KIOXIA:超高IOPS SSD的需求和设计

KIOXIA:超高IOPS SSD的需求和设计

数据存储前沿技术
发布于 2025-11-29 18:15:38
发布于 2025-11-29 18:15:38
阅读收获
- 掌握GPU显存扩展策略:理解GPUDirect Storage等技术如何利用本地SSD作为GPU HBM的“扩展层”,使AI模型能够处理10倍至100倍大的数据集,有效缓解显存容量瓶颈。
- 优化AI数据访问性能:学习“近-GPU缓存”和“分层KV缓存”架构,将低效的网络小I/O转化为高效的本地SSD小I/O,显著提升AI训练和LLM推理的数据吞吐与响应速度。
- 洞察高性能存储介质与接口演进:认识KIOXIA XL-FLASH等低延迟NAND技术和PCIe 5.0到7.0的演进,及其对实现1亿IOPS超高存储性能的决定性作用。
全文概览
在AI浪潮席卷全球的今天,GPU已成为驱动智能未来的核心引擎。然而,随着大模型和复杂AI应用的爆发式增长,我们正面临一个日益严峻的挑战:昂贵的GPU高带宽内存(HBM)容量捉襟见肘,传统存储I/O模式已无法满足GPU饥渴的数据需求。 你的AI训练是否因显存不足而受限?你的LLM推理是否因KV缓存膨胀而性能骤降?
本文将深入探讨高性能SSD如何在AI时代扮演“隐形加速器”的角色,通过一系列创新技术,有效突破GPU显存瓶颈,重塑AI工作负载的数据访问模式。我们将揭示GPU内存扩展、近-GPU缓存以及分层KV缓存等前沿架构,并剖析XL-FLASH等低延迟介质和PCIe总线演进如何共同驱动AI存储性能的飞跃。准备好,一起探索高性能SSD如何解锁AI算力的无限潜力!
👉 划线高亮 观点批注
高性能SSD应用场景

GPU内存扩展
GPU内存扩展
“GPU内存扩展” (GPU Memory Extension),它旨在解决AI应用中GPU显存 (HBM) 容量不足和成本高昂的核心痛点。
核心观点是: 许多AI工作负载(如大型图神经网络、推荐系统)受限于内存容量(Memory-bound),而不是计算能力。
所提出的解决方案是: 利用本地的高速SSD(如NVMe SSD)作为GPU HBM的“扩展层”或“交换空间”。
关键实现技术是“GPU发起的I/O” (GPU-initiated I/O),例如NVIDIA的GPUDirect Storage。该技术允许GPU绕过CPU,直接对SSD进行高速I/O操作(高达2亿IOPS)。
最终效果是: GPU可以透明地访问一个远大于其物理HBM的扩展内存池(HBM + SSD),从而使其能够处理比以往大10倍到100倍的数据集,极大地扩展了AI模型可处理问题的规模。
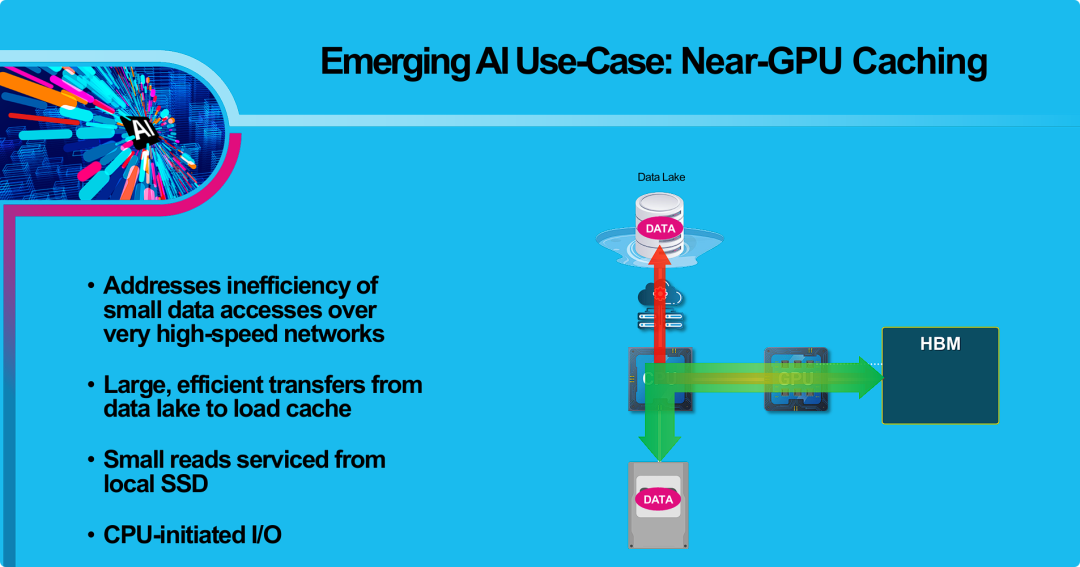
新兴AI用例:近-GPU缓存
新兴AI用例:近-GPU缓存
PPT介绍了一种针对AI工作负载的“近-GPU缓存” (Near-GPU Caching) 架构。
核心观点是: AI应用中常见的大量、小规模、随机的数据读取(Small I/O)通过高速网络从远程数据湖(Data Lake)获取时,效率极低。
所提出的解决方案是: 在计算服务器(GPU附近)部署一个本地SSD作为缓存。其工作流程分为两步:
- 缓存预热: 由CPU发起,从远程数据湖进行一次性的大型、高效、顺序的数据传输,将所需数据预先加载(pull)到本地SSD缓存中。
- 服务读取: 当GPU实际需要数据时,CPU从本地SSD上执行小规模、随机的数据读取,并快速将数据喂给GPU的HBM(高带宽内存)进行计算。
这种架构通过将低效的网络小I/O转换为高效的本地SSD小I/O,规避了网络延迟和协议开销,从而显著提升了AI工作负载的数据访问性能。
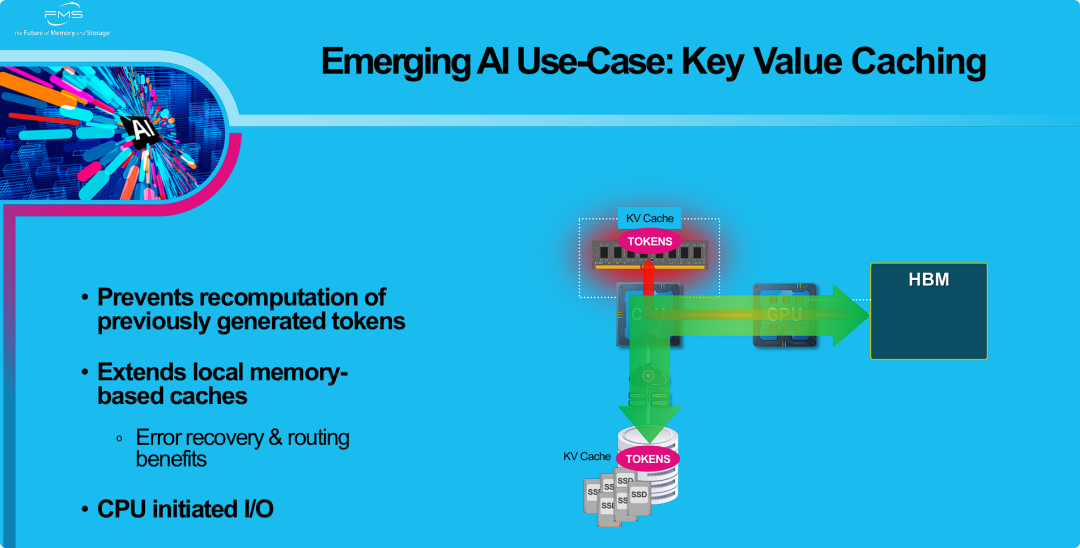
键值缓存
键值缓存
专门针对生成式AI(大语言模型)推理场景的“键值缓存”(KV Caching)架构。
核心观点: LLM推理的性能瓶颈之一是KV缓存。随着对话或生成文本(上下文)变长,KV缓存会急剧增大,迅速耗尽宝贵的GPU HBM(显存)容量。
所提出的解决方案: 采用一种分层缓存(Hierarchical Caching)机制,使用本地SSD来扩展HBM/DRAM内存缓存。
工作机制(由CPU协调):
- 一级缓存(热数据): HBM/DRAM中存储当前最活跃的KV对。
- 二级缓存(冷数据): 当一级缓存满时,将较早的、暂不使用的KV对“卸载”(Offload)到大容量的本地SSD上(如图中红色箭头)。
- 数据重载(Reload): 当需要访问被卸载的KV对时,再从SSD将其“加载”(Load)回HBM(如图中绿色箭头)。

核心观点是: 这一性能的巨大飞跃(从300万跃升至1亿IOPS)主要依赖两大技术支柱:
- 核心存储介质的变革: 从传统的TLC Flash转向KIOXIA自家的XL-FLASH技术(一种高性能、低延迟的NAND闪存)。
- I/O接口的演进: 性能的提升与PCIe总线的换代(从5.0到7.0)紧密同步,以提供足够的传输带宽(从14GB/s到50GB/s)。
一个非常关键的细节是: 从2026年开始,实现1000万及1亿IOPS的测试指标从标准的“4K随机读取”切换到了“512B(字节)随机读取”。这表明KIOXIA的XL-FLASH技术专门针对极小I/O(small I/O)和高IOPS密度的场景进行了优化。
关于 XL-FLASH技术
XL-FLASH 之所以能实现如此高的性能,主要依赖于其在NAND架构上的几项关键创新:
- 基于BiCS FLASH 3D NAND: 它并非像Intel Optane(现已停产)那样采用全新的相变材料(PCM),而是基于铠侠成熟的 BiCS FLASH™ 3D堆叠NAND技术进行深度魔改。这使其能利用现有NAND的庞大制造生态,从而在成本上更具优势。
- 采用SLC模式(为主): 第一代XL-FLASH主要使用SLC(Single-Level Cell,1 bit/cell) 模式。SLC的读写速度最快、延迟最低、且耐久度(P/E cycles)最高。第二代技术也引入了MLC(2 bit/cell)以平衡成本和容量。
- 极高的并行架构(多平面): 这是它的核心秘密之一。常规NAND闪存可能只有2个或4个平面(Plane),而XL-FLASH采用了16平面架构。这意味着它可以同时并行处理更多的I/O请求,这是其实现超高IOPS的关键。
- 优化的内部设计: 它对NAND芯片内部的“位线”(Bit Lines)和“字线”(Word Lines)进行了缩短和优化,大幅减少了内部访问的延迟。
- 小页面尺寸(Page Size): 它使用较小的4KB页面,这更匹配操作系统和数据库的I/O大小,在处理小文件和随机I/O时效率极高。

低延迟介质是关键
低延迟介质是关键
PPT通过数学计算,论证了为什么“低延迟介质”是实现超高IOPS(如1亿IOPS)的“关键”。
核心观点: 实现1亿IOPS的最大瓶颈并非来自接口带宽,而是来自介质本身的物理读取延迟 (tRead)。
论证过程:
- 目标: 1亿IOPS = 平均每10纳秒交付一个I/O。
- TLC的困境: 传统TLC闪存物理延迟高达60,000纳秒。要用它实现10ns的交付目标,SSD控制器必须同时管理一个高达6,000的并发I/O流水线(队列),这在工程上几乎是不可行的。
- XL-FLASH的优势: XL-FLASH将物理延迟降低到了5,000纳秒。为了实现10ns的交付目标,控制器需要管理的并发流水线锐减到了500。
为什么这里说工程上是不可行的 ?
- 要让一个控制器同时管理 6,000 个并发请求,它需要极其庞大的片上SRAM来存储这6,000个I/O的状态。
- 在当前技术下,为单个SSD控制器配备如此海量的SRAM是成本极高且极不现实的。

AI时代的GPU彻底颠覆了传统的I/O模式,对存储(SSD)提出了前所未有的并发挑战。
它通过CPU和GPU的对比,论证了GPU在发起I/O方面的三个根本不同:
- I/O能力不同: GPU的I/O生成能力(2亿IOPS)远超CPU(5千万IOPS)。
- I/O效率不同: GPU生成I/O的内部开销极低(<10%利用率),而CPU开销极高(100%利用率)。
- I/O模式不同: GPU的海量并行特性,使其会产生 “数万”级别(Tens of thousands) 的超深I/O队列深度(Queue Depth)。
Note
GPU工作原理特征,就是会产生大量IO,其片上HBM,就是为满足其IO特征而设计,文章提出超大IOPS SSD的设计,有2条路径可以走:
- 控制器上集成超大SRAM+TLC NAND,用SRAM 来索引NAND并降低访问时延,此举在工程上不可行;
- 创新存储介质,KIOXIA 使用 XL-FLASH结构创新来降低传统NAND访问时延,从而避免片上集成大量SRAM
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- GPUDirect Storage等GPU-initiated I/O技术在实际部署中,除了性能优势,还可能带来哪些新的系统管理和数据一致性挑战?
- XL-FLASH这类低延迟NAND介质,其高昂的成本与传统TLC/QLC SSD相比,在哪些AI应用场景下能真正体现出ROI(投资回报率)?
- 随着AI模型规模持续增长,分层缓存(HBM/DRAM + SSD)的策略是否足以应对未来的KV缓存需求?我们还需要哪些更激进的存储创新?
原文标题:High IOPS SSDs for AI Use Cases[1]
Notice:Human's prompt, Datasets by Gemini-2.5-Pro
#FMS25 #SSD介质创新
---【本文完】---
👇阅读原文,独立站提前更新🚀(测试中)🧪
- https://files.futurememorystorage.com/proceedings/2025/20250806_SSDT-201-1_Bolt-2025-08-04-15.59.14.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号