DMA 技术解析

DMA 技术解析

霞姐聊IT
发布于 2025-12-30 19:51:44
发布于 2025-12-30 19:51:44
DMA(Direct Memory Access 直接内存访问)是解放 CPU 数据搬运负担的核心技术,它凭借专用硬件模块实现了外设与内存的直接数据传输,彻底重塑了系统的 I/O 架构,是实现高速数据传输、提升系统整体性能的关键基石。
接下来,我们一起探寻一下DMA 技术的起源、核心原理,以及它在 Linux 内核中的实现框架吧。
一、技术起源
在DMA出现之前,外设与内存之间的数据传输需要CPU的全程参与,会占用大量CPU资源处理。而CPU的核心价值是执行应用程序、系统调度、复杂计算等高价值任务,让它去做重复性的数据搬运,好比让科学家去搬砖,太浪费了;
怎么将CPU从这个任务中解放出来呢?技术人员发明了DMA。
DMA 技术的思想可追溯至 1958 年 IBM 推出的大型机 IBM 709。在当时的大型机架构中,为缓解 CPU 在数据传输中的繁重负担,工程师首次引入了由专用硬件替代 CPU 完成内存与外设数据搬运的核心思路,这便是 DMA 技术的原始雏形。尽管当时尚未明确提出DMA这一术语,硬件模块也仅能支持简单的数据传输,但已奠定了DMA的核心逻辑。
而DMA这一术语真正走入大众视野、成为行业标准概念,则要归功于二十世纪七八十年代微型计算机的兴起与普及。彼时,个人计算机与工业控制微机快速发展,对 I/O 传输效率的需求日益提升,专门的 DMA控制芯片(DMAC)应运而生并广泛商用,最典型的代表便是 Intel 8237 DMAC 芯片。这类芯片被直接集成到微机主板中,作为独立的硬件单元负责管理各类外设(如软盘驱动器、声卡、串口)与内存的直接数据传输,彻底解决了早期微机中 CPU 被数据搬运占用的痛点。随着 DMAC 芯片在 Apple II、IBM PC 等经典微机中的大规模应用,DMA术语逐渐标准化,其技术原理也成为计算机体系结构中的基础知识点,被广泛认知与应用。
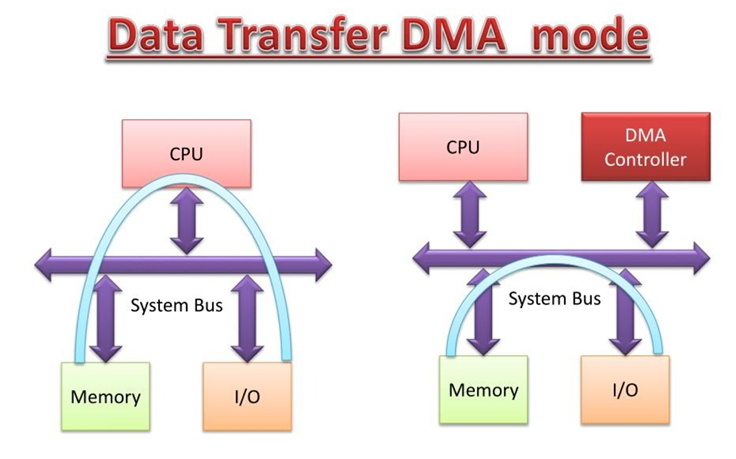
二、技术简介
DMA是一种数据传输机制,这种机制需要专门的硬件支撑。这种专门的硬件原先是专门的DMAC芯片,但技术发展到现在,除了嵌入式领域外,在服务器领域,几乎看不到单独的DMAC芯片了,因为它已经被集成到PCH芯片、NVMe SSD、高性能网卡内部,而这个集成的硬件模块也被称为DMA引擎。
没有DMA 时,CPU需逐字节读写,频繁处理中断;而有了DMA后,CPU只需要做三件事就好了:①初始化传输参数(源/目的地址、长度)、②启动 DMA、③处理传输完成中断;
而核心传输全程由DMA控制器独立完成,在此过程中,CPU可并行执行其它计算任务。
DMA有两种工作方式:Block DMA(传统的普通DMA)和Scatter-Gather DMA。
Block DMA一次DMA传输只能处理一个物理上连续的内存区域;
而Scatter-Gather DMA单次DMA传输可以处理多个物理上不连续的内存区域,这些不联系的内存区域用一个链表描述,DMA得到链表首地址后,会根据链表来传输下一块物理上连续的数据,直到传输完毕后。
Block DMA的硬件复杂度低,而Scatter-Gather DMA硬件复杂度会高一些。
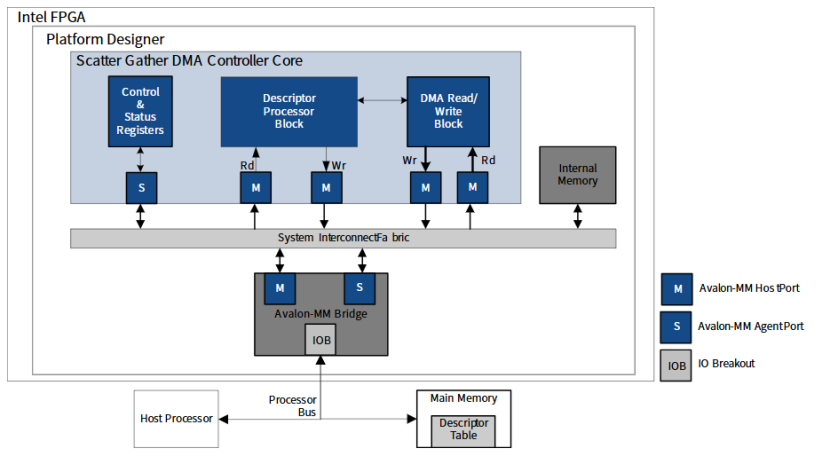
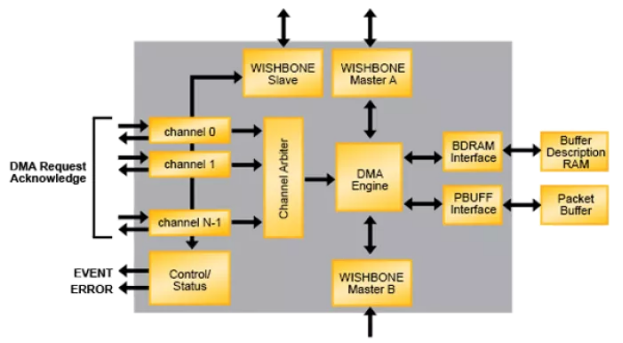
DMA使用channel(通道)来实现并行。每个通道互相独立,有自己的寄存器组,请求/响应逻辑、中断信号通路,可独立服务一个外设或一个外设的某类传输任务。另外,还可通过时间分片和上下文快速切换,实现虚拟通道技术,实现通道的更高效复用。
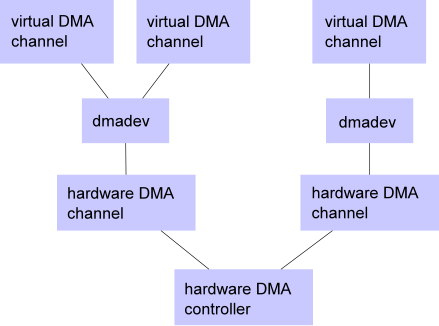
三、Linux内核中的DMA
Linux中有两类关键的DMA框架:DMA mapping和DMA Engine。
下图是这两类框架及上下游的关系示意图:
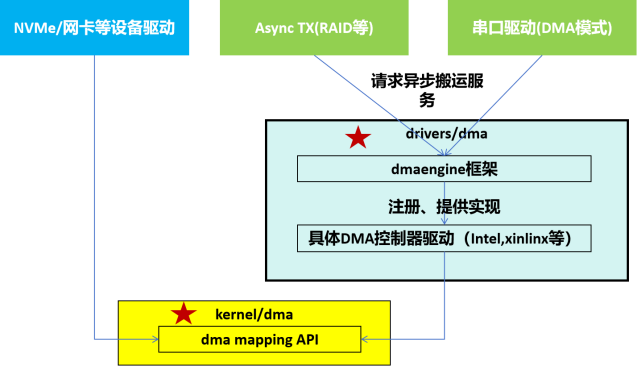
(1)DMA mapping
它的任务是为设备驱动准备一块设备能够直接、安全访问的内存,核心代码位于kernel/dma/ 目录。
CPU 使用虚拟地址访问内存,而 DMA 设备(如网卡、NVMe SSD)直接通过物理总线访问内存,只能识别总线地址,二者地址空间完全独立。如果没有 DMA mapping,DMA 设备会因为地址不识别而无法完成数据传输。
Linux 内核将 DMA mapping分为两大类,分别适配不同的传输场景。
(a)一致性映射(Coherent DMA Mapping)
一致性映射会分配一块同时被CPU 和 DMA 设备访问且数据一致的内存,内核保证该内存的缓存一致性:CPU 写入的数据会立即同步到物理内存,DMA读取的数据也是最新的;反之亦然。
接口有dma_alloc_coherent和dma_free_coherent等。
比如:NVMe SSD 的提交队列(SQ)和完成队列(CQ),它们长期存在且需CPU与NVMe SSD控制器频繁交互,必须保证数据一致性,就需要使用这种映射。
(b)流式映射(Streaming DMA Mapping)
流式映射不保证硬件/CPU缓存一致性,需要驱动程序在访问缓冲区之前刷新缓存,从而同步缓冲区。它适用于一次性数据传输(如文件读写、网络数据包收发)。在这种模式下,驱动程序在每次 DMA 传输前,动态地将一个已存在的内存缓冲区映射供 DMA 使用,并在传输结束后立即解除映射。
接口有dma_map_single、dma_unmap_single、dma_map_sg、dma_unmap_sg等。
比如,NVMe SSD 读写文件时,将碎片化的用户态缓冲区通过dma_map_sg 映射为DMA 地址列表,然后NVMe SSD的控制器的DMA引擎直接遍历其进行读/写。
一致性映射适用于长期、高频交互的缓冲区,流式映射适用于临时、批量的数据传输。
(2)DMA Engine
DMA Engine 是 Linux 内核中为传统外设 DMA 传输设计的通用抽象框架,核心目标是屏蔽不同厂商 DMA 控制器的硬件差异,为上层外设驱动(如网卡、声卡、串口驱动)提供统一的 DMA 操作接口,简化驱动开发并提升代码复用性。
它的代码实现位于内核源码的drivers/dma/ 目录下(而非 kernel/dma/)。
传统外设(如 SATA 控制器、UART 串口)本身不具备独立的 DMA 能力,必须依赖主机侧的通用 DMA 控制器完成数据传输。
但不同厂商(如Intel、ARM)的 DMA 控制器寄存器布局、传输模式差异显著,驱动适配工作量大;不同外设驱动的 DMA 事务管理逻辑(如队列调度、中断处理)高度相似,存在大量重复代码。
DMA Engine 提供统一的 API 接口、事务调度、通道管理、中断分发逻辑,外设驱动可调用 DMA Engine 提供的标准化 API,发起 DMA 传输请求,具体DMA 控制器驱动可通过DMA Engine提供的硬件适配层进行对接。
DMA始于一个简单的想法:将CPU从繁琐的搬运工角色中解放。如今DMA不仅是NVMe SSD实现微秒级延迟、网卡处理百万级数据包的关键,更是RDMA(远程直接内存访问)等技术得以实现的硬件基础。Linux内核中的DMA Mapping与DMA Engine框架,则是对这一硬件能力,兼顾性能、安全、易用性的优雅的软件抽象。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号