给LLM开挂!SGLang 用基数树复用 KV 缓存


SGLang使用程序化的语言模型技术,并利用基数树和压缩有限状态机很好的解决了KV缓存复用和结构化输出问题,本文主要围绕KV缓存复用讨论以下问题:
1)语言模型程序的定义和特点 2)结合持续批处理,如何使用基数树复用KV缓存 3)基于最长匹配序列的缓存感知调度策略介绍
1,语言模型程序
1.1,共享KV缓存的对话模式
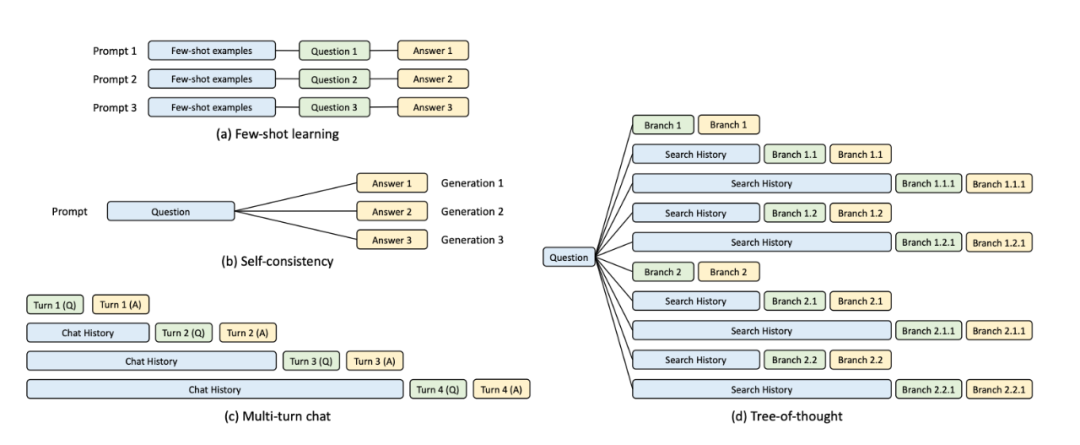
以上展示了四种典型共享KV缓存的对话模式。1)少样本学习中的示例,2)自洽问答中的问题3)多轮对话中的历史记录,4)思考树的搜索历史。
以上四种对话模式中存在大量的KV缓存共享机会,如果使用统一的方式进行管理和共享,可以大量的节省推理过程中的计算量,进而成倍的提升推理速度。如何存储和管理并不是一蹴而就的,vllm实现了基础的共享前缀树的方案,SGLang提出使用基数树同时实现四种对话方式的KV缓存共享方案。
1.2,语言模型程序定义和特点
为应对多样化的对话模型,提出了语言模型程序的概念,即:使用程序化的方式去调度和管理大模型生成。其核心是:将语言模型的调用逻辑与程序化控制流(如条件判断、循环、函数封装)结合,形成可编排、可交互、可扩展的执行单元。
主要特点:
- • 控制流驱动的多轮模型调用。 一个语言模型程序一般包含多次的大语言模型调用,整个过程包含在一个控制流中。
- • 结构化输入与输出的强交互性。语言模型程序一般接收结构化的输入,也会进行结构化的输出。
- • 缓存感知与状态持续性。语言模型程序的多轮调用常涉及重复或相似的输入前缀(如任务描述、历史对话),因此对 KV 缓存的复用需求更高。
2,基数树 Radix Tree 构建
2.1,什么是基数树
定义:
基数树(Radix Tree)也被称为压缩前缀树(Compact Prefix Tree),是一种特殊的前缀树(Trie)数据结构,用于高效存储和检索键值对。
特点:
- • 基数树的每个节点可以存储多个字符,而不仅限于单个字符。
- • 只有当一个节点需要分叉(即存在多个子节点)时,才会创建新的分支。
- • 通过压缩路径,基数树比标准前缀树更节省空间,尤其适用于存储长键或大量相似前缀的数据。
构建过程:
要构建包含以下键的基数树:["apple", "applet", "application", "banana"]。
- • 插入apple,根节点直接连接到包含
"apple"的叶子节点 - • 插入applet,发现
"apple"是"applet"的前缀,因此将"apple"拆分为["appl", "e"],并将"et"作为"e"的子节点。 - • 插入application,在
"appl"后分叉:"e"(对应"apple")和"ication"(对应"application")。 - •
"banana"与"apple"无共享前缀,因此在根节点创建新分支。
搜索过程:
从基数树中搜索键 "application":
- • 从根节点开始。根节点的子节点为
["appl"]和["banana"]。键"application"的前缀"appl"匹配第一个子节点,继续进入该节点。 - • 检查
"appl"的子节点。子节点为["e"]和["ication"]。键的剩余部分"ication"匹配第二个子节点,继续进入。 - • 到达叶子节点。节点
["ication"]是叶子节点,且完整匹配"application",搜索成功。
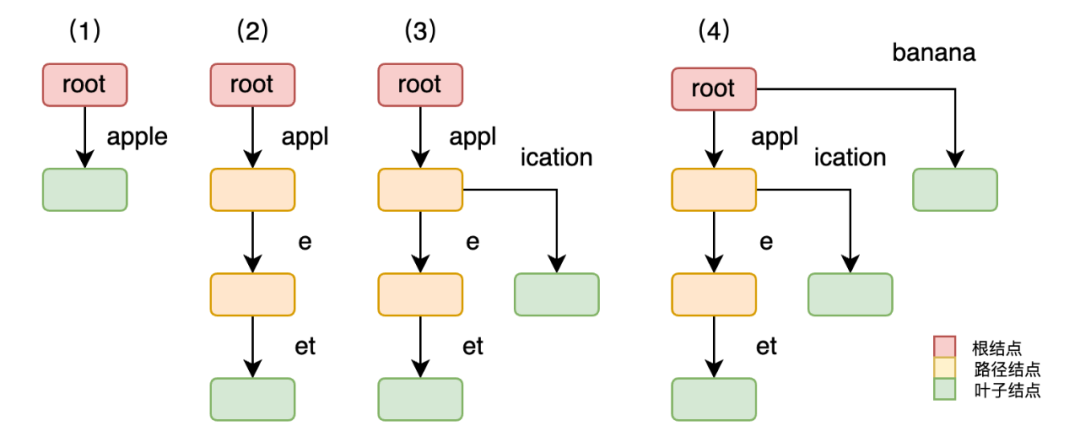
注当搜索apple,结束的结点不为叶子结点,当键的所有字符匹配完毕时,若当前节点被标记为键的终止点,则搜索成功。
2.2,如何利用基数树复用KV 缓存
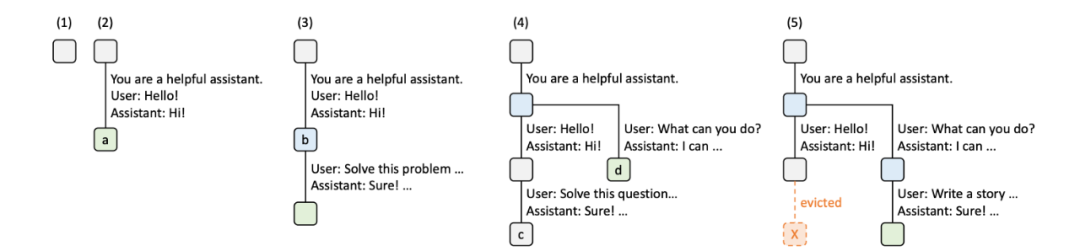
在开始时初始化树为空(1),此时只有一个空结点。在第二时刻(2)用户一条请求进入,称之为R1,系统提示词为“You are a helpful assistant.” 用户提问:“hello”,助手回答:“Hi!”,此时的基数树在空结点上加入结点a,用户的输入作为边。在第三时刻(3)用户接着上一问题接着提问 “Solve this problem”,助手回答“Sure”,此时基数树加入新的结点,并将用户输入作为边。此时的重点是复用了上轮历史对话的KV缓存,减少了计算量。第四时刻(4)新一轮对话开始,称之为R2,只用系统的提示词可以共用,在b结点处生出新的分支d,用户新输入作为边。第五时刻(5)新对话R2开始多轮,需要清理KV缓存,根据LRU规则,将R1对话的最近一轮KV缓存结点c及其边清除。
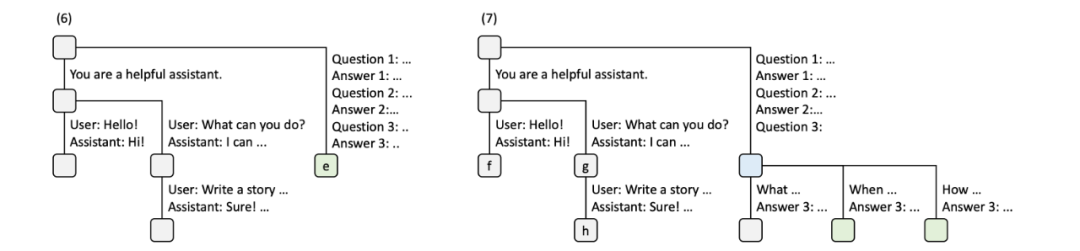
第六时刻(6)服务接收到少样本学习的新对话,称之为R3,系统的提示词也无法共享,即在跟结点处生出新分支e,输入作为边。第七时刻(7)在少样本学习R3的基础上,用户提问了多个问题,在结点e处生出三个分支和结点,输入分别作为边。
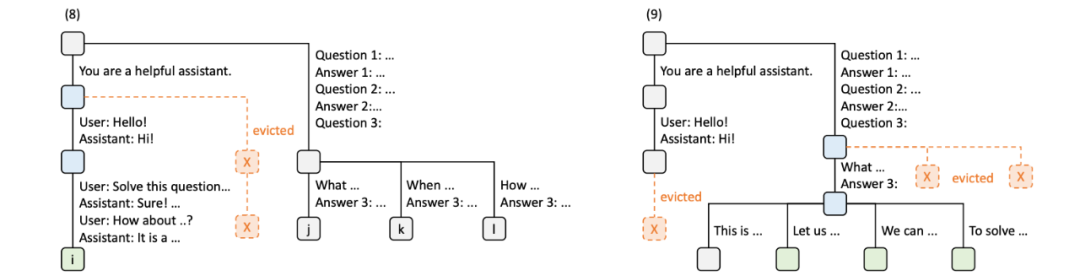
第八时刻(8)第一次对话R1,又进行了新提问,为此生成结点 i,共享之前生成的KV缓存,并将新输入作为边,缓存新输入的KV值。同时第二次对话R2下的结点 g和h及其对应边被清除。第九时刻(9)少样本学习R3下的第一问进行了多轮的问答,生成新结点,而其它问题分支的缓存被清除。同时第一次对话R1下的 i 结点及对应边被清除。
3,缓存感知的调度策略
3.1,最长匹配序列排序
缓存命中率:命中缓存的token和总输入的token之比。当调度等待队列中的请求频繁的在不同请求间切换时,导致KV缓存的命中率很低。所以在一个batch中的请求,使用最长匹配序列进行排序,决定最终请求优先级,代替“先来先服务”的抢占策略,以此提高缓存命中率。
排序步骤具体为:
- • 对等待队列中的所有请求,通过基数树计算各自的最长匹配序列长度;
- • 按长度降序排序,长度相同的请求再按缓存命中率降序排序;
- • 优先选择排序靠前的请求进入当前 batch 执行。
这种策略相比 “先来先服务(FCFS)” 优势在于:
- • 连续匹配的请求可共享缓存块,减少 KV 缓存的频繁切换,降低内存带宽压力;
- • 连续缓存块可直接复用,减少重复计算的开销,提升计算效率。
3.2,基数树和持续批处理的结合
持续批处理(Continuous Batching)的核心是打破静态批处理的 “一次性打包” 限制,在模型推理的每轮迭代后与调度器交互:移除已完成生成的请求(释放缓存)、加入新到达的请求(接收新任务),实现 batch 的动态调整。而基数树的引入,使得这种动态调整能基于实时缓存状态优化,进一步提升效率。
结合基数树,在等待队列中的一个batch内,所有的请求按匹配序列长度进行排序,如下图1的伪代码。排序之后再根据可用的显存空间,决定要执行的请求数量如下图2。这样最大程度保证了,KV缓存的利用率和整体推理的效率。
优势:
- • 实时性与复用率平衡:持续批处理保证新请求及时入队、完成请求及时出队,而基数树的实时查询确保每次重组 batch 时,优先选择能复用最多连续缓存的请求;
- • 避免缓存碎片化:通过基数树的路径管理,KV 缓存始终以连续前缀块的形式被复用,减少碎片化缓存导致的内存浪费;

总结:
SGLang 的缓存感知调度策略核心目标是通过最大化 KV 缓存复用率,降低内存读写开销,从而提升大模型推理的吞吐量与响应速度。其设计紧密依赖基数树(用于高效管理 KV 缓存元信息)和动态优先级排序机制。
参考:arxiv:2312.07104
更多精彩:
历史文章:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号