Nat. Catal.|给酶匹配“对象”,基座模型EnzymeCAGE破解酶招募难题

Nat. Catal.|给酶匹配“对象”,基座模型EnzymeCAGE破解酶招募难题

DrugAI
发布于 2026-03-03 10:25:15
发布于 2026-03-03 10:25:15
DRUGONE
酶催化被公认为实现工业可持续发展的关键绿色生物制造技术。作为生物制造体系的核心“芯片”,酶以其高效且高度特异的催化能力维系着复杂的代谢网络。然而,酶的序列、结构与催化功能之间尚缺乏可系统刻画的对应规律,制约了生物制造规模化应用的效率。
当前代谢数据库中,超过半数已报道的生化反应仍为“孤儿反应”,缺乏明确的催化酶注释,限制了复杂天然产物的生物合成解析及人工代谢通路设计。现有计算方法主要基于序列同源性进行酶筛选,未能充分整合进化信息与底物特异性约束,在定向匹配特定反应催化酶方面存在显著不足。因此,建立高精度、可扩展的酶功能识别与开发框架,已成为推动合成生物学与生物制造升级的关键突破方向。
2026年2月12日,上海交通大学郑双佳课题组联合香港科技大学、Mila-Quebec人工智能研究院、麻省理工学院、中山大学等国内外科研机构,在《Nature Catalysis》发表题为“A Geometric Foundation Model for Enzyme Retrieval with Evolutionary Insights”的研究工作,提出酶催化基座模型EnzymeCAGE,通过学习催化位点空间结构特征与进化信息,为酶招募与功能预测提供新的技术途径。

模型架构
EnzymeCAGE的核心创新在于其多模态的几何增强架构 。该模型利用蛋白质语言模型捕获酶的全局进化信息,同时采用AlphaFill提取催化口袋的局部几何特征,并以图神经网络进行精确编码。在反应端,模型通过识别化学反应中心并分配更高权重,捕捉分子转化过程中的动态变化。这种几何引导的交互模块能够有效过滤冗余信息,专注于口袋区域的物理化学交互,实现了比传统对齐方法更高性能、更具可解释性的预测 。
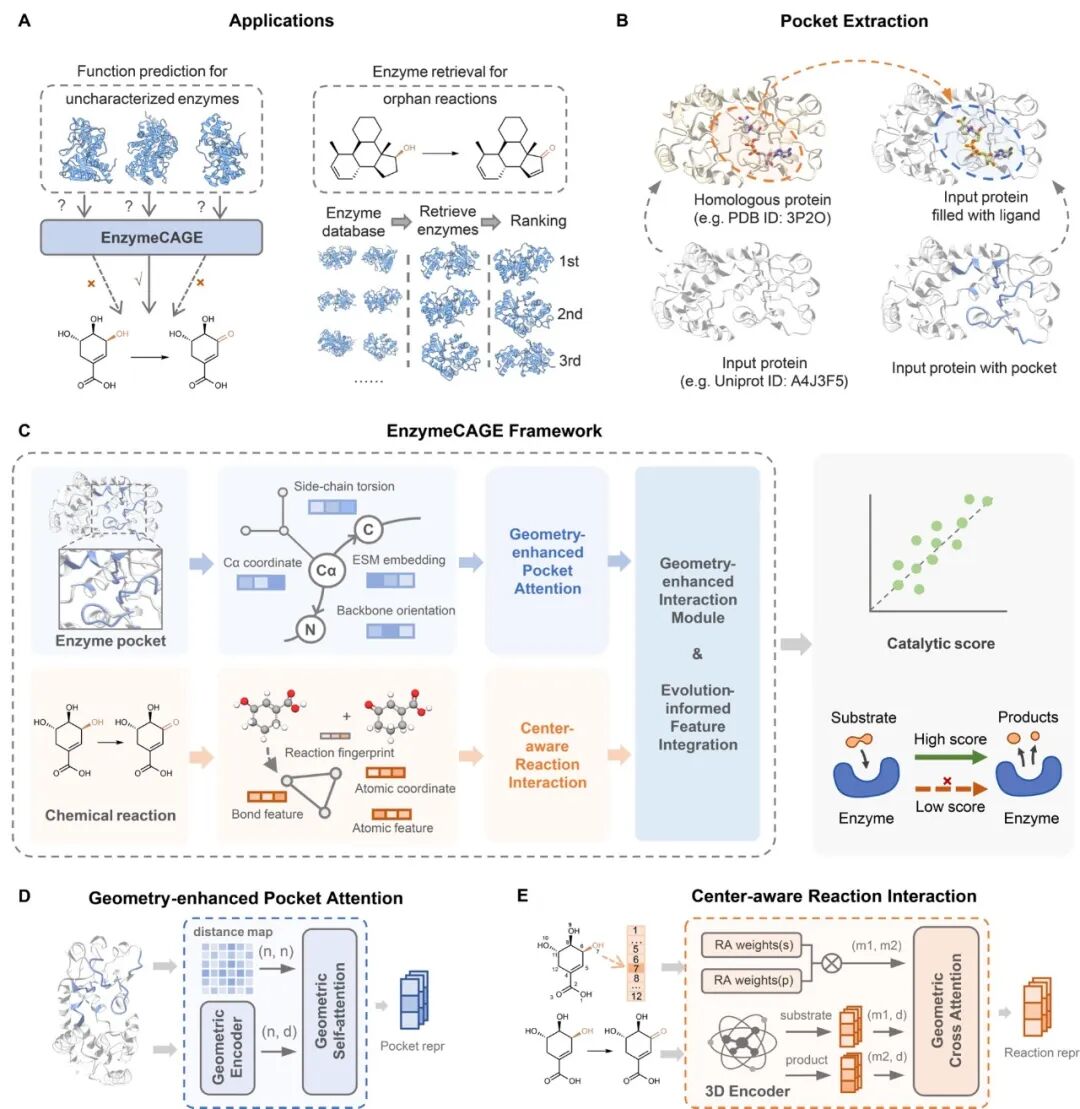
图 1: EnzymeCAGE 几何增强型酶功能预测框架。EnzymeCAGE 集成了蛋白质结构、进化上下文与化学反应中心的变换信息,通过 AlphaFill 提取催化口袋并结合蛋白语言模型捕捉全局特征 。该模型利用几何引导机制直接建模酶与反应的兼容性,为未知酶功能鉴定和孤儿反应催化剂检索提供了高效的双向预测方案 。
多场景验证刷新性能天花板
研究人员利用Enzyme-405基准测试集对模型预测未表征酶功能的能力进行了深入评估,该集合包含295个反应和 405 个训练集中未出现的酶 。在针对15,921个候选对的评估中,EnzymeCAGE在Top-10成功率上达到了58%,显著优于现有基准模型。相较于传统方法,该模型在酶功能预测任务中实现了 45% 的性能提升,并在富集因子(EF)和 Top-10 折现累积增益(DCG)等指标上均表现优异 。此外,在与CLEAN和GraphEC等基于 EC 编号预测的模型对比中,EnzymeCAGE在处理具体酶-反应特异性设置时表现出更强的排除负样本能力,且在六大类 EC 分级中均展现了更高的预测精度 。
针对孤儿反应的去孤化能力,研究团队构建了Orphan-335 测试集,其中包含 335 个在训练数据中未出现且最初缺乏已知催化剂的反应 。实验结果显示,EnzymeCAGE 能够精准检索这些孤儿反应的催化酶,在识别此类反应的潜在酶方面比基线方法提升了41% 。通过对不同反应相似性阈值(0.6 到 0.9)的详尽分析,模型一致性地在 EF 评分、Top-10 DCG 和Top-k成功率上超越了Selenzyme、ESP 和CLIPZyme等领先工具 。这种强大的检索能力证明了 EnzymeCAGE能够有效捕捉催化特异性,为发现未知生化反应的催化机制提供了稳健的计算支撑。
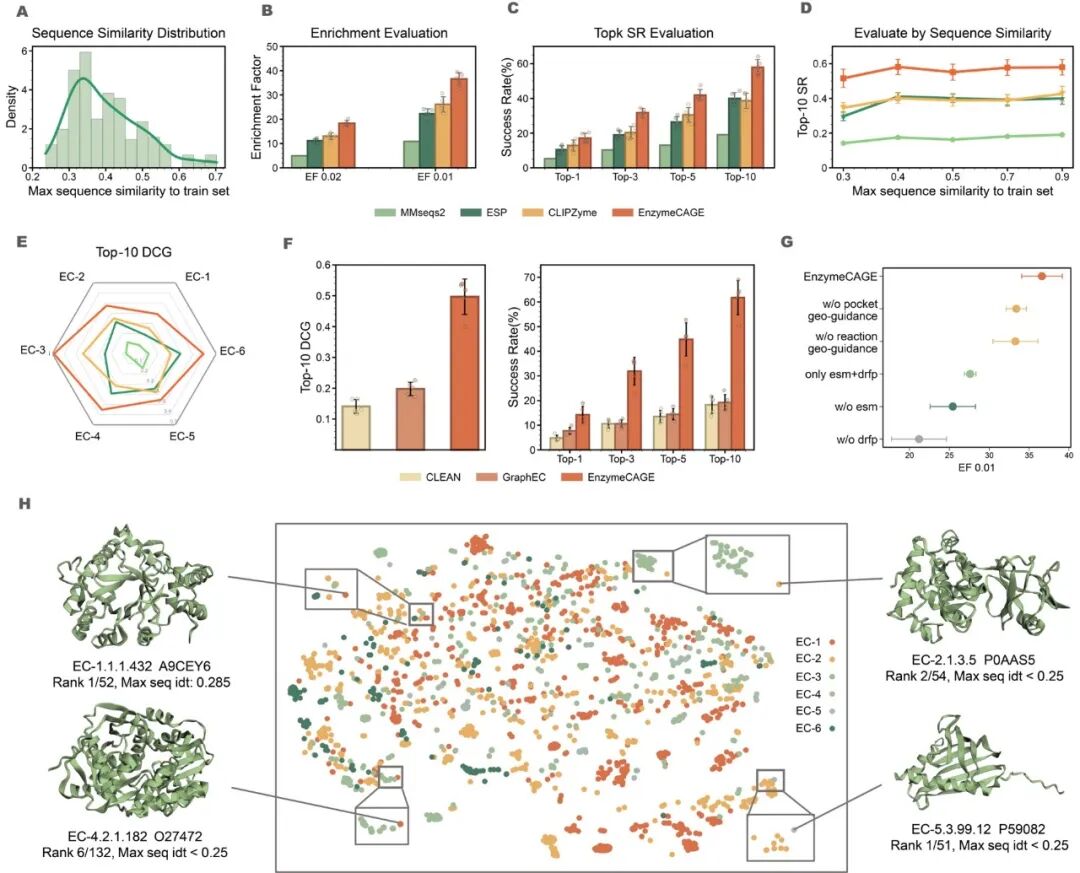
图 2: Enzyme-405 基准测试与预测精度评估。在针对未见酶(Unseen enzymes)的测试中,EnzymeCAGE 的 Top-10 成功率达到 58%,显著优于 CLEAN 和 GraphEC 等深度学习基准模型 。消融实验证实,催化口袋的几何引导与 ESM 进化嵌入对提升预测性能至关重要 ,使模型在处理低序列相似度蛋白时仍能保持高精准度 。
在针对细胞色素P450、萜烯合酶及磷酸酶三个外部测试集的评估中,EnzymeCAGE展现出卓越的领域适用性与强大的可扩展性 。模型在P450和萜烯合酶的任务中表现优异,Top-k SR指标显著超越了Selenzyme和ESP等现有方法;而对于结构功能极其多样化的磷酸酶家族,通过引入领域特定的微调技术,其预测准确性得到了跨越式提升,达到并超过了基准模型水平 。这些结果有力地证明了 EnzymeCAGE不仅是一个通用的基座模型,更是一个能通过微调精准捕捉家族特性、有效应对生物工程中各类复杂酶学挑战的高精度定制工具 。
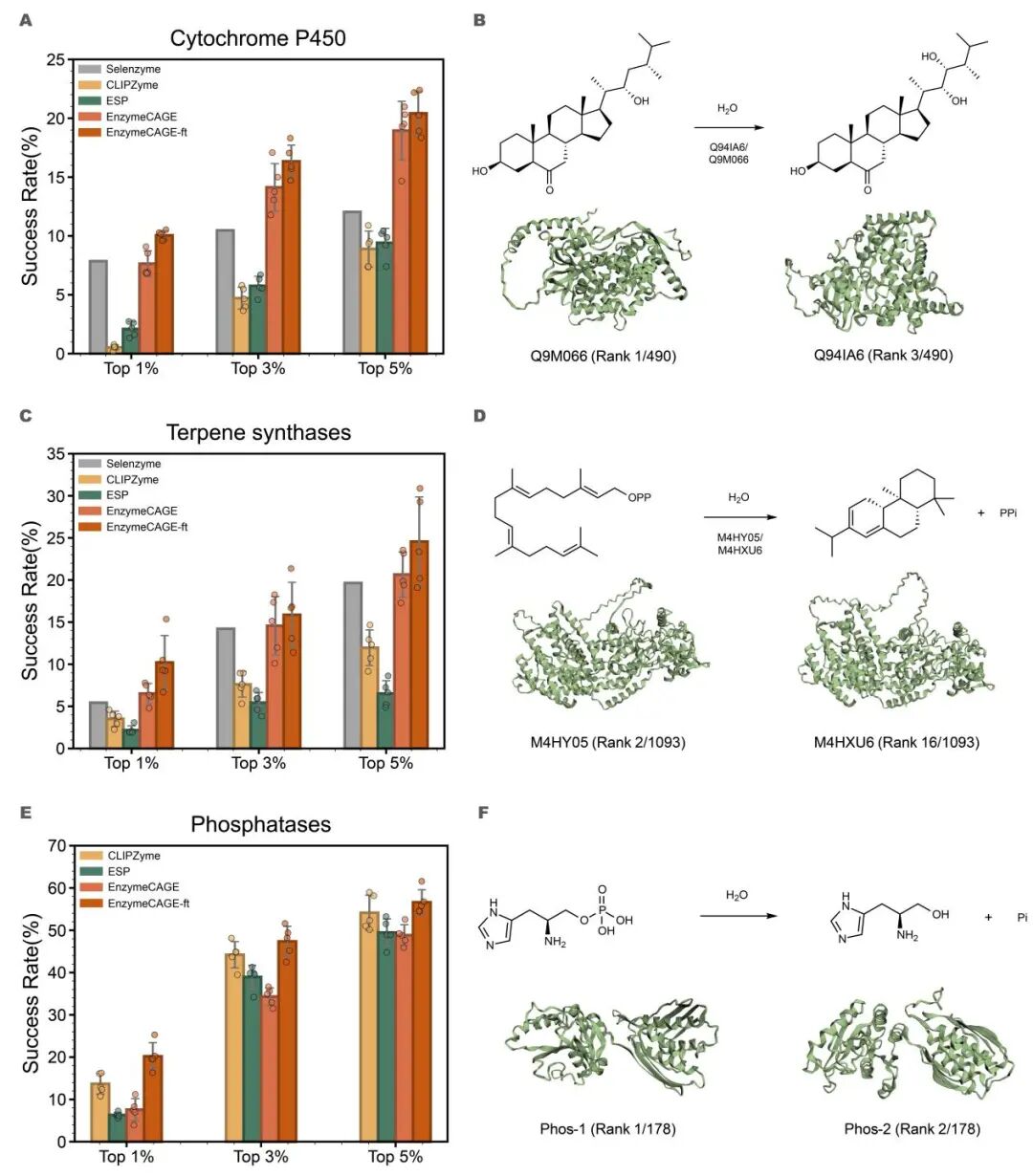
图 3: 特定酶家族的领域微调与迁移应用。通过对 P450、萜类合成酶及磷酸酶家族进行定向微调,EnzymeCAGE在外部测试集上的表现得到了进一步强化 。
从基础研究到实战应用
为验证其实战能力,研究团队将EnzymeCAGE应用于复杂的生物合成路径重构 。在戊二酸案例中,模型成功为其新型生物合成路径上的反应进行了酶招募,在所有步骤的检索排名中均名列前茅,显著优于现有的Selenzyme和 CLIPZyme等工具 。在睡茄内酯生物合成研究中,模型也精准预测了三种关键P450 酶的功能 。这些结果充分证明了EnzymeCAGE作为一种通用基座模型,在加速先进生物催化剂发现、重构代谢网络以及推动合成生物学创新方面的巨大潜力 。同时,在绿色化工领域,EnzymeCAGE助力了戊二酸新型生物合成路径的六步级联反应酶筛选,不仅稳定输出了关键步骤的目标酶,更在复杂代谢链条的构建中表现出极高的准确性,为戊二酸的高效生物制造提供了可靠的计算支撑。
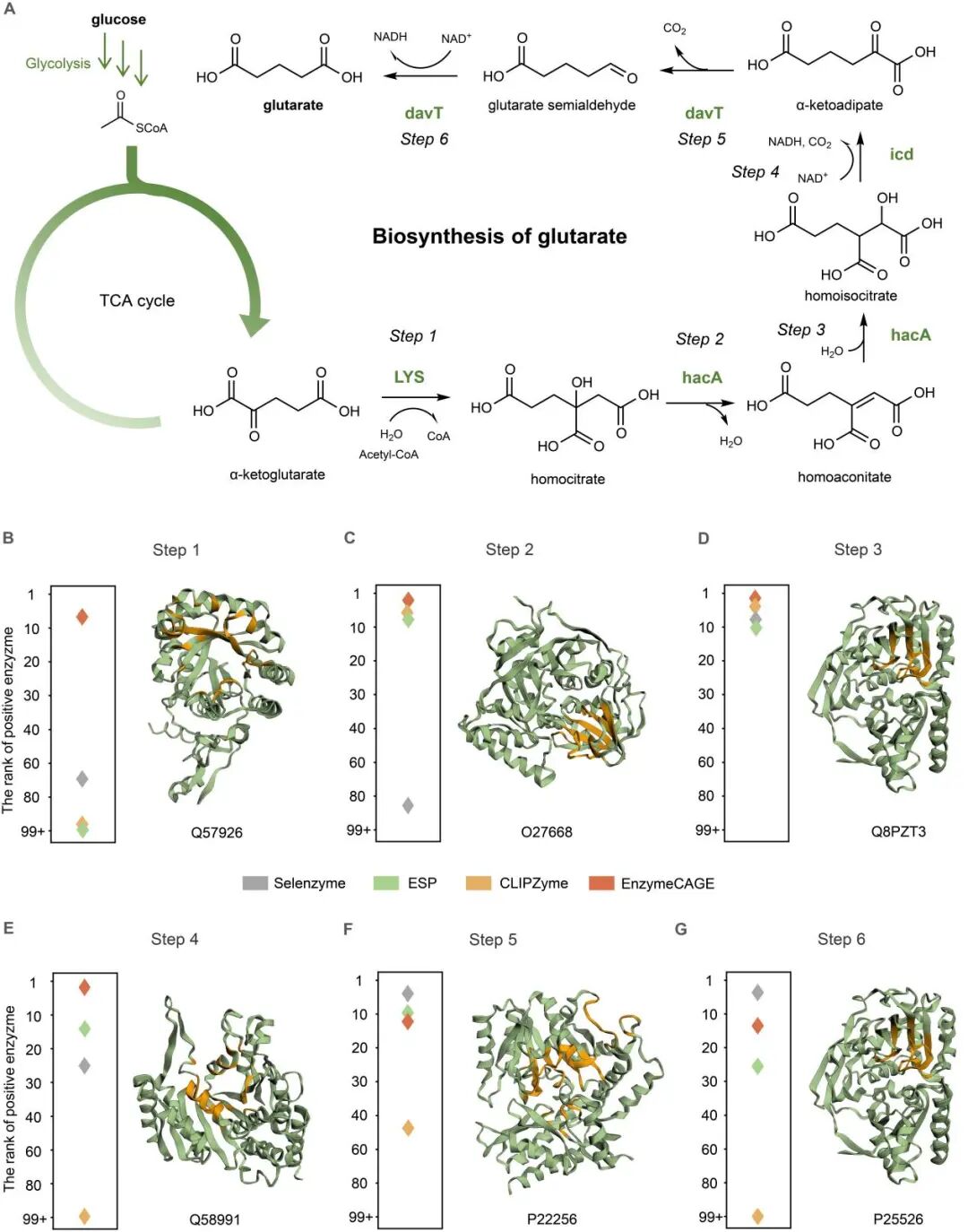
图 4: 戊二酸人工生物合成途径的重建。针对具有广泛工业价值的戊二酸合成路径,EnzymeCAGE展现了强大的路径导航能力,在全部六个反应步骤中均能将对应的正向酶锁定在检索列表的前列 。这一案例凸显了模型在辅助合成生物学设计、加速代谢工程路径构建方面的实际应用潜力和稳定性 。
局限性与展望
EnzymeCAGE的提出为酶与化学反应之间的关联建立了以结构、功能与进化信息为核心的一体化建模思路,从而在很大程度上突破了传统预测策略的局限。但研究团队也发现该模型在硫转移酶,酰胺水解酶,糖苷水解酶等数据较为稀缺的领域表现欠佳,未来将继续改进反应中心识别方法,以提高模型处理复杂生物转化过程的能力,并对特定酶家族开展更有针对性的精细化优化。目前该模型代码已经公开发布,向全球研究者提供了可自由获取与复用的研究工具,其应用有望显著缩短新酶筛选与鉴定的周期,并推动生物催化在医药、能源等方向的实际应用进程。
参考资料
Liu, Y., Hua, C., Xu, M. et al. A geometric foundation model for enzyme retrieval with evolutionary insights. Nat Catal (2026).
https://doi.org/10.1038/s41929-026-01478-y
代码
https://github.com/GENTEL-lab/EnzymeCAGE.git
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号