Nat. Mach. Intell. | 面向材料科研的大语言模型家族:持续预训练揭示模型适应性的关键机制

Nat. Mach. Intell. | 面向材料科研的大语言模型家族:持续预训练揭示模型适应性的关键机制

DrugAI
发布于 2026-03-03 17:48:30
发布于 2026-03-03 17:48:30
DRUGONE
材料发现与开发是应对能源转型、可持续发展与先进制造等全球挑战的关键。尽管大语言模型为加速材料研究带来了前所未有的机遇,但其在实际科研场景中的有效应用仍依赖于深度的领域适配。研究人员提出了面向材料科学的大语言模型家族——LLaMat,通过在约400万篇材料科学论文与晶体结构数据构建的300亿token语料上进行持续预训练,并结合17.5万条材料科学问答数据进行指令微调,构建了一个完整的材料科研“副驾驶”系统。
在覆盖材料科学全流程的42项任务评估中,LLaMat在自然语言处理、结构化信息抽取以及晶体生成等方面均优于主流商业大模型,同时保持良好的通用语言能力。更重要的是,研究人员在系统评估中发现了一个新的现象——“适应刚性”:在超大规模预训练后,模型对领域再适配反而表现出更强的刚性。这一发现对未来科学领域专用AI系统的设计具有重要启示意义。

材料创新对联合国可持续发展目标中的多个关键议题具有决定性影响。然而,材料科学文献数量已超过一亿篇,信息爆炸使研究人员难以高效获取、整合和利用知识。材料科研迫切需要能够处理海量非结构化文本与半结构化数据的智能助手。
大语言模型在文本理解与生成方面展现出卓越能力,并已在材料识别、合成路径推断、晶体生成与实验规划等环节展现潜力。然而,通用模型在理解材料专业术语、物理定律、晶体结构表示等方面存在明显不足。现有工作多为局部任务优化,缺乏一个覆盖材料科研全流程的统一基础模型。
为解决这一问题,研究人员构建了LLaMat模型家族,通过持续预训练与多阶段微调,使模型同时具备文献理解、结构化信息抽取与晶体生成能力,从而形成一个面向材料研究的综合性AI副驾驶系统。
方法
LLaMat的构建分为三个阶段。首先,在名为R2CID的大规模语料上进行持续预训练,该语料由材料科学论文、晶体结构文件以及少量通用语料混合构成,以避免通用能力遗忘。
其次,研究人员设计了双路径微调方案。一条路径构建LLaMat-Chat,用于文献分析与信息抽取;另一条路径构建LLaMat-CIF,专注于晶体结构理解与生成。指令微调数据涵盖通用问答、数学推理以及材料科学专属任务,以保持模型在定量推理与领域知识之间的平衡。
最后,通过任务级微调与参数高效微调,使模型能够适配材料自然语言处理任务与晶体生成任务。
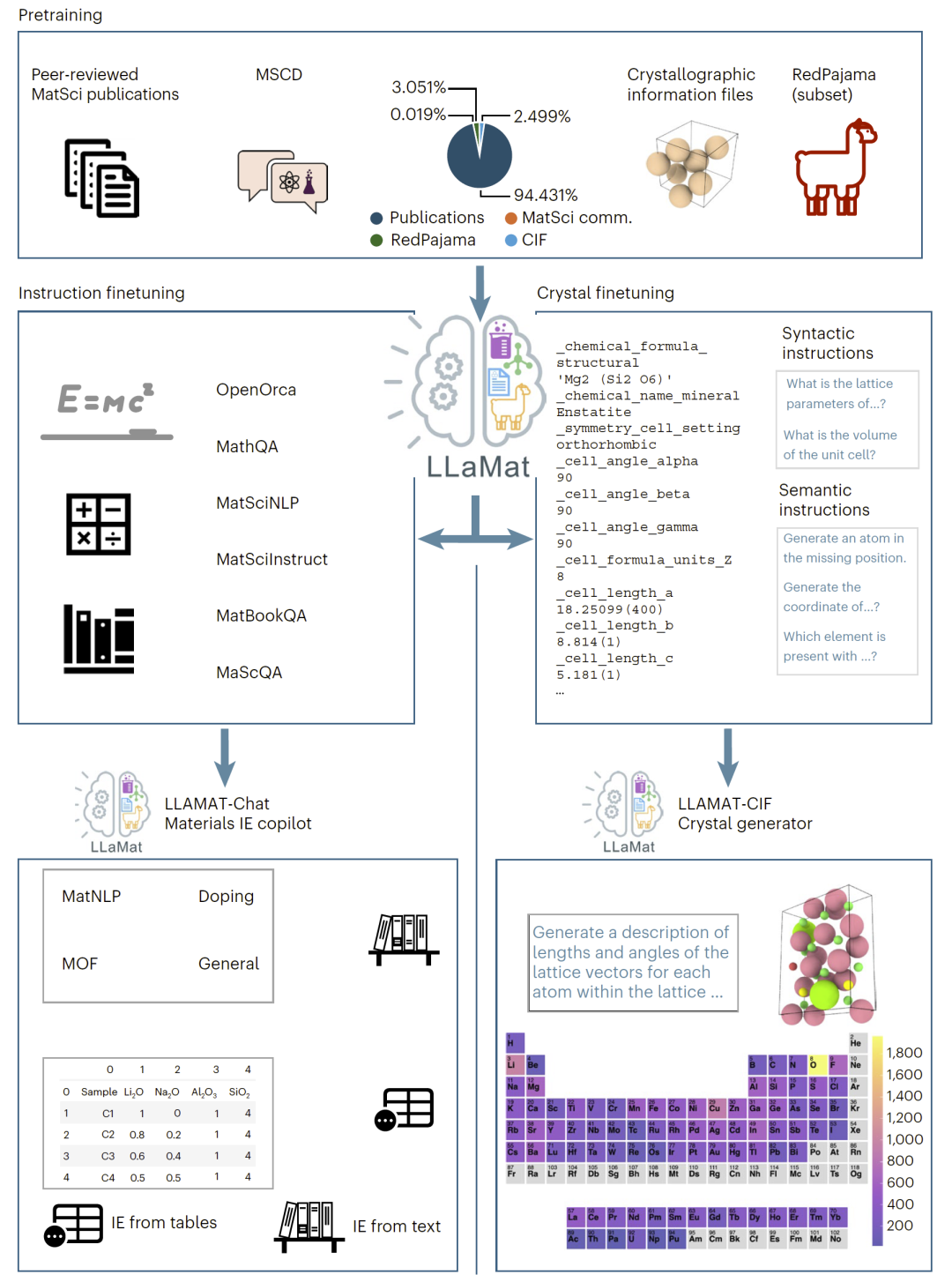
图1: LLaMat在综合材料科学研究中的开发流程与核心能力示意图。
结果
材料语言处理能力
在包含14个材料专属任务与通用任务的MatNLP基准上,LLaMat显著优于基础模型与商业模型。无论是实体识别、关系抽取还是文本分类任务,领域适配模型均表现出更高的F1分数。
有趣的是,尽管LLaMA-3基础模型整体能力更强,但在材料领域适配后,LLaMat-2系列反而在多项材料任务中表现更优。这种反常现象提示模型规模与领域适配效果之间并非简单正相关。
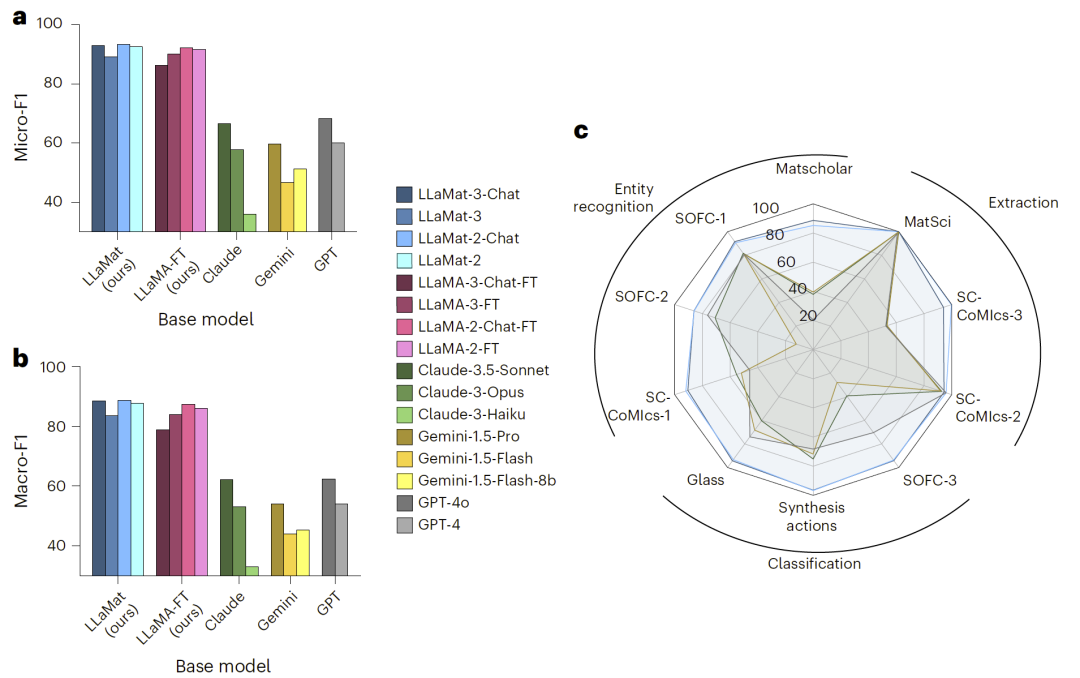
图2: LLaMat作为材料科研“副驾驶”系统的性能评估:与商业大模型及基线模型的对比分析。
结构化信息抽取
在掺杂研究、MOF体系及一般材料文本的结构化信息抽取任务中,LLaMat-Chat模型持续优于商业模型,尤其在复杂材料关系抽取方面表现突出。
在材料表格数据抽取任务中,LLaMat-2-Chat整体略优于商业模型,尤其在正则表达式型复杂表格识别方面表现出明显优势。但在部分通用表格结构理解上,商业模型仍具一定竞争力。
适应刚性现象
系统比较显示,LLaMA-2在领域微调后的性能提升幅度远高于LLaMA-3。例如,在材料NLP任务中,LLaMA-2微调后性能提升超过600%,而LLaMA-3提升幅度仅约140%。
然而,在通用英语任务中,LLaMA-3仍保持优势。这表明,大规模预训练可能形成强烈的通用语言表征结构,从而在一定程度上限制模型向特定领域迁移的能力。研究人员将这一现象称为“适应刚性”。
归因分析显示,LLaMat-2形成了更集中、更具领域特异性的token关联模式,而LLaMat-3则表现出更均匀、分散的表征结构。
晶体结构生成
在无条件晶体生成任务中,LLaMat-2-CIF在结构有效性、稳定性与生成效率方面均优于LLaMat-3-CIF。其生成的结构更接近热力学稳定区域,并具有合理的元素组合分布。
在条件生成任务中,LLaMat-2-CIF在成分匹配与空间群匹配上远优于LLaMat-3-CIF,差距高达70个百分点以上。这进一步强化了适应刚性的结论。
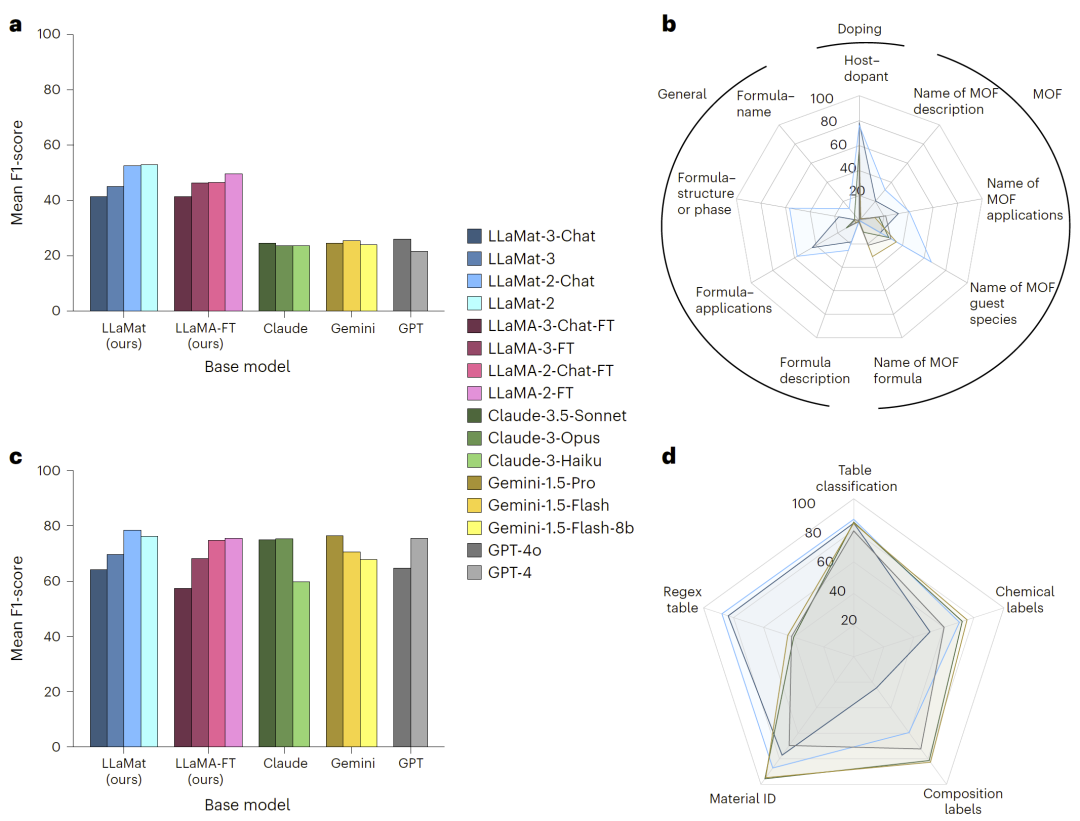
图3: LLaMat在材料科学各子领域中的结构化信息抽取能力评估结果。
讨论
本研究表明,通过持续预训练与针对性指令微调,中等规模模型可以在材料科研任务上超越更大规模的通用商业模型。这为科学领域AI的经济部署提供了可行路径。
更具理论意义的是,研究人员首次系统提出“适应刚性”概念,揭示预训练规模与领域适配能力之间可能存在非单调关系。这挑战了传统“模型越大越好”的扩展假设。
LLaMat模型家族在文献分析、结构化信息抽取与晶体生成之间形成互补能力,为构建“代理式科研系统”奠定基础。未来工作应进一步探索该适应规律在不同模型架构与科学领域中的普适性,并推动模型与实验验证流程的深度整合。
整理 | DrugOne团队
参考资料
Ahlawat, D., Mishra, V., Singh, S. et al. A family of large language models for materials research with insights into model adaptability in continued pretraining. Nat Mach Intell (2026).
https://doi.org/10.1038/s42256-026-01199-8

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号