如何更好的应用AI辅助写作06-从RAG到Agentic RAG的实践方法论参考

如何更好的应用AI辅助写作06-从RAG到Agentic RAG的实践方法论参考

人月聊IT
发布于 2025-12-29 11:09:51
发布于 2025-12-29 11:09:51
大家好,我是人月聊IT。
今天继续聊AI辅助写作的内容核心还是重新归纳整理下我前面谈过的基于AI辅助工具,将RAG转化为Agentic RAG或FullText Research模式的智能AI辅助写作实践。
这篇文章详细探讨了AI智能知识库从传统RAG(检索增强生成)向Agentic模式演进的技术路径。个人通过实战对比发现,利用Claude Code等工具直接访问完整Markdown文件系统的效果显著优于碎片化的向量检索,能更好地保持文章的逻辑连贯性与个人写作风格。同时文中深入解析了Agentic RAG与GraphRAG的内在逻辑,强调了任务规划、多轮动态检索及自我验证在高质量内容生成中的核心作用。
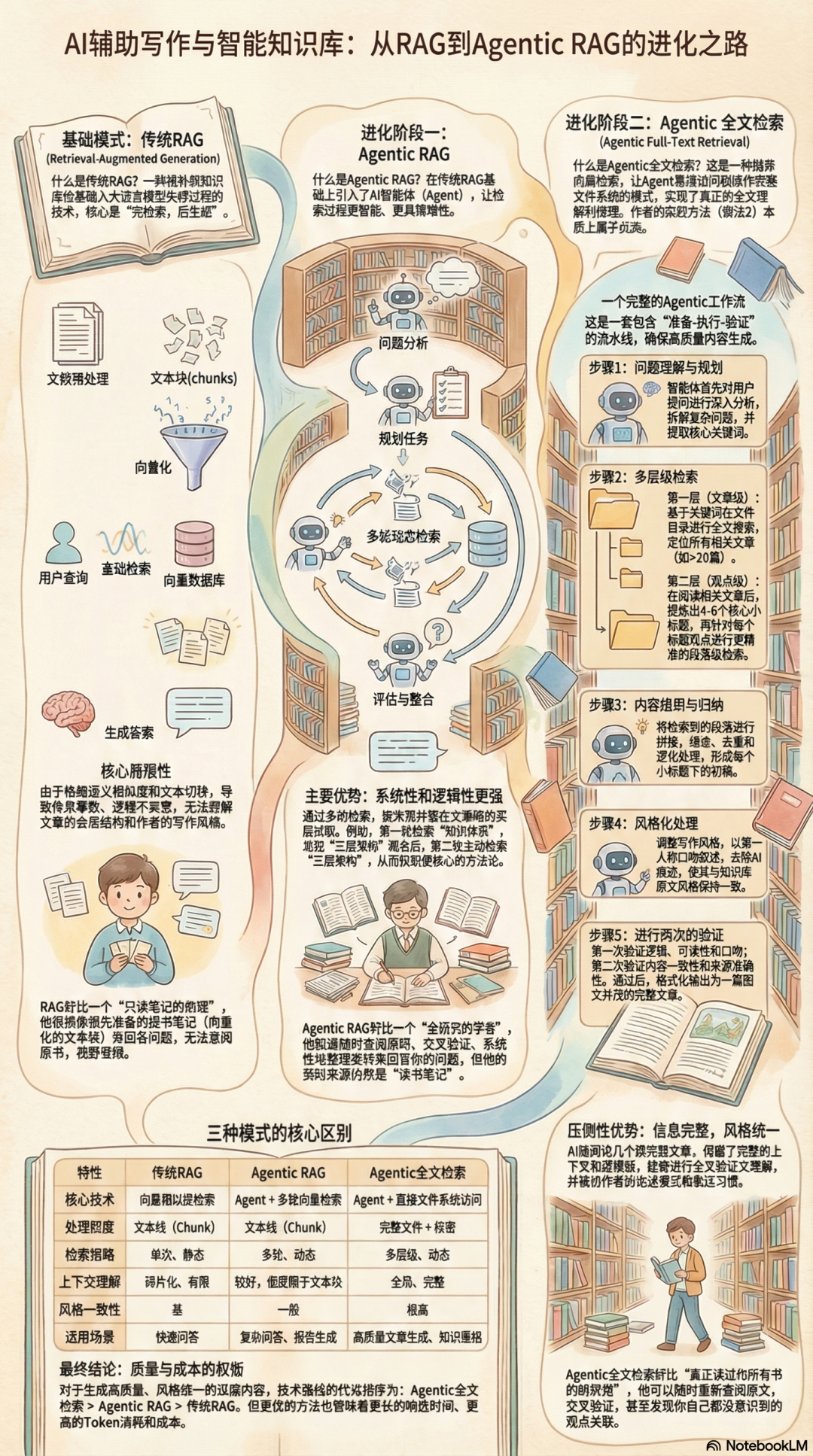
引言:超越传统RAG,迈向智能内容合成
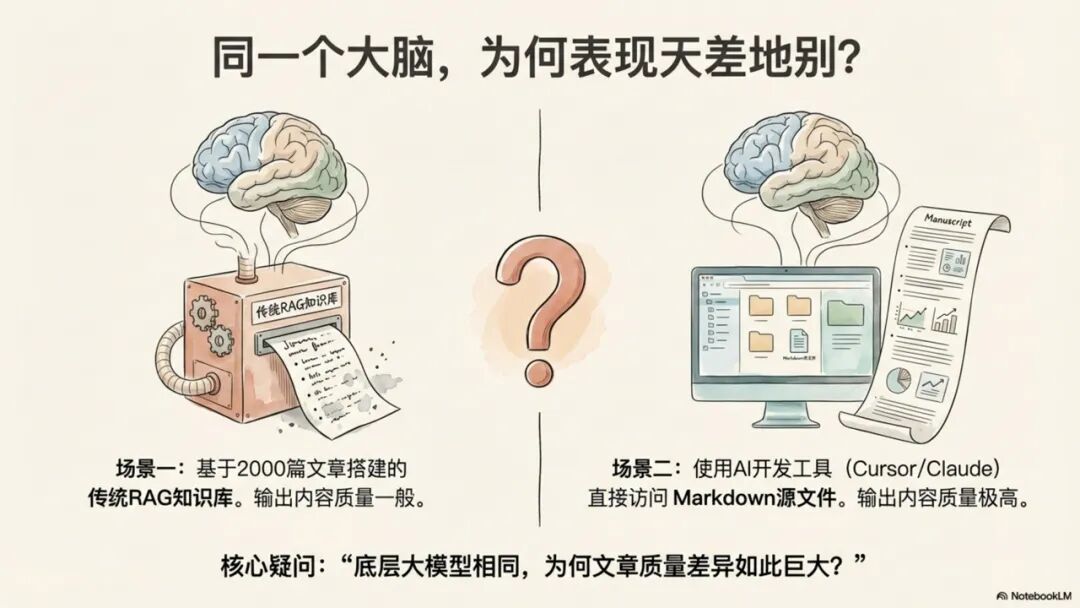
在当今信息爆炸的时代,严肃的知识工作者与内容创作者正寻求一种能将AI从简单的“问答工具”转变为真正的“智能伙伴”的方法。我们期望AI能深度理解并整合我们毕生积累的知识,辅助生成长篇、风格统一且逻辑严谨的深度内容。然而,传统的基于检索增强生成(RAG)的系统在此类高级任务面前显得力不从心,其输出往往是零散观点的拼凑,缺乏灵魂与深度。
这一瓶颈源于传统RAG的架构性缺陷。它依赖语义相似度进行被动的、片段化的信息检索,这种Chunking(分块)机制天然地破坏了原文完整的逻辑链。AI如同一个只能翻阅零散笔记卡片的助理,无法全局性地理解作者深层的知识体系、独特的论证结构与写作风格。因此,它只能“检索”,而无法真正地“合成”。
本文并非又一篇RAG的综述,而是一份用于构建真正AI赋能的智能伙伴的实践蓝图。我们将阐述一种基于“智能体(Agent)”和“全文访问(Full-text Access)”的全新范式,旨在提供一套系统且可复现的操作指南,帮助您构建一个能够实现高质量内容“合成”(Synthesis)而非简单“检索”(Retrieval)的AI辅助写作系统。下文将从核心理念、知识库构建、智能引擎设计、指令工程和验证机制五个核心方面,逐一展开论述。
1. 核心理念:从“被动检索”到“主动合成”的范式革命
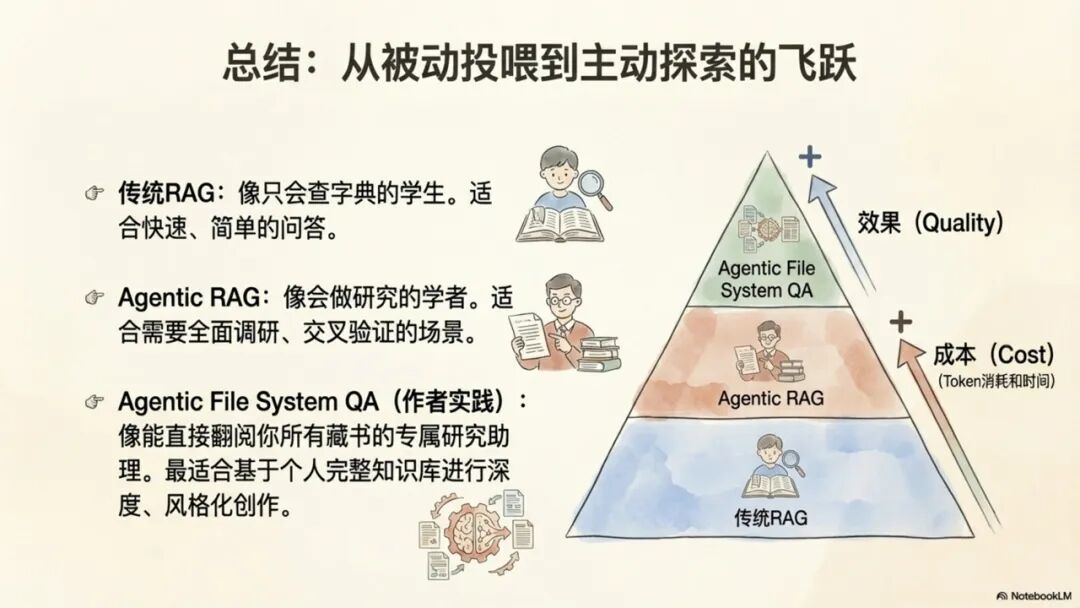
成功实施本方法论的基石,在于深刻理解其背后的核心理念。本章节将深入剖析四种截然不同的技术范式——传统RAG、智能体RAG(Agentic RAG)、图谱RAG(GraphRAG)以及本方法论所采用的“智能体文件系统问答”(Agentic File System QA),以揭示其根本差异和演进路径。
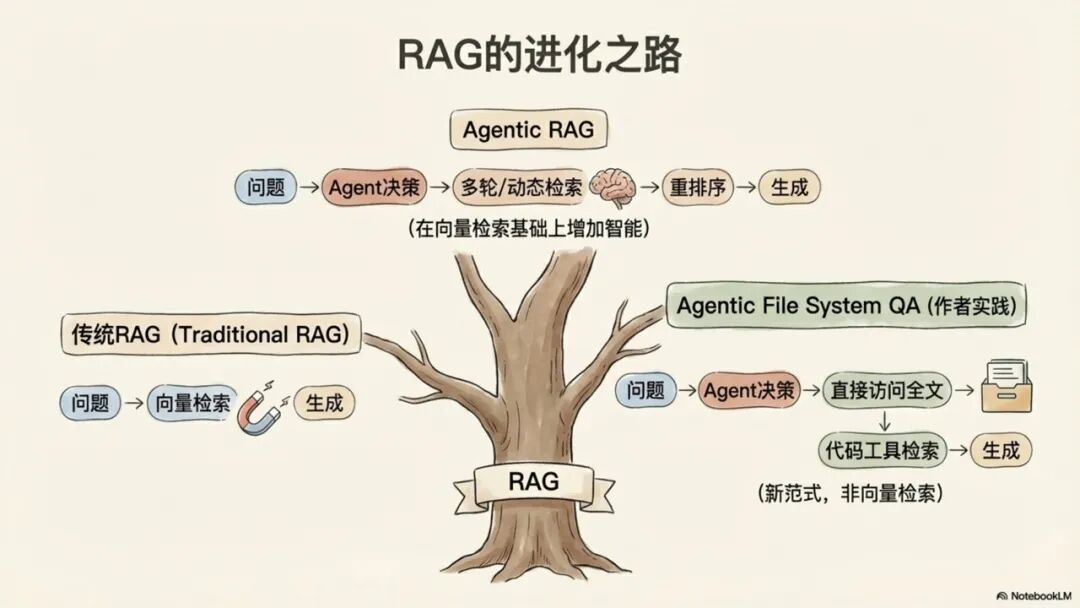
1.1 范式一:传统RAG(Retrieval-Augmented Generation)——信息检索的基石与局限
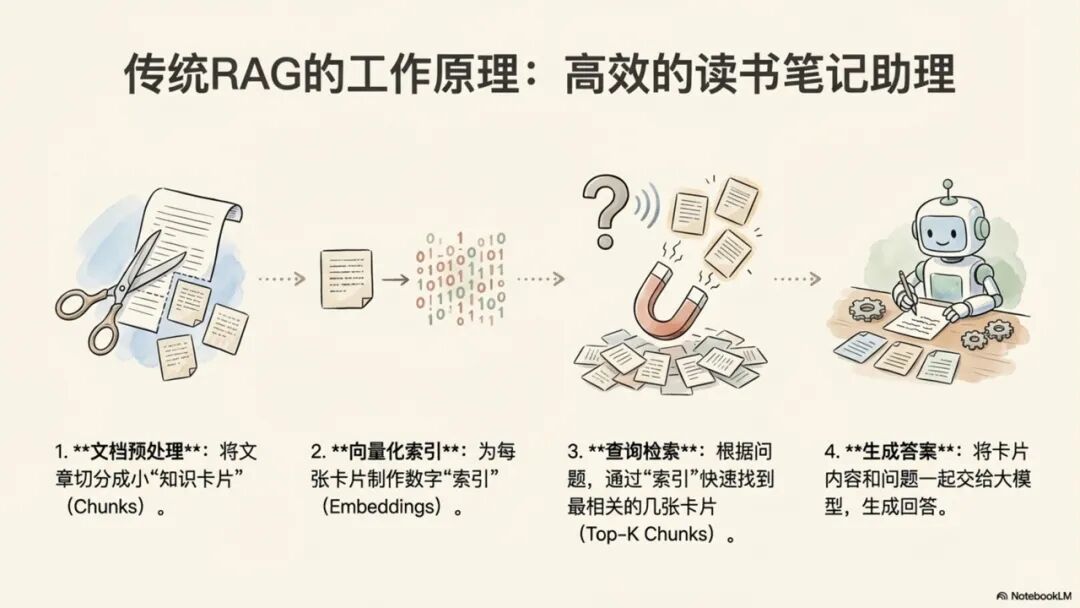
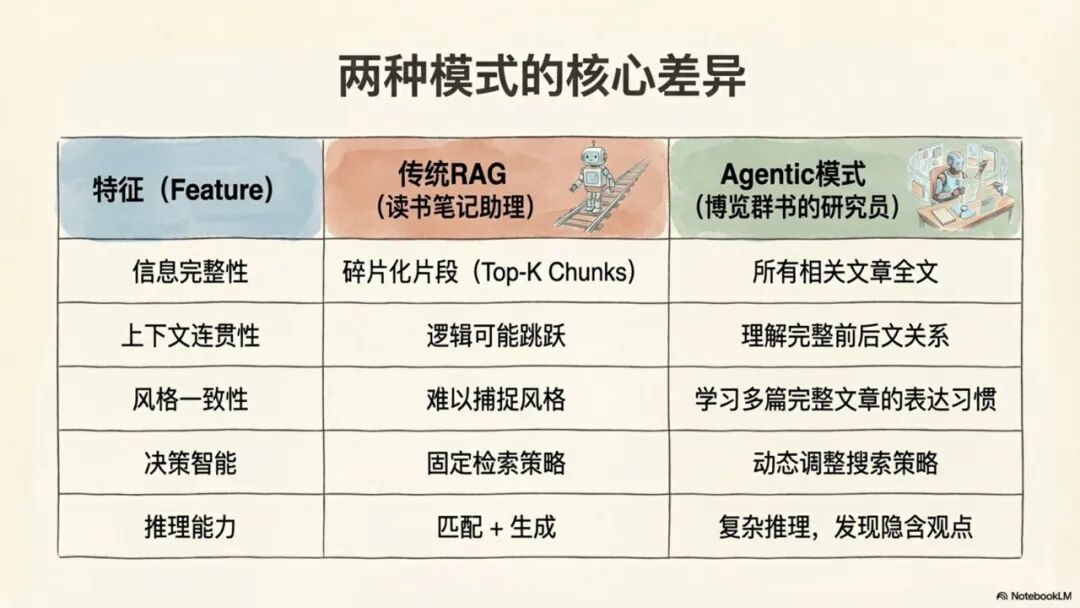
传统RAG是当前AI问答系统的主流技术,其工作流程通常分为四个步骤:首先对文档进行分块(Chunking),然后将这些文本块向量化并建立索引,当用户提问时,系统会检索(Top-K)出与问题语义最相似的文本块,最后将这些文本块作为上下文注入给大语言模型以生成答案。
尽管RAG为AI结合外部知识提供了基础框架,但其局限性也十分明显:
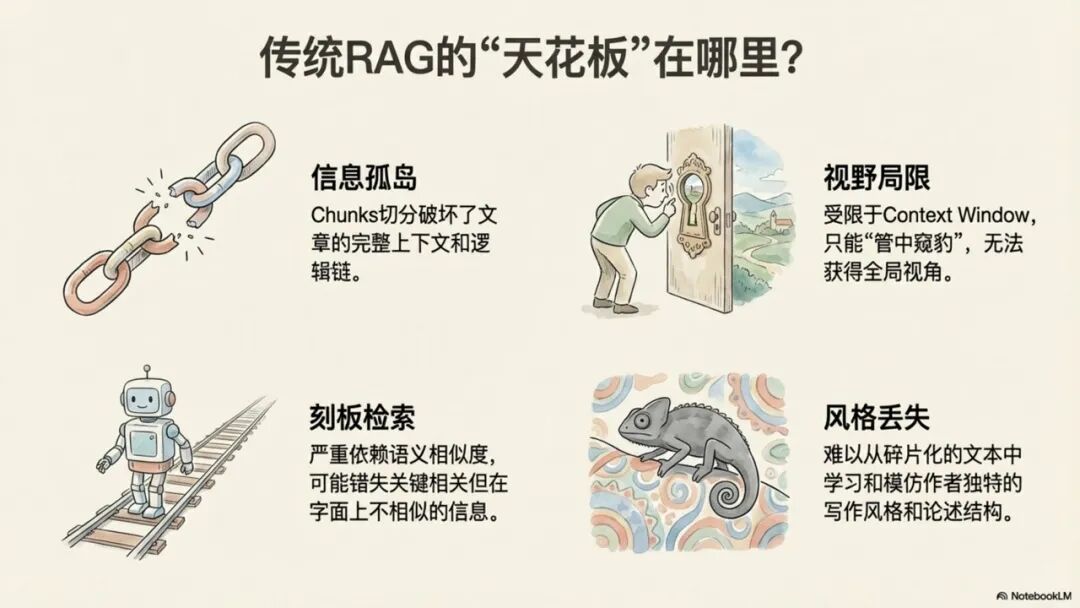
• 信息不完整:检索过程严重依赖语义相似度,可能会遗漏上下文中的关键信息。同时,受限于检索片段(Top-K)的数量,AI获得的信息视野是残缺的。
• 逻辑割裂:将原文强行切分为独立的文本块(Chunks),直接破坏了文章内在的论证结构和上下文的连贯性,导致AI无法理解完整的逻辑链。
• 风格丧失:AI只能看到碎片化的文本,无法学习和模仿作者在完整文章中体现出的整体写作风格、论述节奏和用词偏好。
• 策略固化:检索策略是固定的(通常是向量相似度),缺乏根据问题的复杂性动态调整策略的智能决策能力。
一个形象的比喻是: 传统RAG就像一个只能根据预先做好的、零散的读书笔记来回答问题的助理。他无法访问完整的书籍,也无法理解作者真正的思想体系。
1.2 范式二:智能体RAG(Agentic RAG)——检索过程的智能化升级
Agentic RAG是对传统RAG的一次重要改进。其核心特征是引入了AI智能体(Agent)来优化和编排检索过程。其工作流程变为:用户提出问题后,Agent首先对问题进行分析和规划,然后可能采取改写查询、评估检索结果、决定是否需要再次检索等多轮动态策略,最后对检索到的信息进行重排序和整合,再交由大模型生成答案。
Agentic RAG的关键进步在于,它通过Agent的任务规划、分解和多轮执行能力,让检索过程本身变得更智能、更具系统性。尽管其底层检索技术大多仍基于向量数据库,但决策的智能化使其能够更深入地探索知识。
一个形象的比喻是: Agentic RAG就像一个会帮你优化检索策略的聪明图书管理员。他不仅会帮你查找资料,还会主动优化检索策略,帮你找到更全面、更相关的参考书籍。
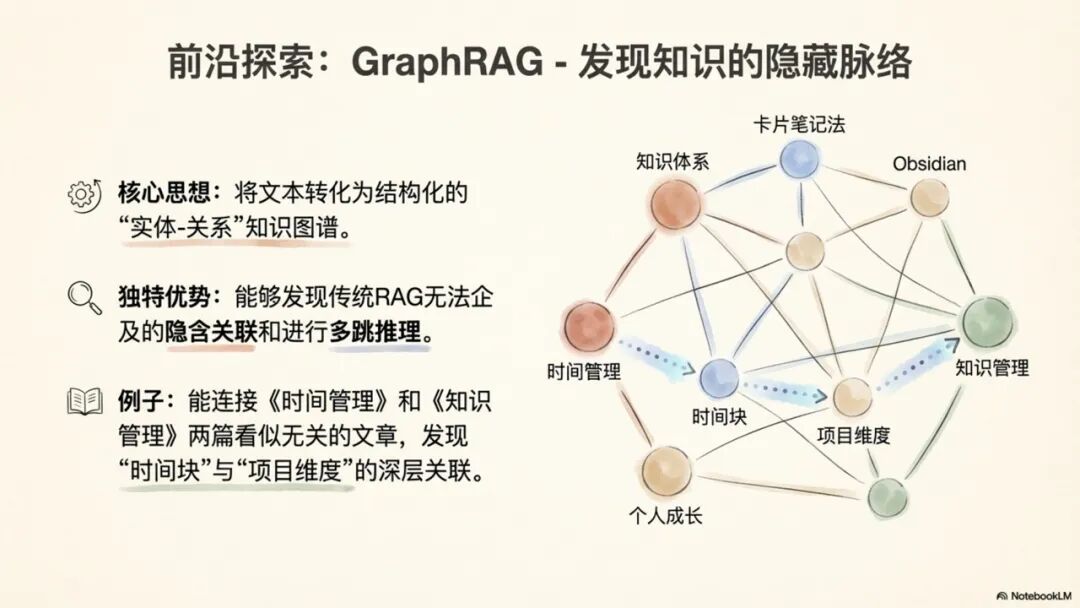
1.3 范式三:图谱RAG(GraphRAG)——揭示深层关系的结构化革命
GraphRAG则代表了另一个维度的革命,它致力于将非结构化文本转化为结构化的知识图谱。其工作流程是:文档 → 实体抽取 → 关系抽取 → 构建知识图谱 → 图推理 → 生成答案。
GraphRAG的独特优势在于它能够发现隐性关联并支持多跳推理(multi-hop reasoning)。例如,在知识库中,《时间管理》文章提到“按项目组织时间块”,而《知识管理》文章提到“按项目维度组织知识库”。传统RAG因语义相似度不高可能无法连接这两点。但GraphRAG能构建出“时间管理” --关联--> “项目管理” --关联--> “知识体系”这样的关系,从而在回答中提出“搭建知识体系时,可结合时间管理习惯,按项目组织”的深刻见解。这种能力使其在需要全局视角和深度关系挖掘的场景中表现卓越。
一个形象的比喻是: GraphRAG像一位知识考古学家,他能从看似无关的文献中挖掘出深埋的联系,并绘制出一幅完整的思想脉络图。
1.4 范式四:智能体文件系统问答(Agentic File System QA)——本方法论的最终选择
本方法论采用的是一种超越向量检索的全新模式,我们将其精确地命名为“Agentic File System QA”。它不依赖于预处理的文本块和向量索引,而是赋予AI智能体直接与原始文件系统交互的能力。其工作流程建立在四大支柱之上:
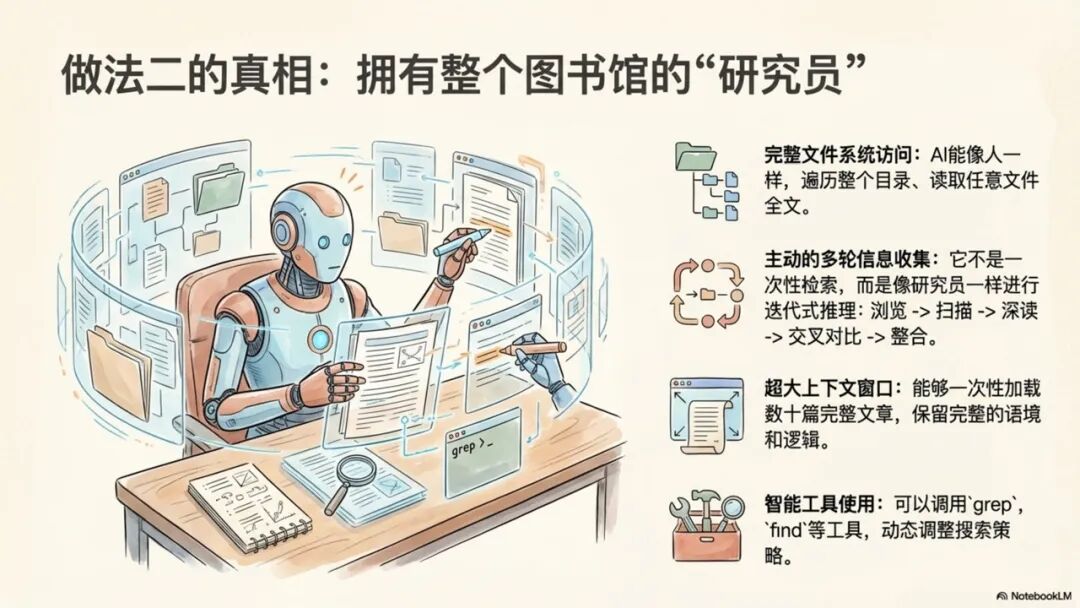
• 完整的本地文件系统访问:AI能够像人类一样,直接遍历整个知识库的目录结构,读取任意Markdown文件的全文。这使得AI能够理解文件间的组织关系,并根据需要动态决定读取哪些文章。
• 主动的多轮信息收集:这是一个迭代推理(Iterative Reasoning) 的过程。AI会首先浏览目录,根据问题识别关键词,然后扫描可能相关的文章,接着深度阅读选定的全文,并在多篇文章之间进行交叉对比和信息整合,最终形成结构化的回答。
• 超大上下文窗口的优势:借助拥有超大上下文窗口(如Claude Sonnet 4.5 200K Tokens)的大模型,系统可以一次性加载数十篇完整的文章进行分析。这从根本上解决了逻辑割裂和信息不完整的问题,完整保留了原文的语境和逻辑链。
• 灵活的工具使用能力:AI可以动态调用grep、find等命令行工具,在整个文件系统中进行关键词搜索或按模式筛选文件,从而实现检索策略的实时动态调整。
一个形象的比喻是: 这种模式就像一个真正读过你所有文章、可以随时重新查阅原文并进行交叉验证的专属研究员。他能够全面、深入地理解你的整个知识体系。
1.5 范式对比与选择
为了更直观地展示四者差异,我们从五个关键维度进行对比:
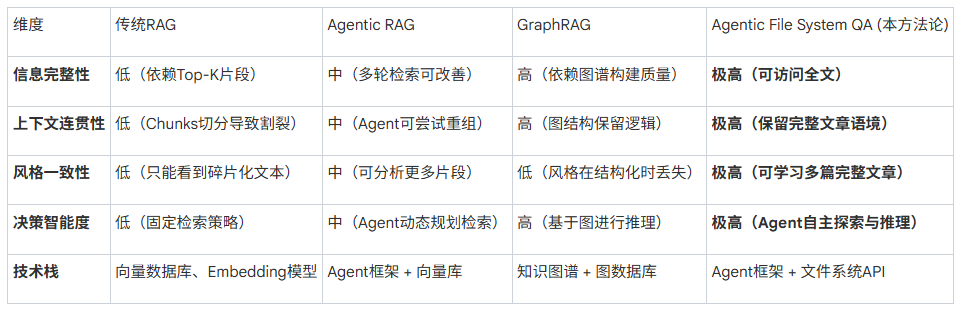
综上所述,对于“基于个人大量历史文章、生成风格一致的高质量内容”这一特定需求,其效果排序显而易见:Agentic File System QA > Agentic RAG > GraphRAG > 传统RAG。
在确定了“Agentic File System QA”为我们的核心架构后,构建该系统的第一步便是为AI智能体准备结构化的“精神食粮”——我们的知识库。
先决条件与心态转变
在进入实施阶段之前,必须明确本方法论并非轻量级的即插即用工具,它要求实践者具备相应的资源和心态。这既是先决条件,也是一次深刻的心态转变:
1. 拥有足够的内容资产:本方法论的“原材料”是您个人创作的大量历史文章。您需要拥有一个相当规模的语料库(例如,数十篇乃至数百篇深度文章),这是AI学习您的思想和风格的基础。
2. 将知识视为代码库(Knowledge as Code):您需要像软件工程师管理代码库一样,系统地管理您的知识。这意味着要进行版本控制、结构化组织,并将每一篇文章视为一个可被程序读取和操作的模块。
3. 接受更高成本换取更高质量:与追求毫秒级响应的传统RAG不同,本系统追求的是输出质量的极致。这意味着它需要更长的处理时间(分钟级)和更高的计算成本(Token消耗大)。这是一种从“快餐”到“米其林级大餐”的取舍。
2. 实施阶段一:知识库的结构化——构建系统的基石
知识库的质量和结构,决定了整个AI辅助写作系统的性能上限。一个杂乱无章、非结构化的知识库,即使配备最强大的AI引擎,也无法产出高质量的内容。本章节将提供一套具体的操作指南,帮助您将分散在各处的个人知识,转化为AI智能体可以直接访问和深刻理解的结构化知识库。
2.1 知识的收集与离线化
第一步,是将散落在互联网各个角落的个人知识资产进行统一回收。这通常需要利用爬虫程序或平台自带的导出工具,将您在个人博客、公众号、知识星球等平台发布的所有历史文章完整地抓取到本地。
此步骤的核心目标是资产统一管理。通过将在线、分散的知识转化为一个离线的、可随时被本地程序访问的文件集合(例如,初始形态可能是一系列PDF文件),我们为后续的结构化处理奠定了基础。
2.2 知识的Markdown化与项目化
这是整个知识库构建过程中最关键的一步。我们需要将所有离线的文章(无论是PDF、HTML还是其他格式)批量转换为标准的Markdown(.md)格式文件。
Markdown格式之所以是理想选择,其核心优势在于:
它是一种结构化的纯文本格式。这意味着它不仅保留了文章的完整内容,还通过简单的标记(如#表示标题,*表示列表,**表示加粗)保留了文章的内在结构。这使得AI能够像读取源代码一样,直接理解文章的标题层级、段落划分和重点标记,而无需进行复杂的非结构化文本解析。
完成转换后,需要将所有Markdown文件以及文章中引用的图片等资源,统一组织在一个本地文件夹中。这个文件夹就构成了一个完整的“源代码项目”,成为AI智能体的工作空间。最终的知识库形态应如下图所示:
/my_knowledge_base
├── [2024-01-01]_关于AI辅助写作的思考.md
├── [2024-03-15]_构建个人知识体系的核心方法.md
├── ...
└── /images
├── image_workflow.png
└── image_architecture.svg
采用 [YYYY-MM-DD]_文件名.md 的格式,不仅便于按时间排序,也符合将知识库作为日志和版本化项目管理的理念。
2.3 (可选)结构化方案文档的高级应用
对于有专业需求的用户,例如需要频繁编写技术方案或建议书的专业人士,可以采用一种更高级的结构化方法。
具体操作如下:将一份标准的产品解决方案文档,按照其逻辑模块(如产品概述、核心功能、技术架构、实施方案、服务支持等)拆分为多个独立的Markdown文件。更进一步,将方案中所有的架构图、流程图等,用SVG源代码格式重新绘制并嵌入Markdown文件中。
这样做的好处是实现了文档的完全模块化和代码化。当面对一个新的需求(如一份新的招标文件)时,AI智能体可以:
1. 理解新需求。
2. 从模块化的Markdown文件中自动选择、组合和修改相关内容。
3. 直接读取并动态调整SVG源代码,生成符合新需求的定制化架构图。
通过这种方式,AI能够自动化地生成高度定制化的专业文档,极大地提升了工作效率。
至此,一个结构良好、内容完整的Markdown知识库已经准备就绪。接下来,我们需要设计一个能够高效利用这些知识的智能处理引擎。
3. 实施阶段二:设计智能处理引擎——Agentic工作流详解
拥有一个结构化的知识库只是第一步,系统的核心在于设计一个能够模拟领域专家进行思考、研究和写作的智能处理流程。一个优秀的引擎能够将静态的知识库转化为动态的创作能力。本章节将详细拆解该系统内部的“Agentic”工作流,揭示其高质量输出背后的精密机制。
3.1 整体架构:三阶段流水线
本系统采用一种稳健的“多阶段流水线架构”,确保整个内容生成过程的质量可控。该架构由三个核心阶段组成:
1. 准备阶段 (Preparation):接收并理解用户指令,进行初步规划。
2. 执行阶段 (Execution):通过多轮次、多层级的检索与内容合成,完成初稿。
3. 验证阶段 (Validation):对初稿进行严格的质量审查与修正,确保最终交付物达标。
这种架构设计的战略意义在于,它将一个复杂的创作任务分解为一系列有明确输入、输出和验证标准的子任务,从而系统性地保障了最终内容的整体质量。
3.2 核心机制:多层级递进式工作流
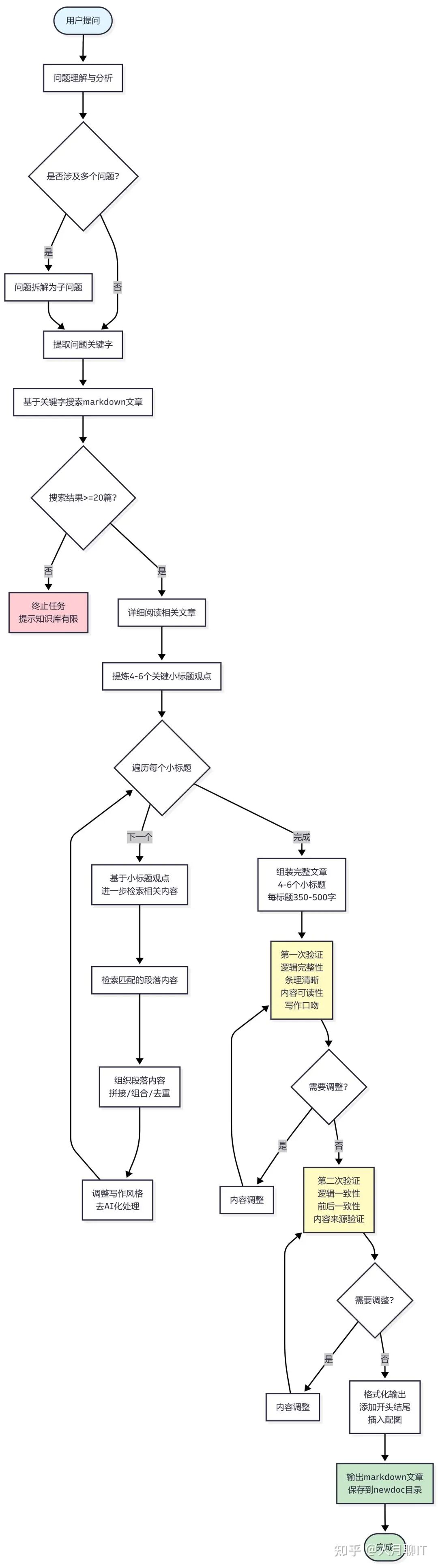
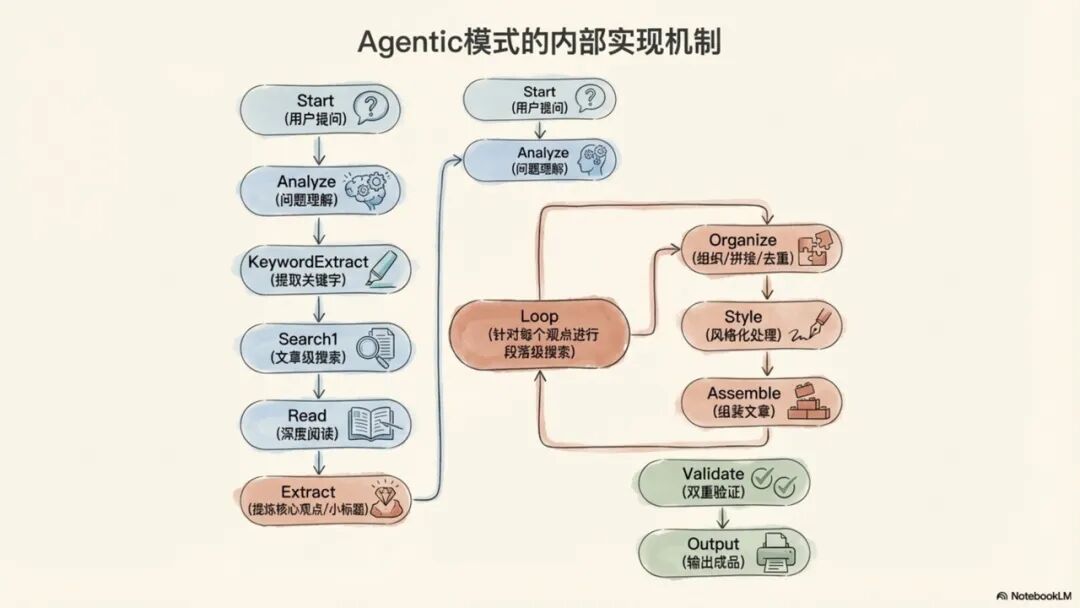
AI智能体在接收到用户问题后,会启动一个精密的、多层级递进式的工作流程。以下是其详细步骤分解:
1. 问题理解与分析: AI首先对用户的提问进行深度分析,如果是复杂问题,则会将其拆解为多个子问题,并从中提取出核心关键词。
2. 第一轮检索(文章级): 基于提取的关键词,AI在整个Markdown知识库目录中进行全文搜索,以定位所有可能相关的文章。此阶段引入了阈值控制机制:例如,如果搜索到的相关文章少于20篇,系统将判断知识库内容不足以支撑高质量回答,并终止任务。这确保了AI的创作基于充分的原材料。
3. 观点提炼与结构化: AI会深度阅读所有在第一轮检索中锁定的文章,通过归纳和提炼,形成4到6个核心的小标题观点。这些观点将构成最终文章的逻辑骨架,确保内容的结构性和系统性。
4. 第二轮检索(观点级): 针对每一个提炼出的小标题观点,AI会进行更精准的二次检索。这次检索的范围被限定在第一轮已锁定的文章集合内,目标是为每个观点寻找所有直接相关的支撑段落。这是一种动态检索,检索策略会根据每个观点的不同而调整。
5. 内容组织与合成: AI将第二轮检索到的相关段落进行整合,包括逻辑排序、内容拼接、观点组合以及去重处理,形成每个小标题下的初稿内容。
6. 风格化与“去AI化”处理: 这是提升内容自然度的关键一步。AI会模仿知识库原文的写作风格、第一人称口吻和用词习惯。这包括避免使用‘首先、其次、再次’等僵硬的过渡词,避免将每段的首句都进行加粗,并控制整体加粗比例在10%以下,从而使行文更自然、更接近人类作者的原始风格。
7. 组装与验证: 将所有小标题下的内容组装成一篇完整的文章,并立即启动严格的双重验证机制(详见第5章),对文章的逻辑、风格和内容来源进行审查。
8. 格式化输出: 通过所有验证后,AI会为文章添加合适的开头和结尾,根据上下文智能地匹配知识库中的相关图片,最终生成一篇图文并茂、格式规范的Markdown文章。
3.3 对比传统RAG:从“单次投喂”到“多轮探索”
本系统的智能处理引擎与传统RAG在工作模式上存在本质区别:
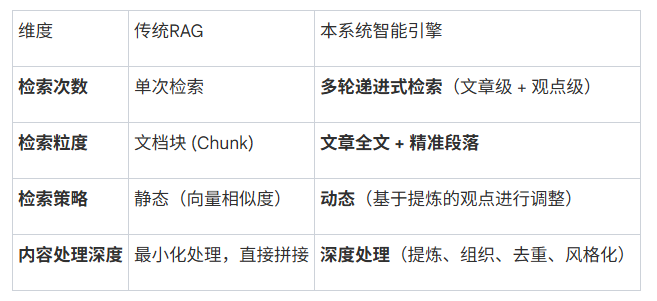
其本质差异在于:本系统是一个具备任务分解、动态决策和深度内容处理能力的智能系统,它主动地、有策略地探索整个知识库;而传统RAG更像一个简单的信息匹配与返回工具,被动地根据一次性查询返回最相似的片段。
这个强大的智能引擎需要精确的指令来驱动。下一章,我们将聚焦于如何设计高效的提示词(Prompt),以充分激活它的潜力。
4. 实施阶段三:指令工程——编写高效的AI写作提示词
提示词(Prompt)是连接人类意图与AI智能体执行能力的桥梁。一个模糊、宽泛的提示词只会得到平庸甚至错误的输出,而一个结构化、高约束的提示词则能精确地引导AI,激活其全部潜力。本章节将以经过实践验证的最佳提示词为例,提供一个构建高效AI写作提示词的框架。
4.1 提示词的核心构成要素
一个高效的提示词并非简单的问句,而是一份详尽的工作指令。它应至少包含以下六个关键组成部分:
• ### 角色 (Role) 为AI设定一个明确的身份。这个角色定义了它的行为边界和总体目标。
• ### 当前知识库 (Knowledge Base Scope) 清晰地界定AI允许访问的信息范围,防止它引用外部知识或产生“越界”幻觉。
• ### 工具要求 (Tool Requirement) 指定AI在执行任务时必须使用的思考框架或工具。这能强制AI采用结构化、有条理的工作方式,而不是随意发挥。
• ### 具体回答的要求 (Content & Style Requirements) 这是指令的核心部分。使用清晰、可量化的列表形式,详细规定内容的来源、逻辑性、结构(如小标题数量、字数范围)、风格(如第一人称、与原文风格一致)和核心处理方式(是整合加工而非创新)。
• ### 回答规则 (Strict Constraints) 设立绝对的、不容违反的底线规则。这些规则是防止AI产生幻觉、确保内容忠实于原文的最后防线。规则必须是斩钉截铁的,没有任何模糊空间。
• 该部分是整个指令工程的基石,其斩钉截铁的强约束是确保内容100%忠于原文、杜绝模型产生幻觉的根本保障。
• ### 输出要求 (Output Format) 精确定义最终交付物的格式、总字数范围以及文件保存方式,确保AI的输出直接可用。
4.2 提示词设计的关键原则
基于以上构成要素,我们可以总结出设计高质量提示词的三大核心原则:
1. 明确性与具体性:避免使用“写得好一点”等模糊指令。尽可能提供量化指标,如“4到6个小标题”、“总字数2000到3000字”、“加粗量不超过10%”等。
2. 强约束性:通过设置严格的规则(如“禁止任何扩写、缩写、改写或编造”)来有效抑制AI的“创造性”,防止其自由发挥而导致内容失真或产生幻觉。
3. 过程导向:不仅要定义最终结果(What),更要指导AI如何达成结果(How)。例如,要求其“采用Sequential Thinking MCP工具”和“分步骤执行”,就是对过程的引导。
当智能体根据这样一份精确的指令生成内容后,我们还需要最后一道关键工序——严格的验证,以确保交付物达到最高质量标准。
-----------------------------------------------------------------------------
5. 实施阶段四:闭环验证机制——确保高质量输出的最后一道防线
AI的输出本质上是基于概率的生成,即使有再精密的指令,也无法保证100%的完美。因此,建立一个系统性的验证与反馈机制,是确保内容质量从“优秀”迈向“卓越”的最后一道、也是最重要的一道防线。本方法论中采用的“双重验证机制”构成了一个强大的闭环反馈系统,将AI的生成过程从开放式创作转变为有严格质量门禁的生产流程。
5.1 第一次验证:逻辑、可读性与风格审查
在AI完成内容初步组装后,系统会立即启动第一次验证。这次验证的目标是审查文章的内在质量,确保其作为一篇独立作品是合格的。
其核心审查点包括:
• 逻辑完整性:评估文章的整体论证结构是否严密,观点与观点之间是否存在逻辑跳跃或断层。
• 条理清晰度:检查小标题的划分是否合理,段落的组织是否有序,能否清晰地引导读者。
• 内容可读性:判断行文是否流畅自然,语言是否通俗易懂,避免生硬晦涩的表达。
• 写作口吻与“去AI化”:检验文章的风格和口吻是否与知识库原文保持高度一致,是否成功避免了AI写作中常见的固定套路和机械感。
如果第一次验证未能通过,系统将进入“内容调整”环节,针对上述问题进行修正,然后重新进入第一次验证流程。这个循环构成了第一个质量控制闭环。
5.2 第二次验证:一致性与来源核查
当文章通过了对内在质量的审查后,系统将启动更严格的第二次验证。这次验证的目标是确保内容的准确性和对知识库的忠实度。
其核心审查点包括:
• 内容一致性 (Content Consistency):检查文章的核心观点、论据和结论是否存在自相矛盾之处。
• 内容来源验证:这是最严格的核查环节。系统需要确保文章中的所有内容100%来源于知识库原文,没有任何AI杜撰、编造或引入的外部信息。
• 术语一致性 (Terminology Consistency):确保关键术语、专有名词和案例在全文中的使用保持统一,避免混淆。
同样,如果第二次验证不通过,系统将再次返回“内容调整”环节进行修正,并重新发起验证。这构成了第二个、标准更高的质量控制闭环。
5.3 验证机制的价值
这套双重、闭环的验证机制,其核心价值在于:它将一个开放的、不确定性较高的AI生成任务,转变为一个有明确质量门禁、可控的生产流程。它不仅是对结果的检查,更是对过程的矫正,是确保最终输出内容高质量、逻辑严谨且风格一致的关键所在。
通过这套严密的验证机制,我们完成了从知识准备到最终内容输出的完整闭环,为实现高质量的AI辅助写作提供了系统性的质量保障。
6. 总结与展望
本方法论详细阐述了一套构建高质量AI辅助写作系统的实践指南。其核心在于实现了从传统RAG的“被动信息检索”到基于智能体的“主动内容合成”的根本性范式转变。这一转变使得AI不再是一个简单的信息查找工具,而是一个能够深度理解并重组个人知识体系的智能创作伙伴。
回顾整个构建过程,该系统依赖于四大核心支柱的协同工作:
• 结构化的Markdown知识库:它为AI提供了高质量、结构化、可全局访问的“原材料”。
• Agentic多轮处理引擎:它模拟了领域专家的研究与写作流程,实现了从宏观到微观的深度内容处理。
• 高约束的指令工程:它通过精确、具体的指令,确保AI的行为和输出严格符合预设目标。
• 闭环的双重验证机制:它为最终产出的内容质量与忠实度提供了系统性的、可重复的保障。
当然,这一方法论也具备其优势与局限性。其显著优势在于能够稳定地产出高质量、结构化、风格高度一致的深度内容,尤其适用于个人知识管理和专业内容创作领域。然而,其局限性也同样明显:由于涉及多轮次的全文阅读和深度处理,系统的计算成本较高、响应时间较长,并且其输出质量高度依赖于知识库本身的质量与主题覆盖度。
展望未来,这种深度内容合成技术拥有广阔的应用前景。在个人知识管理领域,它可以帮助我们对抗信息遗忘,激活沉睡的知识资产;在专业内容创作领域,它可以极大提升报告、方案和技术文档的撰写效率与质量;在教育培训领域,它可以根据学生的特定需求,动态生成个性化的学习材料。
我们鼓励更多的内容创作者和知识管理者动手实践,基于这一方法论,探索并构建属于自己的高质量AI辅助写作系统,真正将AI从一个“问答机器人”转变为赋能个人智慧的强大引擎。
附: NotebookLM辅助输出的ppt材料




本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号