Skills 深度解析:从原理到实践


本文参考 Anthropic 官方发布的 《The Complete Guide to Building Skills for Claude》,结合工程博客、社区实践和企业案例,深入解析 2025 年 10 月推出、12 月正式开放为行业标准的 Agent Skills 技术体系。从架构设计、核心原理、实战开发到企业部署,全方位剖析这一正在重塑 AI Agent 生态的关键技术。
AI Agent 的工程化新范式
2025 年 12 月 18 日,Anthropic 宣布将 Agent Skills 作为开放标准发布,这一举措被业界视为继 Model Context Protocol (MCP) 之后,anthropic在 AI Agent 标准化领域的又一重大布局。 Simon Willison 在其博客中也提到:"Claude Skills 可能比 MCP 更具影响力。"
从skills发布至今四个多月的时间,Skills 已经获得了包括 Microsoft(VS Code 和 GitHub)、Cursor、Goose、Amp、OpenCode 在内的众多平台采用,OpenAI 也在Codex CLI 中实现了结构相近的架构。Anthropic 的 Skills 仓库在 GitHub 上已突破 6 万star,社区创建和分享的skill也在呈现快速发展趋势,比较有意思的是,目前在skills.sh上排名top 1的skill是"find-skills",这不但说明skill的增长速度多到大家都应接不暇,需要一个专门的skill来帮忙查找适合的skill,同时也说明skills还处于发展初期,仍然在继续探索其实际应用价值。
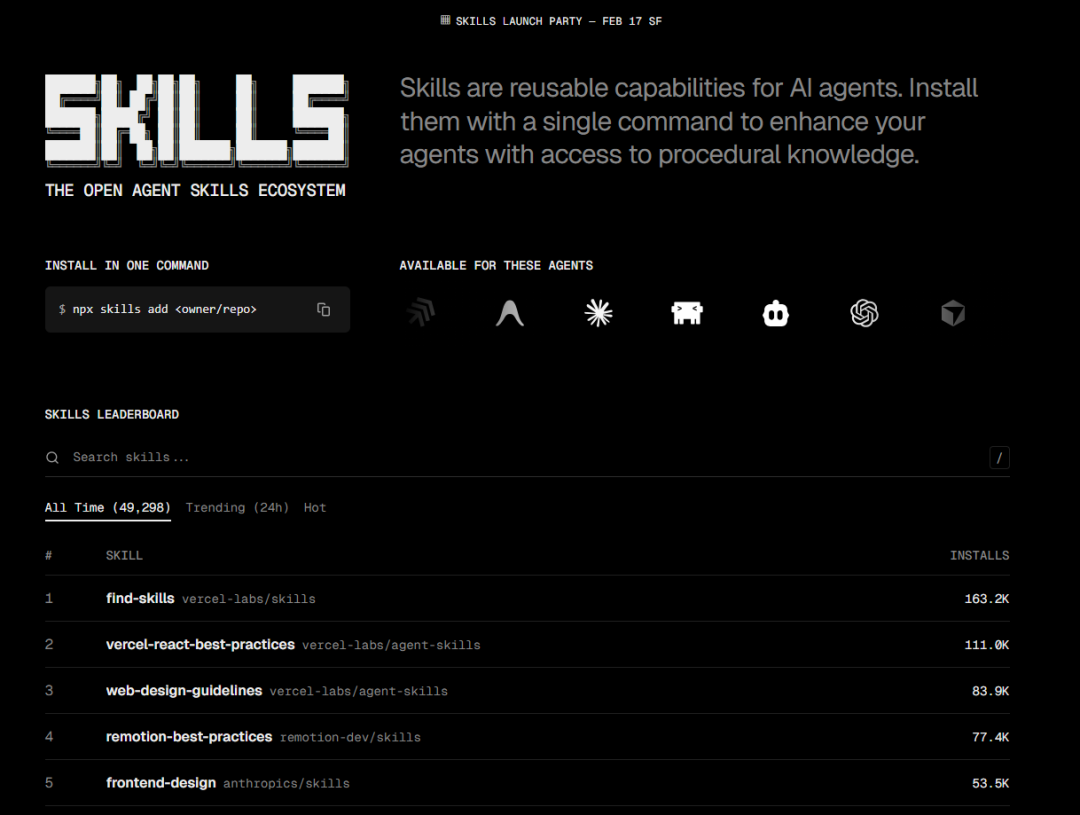
本文将结合anthropic发布的skills构建指南,系统梳理 Skills 的技术架构、设计哲学、开发实践以及应用场景,一起加深对这一agentic工程实践的理解。
业内实践速览
在深入技术细节之前,先看几个检索到真实案例,感受下 Skills 的实际价值。
企业案例
案例 | 应用场景 | 成果 | 来源 |
|---|---|---|---|
Rakuten | 管理会计和财务工作流自动化 | 一天 8 小时任务缩短到 1 小时 | claude.com/skills |
Notion | Skills 让 Claude 与 Notion 无缝协作 | "让用户从提问更快地转向行动,复杂任务更少需要反复调试提示词,结果更可预测" | claude.com/skills,Notion 产品经理 MJ Felix |
Canva | 多平台营销内容生成 | "任何人都可以用一句提示词创建完整的跨平台设计营销方案" | Skills 合作伙伴公告 |
Cloudflare | AI Agent 和 MCP 服务器部署 | "Skills 让一次对话就能将 Agent 部署到 Region:Earth 成为可能" | 同上 |
Figma | 设计稿转代码 | "Claude 能更好地理解 Figma 设计的上下文、细节和意图,精准转化为代码" | 同上 |
以Rakuten AI 为例,团队提到"Skills 让我们的管理会计和财务工作流程显著改善。Claude 同时处理多个电子表格,捕捉关键异常,并按照我们的程序生成报告。曾经需要一天的工作,现在一小时就能完成。"

社区实践
另外社区也有不同个人用户及垂直业务场景落地使用skills的相关案例。
案例 | 应用场景 | 成果 | 来源 |
|---|---|---|---|
SEO 内容优化师 | 将完整 SEO 优化流程封装为单个 Skill | 原本 2+ 小时的初级写手工作量,封装为skill之后几分钟完成 | AI Maker Labs |
客户入职自动化 | 用 Skill 封装客户入职清单:具体步骤、数据库脚本、模板文档 | 每个新客户节省约 4 小时 | Medium: Kristopher Dunham |
会计师资产管理 | 构建资产全生命周期 Skills:购置、折旧、处置 | 自动生成日记账、折旧表(CSV+XLSX)、PPE 滚动报告、损益计算,全部带审计公式 | Medium: Lovely Mcinerney |
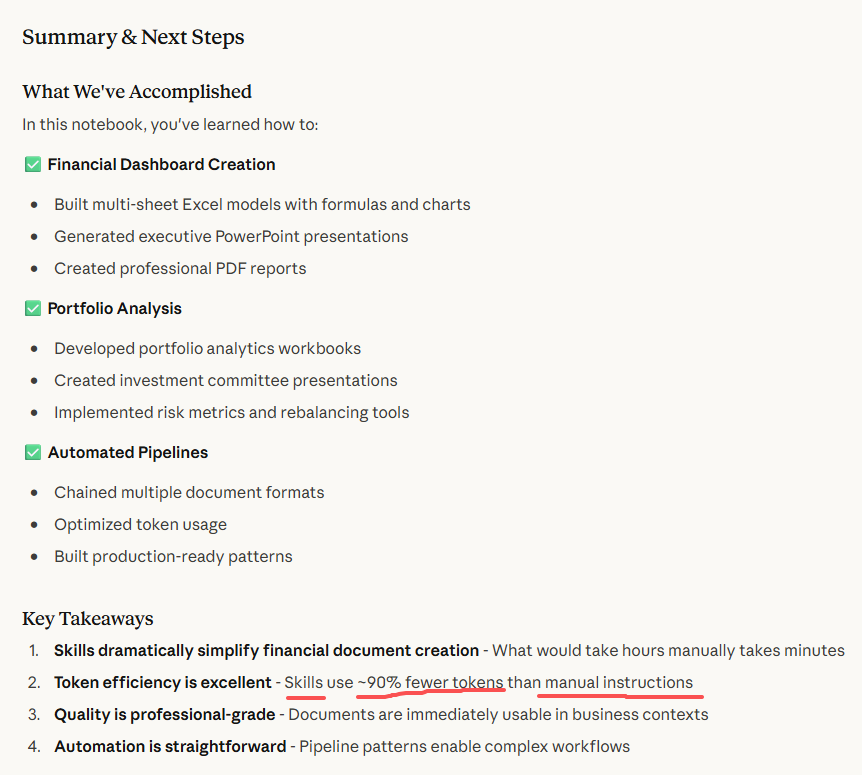
金融报告流水线 | Skills 串联 Excel 分析 → PPT 汇报 → PDF 文档 | 三步自动化流水线,token 效率比手动指令提升约 90% | Anthropic Cookbook |
VentureBeat 在 Skills 发布时的报道中也提到,在特定场景,skill通过精简特定工作流可实现约8倍生产力提升。

这些案例的共同规律:Skills 的价值不在于单次输出的效果有多好,而在于可重复的标准化工作流程所带来的复合效率提升。无论是企业级财务流水线还是个人的 SEO 工作流,核心逻辑一致,把反复输入的提示词和行业经验知识变成一次性封装、持续复用的专业技能。
理解 Skills 的本质
什么是 Skills?
从最简单的定义来看,Skills 是一个包含指令、脚本和资源的文件夹,用于教会大模型如何更好地执行特定任务。这个看似简单的定义背后,也是anthropic对llm,agent应用工程实践积累凝练出来的一套可复用技术手段。

Skills 的核心文件是 SKILL.md,一个包含 YAML 前置元数据和 Markdown 内容的文件。其基本结构如下:
---
name: my-skill-name
description: 技能描述和触发条件
---
# 技能名称
## 指令
[Claude 执行任务时遵循的详细步骤]
## 示例
[具体使用场景]
## 指南
[最佳实践和注意事项]这种设计看起来很简单,简单到有人质疑它是否真的是一个"功能"。毕竟,将额外指令放入 Markdown 文件并告诉 AI 代理读取该文件,这不是很多人早就在做的事情吗?
但正是这种"极简主义"的设计,体现了 Anthropic 团队对 AI Agent 工程化的深刻理解。
Skills 与传统方案的本质区别
要理解 Skills 的真正价值,我们需要与传统方案进行对比。
传统 Prompt Engineering 方案的常见痛点:
- 1. 上下文污染:每次对话都需要携带完整的指令集,消耗大量 token
- 2. 一致性差:不同用户、不同会话可能得到不同质量的输出
- 3. 不可复用:专业知识难以跨会话、跨用户共享
- 4. 维护困难:更新指令需要修改所有相关的 prompt
Skills 的解决思路:
Skills 通过渐进式披露(Progressive Disclosure)机制显著改善了这些问题,这是其最核心的技术设计。
渐进式披露:Skills 的技术基石
渐进式披露是一个三级系统,每一级在不同时机加载不同粒度的信息:
第一级:元数据(YAML 前置元数据)
- • 内容:仅包含
name和description - • 时机:系统启动时加载到 Claude 的系统提示中
- • 作用:为 Claude 提供"技能目录",让它知道有哪些技能可用,以及何时应使用每个技能,而无需将全部内容加载到上下文中。
第二级:完整指令(SKILL.md 主体)
- • 内容:SKILL.md 的主体部分
- • 时机:当 Claude 判断该技能与当前任务相关时加载
- • 作用:提供具体的工作流程和操作指南
第三级:捆绑资源(链接文件)
- • 内容:技能目录内的附加文件(scripts/、references/、assets/ 等)
- • 时机:Claude 根据需要自主导航和发现
- • 作用:提供详细文档、可执行脚本、模板资源等
通过三级知识系统的设计,模型会按照加载顺序,依次触发披露加载元数据,完整指令,并根据SKILL.md指令中提到的对捆绑资源的依赖,进一步调用链接文件资源。这种架构的巧妙之处在于:你可以安装数十个 Skills,但在实际完成特定任务的某个时间节点,上下文窗口中主要只包含与当前任务相关的内容,按需加载,渐进披露。
我们用一个在claude中触发使用skill具体例子说明这个过程:
用户:帮我处理这个 PDF 表单
Claude 目前的内部流程(已内置pdf skill):
1. 扫描系统提示中的技能元数据
2. 发现 "pdf" 技能的描述匹配当前任务
3. 通过 Bash 工具读取 pdf/SKILL.md 到上下文
4. 根据指令,进一步读取 pdf/FORMS.md(专门处理表单)
5. 执行 scripts/extract_form_fields.py(脚本输出进入上下文,但脚本代码本身不进入)
6. 完成任务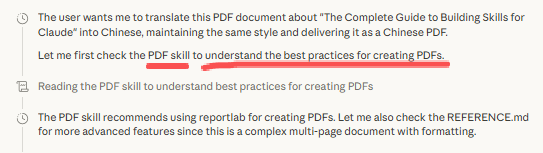
在这个过程中,即使 pdf 技能包含大量参考文档,未被访问的文件基本不消耗上下文 token。
Skills vs MCP:厨房类比
Anthropic 官方提供了一个非常贴切的类比来解释 Skills 和 MCP 的关系:
MCP 是专业厨房:提供工具、食材和设备的访问权限。它解决的是"Claude 能做什么"的问题,包括连接数据库、调用 API、访问文件系统等。
Skills 是食谱:提供如何创造有价值成果的分步说明。它解决的是"Claude 应该怎么做"的问题,提供工作流程、最佳实践、领域知识指引。
MCP(连接性) | Skills(知识) | |
|---|---|---|
功能 | 将 Claude 连接到外部服务 | 教 Claude 如何有效使用这些服务 |
提供 | 实时数据访问和工具调用 | 工作流程和最佳实践 |
回答 | Claude 能做什么 | Claude 应该怎么做 |
这两者的结合,就能比较高效加工出一道美味的佳肴。例如一个 Salesforce MCP 服务器可能只定义了查询语法和 API 格式,而一个 Salesforce Skill 则会告诉 Claude:首先检查哪些记录、如何与 Slack 对话中的上下文交叉引用、如何为团队的流水线审查格式化输出等。
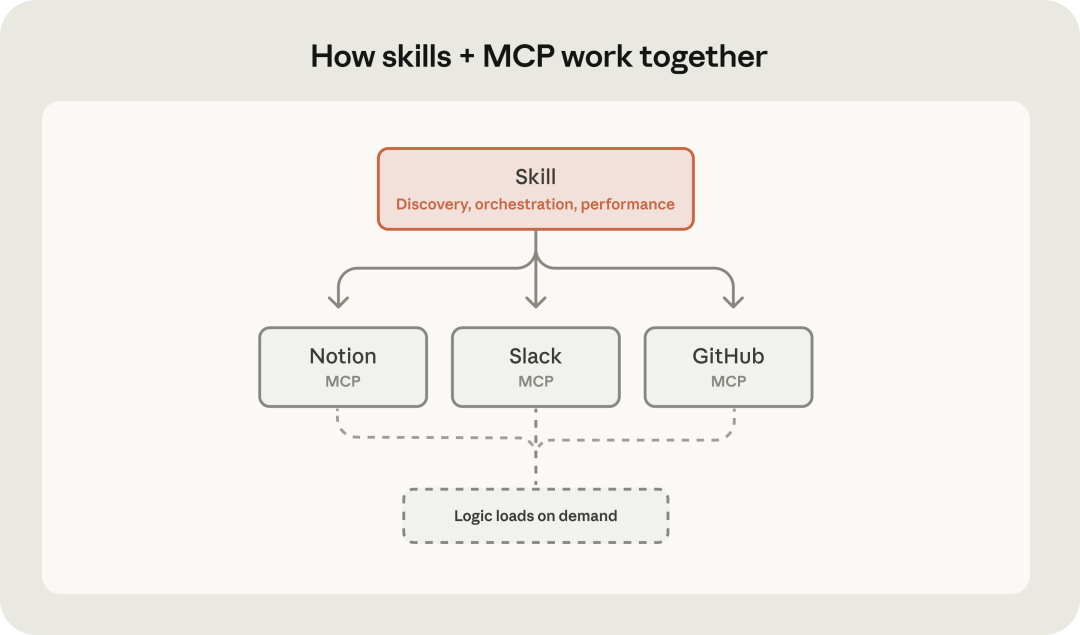
MCP提供了场景所需要的各项基础服务,但是在这个场景下如何有效调用mcp服务来完成组合性任务缺乏有效的可复用技术手段,skills则正好弥补了这个空缺。正如官方指南所强调的:没有 Skills 的 MCP,用户连接后不知道下一步做什么,每次对话都需要从头开始。而有了 Skills,工作流知识会在需要时自动激活注入指导agent参考既定的工作流执行子任务,将最佳实践嵌入到更具体的任务过程中。
Skills 的技术架构深度剖析
文件结构规范
一个完整的 Skill 目录结构如下:
your-skill-name/
├── SKILL.md # 必需 - 主技能文件
├── scripts/ # 可选 - 可执行代码
│ ├── process_data.py
│ └── validate.sh
├── references/ # 可选 - 参考文档
│ ├── api-guide.md
│ └── examples/
└── assets/ # 可选 - 模板和资源
└── report-template.md关键规则:
- 1. SKILL.md 命名:必须精确使用
SKILL.md(区分大小写),不接受任何变体(如 SKILL.MD、skill.md 等) - 2. 文件夹命名:必须使用 kebab-case(如
notion-project-setup),不允许空格、下划线或大写字母 - 3. 禁止 README.md:技能文件夹内不应包含 README.md,所有文档应在 SKILL.md 或 references/ 中。注意:如果通过 GitHub 分发,仓库级别的 README 仍然需要(供人类用户阅读),但它独立于技能文件夹
YAML 前置元数据详解
前置元数据是 Claude 决定是否加载技能的关键。它的设计遵循"最小必要信息"原则:
---
name: skill-name-in-kebab-case
description: 技能做什么以及何时使用它。包含具体触发短语。
---前置的yaml元数据让大模型知道什么时候来加载这个skill,yaml对写入字段也有对应的要求和限制。
字段要求:
字段 | 要求 | 限制 |
|---|---|---|
name | 必需 | 仅小写字母/数字/连字符,应与文件夹名匹配 |
description | 必需 | 最多 1024 字符,不能包含 XML 标签,必须包含"做什么"和"何时使用" |
license | 可选 | 常见:MIT、Apache-2.0 |
allowed-tools | 可选 | 限制技能可访问的工具 |
compatibility | 可选 | 1-500 字符,说明环境要求(目标产品、系统包、网络需求等) |
metadata | 可选 | 任意键值对,建议包含 author、version、mcp-server |
安全限制:
- • 禁止使用 XML 尖括号(< >)
- • 名称中不能包含 "claude" 或 "anthropic"(保留字)
这些限制是出于安全考虑:前置元数据会出现在 Claude 的系统提示中,恶意内容可能会注入指令。
description 字段的艺术
description 是整个 Skill 最重要的部分之一,因为它直接决定了技能何时被触发。Anthropic 工程博客也提到:"这个元数据...仅提供足够的信息让 Claude 知道何时应使用每个技能,而无需将全部内容加载到上下文中。",这也是渐进式披露的第一级信息,如果不能提供清晰正确的描述信息,就不能保证skill会得到准确调用(这个调用逻辑其实和tools调用也比较相似,tools也需要提供清晰的工具使用说明)。
description 的结构公式:
[技能做什么] + [何时使用它] + [关键功能/文件类型]好的描述示例:
# 好 - 具体且可操作
description: 分析 Figma 设计文件并生成开发者交接文档。当用户上传 .fig 文件、要求"设计规范"、"组件文档"或"设计转代码交接"时使用。
# 好 - 包含触发短语
description: 管理 Linear 项目工作流程,包括冲刺规划、任务创建和状态跟踪。当用户提到"冲刺"、"Linear 任务"、"项目规划"或要求"创建工单"时使用。
# 好 - 明确的价值主张
description: PayFlow 的端到端客户入职工作流程。处理账户创建、支付设置和订阅管理。当用户说"入职新客户"、"设置订阅"或"创建 PayFlow 账户"时使用。差的描述示例:
# 太模糊 - "帮助处理项目"几乎什么都能匹配
description: 帮助处理项目。
# 缺少触发器 - 没有告诉 Claude 何时使用
description: 创建复杂的多页文档系统。
# 太技术化,没有用户触发器 - 用户不会这样说话
description: 实现具有层次关系的 Project 实体模型。可组合性与可移植性
除了渐进式披露,Skills 的另外两个核心设计原则同样值得关注:
可组合性(Composability):Claude 可以同时加载多个技能。你的技能应当能与其他技能良好协作,而不是假设自己是唯一可用的能力。所以在设计技能时,应避免过于宽泛的触发条件与其他技能冲突。
可移植性(Portability):skills在 Claude.ai、Claude Code 和 API 中的工作方式基本一致。创建一次,即可在所有支持的平台上使用,前提是目标环境支持技能所需的依赖项。
三类常见应用场景的 Skill
Anthropic 在实践中观察到三类比较常见的 Skill 用例,每类都有其特定的设计模式和适用场景。
类别一:文档与资产创建
用途:创建一致、高质量的输出,包括文档、演示文稿、应用程序、设计、代码等。
实例:frontend-design 技能、docx、pptx、xlsx、pdf 技能
关键技术:
- • 嵌入的风格指南和品牌标准
- • 一致输出的模板结构
- • 完成前的质量检查清单
- • 通常不需要外部工具,可以直接使用 Claude 的内置功能
这类技能的核心价值在于可重复的高质量输出。例如,一个企业的品牌指南技能可能包含:
---
name: brand-guidelines
description: 应用公司品牌标准到所有文档和设计输出。当创建营销材料、演示文稿或面向客户的内容时使用。
---
# 品牌指南
## 颜色规范
- 主色:#1E3A8A(深蓝)
- 辅助色:#3B82F6(亮蓝)
- 强调色:#F59E0B(橙色)
## 排版规范
- 标题:Inter Bold, 24-48px
- 正文:Inter Regular, 16px
- 代码:JetBrains Mono, 14px
## 语气规范
- 专业但友好
- 避免技术术语(除非面向技术受众)
- 使用主动语态
## 质量检查清单
在完成任何输出前,验证:
[ ] 颜色符合品牌规范
[ ] 字体使用正确
[ ] 语气一致
[ ] 无拼写/语法错误类别二:工作流程自动化
用途:受益于一致方法论的多步骤流程,包括跨多个 MCP 服务器的协调。
实例:skill-creator 技能
关键技术:
- • 带有验证门的分步工作流程
- • 常见结构的模板
- • 内置的审查和改进建议
- • 迭代改进循环
这类技能的价值在于将专家知识编码为可重复的流程。一个典型的用于sprint规划的工作流程技能结构:
---
name: sprint-planning
description: 完整的冲刺规划工作流程。当用户说"规划冲刺"、"创建冲刺任务"或"开始新迭代规冲刺计划"时使用。
---
# 冲刺规划工作流程
## 前置条件检查
1. 确认连接到 Linear MCP
2. 确认用户有项目访问权限
3. 检查是否有待处理的上一迭代任务
## 步骤 1:收集上下文
- 通过 MCP 获取当前项目状态
- 分析最近 3 个冲刺的速度
- 识别阻塞项和依赖关系
## 步骤 2:任务评估
- 列出待办事项中的所有任务
- 与用户确认优先级
- 估算每个任务的工作量
## 步骤 3:冲刺构建
- 根据团队产能分配任务
- 设置适当的标签和里程碑
- 创建依赖关系图
## 步骤 4:验证与确认
- 与用户回顾冲刺计划
- 根据反馈调整
- 生成冲刺概览文档
## 错误处理
如果 MCP 连接失败:
1. 检查设置 > 扩展 > Linear
2. 验证 API 密钥状态
3. 尝试重新连接类别三:MCP 增强
用途:为 MCP 服务器提供的工具访问添加工作流程指导。
实例:Sentry 的 sentry-code-review 技能
关键技术:
- • 按顺序协调多个 MCP 调用
- • 嵌入领域专业知识
- • 提供用户否则需要指定的上下文
- • 常见 MCP 问题的错误处理
这类技能的核心洞察是:MCP 提供能力支持,Skills 提供能力组合指引。MCP 服务器给 Claude 提供了"能做什么"的工具接口,但它不知道"该怎么做",按什么顺序调用、遇到异常怎么处理、输出应该符合什么规范。MCP 增强型 Skill 正是填补这个缺口。
实际案例:Sentry 的 sentry-code-review(https://github.com/getsentry/sentry-for-claude) 技能
这个技能"自动分析并修复 GitHub Pull Request 中 Sentry 错误监控数据检测到的 bug"。它是 Sentry 为 Claude Code 发布的官方插件(getsentry/sentry-for-claude)的一部分,与 Sentry MCP 服务器配合工作。整个插件的结构展示了 Skills、MCP、Commands、Agents 如何在同一个插件包中协同:
sentry-for-claude/
├── .mcp.json # MCP 服务器配置(提供 Sentry API 访问)
├── commands/
│ ├── seer.md # /seer 自然语言查询命令
│ └── getIssues.md # /getIssues 获取问题列表
├── agents/
│ └── issue-summarizer.md # 并行分析多个 issue 的 agent
├── skills/
│ └── sentry-code-review/
│ └── SKILL.md # 代码审查工作流技能
└── MCP-SETUP.md这里的关键设计是分层协作:MCP 服务器提供对 Sentry 数据的原始访问能力,而 sentry-code-review Skill 封装了"拿到这些数据后该怎么做"的领域知识—如何识别 Sentry Bot 的评论、如何验证问题的真实性、修复后该生成什么格式的报告。用户只需要说 Review PR #118 and fix the Sentry comments,Skill 就会自动协调整个流程。
五大设计模式
Anthropic 在其指南中总结了五种早期采用和内部团队验证的 Skill 设计模式。这些模式代表了常见的有效方法,但非刚性模板,你可以根据实际场景灵活调整。
模式一:顺序工作流程编排
适用场景:用户需要按特定顺序执行的多步骤流程。
核心结构:
# 工作流程:客户入职
# 步骤 1:创建账户
调用 MCP 工具:`create_customer`
参数:name, email, company
# 步骤 2:设置支付
调用 MCP 工具:`setup_payment_method`
等待:支付方式验证
# 步骤 3:创建订阅
调用 MCP 工具:`create_subscription`
参数:plan_id, customer_id(来自步骤 1)
# 步骤 4:发送欢迎邮件
调用 MCP 工具:`send_email`
模板:welcome_email_template关键技术要点:
- • 明确的步骤顺序
- • 步骤之间的依赖关系
- • 每个阶段的验证
- • 失败时的回滚指令
模式二:多 MCP 协调
适用场景:工作流程跨越多个服务。
核心结构:
# 设计到开发交接
# 阶段 1:设计导出(Figma MCP)
1. 从 Figma 导出设计资产
2. 生成设计规范
3. 创建资产清单
# 阶段 2:资产存储(Drive MCP)
1. 在 Drive 中创建项目文件夹
2. 上传所有资产
3. 生成可分享链接
# 阶段 3:任务创建(Linear MCP)
1. 创建开发任务
2. 将资产链接附加到任务
3. 分配给工程团队
# 阶段 4:通知(Slack MCP)
1. 在 #engineering 发布交接摘要
2. 包含资产链接和任务引用关键技术要点:
- • 清晰的阶段分离
- • MCP 之间的数据传递
- • 在进入下一阶段前验证
- • 集中式错误处理
模式三:迭代改进
适用场景:输出质量可以通过循环迭代得以提高的场景。
核心结构:
# 迭代报告创建
# 初稿
1. 通过 MCP 获取数据
2. 生成初稿报告
3. 保存到临时文件
# 质量检查
1. 运行验证脚本:`scripts/check_report.py`
2. 识别问题:
- 缺少章节
- 格式不一致
- 数据验证错误
# 改进循环
1. 解决每个识别的问题
2. 重新生成受影响的部分
3. 重新验证
4. 重复直到达到质量阈值
# 最终确定
1. 应用最终格式
2. 生成摘要
3. 保存最终版本关键技术要点:
- • 明确的质量标准
- • 迭代改进机制
- • 验证脚本的使用
- • 知道何时停止迭代
模式四:上下文感知工具选择
适用场景:为了实现共同目标结果,对上下文存在依赖的不同工具选择的调用场景。
核心结构:
# 智能文件存储
# 决策树
1. 检查文件类型和大小
2. 确定最佳存储位置:
- 大文件(>10MB):使用云存储 MCP
- 协作文档:使用 Notion/Docs MCP
- 代码文件:使用 GitHub MCP
- 临时文件:使用本地存储
# 执行存储
根据决策:
- 调用适当的 MCP 工具
- 应用服务特定的元数据
- 生成访问链接
# 向用户提供上下文
解释为什么选择该存储关键技术要点:
- • 清晰的决策标准
- • 备选选项
- • 选择透明度
模式五:领域特定智能
适用场景:不局限于通过工具访问知识资源之外的专业领域知识处理。
核心结构:
# 带合规的支付处理
# 处理前(合规检查)
1. 通过 MCP 获取交易详情
2. 应用合规规则:
- 检查制裁名单
- 验证司法管辖区许可
- 评估风险级别
3. 记录合规决定
# 处理
如果合规通过:
- 调用支付处理 MCP 工具
- 应用适当的欺诈检查
- 处理交易
否则:
- 标记待审查
- 创建合规案例
# 审计跟踪
- 记录所有合规检查
- 记录处理决定
- 生成审计报告关键技术要点:
- • 领域专业知识嵌入逻辑
- • 行动前合规
- • 全面文档
- • 清晰治理
选择方法的思路:问题驱动 vs 工具驱动
这五种设计模式可以从驱动方式上来做一个划分,官方指南用了一个很形象的比喻:就像走进五金店。你可能带着一个问题进来,"我需要修一个厨柜",店员可以帮你找到合适的工具,也可能你自己挑了一把新电钻,问怎么用它完成你的具体工作。
Skills 也是如此:
- • 问题驱动:"我需要建立项目工作区"→ 你的技能编排正确的 MCP 调用序列。用户描述期望结果,技能处理工具细节。
- • 工具驱动:"我连接了 Notion MCP"→ 你的技能可以给agent提供notion的最优工作流程和最佳实践。用户获得工具访问权限,技能提供专业指导。
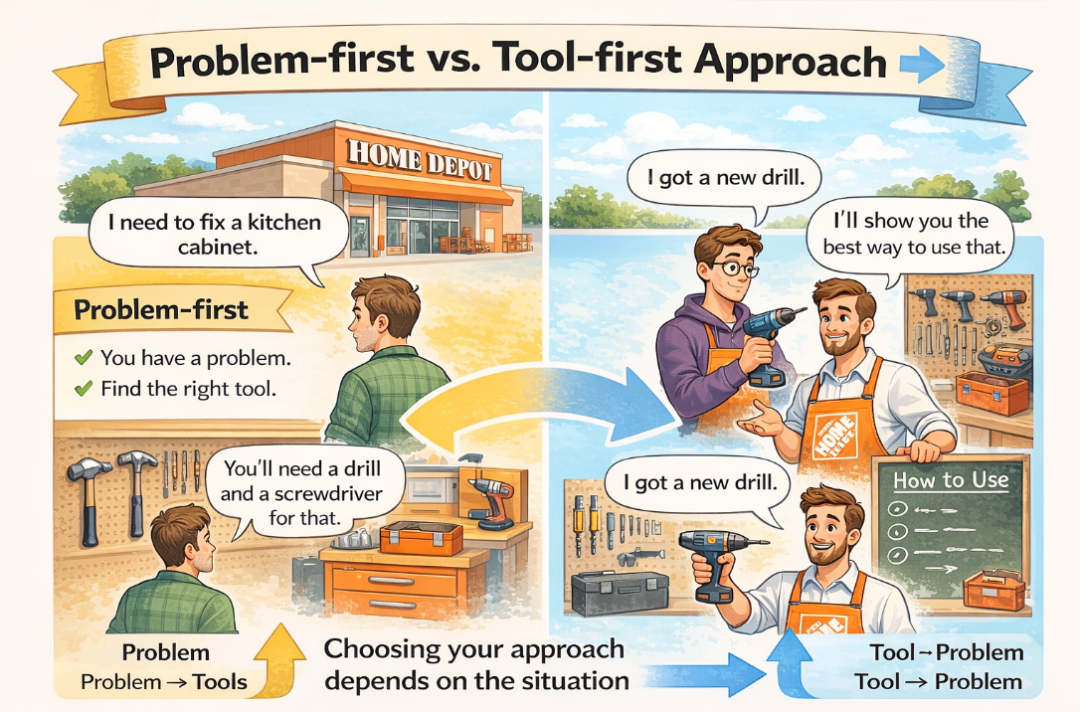
大多数技能的使用会偏向其中一个方向。通过明确你的用例属于哪种,有助于选择合适的设计模式。
Token 效率优化
渐进式披露的量化收益
Skills 的渐进式披露架构在 token 效率上带来了显著的改善。以下是基于架构设计的粗略估算:
加载阶段 | Token 消耗 | 说明 |
|---|---|---|
元数据扫描 | 较少(约几十到上百 tokens/技能) | 所有已安装技能的 name + description |
完整指令 | 通常 <5k tokens | 仅被触发的技能 |
捆绑资源 | 0 tokens | 直到实际访问 |
这意味着即使安装了大量技能,在任何给定时刻的上下文成本可以控制在合理范围内。相比之下,传统方案将所有指令放入系统提示可能导致 token 消耗大幅上升。
不过需要注意,活跃 Skills 过多时,每个技能的元数据都在系统提示中竞争注意力,这可能影响大模型选择正确技能的准确性。
优化策略
策略一:保持 SKILL.md 精简
官方指南建议 SKILL.md 控制在 5,000 词以内。将详细文档移至 references/ 目录并通过链接引用,而非内联在主文件中。
优化后的结构:
skill-example/
├── SKILL.md (~核心指令) # 始终加载
├── references/
│ ├── api-guide.md # 按需加载
│ └── examples/ # 按需加载
└── scripts/
├── validate.sh # 执行但不加载代码本身
└── setup.sh # 执行但不加载代码本身策略二:脚本执行 vs 代码生成
执行捆绑脚本通常比让 Claude 生成等效代码更高效且更可靠。对于关键验证,考虑捆绑一个程序化执行检查的脚本,而不是依赖语言指令。代码是确定性的,语言解释不是。
当 Claude 运行 validate_form.py 时:
- • 脚本代码不进入上下文窗口
- • 只有脚本输出消耗 tokens
- • 确定性执行,无 LLM 推理偏差
策略三:控制同时启用的技能数量
评估你是否同时启用了超过 20-50 个技能。如果是,建议选择性启用,或者考虑将相关技能打包为"技能包"。
CData 的实际案例
CData 在其博客中分享了结合 Skills 和 MCP 可以显著减少 token 使用量的案例。
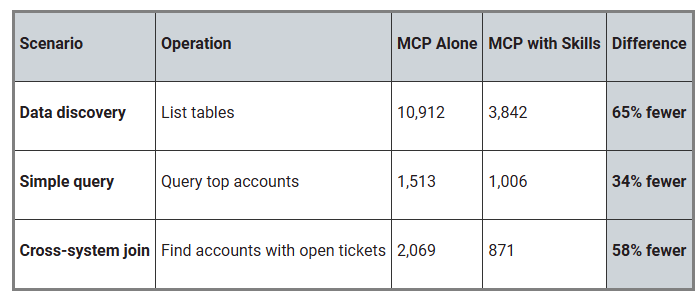
他们的方法主要才用三种结合方式:
- 1. 将重复的 MCP 查询模式封装为 Skills
- 2. 预定义常用的数据转换逻辑
- 3. 使用脚本处理复杂的数据聚合
开发实战参考
快速开始
步骤 1:创建技能目录
mkdir -p my-skill/scripts
mkdir -p my-skill/references步骤 2:创建 SKILL.md
---
name: my-skill
description: 我的第一个技能。当用户说"帮我做 X"时使用。
---
# 我的技能
## 指令
1. 首先,确认用户需求
2. 然后,执行具体操作
3. 最后,验证结果
## 示例
用户说:"帮我做 X"
操作:
1. 执行 A
2. 执行 B
结果:完成 X
## 故障排除
如果遇到问题:
1. 检查 Y
2. 尝试 Z步骤 3:添加脚本(可选)
# my-skill/scripts/helper.py
import sys
def process(input_data):
# 处理逻辑
return f"Processed: {input_data}"
if __name__ == "__main__":
print(process(sys.argv[1] if len(sys.argv) > 1 else "default"))步骤 4:安装和测试
在 Claude.ai:
- 1. 设置 > 功能 > 技能
- 2. 点击"上传技能"
- 3. 选择技能文件夹(压缩为 .zip)
在 Claude Code:
# 复制到技能目录
cp -r my-skill ~/.claude/skills/使用 skill-creator
Anthropic 提供了内置的 skill-creator 技能来辅助开发,可在 Claude.ai 的插件目录中获取,也可下载用于 Claude Code:
"使用 skill-creator 技能帮我为 [您的用例] 构建一个技能"skill-creator 可以:
- • 从自然语言描述生成技能
- • 生成带有正确前置元数据的 SKILL.md
- • 建议触发短语和结构
- • 审查现有技能并提供改进建议
- • 基于你遇到的边缘情况或失败案例进行迭代改进
需要注意的是:skill-creator 帮助你设计和优化技能,但它不会执行自动化测试套件或产生量化评估结果。
调试技巧
检查技能是否被触发:
问 Claude:"你什么时候会使用 [技能名称] 技能?"Claude 会引用 description,帮助你识别触发条件是否正确。
常见问题诊断:
问题 | 可能原因 | 解决方案 |
|---|---|---|
技能不触发 | description 太模糊或缺少触发短语 | 添加具体触发短语,包括技术术语关键词 |
技能触发过度 | description 太宽泛 | 添加负向触发器(如 "Do NOT use for..."),更明确范围 |
MCP 调用失败 | 连接问题或工具名称错误 | 1) 检查 MCP 连接状态 2) 验证 API 密钥 3) 先不通过技能直接测试 MCP 调用 |
指令不被遵循 | 指令太冗长、关键信息位置靠后或措辞模糊 | 简化指令,关键内容前置,使用具体示例,考虑用脚本替代语言指令 |
响应变慢或质量下降 | 技能内容过大或同时启用技能过多 | 将详细文档移至 references/,减少同时启用的技能数量 |
高级技巧:指令不被遵循时
当skill被加载了但是指令没有遵循时,常见的问题主要有两类:指令过于冗长或指令被埋没(在skill文件中)。 针对两种问题也提供了对应的对策,对于指令过于冗长,应该采取以下措施: (1)保持指令的简洁性 (2)使用项目符号和编号列表进行内容规范化表达 (3)将详细说明移至单独的文件
对于指令被埋没,可以考虑: (1)将关键指令放在顶部 (2)使用## 重要或## 关键标题(mrakdown标题语法) (3)根据需要重复重点内容
官方指南也提供了一个指令编写对比实例:
# 不够好 - 模糊
确保正确验证各项内容
# 更好 - 具体且可操作
CRITICAL: 在调用 create_project 前,验证:
- 项目名称非空
- 至少分配了一名团队成员
- 开始日期不在过去此外,如果需要鼓励模型更仔细地执行,在用户提示中添加相关说明(如"请仔细完成,质量比速度重要")通常比在 SKILL.md 中添加更有效。

另外社区还有两点关键经验可供参考:
- • 一技能一职责—诊断技能只诊断,不尝试修复
- • 版本控制集成—技能放在
.claude/skills/,随代码提交
测试与质量保证
测试的灵活性
官方指南明确指出,Skills 可以根据需求选择不同严格程度的测试方式:
- • 手动测试(Claude.ai):直接运行查询并观察行为。迭代快,无需额外设置。
- • 脚本化测试(Claude Code):自动化测试用例,确保跨变更的可重复验证。
- • 程序化测试(Skills API):构建系统性运行的评估套件。
选择哪种方式取决于你的质量要求和技能的使用范围,内部小团队使用的技能和面向数千企业用户部署的技能,测试需求会有所不同。
核心建议:先在单一任务上迭代,再扩展覆盖面
官方指南特别强调了一个实践发现:最有效的技能创建者往往先在一个有挑战性的任务上反复迭代,直到 Claude 能成功完成,然后再将成功的方法提取为技能。这利用了 Claude 的上下文学习能力,比一开始就做广泛测试能更快获得信号。
测试金字塔
Skills 测试应覆盖三个层面:
1. 触发测试(Trigger Tests)
目标:确保技能在正确的时间加载(以创建项目为例)
应该触发:
- "帮我设置一个新的 ProjectHub 工作区"
- "我需要在 ProjectHub 中创建一个项目"
- "为 Q4 规划初始化一个 ProjectHub 项目"
不应该触发:
- "旧金山的天气怎么样?"
- "帮我写 Python 代码"
- "创建一个电子表格"(除非技能处理表格)2. 功能测试(Functional Tests)
目标:验证技能产生正确的输出。
测试:创建带有 5 个任务的项目
给定:项目名称"Q4 规划",5 个任务描述
当:技能执行工作流程
那么:
- 在 ProjectHub 中创建项目
- 创建 5 个具有正确属性的任务
- 所有任务链接到项目
- 无 API 错误3. 性能比较(Performance Comparison)
目标:证明技能相比基线改善了结果。
基线比较:
无技能:
- 用户每次提供指令
- 15 次来回消息
- 3 次需要重试的失败 API 调用
- 12,000 个 token
有技能:
- 自动执行工作流程
- 仅 2 个澄清问题
- 0 次失败的 API 调用
- 6,000 个 token成功标准
Anthropic 建议的成功指标是理想化的目标是粗略的基准而非精确阈值。官方指南原文提到:"追求严谨,但也接受评估中会有 vibes-based(基于感觉的)成分。官方正在积极开发更健壮的测量指导和工具。"
定量参考:
- • 技能在约 90% 的相关查询上触发
- • 测量方法:运行 10-20 个应该触发技能的测试查询,追踪自动加载 vs 需要手动触发的比例
- • 在 X 次工具调用中完成工作流程
- • 测量方法:对比有无技能时完成同一任务的工具调用次数和 token 消耗
- • 每个工作流程 0 次失败的 API 调用
- • 测量方法:监控测试运行期间 MCP 服务器日志中的重试率和错误码
定性参考:
- • 用户不需要提示 Claude 下一步
- • 评估方法:测试过程中记录你需要重定向或澄清的频率,收集测试用户反馈
- • 工作流程完成无需用户纠正
- • 评估方法:对同一请求运行 3-5 次,比较输出的结构一致性和质量
- • 新用户能否在首次尝试时以最少的引导完成任务
结语
Agent Skills 不是一个复杂的技术创新,但是一个集上下文管理,动态调用,渐进式披露等多种大模型工程实践为一体的优雅设计哲学的体现,通过最简单的形式(文件夹 + Markdown)实现强大的功能(可复用的专业知识)。
Skills 的真正价值不在于技术本身的复杂性,而在于它为 AI Agent 的构建提供了一个标准化、可组合、可移植的范式。当你发现自己在多个对话中重复输入相同的提示,在重复执行特定任务的工作流,mcp选择无法准确理解业务逻辑时,就是创建 Skill 的时候了。
个人可以从使用 skill-creator 构建和测试你的第一个skill开始,并且利用你已有的MCP server来构建适合你的当前场景的核心工作流,相对而言,Skills 的学习曲线比较平缓,但其应用潜力则随着你在应用领域的深度扩展和集成而增长。
在企业场景中,Skills 提供了一条将 AI 从实验性工具变为生产力工具的清晰路径。通过将组织的最佳实践、领域知识和工作流程编码为 Skills,企业可以提升 AI 输出的一致性和质量,形成可复用的知识资产,为业务流程赋能,为产品服务增效。当然,这条路径也需要配套的治理框架和持续的迭代优化。
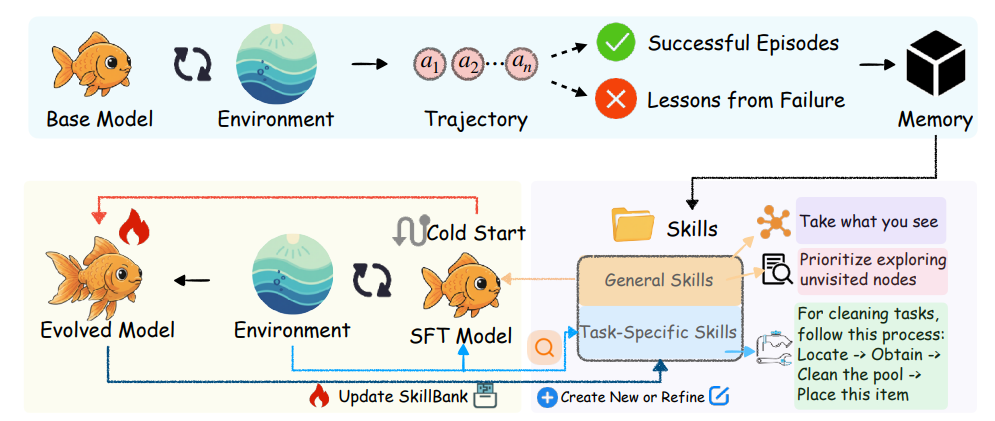
AI Agent 正在快速发展演进,而 Skills 正是这个生态中一块重要的拼图,挖掘更多的隐式知识,抽象更多的人类先验,不仅成为更有效的大模型自动化工具,同时成为agent的持续学习提供训练知识之外的抽象指引,北卡大学教堂山分校最近的一篇论文-SkillRL (https://arxiv.org/pdf/2602.08234),提出一种将agent的“原始轨迹记忆”升级为“可复用skill”的递归技能增强RL学习框架,让 agent 真正从过去经验中抽象出高层策略。Skills 在这一过程中,扮演着知识沉淀和经验抽象的核心作用,推动 Agent 真正从过去经验中抽象出高层策略,探索agent下一阶段的重要核心能力 -> 持续进化。
参考资源
官方文档
- • Skills 文档
- • 最佳实践指南
- • Skills 与 MCP 集成
- • Skills 解释
- • Skills API 快速入门
工程博客
- • 为真实世界装备 Agent 的 Agent Skills
- • 组织技能和目录
社区资源
- • GitHub: anthropics/skills
- • awesome-claude-skills
- • Claude Skills 深度解析
技术分析
- • Simon Willison: Claude Skills 可能比 MCP 更重要
- • Claude Skills vs MCP 技术比较
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号