来自 1986 的 DFT 改进算法(高阶插值实现)


来自 1986 的 DFT 改进算法(YUNSWJ 数值分析实现版)
昨天的优化 DFT 算法只是简单的使用了一次插值,那对我来说,优化的空间还是非常大的,所以接下来我们更近一步:来加一个“分段二次插值版本”的代码(多一个 核),和然后和线性版本 / FFT 一起对比误差。
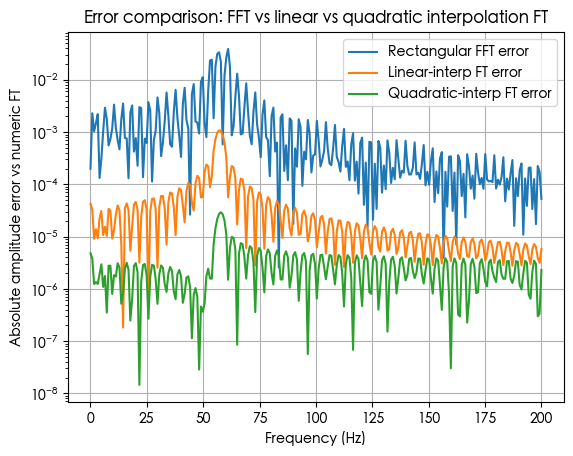
FFT vs 线性插值FT vs 二次插值 FT 的误差对比
FFT vs 线性插值FT vs 二次插值 FT 的误差对比
它和线性版的结构完全平行,只是多了一组 项:
对比结果:二次插值比线性又好多少?
图是这么算出来的(核心部分总结一下):
信号:
非整数 bin 的正弦 + 线性趋势(故意让边界不平滑)。
真值: 用一个高采样率的时间轴,直接数值积分:
三种方法在同一组频率 上算出幅度,再和真值比误差:
FFT(矩形窗):把 np.fft.rfft() 的结果插值到这些频点
线性插值 FT:fourier_linear_interp
二次插值 FT:fourier_quad_interp
误差定义:
图里的结果非常直观:
蓝色:FFT 误差
在主峰附近(约 50–70 Hz),最大误差可到 量级;整个频段大概在 ~ 之间抖。
橙色:线性插值 FT 误差
主峰处误差降到大约 ~;整体比 FFT 好差不多 1 个数量级。
绿色:二次插值 FT 误差
主峰附近基本落到 左右;整个频段都在 ~ 级别;比线性再好 1 个数量级左右,比 FFT 好接近 2–3 个数量级。
也就是说:
在这个有趋势、有边界不连续的示例里, “阶数每升一级,误差往下砸约 10×”,趋势非常明显。
这和数值分析里的直觉一致:矩形积分(零阶保持) → 一阶方法;线性插值积分 → 二阶;二次插值 → 三阶附近。
工程上怎么搞:线性 vs 二次
复杂度方面:线性/二次这两种改进算法,对每个频点的复杂度都是 O(N);线性版本需要每段 2 个系数 + 2 个核函数(A,B);二次版本需要 3 个系数 + 3 个核函数(A,B,C),CPU 时间大概多 1.5~2 倍。所以如果在 狭窄频带上算高精度谱(比如几十~几百个频点),两种方法都比 FFT 快不了多少、也不会太慢 → 可以直接优先上二次插值版本,误差更小.
画外音

咱们也不知道他懂不懂,不过说都说了,也可以再深入一些。

不过怎么想都是觉得上面说的是小jb 话
不过怎么想都是觉得上面说的是小jb 话
简单说:
用偶数阶切比雪夫等纹波 FIR / 奇数阶椭圆 IIR 做“内插滤波”,本质上就是:把原来“线性插值那只三角形核”换成一个优化过的插值核 h(t)。 理论上,如果这个核做得足够接近理想低通(sinc),重构质量会比线性插值好得多。
统一框架:插值 = 重构滤波器
先把所有插值方式放到同一个框架里:
采样点:
采样间隔
离散序列
广义插值/重构写成:
就是“内插核/重构滤波器”的冲激响应,那对于不同的插值方式,就是不同的 :
典型情况:
零阶保持(ZOH):阶梯波 → 是一段矩形
线性插值(FOH):折线 → 是一个三角形
理想带限插值:
现在说的 FIR / IIR 插值,就是让 变成某个 FIR / IIR 对应的脉冲响应。
频域里,就是:
:重构滤波器的频响(来自你的 FIR / IIR)
:采样冲激串的频谱(本质上是原离散序列的 DTFT 的重复)
线性插值 vs FIR/IIR 插值,本质区别
线性插值(FOH)是什么滤波器?
线性插值的核是三角形函数,频响是(只看低频):
可以看成:ZOH 的 sinc 核再平方,低频幅度 OK,但带外滚降比较慢,旁瓣衰减一般
FIR / IIR 插值滤波器
如果设计了一个离散时间滤波器 (比如 equiripple Chebyshev FIR 或 elliptic IIR),用于“上采样 + 低通插值”,对应的连续域重构核大概是:
它的频响就是理想 sinc 低通被这个 FIR/IIR 逼近,等价于:
快速滚降
用 偶数阶等纹波 FIR:线性相位、对 passband 误差做 Chebyshev 最优化 → 非常适合做插值核
用 奇数阶椭圆 IIR:阶数可以很低就有非常陡的过渡带,但相位严重非线性,波形会“扭曲”。
这和我们前面“线性插值傅里叶积分”的关系?
前面那套 fourier_linear_interp() 做的是:
在每个区间 内,用一次多项式拟合:
然后把 做解析积分,推成核函数 。
如果插值核换成 FIR/IIR,数学形状会变成:
也就是说:
改插值滤波器 → 就是在频域里给离散谱乘上一个 ,而不再是简单的 sinc²(线性)、sinc(ZOH)。
所以,如果只关心频域幅度,其实有两种做法:直接按“算法实现”做:对每段三角形/多项式解析积分,如果换成“滤波器视角”:FFT 得到 ,再乘上
对于复杂的 FIR / IIR 内插核,频域卷积更自然:频域算一下滤波器的频响 H_interp(f)(可一次预计算),然后 FFT 出来的谱点逐点乘上 H_interp,就等效于“用这个滤波器内插后的连续谱”。
用 Chebyshev FIR / 椭圆 IIR 做内插,大概会发生什么?
如果信号在 内是带限的,设计一个 FIR 内插滤波器:
passband:0 ~ ,Ripple 很小(比如 0.01 dB)
stopband:> ,衰减 80–100 dB
那它对低频的频响可以做到“很好地近似 1”,带外强衰减,意味着:带内幅度误差,比线性插值要小得多,带外 alias / 泄漏,通过 stopband 衰减压掉。
从“连续傅里叶积分逼近”的角度,这比一次/二次多项式要靠谱(多了一个“逼近 ideal LPF”的自由度),尤其是在靠近 Nyquist 的频段。
有啥问题!
失去解析积分的简洁性,用线性/二次多项式, 有封闭公式;用一般 FIR/IIR,只能走“FFT + 乘 H(ω)”或“数值积分/卷积”路线,没那么干净。
IIR 的相位问题
Chebyshev FIR 一般设计成线性相位,所以只是幅度 shaping;椭圆 IIR 有非常非线性的群延时,作为“重构核”会让时域波形被扭曲。
后记
学习要懂的所有细节,而不是和关键词做关联。
import numpy as np
def fourier_quad_interp(x, dt, freqs, angular_freq=False):
"""
Piecewise-quadratic interpolation FT.
每个区间 [t_n, t_{n+1}] 上把信号近似成二次多项式:
x(t) ≈ a_n + b_n * τ + c_n * τ^2
其中 τ = t - t_n, 0 <= τ <= dt
系数的求法:
- 内部段 (1..N-3): 用 x[n-1], x[n], x[n+1] 三点
在局部坐标 τ = -dt, 0, dt 上拟合二次多项式
- 第 0 段: 用 x[0], x[1], x[2] (τ = 0, dt, 2dt)
- 最后一段: 用 x[N-3], x[N-2], x[N-1] (τ = -dt, 0, dt)
然后对每段做解析积分,再叠加得到频谱。
"""
x = np.asarray(x, dtype=np.complex128)
freqs = np.asarray(freqs, dtype=np.float64)
if x.ndim != 1:
raise ValueError("x must be 1-D array of samples.")
if x.size < 3:
raise ValueError("Need at least 3 samples for quadratic interpolation.")
if angular_freq:
omega = freqs
else:
omega = 2.0 * np.pi * freqs
N = x.size
n_seg = N - 1
a = np.zeros(n_seg, dtype=np.complex128)
b = np.zeros(n_seg, dtype=np.complex128)
c = np.zeros(n_seg, dtype=np.complex128)
# --- 段 0:用 τ=0, dt, 2dt 上的三点 (x0,x1,x2) 拟合 ---
x0 = x[0]
x1 = x[1]
x2 = x[2]
a[0] = x0
u = (x1 - a[0]) / dt
v = (x2 - a[0]) / dt
c[0] = (v - 2 * u) / (2 * dt)
b[0] = u - c[0] * dt
# --- 中间段:用 τ=-dt, 0, dt 上的三点 (x[n-1],x[n],x[n+1]) 拟合 ---
for n in range(1, n_seg - 1):
x_minus = x[n - 1]
x0n = x[n]
x_plus = x[n + 1]
a[n] = x0n
c[n] = (x_plus + x_minus - 2 * x0n) / (2 * dt**2)
b[n] = (x_plus - x_minus) / (2 * dt)
# --- 最后一段:同样用 (x[N-3], x[N-2], x[N-1]),τ=-dt,0,dt ---
n = n_seg - 1
x_minus = x[N - 3]
x0n = x[N - 2]
x_plus = x[N - 1]
a[n] = x0n
c[n] = (x_plus + x_minus - 2 * x0n) / (2 * dt**2)
b[n] = (x_plus - x_minus) / (2 * dt)
t_n = dt * np.arange(n_seg, dtype=np.float64)
X = np.zeros_like(omega, dtype=np.complex128)
eps = 1e-12
mask_zero = np.abs(omega) < eps
mask_nonzero = ~mask_zero
# -------- ω ≈ 0 时用精确极限 --------
if np.any(mask_zero):
# ∫_0^dt (a + bτ + cτ^2)dτ = a dt + b dt^2/2 + c dt^3/3
seg_int = a * dt + b * (dt**2 / 2.0) + c * (dt**3 / 3.0)
X[mask_zero] = np.sum(seg_int)
# -------- ω ≠ 0 时用闭式表达式 --------
if np.any(mask_nonzero):
w = omega[mask_nonzero]
# A(w) = ∫_0^dt e^{-j w τ} dτ
A = (1.0 - np.exp(-1j * w * dt)) / (1j * w)
# B(w) = ∫_0^dt τ e^{-j w τ} dτ
B = (((1j * dt * w + 1.0) * np.exp(-1j * w * dt)) - 1.0) / (w**2)
# C(w) = ∫_0^dt τ^2 e^{-j w τ} dτ
# 用符号积分推出来的结果:
# C = [ (j dt^2 w^2 + 2 dt w - 2j) e^{-j w dt} + 2j ] / w^3
C = (((1j * dt**2 * w**2 + 2 * dt * w - 2j) * np.exp(-1j * w * dt) + 2j)
/ (w**3))
A = A[:, None]
B = B[:, None]
C = C[:, None]
a_col = a[None, :]
b_col = b[None, :]
c_col = c[None, :]
t_col = t_n[None, :]
exp_term = np.exp(-1j * w[:, None] * t_col)
seg_contrib = exp_term * (a_col * A + b_col * B + c_col * C)
X[mask_nonzero] = np.sum(seg_contrib, axis=1)
return X本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号