面向3D人体运动预测的语义信念状态世界模型:架构、原理与流形动力学
原创
面向3D人体运动预测的语义信念状态世界模型:架构、原理与流形动力学
原创
走向未来
发布于 2026-01-26 20:06:42
发布于 2026-01-26 20:06:42
语义信念状态世界模型(SBWM)重塑3D人体运动预测,深度解析具身智能和机器人的核心算法
走向未来
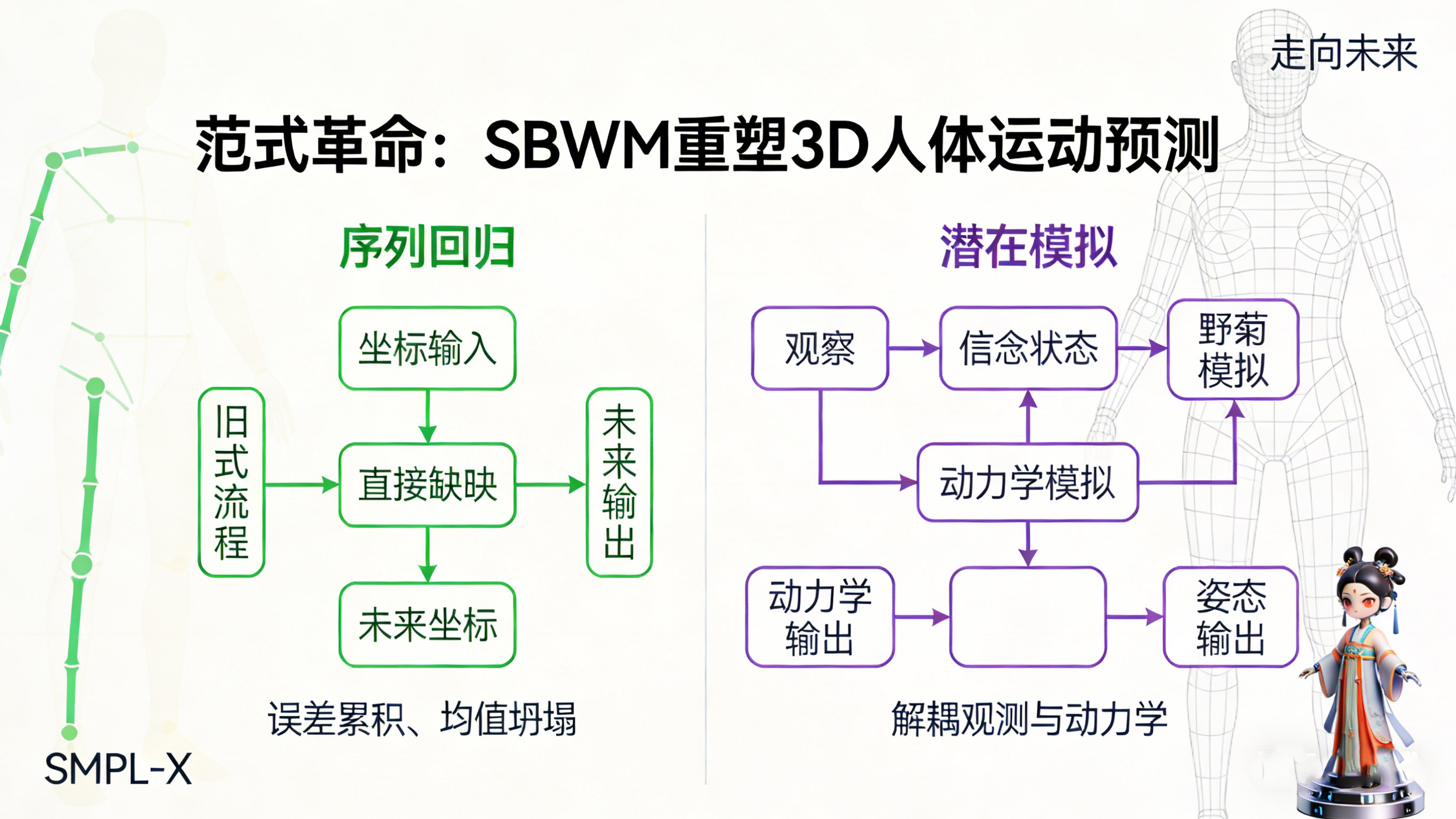
在人工智能与计算机视觉的交叉前沿,人体运动预测(Human Motion Prediction)正经历着一场静悄悄却具有颠覆性的范式革命。长期以来,这一领域被“序列回归”的思维定势所主导,无论是早期的循环神经网络(RNN)还是当下大热的Transformer与扩散模型(Diffusion Models),其本质均试图建立从历史姿态到未来姿态的直接映射。然而,这种基于观察空间的机械外推在面对长时程预测时,不可避免地陷入了误差累积、均值坍塌与动力学冻结的泥潭。
/Users/wgwang/futureland/0120/6.jpg
本文探讨了语义信念状态世界模型(Semantic Belief-State World Model, SBWM),将预测任务重构为“潜在动力学模拟”,在根本上解决了上述系统性难题。文章将详细阐述SBWM如何利用信念状态(Belief State)解耦观测与动力学,如何通过SMPL-X人体流形对齐引入结构化信息瓶颈,以及如何利用随机潜在变量实现“反冻结”动力学。同时,本文还将站在产业与战略的高度,评估这一技术突破对具身智能、机器人交互及元宇宙内容生成的深远影响。这不仅仅是一个新算法的诞生,更是AI对物理世界认知方式的一次升维——从“预测结果”进化为“模拟过程”。本文的PDF版本及相关参考资料都已经收录到走向未来知识星球,有兴趣的读者可加入星球获取。
一 范式转移:从序列外推到潜在模拟
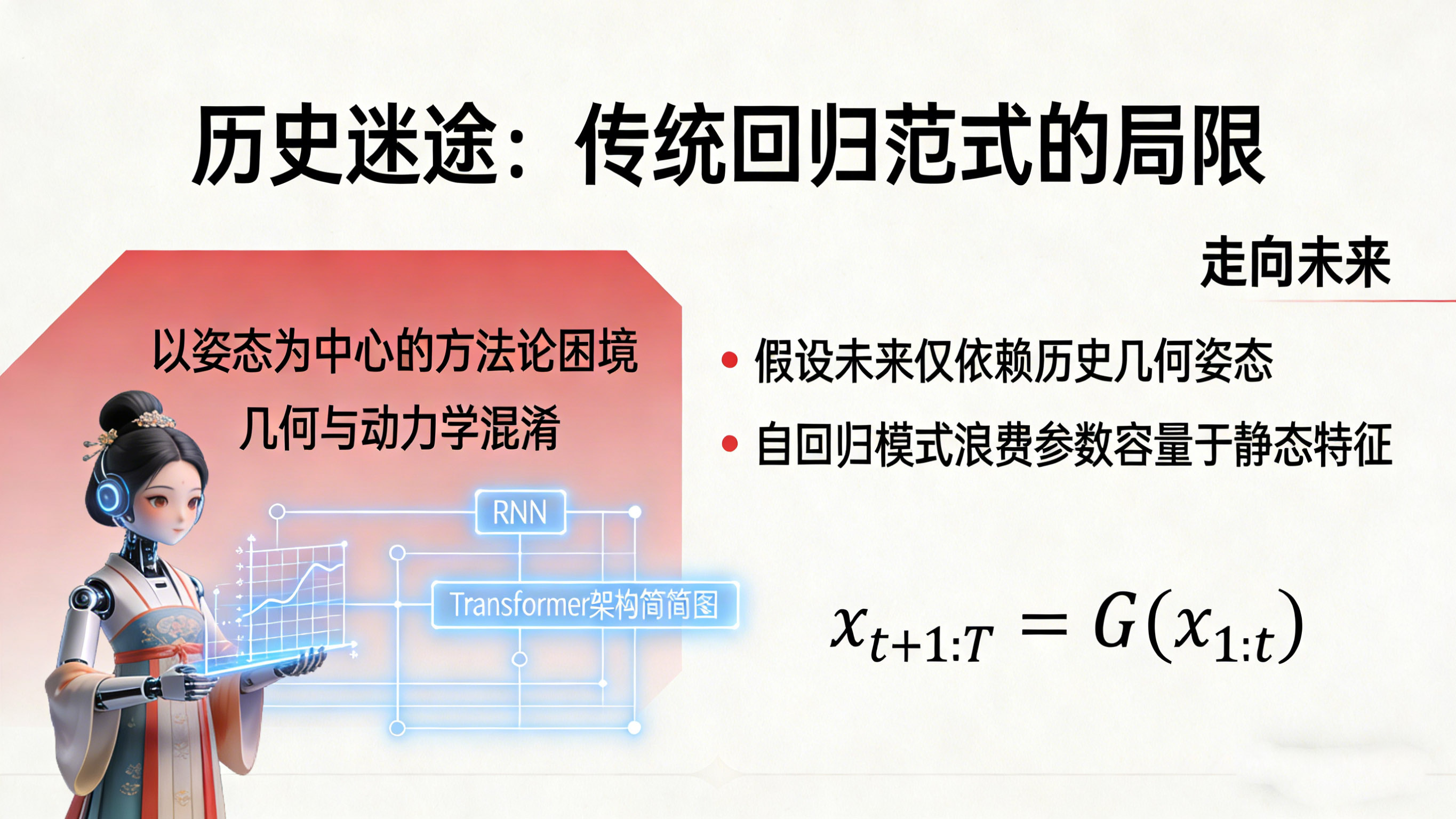
1.1 历史的迷途:回归范式的局限
过去十年,人体运动预测的研究轨迹可以说是一部不断堆砌模型容量的历史。从最初的线性动力系统(LDS),到能够捕捉非线性关系的RNN与LSTM,再到利用注意力机制捕捉长距离依赖的Transformer,乃至近期利用生成式去噪过程建模分布的扩散模型,学术界的努力主要集中在设计更复杂的函数 以拟合映射 。
/Users/wgwang/futureland/0120/7.jpg
这种“序列回归”范式隐含着两个危险的假设:第一,未来的运动完全取决于过去观察到的几何姿态;第二,模型可以通过不断地将自己的预测结果作为输入(自回归),来推演长远的未来。然而,现实物理世界特别是生物体的运动规律,并不直接显露在几何姿态的表面。一个人的下一个动作,往往不取决于他上一秒手肘的坐标,而取决于他内在的意图(Intent)、当前的平衡状态(Balance)、积累的动量(Momentum)以及所处的运动相位(Phase)。这些关键变量是“潜在”的,无法从单一或的一组姿态坐标中直接观测得到。
当我们强行训练模型在姿态空间(Pose Space)进行回归时,模型被迫将宝贵的参数容量浪费在记忆静态的几何特征和传感器噪声上,而非学习控制运动演变的时间规律。这种“几何与动力学的混淆”是导致当前技术瓶颈的根源。
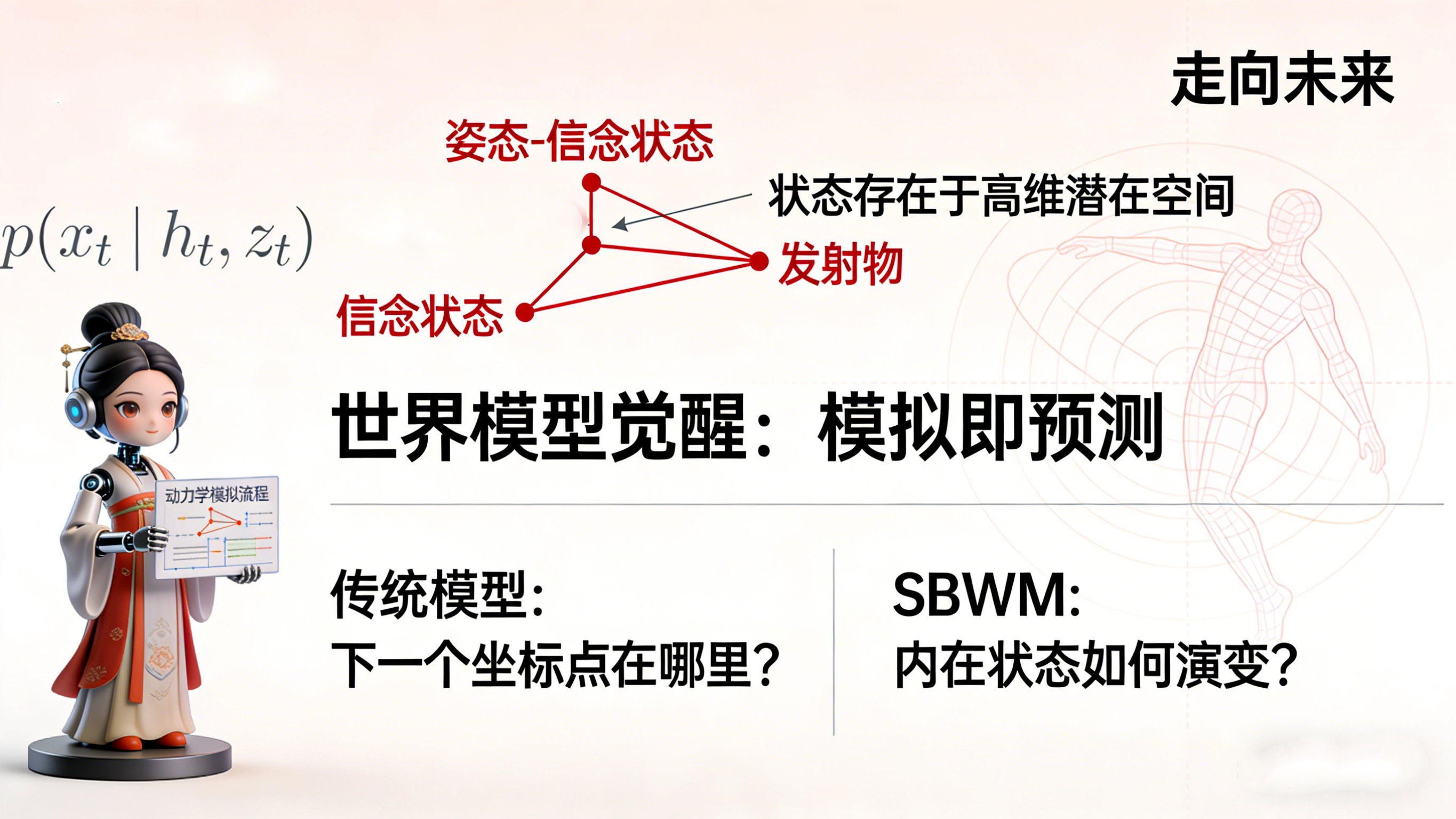
1.2 世界模型的觉醒:模拟即预测
SBWM的提出,标志着该领域向“基于模型的认知”(Model-Based Cognition)迈出了关键一步。受到强化学习中“世界模型”(World Models)概念的启发,SBWM不再试图直接预测姿态,而是试图在机器内部构建一个微缩的、动态的“人”的模型。
/Users/wgwang/futureland/0120/1.jpg
在这个框架下,姿态不再是系统的状态(State),而是潜在信念状态(Belief State)的“发射物”(Emission)。真正的“状态”存在于一个高维的潜在空间中,它是一个随时间演变的概率分布,独立于具体的观测数据而存在。预测的过程,不再是针对像素或坐标的数值拟合,而是对这个潜在信念状态的动力学模拟(Dynamical Simulation)。
这种视角的转换具有本体论层面的意义:
- 传统模型问: “根据过去这一串坐标,下一个坐标点在哪里?”
- SBWM问: “根据过去的信息,这个人的内在状态(意图、重心、相位)目前是什么?在这个状态下,依照物理和生理规律,他下一步会演变成什么状态?这个新状态如果表现为外在姿态,看起来会是什么样?”
从“外推”到“模拟”,看似只有两字之差,实则决定了模型在面对未知未来时,是机械地重复历史的平均值,还是像人类一样具有连贯的想象力和推理能力。
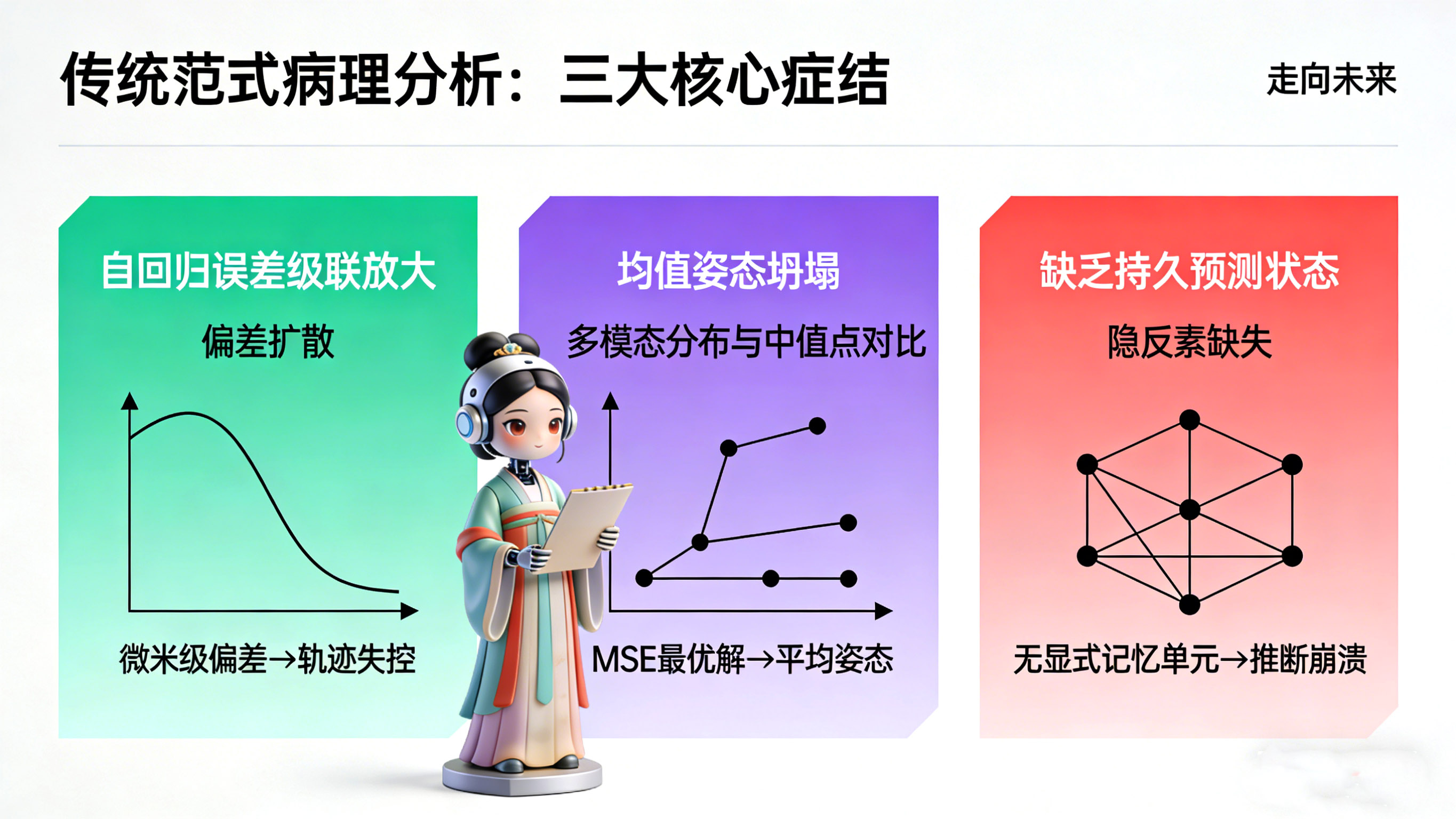
二 传统回归范式的病理学分析
要深刻理解SBWM的创新价值,我们必须以手术刀般的精准,剖析现有序列回归模型在长时程任务中必然失效的病理机制。这并非针对某一特定架构的批评,而是对整个“以姿态为中心”(Pose-Centric)的方法论的批判。
/Users/wgwang/futureland/0120/3.jpg
2.1 自回归误差的级联放大(Compounding Drift)
在传统推理模式中,模型在 时刻生成的预测值 会被无条件地作为真值输入到 时刻的预测中。这种机制被称为“教师强制”(Teacher Forcing)的移除。在训练时,模型总是能看到真实的上一帧,但在推理时,它只能依靠自己。
这就导致了一个正反馈的误差回路:初始预测中哪怕微米级的几何偏差,都会导致模型对当前状态的误判,进而导致下一帧预测偏差的扩大。由于模型从未学习过一个独立的、具有纠错能力的潜在动力学机制,这种偏差无法自我修正。在几秒钟的推演后,这种级联效应会导致人体轨迹完全脱离物理约束——原本的步行变成了滑行(Skating),关节角度超出了生理极限,甚至出现肢体穿模。这就像一个没有指南针的盲人在走路,每一步微小的方向偏差,最终都会导致他偏离目标数公里。
2.2 均值姿态坍塌(Mean-Pose Collapse)
这是序列回归模型最令人绝望的特性。人体运动本质上是高度多模态(Multi-modal)和不确定性的。当一个人站在路口,他可能向前走,可能向左转,也可能停下来看手机。这意味着未来的概率分布 是多峰的。
然而,传统的回归损失函数(如MSE或L2 Loss)本质上是在最小化预测值与所有可能真实值之间的欧几里得距离。数学上可以证明,最小化MSE的最优解是所有可能结果的算术平均值。
- 如果未来可能向左转(),也可能向右转(),模型的MSE最优解往往是原地不动()。
因此,随着预测时间的推移,不确定性增加,传统模型的预测会迅速收敛到一个“平均姿态”——通常是静止站立或极其微小的动作幅度。这就是为什么大多数SOTA模型在预测超过1秒后,动作就会变得“死气沉沉”,仿佛被冻结了一样。这不是模型没学好,而是它的目标函数(Objective Function)逼迫它选择了平庸。
2.3 缺乏持久的预测状态(Absence of Predictive State)
控制理论告诉我们,要预测一个动力系统的未来,必须拥有一个能够概括历史信息的“充分统计量”(Sufficient Statistic),即状态(State)。在序列模型中,观察到的姿态序列()被直接用作状态的替代品。
这是一个范畴错误。姿态只是表象,是内在动力学过程在某一时刻的投影,且往往充满了噪声和不完整信息(如遮挡)。真正的驱动变量——如行走的相位(Phase)、身体的角动量、动作的意图——是隐藏的。 由于序列模型缺乏一个显式的记忆单元来维护这些隐变量,它被迫在每一个时间步重新从一堆坐标中“猜测”当前的动力学特征。一旦观测序列中出现异常(如传感器抖动),这种脆弱的推断就会崩溃,导致预测的不连续。
三 语义信念状态世界模型(SBWM)的架构哲学
SBWM通过引入“信念状态”(Belief State)的概念,彻底重构了运动预测的计算图。其架构设计深受基于模型的强化学习(Model-Based RL)启发,特别是循环状态空间模型(RSSM),但针对人体运动的特殊性进行了语义层面的深度定制。

/Users/wgwang/futureland/0120/2.jpg
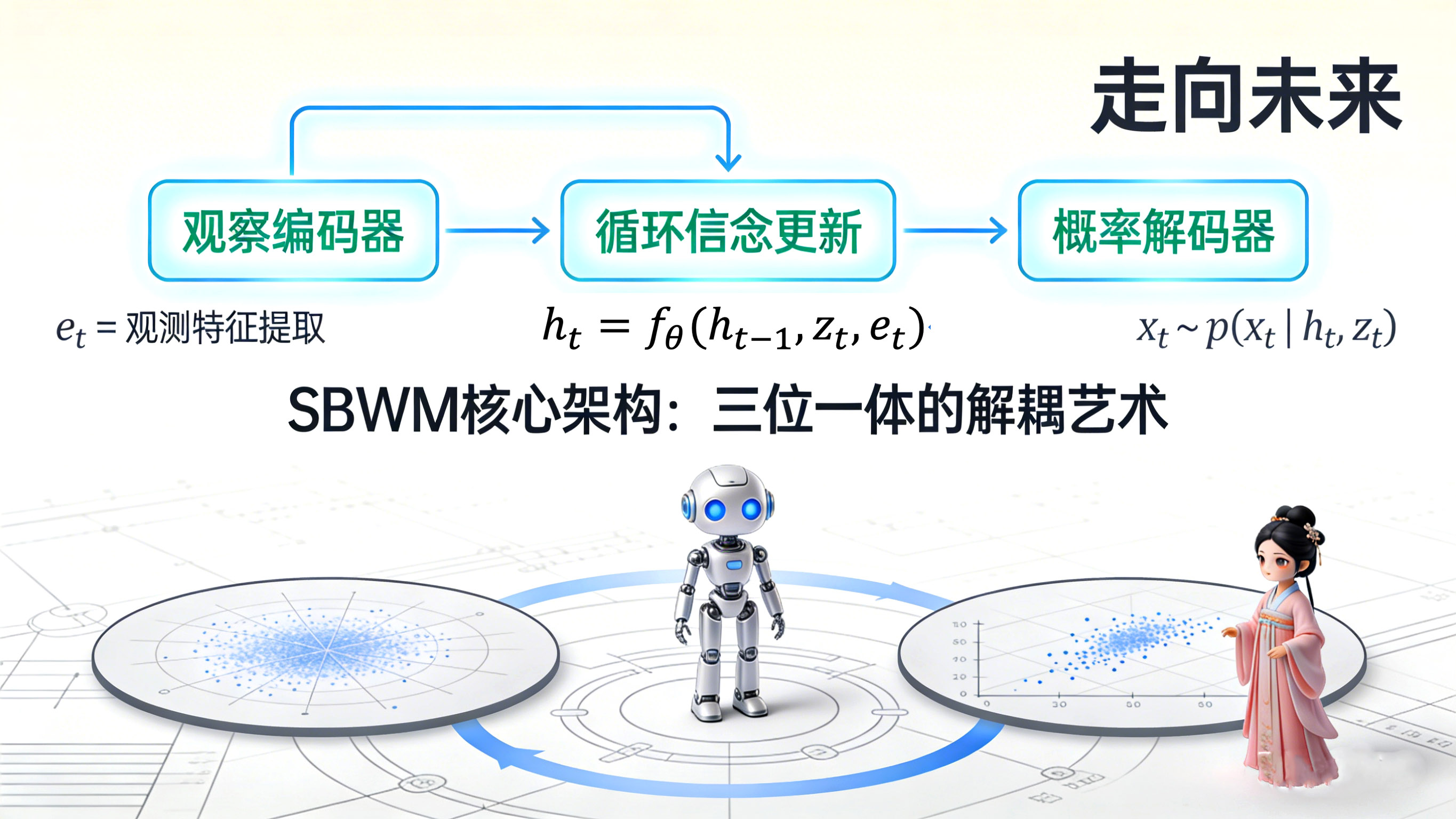
3.1 核心三位一体架构:解耦的艺术
SBWM并没有采用端到端的黑盒设计,而是采用了模块化的“三位一体”架构,实现了感知、推理与生成的严格解耦:
/Users/wgwang/futureland/0120/8.jpg
- 观测编码器(Observation Encoder):感知层 它的任务是将高维的SMPL-X参数映射为紧凑的特征向量 。至关重要的是,这个编码器并不追求完美地重建输入图像或坐标。它的训练目标是服务于后续的信念更新。因此,它会自动学习过滤掉那些对预测未来无用的高频噪声(如轻微的肌肉抖动)或静态形状信息,只提取与运动趋势相关的特征。这是一个主动的信息筛选过程。
- 循环信念更新(Recurrent Belief Update):认知层 这是SBWM的灵魂所在。模型维护一个确定性的信念状态 ,并通过门控循环单元(GRU)进行更新:
- 这里, 是这一时刻模型对世界(人体)状态的全部认知。它不仅融合了当前的观测证据 ,还继承了上一时刻的记忆 ,以及当前的随机潜在变量 。这个 是时间连续的,它像一条河流,承载着动作的惯性、相位和长时程意图。即使观测信号中断,这条河流依然会依据自身的流体力学(学到的动力学规律)继续流淌。
- 概率解码器(Probabilistic Decoder):表达层 SBWM将姿态生成视为从信念状态中“发射”观测的过程:
- 这种设计通过非对称性强调了:姿态是果,状态是因。 解码器是一个轻量级的网络,它不需要处理时间依赖性(因为 已经处理了),只需要负责将抽象的动力学状态翻译回具体的、符合解剖学结构的人体参数。
3.2 信念状态作为充分统计量
从信息论的角度看,SBWM中的信念状态 实际上是历史观测序列 的一个被学习到的压缩表示。它不是简单的无损压缩,而是一种“预测性压缩”。 训练过程中的ELBO(Evidence Lower Bound)目标函数,迫使 只保留那些有助于降低未来预测不确定性的信息。这种机制天然地形成了一个“信息瓶颈”(Information Bottleneck),过滤掉了大量冗余的几何细节,使得模型在面对新场景时具有极强的泛化能力。因为虽然具体的动作姿态千变万化,但支配人体运动的底层动力学规律(如重力、平衡、动量守恒)是相对恒定且低维的。
3.3 推理与模拟的显式分离(Inference vs. Simulation)
SBWM最精妙的设计之一,在于明确区分了“观测校准”与“纯粹模拟”两种模式:
- 观测阶段(Inference): 当有真实数据输入时,模型计算后验分布 。这相当于在不断地用现实修正自己的想象,类似于卡尔曼滤波中的“Update”步骤。
- 模拟阶段(Rollout): 当需要预测未来时,外部观测被切断。模型切换到先验分布 进行采样,完全依赖内部的信念动力学 演进。这相当于人类闭上眼睛,仅凭大脑中的物理引擎推演接下来会发生什么。
由于在训练中使用了“计划采样”(Scheduled Sampling)策略,SBWM被刻意训练得能够在没有观测纠正的情况下生存。这使得它在推理阶段面对长达数秒的开环预测(Open-loop Prediction)时,依然能保持轨迹的平滑与连贯,彻底根治了自回归模型的“断片”症。
四 SMPL-X流形:语义对齐的结构性约束
将世界模型应用于人体运动的一个核心挑战在于:观测空间到底应该是什么?
如果直接在3D关节坐标(Joint Coordinates)或点云(Point Clouds)上构建世界模型,潜在状态 将被迫花费大量容量去学习基础的人体解剖学知识——例如大腿骨长度是固定的、膝关节不能反向弯曲等。这不仅浪费了计算资源,而且这种隐式学习的约束非常脆弱,一旦遇到分布外数据,模型很容易生成肢体扭曲的怪物。

/Users/wgwang/futureland/0120/5.jpg
4.1 语义流形的引入
SBWM创新性地将信念状态与 SMPL-X 参数化人体模型进行了显式对齐。SMPL-X 是一个基于大量3D扫描数据构建的统计学模型,它通过一组低维参数(姿态 ,形状 等)来数学化地定义高维的人体网格。 关键在于,SMPL-X 参数空间构成了一个语义流形(Semantic Manifold)。在这个空间里的每一个点,解码后都对应一个解剖学上合法的人体。
4.2 结构化信息瓶颈(Structural Information Bottleneck)
这种对齐不仅仅是换了一种数据格式,它引入了强大的归纳偏置(Inductive Bias)。 通过强制模型预测 SMPL-X 参数而非坐标,SBWM 构建了一个过滤器:
- 解剖学一致性: 模型无需从零学习“人是什么样子的”,因为输出空间本身已经剔除了所有非人类的形态。
- 聚焦动力学: 既然不需要操心几何结构的合理性,潜在状态 就可以被完全解放出来,专注于学习高阶的动力学特征——如步态的周期性、重心的转移逻辑、动作之间的因果转换。
实验结果极具说服力:在基于关节坐标的基线模型中,长时预测往往伴随着骨骼长度的变化(肢体忽长忽短);而在SBWM中,这种解剖学违规现象降为零。这证明了,只有在正确的语义流形上进行模拟,世界模型才能发挥其真正的威力。
五 反冻结动力学与不确定性校准
针对前文提到的“均值坍塌”导致的“冻结”现象,SBWM给出了一套优雅的概率论解法。
5.1 随机潜变量 :运动的引擎
在SBWM中,动力学系统并非完全确定性的。除了确定性的信念状态 ,模型在每一个时间步都会采样一个随机潜变量 。
这个公式揭示了反冻结的奥秘:即使 倾向于保持现状,新注入的随机噪声 也会持续地扰动系统状态。只要状态转移函数 对 的导数不为零,系统就不可能陷入静止的不动点。 这在物理上对应着生物运动的本质:生命体总是处于微小的涨落之中,绝对的静止只属于无机物。 模拟了这种内在的活力(Vitality)。
5.2 意图的多模态表达
不仅仅是噪声,它编码了运动的分支点(Branching Points)。 在面对歧义场景时(如起跑动作),传统模型会输出一个平均姿态。而SBWM通过对 的不同采样,可以生成多条截然不同但物理上都合理的未来轨迹——一条加速跑,一条减速停。 这种能力被称为分布预测(Distributional Forecasting)。SBWM实际上是在学习预测未来所有可能状态的概率密度函数,而不是单一的期望值。
5.3 潜在活跃度监控:KL散度
为了防止模型偷懒(即忽略 ,退化为确定性模型,称为 Posterior Collapse),SBWM使用了KL散度作为训练中的核心监控指标。
实验显示,SBWM在训练过程中,KL散度在预热后稳定在一个非零的平台。这意味着模型在持续地将信息编码进随机潜变量中,并没有发生坍塌。消融实验更是惊人地表明:如果移除 机制,模型的冻结率(Freeze Rate)会瞬间从4%飙升至42%。这铁证如山地表明,随机性不是噪音,而是维持长时程模拟活力的核心燃料。
六 计算效率与帕累托最优前沿
在追求高精度的同时,SBWM并没有牺牲效率,反而在计算成本上展现出了压倒性的优势,处于精度-效率权衡的帕累托最优前沿(Pareto-optimal Frontier)。
/Users/wgwang/futureland/0120/4.jpg
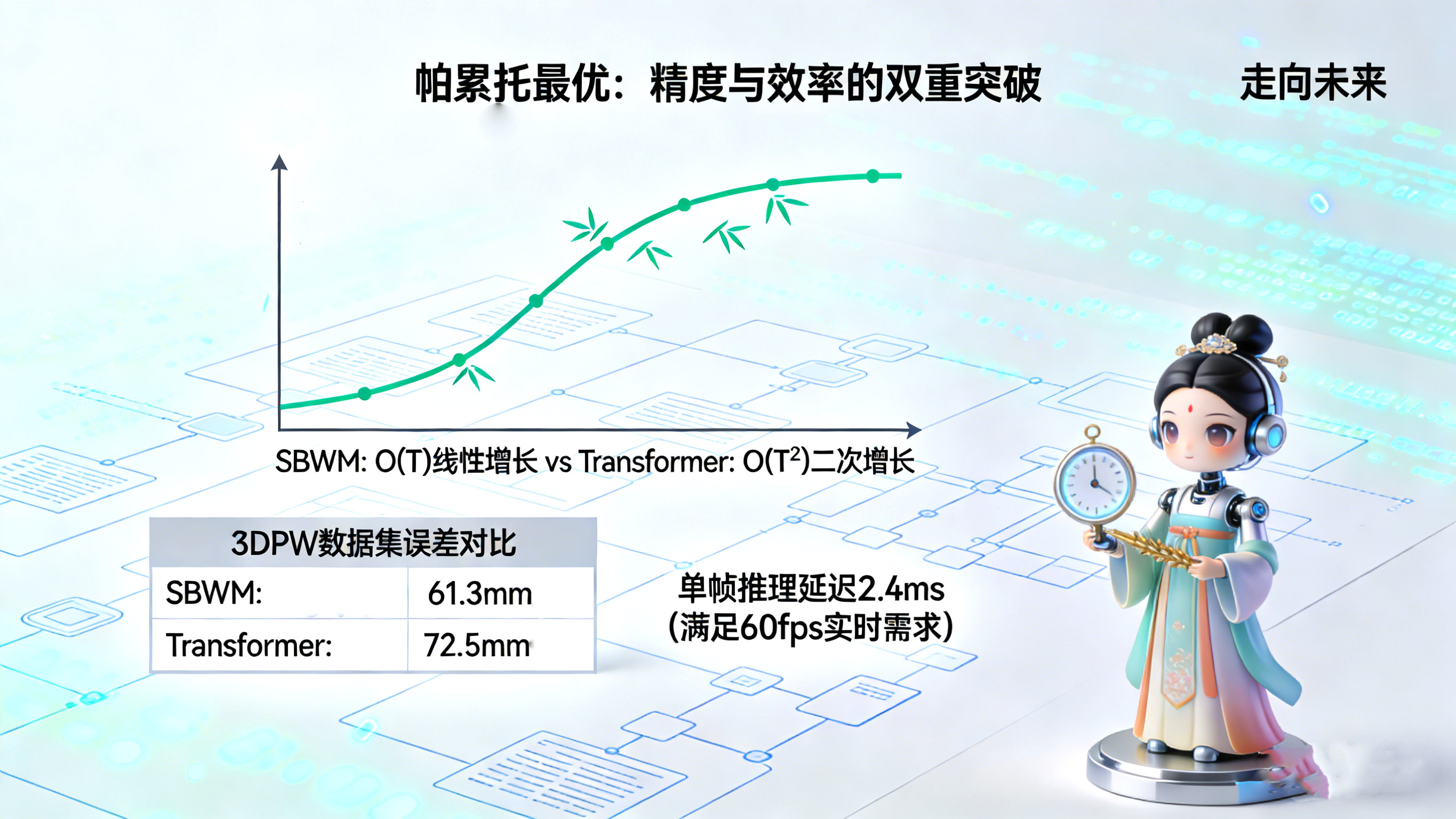
6.1 突破Transformer的二次复杂度陷阱
当前的学术主流Transformer架构,虽然强大,但其核心的自注意力机制(Self-Attention)计算复杂度随序列长度 呈二次方增长()。这意味着,如果你想预测更远的未来,计算资源的消耗将呈爆炸式增长。这对于实时系统(如机器人规划)是不可接受的。 SBWM基于循环机制(Recurrent),其推理复杂度随时间呈线性增长(),且内存占用恒定()。无论预测未来1秒还是1分钟,其对显存的需求都不会改变。
6.2 碾压扩散模型的实时性
扩散模型是生成质量的王者,但其代价是昂贵的迭代推理。生成一帧动作可能需要几十次甚至上百次的去噪步骤。 SBWM在每个时间步只需一次前向传递(Single Forward Pass)。实验数据显示,其单帧推理延迟仅为 2.4毫秒。相比之下,扩散模型的延迟往往在数百毫秒级别。这意味着SBWM比扩散模型快了近两个数量级,完全满足60fps甚至更高帧率的实时交互需求。
6.3 结果对比
在标准的3DPW数据集评测中:
- SBWM 的预测误差(MPJPE 15帧)为 61.3mm。
- Transformer基线为 72.5mm。
- 基于关节的RSSM为 74.5mm。
- 确定性RNN甚至高达 87.2mm。
SBWM不仅在精度上大幅领先,更在“运动持久性”(Motion Persistence)指标上表现出色,证明了其生成的动作具有真实的物理活力,而非死板的滑行。
七 行业应用前景与战略价值
SBWM的出现,不仅仅是发了一篇论文,它为多个高价值的AI应用领域提供了新的技术底座。

/Users/wgwang/futureland/0120/10.jpg
7.1 具身智能与机器人(Embodied AI & Robotics)
这是SBWM最直接的战略高地。在人机共存的环境(如家庭服务机器人、自动驾驶)中,机器人必须具备“预判”能力。
- 安全性: 机器人利用SBWM可以瞬间模拟出周围人类未来几秒的所有可能路径(概率分布),从而规划出绝对安全的避障路线。
- 交互性: SBWM的信念状态可以作为机器人理解人类意图的“心理理论”(Theory of Mind)。机器人不仅仅看到人在动,还能理解人“想去哪里”,从而主动配合(例如提前打开门)。
7.2 元宇宙与程序化内容生成(AIGC for Gaming/VR)
在游戏和虚拟现实开发中,驱动NPC(非玩家角色)进行自然、不重复的运动是巨大的成本中心。
- 无限生成: SBWM可以作为一个轻量级的实时动作引擎。只需给定一个初始状态和简单的意图指令(如“愤怒地走”),模型就能自动推演出无限时长的、符合解剖学规律的、永不重复的动作流。
- 物理可信: 由于其基于动力学模拟,生成的动作不会出现穿模或滑步,大大减少了美术师手动修整动画的工作量。
- 低算力门槛: 2.4ms的低延迟意味着该技术可以直接部署在VR头显或移动设备端,无需云端渲染。
7.3 医疗康复与体育科学
在步态分析与康复训练中,SBWM可以作为一个“基准模拟器”。通过对比患者真实的运动轨迹与模型基于健康动力学模拟的轨迹,医生可以量化地评估患者的运动功能障碍程度。在体育竞技中,它可以用于战术推演,模拟对手在特定情境下最可能的反应动作。
7.4 从预测到因果推理的认知跃迁
长远来看,SBWM代表了AI从“观察者”向“思考者”的进化。 传统的预测模型只能回答“将会发生什么”。而基于世界模型的SBWM,具备了回答反事实问题(Counterfactual Questions)的潜力:“如果刚才我推了他一下,他会怎么倒下?” 这种对因果机制的掌握,是通向通用人工智能(AGI)的核心阶梯。它赋予了AI在虚拟的思维空间中低成本试错、学习和规划的能力,而无需在现实世界中承担真实的风险。
结语
语义信念状态世界模型(SBWM)的提出,不仅是对3D人体运动预测技术的一次成功重构,更是对人工智能如何建模物理世界的一次深刻启示。它告诉我们,在追求大模型、大数据的时代,“结构化的先验”(如SMPL-X流形)与“概率化的模拟”(如信念状态动力学)依然是通往高效、鲁棒智能的必由之路。
SBWM证明了,通过正确的解耦设计与语义对齐,我们可以在不牺牲精度的前提下,获得极高的计算效率和物理可解释性。随着这一技术的成熟与落地,未来的智能体将不再是只会机械反应的自动机,而是拥有丰富内心世界、能够预演未来可能性的智慧生命。这,才是人工智能走进物理世界的正确姿势。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号