Nat. Hum. Behav. | 人类与大语言模型发散性创造力的系统性大规模比较

Nat. Hum. Behav. | 人类与大语言模型发散性创造力的系统性大规模比较

DrugAI
发布于 2026-01-06 14:23:59
发布于 2026-01-06 14:23:59
DRUGONE
随着大语言模型(LLMs)被广泛用于创意生成与知识生产,其是否具备、以及在何种程度上具备“创造力”成为核心问题。研究人员通过一项大规模对比研究,系统评估了人类与多种主流大语言模型在发散性创造力任务中的表现。结果表明:虽然部分模型在平均水平上可接近人类,但在人类高水平创造力所体现的变异性、独特性与极端表现方面,模型仍存在显著差距。这一发现为人机协作中创造力的合理分工提供了重要启示。

创造力是科学发现、技术创新与艺术表达的核心驱动力。近年来,随着生成式人工智能的发展,研究人员开始系统检验大语言模型是否能够在经典创造力测试中达到甚至超越人类水平。以往研究多依赖人工主观评估,规模有限,且可重复性不足。
本研究引入发散联想任务(Divergent Association Task, DAT),这一基于语义距离的自动化指标,使得在大规模条件下公平、可重复地比较人类与模型的创造力成为可能。
方法概述
研究人员收集了约 9,000 余名人类参与者 与 多种主流大语言模型 在 DAT 任务中的表现。该任务要求生成一组彼此差异尽可能大的词语,以量化发散性思维能力。
在模型侧,研究人员系统考察了三类影响因素:
- 基础生成能力(baseline);
- 随机性调控(temperature);
- 提示策略(prompt engineering),包括视角设定、名人角色与人口学角色等。
主要结果
平均水平:人类略优于模型
整体而言,人类在发散性创造力上的平均得分略高于大语言模型。尽管个别模型在均值上可与人类相当,但这种优势并不稳定。
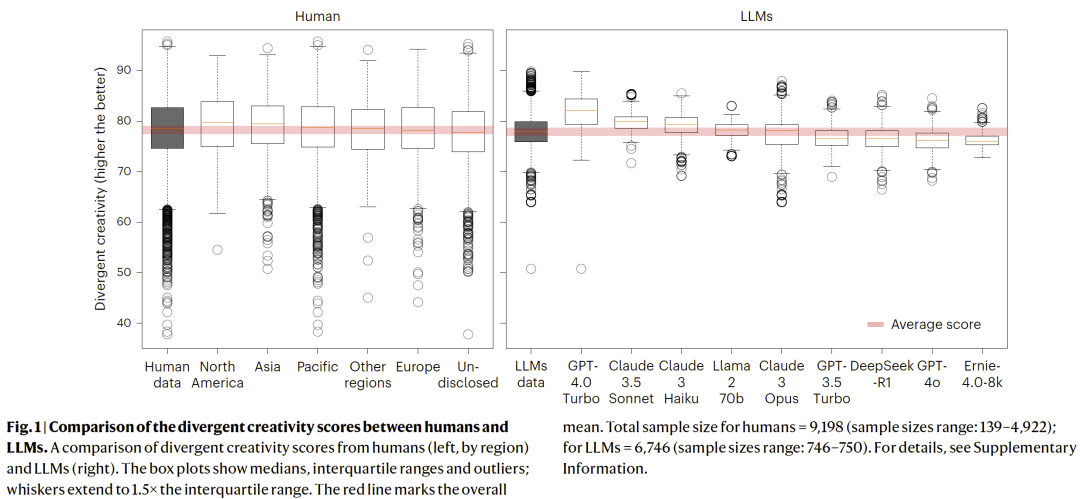
分布差异:真正的差距出现在“高端”
研究人员发现,创造力的核心差异并不体现在平均值,而体现在分布形态上。
- 人类表现出显著更高的方差;
- 在高分尾部(top performers),人类显著超越所有模型;
- 模型输出更趋于均匀、同质化。
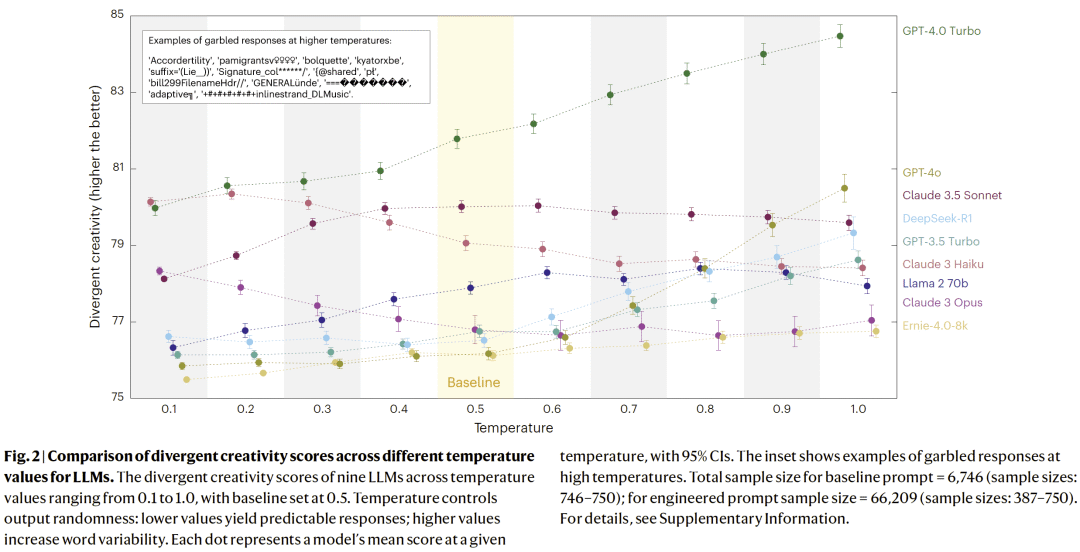
随机性提升并不能复制人类创造力
提高模型生成的随机性(temperature)可在一定程度上提升创造力评分,但当随机性过高时,模型开始生成无意义或语义破碎的输出。这表明,随机性≠创造性。
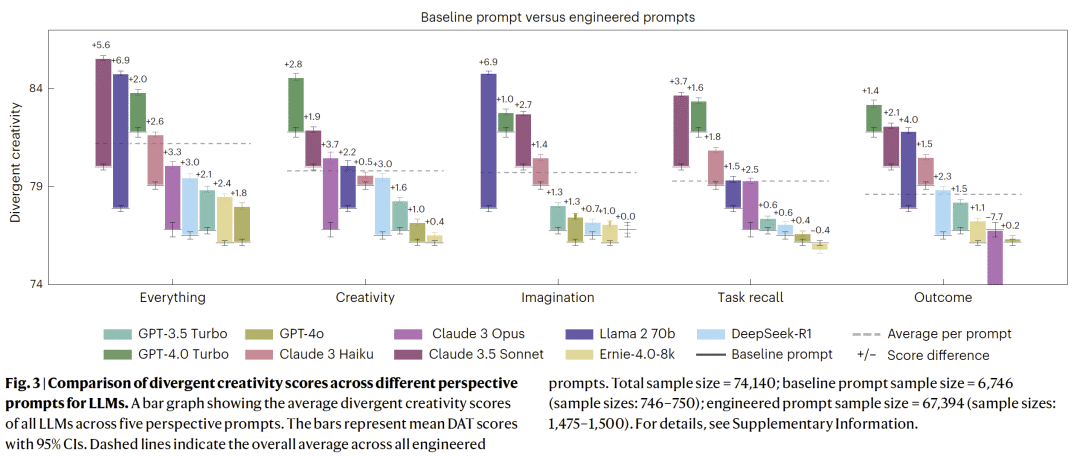
提示工程的“上限效应”
在多种提示策略中:
- 任务导向 / 视角导向提示可显著提升模型平均表现;
- 但即便在最优提示下,模型仍无法在词汇多样性与极端表现上超越高水平人类;
- 名人角色提示(如“像爱因斯坦一样思考”)反而普遍降低模型表现。
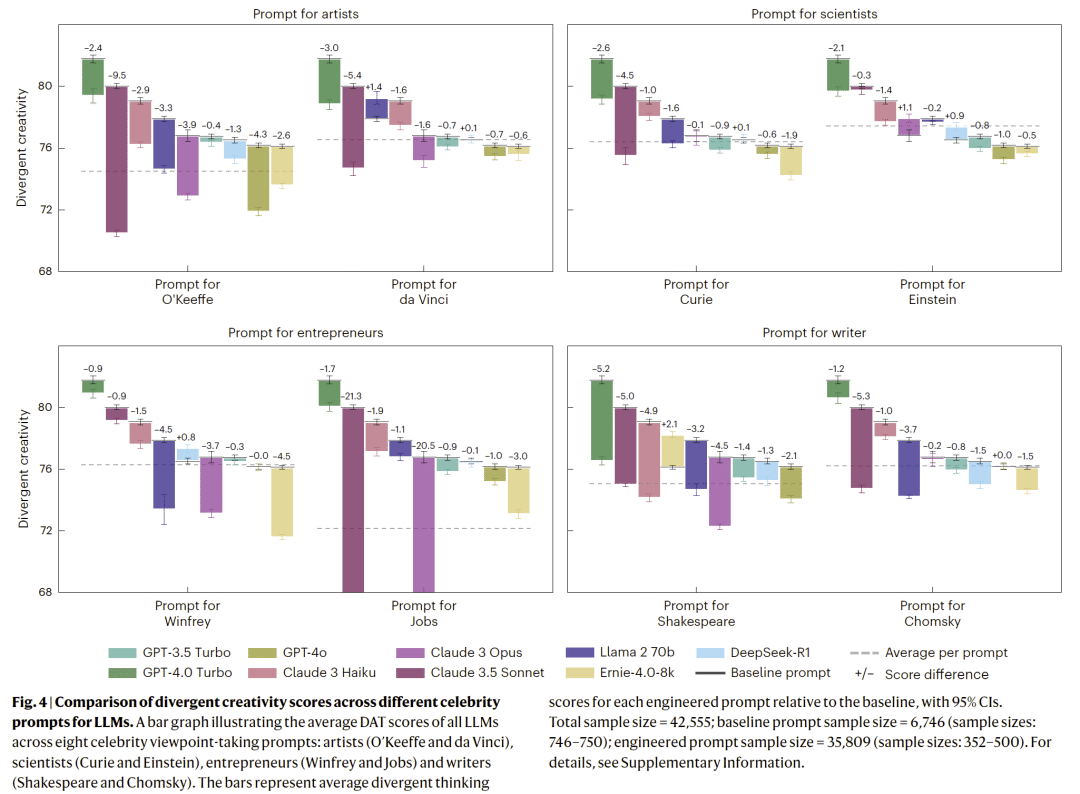
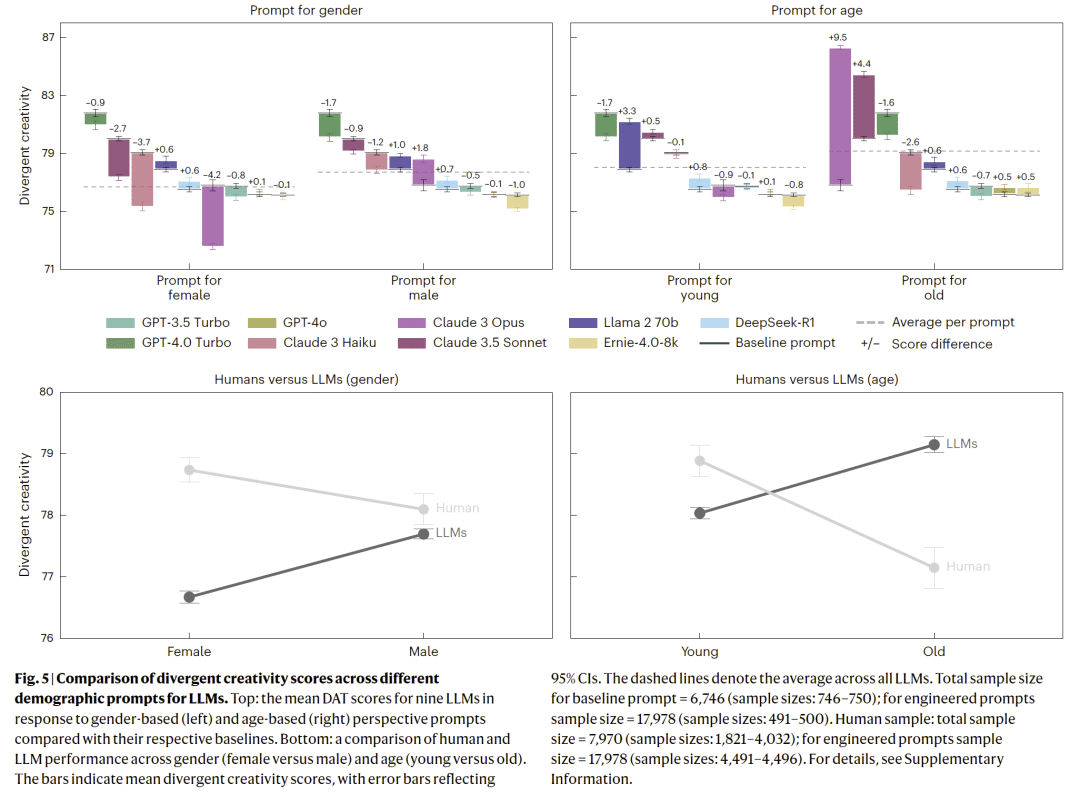
人口学提示产生“反现实”模式
当模型被要求模拟不同性别或年龄群体时,其输出模式与真实人类群体的创造力分布方向相反,显示模型并未真正学习到人类创造力的社会与认知结构。
讨论与启示
研究结果表明,大语言模型尚不具备人类创造力中最关键的特征——高度变异性、语义深度与极端创新能力。模型更适合生成“合格但不卓越”的创意候选,而非突破性想法。
因此,研究人员认为:
- 大语言模型更适合作为创造力的“放大器”而非“替代者”;
- 在实际应用中,可由模型快速生成基础方案,再由人类进行筛选、重组与升华;
- 人机协作的价值,取决于是否尊重并利用双方在创造机制上的根本差异。
整理 | DrugOne团队
参考资料
Wang, D., Huang, D., Shen, H. et al. A large-scale comparison of divergent creativity in humans and large language models. Nat Hum Behav (2025).
https://doi.org/10.1038/s41562-025-02331-1
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号