Nat. Commun. | 融合在线化学标记的串联质谱新策略,全面提升代谢物注释能力

Nat. Commun. | 融合在线化学标记的串联质谱新策略,全面提升代谢物注释能力

DrugAI
发布于 2026-01-06 11:05:58
发布于 2026-01-06 11:05:58
DRUGONE
非靶向质谱代谢组学中,受限于光谱库覆盖率不足和代谢物裂解模式预测的困难,代谢物鉴定依然是重大挑战。研究人员提出了一种多路化学代谢组学(MCheM)方法,将多种正交的色谱后衍生化反应整合到统一的质谱数据框架中。该方法能够生成正交的结构信息,显著提升基于计算机模拟光谱匹配和开放修饰搜索的代谢物注释能力,从而为大规模未知代谢物结构解析提供了新工具。

虽然高分辨液相色谱-串联质谱(LC-MS/MS)硬件和计算方法不断进步,代谢物注释仍然困难。通常,质谱分析中能被可靠注释的特征不到 10%。大量未注释特征源于离子加合物和源内碎片,但越来越多的代谢组学、基因组挖掘及天然产物发现研究表明,代谢物的化学空间极其广阔且大部分未知。造成代谢物鉴定瓶颈的主要原因之一是光谱库覆盖不足,相比之下,结构数据库的规模要大得多。虽然利用结构数据库的计算机模拟注释方法及 de novo 结构预测方法取得了进展,但高置信度的代谢物注释依然难以实现。
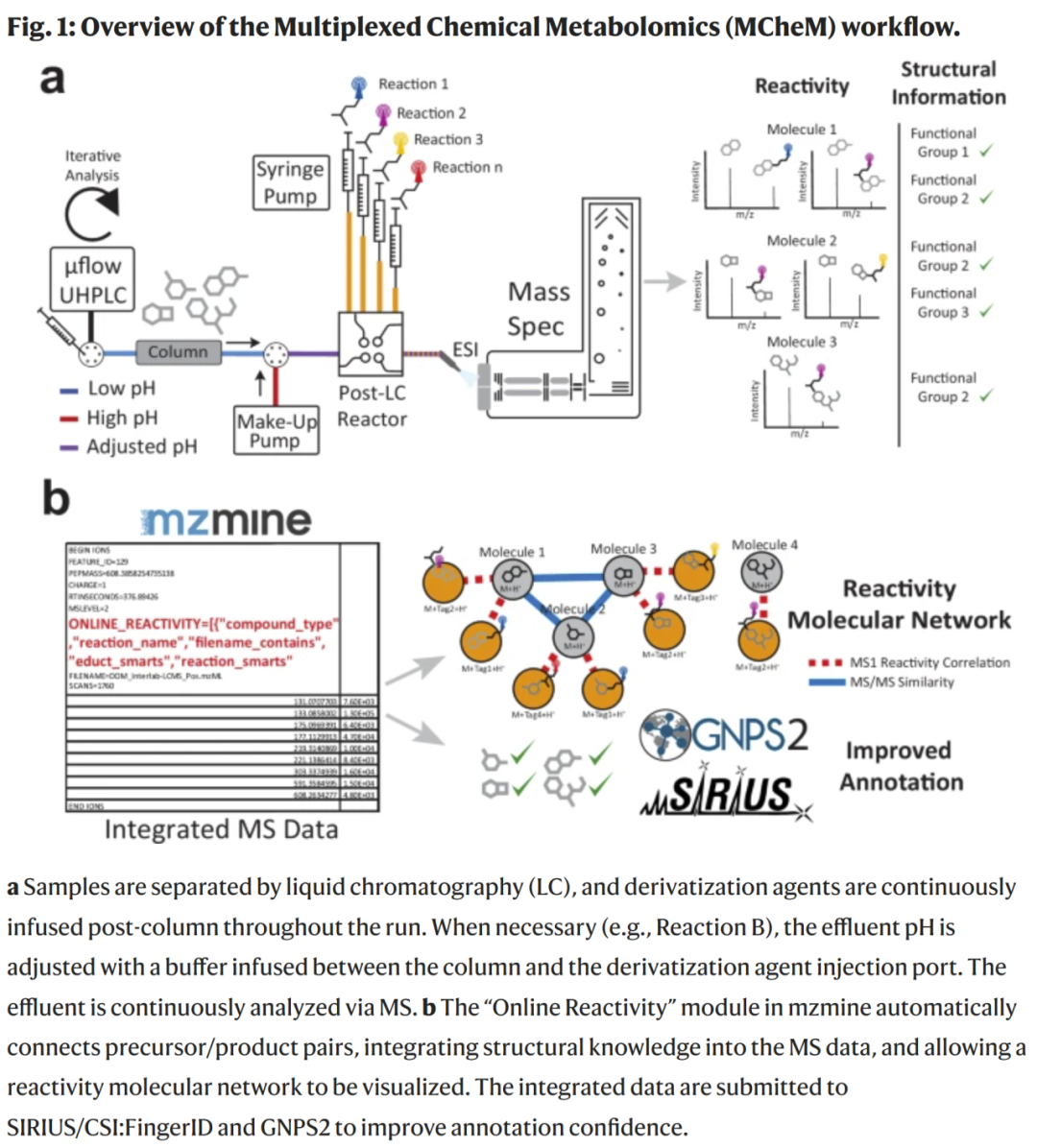
化学衍生化常被用来提升结构解析能力并降低检测限,通过靶向特定官能团的反应提高检测灵敏度。在靶向代谢组学中,色谱后的衍生化可增强特定化合物的检测,而在非靶向代谢组学中,大多数衍生化策略仍局限于色谱前的批量反应。色谱后衍生化具备巨大潜力,可在保持前体和衍生产物共洗脱关系的同时,提供未知分子官能团信息。这为复杂混合物中利用多种反应探针获取更多结构信息提供了可能。
结果
MCheM 硬件与软件实现
研究人员构建了一套 LC-MS/MS 专用硬件,包括补液 UHPLC 泵、T 型接头或反应歧管以及注射泵,并实现了三种 LC-MS 兼容的色谱后衍生化反应:
- 反应 A:L-半胱氨酸标记亲电子基团;
- 反应 B:AQC 标记氨基和酚羟基;
- 反应 C:羟胺盐酸盐标记醛基和酮基。
为处理多反应数据,研究人员开发了 mzmine 的“在线反应性”模块,结合离子身份网络和用户定义的质量差,将前体与衍生产物关联,输出包含质谱信息和反应性信息的混合数据集,并生成可供 CSI:FingerID、GNPS2 等工具利用的官能团或子结构信息。
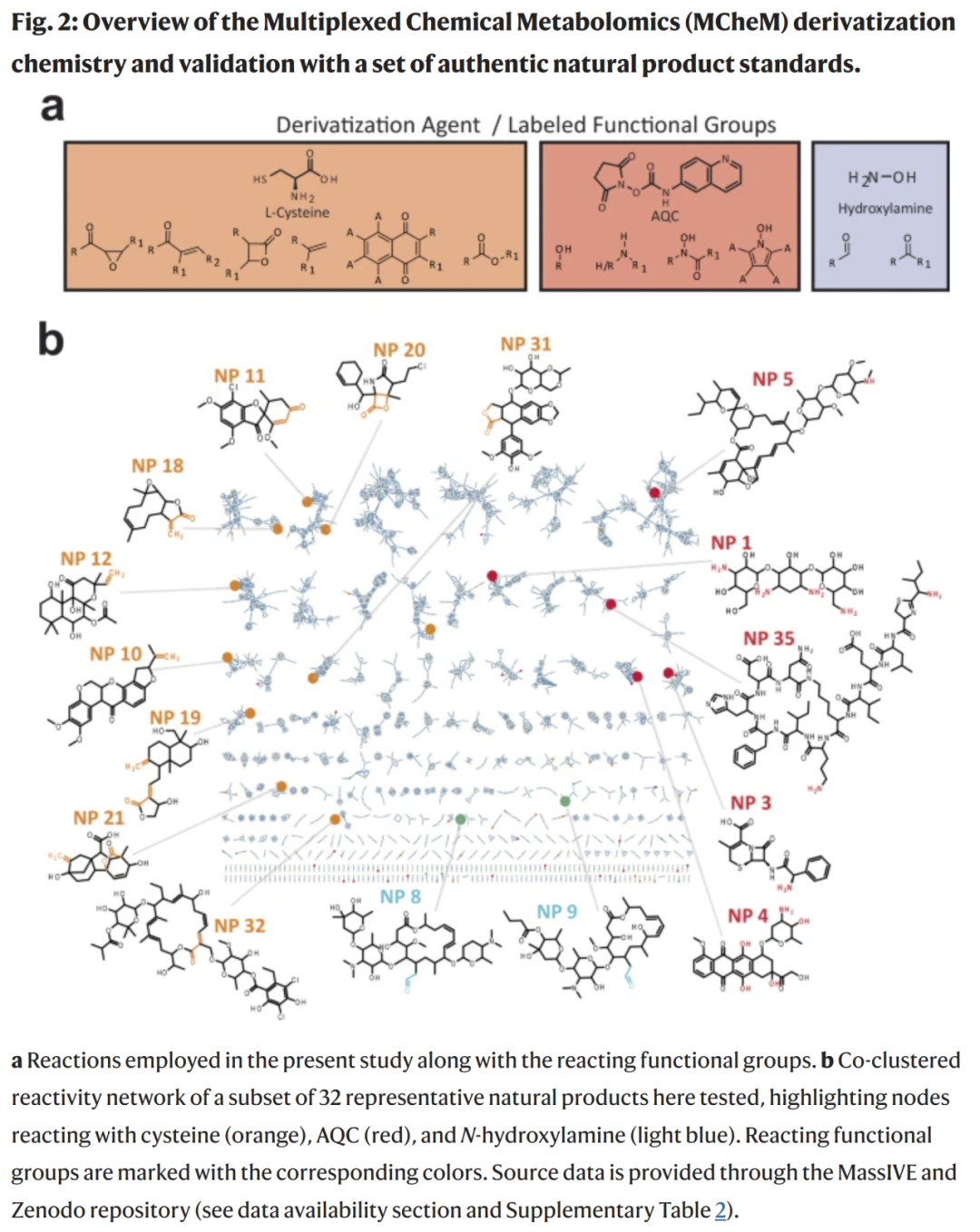
MCheM 提升串联质谱代谢物注释能力
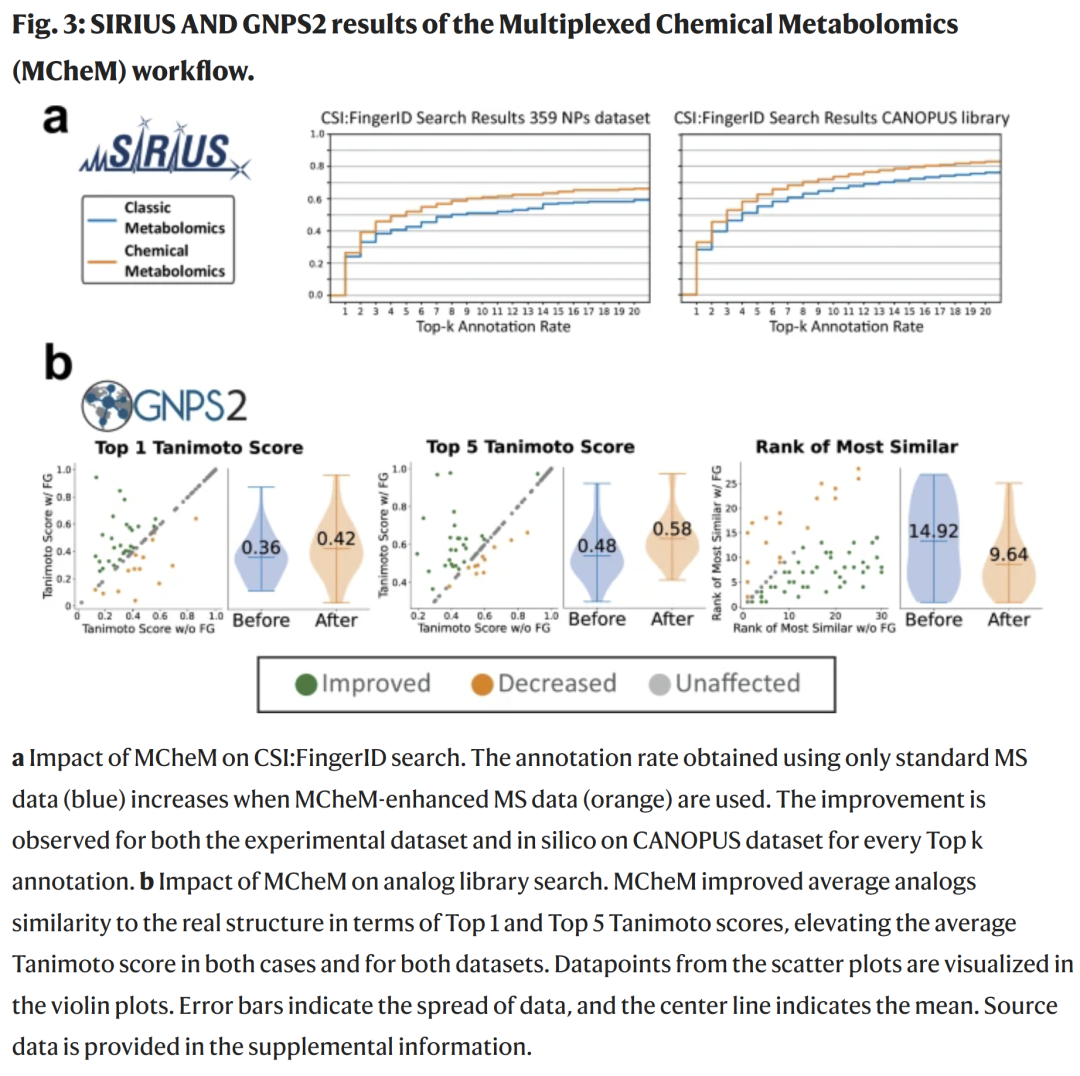
在 359 种天然产物标准品的验证中,三类反应均表现出高度特异性,假阳性仅占 3.6%。将 MCheM 数据整合进 CSI:FingerID 查询后,实验数据中约 49% 的谱图排名提升,其中 20% 进入前三名,6% 升至第一。利用大规模公开数据集模拟加入官能团信息,也观察到 32% 的谱图排名改善。
在 GNPS2 开放修饰搜索中,MCheM 同样显著提高了与真实结构的相似性评分(Tanimoto 指数)及排名。例如,359 种标准品中符合筛选条件的 125 个谱图中,约 22% 的最佳相似性得分提高,平均 Tanimoto 值由 0.36 升至 0.44;在更大规模的 CANOPUS 数据集中,平均得分提升幅度达 18%。
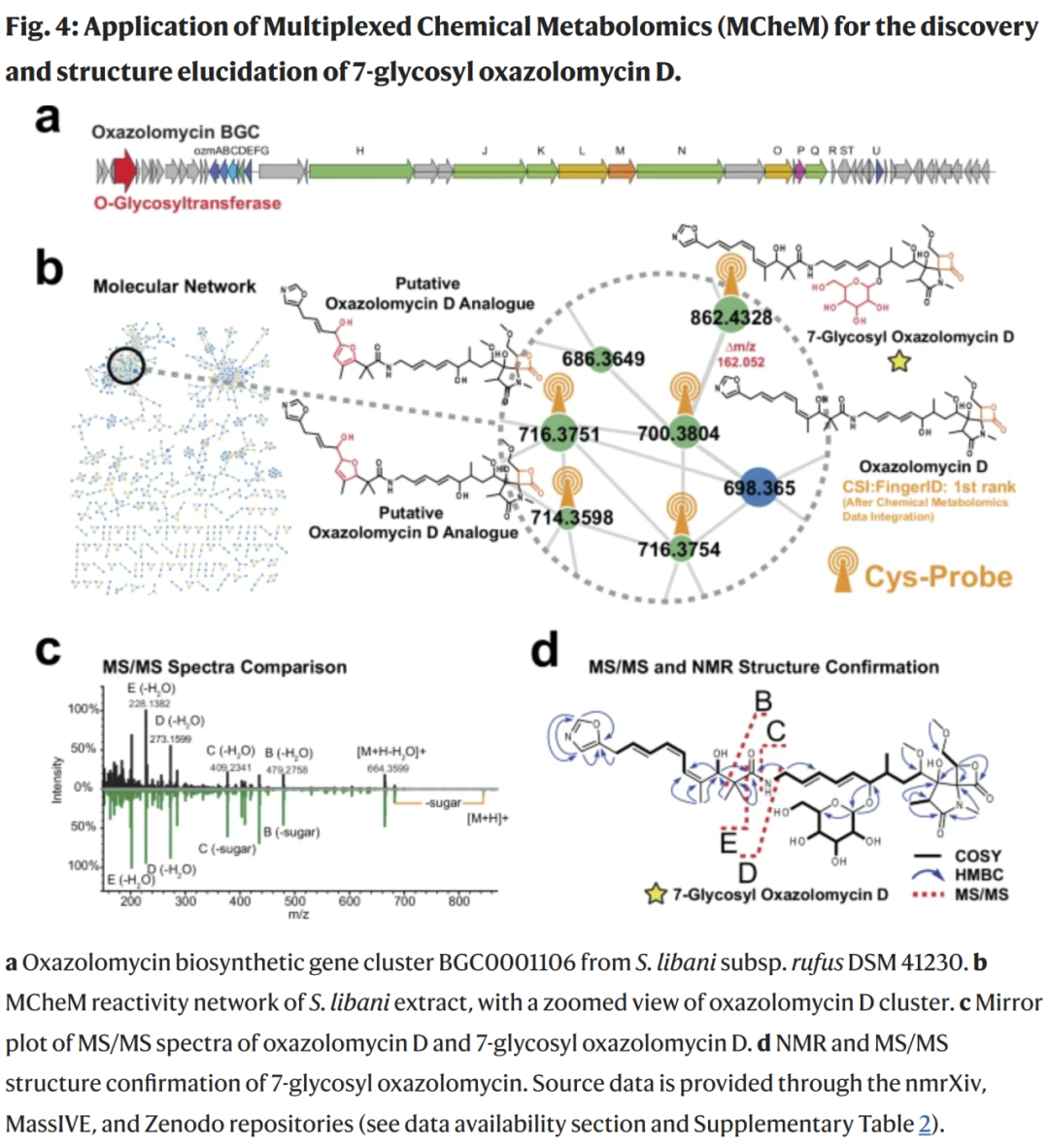
MCheM 促进 7-糖基氧唑霉素 D 的发现
研究人员将 MCheM 应用于基因组指导的天然产物发现。在分析 Streptomyces libani subsp. rufus DSM 41230 的发酵提取物时,通过反应 A 成功捕获了 β-内酯特征信号,使得原本未进入常规搜索前列的氧唑霉素 D 在 MCheM 辅助排名中升至第一位。进一步的分子网络分析发现多个结构相关、含糖基修饰的氧唑霉素类似物,其中一种分子质量差与己糖基一致,并通过 NMR 和 MS/MS 确证为 7-糖基氧唑霉素 D,这是该化合物家族中首个被报道的糖基化成员。
讨论
MCheM 将多种正交衍生化反应与串联质谱数据采集、计算分析深度结合,能够在不依赖庞大光谱库的情况下显著提升非靶向代谢物注释的准确性。该方法硬件要求低,适用于大多数 LC-MS/MS 平台,并且仅用三种反应就取得了明显效果。未来可进一步增加针对其他官能团的反应,以扩展结构信息覆盖范围,并与新兴计算方法结合,推动基于 MS/MS 的完整 de novo 结构解析。
整理 | DrugOne团队
参考资料
Vitale, G.A., Xia, SN., Dührkop, K. et al. Enhancing tandem mass spectrometry-based metabolite annotation with online chemical labeling. Nat Commun 16, 6911 (2025).
https://doi.org/10.1038/s41467-025-61240-z
内容为【DrugOne】公众号原创,|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号