三个 40 岁老程序员决定用 AI 重新出发(四):文档驱动的 Spec Coding 实践

三个 40 岁老程序员决定用 AI 重新出发(四):文档驱动的 Spec Coding 实践

曹犟
发布于 2026-03-03 15:42:04
发布于 2026-03-03 15:42:04
你好,我是曹犟,欢迎关注我的公众号。先给大家拜个晚年,马年春节快乐!祝各位在新的一年里,无论是写代码还是做产品,都能马到成功。
在上一篇文章我分享了我们如何用 Use Case 驱动的方式完成产品设计。而 Use Case 写完之后,接下来就是最关键的一步:怎么把这些 Use Case 变成可运行的代码?
在这篇文章中,我会分享我们在这方面的实践经验,包括我们选择的 Spec Coding 方法论、使用的工具、工作流程、协作方式,以及一些踩过的坑。
PART01
什么是 Spec Coding
1.从 Vibe Coding 说起
相信关注这个系列的读者对 Vibe Coding 都不陌生,很多人应该已经在日常工作中大量使用了。用自然语言驱动 AI 写代码,是这个时代最重要的生产力变革之一,这一点毋庸置疑。
但当项目变得复杂,例如,涉及多个模块、前后端协同、多人协作、需要长期维护时,纯粹的 Vibe Coding 就会遇到一些挑战:AI 容易“越做越偏”,返工成本高,多人各自和 AI 对话导致协作困难等等。
这些问题的根源不在于 Vibe Coding 本身,而在于当项目复杂度上来之后,它需要一层结构来约束和引导。
2.Spec Coding:给 Vibe Coding 加上结构
Spec Coding,全称是 Spec-Driven Development(规格驱动开发),最早是 AWS 在它的 AI IDE 产品 Kiro 中正式提出的。核心理念很简单:在让 AI 写代码之前,先写清楚规格说明(Specification)。
换句话说,文档是代码的前置条件,而不是后置补充。
需要强调的是,Spec Coding 并不是 Vibe Coding 的对立面,而是它的进化。在最终的实现阶段,AI 仍然是用 Vibe Coding 的方式来写代码。只不过它不再是根据一个模糊的指令去猜,而是拿着一份清晰的文档去执行。
在我们的实践中,每个 Use Case 的开发都会经过四个阶段:
-Requirements:把 Use Case 转化为结构化的需求文档,包含明确的 User Story 和验收标准
-Design:基于 Requirements 生成技术设计文档,包括数据模型、API 设计、组件设计等
-Tasks:把 Design 拆解为可执行的原子任务,按依赖关系排序
-Implementation:AI 按照 Tasks 逐个进行代码实现
这个流程看起来和传统的瀑布模型有点像,但关键区别在于:每个阶段的产出都是 AI 生成、人审核的,整个过程非常快。传统模式下写一份详细的技术设计文档可能需要几天,而用 AI 来写,可能一个小时就能完成初稿,人只需要花时间审核和调整。
3.为什么 Spec Coding 更适合复杂项目
第一,给 AI 一个“北极星”。Spec 把目标、约束、验收标准都固定下来了,AI 在实现的时候有明确的参照,不需要漫无目的地猜你要什么。这大幅减少了“越做越偏”的问题,也减少了返工。
第二,迭代意图而非迭代代码。如果发现方向需要调整,修改一份 Spec 文档比修改一堆已经写好的代码成本低得多、风险也小得多。在 Requirements 阶段发现问题,改起来几乎是零成本;到了代码阶段才发现,改起来可能要伤筋动骨。
第三,天然的可追溯性。从 Use Case → Requirements → Design → Tasks → Code,形成了一条完整的链条。任何一行代码都能追溯到它对应的业务意图。这不仅便于 Code Review,也便于后续的维护和迭代。
第四,适合多人协作。Spec 本质上是团队的“共识文档”。三个人各自用 AI 写代码,但大家对“要做什么”和“怎么做”的理解是一致的,因为这些都写在 Spec 里了。
PART02
ClaudeCodeSpecWorkflow 介绍
1.工具简介
确定了 Spec Coding 的方法论之后,我们需要一个具体的工具来落地执行。我们选择的是一个开源项目——ClaudeCodeSpecWorkflow(项目地址:https://github.com/Pimzino/claude-code-spec-workflow )。
这个项目的核心价值是:它把 Spec Coding 的工作流固化成了 Claude Code 可以执行的标准流程。你不需要每次都手动告诉 AI “先写需求、再写设计、再拆任务”,这些流程已经预置好了。
2.预置的工作流程
ClaudeCodeSpecWorkflow 把前面提到的四阶段流程固化为标准模板,每个阶段都有:
-输入约束:这个阶段需要哪些前置文档作为输入
-输出模板:这个阶段的产出应该是什么格式、包含哪些内容
-模板检查:AI 会自动检查产出是否符合模板要求
-STATUS 维护:每个 Spec 都有一个 STATUS.md 文件,像是这个 Spec 的“控制中心”,记录当前进度、责任人、审核状态、审核意见和变更历史等,让团队中的任何人都可以快速了解某个功能的当前状态
这意味着,当你告诉 AI “为这个 Use Case 创建一个新的 Spec”时,AI 会自动按照标准流程来走,而不是随意发挥。
3.一个完整示例
为了让大家更直观地理解这个流程,我用一个真实的例子来说明。
在开发过程中,我们因为新的业务认知对某个 Use Case 做了一个比较大的改动,涉及前后端多个文件的新增和修改。这个改动就非常适合走完整的 Spec 流程。
Step 1:Requirements
我们把 Use Case 中相关章节的改动告诉 AI,让它根据 git 上记录的前后的改动内容细节生成结构化的需求文档。AI 会把改动拆解为多个独立的 Requirement,每个 Requirement 都包含 User Story 和 Acceptance Criteria(验收标准)。
这里值得展开说一下 Acceptance Criteria 的写法。ClaudeCodeSpecWorkflow 采用的是 EARS 格式(Easy Approach to Requirements Syntax),这是一种用固定句式来书写需求的方法,核心句式是:
> WHEN <触发条件> THEN 系统 SHALL <行为>
> IF <状态条件> THEN 系统 SHALL <行为>
举个例子,如果你用自然语言写需求,可能会写:“系统应该能区分新老用户”。这句话有太多的模糊空间:怎么区分?区分之后做什么?边界情况怎么处理?
而用 EARS 格式写,就会变成:
> WHEN 用户首次登录 THEN 系统 SHALL 创建用户记录
> IF 用户已关联业务账户 THEN 系统 SHALL 判定为老用户
> IF 用户未关联业务账户 THEN 系统 SHALL 判定为新用户
显而易见,这么写 AI 就可以直接把每条 Acceptance Criteria 转化为代码逻辑和测试用例,大幅减少了实现偏差。
除了功能性需求,Requirements 还会包含非功能性需求:性能要求、安全要求、可靠性要求等。
人在这一步的工作:审核需求是否完整、逻辑是否自洽、是否遗漏了边界情况。AI 写需求的速度很快,但它有时候会遗漏一些你觉得“显然”但它并不知道的业务约束,这些需要人来补充。
Step 2:Design
Requirements 审核通过之后,AI 会基于 Requirements 加上项目已有的技术规范,生成技术设计文档。这份文档通常包含:
- 数据模型设计:需要新建或修改哪些表、字段定义是什么
- API 接口设计:需要新增或修改哪些接口、请求和响应格式是什么
- 前端组件设计:需要新增或修改哪些页面和组件
- 代码复用分析:哪些已有的代码可以直接复用、哪些需要扩展
这一步的一个关键点是:AI 会自动对齐项目已有的技术栈和项目结构。因为我们的项目规范(技术选型、目录结构、编码规范等)都以文档的形式存在于项目中,AI 可以直接读取这些文档,确保设计方案和现有架构保持一致。
人在这一步的工作:审核架构决策是否合理、是否充分复用了已有代码、是否引入了不必要的复杂度。在我们的实践中,AI 生成的设计方案大部分时候是合理的,但偶尔会“过度设计”——比如引入了不必要的抽象层,或者没有意识到某个功能可以通过扩展现有模块来实现而非新建。
Step 3:Tasks
Design 审核通过之后,AI 会把设计方案拆解为可执行的原子任务,按依赖关系分成多个 Phase。每个 Task 都包含:
-操作文件:具体要修改或新建哪个文件
-具体内容:要做什么改动
-关联的 Requirement:这个 Task 对应哪条需求
-给 AI 的执行 Prompt:一段结构化的指令,告诉执行 AI 应该扮演什么角色、完成什么任务、有什么限制条件、怎么验证完成
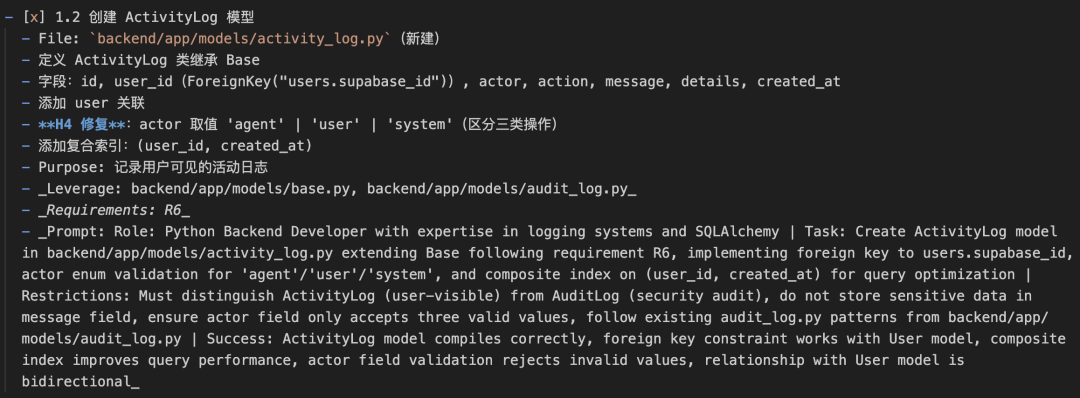
人在这一步的工作:审核任务拆解的粒度是否合适、依赖顺序是否正确。粒度太粗,AI 执行时容易出错;粒度太细,又会增加不必要的开销。
Step 4:Implementation
人批准 Tasks 之后,AI 就可以按照 Phase 顺序逐个执行了。每完成一个 Task,STATUS.md 会自动更新进度,你可以随时看到当前执行到了哪一步。
人在这一步的工作:Review 代码、跑测试、处理 AI 实现中遇到的问题。虽然有了详细的 Spec,AI 的实现质量已经好了很多,但仍然不是完美的,偶尔还是会遇到需要人工干预的情况。
Step 5:迭代与变更
需要特别强调的是,Spec 不是一次写完就不动的。在我们的实践中,一个 Spec 在实现过程中经常会经历多次修订,可能是在实现过程中发现了新的边界情况,也可能是业务需求本身发生了变化。
每次变更都会记录在 Revision History 中,包括版本号、日期和变更内容。这样任何人在任何时候都可以追溯这个 Spec 的演变过程。
4.上下文管理技巧
Spec Coding 天然会产生大量的文档,一个完整的 Spec 加上相关的已有代码,可能有几万甚至十几万 token。好在现在主流模型都支持很长的上下文窗口,可以让 AI 同时“看到”所有 Spec 文档和相关代码,避免实现过程中前后不一致。
在实际使用中,我们总结了两个关于上下文管理的技巧:
如何组织上下文:我们通常会确保 AI 的上下文中包含三类信息:当前 Spec 文档、与本次改动相关的已有代码、项目级别的规范文档。这些信息的优先级从高到低排列。
什么时候需要“刷新”上下文:当一个 Spec 的 Tasks 特别多、实现跨度比较长时,AI 的上下文可能会被大量的对话历史占满。这时候我们会开一个新的对话,重新加载 Spec 和相关代码,让 AI 从一个“干净”的上下文重新开始。什么时候该刷新?当你感觉 AI 的输出质量开始下降、或者开始“忘记”之前的约定时,就该刷新了。
PART03
三个人都写代码的协作方式
1.分工但不分家
在我们这个三个人的小团队里,虽然每个人有各自的侧重方向,但在必要的时候,三个人都会写代码。这在传统团队中可能会带来很多协作问题,但在 Spec Coding 的框架下,反而变得比较顺畅。
分工方式主要有两种:
第一种,按 Use Case 分工。每个人负责一个 Use Case 的完整 Spec Workflow,从 Requirements 写到 Implementation。这种方式的好处是每个人对自己负责的功能有完整的理解,减少沟通成本。
第二种,在同一个 Use Case 内分工。例如,一个人写 Requirements,另一个人负责 Review 和后续过程。这种方式的好处是有交叉审核,能发现更多问题。
2.协作中的额外技巧
有了 Spec 和统一的模板,多人协作中常见的风格不一致、重复造轮子等问题已经大幅缓解。在此基础上,我们还有两个额外的实操技巧:
第一,要求 AI 做全局检查。在实现每个 Task 时,我们会刻意要求 AI 先检查项目中是否已有类似的功能或工具函数,避免重复实现。在每个 Use Case 开发完成之后,我们都会要求 AI 做全局检查,保证文档与代码的一致性,并且对无效代码做精简。
第二,频繁小步增量提交。每完成一个 Task 就提交一次,而不是攒一大堆改动一起提交。这样即使有合并冲突,影响范围也小,解决起来容易。
3.人与人之间的沟通
还有一点值得强调:虽然 Spec Coding 强调的是基于文档的人与 AI 协作,但人与人之间的必要讨论依然不可少。
在实践中,我们三个人会定期讨论业务认知、优先级调整、架构决策等问题。这些讨论的结论不会仅仅停留在口头上,而是会让 AI 帮忙整理成文档归档到项目中。一方面确保讨论结果不会被遗忘,另一方面这些文档也成为了 AI 后续工作时的上下文。
PART04
用 GitLab Issue 补全轻量级工作流
1.Spec 不是万能的
前面花了很大篇幅介绍 Spec Coding 的流程,但必须坦诚地说:不是所有改动都需要走完整的 Spec 流程。
它适合的是 Use Case 级别的开发,但在日常开发中,还有大量的小改动:修一个 bug、调一个样式、改一个配置、优化一段性能不佳的代码。如果这些小改动也要走Requirements → Design → Tasks → Implementation 的完整流程,就太重了。
我们需要一条“轻量级通道”来处理这类工作。这条通道就是 GitLab Issue。
2.AI + GitLab Issue 的集成
Claude Code 可以很简单地配置来直接操作 GitLab。这意味着 AI 不仅可以写代码,还可以:
- 提交 Issue:发现了一个问题,直接创建一条 Issue
- Review Issue:查看和理解现有 Issue
- 关闭 Issue:实现完成后,自动关闭对应的 Issue
这让 AI 从一个纯粹的“代码生成器”变成了一个“项目管理参与者”,它可以参与到任务管理的完整生命周期中。
3.两条通道:Spec vs Issue
在我们的实践中,逐渐形成了一套“两条通道”的工作方式:
大改动走 Spec:涉及新的业务逻辑、新的架构设计、或者对已有功能的大规模重构,走完整的 Spec 流程。
小改动走 Issue:bug 修复、UI 微调、配置变更、小优化等,直接以 GitLab Issue 的形式管理。AI 可以直接提交 Issue,经人确认后实现。
判断标准也很简单:这个改动是否涉及新的业务逻辑或架构变化?如果是,走 Spec;如果不是,走 Issue。比如当 Use Case 发生变更时,我们会让 AI 对比 diff,自动按这个标准做分流:小改动拆成 Issue,大改动进入 Spec 流程。
4.AI 驱动的 Issue 生命周期
在 Issue 的管理上,我们也尝试让 AI 承担更多的主动性:
AI 会定期 Review 所有 Open 的 Issue,理解每一条 Issue 的内容和优先级,然后逐个实现。每个 Issue 实现完成并通过测试之后,AI 会自动关闭它。
这样就形成了一个完整的闭环:发现问题 → 创建 Issue → 实现 → 验证 → 关闭。人的角色主要是在关键节点做审核和决策,而 AI 负责执行的部分。
PART05
写在最后
总结一下,Spec Coding 的核心价值,是让 AI 编程从“碰运气”变成了“可控的工程”。方法论永远要匹配场景,而不是反过来。
在下一篇文章中,我会分享代码写完之后,我们是如何用 AI 来做 PLG 模式下的增长获客的:包括官网搭建、内容生成、客户沟通等方面的实践。敬请期待。
以上都是一家之言,欢迎大家与我交流讨论。
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号