Nat. Commun. | 让蛋白语言模型学会预测蛋白质相互作用

Nat. Commun. | 让蛋白语言模型学会预测蛋白质相互作用

DrugAI
发布于 2026-01-06 13:35:18
发布于 2026-01-06 13:35:18
DRUGONE
虽然深度学习已能仅凭氨基酸序列高精度地预测蛋白结构,但预测蛋白–蛋白相互作用(PPI)仍面临挑战。研究人员提出 PLM-interact,一种可扩展至蛋白复合物层面的蛋白语言模型(Protein Language Model, PLM),通过联合编码蛋白对并引入“下句预测”(Next Sentence Prediction)任务,使模型能够从序列层面学习蛋白间关系。该方法在跨物种 PPI 基准上取得最优性能:模型在人体数据上训练后,可准确预测小鼠、果蝇、线虫、酵母及大肠杆菌的 PPI。研究人员还开发了针对突变效应预测的微调策略,使模型能判断突变对相互作用强度的影响。此外,PLM-interact 在病毒–宿主蛋白互作预测中也显著优于现有方法,证明大型语言模型能从氨基酸序列中学习复杂的分子互作规律。

蛋白质通过相互作用执行几乎所有生命活动。PPI 的破坏常与疾病发生相关,如突变导致的蛋白结合丧失;而在病毒学中,病毒依赖宿主蛋白进行复制,其感染机制本质上是病毒–宿主 PPI 的重构。实验手段虽能确定 PPIs,但代价高昂、覆盖度有限。计算预测成为重要替代方案,已有方法利用结构、序列和进化特征,通过机器学习或深度学习实现预测。然而,这些方法大多基于单蛋白训练的语言模型(PLM),并未真正捕获蛋白之间的交互语义。传统 PPI 模型使用预训练的 PLM 生成每个蛋白的独立表示,再由分类器判断是否互作。这种“冻结式”架构忽视了互作背景,仅依赖浅层分类头推断关系,难以捕捉复杂的跨蛋白模式。
为解决此问题,研究人员提出 PLM-interact:直接在蛋白对上微调预训练语言模型 ESM-2,使模型在训练中联合编码两个蛋白序列,从注意力层学习跨链残基关联,从而建立跨蛋白语义连接。
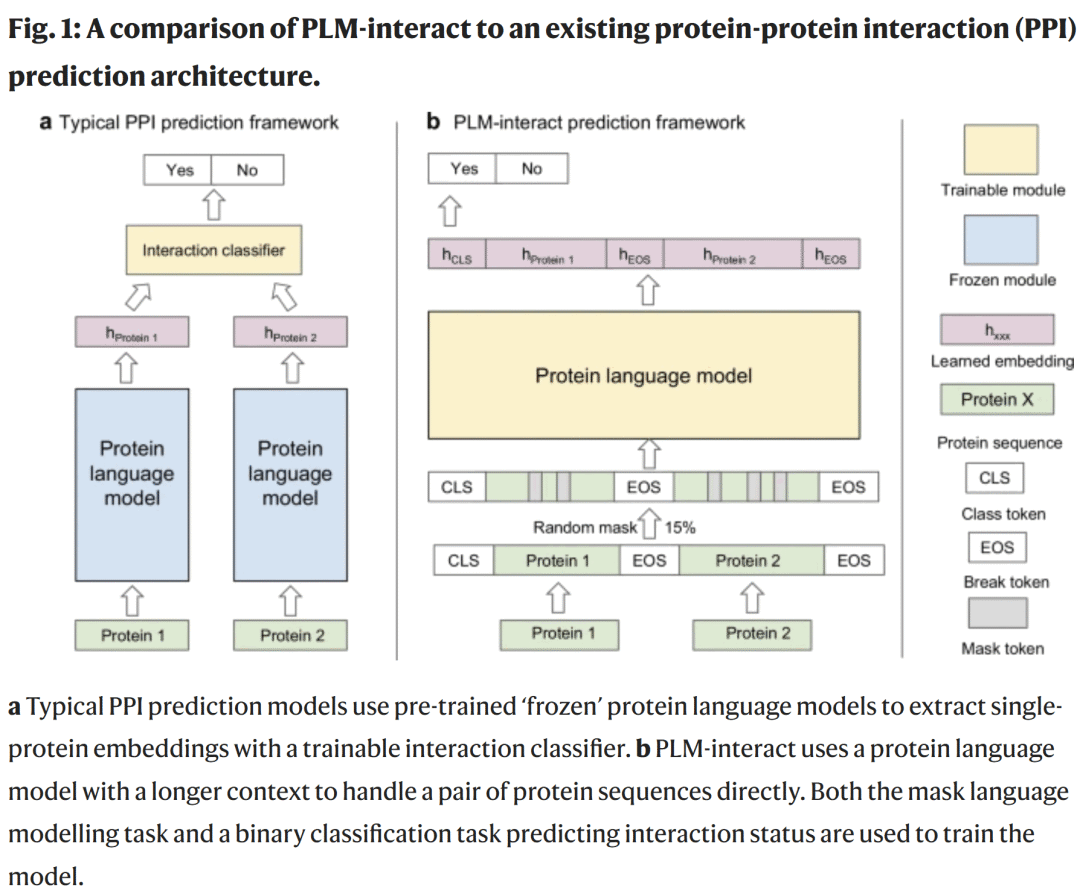
图1. 传统 PPI 模型与 PLM-interact 架构对比示意
方法
PLM-interact 在 ESM-2 模型基础上进行两项关键扩展:
- 联合序列编:将两个蛋白序列连接输入 Transformer,使注意力层能学习跨蛋白残基对应关系;
- 双任务训练:同时进行掩码语言建模与二分类(是否互作)任务,并引入“下句预测”逻辑。
研究人员系统测试了不同的任务权重比例,最终确定分类损失与掩码损失的最优比为 1:10。模型在跨物种数据集上训练与验证,利用约 42 万个人体蛋白对作为训练集,另在小鼠、果蝇、线虫、酵母与大肠杆菌数据集上测试性能。
结果
跨物种预测性能显著提升
研究人员将 PLM-interact 与六种主流 PPI 预测模型(TUnA、TT3D、Topsy-Turvy、D-SCRIPT、PIPR、DeepPPI)进行比较。模型在人类数据上训练,在五个物种上测试。结果显示,PLM-interact 在所有物种上取得最高的 AUPR 值。
在小鼠、果蝇与线虫中,AUPR 相比 TUnA 分别提升 2%、8% 和 6%;相较 TT3D 提升 16%、21% 和 20%。
在进化距离更远的酵母与大肠杆菌数据集上,PLM-interact 分别取得 0.706 与 0.722 的 AUPR,比 TUnA 分别高出 10% 与 7%,比 TT3D 分别高出 28% 与 19%。
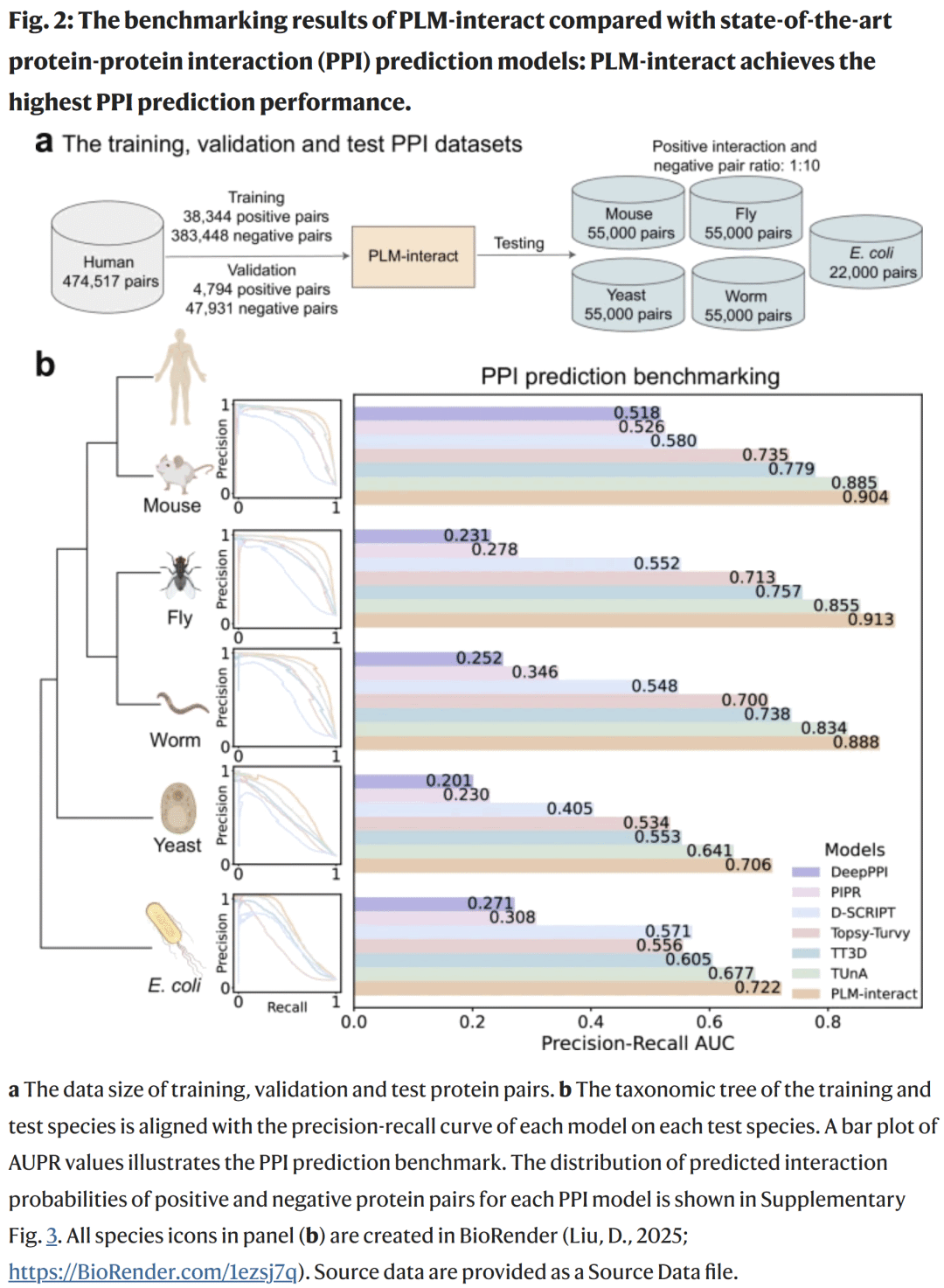
图2. 跨物种基准结果与 AUPR 对比
进一步分析发现,模型的提升主要来源于对真阳性互作的准确识别。PLM-interact 对真实互作的预测概率更高,而对非互作的置信度更低,表现出良好的判别能力。
成功预测关键生物学互作
研究人员展示了五个在不同物种中的典型互作实例,这些样本中 PLM-interact 预测正确,而 TUnA 与 TT3D 均预测错误。这些互作涉及白血病细胞分化、线粒体蛋白导入、RNA 聚合及跨膜转运等关键生命过程。
研究人员使用 Chai-1 与 AlphaFold3 进行结构预测和可视化,结果显示这些复合物在空间构象上高度匹配。
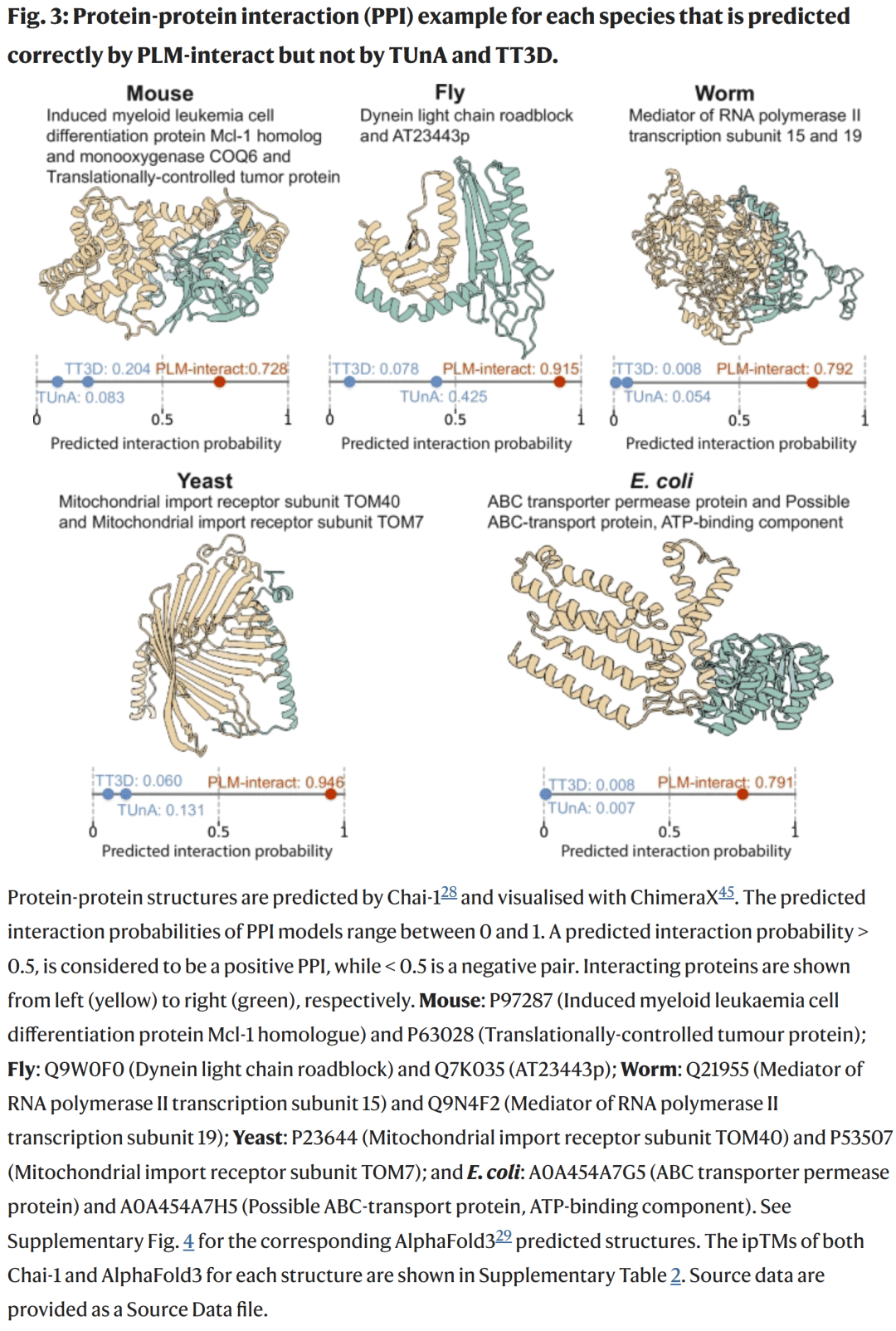
图3. 五个跨物种 PPI 预测示例与结构可视化
在严格无泄漏数据集上的验证
在 Bernett 数据集上(训练、验证、测试间无序列重叠),PLM-interact 与 TUnA 的整体 AUPR 与 AUROC 均为 0.7,但在 F1-score 与召回率上 PLM-interact 更优,召回率提升 9%,显示其更擅长发现真实互作。
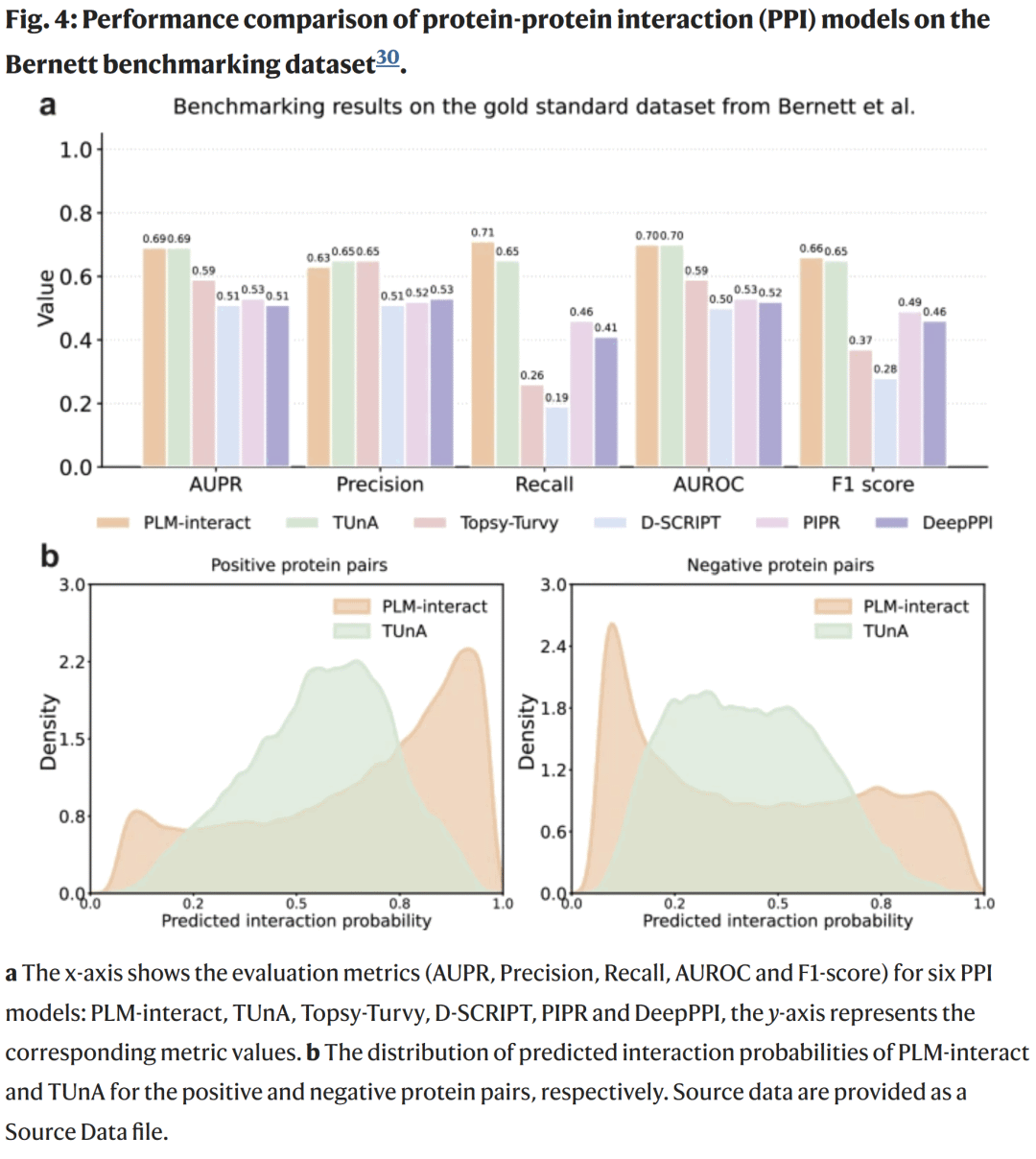
图4. 无泄漏数据集下的模型性能比较
突变对蛋白互作影响的预测
研究人员进一步验证 PLM-interact 预测突变对 PPI 的影响能力,使用 IntAct 数据集中 6979 个带注释的突变实例。通过微调策略,模型学习突变前后互作概率变化的对数比值,判断突变是否增强或削弱结合。
微调后的 PLM-interact 在 AUPR 提升 150%、AUROC 提升 36%,显著优于未经微调的模型。
例如:
- MCM7 Y600E 突变增强了与 MCM5 的结合,模型正确预测交互增强;
- Frataxin N151A 突变降低了与 ISCU 的结合,模型亦正确预测为交互减弱。
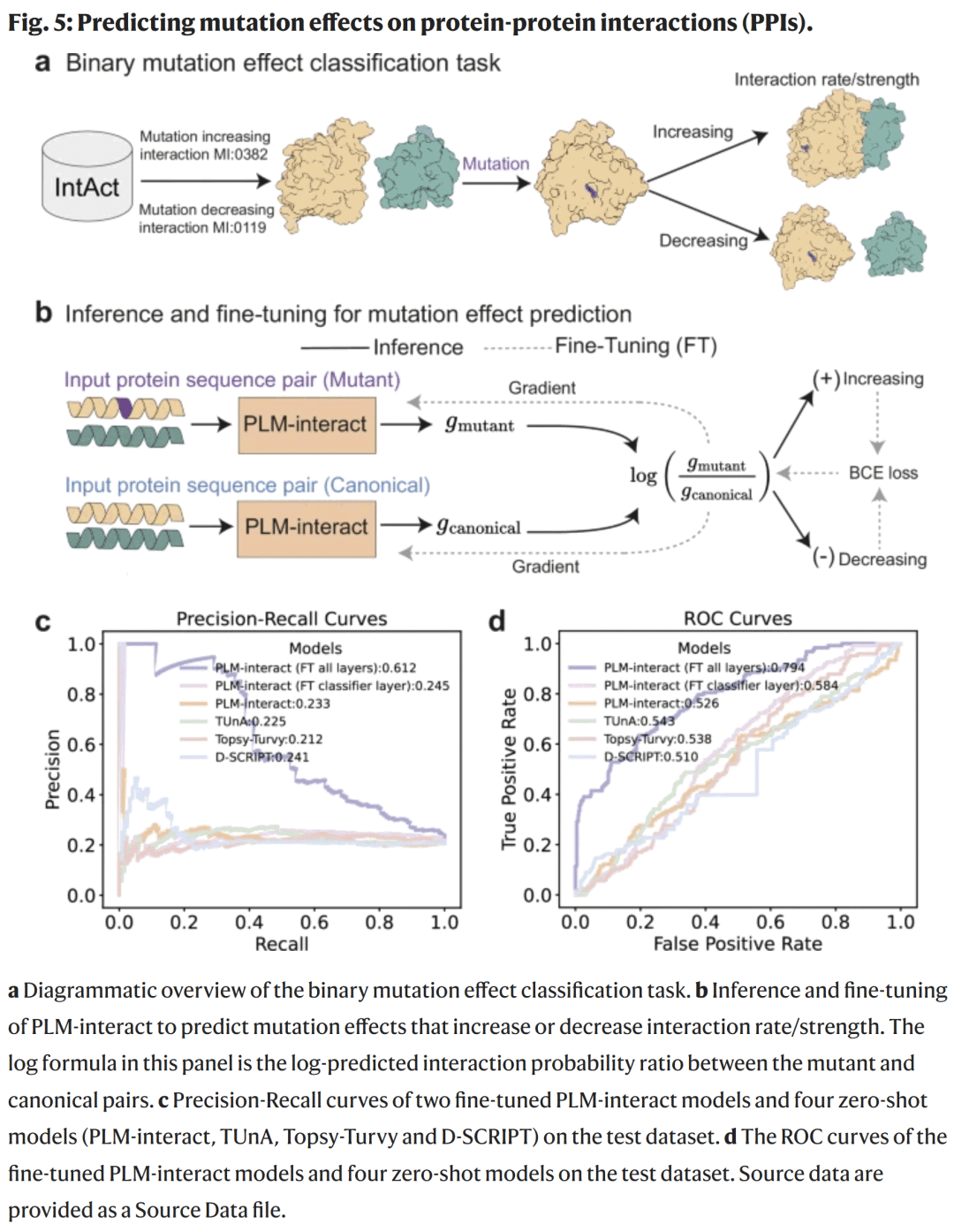
图5. 突变效应预测流程与性能比较
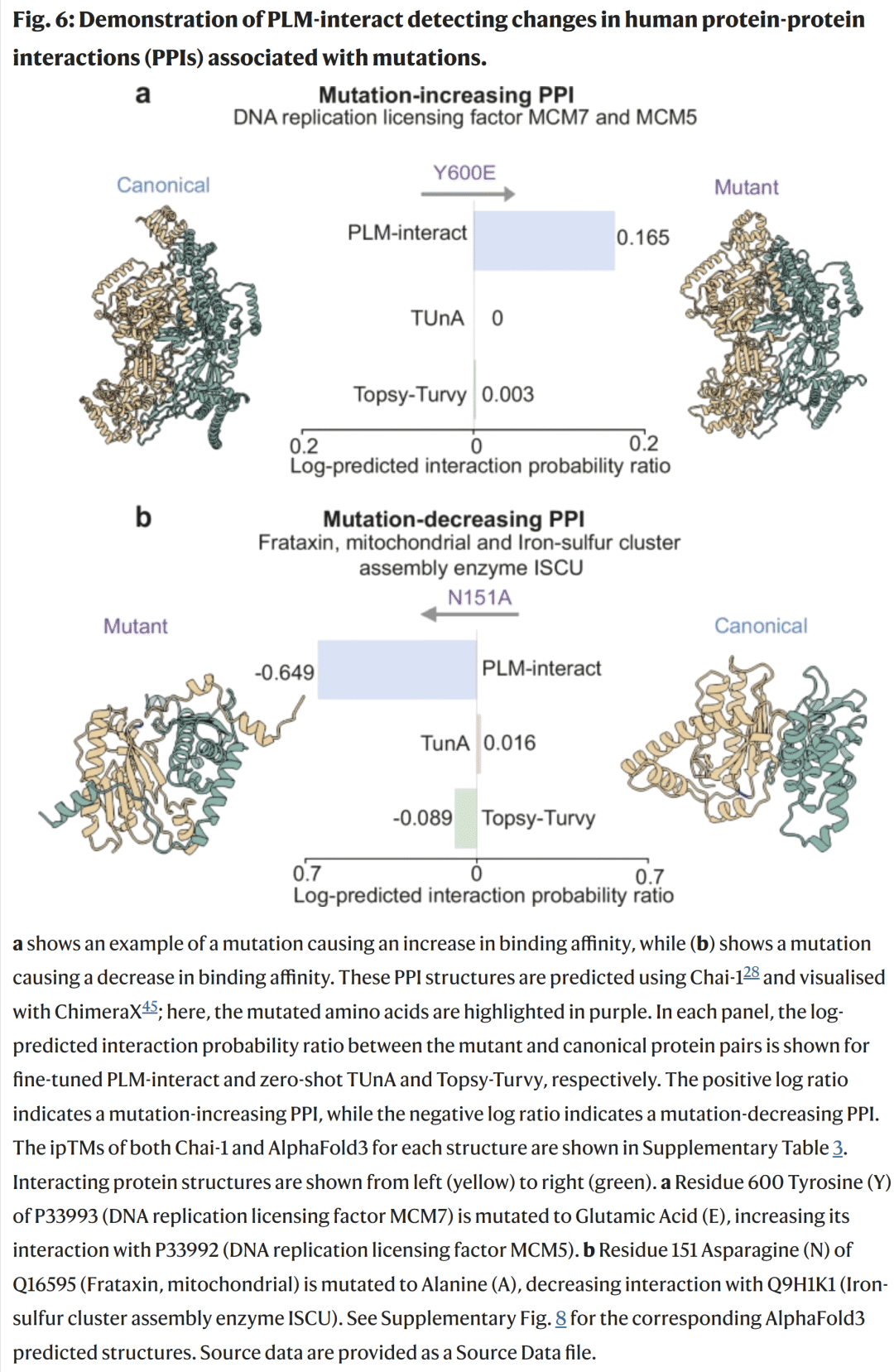
图6. 突变导致的结合增强与削弱案例可视化
病毒–宿主相互作用预测的扩展
PLM-interact 还在病毒–宿主互作预测任务中展示卓越性能。研究人员基于 HPIDB 数据库训练病毒–人类 PPI 模型,并与 STEP、LSTM-PHV、InterSPPI 等方法对比。
PLM-interact 在 AUPR、F1 与 MCC 指标上分别提升 5.7%、10.9% 与 11.9%。
模型对三种实验验证的病毒–人类复合物(HSV1、Nipah 病毒与 SV40)预测均正确。
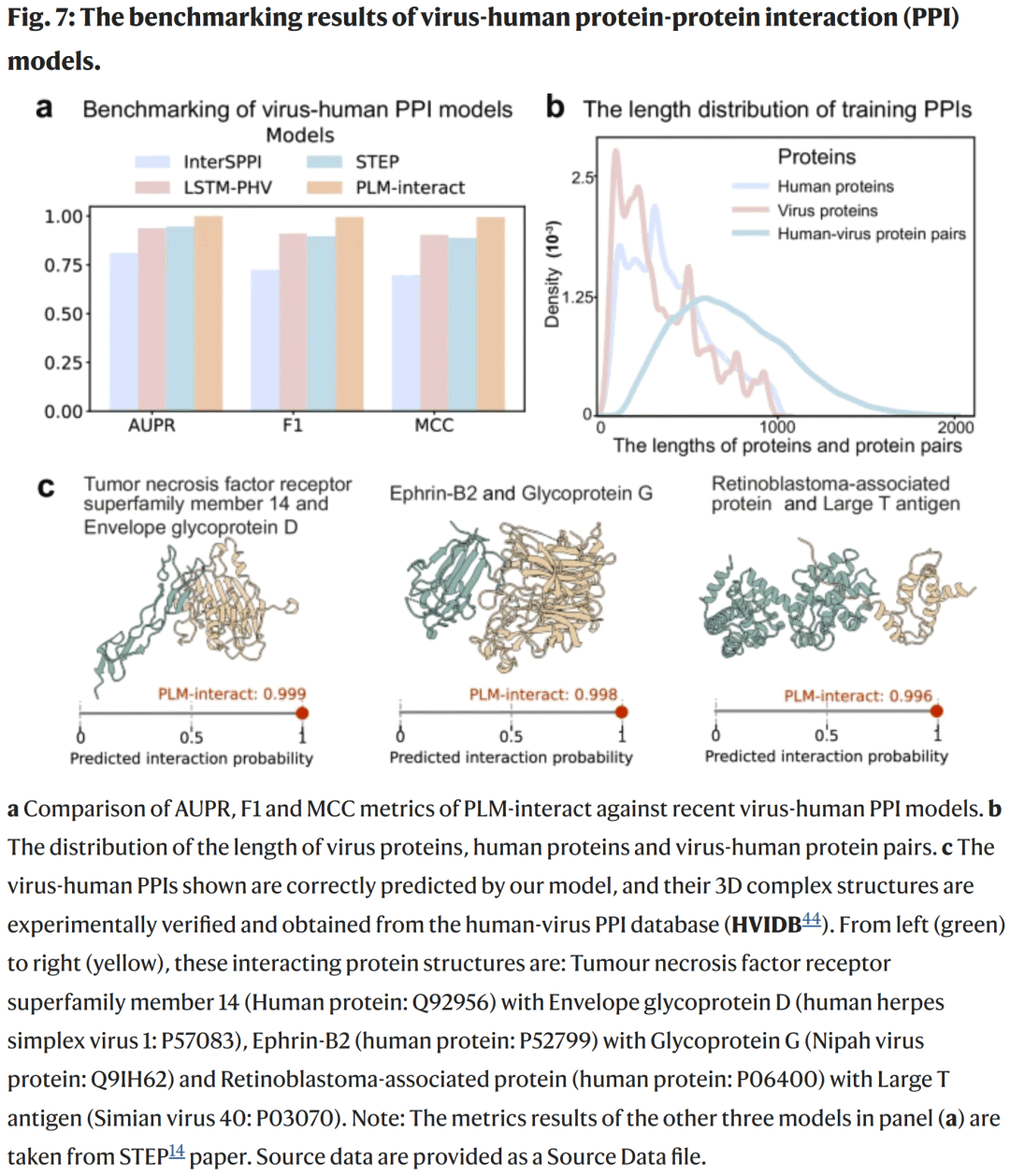
图7. 病毒–宿主 PPI 模型性能比较与结构示例
讨论
PLM-interact 证明了蛋白语言模型可从单链序列扩展至分子交互层面。与传统基于静态嵌入的分类器不同,该模型在训练中直接学习跨蛋白残基的依赖关系,从而捕捉真实的互作语义。
其主要优势包括:
- 跨蛋白注意力建模 —— 直接关联两个序列中残基间的语义联系;
- 强泛化性 —— 能跨物种迁移,捕捉进化保守的互作模式;
- 突变敏感性 —— 通过微调可识别结构扰动导致的结合变化;
- 病毒–宿主拓展性 —— 为病原体互作与宿主特异性预测提供分子级信息。
研究人员指出,未来工作可通过引入结构与多模态输入(蛋白–RNA–DNA)进一步增强模型性能,并利用高质量实验数据提升病毒–宿主互作预测的可靠性。
PLM-interact 展示了语言模型在解析生命体系“语法”方面的潜力,为构建可解释、可迁移、跨尺度的生物分子交互模型开辟了新路径。
整理 | DrugOne团队
参考资料
Liu, D., Young, F., Lamb, K.D. et al. PLM-interact: extending protein language models to predict protein-protein interactions. Nat Commun 16, 9012 (2025).
https://doi.org/10.1038/s41467-025-64512-w
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号