ManiAgent:多智能体协作的通用机器人操作框架介绍
原创
ManiAgent:多智能体协作的通用机器人操作框架介绍
原创
buzzfrog
发布于 2025-12-27 14:16:40
发布于 2025-12-27 14:16:40
让机器人像人一样理解任务,像专家一样执行动作
引言
在机器人操作领域,如何让机器人理解自然语言指令并完成复杂的操作任务,一直是一个充满挑战的问题。传统的机器人控制方法往往需要精确的编程和预定义的动作序列,难以适应开放世界中多样化的任务需求。
ManiAgent 提出了一种创新的解决方案:将通用操作任务分解为多个专业智能体(Agent),通过它们的协作来完成复杂的操作任务。这种"分而治之"的思想,让每个智能体专注于自己擅长的领域,最终实现 1+1>2 的协同效果。
系统架构
ManiAgent 采用模块化的多智能体架构,主要由以下核心组件构成:
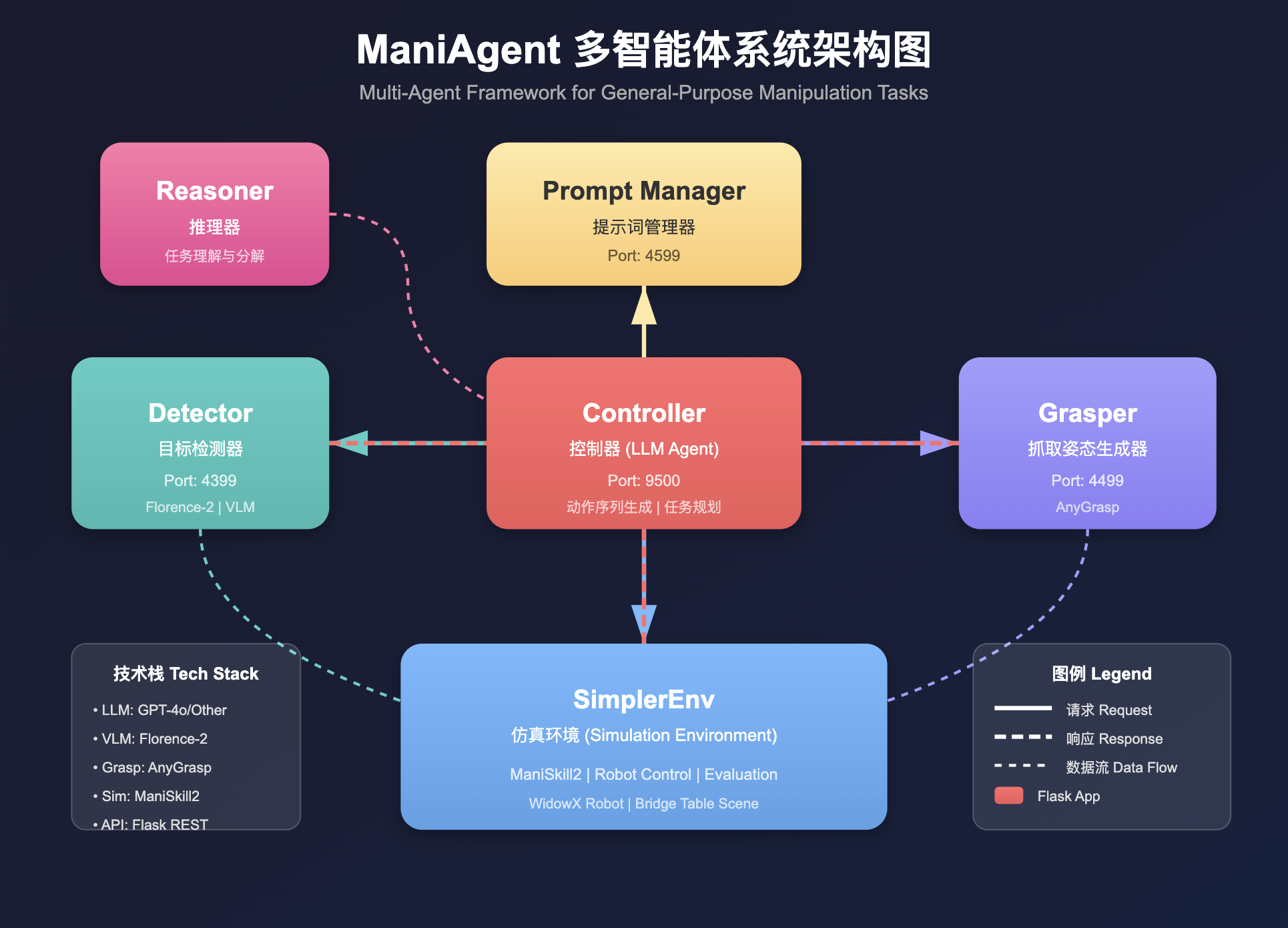
ManiAgent多智能体系统架构图
核心组件详解
1. Reasoner(推理者)
Reasoner 是任务理解的核心,负责:
- 语义理解:解析自然语言指令的含义
- 任务分解:将复杂任务拆解为可执行的子任务
- 目标提取:识别任务涉及的目标对象
示例:输入 "把香蕉放到盘子上",Reasoner 会识别出需要检测
["banana", "plate"]两个目标对象。
2. Controller(控制者)
Controller 是动作规划的大脑,基于大语言模型(LLM)生成机器人动作序列:
输入:
- 任务描述(自然语言)
- 场景信息(包含目标物体的 3D 位置和抓取姿态)
输出:
{
"sequence": [
[0.217, -0.092, 0.215, 0, 1.56, 0, 1],
[0.217, -0.092, 0.015, -0.874, 1.56, 0, 1],
[0.217, -0.092, 0.015, -0.874, 1.56, 0, 0],
...
],
"steps_description": [
"移动到香蕉上方,打开夹爪",
"旋转到抓取姿态",
"下降到香蕉位置,关闭夹爪",
...
]
}每个动作是一个 7 维向量:[x, y, z, roll, pitch, yaw, gripper_state]
x, y, z:末端执行器的 3D 位置roll, pitch, yaw:末端执行器的姿态角(弧度)gripper_state:夹爪状态(0=关闭,1=打开)
3. Detector(检测者)
Detector 使用 Florence-2 视觉语言模型进行目标检测:
步骤 | 输入 | 输出 |
|---|---|---|
2D 检测 | RGB 图像 + 物体名称 | 边界框 |
深度融合 | 2D 坐标 + 深度图 | 3D 位置 |
多目标选择 | 多个候选 + 任务描述 | VLM 辅助选择最佳目标 |
关键技术:
- 开放词汇检测:使用
<OPEN_VOCABULARY_DETECTION>任务支持任意物体检测 - 深度融合:结合相机内外参数,将 2D 像素坐标转换为机器人 base_link 坐标系下的 3D 位置
4. Grasper(抓取者)
Grasper 基于 AnyGrasp 算法生成精确的抓取姿态:
点云数据 + 目标位置
↓
AnyGrasp 处理
↓
抓取姿态 6DoF (grasp_x, grasp_y, grasp_z, roll, pitch, yaw)为什么需要 Grasper?
Detector 提供的是物体的几何中心位置,但对于抓取任务,我们需要知道:
- 最佳抓取点:物体的哪个位置最适合抓取
- 夹爪姿态:夹爪应该以什么角度接近物体
AnyGrasp 通过点云分析,为每个物体计算出最优的抓取配置。
5. Prompt Manager(提示管理器)
Prompt Manager 负责构建发送给 LLM 的提示词,包含:
- 系统提示:定义机器人的角色和输出格式
- 任务模板:标准化的任务描述格式
- Few-shot 示例:典型任务的输入输出样例
通过精心设计的提示词工程,确保 LLM 能够生成格式正确、逻辑合理的动作序列。
工作流程
完整的任务执行流程如下:
graph TD
A[接收任务指令] --> B[Reasoner 推理]
B --> C[Controller 规划]
C --> D{需要目标检测?}
D -->|是| E[Detector 检测]
E --> F{需要抓取姿态?}
D -->|否| F
F -->|是| G[Grasper 抓取]
G --> H[SimplerEnv 执行]
F -->|否| H
H --> I{任务完成?}
I -->|否| C
I -->|是| J[结束]具体执行步骤
- 任务解析:Reasoner 理解自然语言指令,提取目标对象列表
- 目标检测:Detector 对每个目标进行 2D 检测和 3D 定位
- 抓取规划:Grasper 为需要抓取的物体生成最优抓取姿态
- 动作生成:Controller 根据场景信息生成完整的动作序列
- 仿真执行:SimplerEnv 执行动作序列并返回状态观测
- 闭环控制:根据执行结果判断是否需要重新规划
快速开始
环境要求
- GPU:NVIDIA 显卡,16GB+ 显存
- CUDA:推荐 11.8 版本
- Python:3.10
安装步骤
# 1. 克隆代码
git clone https://github.com/yi-yang929/maniagent.git
cd maniagent
git submodule update --init --recursive
# 2. 创建 Agent 环境
conda create -n agent python=3.10 -y
conda activate agent
pip install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
# 3. 配置 LLM API
export OPENAI_API_KEY=your_api_key
export OPENAI_BASE_URL=https://api.openai.com/v1启动服务
# 终端 1:启动 Controller
python controller/app.py
# 终端 2:启动 Detector
python detector/app.py
# 终端 3:启动 Prompt Manager
python prompt_manager/app.py
# 终端 4:启动 Grasper(需要单独配置 AnyGrasp 环境)
cd grasper/anygrasp_ManiAgent/grasp_detection
python app.py
# 终端 5:启动仿真器
cd benchmark
bash scripts/env_sh/simpler.sh ./evaluation/configs/simpler/example_simpler.yaml技术亮点
1. 参数化动作序列缓存
Controller 支持将生成的动作序列参数化并缓存,相同类型的任务可以复用已有模板:
# 参数化动作序列示例
"sequence_param": "[
[scene_info['objects'][0]['grasp_x'],
scene_info['objects'][0]['grasp_y'],
scene_info['objects'][0]['grasp_z'] + 0.2,
0, 1.56, 0, 1],
...
]"这种设计使得系统能够:
- 提高效率:相似任务直接复用,无需重新调用 LLM
- 保证一致性:同类任务的动作模式保持稳定
- 便于调试:可追踪和分析动作生成逻辑
2. 多模态物体选择
当场景中存在多个同类物体时,Detector 会:
- 在图像上标注每个候选物体的编号
- 将标注图像和任务描述发送给 VLM
- VLM 根据空间关系和任务语义选择最合适的目标
3. 模块化微服务架构
每个 Agent 都是独立的 Flask 服务,支持:
- 分布式部署:各服务可运行在不同设备
- 独立扩展:单独升级或替换某个模块
- 灵活配置:通过命令行参数调整模型和端口
实验验证
ManiAgent 在 SimplerEnv 仿真环境中进行了验证,支持的任务类型包括:
任务类型 | 描述 | 关键技术 |
|---|---|---|
抓取放置 | 把物体从 A 放到 B | 完整流程 |
物体堆叠 | 将物体叠放在一起 | 精确定位 |
旋转操作 | 拧开瓶盖等旋转动作 | 姿态控制 |
拖拽操作 | 拖动碗/盘等不易抓取的物体 | 特殊策略 |
相关资源
总结
ManiAgent 展示了多智能体协作在机器人操作任务中的巨大潜力。通过将复杂任务分解为感知、推理、规划、执行等多个专业模块,系统能够灵活应对开放世界中的多样化挑战。
这种模块化设计不仅提高了系统的可维护性和可扩展性,也为未来引入更先进的视觉模型、语言模型和控制算法提供了良好的架构基础。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号