AI基础设施的算力互连底座:400G高速铜/光互连技术与PCIe 8.0的演进路径

AI基础设施的算力互连底座:400G高速铜/光互连技术与PCIe 8.0的演进路径

光芯
发布于 2026-03-02 21:53:20
发布于 2026-03-02 21:53:20

随着生成式AI与大模型技术的规模化落地,数据密集型负载对底层基础设施的带宽、延迟与端到端数据流动能力提出了前所未有的严苛要求。互连系统作为连接计算、存储与网络的核心载体,已成为制约AI算力释放的关键瓶颈。本文基于全球网络存储工业协会(SNIA)数据存储与网络论坛(DSN)的技术研讨会内容,系统拆解下一代AI基础设施中,400G高速互连与PCIe 8.0技术的核心架构、技术挑战、落地路径,以及配套存储系统的协同演进方向。

一、AI时代互连技术的核心需求底层逻辑

AI负载的核心特征带来了两大存储与互连的核心趋势:其一,存储系统承担了GPU补充内存容量的核心角色,需要支撑海量训练与推理数据的低延迟访问;其二,传统冷数据的访问频率显著提升(冷数据变暖),跨芯片、跨设备、跨机架的海量数据流动成为常态。在此背景下,互连系统的带宽能力直接决定了数据处理的效率,一旦互连带宽无法匹配计算与存储的性能,将直接导致AI计算任务的处理延迟与算力浪费。
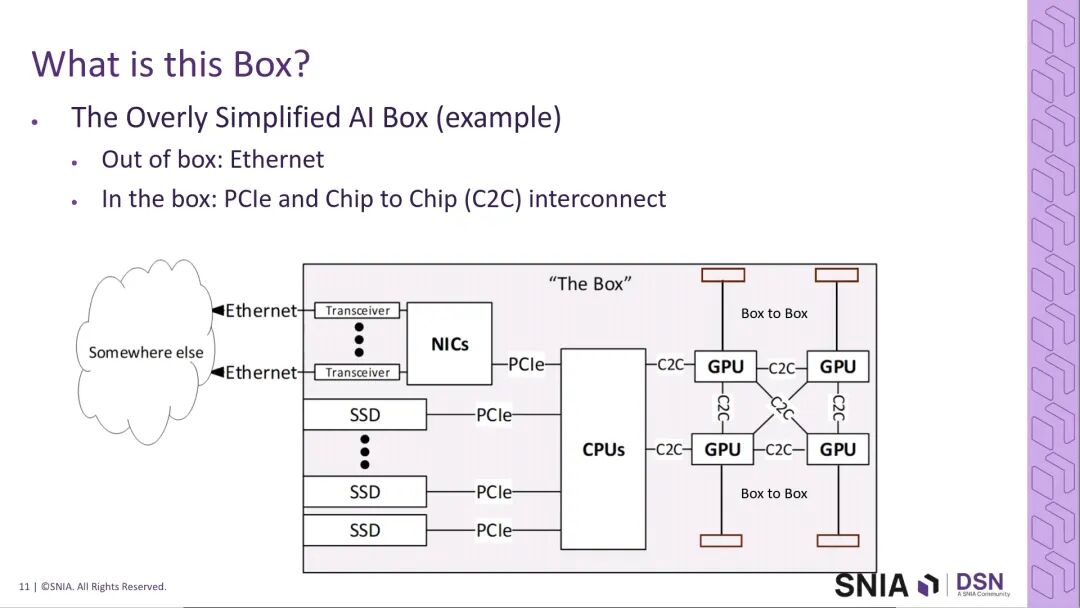
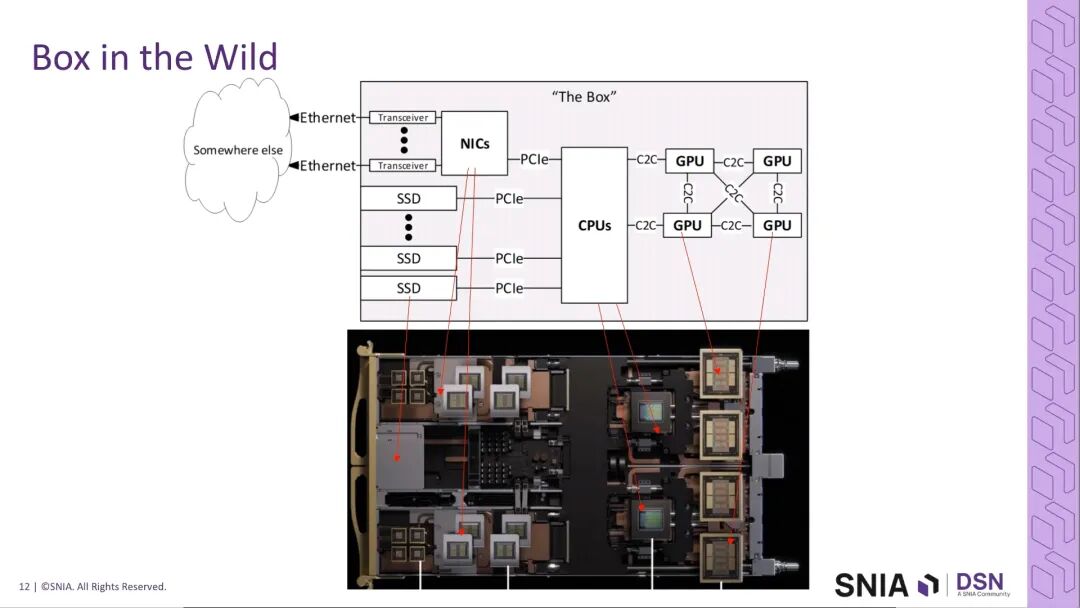
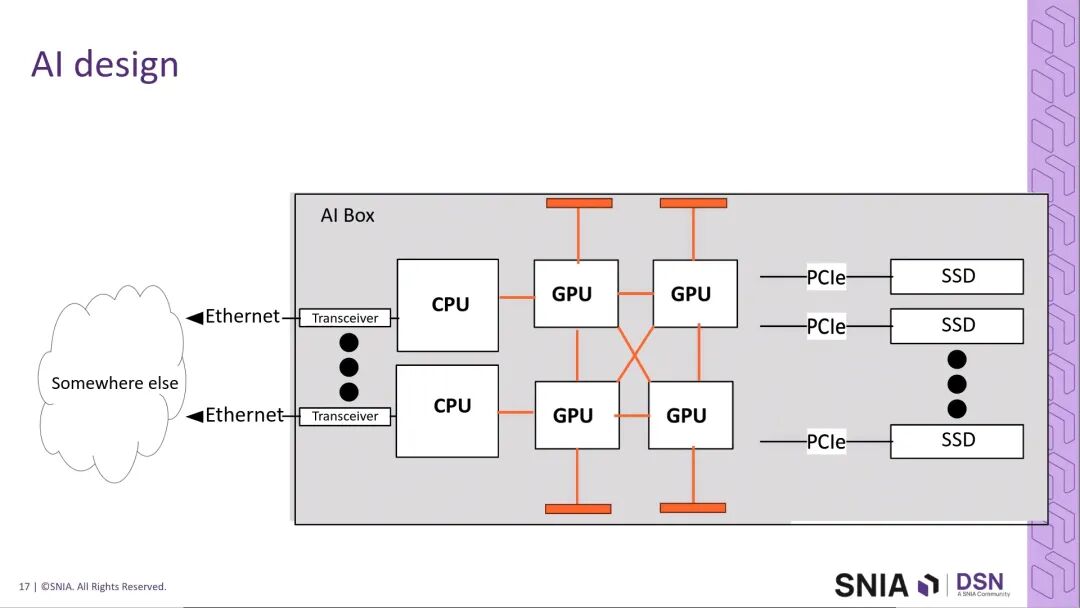
从典型AI系统的架构来看,互连系统覆盖了三大核心场景:一是系统外部的以太网互连,负责跨机架、跨数据中心的长距数据传输;二是系统内部的PCIe互连,负责CPU与SSD、加速器之间的存储与外设连接;三是芯片到芯片的高速互连,包括CPU-GPU、GPU-GPU之间的短距高速通信,同时覆盖机架内sled-to-sled以及box-to-box的近距传输场景。这三大场景共同构成了AI基础设施的互连底座,也是400G与PCIe 8.0技术的核心发力方向。
二、400G铜互连的技术体系与核心挑战

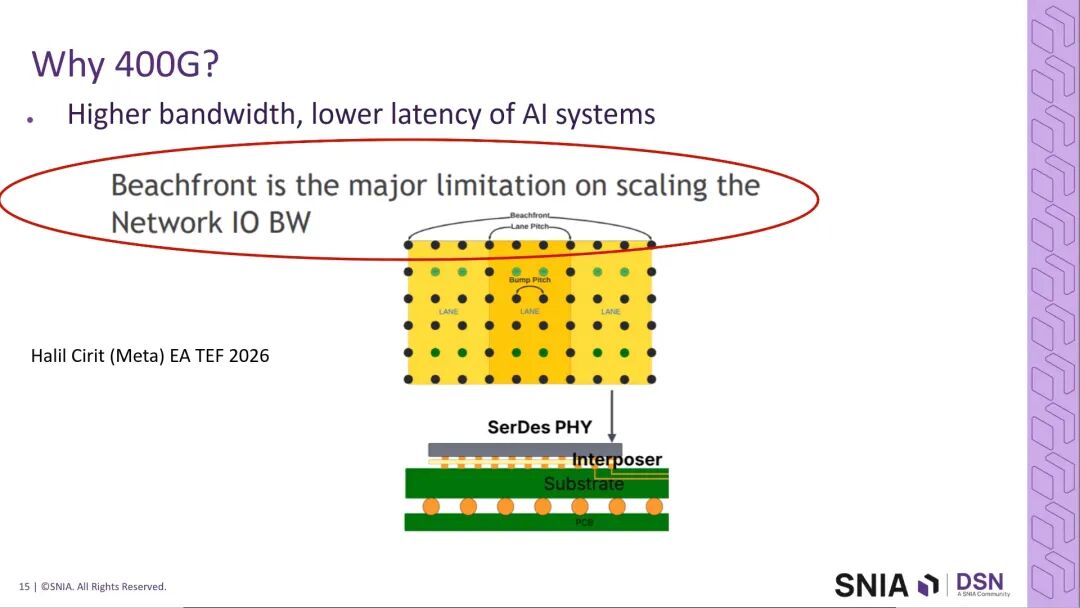
400G高速互连的核心驱动力,来自芯片封装的物理极限。根据Meta的技术实践,芯片封装的焊球与凸点密度受限于机械结构与尺寸,无法通过无限增加IO数量来提升带宽,提升单通道的信号速率成为唯一可行的技术路径。本章节聚焦SNIA SFFF工作组主导的GPU-to-GPU 400G铜互连场景,从调制方案、封装设计、通道实现三大维度拆解技术细节。

2.1 调制方案的选型与权衡
传统NRZ调制技术已无法满足高速率需求,行业已全面转向多电平脉冲幅度调制技术,当前400G互连的核心选型集中在PAM4、PAM6、PAM8三种方案,三者的核心性能差异如下:

- PAM4调制:采用4电平编码,单周期可传输2bit数据,实现400G速率所需的奈奎斯特频率为120GHz,无额外SNR损失,但对通道带宽提出了极高要求,现有通道技术难以支撑;
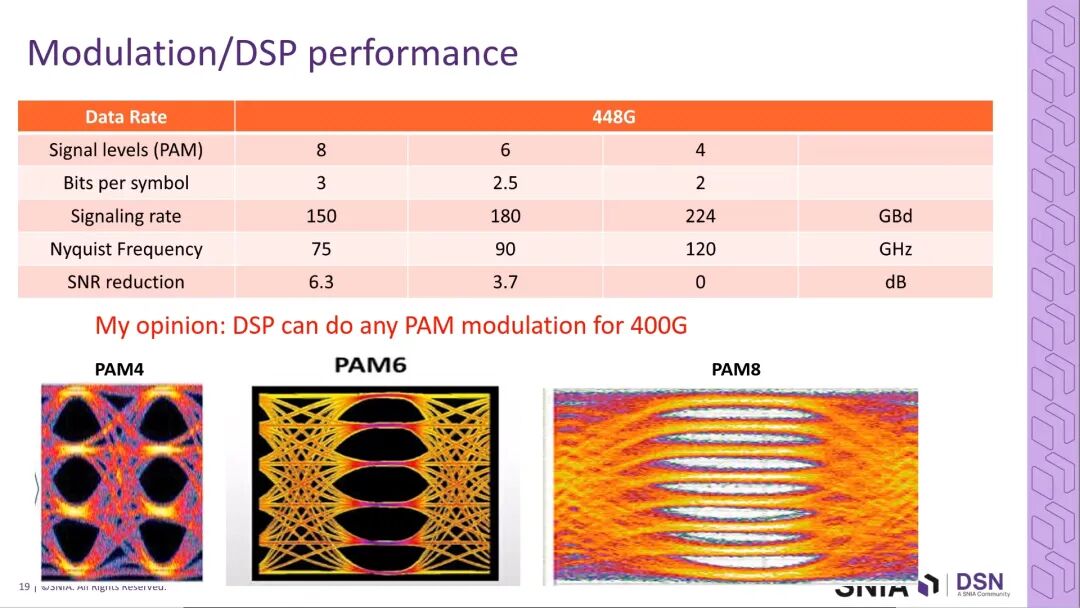
- PAM6调制:采用6电平编码,单周期可传输log2(6)bit数据,奈奎斯特频率为90GHz,SNR损失为3.7dB,是性能与可行性的折中方案;
- PAM8调制:采用8电平编码,单周期可传输3bit数据,奈奎斯特频率仅为75GHz,但SNR损失高达6.3dB,对前向纠错(FEC)技术的要求大幅提升,误码率控制难度显著增加。
行业技术观点认为,当前DSP设计已可支撑上述三种调制方案的稳定运行,调制技术本身不会成为400G互连的核心限制因素。
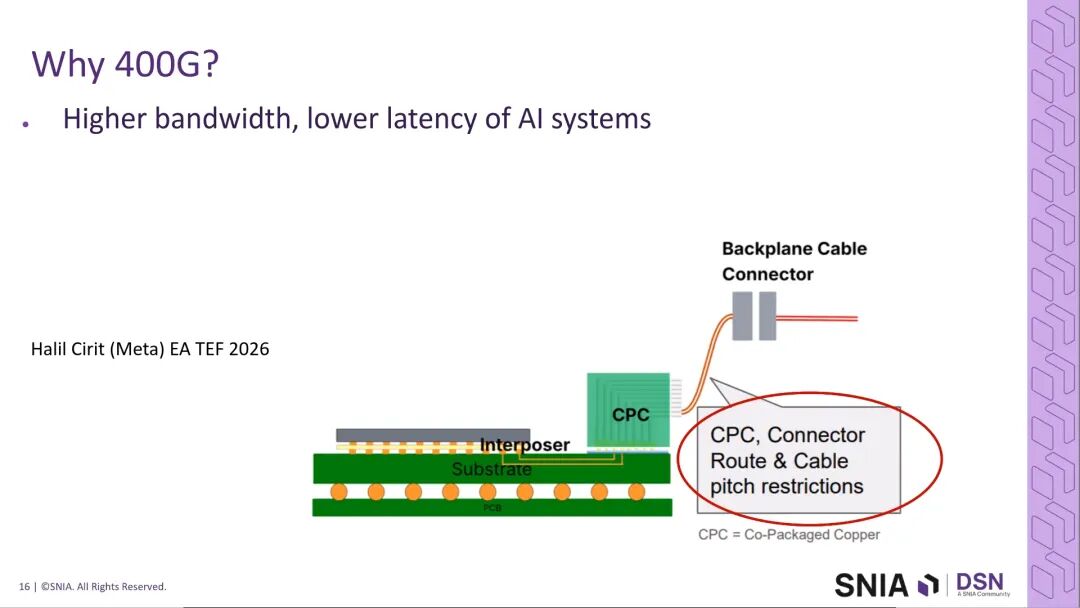
2.2 封装设计的突破:共封装铜互连(CPC)
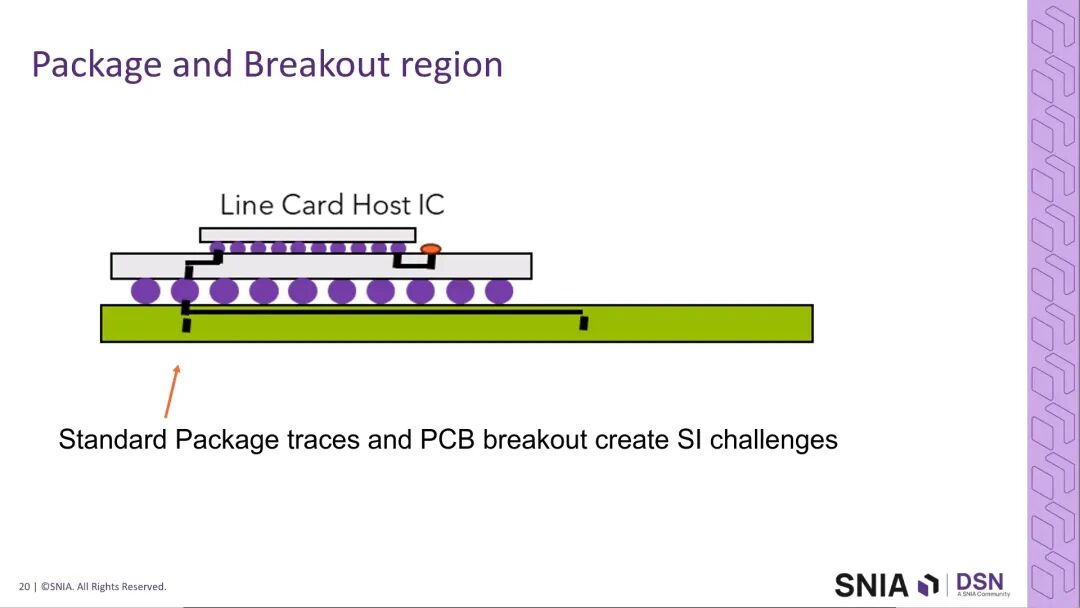
传统芯片封装的信号路径为:裸片焊球→封装内部走线→封装焊球→PCB板,核心挑战来自高密度焊球间距下的走线逃逸区域设计。在高密度IO场景下,封装内部走线的弯折、过孔stub都会引入严重的信号完整性(SI)问题,即使采用背钻、跳层等优化手段,仍无法完全消除插入损耗与阻抗不连续。
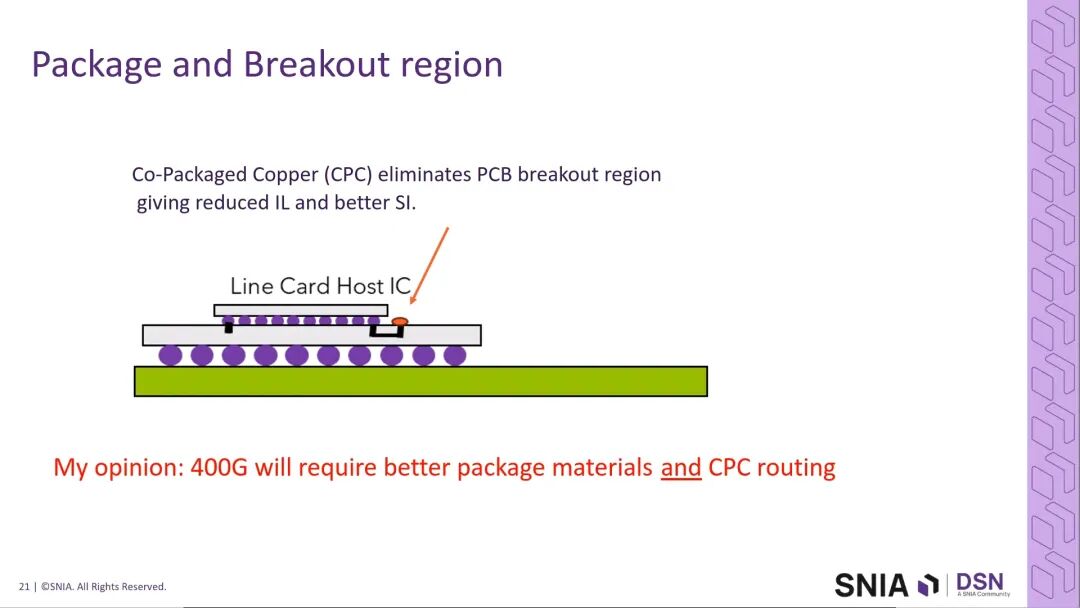
针对这一挑战,行业提出了共封装铜互连(Co-Package Copper, CPC)技术方案:将裸片的信号直接在封装顶部完成走线与焊盘引出,完全消除了传统的封装逃逸区域,大幅优化了信号完整性。行业观点明确,400G互连的落地需要更高性能的封装材料,同时必须具备CPC布线能力,这是实现400G短距互连的核心基础。
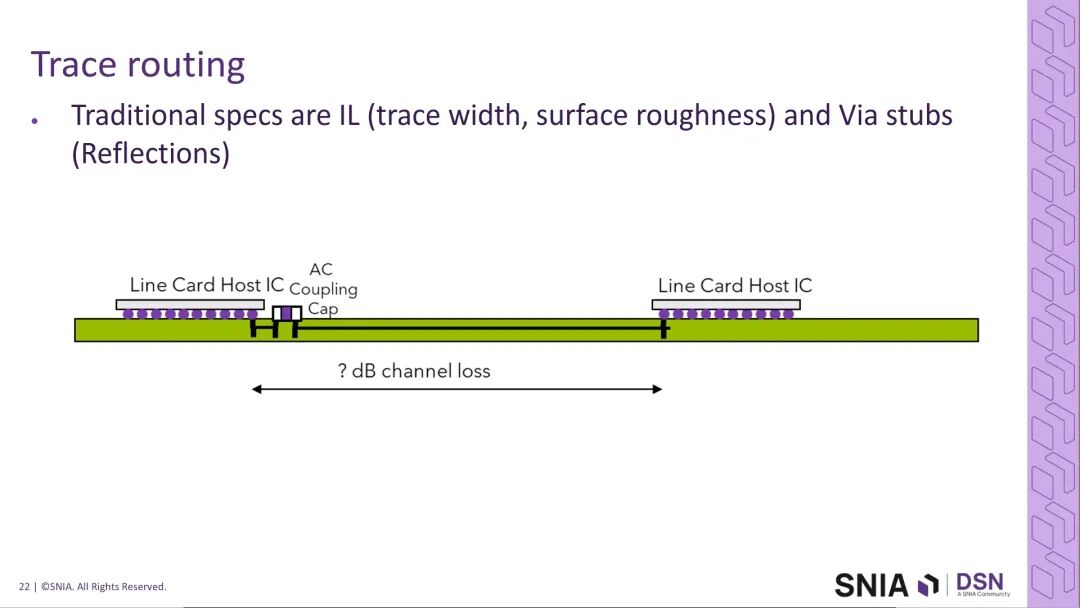
2.3 通道实现的瓶颈与仿真验证
完整的400G铜互连通道包括封装走线、PCB布线、连接器、传输线缆四大核心环节,各环节的损耗特性直接决定了通道的可行性。
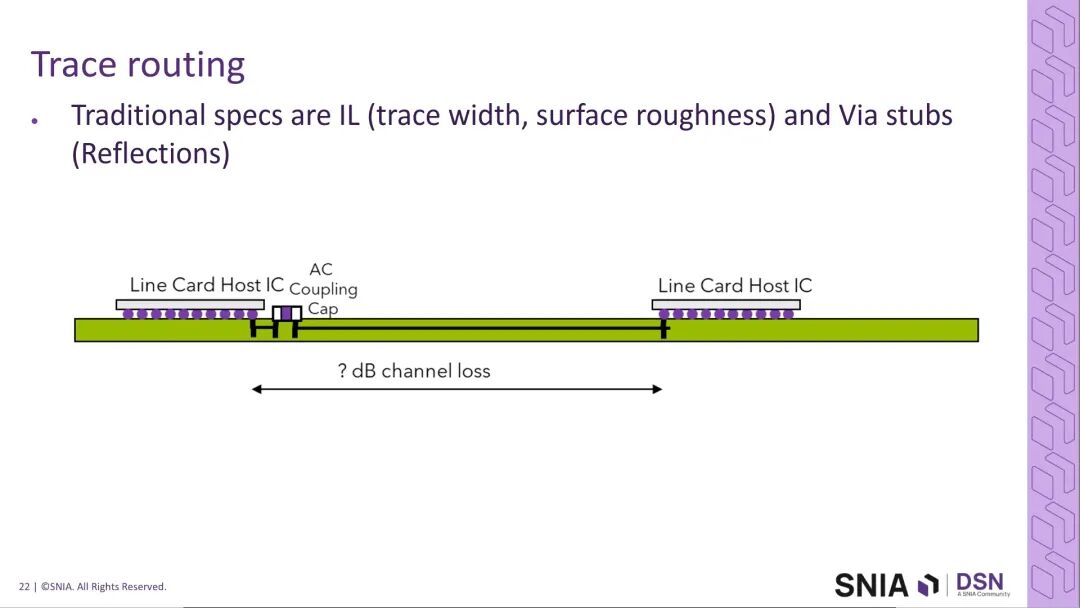

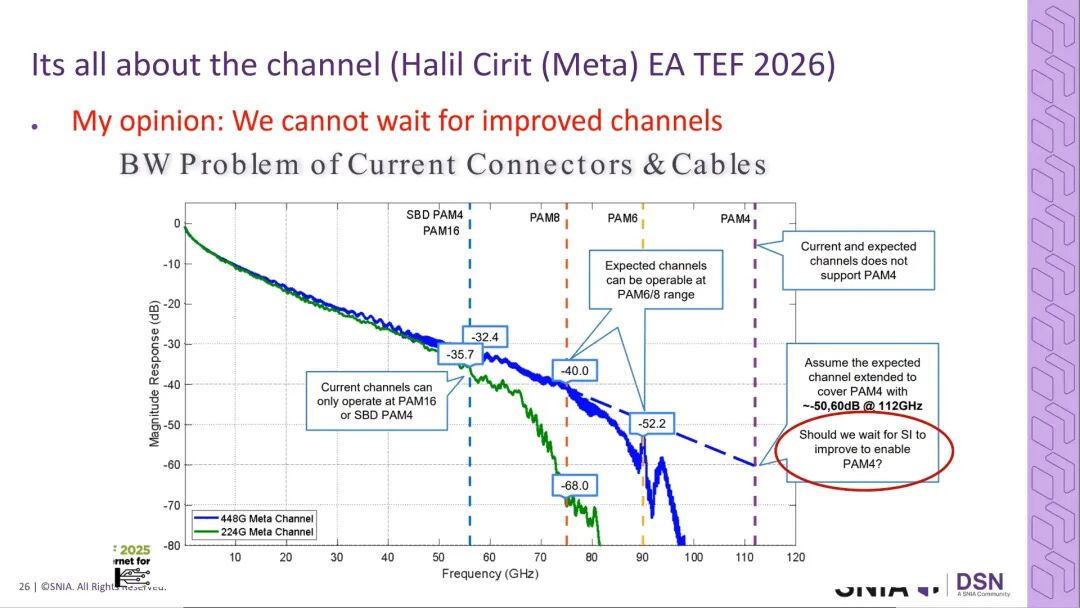
在PCB布线环节,传统224G通道的插入损耗特性无法支撑400G的任何调制方案,即使经过优化的全新通道,也仅能支撑PAM8与PAM6调制,无法满足PAM4所需的120GHz带宽需求。行业明确,无法等待PCB材料技术的迭代升级,必须在1年内完成400G互连的技术落地,否则AI系统厂商将转向替代技术方案。

连接器是当前400G互连的最大瓶颈,连接器的插入损耗与串扰性能直接决定了调制方案的选型,当前行业内的连接器带宽尚未被公开证明可支撑400G所需的高调制速率,相关技术细节仍处于保密阶段。
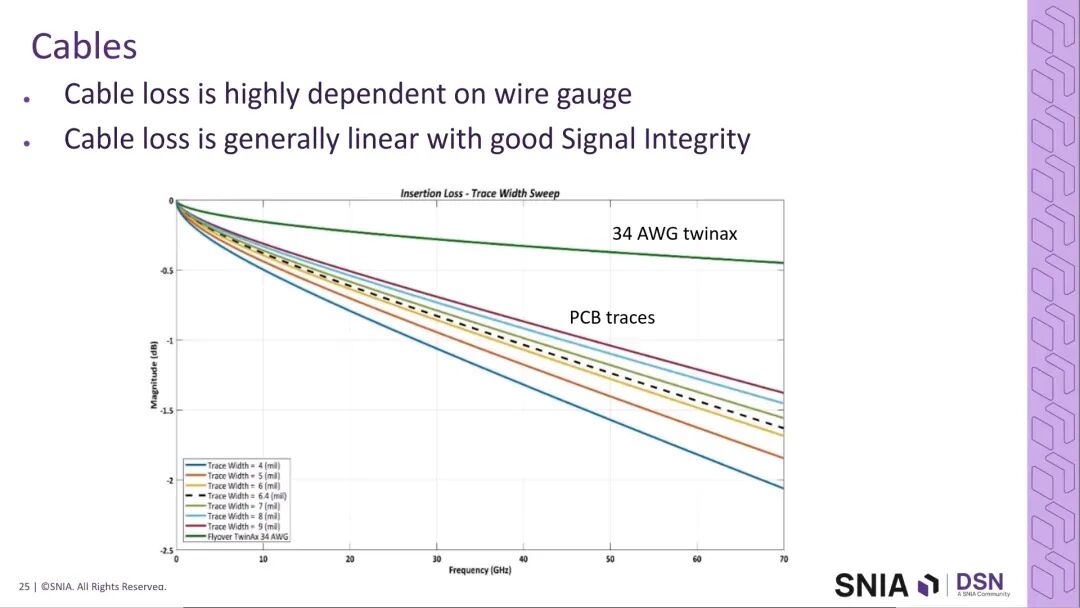
传输线缆方面,Twinax线缆是400G铜互连的核心传输介质,其插入损耗随频率提升呈线性增长,而非断崖式下降。现有公开数据可支撑70GHz以内的稳定传输,行业内部已有验证数据可将其性能延伸至PAM4所需的120GHz,线缆本身不会成为400G互连的限制因素。

在通道仿真与验证层面,行业已完成多轮技术验证:
- Socionext的封装测试数据显示,现有封装材料在224G速率下的插入损耗仅为3-6dB,400G PAM8调制下为6-9dB,PAM6调制下为9-12dB,可稳定支撑GPU-to-GPU的短距传输,但无法满足3米背板线缆的长距需求;
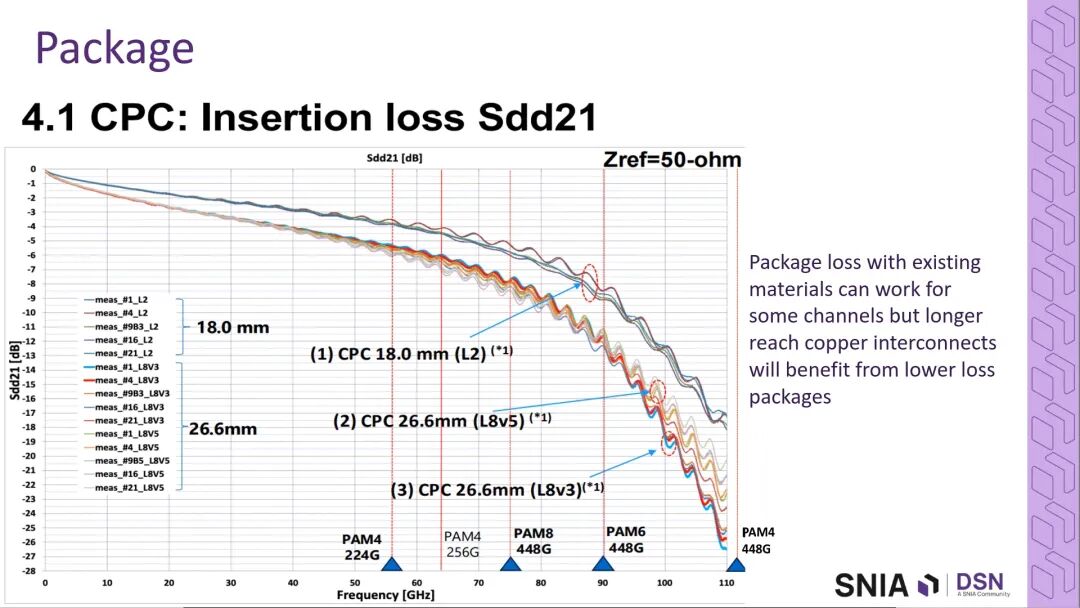
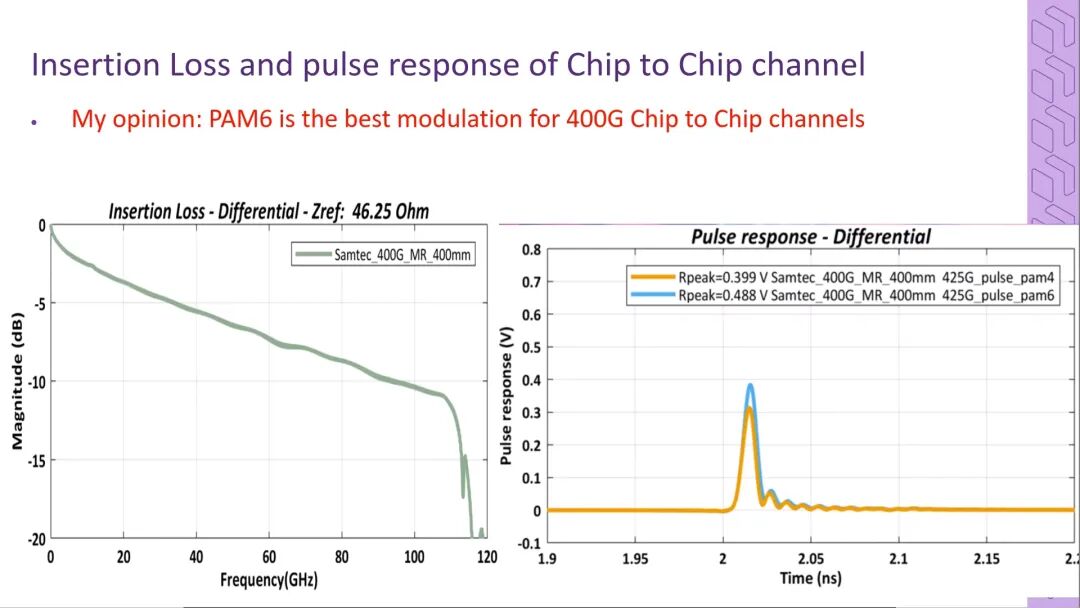
- 基于CPC的完整通道仿真结果显示,通道在100GHz以内的插入损耗曲线平滑,110GHz处仍具备良好的脉冲响应,可稳定支撑PAM6 400G芯片到芯片互连,甚至有机会实现PAM4的超短距传输;
- Amphenol提供的前面板可插拔模块通道仿真数据显示,通道在100GHz以内的插入损耗特性良好,PAM6调制下插入损耗约30dB,具备落地可行性,但无法支撑PAM4的带宽需求。
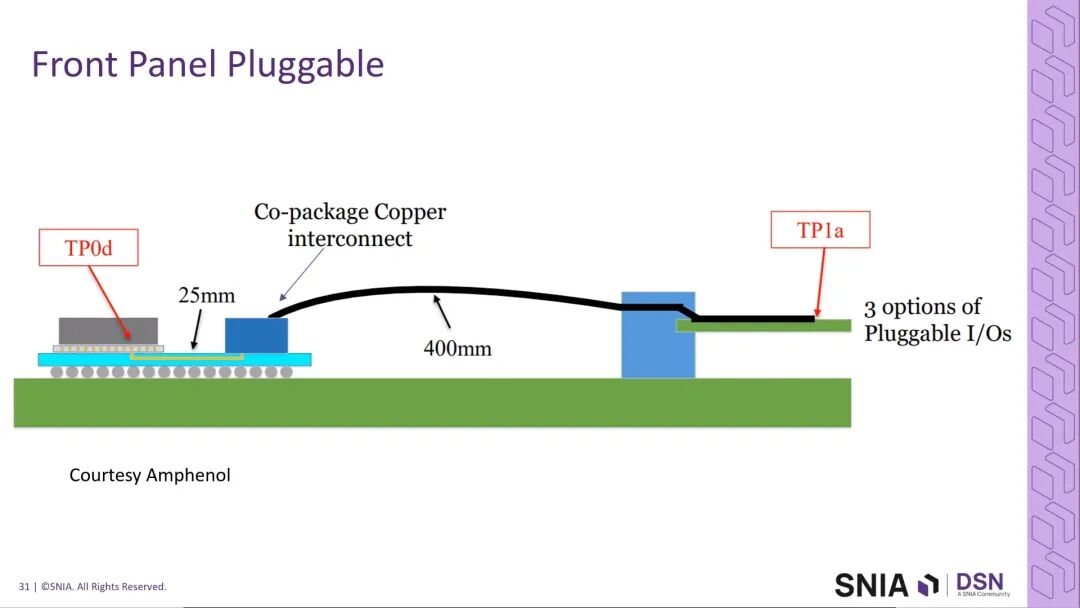
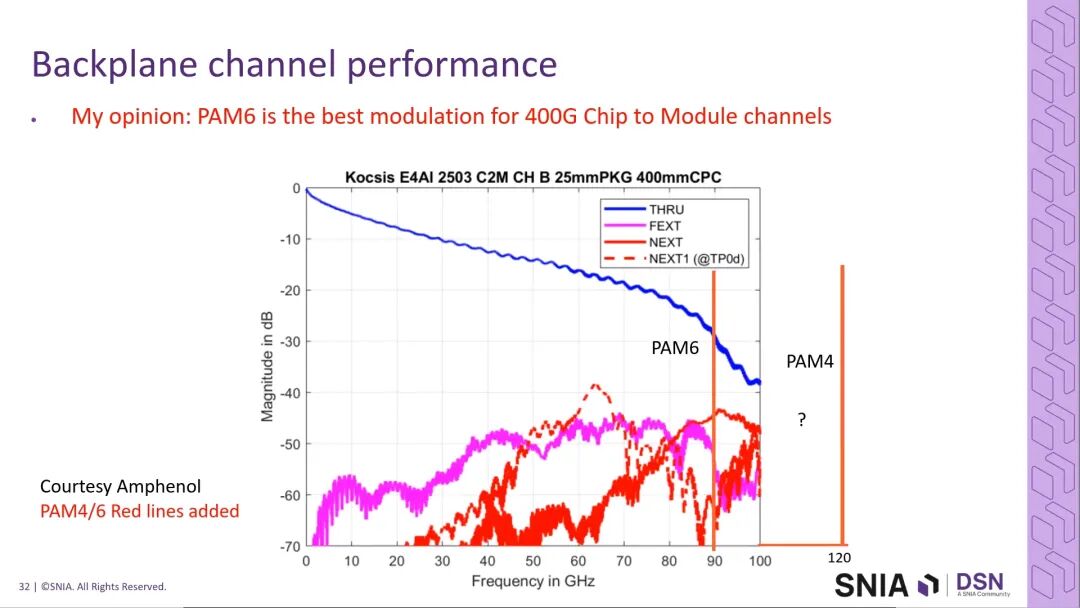
三、PCIe 8.0时代的存储互连技术演进

SSD作为PCIe通道的核心端点设备,是PCIe技术代际演进的核心验证载体,其拓扑路径的长度与复杂度逼近PCIe通道性能极限。本章节聚焦PCIe从5代到8代的技术演进,拆解存储互连的核心挑战与优化方案。
3.1 PCIe代际演进的损耗挑战
传统PCIe存储拓扑为:根复合体root complex→主板走线→连接器→线缆→背板→SSD连接器→SSD端点,完整路径长度可达1米,同时包含大量主板、背板走线与多个连接器,插入损耗与回波损耗是核心挑战。
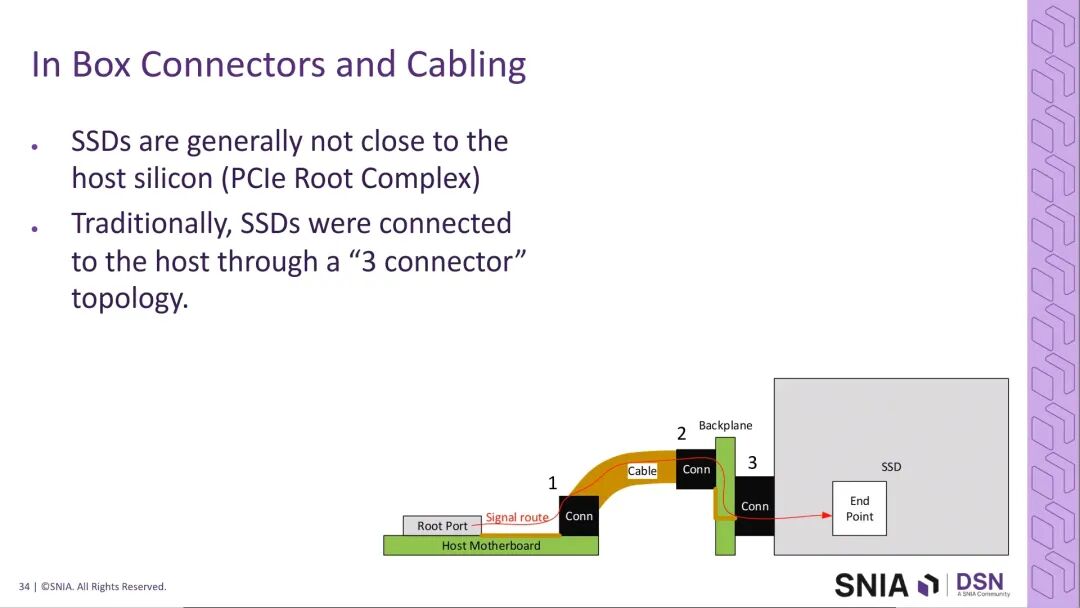
随着PCIe代际的提升,通道的奈奎斯特频率成倍增长,插入损耗的压力呈指数级上升:

- PCIe 5/6的奈奎斯特频率为16GHz,普通主板走线的插入损耗约为1.5dB/英寸,可通过低损耗PCB材料实现性能优化;
- PCIe 7的奈奎斯特频率提升至32GHz,相同PCB材料下的走线插入损耗恶化约70%,通道损耗预算的压力大幅提升;
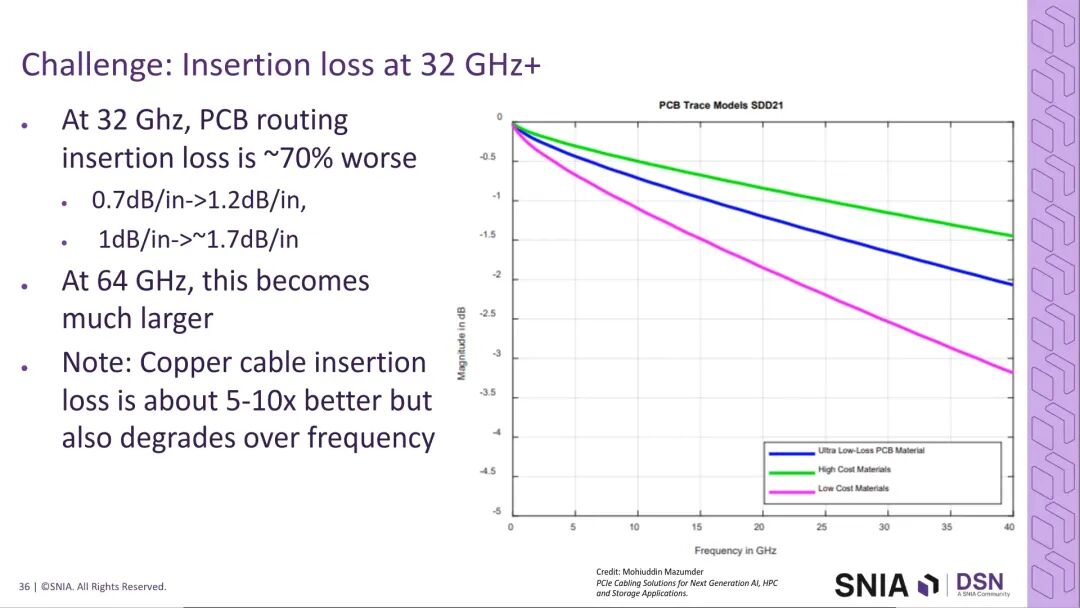
- PCIe 8的奈奎斯特频率将达到64GHz,当前行业预期其将继续沿用PAM4调制,通道损耗与信号完整性的挑战将进一步加剧。

3.2 拓扑优化的核心突破
针对传统拓扑的损耗问题,行业已实现了从三连接器背板拓扑到双连接器拓扑的升级:取消传统的背板与对应连接器,线缆直接连接至SSD/设备连接器,midplane仅作为固定结构与低速信号、电源的传输载体。这一优化既消除了背板走线与一个连接器带来的插入损耗,也减少了阻抗不连续点,显著优化了回波损耗。
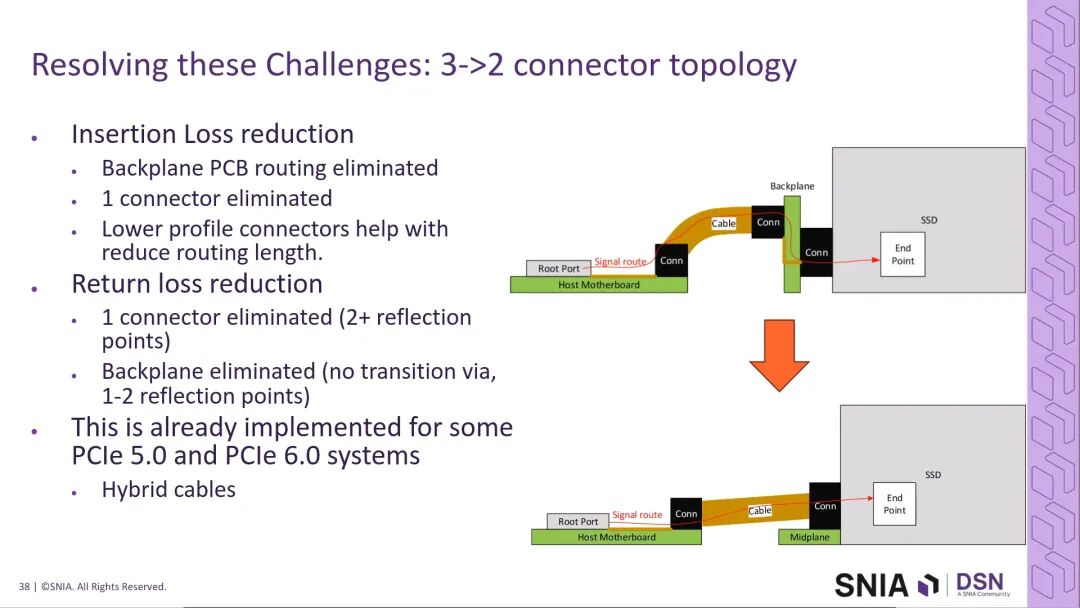
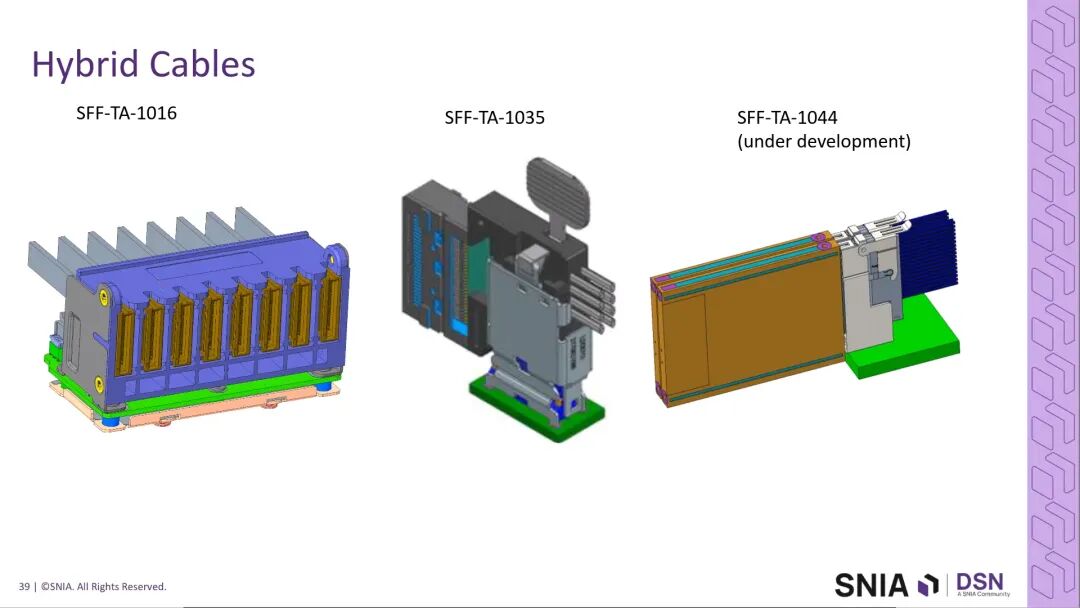
相关技术已通过SNIA发布的SFF-TA-1016、SFF-TA-1035规范实现规模化落地,同时SFF技术工作组正在开发新一代SFF-TA-1044连接器规范,进一步优化高速场景下的互连性能。
3.3 PCIe 8.0的技术使能方向

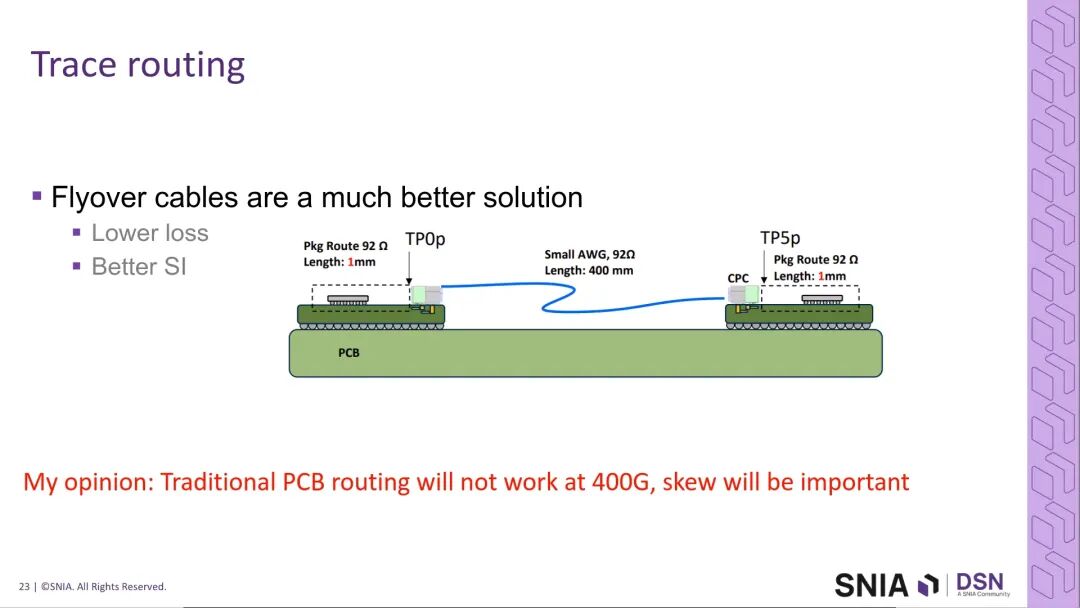
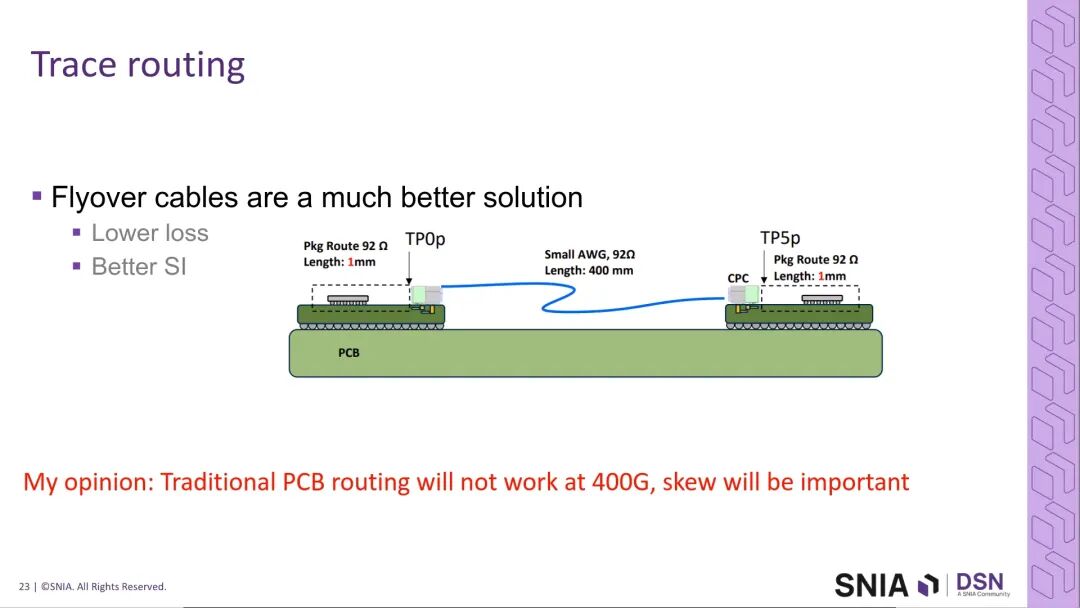
行业分析认为,PCIe 7可通过高端低损耗PCB材料与拓扑优化实现稳定落地,但PCIe 8.0必须引入额外的技术方案来应对通道损耗的挑战,核心使能技术包括:有源铜缆(线缆两端集成重定时器,补偿通道损耗)、有源光缆、PCIe SIG推出的LPO直驱光学接口规范,同时低损耗PCB材料的优化仍将持续,但仅靠材料升级无法满足PCIe 8.0的长期需求。
四、铜与光的技术拐点:光学互连的规模化落地路径

随着速率的提升,铜互连的带宽瓶颈日益凸显,光学互连成为长距、高速场景的核心替代方案。本章节拆解400G时代铜与光的技术拐点,以及光学互连规模化落地的核心条件。
4.1 铜与光的调制方案分化
铜互连的核心限制是带宽,而光学互连的核心限制是噪声,这一差异导致400G时代可能出现调制方案的分化:铜互连将采用PAM6调制平衡带宽与SNR需求,光学互连将沿用PAM4调制匹配其噪声受限的特性,两种调制方案的转换将在光模块内部完成。当前的核心技术挑战,是DSP能否同时支持PAM4与PAM6两种调制方案。
4.2 光学互连的架构演进
当前主流的光学互连架构为:交换机ASIC→封装→PCB走线→前面板可插拔光模块(内置DSP)→光纤传输,该架构已完成200G速率的规模化落地,相关技术规范已完善。针对400G时代的需求,行业提出了两大演进方向:
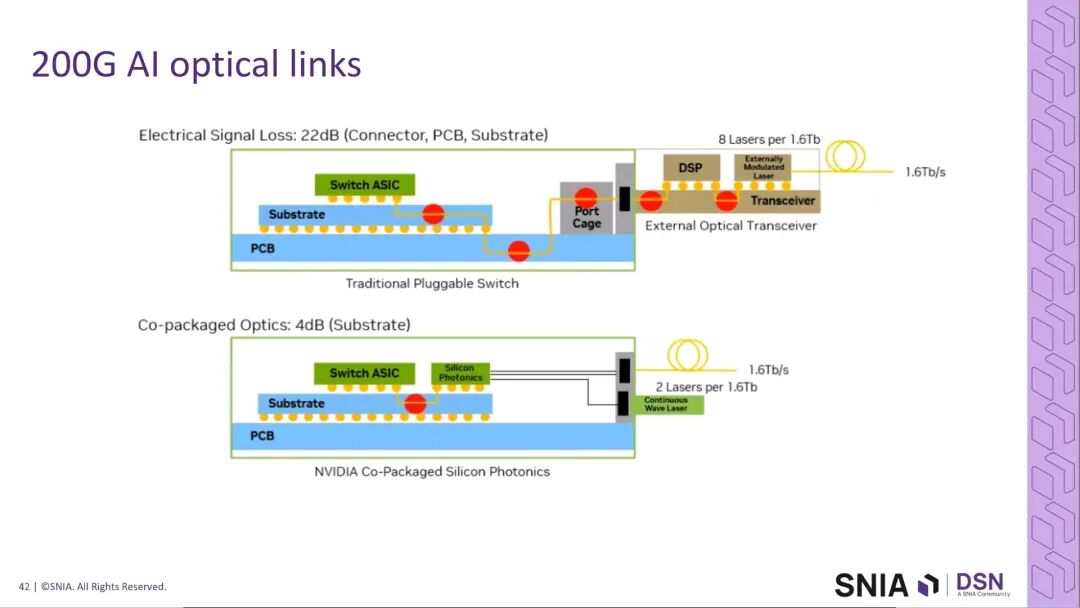
其一,基于CPC的低功耗光模块方案,该方案通过CPC技术将通道插入损耗从传统的32dB降至22dB,可取消光模块内部的DSP,大幅降低功耗与成本,当前LPO MSA工作组正在制定相关技术规范,200G场景已在落地过程中。
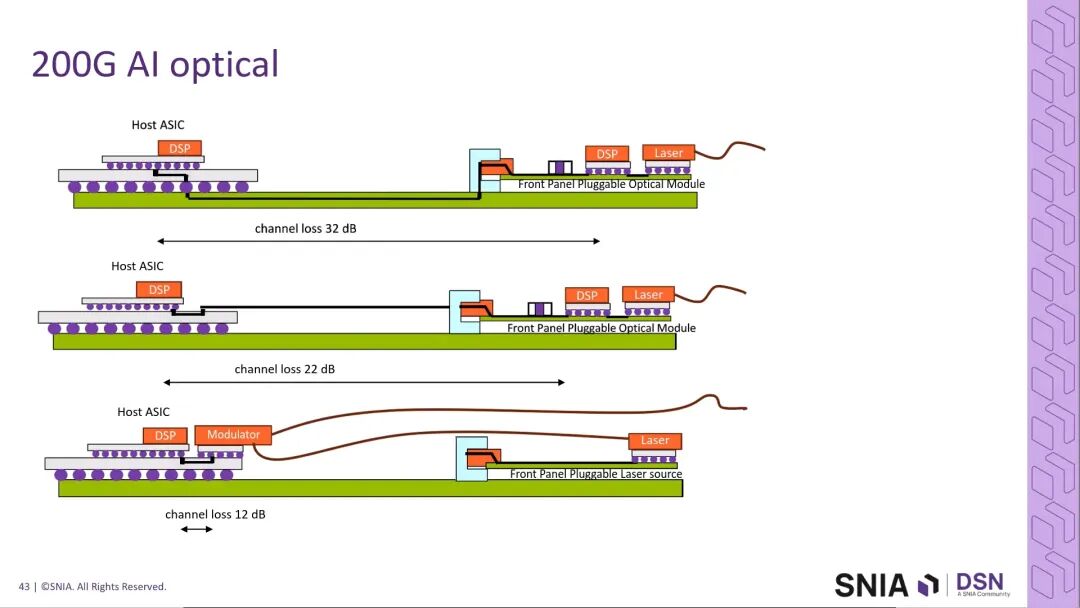
其二,共封装光学(CPO)架构,将光模块直接集成在芯片封装顶部,ASIC的信号直接通过封装顶部的光学接口输出,通道插入损耗可降至12-15dB,仅保留ASIC端的DSP,大幅优化了功耗与信号完整性。该架构采用前面板可插拔的激光器设计,单个激光器可支撑8个调制器,解决了封装顶部的热源集中问题。
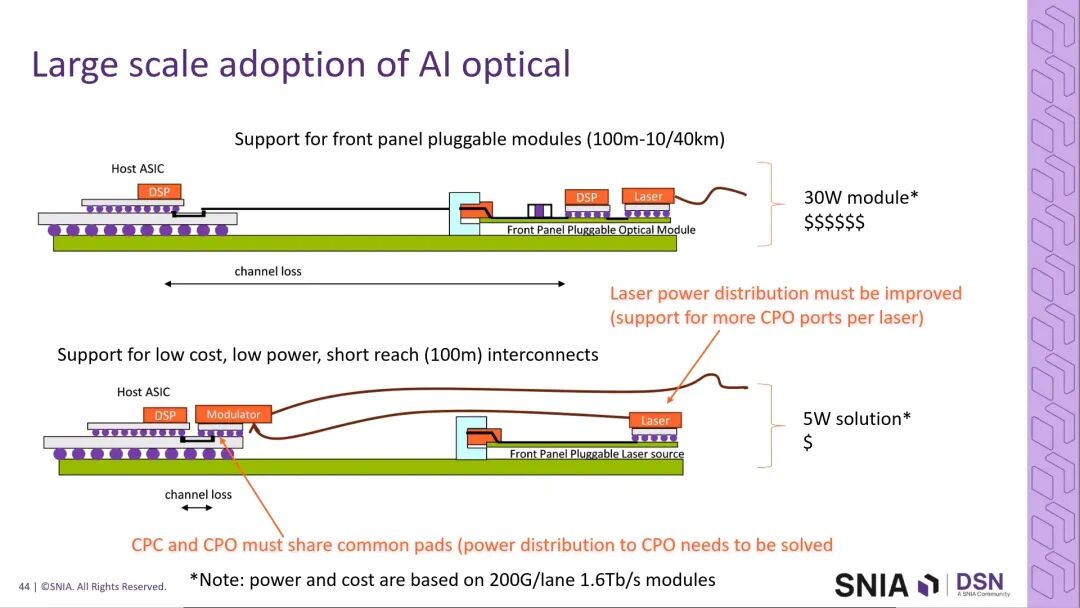
4.3 光学互连规模化落地的核心条件
行业技术观点明确了光学互连的落地路径:
- 400G时代,前面板可插拔光模块是长距传输场景的必选项,将采用CPC+Twinax线缆直连的架构,内置DSP,功耗>30W,可支撑500米至40公里的传输距离;
- 要实现机架内、盒内短距场景的光学互连规模化渗透,必须实现功耗约5W、传输距离达100米的CPO方案,同时需要实现单个激光器支撑的调制器数量翻倍,以及CPC焊盘的铜/光共用设计;
- CPO的可靠性优势显著,Meta的实测数据显示,CPO的链路稳定性远优于前面板可插拔模块,可大幅减少模块插拔带来的链路闪断问题,这将成为CPO规模化落地的重要支撑。
五、AI场景驱动的SSD技术协同演进

互连技术的代际升级,需要配套的存储系统同步演进,才能充分释放AI负载的性能潜力。本章节拆解AI场景对SSD的两大核心需求方向:面向高性能的AI SSD,以及面向大容量成本优化的近线SSD。

5.1 AI SSD的性能、功耗与散热挑战
AI场景下,存储作为GPU补充内存的核心定位,要求SSD提供极致的带宽与IOPS能力,也就是AI SSD。AI SSD需要匹配PCIe 7/8.0的带宽能力,要求高性能主控ASIC与后端NAND带宽的同步升级,从PCIe 6到PCIe 7/8,SSD的功耗预计将提升50%以上,功耗与散热成为核心瓶颈。

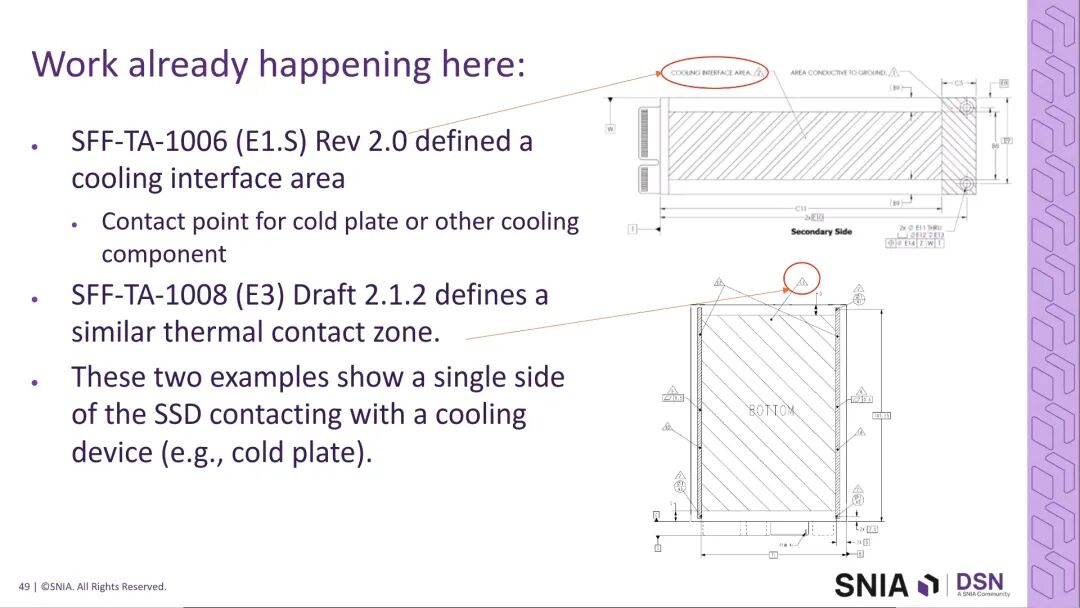
当前EDSFF系列SSD的连接器最大支持79W的功率传输,更高功率的需求需要连接器的优化修改,行业正在推进相关规范的迭代,同时维持向后兼容。在散热层面,传统风冷可支撑PCIe 6及之前的SSD散热需求,PCIe 7及以上将面临显著的散热压力。行业正在推进基于冷板的直接液冷技术,已在去年末发布针对SFF SSD的液冷规范,定义了专用的冷却接口区域,同时正在开发更多规格的液冷SSD规范。

当前的液冷方案以单面冷却为主,可支撑PCIe 7的散热需求,更高代际的PCIe SSD可能需要双面冷却方案。需要明确的是,E1.S规格的所有厚度版本均无法支持冷板冷却,当前行业的液冷规范聚焦E3.S、E3.L的7.5mm厚度版本,以及E1.S的9.5mm厚度版本。
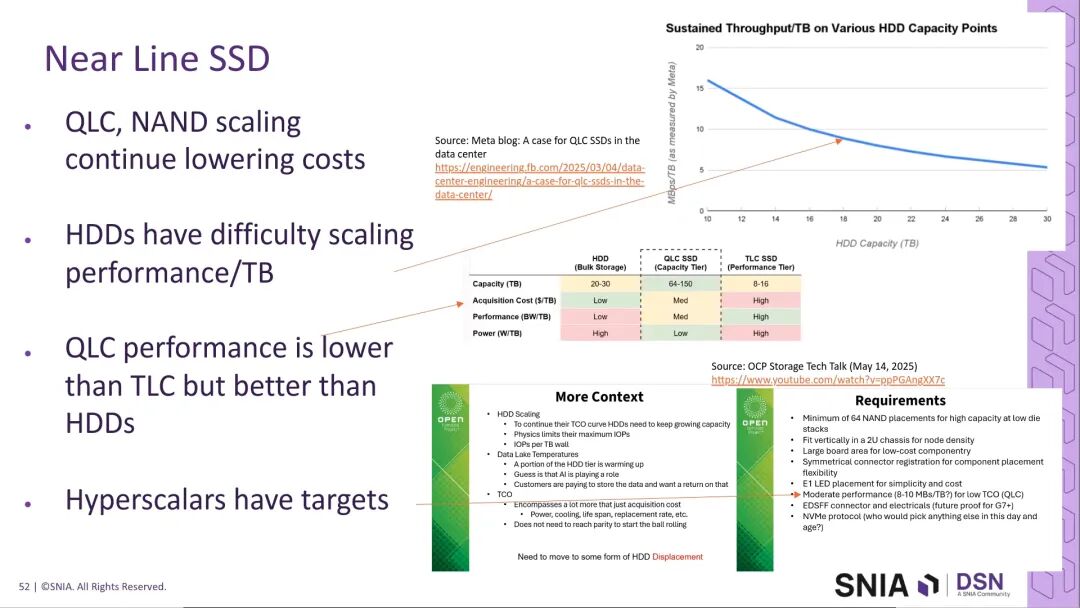
5.2 近线SSD的容量与成本优化
AI负载带来的冷数据变暖趋势,要求大容量SSD维持稳定的每TB带宽,平衡容量、性能与成本。随着QLC NAND的持续成本下探,近线SSD成为行业的核心发展方向,近线SSD聚焦成本优化,同时维持AI负载所需的基础性能,其性能表现优于HDD,低于TLC SSD。

提升SSD的标称容量可有效降低整体机架与系统成本,行业观点认为,E2规格是实现大容量近线SSD的最优成本路径,可通过堆叠更多NAND裸片实现容量的大幅提升,同时维持可控的成本。


结语

400G高速互连与PCIe 8.0是下一代AI基础设施的核心底座,其技术演进始终围绕信号完整性优化、插入损耗控制、功耗成本平衡三大核心命题展开。共封装铜互连、拓扑优化、共封装光学、直接液冷等技术,将成为两大技术体系落地的核心支撑。同时,存储系统的演进必须与互连技术同步,才能打通AI负载端到端的数据流动瓶颈,充分释放AI算力的潜力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号