Meta 发布 UMA 原子通用模型家族,颠覆计算化学与材料科学领域

Meta 发布 UMA 原子通用模型家族,颠覆计算化学与材料科学领域

MindDance
发布于 2026-01-08 12:53:53
发布于 2026-01-08 12:53:53
在计算化学和材料科学领域,一项革命性的成果横空出世。Meta旗下的FAIR团队推出了Universal Models for Atoms(UMA)原子通用模型家族,它以5亿独特的3D原子结构作为训练数据,在速度、准确性和泛化能力上都实现了突破,为药物发现、能源存储和半导体制造等众多应用带来了新的可能。
为什么需要UMA?
密度泛函理论(DFT)作为现代计算化学和材料科学的基础,虽在药物发现、能源存储、半导体等诸多领域提供了深刻见解,但计算成本极高,这严重限制了其应用。
而机器学习模型有望精确近似DFT,且速度大幅提升,将计算时间从数小时缩短至不到一秒。理想情况下,这些被称为机器学习原子势(MLIPs)的模型应能在众多DFT应用任务中实现泛化。然而,训练能跨这些任务泛化的MLIPs仍是一个未解决的难题。
UMA的出现,正是为了应对这一挑战,推动速度、准确性和泛化能力的边界突破。
UMA的“硬核”实力
超大规模训练数据
UMA模型在5亿个独特的3D原子结构上进行训练,这是迄今为止最大规模的训练。这些数据来自多个化学领域,如分子、材料和催化剂等,涵盖了近乎整个化学空间(放射性元素除外)。
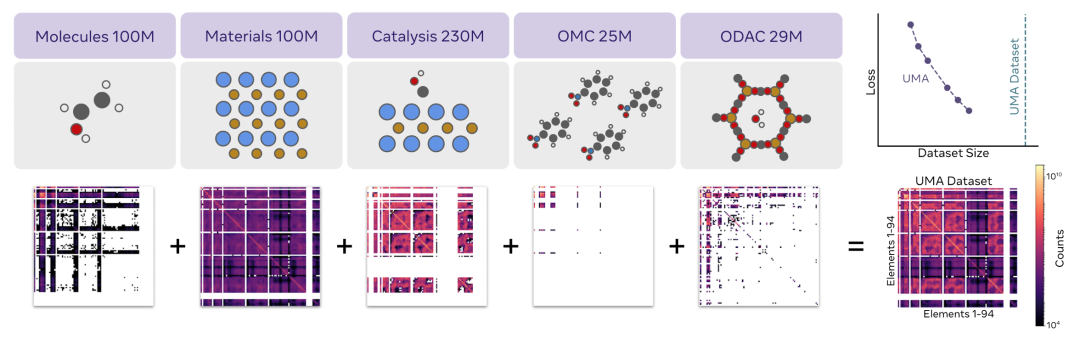
图 1:训练数据集可视化:展示了用于训练 UMA 模型的不同数据集,包括 Open Molecules 2025(OMol25)、Open Materials 2024(OMat24)、Open Catalyst 2020(OC20)、OpenDAC 2025(ODAC25)和 Open Molecular Crystals 2025(OMC25)。2D 图呈现了每个数据集包含的元素间成对相互作用的数量,其组合几乎涵盖整个化学空间(放射性元素除外)。从图中能直观看到不同数据集的规模和元素相互作用的覆盖情况,为理解 UMA 模型训练数据的多样性和全面性提供依据,体现了大规模多领域数据对模型训练的重要性。
图 1:训练数据集可视化:展示了用于训练 UMA 模型的不同数据集,包括 Open Molecules 2025(OMol25)、Open Materials 2024(OMat24)、Open Catalyst 2020(OC20)、OpenDAC 2025(ODAC25)和 Open Molecular Crystals 2025(OMC25)。2D 图呈现了每个数据集包含的元素间成对相互作用的数量,其组合几乎涵盖整个化学空间(放射性元素除外)。从图中能直观看到不同数据集的规模和元素相互作用的覆盖情况,为理解 UMA 模型训练数据的多样性和全面性提供依据,体现了大规模多领域数据对模型训练的重要性。
创新的模型架构
UMA小模型和中模型采用了一种名为“线性专家混合(mixture of linear experts)”的新颖架构设计。这种设计能在不牺牲速度的情况下增加模型容量。例如,UMA-medium拥有14亿参数,但每个原子结构仅约5000万活跃参数。
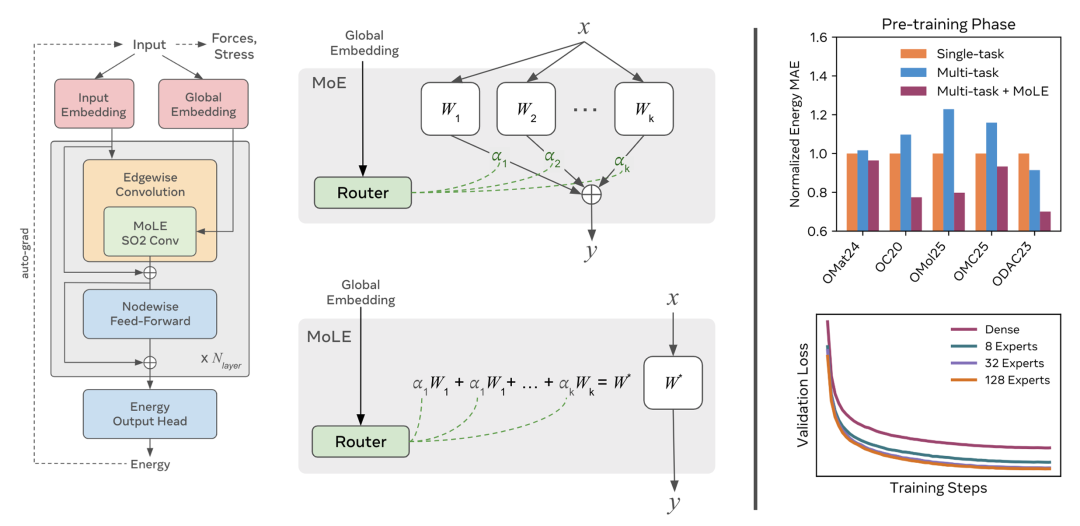
图 2:UMA 模型架构及 MoLE 相关图示:左边部分是 UMA 模型架构的概述,展示 SO2 卷积由一系列线性操作组成,且这些操作被 MoLE 替代的结构,帮助读者理解模型的基本构建模块和创新点;中间部分说明了 MoE 和 MoLE 的原理,以及用于路由的嵌入仅依赖全局信息,使得在模型前向传递前合并成为可能,这对分子动力学等应用意义重大,通过图示可以更直观地理解其工作机制;右边部分通过柱状图对比了 UMA-S 使用 MoLE 进行多任务训练和不使用 MoLE 进行单任务、多任务训练的效果,还展示了 UMA-S 在不同专家数量下的损失变化。从图中可以清晰看到 MoLE 对模型性能的提升作用,以及不同专家数量对模型损失的影响,比如随着专家数量增加,损失先显著下降后趋于平稳。
图 2:UMA 模型架构及 MoLE 相关图示:左边部分是 UMA 模型架构的概述,展示 SO2 卷积由一系列线性操作组成,且这些操作被 MoLE 替代的结构,帮助读者理解模型的基本构建模块和创新点;中间部分说明了 MoE 和 MoLE 的原理,以及用于路由的嵌入仅依赖全局信息,使得在模型前向传递前合并成为可能,这对分子动力学等应用意义重大,通过图示可以更直观地理解其工作机制;右边部分通过柱状图对比了 UMA-S 使用 MoLE 进行多任务训练和不使用 MoLE 进行单任务、多任务训练的效果,还展示了 UMA-S 在不同专家数量下的损失变化。从图中可以清晰看到 MoLE 对模型性能的提升作用,以及不同专家数量对模型损失的影响,比如随着专家数量增加,损失先显著下降后趋于平稳。
出色的性能表现
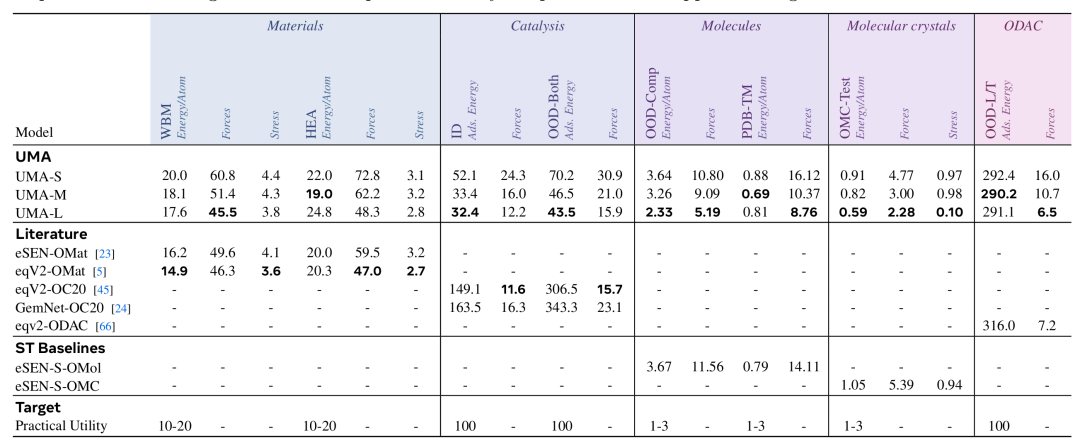
在多个领域的各种应用评估中,UMA模型表现惊人。一个未经任何微调的单一模型,性能与专业模型相当甚至更优。
- • 在热门的Matbench Discovery排行榜上,UMA取得了最先进的结果。
- • 在催化反应的吸附能计算中,成功度提高了25%。
- • 在基于结构的药物设计中,对于配体应变能等实际应用,准确性足以满足需求。
实用的模型家族
UMA模型家族分为小(S)、中(M)、大(L)三种规模,各具特点,适用于不同场景:
- • UMA-S在准确性和效率之间取得平衡,适合长时间分子动力学模拟等计算密集型应用。
- • UMA-M更准确,可作为DFT的替代模型用于弛豫、振动分析以及分子动力学等。
- • UMA-L是高度准确的DFT替代模型,主要用于原理验证,帮助理解缩放行为并展示当前可行的极限。
模型 | 总参数 | 活跃参数 | 1k原子每秒推理次数 | 80GB GPU最大原子数 | 保守性 |
|---|---|---|---|---|---|
UMA-S | 1.5亿 | 600万 | 16 | 10万 + | ✓ |
UMA-M | 14亿 | 5000万 | 3 | 1万 + | ✓ |
UMA-L | 7亿 | 7亿 | 1.6 | 1k + | ✗ |
创新技术解析
混合线性专家(MoLE)
为在增加模型容量的同时保持推理效率,UMA引入了混合线性专家(MoLE)架构。 MoLE结合了一组线性专家,其表达式为(),其中每个专家k都有一组权重()和贡献()。
它为MLIPs带来了诸多优势:
- • 能学习在任务间共享信息且平滑变化的函数,鼓励密集使用所有专家而不强制稀疏性。
- • 作为线性专家的混合体,在eSCN卷积中使用时能保持旋转等变性。
- • 若专家权重仅依赖于元素组成等时间不变的全局信息,可在运行模拟前预计算网络权重,使MoE推理时间与非MoE模型相似。
两阶段训练流程
为提高训练效率,UMA采用了两阶段训练方法:
- • 第一阶段:训练直接预测力的模型。
- • 第二阶段:移除力头,使用自动梯度微调模型以预测守恒力和应力。
这种方法既利用了直接模型训练速度快的优势,又能提供许多应用所需的能量守恒和平滑的势能面。
同时,在训练中还有诸多改进:
- • 半精度对在现代GPU上高效训练至关重要,BF16比FP16更稳定,但MLIPs对数值精度更敏感,预训练用BF16,微调切换到FP32可恢复精度损失。
- • 针对大量MoLE专家训练的内存限制,进行了进一步优化以限制和分摊内存使用,并结合了图并行和全分片数据并行等技术,使模型训练能可靠地扩展到100亿参数规模。
广泛的应用前景
UMA模型在多个领域的基准测试中都展现出强大性能:
- • 材料领域:在WBM和高熵合金(HEA)等OOD测试集上表现出色,在Matbench Discovery基准测试中F1分数最高,在声子相关特性等方面也有优异表现。
- • 催化领域:在OC20 S2EF和AdsorbML等基准测试中大幅超越先前的最先进模型,尤其是在AdsorbML中,UMA-L的成功率提高了25%,显示出在新型催化发现中的实用价值。
- • 分子领域:在OMol25的多个测试集上表现略优于强基线模型,在药物发现的配体应变能和口袋-配体相互作用能预测等基准测试中也表现出色。
- • 分子晶体领域:在OMC25测试集和第7届晶体结构预测(CSP)盲测中,性能优于仅在OMC25数据集上训练的基线模型,晶格能预测精度高,可作为DFT的可靠替代方案。
- • 金属有机框架领域:在ODAC的ID测试集上与先前的最先进模型相当,在最难的ODAC OOD测试集上表现最佳,泛化能力有所提升。
总结与展望
UMA模型家族通过利用近5亿个训练样本,结合数据集大小、模型容量和损失之间的缩放关系,成功训练出与任务专用模型相比具有竞争力甚至更优的模型。混合线性专家(MoLE)方法在增加模型容量的同时保持了推理效率。
尽管UMA存在长程相互作用处理、电荷和自旋整合等方面的局限性,但它的出现表明,单一模型能够在化学和材料科学的广泛应用中达到足够的精度,为通用MLIPs铺平了道路,为原子模拟开辟了新的机遇。
目前,UMA的代码、权重和相关数据已发布,将加速计算工作流程,助力社区构建更强大的AI模型。
模型地址:https://huggingface.co/facebook/UMA 代码地址:https://github.com/facebookresearch/fairchem
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号