效率就是一切:并行计算如何重塑 AI 训练与现代应用

效率就是一切:并行计算如何重塑 AI 训练与现代应用

随机比特
发布于 2025-12-30 20:08:30
发布于 2025-12-30 20:08:30
【万字长文】从云计算到 AI 推理,一文看懂并行计算的底层逻辑
为什么王者荣耀进入游戏,要先选区? 为什么英伟达成了 AI 时代的硬通货? 为什么 DeepSeek/ChatGPT 回答问题前要"自言自语"一大段?
这三个看似无关的问题,背后藏着同一条主线:无状态 → 并行计算。
本文分三部分:
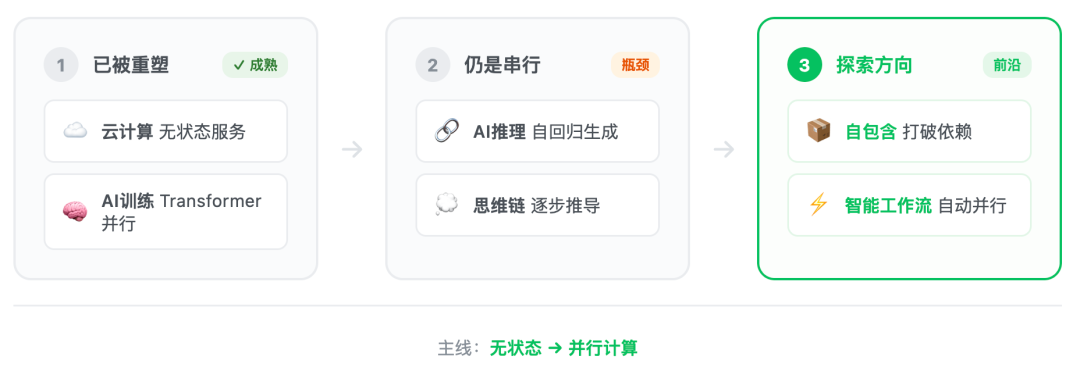
- 并行已经重塑了什么——云计算和 AI 训练的成熟实践
- 推理为什么还是串行的——自回归生成和思维链到底是怎么回事
- 推理并行化的探索方向——从学术思路到前沿框架
第一部分:并行已经重塑了什么
1. 云计算:无状态服务的胜利
先从一个每天都在用的技术说起:无状态服务(Stateless Services)。
无状态服务是什么?
一个无状态服务就像一个"没有记忆的专家":
- 你通过 API 请求把所有必要的数据一次性发给它
- 它干完活,返回结果
- 然后彻底忘记这次交互
每一次调用都是独立事件,和其他调用毫无关联。腾讯云函数、Cloudflare Workers 都是典型代表。
在代码里,我们称之为纯函数(Pure Function)。
无状态的三大优势
极易扩展 | 流量暴涨?加机器就行,无需复杂同步 |
|---|---|
高容错性 | 单个实例崩溃不影响其他服务,请求自动转给健康实例 |
简化架构 | 功能边界清晰,测试、部署、回滚都更好做 |
反例:为什么王者荣耀要选区?
再来看一个有状态服务的典型——游戏服务器。
王者荣耀对玩家状态同步的实时性要求极高:你的位置、技能、血量、装备,必须在毫秒级同步给队友和对手。
这意味着服务器必须持续记住每个玩家的状态,并在整局游戏期间维护这些状态。
这就是"有状态服务"的代价:
- 难以横向扩展:每台服务器都记着一群玩家的状态,不能随便把玩家挪到另一台
- 扩容成本高:增加服务器需要复杂的状态迁移和同步机制
- 单点故障风险:服务器崩溃,正在进行的对局数据可能丢失
怎么办?分区。
王者荣耀让玩家在进入游戏时先选择服务器区(微信区、QQ区、不同大区),其实是把用户分流到不同的有状态服务器集群。这是应对"有状态"架构扩展困难的妥协方案。
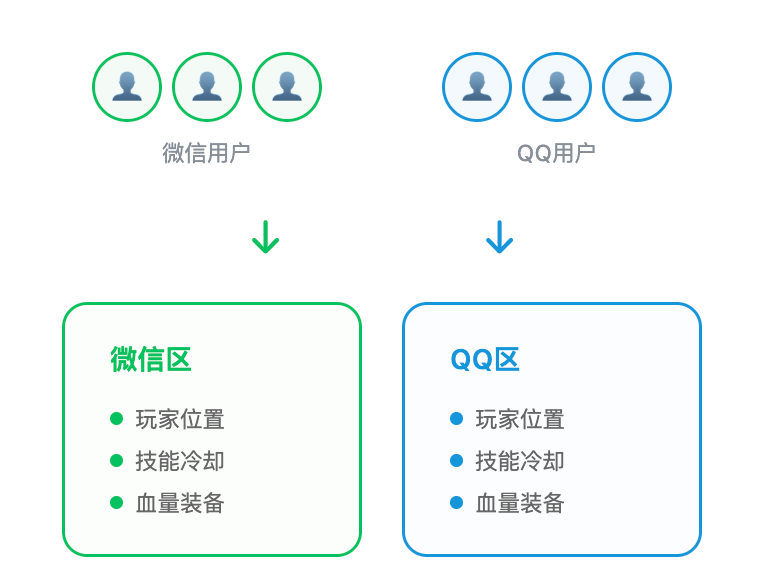
回答开头第一个问题:王者荣耀要选区,是因为游戏服务是有状态的,难以横向扩展,只能用分区把状态切开。
2. AI 训练:Transformer 为什么能干掉 RNN
现在看第二个问题:为什么英伟达成了 AI 时代的硬通货?
答案藏在一篇 2017 年的论文里——《Attention Is All You Need》。
RNN 的"锁链"困境
在 Transformer 出现之前,处理序列数据(文本、语音、时间序列)的主流模型是 RNN(Recurrent Neural Network,循环神经网络) 及其变体 LSTM。
RNN 的工作方式是这样的:
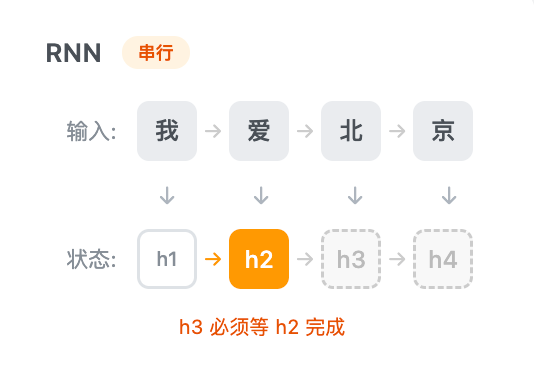
处理"爱"这个字,必须先处理完"我",拿到隐藏状态 h1;处理"北",必须先拿到 h2……
每一步都在等上一步。RNN 就是这么设计的,没法改。
训练一个 RNN 模型,即使你有 1000 块 GPU,处理一句话时也只能一个词一个词地算。其他 999 块在干等。
Attention:同时看所有词
Transformer 最牛的地方是自注意力机制(Self-Attention):
计算某个词的表示时,不需要等前面的词处理完,可以同时看整句话的所有词。
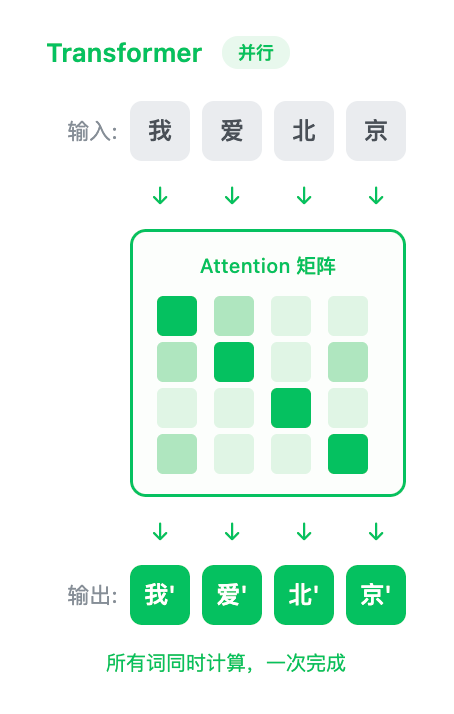
"我"和"京"之间的关系、"爱"和"北"之间的关系——可以同时计算,不需要等待。
这就是论文标题的含义:Attention Is All You Need——有了注意力机制,你不再需要顺序处理,不再需要 RNN。
为什么英伟达成了硬通货?
Attention 计算说白了是什么?矩阵乘法。
Attention(Q, K, V) = softmax(Q × K^T / √d) × V
Q、K、V 是矩阵,整个计算就是一系列矩阵运算。而矩阵运算,正是 GPU 最擅长的事情。
但 GPU 最初可不是为 AI 设计的——它是为游戏而生的。
图形渲染天生适合并行
渲染一帧游戏画面需要什么?计算屏幕上每一个像素的颜色。
一个 1080p 画面有 200 万个像素,每个像素都要根据光照、纹理、阴影等信息计算颜色。关键是:每个像素的计算是独立的——像素 A 的颜色不依赖像素 B。
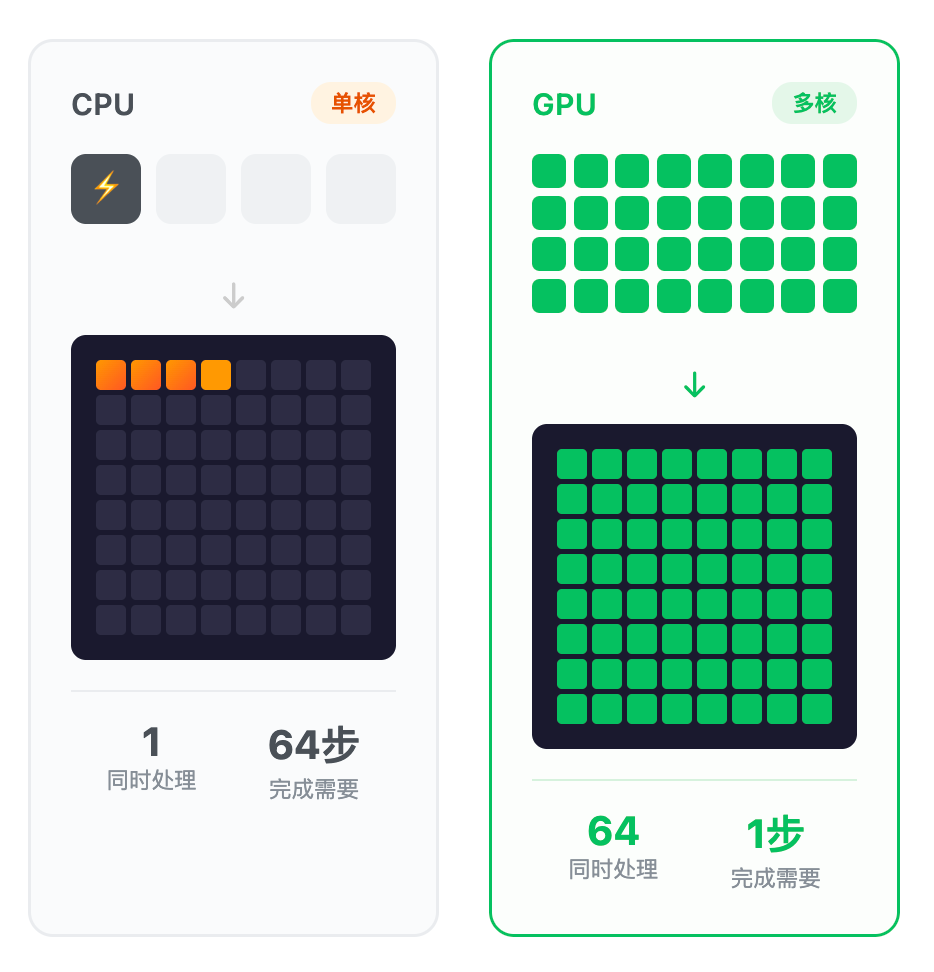
这就是天然的并行场景。与其用一个超强的核心一个像素一个像素地算,不如用几千个小核心同时算几千个像素。
从游戏到 AI:一次意外的适配
英伟达当年设计 GPU,目标是"同时处理大量相似但独立的小任务"。
后来人们发现:
- 科学计算(矩阵运算)也是这种模式
- 深度学习训练(大量矩阵乘法)也是这种模式
- Transformer 的 Attention(更大量的矩阵乘法)还是这种模式
GPU 为游戏而生,却意外成了 AI 时代的硬通货——因为图形渲染和 AI 训练,底层都是"大量独立任务的并行计算"。
RNN | Transformer | |
|---|---|---|
计算方式 | 顺序,一个词接一个词 | 并行,所有词同时处理 |
GPU 利用率 | 低(大量核心闲置) | 高(所有核心满载) |
训练速度 | 慢 | 快几个数量级 |
这就是为什么 GPT-3(1750 亿参数)能在合理时间内训练完成——不是因为算法多聪明,而是因为 Transformer 的并行特性正好对上了 GPU 的硬件能力。
如果没有 Transformer,AI 还在用 RNN 一个词一个词地算,英伟达的 GPU 再强也没用——就像给一个单车道公路配 100 个收费站,车还是只能一辆一辆过。
回答开头第二个问题:英伟达成为 AI 硬通货,是因为 Transformer 让 AI 训练可以并行化,而 GPU 天生擅长并行计算。
第二部分:推理为什么还是串行的
3. 训练并行了,推理呢?
Transformer 重塑了训练——但推理依然是串行的。
训练 vs 推理:差在哪儿?
阶段 | 知道什么 | 能否并行 |
|---|---|---|
训练 | 知道完整的输入和输出(答案) | ✓ |
推理 | 只知道输入,输出要一个个生成 | ✕ |
训练时,我们已经知道正确答案,可以同时计算所有位置的 loss。
什么是 loss? 损失函数(Loss Function)是衡量模型预测与标准答案差距的误差指标,用来反向更新模型参数。
但推理时,你不知道下一个词是什么:
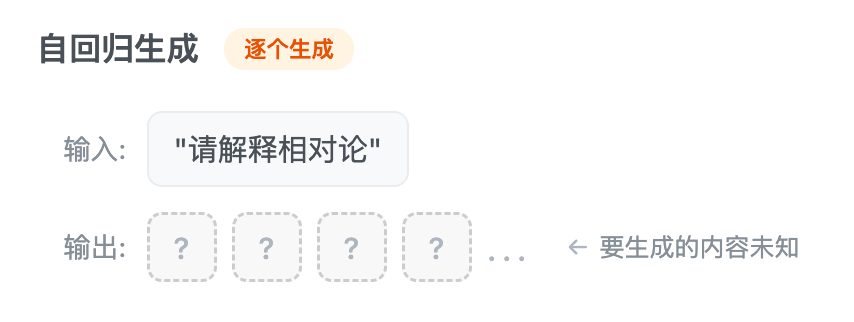
模型必须:
- 根据输入,生成第 1 个 token:"相"
- 把"相"加入上下文,生成第 2 个 token:"对"
- 把"相对"加入上下文,生成第 3 个 token:"论"
- ……
每个 token 的生成都依赖于前面所有 token。这就是自回归生成(Autoregressive Generation)——必须串行。
这也是为什么你看到 ChatGPT 一个字一个字往外"蹦"——它确实在一个一个生成。
思维链:用效率换准确性
思维链(Chain of Thought, CoT) 让这个串行过程更明显了。
对于复杂推理任务,一步到位容易出错;拆成多步、逐步推导,虽然慢,但每一步都更可控、更可验证。就像解数学题:直接写答案容易算错,列出推导过程反而更稳。
当你问 GPT 一个需要多步推导的问题时,它必须:
- 先想清楚第一步
- 等第一步输出后,才能开始第二步
- 第二步完成,才能进入第三步
- ……
每一步都像链条上的一环,被前一环"锁住",无法跳跃、省略或并行。
这就是为什么 DeepSeek/ChatGPT 要"自言自语"——它必须把推理过程逐步展开,一步一步算出来。你看到的那一大段"思考过程",就是思维链在顺序执行。
回答开头第三个问题:ChatGPT 要"自言自语",是因为推理必须串行(自回归生成),而思维链让模型把推理过程展开输出,所以你看到了一大段"思考过程"。
小结:训练与推理的并行化现状
云计算 | 无状态服务已成熟 | |
|---|---|---|
AI 训练 | 已被 Transformer 重塑 | |
AI 推理 | 仍是串行(自回归 + 思维链) |
那推理能并行化吗?这正是当前研究的前沿方向。
第三部分:推理并行化的探索方向
4. 底层原理:自包含
要让推理并行化,首先要理解一个关键原则:无记忆性(Memorylessness)。
什么是无记忆性?
通俗地说,一个任务具备"无记忆性",意味着:执行这个任务时,只需要当前的输入数据,不需要知道这些数据是怎么来的。
任务与它的"过去"完全解耦,成为一个自包含(Self-contained) 的功能单元。
用快递柜来理解自包含
想象你去快递柜取件。你需要什么?
- 一个取件码
你不需要知道:
- 这个快递从哪个城市发出
- 经过了几个中转站
- 快递员叫什么名字
- 包裹在柜子里放了多久
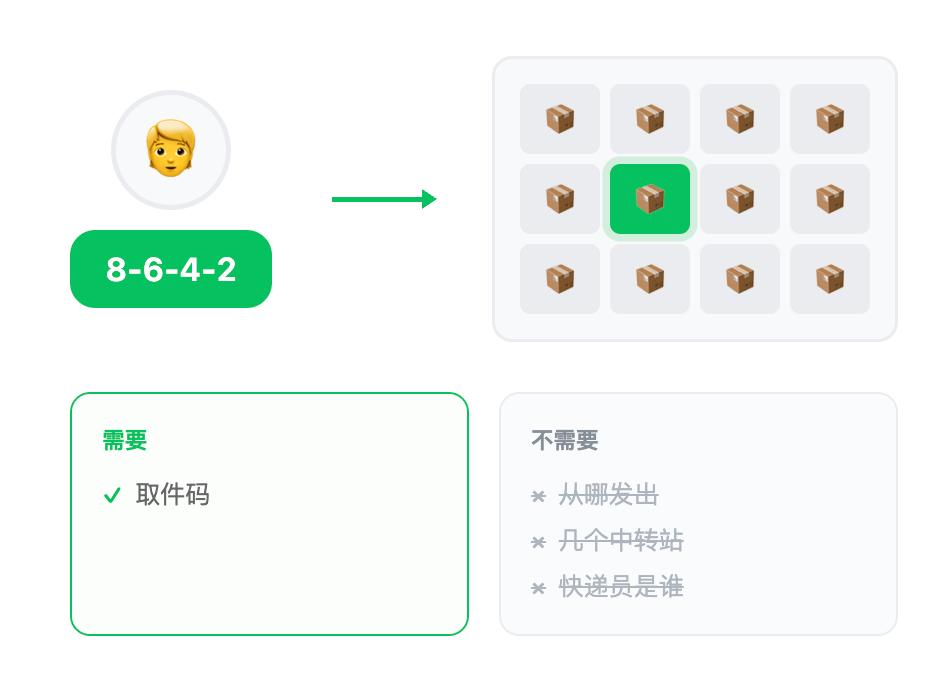
取件码就是"自包含"的全部信息。快递柜系统对你来说是"无记忆"的——它只关心取件码对不对,不关心包裹的"来龙去脉"。
为什么这对并行至关重要?
如果一个子问题是"自包含"的,那么:
- 它可以被分发给任意一个计算单元
- 接收任务的计算单元不需要加载历史状态
- 多个子问题可以同时被不同计算单元处理
- 计算单元之间不需要相互通信、同步
这就是大规模并行计算的根基:通过把任务设计成"自包含"的,打破顺序依赖的枷锁。
并行的本质不是"同时做很多事",而是"让每件事都不需要等别人"。
5. 方法论:从"链"到"图"
理解了"自包含"的原理,接下来的问题是:如何把一个复杂问题拆成多个自包含的子问题?
厨房里的并行烹饪
想象你要做一桌四菜一汤招待客人。顺序思维是这样的:
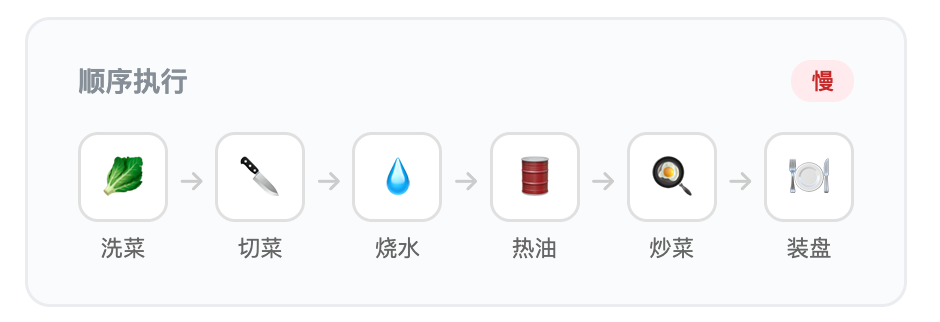
每一步都在等上一步。这就是链式依赖的代价:资源闲置,时间浪费。
但一个老练的厨师不会傻等,他会这样安排:
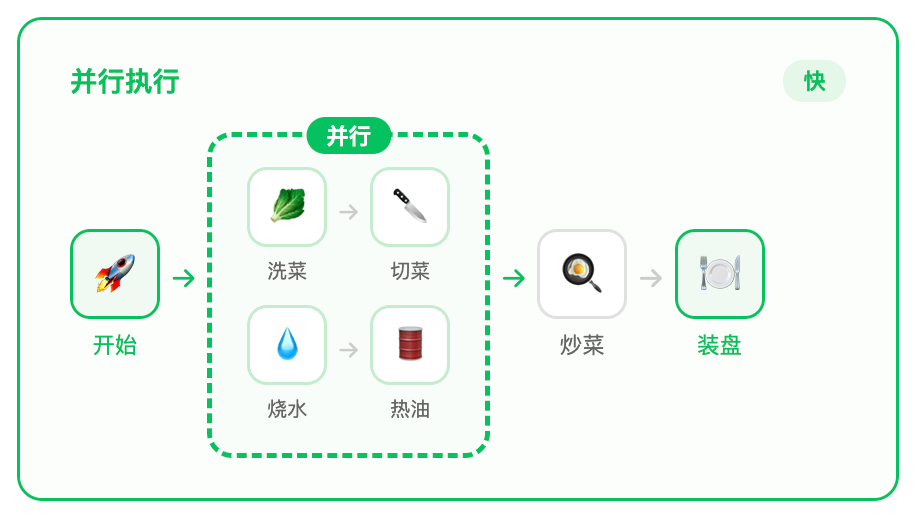
洗菜和烧水没有依赖关系,可以同时进行。切菜和热油也可以并行。只有"炒菜"这一步,必须等食材准备好、油也热了,才能开始。
这就是任务分解 + 依赖分析:
- 找出哪些任务是独立的(可并行)
- 找出哪些任务有依赖(必须等待)
- 让独立任务同时执行,只在必要时同步
AI 推理中的"分解收缩"
在 AI 领域,这种思路被称为分解收缩(Decomposition-Contraction)。主要步骤是:
- 构建依赖图:把复杂问题拆解成多个子任务,用有向图表示它们的依赖关系
- 并行求解独立节点:没有依赖的子任务,分发给多个计算单元同时处理
- 收缩更新:当一个子任务完成,把结果"喂"回图中,更新依赖它的任务
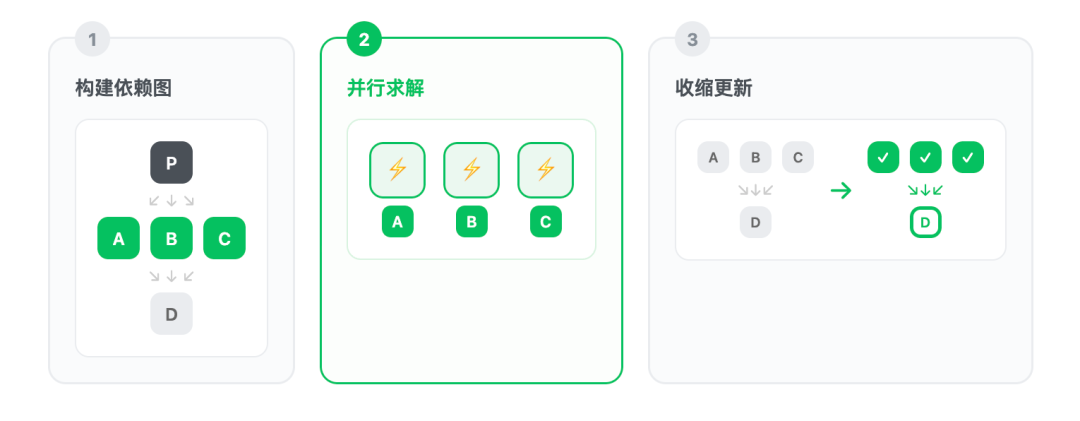
最关键的是收缩:当一个独立任务被解决后,整个问题图可以被"收缩"成一个新的、更简单的问题。这个新问题是自包含的——它包含了继续求解所需的全部信息,不需要再回溯历史。
并行的威力在于:一本书拆成 100 章,100 个计算单元同时干,耗时就接近只处理 1 章——前提是章节之间没有依赖。
思维链不是要被干掉的对象
所以思维链不是要被"消灭"的对象——并行化的目标是让多个独立的思维链同时跑,而不是消灭思维链本身。
每条思维链内部仍然是串行的,但多条思维链之间可以并行。
6. 前沿方向:让 AI 自己设计并行策略
掌握了"分解收缩"的方法论,视野自然会拓展到更大的命题:如何让 AI 自己分析任务依赖,自己设计并行策略?
想想我们现在怎么用 AI 写代码:
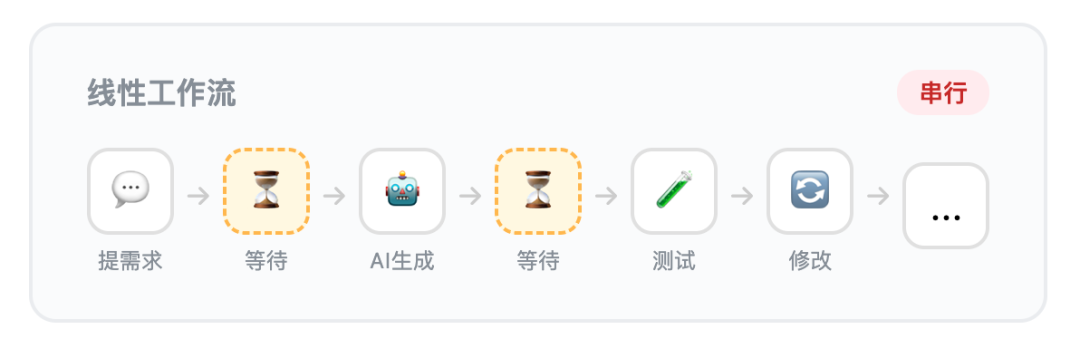
这个过程完全是线性的,每一步都在等上一步。
但如果 AI 能自己分析任务依赖,自己设计并行策略呢?
这就是智能工作流(Agentic Workflow) 的前沿方向:
- AI 分析任务,构建依赖图
- 识别哪些任务可以并行
- 自动尝试不同的执行策略
- 根据反馈迭代优化
实验结果很惊人:通过自动优化工作流,小模型在特定任务上的表现可以超越 GPT-4o,而推理成本仅为其 4.55%。(数据来源:《《AFLOW: Automating Agentic Workflow Generation》)
在《从 Demo 到生产:打造我的技术资讯 + 知识库 Agent》中,通过手动优化工作流,表现和成本也侧面佐证了上面的结论。
从 Demo 到生产:打造我的技术资讯 + 知识库 Agent
这体现了并行思维的终极应用——我们不仅并行化了任务的执行过程,更并行化了任务执行方式的设计过程本身。
第四部分:行动指南
7. 改变你的系统设计方式
说到底就三件事:拆开(搞清楚依赖关系)→ 自包含(每个任务只看输入,不管历史)→ 并行跑(能同时干的就同时干)。
从上下文丢失说起
你有没有遇到过:让 ChatGPT 处理一个复杂任务,前面几轮对话还正常,到后面它开始"忘记"之前说过的话,甚至自相矛盾?
这是上下文丢失的典型症状。
随着对话变长,任务变复杂,上下文窗口被塞满,早期的信息被挤出去或被稀释。模型"记不住"了。
但如果换一种思路:把任务设计成自包含的,每个子任务都携带它需要的全部信息,不依赖漫长的对话历史——那么 context 就不会随着任务膨胀,上下文丢失的问题自然消失。
一个问题
下次设计系统时,可以问自己:
这个任务能自包含吗?
如果能,自包含往往带来三个优势:
- 可扩展:更容易并行、更容易水平扩容
- 可容错:失败能重试,影响面更小
- 可维护:输入输出清晰,测试更好写
如果不能,可以尝试两种改法:
- 把隐含状态显式化:把"我以为你记得"的东西写进输入
- 切断长依赖链:把能提前准备的部分拆出去并行做
总结:把"等待"从系统里赶出去
从云计算到 AI 训练,从游戏架构到智能工作流,"解耦"与"并行"的思维模式正在改变整个技术世界。
这不仅是 AI 时代的效率密码,更是构建一切可扩展系统的底层逻辑。
在微信支付的复盘中,一个影响开发效率十分高频的词就是**"等待"**。
想想你手头最慢的那段流程——不管是写代码、写文档、做运营,还是其他什么——慢在"计算",还是慢在"等待别人/等待上一步"?你能把哪一段改成自包含?
- 并行的本质不是"同时做很多事",而是"让每件事都不需要等别人"。
- 无状态不是没有状态,而是把状态交给别人保管,自己轻装上阵。
- 自包含是解耦的终极形态:我只需要知道"做什么",不需要知道"来龙去脉"。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号