CANN 技术全景图:构建自主可控的 AI 全栈底座

CANN 技术全景图:构建自主可控的 AI 全栈底座

晚霞的不甘
发布于 2026-02-09 16:56:45
发布于 2026-02-09 16:56:45
CANN 技术全景图:构建自主可控的 AI 全栈底座
在“算力自主”成为国家战略的今天,一个完整的 AI 软件栈必须回答三个问题:
- 能否高效利用国产芯片?(硬件亲和)
- 能否支撑前沿算法演进?(算法兼容)
- 能否满足工业级落地需求?(工程可靠)
CANN(Compute Architecture for Neural Networks) 正是围绕这三大命题,构建了一套覆盖 “芯片 → 驱动 → 编译器 → 运行时 → 框架 → 行业方案” 的全栈体系。
相关资源链接 cann组织链接:cann组织 ops-nn仓库链接:ops-nn仓库
一、CANN 全栈架构五层模型
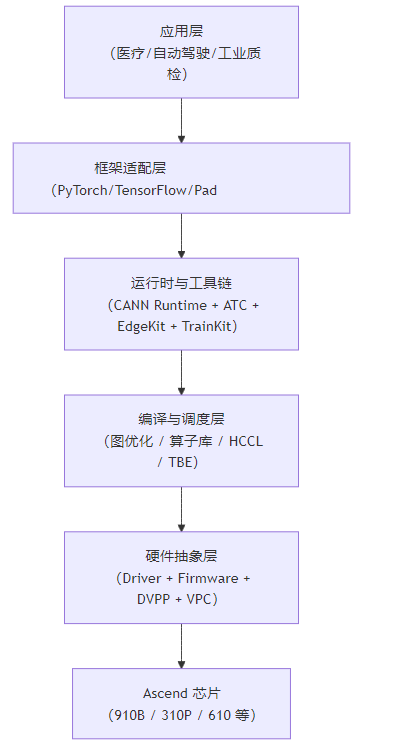
每一层都承担关键职责,共同构成“训推一体、云边协同”的 AI 底座。
二、逐层解析:CANN 的核心技术能力
第 5 层:Ascend 芯片 —— 算力之源
- 达芬奇架构 NPU:Cube 单元支持 INT8/FP16/FP32 混合计算;
- 高能效比:910B 达 256 TFLOPS FP16,功耗仅 300W;
- 专用加速单元:
- DVPP:图像/视频预处理(JPEG 解码、Resize、色彩转换);
- VPC:视觉后处理(ROI Crop、Format Convert);
- AIPP:AI 预处理(归一化、通道交换)。
✅ 芯片设计即面向 AI 工作负载优化,非通用 GPU 改造。
第 4 层:硬件抽象层(HAL)—— 屏蔽底层差异
- 统一驱动接口:
acl.rt/acl.dvppAPI 跨芯片兼容; - 固件管理:动态加载微码,支持 OTA 升级;
- 资源虚拟化:多进程共享 NPU,支持容器化部署。
示例:DVPP 图像解码(零 CPU 参与)
acldvppJpegDecodeAsync(jpeg_data, output_yuv, stream);
aclrtSynchronizeStream(stream); // 等待 NPU 完成⚡ 减少 CPU-GPU 数据拷贝,端到端延迟降低 30%。
第 3 层:编译与调度层 —— 性能引擎
核心组件:
组件 | 功能 |
|---|---|
ATC 编译器 | ONNX → CANN IR → .om,支持图优化、量化、融合 |
TBE(Tensor Boost Engine) | 自定义算子开发框架(Python/C++) |
HCCL | 高性能集合通信库,替代 NCCL |
Runtime Scheduler | 确定性任务调度,支持 ASIL-B |
🔑 关键创新:软硬协同编译——编译时感知芯片拓扑、内存带宽、计算单元数量。
第 2 层:运行时与工具链 —— 开发者体验
工具 | 用途 |
|---|---|
CANN Runtime | 轻量推理引擎(<10MB),支持 Python/C++ |
msame / ais-bench | 模型 benchmark 与 profiling |
EdgeKit | 边缘设备全生命周期管理 |
TrainKit | 分布式训练集群管理 |
ModelZoo | 100+ 预优化模型(YOLOv8, Qwen-VL, BEVFormer 等) |
🛠️ 目标:让开发者“写得少,跑得快,管得住”。
第 1 层:框架与应用层 —— 生态连接器
- 原生支持:MindSpore(深度协同);
- 无缝兼容:
- PyTorch(via ONNX / TorchAdapter);
- TensorFlow(via tf2onnx);
- PaddlePaddle(via paddle2onnx);
- 行业 SDK:
- Medical SDK:DICOM 支持、热力图生成;
- Auto SDK:BEV 感知、功能安全封装;
- Vision SDK:工业质检模板、亚像素对齐。
🌐 不绑定单一框架,拥抱开放生态。
三、CANN 的差异化优势
维度 | 通用 GPU 方案 | CANN 方案 |
|---|---|---|
全栈可控 | 驱动/编译器闭源 | 从芯片到应用全自研 |
能效比 | 高性能但高功耗 | 同性能下功耗低 30~50% |
边缘部署 | 依赖 Jetson 等 | 原生支持 30W 以下平台 |
安全合规 | 需额外加固 | 内置 TEE、安全启动、审计日志 |
国产化适配 | 受限于供应链 | 完整信创生态支持 |
💡 CANN 的核心价值:不是“替代 GPU”,而是“重构 AI 计算范式”。
四、典型全栈落地案例
案例 1:三甲医院肺结节筛查系统
- 芯片:Ascend 310P(边缘服务器)
- 编译:ATC + 混合精度(检测头 FP32)
- 运行时:Medical SDK + DICOM-SR 输出
- 合规:等保三级 + 模型加密
- 效果:22 秒/例,医生采纳率 89%
案例 2:L4 无人配送车感知系统
- 芯片:双 Ascend 910B(域控制器)
- 训练:CANN-Train + 256 卡集群
- 推理:BEVFormer + 硬实时调度
- 安全:ISO 26262 ASIL-B 认证
- 效果:P99 延迟 48ms,30 天无故障
五、挑战与未来方向
当前挑战:
- 社区生态:相比 CUDA,开发者工具链仍需丰富;
- 长尾算子:部分科研模型需手动开发 TBE 算子;
- 跨厂商兼容:与其他国产芯片生态尚未打通。
未来重点:
- CANN IR 原生支持:绕过 ONNX,直接对接主流框架;
- AI 编译器升级:引入 MLIR,支持更激进优化;
- 云边端协同训练:边缘设备参与联邦学习;
- 开源策略深化:更多组件以 Apache 2.0 开源。
🔮 愿景:打造一个开放、高效、安全的国产 AI 基础软件根生态。
结语:全栈之力,方成自主之基
CANN 的意义,远不止于“一个推理引擎”。它代表了一种系统性思维——从晶体管到行业应用,每一层都为 AI 而生,每一环都可自主演进。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号