Chem. Sci. | 利用领域专用大语言模型实现少样本分子性质优化

Chem. Sci. | 利用领域专用大语言模型实现少样本分子性质优化

DrugAI
发布于 2026-03-03 17:31:38
发布于 2026-03-03 17:31:38
DRUGONE
研究人员提出 DrugLLM,一种专门面向小分子优化的大语言模型。该模型通过功能基团级别的分子表示方法(FGT)对分子进行语义化分词,并设计了“下一步修改预测”学习框架,使模型能够从少量历史分子修改案例中学习结构–性质关系,从而逐步生成具有更优药理性质的新分子。计算实验表明,DrugLLM在少样本分子优化任务中达到当前最佳性能,甚至超过主流语言模型。进一步在HCN2抑制剂设计任务中,模型生成的两个候选分子经过湿实验验证显示出更强的抑制活性,证明该方法在真实药物发现中的潜力。

大语言模型在自然语言与代码等领域展现出强大的少样本学习能力,但在化学领域仍面临困难,因为分子的语义并不体现在字符语法,而体现在三维结构和电子性质中。尤其在药物发现中的分子优化阶段,需要不断迭代修改候选分子以满足复杂的药代和药效要求,而传统物理模拟方法计算成本极高,数据驱动模型又通常需要大量标注样本,这使得真实场景中很难应用。
研究人员认为,大语言模型的上下文学习机制本质上类似于药物化学家的推理过程,可以从有限的结构修改案例中总结规律。因此,本研究尝试将分子优化问题重构为序列生成任务,使模型能够像专家一样理解分子修改对性质的影响,并据此进行设计。
方法
DrugLLM的核心由两个关键设计组成。首先,研究人员提出功能基团分词表示FGT,将分子分解为具有化学意义的结构片段,从而显著缩短序列长度并提高表示一致性。其次,提出“下一步修改预测”学习范式,将分子优化过程表示为连续的结构修改序列,使模型通过自回归方式预测下一步分子结构。研究人员从ZINC和ChEMBL数据库构建了包含数亿分子修改记录的大规模训练语料,并基于Transformer架构训练70亿参数模型,使其能够在无需微调的情况下执行少样本和零样本分子优化任务。
DrugLLM框架与FGT表示
研究人员首先介绍了DrugLLM的表示体系。传统SMILES表示在结构微小变化时可能产生完全不同的字符串,从而增加建模难度。FGT通过将分子分解为功能基团并按核心到外围的顺序排列,使模型能够把结构片段作为整体语义单元进行学习。实验表明,FGT可将序列长度平均缩短约一半,同时保持高精度结构重建能力,从而为语言模型训练提供稳定输入。
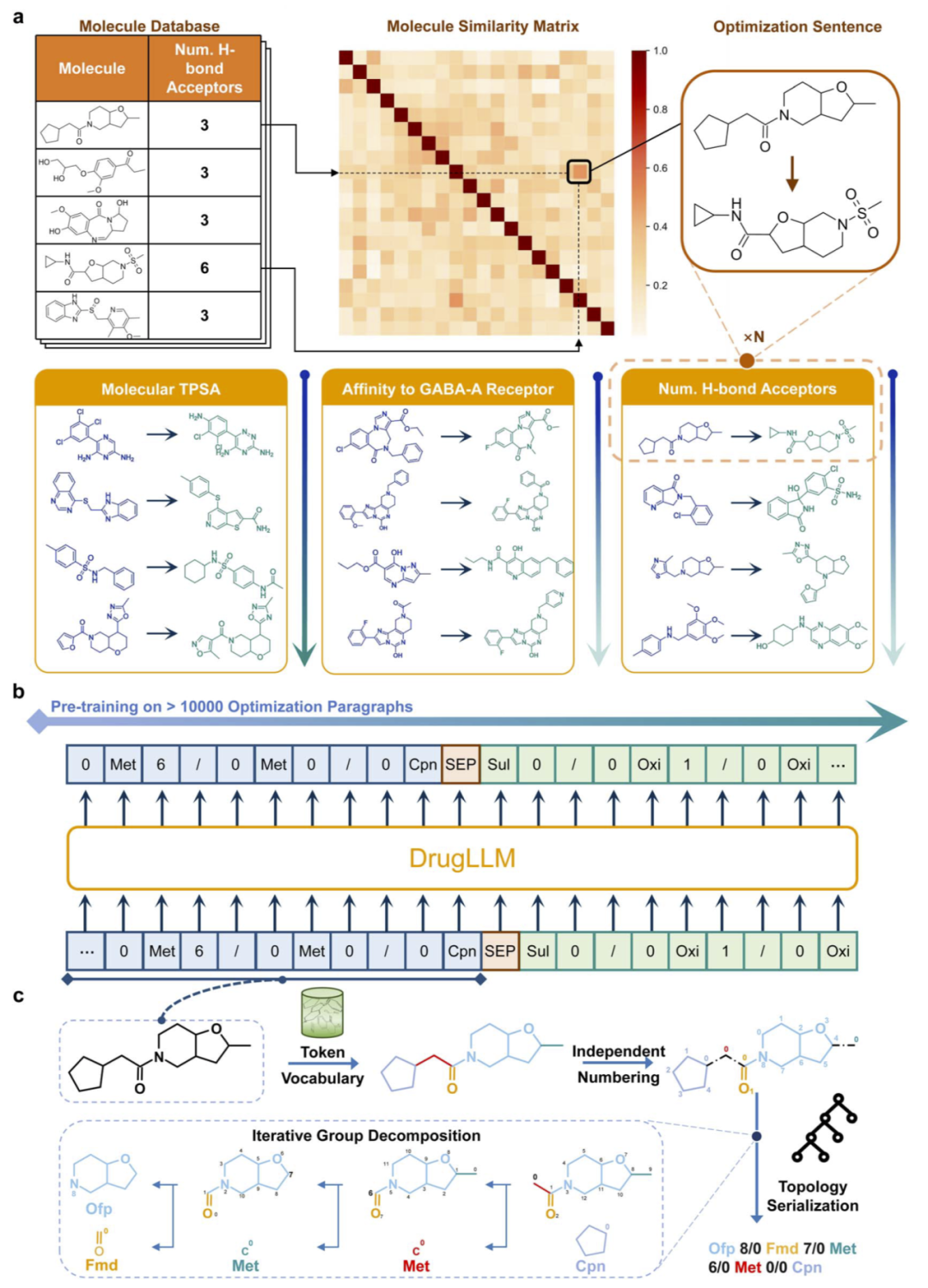
图1|DrugLLM框架示意图。
少样本理化性质优化
在少样本分子优化任务中,模型需要根据少量示例修改对新的分子进行改进。研究人员在未参与训练的四种理化性质(如LogP、溶解度等)上进行测试。结果显示,生成分子的性质分布整体向优化方向移动,同时保持与原分子相似的结构空间分布。与多种经典生成模型相比,DrugLLM在成功率方面显著更高,并且只需要极少的上下文示例即可达到类似性能。
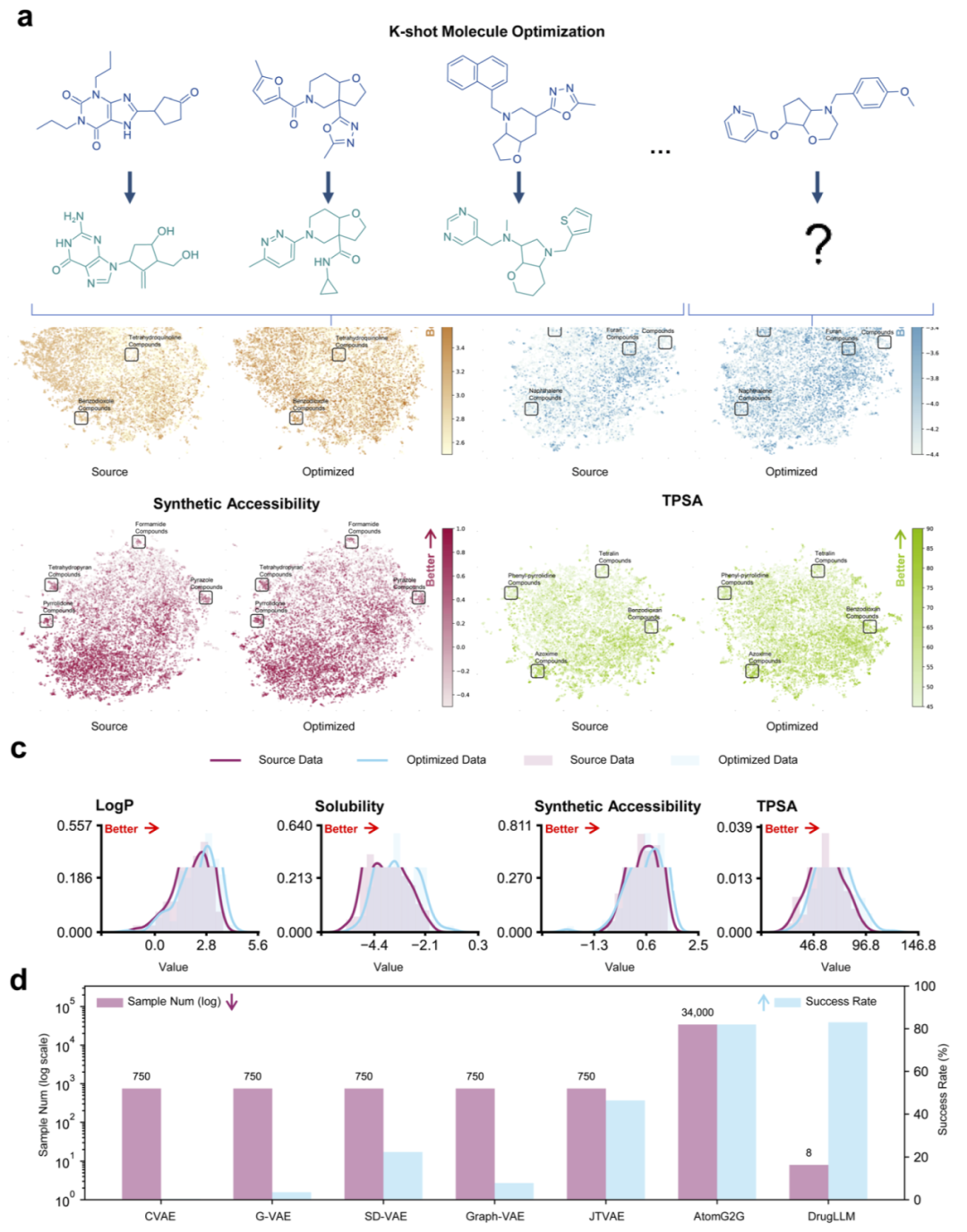
图2|少样本分子优化中分子分布的对比。
进一步分析发现,随着示例数量增加,DrugLLM的优化成功率逐步提升至约0.72,而传统生成模型表现接近随机水平。FGT表示的模型明显优于SMILES表示版本,说明语义化分词对于语言模型学习分子规则具有重要作用。
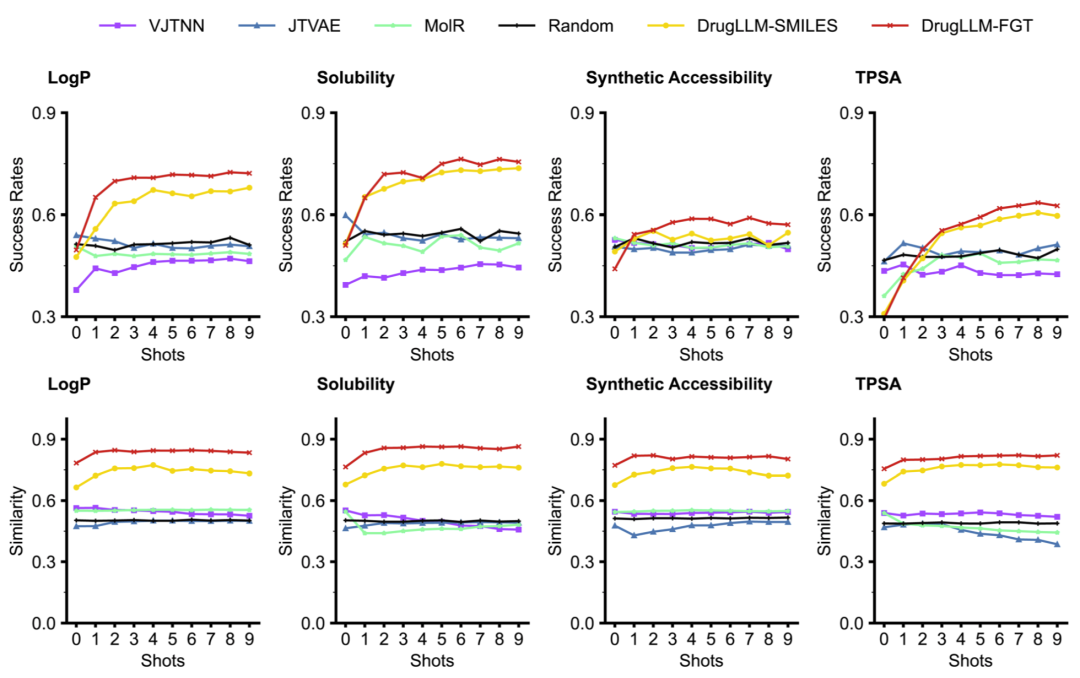
图3|不同生成方法在少样本分子优化任务中的性能比较。
少样本生物活性优化
研究人员随后测试模型在更复杂的生物活性优化任务中的能力。由于真实实验数据昂贵,研究人员使用经过训练的性质预测模型评估生成分子。实验覆盖二十个未在训练集中出现的靶点。结果显示,传统分子生成模型几乎无法在这些任务中取得有效提升,而DrugLLM在多数靶点上显著提高优化成功率,例如某些Ki任务成功率达到0.76。这说明模型能够从少量示例中推断新的结构修改规律。
零样本分子优化能力
研究人员进一步测试DrugLLM在零样本条件下的表现,即只给出自然语言优化目标而不给示例。结果表明,通用语言模型虽然能理解指令,但优化成功率较低,而DrugLLM在所有测试组合任务中均取得更高成功率,显示其能够将已学习的单属性规则组合推广到新的多属性优化任务。
HCN2抑制剂真实药物设计验证
为了验证模型的实际应用价值,研究人员使用DrugLLM优化已知药物ivabradine以提高其对HCN2通道的抑制能力。模型生成多个候选分子,研究人员选择其中两个进行合成与电生理实验测试。实验结果显示,这两个分子的IC50显著低于原始化合物,抑制能力约提高三倍。同时模型注意力分析显示,其在生成过程中重点关注关键药效基团,说明模型学习到了真实的结构–活性关系。
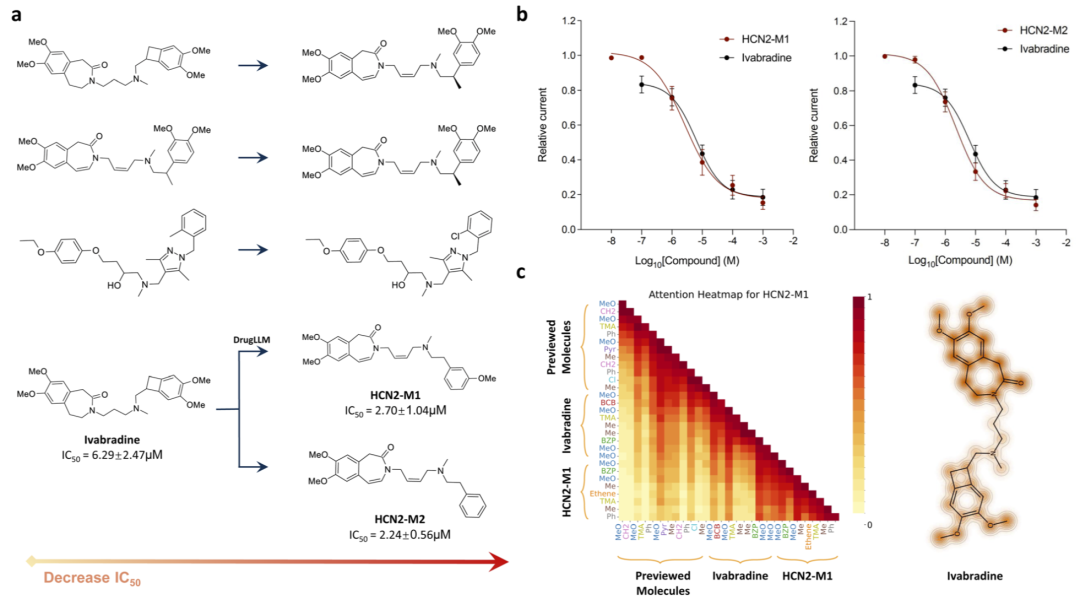
图4|DrugLLM在HCN2抑制剂优化中的应用。
讨论
研究人员提出的DrugLLM展示了一种新的分子优化范式,即利用语言模型在少样本条件下学习结构修改规则。实验结果表明,该模型能够在大量理化性质和生物活性任务上超过现有方法,并在真实实验中成功生成更有效的候选分子。模型在优化过程中往往自然保持核心骨架,仅对外围结构进行修改,这种行为与药物化学家的优化策略一致,说明模型确实学习到了合理的设计逻辑。
尽管如此,该方法仍存在局限,例如零样本优化能力仍较基础,同时目前只能处理单属性或简单双属性优化,复杂多目标设计仍需进一步研究。此外,湿实验验证规模仍有限,未来需要更系统的实验评估和更复杂的设计任务。
总体而言,该研究展示了专用大语言模型在药物分子设计中的巨大潜力,为基于语言模型的自动化药物优化提供了新的技术路线。
整理 | DrugOne团队
参考资料
Guo, Y.; Luo, M.; Zhang, W.; Liu, P.; Liu, J.; Huang, S.; Lv, J.; Ke, B.; Liu, X. Few-shot molecular property optimization via a domain-specialized large language model. Chem. Sci. 2026, DOI: 10.1039/D5SC08859C.

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号