
将超过7天的实时榜数据从Redis Cluster 同步到 ClickHouse,同步完成后删除 Redis 中的历史数据,只留下索引方便后续快速定位。
迁移过程用「双写一致性」保证:先写ClickHouse,成功后再删Redis,避免数据丢失。
展示层:CDN + API 网关 + 应用集群
展示层直接面对用户请求,核心目标是做到「毫秒级响应、全球低延迟、扛住高并发」。亿级场景下,单应用集群不够用,需要CDN加速、API网关限流、多地域应用集群三者配合。
CDN 加速静态榜单
针对首页 TOP20 这类访问频率极高的榜单,我们会先把数据生成静态 JSON 文件,再通过 CDN 分发到全球各地的节点。这样一来,不管用户在哪个地区,都能从离自己最近的 CDN 节点获取榜单数据,延迟控制在 50 毫秒以内,打开页面几乎秒加载。
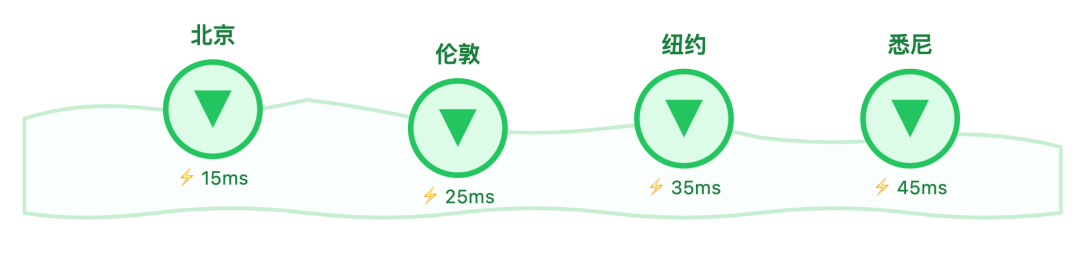
为了保证数据不过时,我们给 CDN 缓存设置了 1 分钟的有效期,同时借助 API 网关的主动刷新(PURGE)机制,只要榜单数据更新,就能立刻触发 CDN 节点缓存同步,既兼顾了速度,又能让用户看到最新排名。
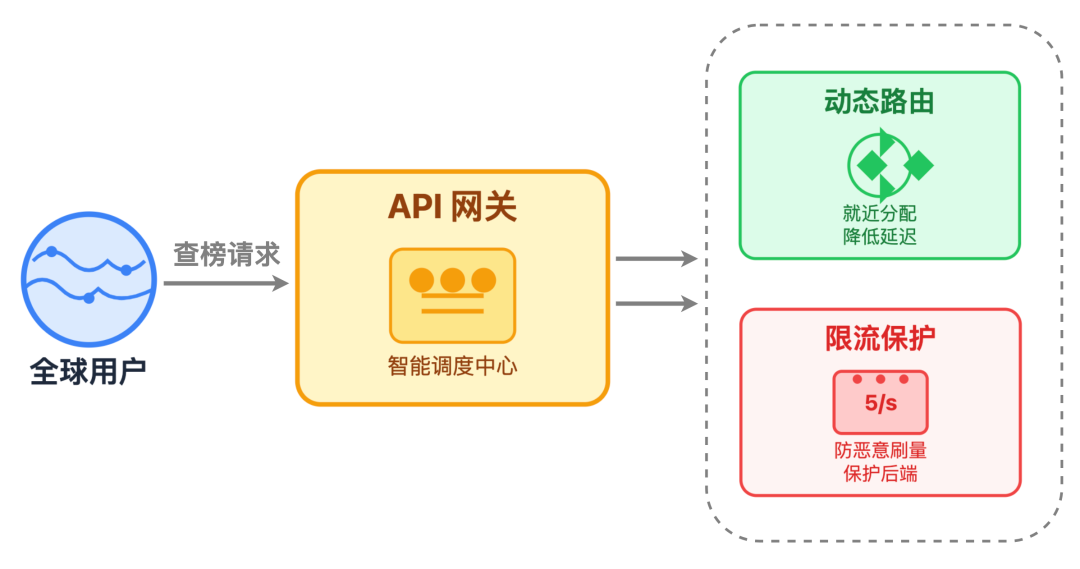
API 网关动态路由
全球用户的查榜请求,会先汇总到 API 网关。它主要做两件事:
- 一是动态路由,根据用户所在地区,自动把请求转发到最近的应用集群,比如北美用户的请求直接分配到美东集群,进一步缩短跨地域访问的延迟;
- 二是限流保护,给单个用户、单个 IP 设定访问上限,比如限制每个用户每秒最多查 5 次榜单,避免恶意刷量冲垮后端服务。
应用集群弹性扩容
应用集群基于 K8s 部署,搭配 HPA 机制,也就是水平 Pod 自动扩缩容,根据实际流量自动调整资源。
比如把 CPU 利用率 70% 设为阈值:当超过 70% 时,比如晚间 8-10 点用户查榜的高峰时段,集群会自动增加 Pod 数量,最多能扩展到 100 个;而当流量回落,CPU 利用率降低时,又会自动缩减 Pod,最低保留 8 个。
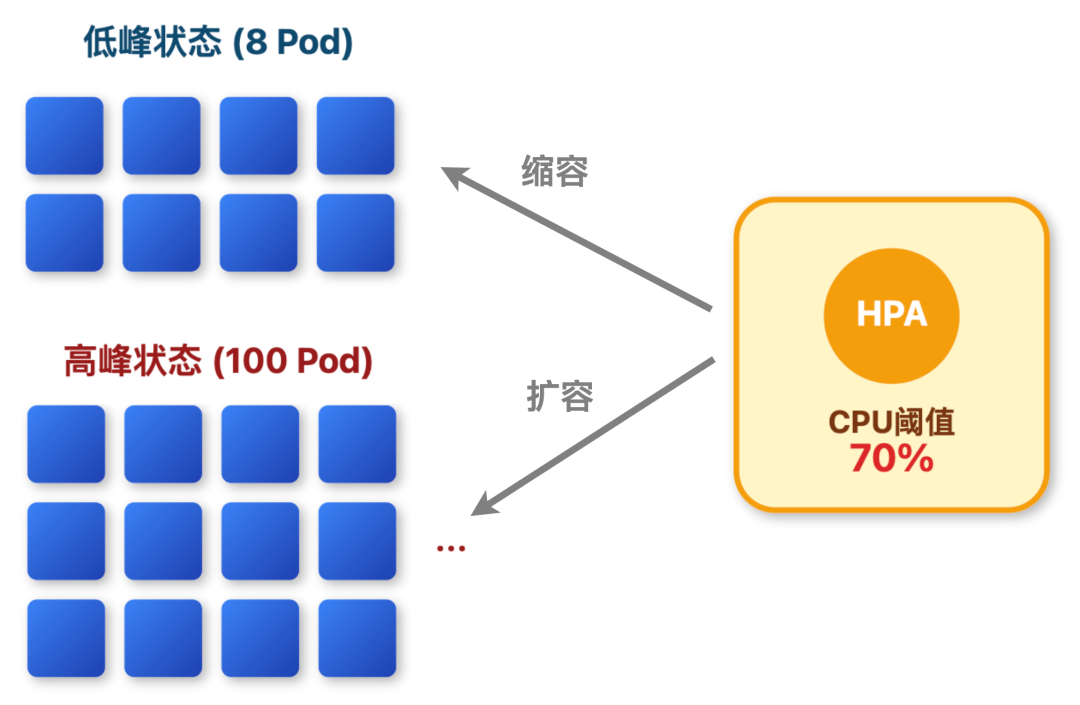
这样既保证了高峰期能扛住压力,又避免了低峰期的资源浪费。
关键实现:亿级场景的避坑指南
基础架构搭好后,系统可能能用,但未必扛得住亿级流量。这些关键实现细节,决定了系统从及格到优秀的差距。
跨分片查询:从慢合并到预计算加速
查询全服 TOP100 榜单时,需要从100个分片中各查 TOP100,得到100×100=10000 个候选结果后,再合并排序取 TOP100。
亿级场景下,这个过程异常耗时,显然无法满足用户对"秒开"的需求,需要优化。
1. 预计算候选集
每个分片每 5 分钟预计算 TOP1000 的榜单数据,把这些数据缓存到本地,合并时从每个分片取 TOP1000,得到100×1000=100000 个候选结果。

虽然数据量增加10倍,但能避免"分片内 TOP100 之外的用户,实际可能是全局 TOP100" 的情况。
2. 分布式合并计算
在应用层,我们用 Java 的 PriorityQueue 也就是小顶堆来合并候选结果,把堆的大小固定为 100。遍历所有候选数据时,只要当前用户的分数高于堆顶分数,就替换堆顶元素,最终堆里剩下的就是全局 TOP100。
不过,100000 条数据的合并耗时约 30ms,再加上 100 次 Redis 查询(每次约 5ms),总耗时会达到 530ms,不满足 P99 延迟 ≤200ms 的主流标准,依然需要优化。
3. 终极优化 — 分层合并
终极解决方案是「分层合并」:先把 100 个分片按机架或可用区,分成 10 个组,每组包含 10 个分片。
第一步先在组内合并,每个组算出自己的 TOP1000;第二步再合并 10 个组的 TOP1000,得到最终的全局 TOP100。
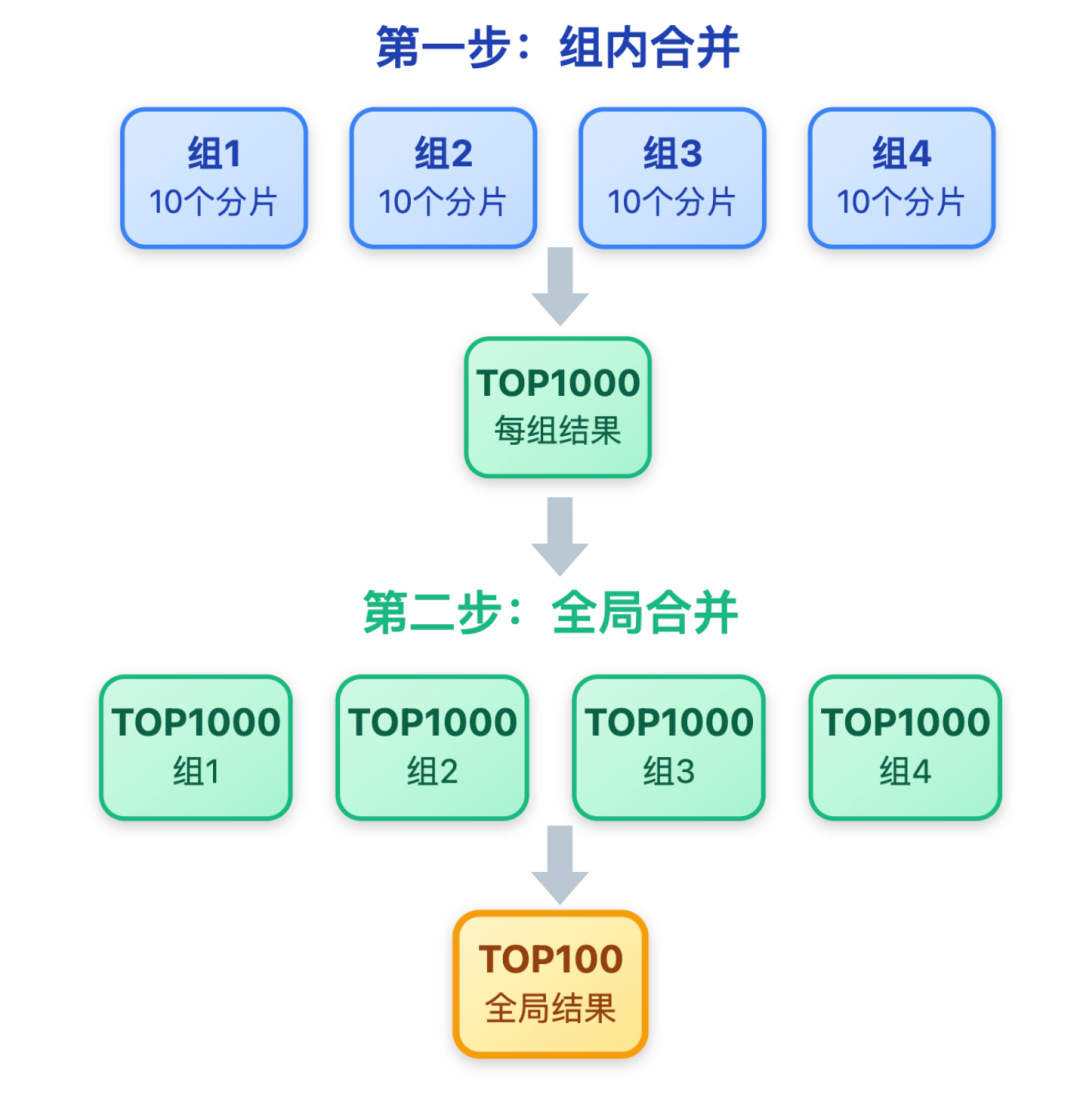
组内合并可以直接在 Redis Proxy 层完成,这样应用层只需发起 10 次组查询,再做一次全局合并即可。优化后总耗时降到 80ms(10 次查询 ×5ms + 合并 30ms),完全满足亿级场景的响应要求。
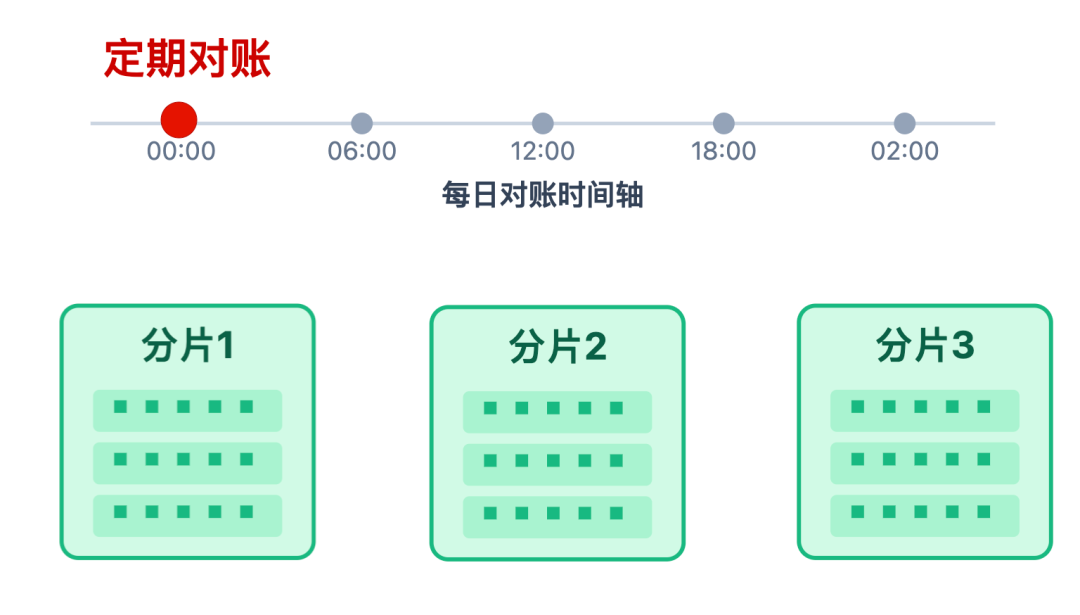
数据一致性:从最终一致到可追溯
亿级场景下,绝对一致性无法实现,因为跨分片实时同步成本太高,但要保证「最终一致+可追溯」。具体通过三层策略实现:
实时数据一致性
主要通过保证单分片原子性,跨分片定期修复的策略实现:
- 单分片内:用 Lua 脚本保证「查询状态 + 修改分数」的原子性,确保高并发下不会出现 “同一用户重复通关,导致通关积分重复增加” 的脏数据。
- 跨分片间:允许短暂的不一致,但每天凌晨会启动定期对账,比对各分片的总分,发现偏差后自动修复。
历史数据一致性
主要通过「批处理对账 + 告警排查」实现。每天用 Spark 批处理计算用户的每日总分,再和 Redis Cluster 中存储的分数总和对比,允许误差控制在 0.1% 以内;如果超过这个阈值,就会触发告警,提醒工程师排查原因。
用户行为可追溯
每一次分数更新操作,都会记录详细日志,包括用户 ID、行为类型、分数增减量、操作时间戳、请求 ID 等。日志通过ELK存储,支持按用户ID/时间范围查询,当用户投诉分数异常时,工程师能通过日志快速定位问题根源。

监控告警体系:亿级下的可观测性
亿级系统"黑盒运行"等于裸奔,必须构建完善的监控告警体系,覆盖分片健康度、数据一致性、性能指标。
1. 分片健康度监控
监控每个 Redis 分片的QPS、内存使用率、响应时间,尤其是响应时间重点关注 P99、P999 分位值。一旦任一指标触及设定的阈值,比如 QPS 超过 1 万、内存使用率超过 80%、P99 响应时间超过 100ms,就会立刻发送告警;

同时监控分片迁移状态,要是迁移速度低于 10MB/s,同样会触发告警,以此避免迁移超时影响服务的可用性 。
2. 数据一致性监控
- 实时监控:每分钟计算 Redis Cluster 的总分波动,若当前总分与 5 分钟前的差值超过 10 万,立即告警。
- 离线对账:每天凌晨比对 Redis 和 ClickHouse 中的历史分数,误差超过 0.1% 就触发告警,确保历史数据不丢不错。
3. 用户体验监控
通过前端埋点收集榜单加载时间,P95>500ms 时触发告警,及时发现CDN缓存失效、应用集群过载等问题。
总结:亿级排行榜的设计心法
设计亿级用户排行榜,本质是对"实时性 - 准确性 - 成本 - 可用性"的四重权衡。记住这6个核心原则,无论面试还是实战都能游刃有余:
1. 大 Key 必须分片,小 Key 优化存储:单ZSet存不下亿级用户,用Redis Cluster按哈希分片;非热门数据启用ziplist编码
2. 实时用 Redis+Lua,批处理用 Spark/Flink
3. 跨分片查询分层合并:先组内合并再全局合并
4. 多级存储控成本:热数据、温数据、冷数据分层存储
5. 数据一致性可追溯:单分片原子操作+定期对账+行为日志,保证最终一致且问题可追溯
6. 监控容灾不可少:分片健康度、数据一致性、用户体验全链路监控,确保系统活下来
最后想说,面试时被问到这类问题,别再直接说"用Redis ZSet"了,先问清楚业务场景,再给出分层方案,这才是面试官想看到的系统设计能力。

图片

图片
学习与交流

图片
如果你在编程面试、技术提升的路上苦苦摸索,别错过!码哥专注聚焦高频面试场景题,深挖技术要点与解题思路,持续输出干货。
公众号定期更新系列知识,帮你精准攻克面试难关。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号