Nat. Biotechnol. | 利用蛋白质语言模型定制CRISPR–Cas的PAM特异性

Nat. Biotechnol. | 利用蛋白质语言模型定制CRISPR–Cas的PAM特异性

DrugAI
发布于 2026-03-03 17:09:39
发布于 2026-03-03 17:09:39
DRUGONE
CRISPR–Cas基因编辑系统在识别靶序列时必须依赖一种称为PAM(原间隔序列邻近基序)的短DNA序列,这一限制显著缩小了可编辑基因位点的范围。尽管已有多种工程化策略用于改变Cas蛋白的PAM识别特异性,但这些方法通常需要大量重复实验与长期筛选。研究人员提出了一种基于蛋白质语言模型的深度学习框架Protein2PAM,能够直接从 Cas 蛋白序列预测其PAM偏好,并高效引导定制化 Cas变体设计。该模型在超过4.5万个CRISPR–Cas PAM 数据上训练,可跨多种 CRISPR 类型准确预测PAM特性,并在无需结构信息的情况下识别关键识别位点。研究人员进一步利用该模型对Cas9进行计算进化,成功获得具有更宽PAM识别范围且活性显著增强的新型酶变体,为个性化基因编辑提供了强有力工具。

PAM 是 CRISPR–Cas 系统实现靶向切割的核心识别信号,在自然进化过程中,不同 Cas 蛋白通过与病毒和质粒的长期博弈形成了多样化的 PAM 识别模式。在基因编辑应用中,严格的 PAM 依赖性虽能提升特异性,但同时限制了可操作的基因位点范围,给精细化编辑技术带来挑战。以往的工程化方法多依赖结构指导突变或实验进化筛选,不仅成本高昂,而且难以快速针对特定需求定制 PAM 规则。因此,亟需一种能够从大规模进化信息中学习规律,并实现一次性精准设计的新策略。
PAM进化图谱的系统构建
研究人员通过对超过26太碱基的微生物基因组与宏基因组数据进行系统挖掘,构建了一个大规模 CRISPR–Cas PAM 图谱数据库。他们通过将 CRISPR 间隔序列与病毒和质粒基因组比对,识别靶序列两侧保守的 PAM 模式,最终获得45,816个不同的 PAM 预测结果,涵盖I型、II型与V型 CRISPR系统。分析显示,II型系统的 PAM 多样性最高,进化变化也最快,而I型与V型系统则表现出高度保守性。这一大规模数据集为后续机器学习建模提供了坚实基础。
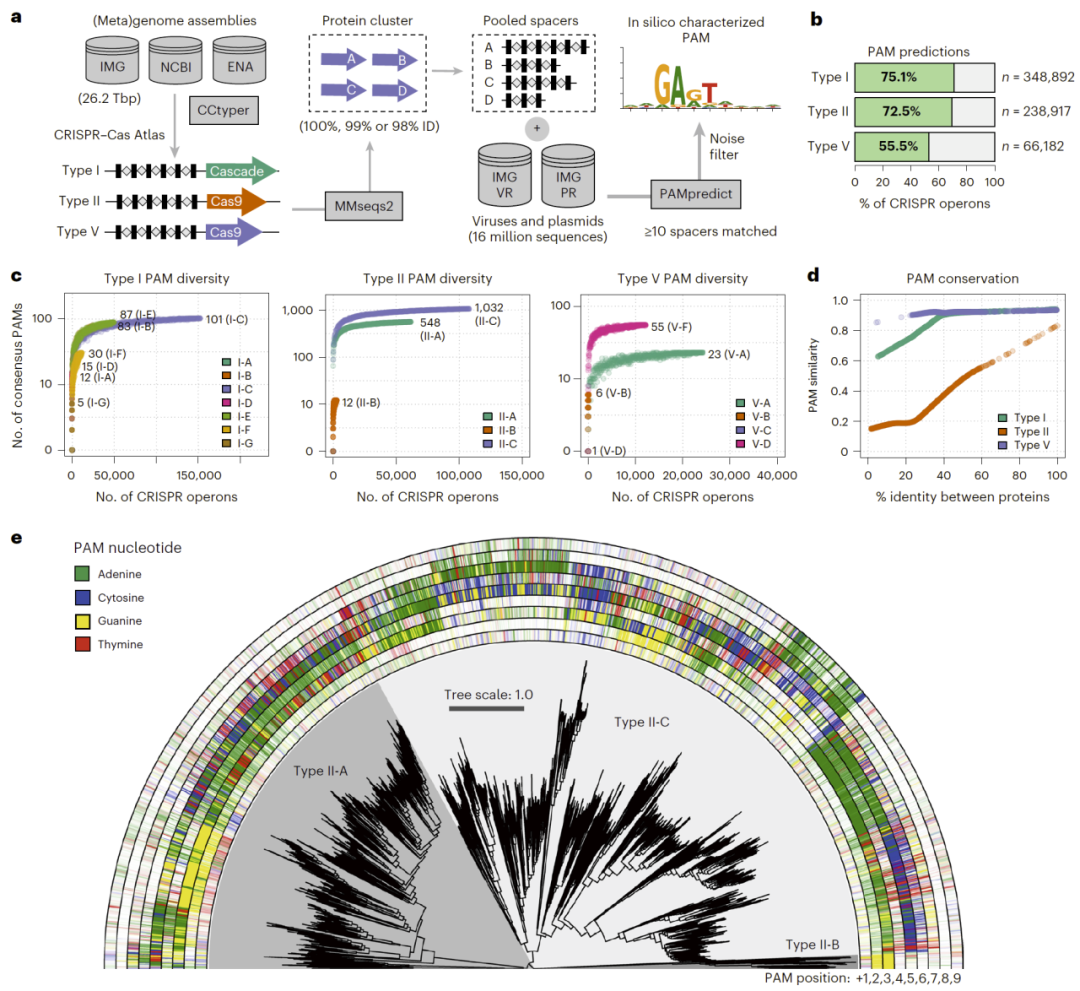
图1:CRISPR–Cas PAM系统性挖掘流程与进化多样性分析。
Protein2PAM模型框架
在此基础上,研究人员构建了 Protein2PAM 深度学习模型。该模型以大规模预训练蛋白质语言模型作为编码器,提取 Cas 蛋白序列中的进化与功能特征,再通过神经网络预测每个 PAM 位点的碱基概率分布。针对不同 CRISPR 类型,研究人员选择了负责 PAM 识别的关键蛋白区域进行建模,从而提高泛化能力。模型在多种 CRISPR 系统中均展现出高预测精度,显著优于传统基于间隔序列比对的方法,并且在计算效率上提升数百倍。
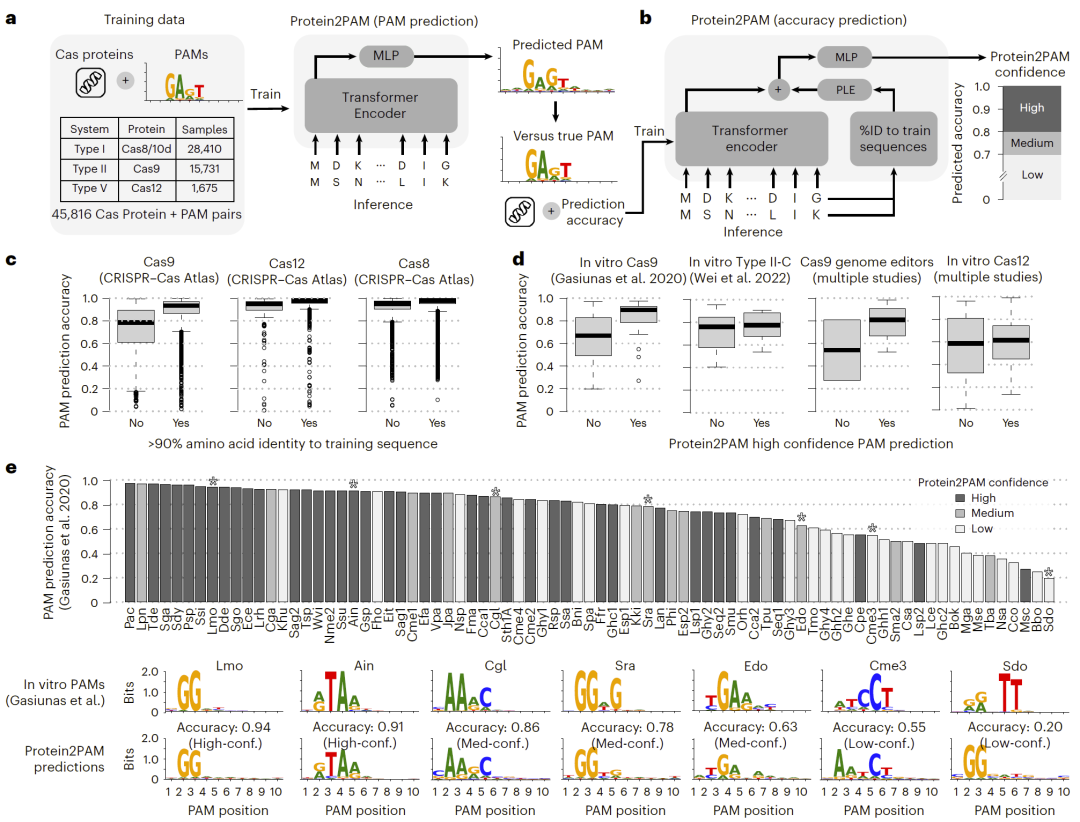
图2:Protein2PAM模型结构与预测性能评估。
与现有方法的对比优势
研究人员将 Protein2PAM 与当前主流 PAM 预测工具 PAMpredict 进行了系统比较。结果显示,Protein2PAM 能为超过九成的 CRISPR 操作单元提供高置信度预测,而传统方法仅覆盖约三成。尤其在V型系统中,由于可匹配间隔序列稀缺,传统方法几乎失效,而 Protein2PAM 依然保持高灵敏度。同时,Protein2PAM 在GPU环境下仅需数分钟即可完成上万条预测任务,而传统方法往往需要数天计算时间,显示出显著的实用优势。
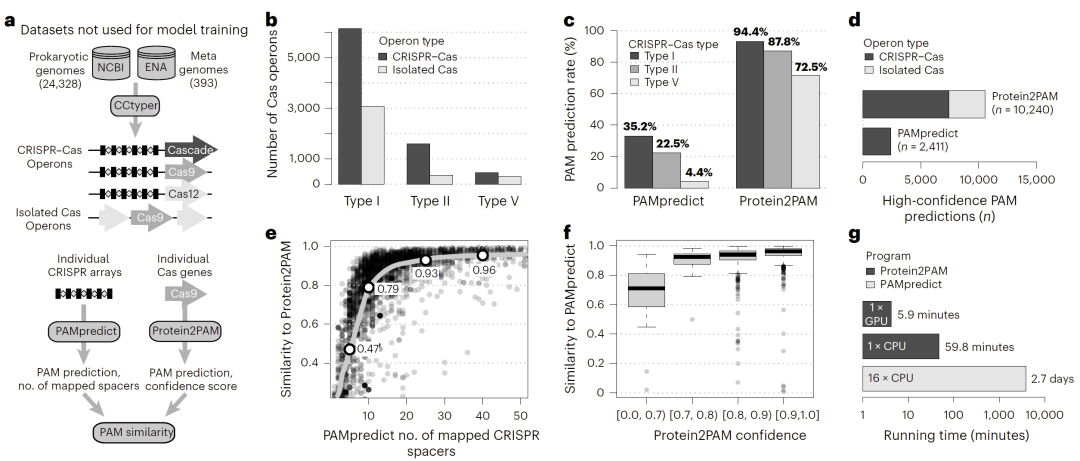
图3:Protein2PAM与传统PAM预测方法的灵敏度与效率对比。
蛋白–PAM相互作用的计算解析
为验证模型是否真正学习到生物物理规律,研究人员对数百万种 Cas 蛋白单点突变进行了计算扫描,筛选出能够显著改变 PAM 偏好的关键突变位点。这些突变几乎全部集中在 Cas9 的 PAM 识别结构域中,与已知结构研究高度一致。进一步分析发现,某些氨基酸(如谷氨酰胺和精氨酸)在 PAM 识别中起到核心作用,并呈现出对特定碱基的偏好性结合模式。这表明 Protein2PAM 不仅具备预测能力,还成功捕捉了底层分子识别机制。
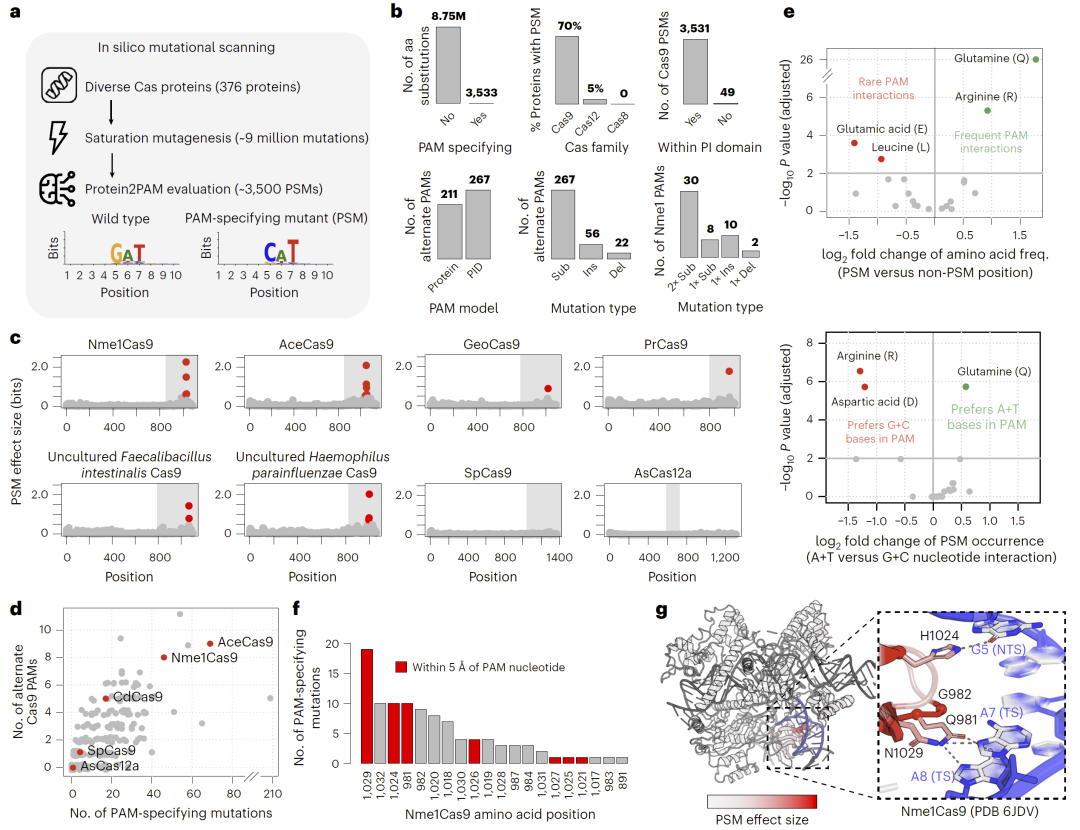
图4:基于计算突变扫描的蛋白–PAM关键识别位点定位。
定制化Cas酶的计算进化设计
在模型指导下,研究人员以 Nme1Cas9 为例,利用计算进化策略设计了一系列具有新型 PAM 特异性的酶变体。通过马尔可夫链蒙特卡洛算法逐步引入突变,模型成功生成了多种能够识别更宽 PAM 范围的 Cas9 变体。实验验证显示,其中部分新酶不仅扩展了可识别 PAM 类型,还在切割效率上超过天然酶和传统定向进化获得的变体。在人类细胞中的编辑测试进一步证明,这些工程化酶在保持高活性的同时实现了更灵活的靶向能力。
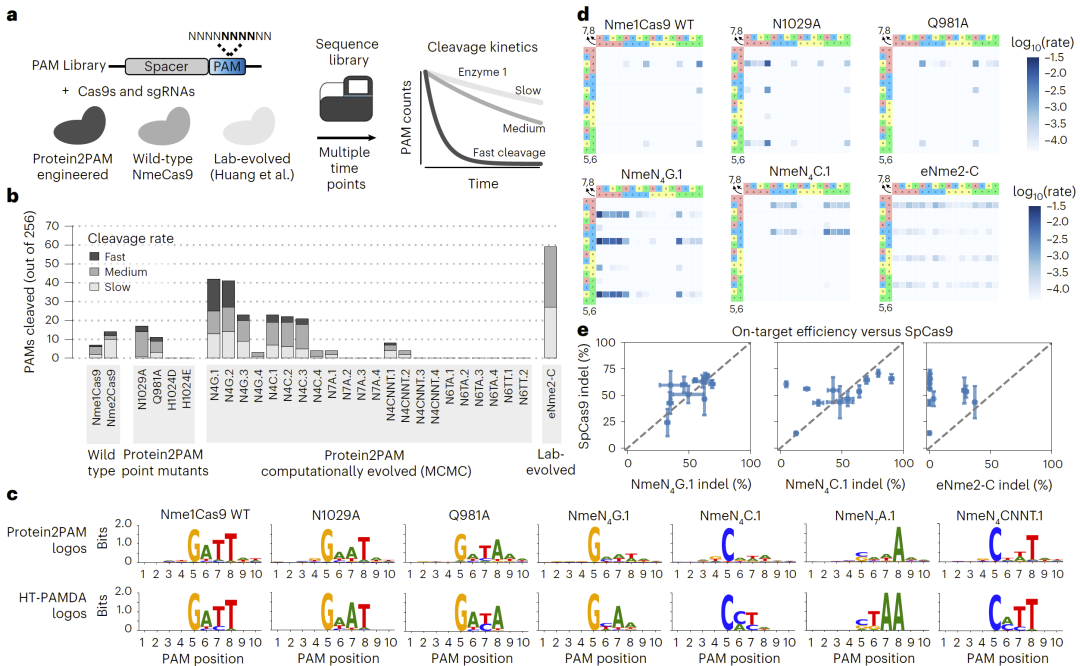
图5:Protein2PAM引导的PAM定制Cas9变体设计与实验验证。
讨论与前景
研究人员展示了蛋白质语言模型在理解与重塑 DNA 识别规则方面的强大潜力。Protein2PAM 实现了无需结构信息与反复实验筛选即可精准定制 PAM 特异性的突破,为 CRISPR 技术从经验驱动走向数据与模型驱动提供了新范式。尽管当前模型在I型与V型系统中仍受进化保守性限制,但随着基因组数据持续增长和实验反馈数据的引入,该框架有望不断进化优化。未来,该方法不仅可用于构建覆盖几乎所有基因位点的高特异性 Cas 工具库,也可能推广至其他DNA结合蛋白的精准工程设计,推动基因治疗与合成生物学的进一步发展。
整理 | DrugOne团队
参考资料
Nayfach, S., Bhatnagar, A., Novichkov, A. et al. Customizing CRISPR–Cas PAM specificity with protein language models. Nat Biotechnol (2026).
https://doi.org/10.1038/s41587-025-02995-0

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号