【ChiP-seq分析】超级增强子系列8: motif 富集分析工具XSTREME输出文件解释

【ChiP-seq分析】超级增强子系列8: motif 富集分析工具XSTREME输出文件解释

三兔测序学社
发布于 2025-12-29 12:55:27
发布于 2025-12-29 12:55:27
一、XSTREME分析结果中的文件类型

文件1:xstreme.TSV
文件2:xstreme.html,
文件3-4:streme_tomtom_out、meme_tomtom_out(Tomtom工具比对结果)核心文件
- xstreme.TSV/txt:XSTREME主程序输出的汇总结果,包含所有motif的综合统计信息(如E值、p值、匹配数等)
- xstreme.html: HTML格式的交互式报告,包含motif富集图、序列logo、统计表格等可视化内容。
2.meme输出文件与steme输出文件
- streme_out、meme_out:不同算法发现的motif序列及其统计信息,包含motif的PWM(位置权重矩阵)和显著性评估。
- streme_tomtom_out、meme_tomtom_out:Tomtom工具比对结果,显示新发现motif与已知motif数据库(如JASPAR、HOCOMOCO)的相似性。
3.fimo输出文件夹
- 功能:记录每个motif在输入序列中的匹配位置、p值、q值等统计信息。
- 用途:用于后续筛选显著匹配的motif位点,常用于可视化或进一步功能注释。
4.其他文件
消息日志文件
progress.log:记录分析过程中的关键步骤和时间戳,便于追踪分析进度和调试问题。sea_msgs.txt / streme_msgs.txt:分别记录SEA和STREME模块的运行日志,包含警告、错误或重要提示信息。
原始文件:Up.FASTA:输入的DNA序列文件,通常为ChIP-seq峰区域或启动子区域的FASTA格式序列。
中间文件与辅助文件
- background.txt:背景序列文件,用于计算motif匹配的统计显著性。
- combined.meme:合并后的MEME格式motif库,便于与其他工具兼容。
- messages.txt / motif_alignment.txt:分别存储程序运行消息和motif比对详情
二、单个文件介绍
1、XSTREME表格(xstreme.TSV)
表格是来自 motif 富集分析工具(如 XSTREME,STREME 或 MEME) 的输出结果,用于识别在一组 DNA 序列中显著富集的转录因子结合位点(motif)。下面是对每一列含义的详细解释:

列名解释
是否为“种子 motif”(即由 STREME 等工具从头发现的核心 motif)。- 1:是种子 motif(由 STREME 发现)- 0:不是种子 motif(可能是 MEME 发现的,或来自其他来源)举例说明
以第一行为例:
11 STREME 7-CTGCCTCAGCCTCC STREME-7 CTGCCTCAGCCTCC 144921.28E-1473.57E-161 db/.../JASPAR2024... MA1596.1 (ZNF460) https://jaspar...- 这是一个由 STREME 发现的种子 motif(SEED_MOTIF=1)
- 属于 cluster 1
- 共在 492 个位点中发现
- 富集极其显著(p = 1.28e-147)
- 与 JASPAR 数据库中的 ZNF460(MA1596.1) 高度相似
- 可点击链接查看 ZNF460 的详细结合谱
2、XSTREME网页结果(xstreme.html)
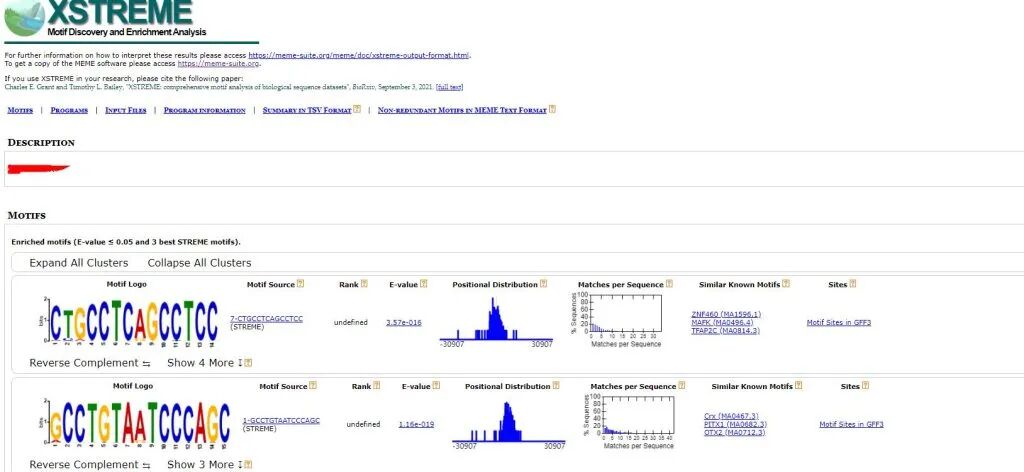
网页列名详细解释
列名 | 含义 | 说明 |
|---|---|---|
Motif Logo | motif 的序列标识图(Sequence Logo) | 可视化展示每个位置上 A/C/G/T 的偏好程度,高度越高表示该碱基越保守、越重要。 |
Motif Source | motif 来源 | - STREME:由 STREME 从头发现的新 motif- 若显示如 JASPAR:MA1516.2,则表示直接来自数据库(但此处应为 STREME 发现的) |
Rank | 排名 | 按富集显著性(通常按 E-value 或 p-value)排序,Rank 1 最显著。你提到“3 best STREME motifs”,所以这里只展示前 3 名。 |
E-value | 期望值(Expectation value) | 表示在随机数据中预期出现如此强富集的次数。E-value ≤ 0.05 被认为统计显著(即不太可能是偶然出现)。例如:E = 1e-10 → 极显著;E = 0.03 → 显著;E = 0.5 → 不显著。 |
Positional Distribution | 位点在序列中的位置分布图 | 显示 motif 在输入序列中的出现位置偏好。 |
Matches per Sequence | 平均每条序列中匹配到的 motif 数量 | 反映 motif 的普遍性。例如:0.8 表示约 80% 的序列至少包含 1 个该 motif。数值高说明广泛存在。 |
Similar Known Motifs | 与已知转录因子 motif 的相似性 | 通常是 TOMTOM 比对结果,格式如:MA1516.2 (KLF3) [q=0.02]表示该新 motif 与 JASPAR 中 KLF3 的结合谱高度相似,且 q-value = 0.02(显著)。这是功能注释的关键:告诉你“这可能是哪个 TF 的结合位点”。 |
Sites | motif在基因上的分布 | 在所有输入序列中,motif在基因上的分布 |
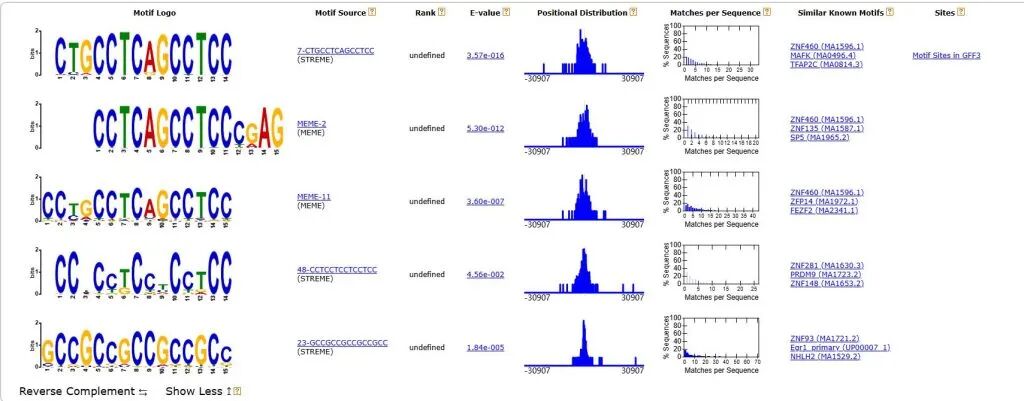
show more选项:一个motif可能有相似的motif序列,并且是来自MEME或者STREME分析结果,并按照E-Value值的显著性排列。并给出每一个类似motif的最相关的top3已知的转录因子motif。
3.TOMTOM页面解读
Tomtom的作用:已知 motif 数据库(如 JASPAR、HOCOMOCO)中的所有 motif 进行比对,找出最相似的已知 TF
在输出文件中,没有xstreme_tomtom_out文件夹,只有streme_tomtom_out、meme_tomtom_out两个文件夹,里面有TSV格式表格文件与html网页文件。网页文件如下
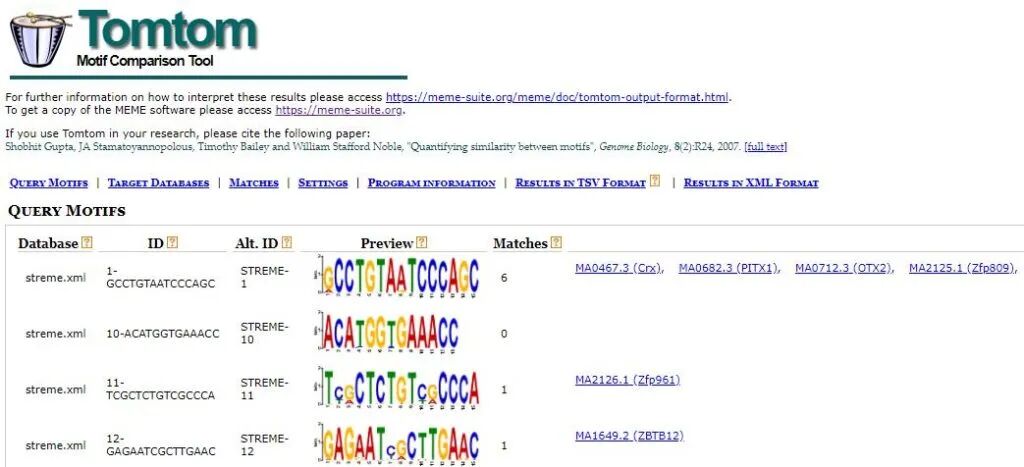
TOMTOM 工具结果界面的一部分。下面逐列解释这些字段的含义,并说明其在分析中的作用:
TOMTOM 结果列名详解
列名 | 含义 | 详细说明 |
|---|---|---|
Database | 查询所用的 motif 数据库名称 | 例如:- streme.xml:表示你将自己的 STREME 发现的 motifs 作为“数据库”进行比对(即 motif vs motif 自比)- 若为 JASPAR2024_CORE_vertebrates.meme,则表示比对的是 JASPAR 数据库 |
ID | 查询 motif 的 ID(Query Motif ID) | 这是你输入给 TOMTOM 的 query motif 的标识符。例如:1-GCCTGTAATCCCAGC 表示这是 STREME 发现的第 1 个 motif,其 consensus 序列为 GCCTGTAATCCCAGC。 |
Alt. ID | 查询 motif 的替代 ID(Alternative ID) | 通常是工具内部更简洁的命名,便于引用。例如:STREME-1 对应上面的 1-GCCTGTAATCCCAGC。 |
Preview | motif 序列 logo 预览(图形) | 在网页界面中会显示一个小的 sequence logo 图标,让你直观看到该 motif 的碱基偏好。 |
Matches | 匹配到的相似 motif 数量 | 表示该 query motif 在指定数据库中找到了 多少个显著相似的 target motifs。 |
List | 相似 motif 的列表 | 列出所有显著匹配的 target motif,格式为:数据库ID (转录因子名称)例如:- MA0467.3 (Crx) → JASPAR 中 Crx 转录因子的 motif- MA2125.1 (Zfp809) → 小鼠 Zfp809 的 moti 注意:虽然 Database 是 streme.xml,但这里的 MAxxxx.x ID 表明——实际上 TOMTOM 同时比对了外部数据库(如 JASPAR) |
问题1:SEA 和 TOMTOM 分析差异
在XSTREME文本结果中存在SEA(Site Enrichment Analysis) 相关列信息SEA_PVALUE,SEA和 TOMTOM 是 MEME Suite 中两个功能不同但互补的分析工具,它们回答的是不同类型的问题。下面详细解释它们的区别和联系:
1. SEA(Site Enrichment Analysis) —— 回答:
“这个 motif 在我的目标序列中是否显著富集(相比背景)?”
- 输入:一个已知或新发现的 motif(如 PWM/consensus)
- 目的:检验该 motif 在你的
目标序列集(如差异表达基因启动子)中出现的频率是否显著高于随机预期。
- 输出关键指标SEA_PVALUE:富集 p 值
EVALUE:校正后的期望值(考虑数据库大小等)- 本质:统计显著性检验(富集分析)
用途:判断某个 motif 是否可能在你的生物学背景下起调控作用。
2. TOMTOM —— 回答:
“我这个 motif 和数据库里哪些已知转录因子的结合谱相似?”
- 输入:一个 query motif(通常是新发现的 consensus 或 PWM)
- 目的:将它与已知 motif 数据库
(如 JASPAR、HOCOMOCO)中的所有 motif 进行比对,找出最相似的已知 TF。
- 输出关键列:
Target_ID:匹配到的数据库 motif ID(如 MA1516.2 = KLF3)p-value / E-value / q-value:相似性统计显著性Query_consensus vs Target_consensus:序列对比Overlap:比对上的碱基数Orientation:是否反向互补(-表示反向)- 本质:motif 相似性搜索
用途:给新发现的 motif 注释功能身份(比如“这很像 KLF3 的结合位点”)。
两者如何配合使用?典型工作流如下:
- STREME/MEME 从你的序列中 发现新 motif(如
GCCGGGCGTGGTGGC) - SEA 告诉你:这个 motif 在你的数据中高度富集(p ≈ 1e-145)→ 很重要!
- TOMTOM 告诉你:这个 motif 长得像 KLF3(MA1516.2)、SP3 等 → 可能是这些 TF 在调控!
所以:SEA 说明“它重要”,TOMTOM 说明“它是谁”。
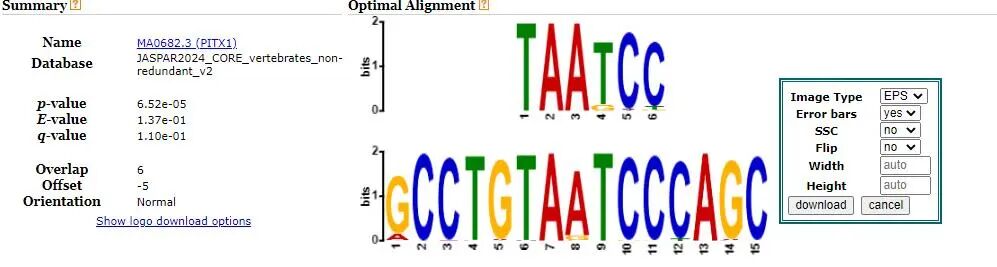
TOMTOM 结果为例:
Query | 匹配到 | Target_consensus | q-value | 解读 |
|---|---|---|---|---|
GCCGGGCGTGGTGGC | MA1516.2 (KLF3) | GGGCGTGGTC | 0.14 | 最佳匹配之一,但 q-value > 0.05,边缘显著.这些都属于 KLF/SP 家族,识别 GC-rich 序列.同样匹配 SP3、KLF6(MA1515.2)、KLF8(MA1517.2)等 |
注意:你的 query 是
GCCGGGCGTGGTGGC,核心是GGGCGTGG—— 典型的 KLF/SP 家族结合位点(如GGGGCGG或CCMCCC类型)。
虽然 TOMTOM 的 q-value(FDR 校正后)未达严格显著(通常 < 0.05),但由于多个 KLF 家族成员都给出相似匹配,且 SEA 富集极强,仍可合理推测 KLF 家族 TF(如 KLF3)可能参与调控。
总结对比表
特性 | SEA | TOMTOM |
|---|---|---|
目的 | 检验 motif 是否富集 | 比对 motif 与已知 TF |
问题 | “它重要吗?” | “它像谁?” |
输入 | motif + 目标/背景序列 | query motif + motif 数据库 |
输出重点 | p-value, E-value(富集强度) | p-value, q-value(相似性) |
依赖关系 | 独立分析 | 通常在发现新 motif 后使用 |
生物学意义 | 功能相关性证据 | 身份注释(TF 预测) |
补充说明
- 在 MEME Suite 中,STREME 默认会自动运行 SEA 和 TOMTOM,所以你会同时看到富集结果和匹配结果。
- 即使 TOMTOM 的 q-value 不显著,如果 多个相关 TF 都匹配,且 SEA 极显著,依然值得深入验证(如 ChIP、敲除实验)。
问题2:XSTREME文件中的SIM_MOTIF 和 TOMTOM 分析motif 哪一个更重要
XSTREME 的 SIM_MOTIF 和 TOMTOM 的结果都用于 motif 注释(即“这个新 motif 最像哪个已知 TF”),但它们的计算方式、用途和可靠性有所不同。
下面我将从 原理、可靠性、使用建议 三个层面帮你判断:到底该以哪个结果为准?
结论先行(快速参考)
优先看 TOMTOM 的结果,而不是 XSTREME 表中的
SIM_MOTIF。 因为 TOMTOM 是专门设计用于 motif 比对的工具,其统计更严谨、比对更细致;而 XSTREME 表中的SIM_MOTIF通常是简化版或快速匹配的结果,可能仅基于 consensus 序列字符串相似性,而非完整的 PWM(位置权重矩阵)比对。
详细对比
项目 | XSTREME 中的 SIM_MOTIF | TOMTOM |
|---|---|---|
目的 | 快速给出一个“最像”的已知 motif 作为参考 | 系统性地比对 query motif 与数据库中所有 motif |
比对基础 | 可能仅基于 consensus 序列 或粗略打分(取决于工具实现) | 基于 完整的 PWM(位置频率/权重矩阵) 进行动态规划比对 |
统计指标 | 通常无详细 p/q-value,或仅为近似值 | 提供 p-value、E-value、q-value(FDR 校正) |
方向性 | 一般不考虑反向互补 | 明确标注 Orientation(+ / -) |
重叠区域 | 不显示 | 显示 Overlap 长度 |
可靠性 | 较低(适合初筛) | 高(标准注释方法) |
是否可调参数 | 否 | 是(如 -dist pearson, -thresh, -min-overlap 等) |
举个实际例子
在 XSTREME 表中:
CONSENSUS: CCACCACGCCCGGCT
SIM_MOTIF: MA1516.2 (KLF3)
在 TOMTOM 表中(另一条 query):
Query: GCCGGGCGTGGTGGC
Match: MA1516.2 (KLF3), q-value = 0.14, Overlap=10, Orientation=-
虽然两者都指向 KLF3 (MA1516.2),但:
- XSTREME 的 SIM_MOTIF 没有告诉你
- 是否反向结合?
- 匹配区域多长?
- 统计是否可靠?
- TOMTOM 告诉你
- 是反向匹配(
Orientation = -) - 有 10 bp 重叠
- q-value = 0.14(虽未达 0.05,但结合其他 KLF 家族成员匹配,仍具提示意义)
- 是反向匹配(
所以 TOMTOM 提供了更全面、可评估的证据。
实际操作建议以 TOMTOM 为主要注释依据。尤其关注:多个同一家族 TF 都匹配(如 KLF3、KLF6、SP3),SEA 富集极强(p < 1e-50),生物学背景支持(如该 TF 在该组织表达) → 仍可视为候选调控因子
XSTREME 的 SIM_MOTIF 仅作快速参考:可用于:初步浏览时快速定位可能 TF与 TOMTOM 结果交叉验证(若一致,则更可信)。警惕假阳性匹配:GC-rich motif(如你的 CCACCACGCCCGGCT)容易匹配多个 KLF/SP 家族成员,因为它们识别相似序列。此时应:查看 TF 在你的实验系统中是否表达(RNA-seq 数据);查看 ChIP-seq 是否有结合证据(如 ENCODE、Cistrome DB)考虑做 motif 突变实验 验证功能
总结
问题 | 推荐做法 |
|---|---|
最终以哪个 motif 注释为准? | TOMTOM 结果 |
XSTREME 的 SIM_MOTIF 有用吗? | 有,但仅作初步参考或交叉验证 |
TOMTOM q-value 不显著怎么办? | 结合 SEA 富集强度 + 生物学背景综合判断 |
多个 TF 匹配同一个 motif? | 很常见(尤其 KLF/SP 家族),需结合表达和功能数据筛选 |
🔬 科研不止于工具,更在于思路。选择正确的工具,才能让数据说话。
【超级增强子系列文章】
超级增强子系列1:super enhancer鉴定-ROSE软件的安装与使用
超级增强子系列2:ROSE准备gff文件:peak 信息文件转化为9列gff格式文件R代码
超级增强子系列3:R语言批量处理ROSE文件生成SE与TE.bed文件
超级增强子系列5:用ChIPseeker进行超级增强子基因注释
超级增强子系列6:GREAT-基因组调控元件专业注释富集工具
如果你觉得这篇博文对你有帮助,请点赞、收藏、转发!支持我们持续输出优质内容!
关注“三兔测序学社”,获取更多实用教程与前沿解读。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号