LLM 系列(十八):注意力机制 Attention

LLM 系列(十八):注意力机制 Attention

磊叔的技术博客
发布于 2025-12-29 12:01:52
发布于 2025-12-29 12:01:52
NLP 的发展过程中,一直在解决这个核心问题:如何构建一个能够理解语言序列性与上下文依赖性的计算模型。在很长一段时间里,循环神经网络(RNN)及其变体长短期记忆网络(LSTM)和门控循环单元(GRU)被认为是解决这一问题的标准答案。
这些模型的设计思路受人类线性阅读习惯的影响非常大,它们按时间逐词处理输入,将前一个时刻的隐藏状态传递给当前时刻,试图在递归的过程中积累上下文信息。不过,这种听起来挺顺理成章的处理方式,其实恰恰成了限制大语言模型进一步发展的最大瓶颈。
序列递归处理带来了两个无法回避的问题:
- • 1、计算的不可并行化。由于当前时刻 的计算严格依赖于 时刻的输出,
GPU这种大规模并行处理的能力在面对 RNN 时显得无用武之地。在处理长序列时,这种串行依赖导致训练时间随着序列长度线性增长,极大地限制了模型规模的扩张和数据的吞吐量。 - • 2、长距离依赖的丢失。尽管
LSTM引入了门控机制来缓解梯度消失问题,但在处理长达数千甚至上万个Token的文本时,早期的信息在经过无数次非线性变换和矩阵乘法后,几乎不可避免地被稀释、扭曲甚至遗忘。当模型读到文章末尾时,往往已经无法准确回忆起开头的主语或关键实体,导致生成的文本在长程逻辑上出现断裂。
Transformer 架构的出现,标志着 NLP 领域从“序列递归”向“全局并行”的范式转移。其核心创新在于抛弃了递归结构,转而依赖 “注意力机制” 来捕捉序列中词与词之间的关系。在 Transformer 中,句子中的每一个词都可以同时 “看见” 句子中的所有其他词,无论它们在序列中的距离有多远。这种全局视野使得模型能够直接建立长距离依赖,将词与词之间的交互路径缩短为常数级 ,而不再受限于序列长度的 。
从序列到并行的转变,不仅仅是计算效率的提升,更是语义理解方式的质变。模型不再是被动地“记忆”过去,而是主动地在全局上下文中“搜索”相关信息。这一转变正是本篇中要深入拆解的 “注意力机制”。它不仅定义了现代 LLM 的基本工作方式,更引发了后续关于计算效率与模型性能之间长达数年的博弈与演进,从最初的 Multi-Head Attention (MHA) 到为了效率妥协的 MQA、GQA,再到 DeepSeek 提出的兼顾性能与效率的 Multi-Head Latent Attention (MLA) 。
一、 为什么需要“注意力”?
在探讨 Transformer 的技术细节之前,我们需要回答一个问题:为什么需要“注意力”?
人类的视觉系统是注意力机制的最佳体现。当我们观察一幅图像或阅读一段复杂文本时,我们的视线并非均匀地扫描每一个像素或每一个字母。

相反,我们会迅速将焦点集中在具有高信息量的区域,比如图像中的人脸、物体边缘,或者句子中的关键词汇,而将背景或其他无关信息模糊化处理。这种机制使人类能够从海量的感知输入中,以极低的认知成本筛选出最关键的信息,实现资源的优化配置。
在深度学习的早期 Encoder-Decoder 架构(如 Seq2Seq 模型)中,我们面临着严重的“信息瓶颈”问题。Encoder 负责将输入序列(如一句中文)压缩成一个固定长度的 Context Vector,Decoder 则基于这个向量生成输出序列(如对应的英文翻译)。这就好比要求一个人读完一整本小说后,只能用一个固定大小的便签纸记下所有内容,然后凭借这张便签纸复述出整本小说的细节。显然,对于长序列,固定长度的向量无法承载足够丰富的信息,导致生成质量随着序列长度增加而急剧下降。这种 Encoder-Decoder 的过程造成了巨大的信息损耗。
注意力机制的引入,打破了这个瓶颈。它允许 Decoder 在生成的每一个步骤,都能够 “回头看” Encoder 的所有输出状态,并根据当前生成的需要,动态地分配关注点。
具体来说,注意力的必要性体现在以下三个维度:
解决信息过载与瓶颈
允许模型在不同时间聚焦于输入序列的不同部分,注意力机制将“死记硬背”转变为“按需检索”。Decoder 不再依赖单一的上下文向量,而是拥有了访问整个输入历史,这样模型能够处理任意长度的序列而不必担心信息被压缩丢失。
建立精确的语义对齐
在机器翻译中,“Apple” 对应 “苹果”,这种对应关系往往跨越了语序的差异,注意力机制通过计算词与词之间的相关性分数,显式地对齐了源语言和目标语言的语义单元。这种对齐能力是处理复杂句法结构(如倒装句、从句)的关键,它让模型知道在翻译当前词时应该看原文的哪个位置。
赋予模型上下文感知能力
词义是流动的,“Bank” 一词在 “River bank” 和 “Bank account” 中具有完全不同的含义。若没有注意力机制,模型只能学习到 “Bank” 的平均含义。而有了 Self-Attention,模型可以通过观察 “Bank” 周围是 “River” 还是 “Account”,来动态调整其对 “Bank” 的向量表示。这种上下文感知是现代 LLM 能够进行复杂推理和生成连贯文本的基础。
因此,注意力是机器实现深度语言理解的一大创新,它将信息的处理方式从线性的流式处理,升级为网状的关系建模,为后续的大模型智能奠定了基础。
二、Q、K、V 到底在表示什么?
《Attention Is All You Need》 中最令人费解也最精妙的设计,莫过于将输入投影为三个向量:Query (查询)、Key (键) 和 Value (值)。这三个概念可以借用于计算机中的 数据库检索系统 来理解;为了理解注意力机制,我们必须先剥离它数学表示,深入到它的语义内核层面,详细阐述 Q、K、V 到底是什么,以及它们如何在向量空间中完成信息的交互与融合的。
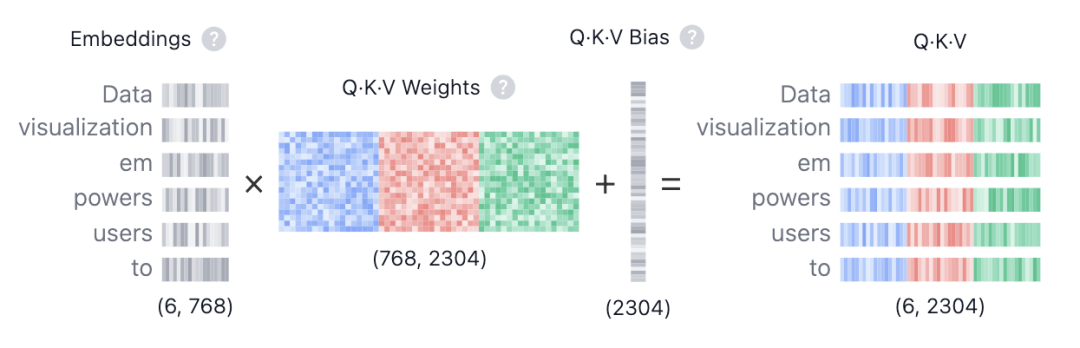
向量空间的语义角色定义
Self-Attention 层中,输入向量序列 (例如词嵌入加上位置编码)并不直接参与计算,而是首先通过三个独立的线性变换矩阵 、、 映射到三个不同的子空间。
对于序列中的每一个 Token,我们计算:
这三个向量分别扮演了完全不同的角色,构成了注意力机制的完整逻辑闭环:
Query (Q) :意图的发出者-“我在找什么?”
代表了当前 Token 的查询意图,它是一个主动的探针,携带着当前 Token 希望从上下文中获取什么信息的信号。
- • 语义理解:在句子
"The cat sat on the mat"中,当模型处理"sat"这个词时,它的Query向量可能会在向量空间中发出一种信号:“我在找动作的主体(谁坐?)和地点(坐在哪?)”。如果这是一个语法分析任务,Query可能会寻找名词短语;如果这是一个指代消解任务,Query可能会寻找之前出现的实体。 - • 数学视角: 是目标向量,它决定了注意力的方向,它是注意力函数的自变量之一,用于与环境中的
Key进行匹配。
Key (K) :特征的标识符-“我包含什么信息?”
代表了当前 Token 的特征索引。它是一个被动的标签,用于向外界展示该 Token 所蕴含的关键特征,以便与 Query 进行匹配。Key 并不直接提供内容,而是提供一种 可被检索的属性。
- • 语义理解:对于
"cat"这个词,其Key向量可能会编码 “我是名词”、“我是有生命物体”、“我是主语候选者” 等信息。当"sat"的Query扫描过来寻找动作主体时,"cat"的Key能够与该Query产生高响应。注意,Key的设计是为了响应Query,而不是为了表达完整的词义。 - • 数学视角: 是源向量的索引,它与
Query进行点积运算,决定了被注意的权重。
Value (V) :内容的承载者-“由于我被关注,我将贡献什么?”
代表了当前 Token 的实际内容。当 Query 与 Key 匹配成功后,Value 是真正被提取并传输的信息。Value 往往包含了 Token 的语义表示,甚至可能经过转换以适应后续层的处理。
- • 语义理解:如果
"cat"被"sat"成功关注,那么"cat"的Value向量(包含了“猫”的语义概念)就会沿着注意力权重传输给"sat",从而更新"sat"的表示,使其变为“猫坐”,Value可以看作是存储在记忆单元中的具体数据。 - • 数学视角: 是加权求和的内容,它决定了注意力的输出结果,最终的上下文向量是所有
Value向量的加权线性组合。
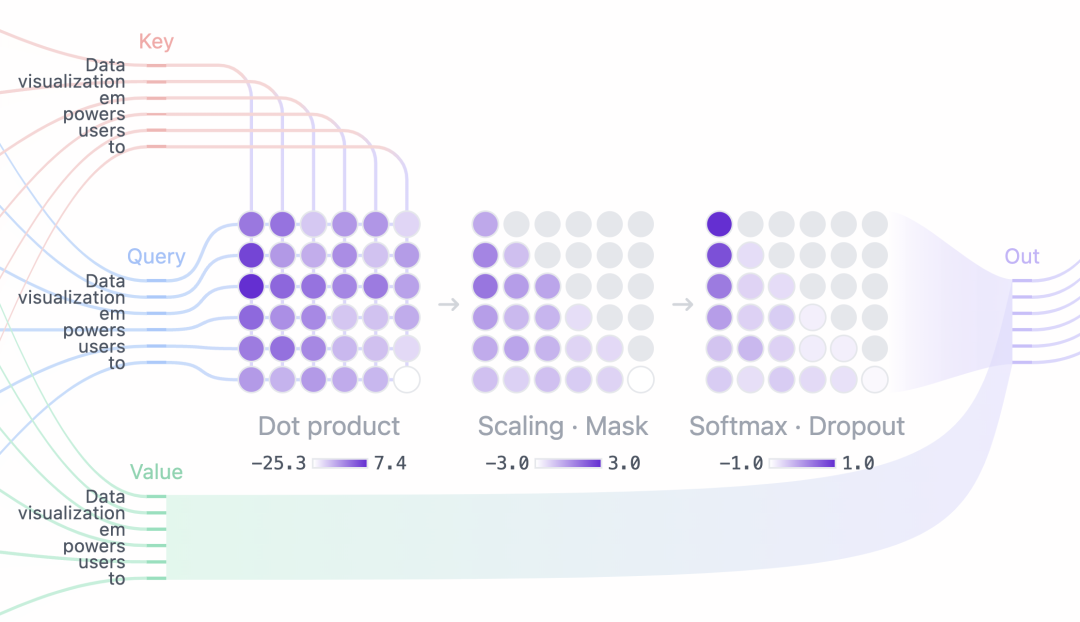
运作机制:从软寻址到信息融合
这三个组件的协作过程可以被看作是一个 软寻址 过程,它不同于哈希表的精确匹配(Key 必须完全相等),注意力机制执行的是基于相似度的模糊匹配,整个过程是完全可微的,因此可以通过反向传播进行训练。
整个过程可以细化为三个步骤:
第一步:计算相关性
模型计算当前 Token 的 Query 与序列中所有 Token 的 Key 之间的相似度,最常用的度量方式是缩放点积(Scaled Dot-Product) 。
- • 点积的几何意义:点积衡量了两个向量在方向上的对齐程度。如果 和 指向相似的方向(或在高维空间中具有正相关的特征激活),点积值就大。这意味着 所寻找的特征,正是 所具备的。
- • 为什么要除以 ?:在高维空间( 很大)中,点积的数值范围会随维度增加而剧烈扩大,如果不进行缩放,极大的点积值输入到
Softmax函数后,会推向梯度极小的饱和区(接近 0 或 1),导致反向传播时出现 梯度消失 。 将点积分布方差归一化,确保了训练的稳定性。
第二步:生成注意力权重(Attention Weights)
通过 Softmax 函数将原始分数转化为概率分布。
表示 Token 对 Token 的关注程度,所有 的权重之和为 1,这一步是一个去噪和聚焦的过程,过滤掉不相关的 Key,高亮匹配度高的 Key。
第三步:信息的加权聚合(Weighted Aggregation)
最后,利用计算出的权重对所有 Token 的 Value 进行加权求和,得到 Token 的最终输出。
这一步实现了信息的流动与融合。Token 不再是孤立的词,而是吸收了整个句子中相关部分信息的聚合体,这种聚合操作是排列不变的,因此 Transformer 需要额外的位置编码来保留序列信息。
为什么 Q、K、V 必须分离?
一个常见的疑问是:为什么不能直接用输入向量 既当 Q 又当 K 还当 V?即 ?
如果 ,这意味着一个词只能关注与它自身最相似的词(因为向量与自身的点积通常最大)。这会限制模型的表达能力。通过引入独立的投影矩阵 和 ,模型可以将输入映射到不同的子空间:
- • 学习将输入转换为“查询空间”的向量。
- • 学习将输入转换为“索引空间”的向量。
这种 不对称性 极其重要,它允许 “动词” 去关注 “名词”,允许 “代词” 去关注 “实体”,即使它们在原始语义空间中并不相似(例如 "it" 和 "robot" 并不相似,但在 "The robot fell because it..." 中,it 必须关注 robot)。Q 和 K 的分离打破了“相似性”的限制,建立了 “功能性” 的连接。
同理,V 的分离允许模型在提取信息时,可以提取与匹配特征不同的内容信息,提供了另一层特征转换的自由度。例如,Query 匹配的是 “语法属性”,但 Value 传输的是“语义内容”,这种设计赋予了 Transformer 强大的灵活性和泛化能力。
三、 从“单头”到“多头”
既然单个注意力机制能够捕捉词与词之间的关联,为什么我们还需要 “多头” 呢?
这就好比人类在思考问题时,需要从多个不同的角度切入,当我们理解一句话时,我们的大脑同时在处理多种关系:
- • 语法关系(如主谓一致、动宾搭配)
- • 语义关系(如指代消解、同义词关联)
- • 位置关系(如相邻词的修饰)
- • 情感色彩(如形容词对名词的修饰)
如果只有一个 Single-Head,模型只能提取出一种类型的相关性,所有这些复杂的关系被迫压缩到同一组权重中,必然导致信息的互相干扰和平均化。Multi-Head Attention 通过并行运行多组独立的注意力机制解决了这个问题。具体而言,我们将输入的维度 切分为 个头,每个头拥有自己独立的 投影矩阵,维度为 。
多头机制带来了两个优势:
1、扩展了模型关注不同位置的能力
在单头情况下,注意力往往由当前位置最强的某种关系主导(例如,只关注到了紧邻的词)。多头机制允许模型在同一时间步,一部分头关注局部邻居,另一部分头关注长距离的特定词。
2、提供了多个“表示子空间”(Representation Subspaces)
每个头可以独立学习一种特定的语义或句法关系。
- • Head 1 可能专门学习捕捉 “主语-谓语” 关系。
- • Head 2 可能专门学习捕捉“指代词-先行词”关系(解决
it指代谁的问题)。 - • Head 3 可能专注于捕捉时间状语。
多头注意力将高维向量空间切分成了多个正交的子空间,使得模型能够在不同的子空间中并行地寻找特征,极大地增强了模型的表达能力和鲁棒性。
四、 多头注意力实际上学到了什么?
Transformer 的架构设计初衷是为了解决序列处理的并行化问题,但这种高度冗余、多通道的机制在海量数据训练后,涌现出了令人惊讶的复杂行为。我们不再仅仅关注它 “能否工作”,而是深入到了机械可解释性(Mechanistic Interpretability)的层面。
Induction Heads
什么是归纳头?简而言之,它是一种能够执行 “前缀匹配与复制” 算法的注意力头。它的工作逻辑可以描述为:“我在当前的上下文中寻找,以前我在哪里见过当前的这个 Token?如果我找到了,我就看看它后面当时跟着的是什么 Token,然后我把那个 Token 复制过来作为现在的预测。”
这听起来像是一个简单的 Ctrl+C, Ctrl+V 操作(比如你看到一段文本里反复出现 “苹果 → 红色”,那么下次再看到 “苹果”,模型就可能直接猜 “红色”),但在神经网络内部,它是通过 双头电路 来实现的:
历史上下文: ... → A₁ → B₁ → ...
↑
│ (回顾头:B₁ 携带 A₁ 信息)
↓
新上下文: ... → A₂ → [?]
↑ ↑
│ └── 归纳头用 A₂ 作 Query
│ 找到携带 A₁ 特征的 B₁
└── A₂ ≈ A₁ → 触发匹配- • 第一步:记住 “谁在我前面” --> 回顾头(Previous-Token Head)
- • 发生在模型较浅的某一层(比如第
N层)。 - • 这个头的作用是:把前一个词的信息“悄悄塞进”当前词的表示里。
- • 处理到序列中的词
B时,回顾头会把前一个词A的信息(通过Key/Value)注入到B的向量中。 - • 结果就是:
B的内部表示不仅代表自己,还“携带”了 “我前面是 A” 这个上下文线索。
- • 发生在模型较浅的某一层(比如第
- • 第二步:找到 “上次
A后面是什么” --> 归纳头(Induction Head)- • 发生在更深的一层(比如第
N+1层)。 - • 当模型再次遇到
A,并要预测下一个词时,归纳头就开始工作:- • 它用当前的
A作为 Query,去搜索整个上下文中有没有“和A配对过”的位置 - • 由于第一步中,历史上
A后面的那个词(比如B)已经 “背上了A的照片”(即包含了A的特征),所以归纳头能通过特殊的注意力匹配(称为Q-Composition和K-Composition)精准定位到那个B - • 一旦找到,它就把
B的内容(Value)提取出来,大幅提高B在预测结果中的概率
- • 它用当前的
- • 发生在更深的一层(比如第
这种机制解释了两个现象:
- • 1、重复模式的学习:模型能轻松处理像
“A B A ?”这样的序列,并正确填出“B”。 - • 2、少样本学习(Few-Shot Learning):当你给模型几个 “问题 → 答案” 的例子(比如 “法国首都是?→ 巴黎”、“日本首都是?→ 东京”),它并不是真的“理解”了地理知识,而是通过归纳头识别出 “问句结构 → 答案” 的重复模式,并套用到新问题上。
换句话说,模型的 “聪明” 并非来自推理,而是来自对上下文中共现模式的高效记忆与复用。而归纳头,正是实现这一能力的核心技术。
位置与距离的动态编码
虽然 Transformer 抛弃了 RNN 的序列结构,但它并没有忽视位置信息,这块我在 LLM 系列(十五):Positional Encoding篇中有过介绍,感兴趣的读者可以详细阅读。
- • 局部卷积行为:在浅层网络中,可以观察到大量的注意力头退化为类似卷积神经网络的行为,仅关注当前
Token的前一个或后一个位置,这说明在处理低级语言特征(如词组搭配、分词)时,局部性依然是最有效的归纳偏置。 - • 稀疏路由:随着层数加深,注意力模式变得越来越稀疏。
Softmax函数虽然理论上给所有Token分配非零概率,但实际上,许多深层头会将99%的权重集中在 1 到 2 个特定的Token上,而对其他Token视而不见。这说明多头注意力实际上演化成了一种 路由网络,也就是说每个头都是一个特定功能的专家,只有在遇到特定的触发条件(如特定句式、特定实体)时才会被激活并传输信息。
综上所述,多头注意力机制并不是一个均质的 “浆糊”,而是一个高度分工、层级分明的机器;它底层处理局部关系,中层搬运历史信息构建归纳回路,高层则进行复杂的语义路由和指代推理。这些复杂的行为,都是为了最小化预测误差而自组织形成的。
五、 从 MHA 到 MLA
Transformer 的核心是注意力机制,但随着模型规模从 BERT 的 1.1 亿参数迈向 GPT-4 级别的万亿参数,以及上下文长度从 512 扩展到 128k 甚至 1M,标准的 多头注意力(Multi-Head Attention, MHA) 就暴露出了问题:推理时的显存占用与带宽瓶颈。
在 LLM 的自回归生成(推理)阶段,为了避免重复计算,会将之前所有 Token 的 Key 和 Value 向量缓存起来,这就是我们熟知的 KV Cache。
对于一个 层、隐藏维度 、头数 (每头维度 )的模型,当上下文长度达到 时,KV Cache 的显存占用(以 FP16 为例)为:
随着 Batch Size 和序列长度 的增加,KV Cache 会迅速吃掉数十 GB 甚至上百 GB 的显存,从而导致显存带宽饱和。GPU 不是在算得慢,而是在等数据搬运。
MHA(Multi-Head Attention)
MHA 是 Transformer 的原始形式,也是我们理解后续变体的基准。
- • 机制:它赋予每个注意力头独立的 矩阵, 个头,就有 组独立的 Q、K、V。
- • 优点:表达能力最强,正如前面所分析的,每个头可以自由捕捉不同的句法或语义特征,互不干扰,形成了丰富的特征子空间。
- • 瓶颈:
KV Cache极大,每个头都需要存储自己独立的K和V。例如,对于一个70B参数的模型,如果使用MHA,仅KV Cache就可能占据超过 100GB 的显存(取决于Context Window),这极大地限制了最大Batch Size,从而限制了推理吞吐量。
MQA(Multi-Query Attention)
为了解决 MHA 的显存问题,Noam Shazeer 等人在 2019 年提出了 MQA。
- • 核心创新:既然
Query是负责“提问”的,需要多样性来捕捉不同的关系;而Key和Value是被检索的“资料”,是不是可以共享?MQA让所有的注意力头 共享同一组Key和Value矩阵(即 只有一组),但保留多组 。 - • 结构变化: 个 Query 头,对应 1 个
Key头和 1 个Value头。 - • 效果:
KV Cache的大小瞬间缩小了 倍(通常是 8 倍或 16 倍),极大地降低了显存占用,使得在相同硬件下可以支持更大的Batch Size,推理速度提升显著。 - • 代价:性能大幅退化,强行让所有头共享同一套
K和V,相当于强迫模型在所有语义子空间中使用完全相同的“资料库”。例如,一个头想查语法关系,另一个头想查语义关系,但它们只能查同一本 “字典”,这严重削弱了模型捕捉复杂细节的能力,且训练往往不稳定。
GQA(Grouped-Query Attention)
鉴于 MQA 的性能损失太大,Llama 2 和 Llama 3 等主流开源模型采用了 GQA 作为折中方案。
- • 核心创新:
GQA是MHA和MQA的插值。它不让所有头共享一组KV,而是将Query头分成 个组,每组内的Query共享一对K 和 V。 - • 结构变化: 个
Query头,对应 个Key/Value头()。例如,64 个Query头,分成8组,每组8个Query共享 1 个 KV,总共有 8 对 KV。 - • 效果:
KV Cache压缩率为 ,GQA成功地在MHA的高质量和MQA的高速度之间找到了平衡点;它保留了足够的KV多样性以维持性能,同时显著减少了显存占用。
MLA(Multi-Head Latent Attention)
尽管 GQA 表现出色,但它仍然是一种 “丢弃信息” 的有损压缩(减少了 KV 的头数)。DeepSeek-V2 和 V3 引入的 MLA (Multi-Head Latent Attention) 则代表了另一种维度的创新:通过低秩投影(Low-Rank Projection)在保持多头能力的同时,实现比 MQA 更极致的压缩。
MLA 的核心创新点在于它不再通过减少“头数”来压缩,而是通过压缩“向量维度”并利用低秩恢复技术,实现了 性能优于 GQA,显存占用甚至少于 MQA 的奇迹。MLA 由两大核心技术构成:
1、低秩键值联合压缩(Low-Rank Key-Value Joint Compression)
在标准 MHA 中,KV Cache 存储的是高维的 和 向量。MLA 认为,这些高维向量中存在大量冗余。因此,MLA 不直接存储 和 ,而是将它们压缩进一个低维的 潜在向量(Latent Vector) 中。
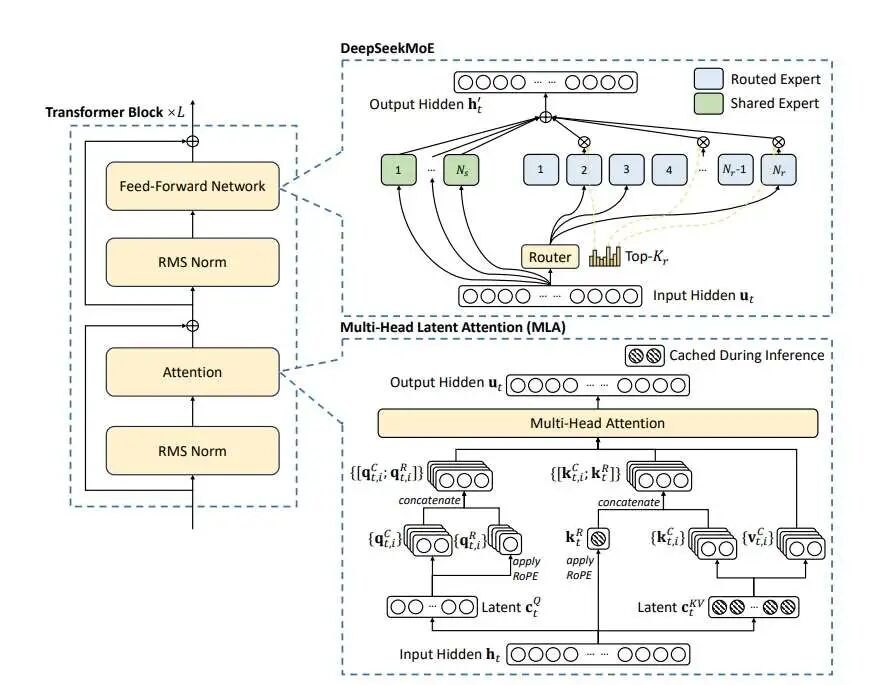
具体过程如下:
a、压缩(Down-Projection)
将输入隐藏状态 投影到一个低维的潜在空间 :
其中 的维度 远小于标准的 。在推理时,我们只缓存这个极小的 向量。
b、解压(Up-Projection)与矩阵吸收
理论上,计算注意力分数时,模型需要将 投影回高维空间,生成每一个头所需的 Key 和 Value
MLA 的精妙之处在于矩阵吸收(Matrix Absorption),由于矩阵乘法具有结合律,我们在推理时不需要显式地恢复巨大的 矩阵。我们可以将解压矩阵 整合到 Query 的投影矩阵中,将 整合到输出矩阵 中,这意味着,虽然我们在数学上拥有 个独立的头,但在物理存储上,我们只需要存储极小的 。
这种方法的精髓在于:用计算换显存;通过存储高度压缩的 ,而不是解压后的 ,MLA 实现了极致的显存效率。
可以参考这篇知乎文章来理解 https://zhuanlan.zhihu.com/p/716976304,同时也推荐各位直接阅读原论文 https://arxiv.org/pdf/2405.04434
2、解耦旋转位置编码(Decoupled RoPE)
RoPE 的核心机制依赖于高维、完整且结构化的向量空间来维持相对位置信息,但是低秩压缩会破坏这种精细的几何结构,导致位置编码失效或严重退化,DeepSeek 的解决方案是 Decoupled RoPE(解耦 RoPE):将 Key 向量一分为二。
- • 内容部分(Content Part):承载语义信息,不加
RoPE,参与低秩压缩,这部分进行完全的极致压缩,对应上述的 。 - • 位置部分(RoPE Part):承载位置信息,单独生成一个携带
RoPE的小向量 ,这个向量很小(例如 64 维),且所有头共享。
最终的 Attention 计算中,Query 也被对应地拆分为 “内容 Query” 和 “位置 Query”。
- • 内容
Query与 压缩恢复后的Key进行交互(主要贡献语义分数)。 - • 位置
Query与 共享的RoPE Key进行交互(主要贡献位置分数)。
两者相加得到最终的 Attention Score。
下表总结了四种注意力机制的关键指标对比:
机制 | 显存占用 (KV Cache) | 性能 (Performance) | 代表模型 | 核心特征 |
|---|---|---|---|---|
MHA | 极大 () | 最优 | GPT-3, BERT | 独立 Q, K, V,显存杀手 |
MQA | 极小 () | 较差 (细节丢失) | Falcon, ChatGLM2 | 共享 K, V,激进压缩 |
GQA | 中等 () | 良好 (平衡) | Llama 2/3 | 分组共享,当前主流 |
MLA | 极小 () | 最优 (无损多头) | DeepSeek-V2/V3 | 低秩压缩 + 解耦 RoPE |
MLA 的出现标志着注意力机制的设计进入了一个新的阶段:从单纯的结构剪枝(如 MQA/GQA 简单粗暴地减少头数)转向了更深层的数学变换与压缩(低秩分解 + 解耦编码)。
六、讲清楚你听到的那些“注意力”
在大模型的世界里,“注意力” 常被提起,但种类繁多,容易混淆。其实,它们大致可分为两类:注意力机制本身,以及 提升其效率的工程技术。
最基础的是 标准自注意力(Scaled Dot-Product Attention),它通过计算词与词之间的相关性,动态决定每个位置该关注哪些上下文。然而,它的计算和显存开销随序列长度平方增长(O(n2)),难以处理长文本。
为此,业界提出了多种优化方案,例如 稀疏注意力(如 Longformer)只计算局部或关键位置的关联;线性注意力(如 Performer)则用数学近似将复杂度降至 O(n),适合超长序列,但会牺牲一定精度。
而真正改变游戏规则的,是两类 不改变模型结构、只优化计算过程 的高效实现:
- • FlashAttention:通过智能分块和
GPU片上内存调度,在不损失精度的前提下,大幅加速计算并减少显存占用,它已成为现代大模型训练和推理的标配。 - • PagedAttention:由
vLLM团队提出,灵感来自操作系统的 “虚拟内存分页”。它将Key-Value缓存划分为固定大小的“页”,按需加载,避免内存碎片。这使得GPU能更高效地服务多个并发请求,并显著提升吞吐量。
需要注意的是,FlashAttention 和 PagedAttention 并非新的注意力机制,而是让 已有注意力跑得更快、更稳、更省资源 的关键技术。前者优化单次计算,后者优化内存管理与批处理。
总之,当我们谈论 “注意力” 时,既要分清是 算法创新(如稀疏、线性),也要识别 工程突破(如 FlashAttention、PagedAttention)。正是这些技术的协同,才让大模型既能理解万字长文,又能实时响应用户请求。
7、总结
本文系统梳理了注意力机制在大语言模型中的核心作用及其技术演进路径。从序列建模的历史背景出发,引出 Transformer 通过注意力机制实现了对全局上下文的并行建模,突破了传统 RNN 在长程依赖与计算效率上的结构性限制。注意力机制本质上是一种基于 Q、K、V 的可检索过程,使模型能够在上下文中动态选择并融合关键信息。
多头注意力通过并行的表示子空间,它提升了模型对不同语义关系的刻画能力,并在训练过程中自然形成具备不同功能分工的注意力头结构。这一机制为上下文理解、信息路由与泛化能力提供了重要支撑。随着模型规模和上下文长度不断扩大,注意力机制的瓶颈逐渐转向显存与计算开销,多头结构也随之演化出 MQA、GQA、MLA 等更高效的变体,以在性能与资源消耗之间取得平衡。
同时,FlashAttention 等工程级优化手段从实现层面释放了注意力机制的计算潜力,使其在大规模训练与推理场景下具备可行性。整体来看,注意力机制既是大模型能力提升的理论基础,也是推动其工程落地的关键支点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号