Nat. Med. | 用于复杂心脏病诊疗的大型语言模型

Nat. Med. | 用于复杂心脏病诊疗的大型语言模型

DrugOne
发布于 2026-03-02 17:30:16
发布于 2026-03-02 17:30:16
DRUGONE
全球范围内专科医疗资源严重短缺,尤其在心脏病领域,及时、精准的管理直接决定患者预后。研究人员评估了一种名为 Articulate Medical Intelligence Explorer(AMIE)的基于大型语言模型的实验性医疗人工智能系统,探讨其在复杂心脏病诊疗中的辅助价值。研究设计为一项随机对照试验,纳入107例疑似遗传性心肌病的真实世界病例,由9名普通心脏科医生在有无 AMIE 辅助的情况下完成临床评估。三名盲法亚专科心脏病专家依据十个维度的评价标准,对分诊、诊断及管理质量进行评分。结果显示,整体而言,专家更倾向于 AMIE 辅助的评估结果。与单独医生相比,AMIE 辅助组在管理方案与诊断检查方面获得更高偏好比例,并显著减少临床重大错误与内容遗漏。同时,医生报告在超过一半病例中,AI 提升了评估质量并节省了时间。本研究为大型语言模型在复杂专科临床场景中的应用提供了随机对照试验级别证据。

全球医疗体系面临专科医生不足的问题,复杂且罕见疾病的诊疗尤为困难。在遗传性心肌病领域,及时识别与干预可显著降低猝死风险,但许多地区缺乏专科中心,导致大量患者未被诊断。大型语言模型近年来在医学问答、文本总结等方面表现突出,但在真实专科场景中的系统性随机评估仍然稀缺。研究人员因此选择遗传性心肌病这一高风险、强依赖多模态检查的领域,检验大型语言模型是否能够提升普通心脏科医生的决策质量。
研究设计与数据集构建
研究人员构建了一项完全盲法、平衡设计的随机对照试验。数据来源于斯坦福遗传性心血管疾病中心的真实患者,包括心电图(ECG)、超声心动图(TTE)、心脏磁共振(CMR)、动态心电监测、心肺运动试验(CPX)等多模态检查文本报告及原始数据。每个病例由两名普通心脏科医生分别评估,其中一名随机分配使用 AMIE 辅助。
医生需完成标准化评估表,包括总体印象、是否需转诊、最可能诊断、进一步检查建议及管理方案。亚专科专家在盲法条件下对两组结果进行A/B直接偏好比较,并对错误、遗漏、推理质量与偏倚等方面进行单独评分。
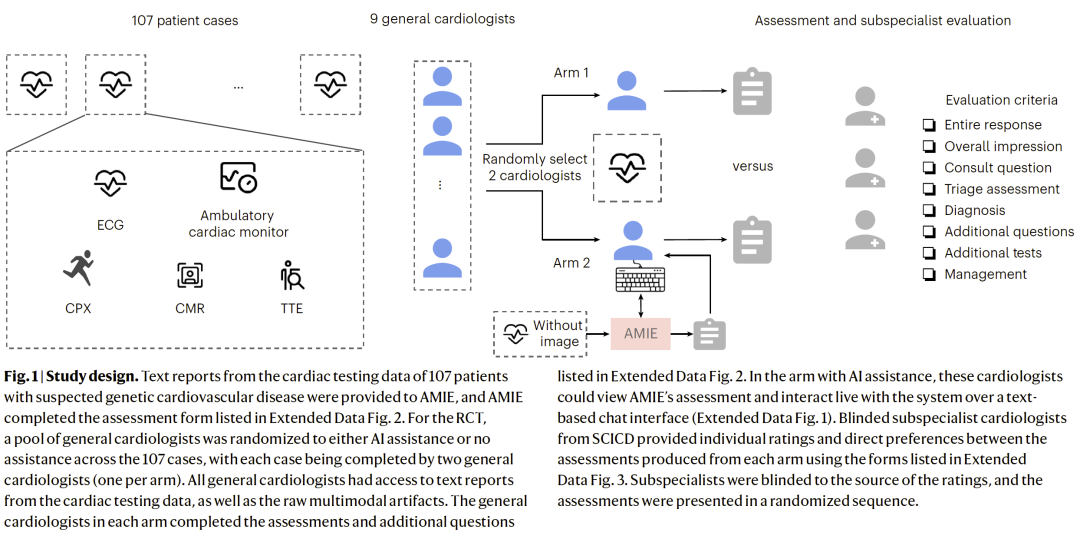
图1:研究设计流程。
普通心脏科医生对AI辅助的主观评价
多数医生对 AI 融入临床流程持积极态度。在57%的病例中,医生认为 AI 改善了临床评估;在超过50%的病例中,AI 增强了决策信心;约50%的病例报告节省时间。AI 幻觉现象发生率较低,多数情况下不存在明显错误或遗漏。医生指出,AI 有助于补充罕见疾病知识、拓展诊断思路并提高效率,但偶尔存在过度自信或信息冗余等问题。
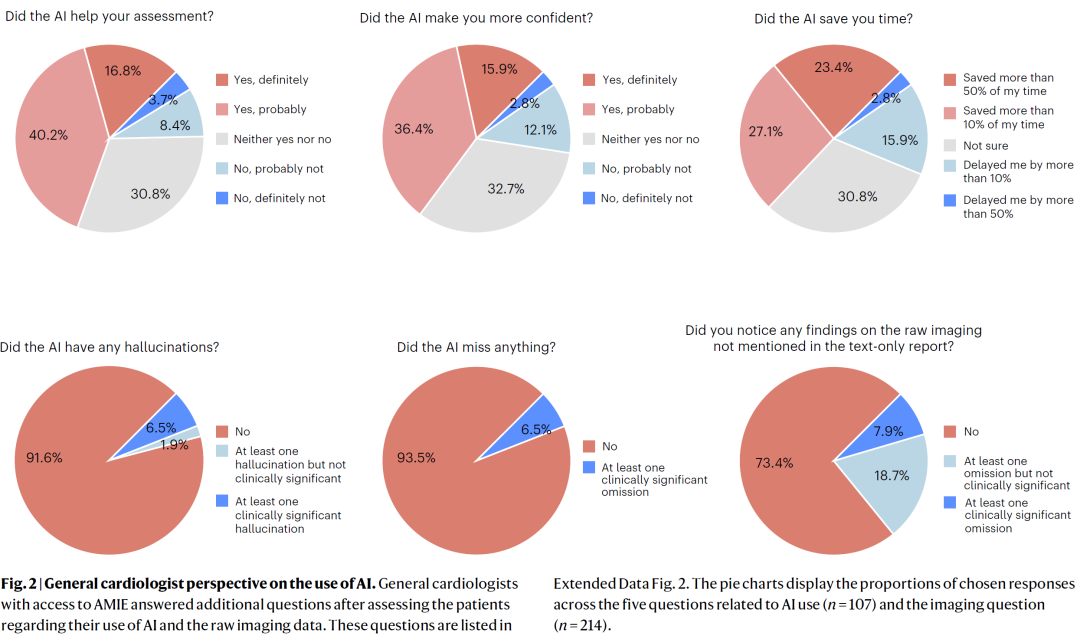
图2:普通心脏科医生对AI使用体验的评价。
亚专科专家的盲法比较结果
在整体评估层面,AMIE 辅助组被偏好的比例为46.7%,显著高于单独医生组的32.7%。在管理方案与进一步检查建议方面,AMIE 辅助组优势更为明显。对于分诊与初步诊断等部分领域,两组表现接近。
在具体质量指标上,AMIE 辅助组的临床重大错误比例显著下降(13.1% 对 24.3%),遗漏重要信息的比例也明显减少(17.8% 对 37.4%)。两组在推理步骤与人口学偏倚方面未见显著差异。这表明 AI 辅助主要通过减少错误和遗漏来提升质量,而非改变推理结构。
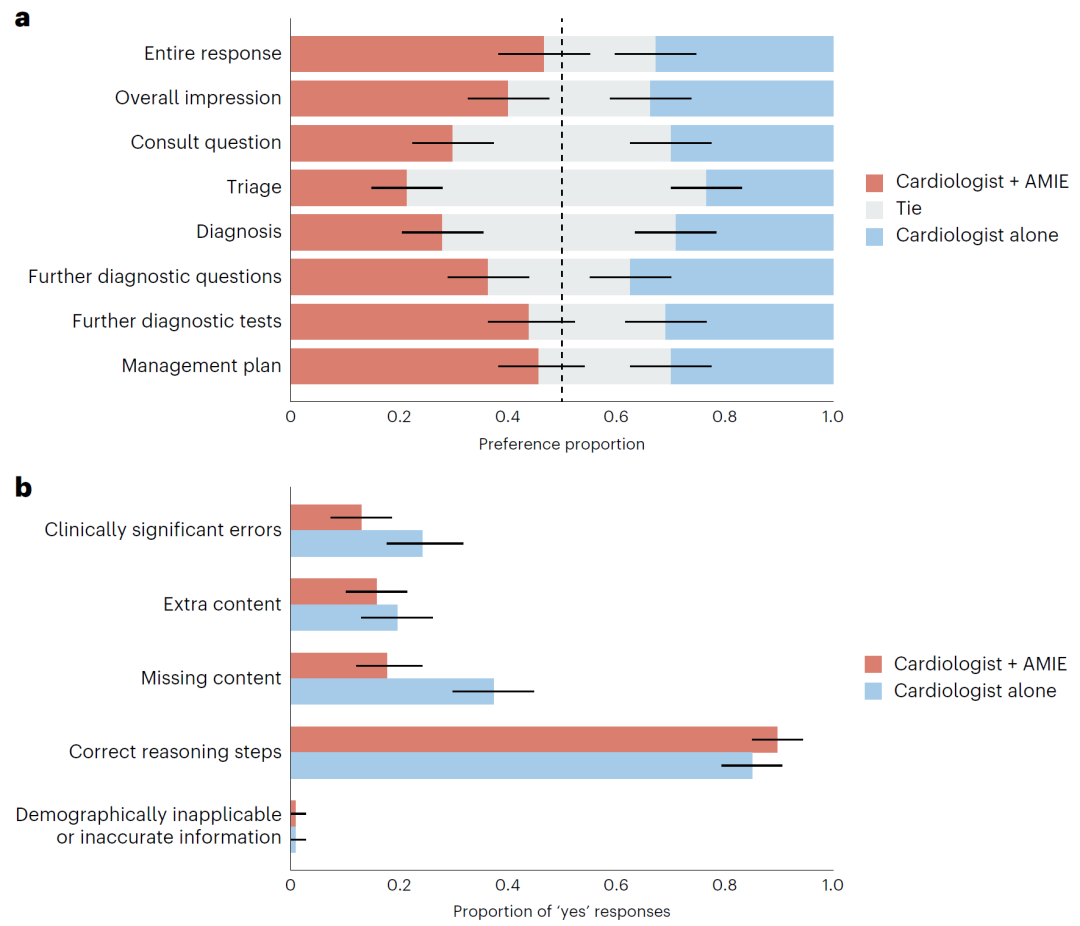
图3:亚专科专家偏好与质量指标比较。
质性分析:AI优势与风险
定性分析显示,AMIE 辅助结果通常更加全面,并引入先进诊断与治疗建议。然而,也存在信息过多或诊断推断过度的问题。个别病例出现幻觉,例如假设影像学未报告的特征或错误解读定量数据,但在医生质疑后系统可自我修正。
研究人员强调,当前模型不适合自主临床部署。尽管 AI 辅助降低了总体错误率,但仍需医生监督以避免自动化偏倚与过度依赖。
研究意义与局限
本研究是心脏病专科领域少数采用随机对照试验设计评估大型语言模型的研究之一,且使用真实患者数据。研究人员公开了数据集与评价标准,为后续研究提供基础。
然而,本研究存在局限:模型仅基于文本报告而非直接处理原始影像;病例来自单一中心;未纳入前瞻性真实临床部署;未评估长期患者结局。此外,自动化偏倚与健康公平问题仍需进一步研究。
结论
研究结果表明,在复杂遗传性心脏病评估中,AMIE 能够提升普通心脏科医生的评估质量,减少临床重大错误与信息遗漏,同时提高效率与信心。在严格监督下,大型语言模型有潜力成为专科医疗资源不足环境中的重要辅助工具。然而,其安全部署仍需更大规模、前瞻性临床研究验证。
整理 | DrugOne团队
参考资料
O’Sullivan, J.W., Palepu, A., Saab, K. et al. A large language model for complex cardiology care. Nat Med (2026).
https://doi.org/10.1038/s41591-025-04190-9

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号