深度万字:强化学习的终局与未来,从DQN、世界模型到LLM智能体
原创
深度万字:强化学习的终局与未来,从DQN、世界模型到LLM智能体
原创
走向未来
发布于 2025-11-29 14:40:48
发布于 2025-11-29 14:40:48
通向通用智能的强化学习:从序贯决策、DQN、A2C到世界模型与大语言模型
走向未来
强化学习(Reinforcement Learning, RL)的本质是关于序贯决策的科学与工程。它试图解决一个根本性问题:一个智能体(agent)如何在复杂的、不确定的环境中,通过与环境的交互来学习一系列动作,以最大化其累积的期望奖励。Kevin P. Murphy发布了一份144页的强化学习的全面概览电子书,梳理了强化学习领域的最新的理论基础,并揭示了一条清晰的技术演进路径——从早期的理论模型,到当今驱动大语言模型(LLM)和自主机器人等先进AI产品的核心架构。事实上,强化学习的价值并不在于其算法的精妙,而在于它提供了一个统一的框架,来工程化地构建能够自主行动和适应的系统。这份概览所呈现的,正是一幅关于“智能”如何从理论走向实践的蓝图。Murphy的144页电子书《Reinforcement Learning: An Overview》已收录到 “走向未来”【https://t.zsxq.cozhi’sm/xpWzq】知识星球中。走向未来知识星球中收录了大量的人工智能大模型相关的技术、产品、应用和市场方面的资料,推荐有兴趣的读者加入星球获取资料,学习AI有关的知识。

1.jpg
序贯决策的通用模型与核心挑战
在深入探讨具体算法之前,我们必须首先理解一个通用的智能体-环境交互模型。智能体在每个时间步观察其内部状态,通过其策略(policy)选择一个动作;环境则响应这个动作,并返回一个新的观测,智能体据此更新其内部状态。这个循环的目标是最大化期望的奖励总和。
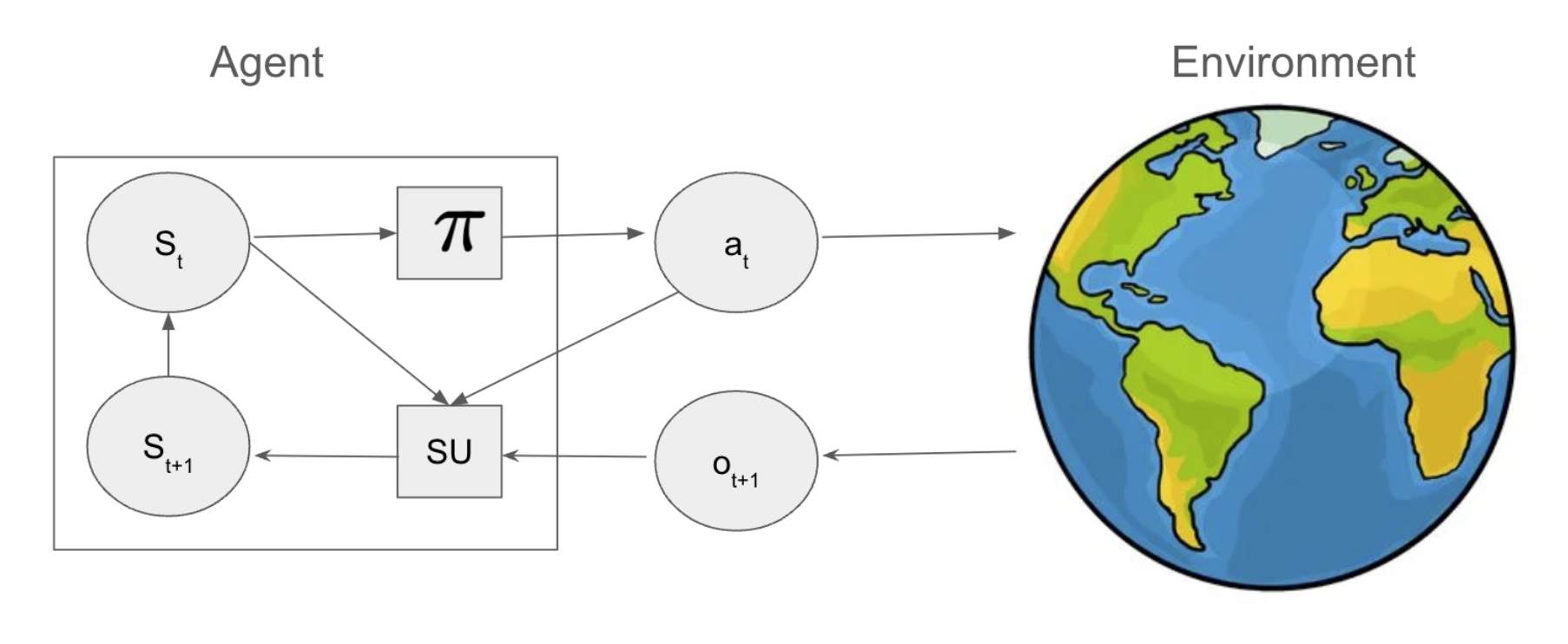
这个简单的循环隐藏着巨大的工程挑战。智能体必须处理“部分可观测性”(POMDPs),即它永远无法完全掌握环境的真实状态,只能依赖有噪声的、局部的观测。这正是现实世界中所有智能产品(如自动驾驶汽车或机器人)面临的困境。智能体的内部状态必须成为其对世界历史的“信念”(belief state)。

2.jpg
更重要的是,智能体面临着“探索-利用权衡”(exploration-exploitation tradeoff)。它必须在“利用”已知的高奖励动作和“探索”未知的、但可能带来更高长期回报的动作之间做出选择。从产品角度看,这是一个关于“短期优化”与“长期价值发现”的根本性权衡。该文件通过贝叶斯方法(如汤森采样)和“面对不确定性的乐观主义”(如UCB算法)来构建解决这一问题的理论基础。这些方法不仅仅是算法,它们是设计智能体在信息不完备时如何获取新知识的策略。
价值与策略:两种核心的智能构建范式
强化学习领域的发展,很大程度上是围绕两种核心范式演进的:学习价值(Value-based)和学习策略(Policy-based)。
基于价值的学习:构建效用地图
基于价值的方法,其核心是学习一个函数,通常称为Q函数(Q-function),来估计在特定状态下采取某个动作的长期期望回报。这好比是为环境绘制一幅“效用地图”。智能体的策略变得非常简单:在任何状态下,只需查看地图,选择通往最高价值的动作。
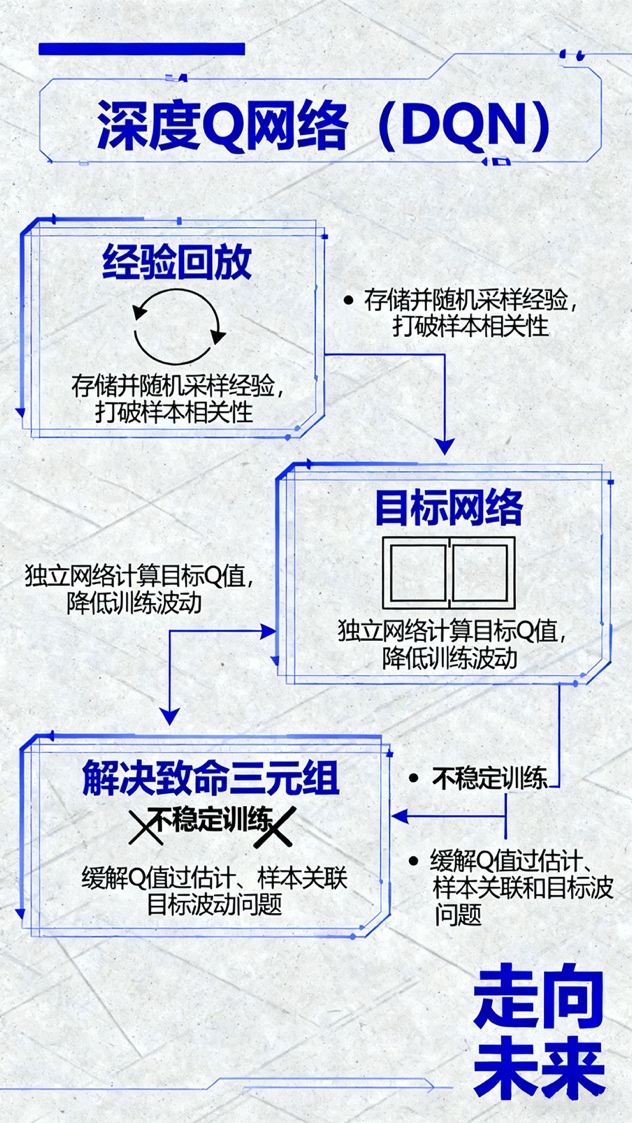
这一范式的顶峰是深度Q网络(DQN)。DQN的突破在于它成功地将高维感知(如原始像素)与动作决策联系起来。然而,正如该文件深入分析的那样,这一突破的背后是解决了严峻的技术挑战。将深度神经网络(一种强大的非线性函数逼近器)与自举(bootstrapping,即用当前的估计值来更新估计值)和离策略(off-policy)学习相结合,会产生一个“致命三元组”(deadly triad),导致训练过程极度不稳定。
3.jpg
从技术架构的角度看,DQN的成功并非源于Q学习本身,而是源于一系列精巧的工程解决方案。其中,“经验回放”(Experience Replay)打破了数据之间的时间相关性,使训练更像传统的监督学习。“目标网络”(Target Networks)则提供了一个稳定的、延迟更新的目标,防止了模型“追逐自己的尾巴”。后续如双重DQN(Double DQN)解决了最大化偏差问题,而彩虹(Rainbow)算法则是这一系列改进的集大成者。这一演进路径表明,基于价值的RL,其核心工程问题是“如何稳定地估计一个递归的价值函数”。
基于策略的学习:直接优化行为
与基于价值的方法不同,基于策略的方法(如策略梯度)不去学习中间的“效用地图”,而是直接参数化智能体的策略(即“演员”,Actor),并优化该策略以直接最大化期望奖励。
这种方法的直接性使其在连续动作空间(如机器人控制)中表现出色,并且可以学习随机策略,这在部分可观测或多智能体环境中至关重要。然而,该文件指出,基础的策略梯度方法(如REINFORCE)面临一个核心困难:高方差。因为奖励信号可能非常稀疏且充满噪声,导致学习信号极其不稳定。
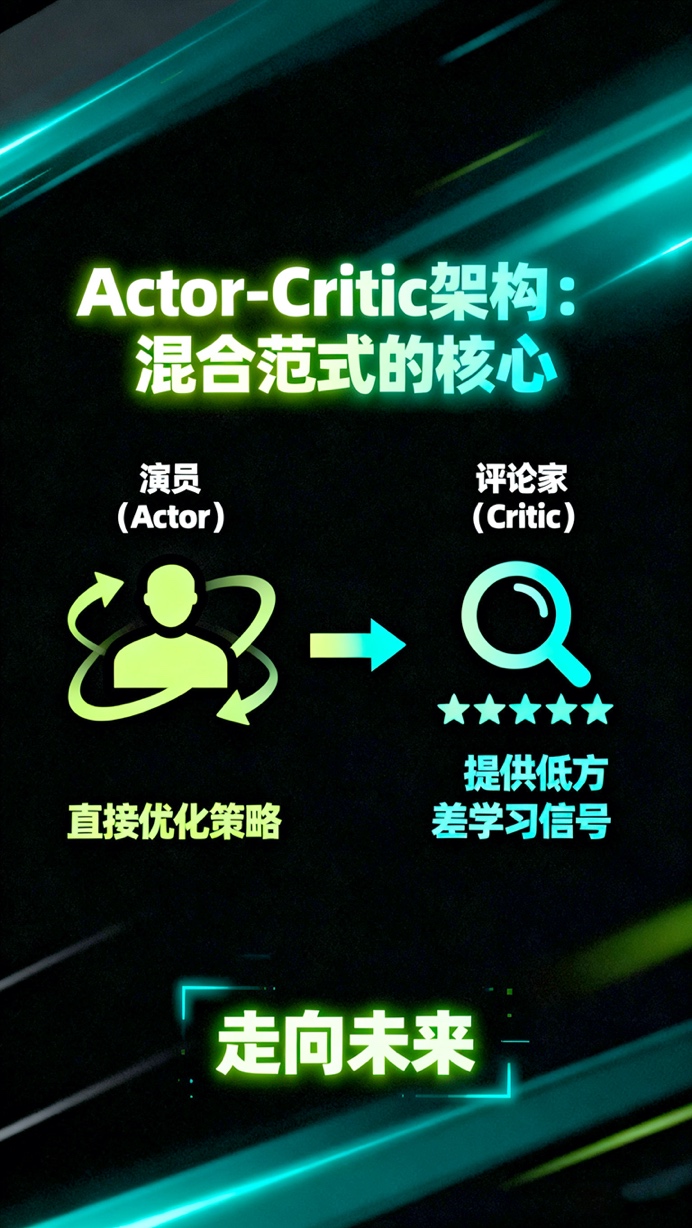
为了解决这个问题,强化学习领域演化出了“演员-评论家”(Actor-Critic, A2C/A3C)架构。这是一种混合范式,它引入了一个“评论家”(Critic)来学习一个价值函数(通常是状态价值V函数或优势函数A函数),其唯一目的是为“演员”提供一个低方差的学习信号。评论家告诉演员,它所采取的动作比“平均水平”好多少(即优势函数),演员则据此调整其行为。
4.jpg
从产品和架构上看,“演员-评论家”模式是强化学习中最重要的设计模式之一。它将问题分解为两个部分:一个负责行动(Actor),一个负责评估(Critic)。这种分离使得系统可以通过一个稳定的内部评估信号来优化一个复杂的外部行为策略。 Murphy在书中详述了PPO(近端策略优化)和SAC(软演员-评论家)等现代算法,都是这一架构的精密变体,它们通过信任区域或最大熵正则化来进一步确保策略更新的稳定性和探索性。
效率前沿:世界模型与模拟的力量
无论是基于价值还是基于策略,上述的“无模型”(Model-Free)方法都有一个致命的弱点:样本效率极低。它们需要数百万甚至数十亿次的交互才能学会复杂的任务。这在虚拟环境(如游戏)中尚可接受,但在现实世界(如硬件机器人或昂贵的市场决策)中是完全不可行的。
因此,该文件将我们引向了强化学习的效率前沿:基于模型的强化学习(Model-based RL, MBRL)。
内部模拟器:世界模型的核心价值
MBRL的核心思想是让智能体学习一个“世界模型”(World Model)——一个关于环境动态(即状态转移)和奖励的内部模拟器。一旦拥有了这个模型,智能体就可以在“想象”中进行规划和策略学习,从而极大地减少对真实世界交互的需求。
从市场和产品的角度看,世界模型是实现资本效率和数据效率的关键。它将感知(学习模型)与决策(使用模型)分离开来。
5.jpg
该文件将MBRL的实践分为两大类:
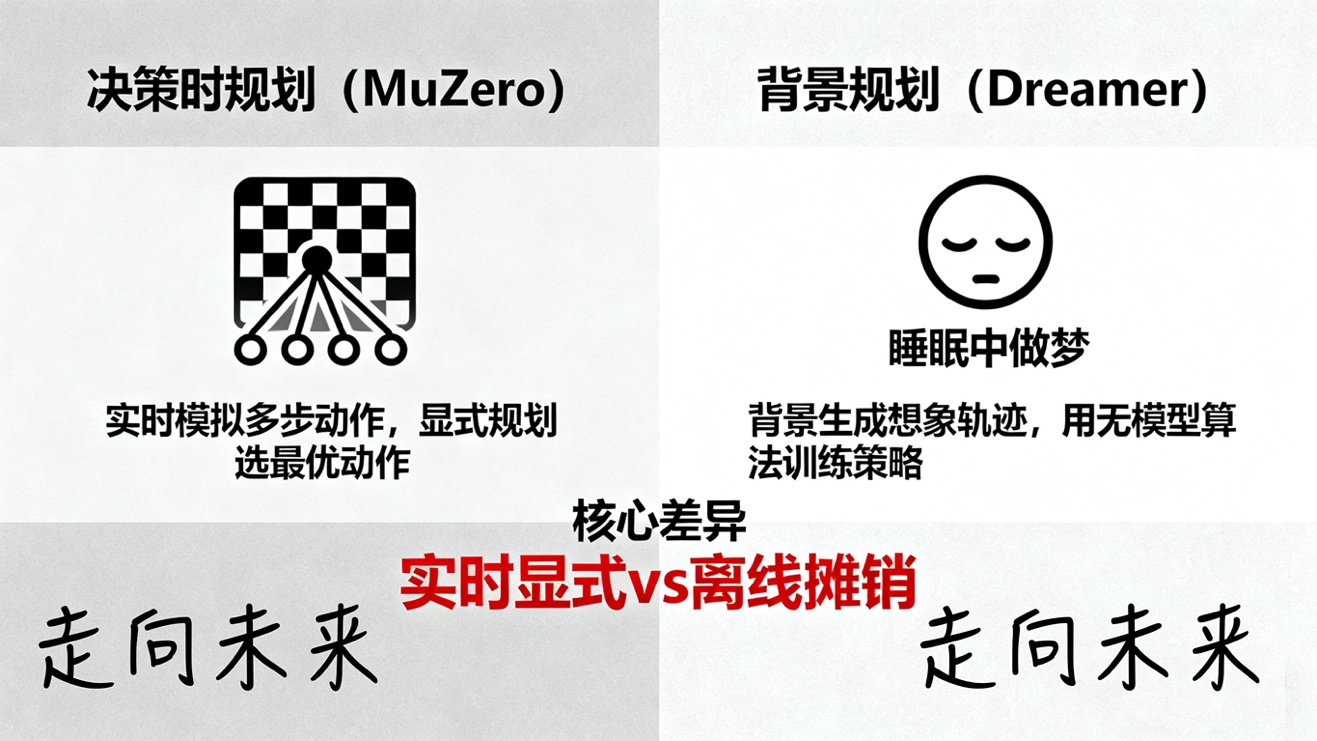
- 决策时规划(Decision-time Planning):以AlphaZero和MuZero为代表。智能体在需要采取行动的“此时此刻”,使用其学到的世界模型,结合蒙特卡洛树搜索(MCTS)等规划算法,向前“看”多步,评估不同动作序列的未来价值,然后选择最佳的起始动作。这是一种审慎的(deliberative)智能,它在每一步都进行显式的未来模拟。MuZero的精妙之处在于,它的世界模型是在一个抽象的潜(latent)空间中学习的,模型只需要预测对规划至关重要的信息(价值、策略、奖励),而无需重构高维的原始观测(如棋盘图像)。
- 背景规划(Background Planning):以Dyna和Dreamer为代表。智能体使用其世界模型在“背景”中(例如在“睡眠”时)生成大量的“想象”轨迹。然后,它使用这些合成数据,通过无模型算法(如Q学习或Actor-Critic)来训练其价值函数或策略。这种方法将昂贵的规划过程“摊销”(amortize)到一个快速、反应式的策略中。Dreamer系列算法是这一思想的极致体现,它在一个潜空间中学习世界模型,并在该潜空间中“做梦”来训练其Actor-Critic策略,实现了在雅达利游戏等复杂视觉任务上的超高样本效率。
抽象的价值:超越像素的预测
MBRL的深入探索揭示了一个更深刻的观点:一个好的世界模型不一定需要是一个能生成逼真图像的生成模型。该文件在第四章末尾讨论的“非生成式世界模型”和“预测性表征”是通往更高效智能的关键。
智能体的最终目标是最大化奖励,而不是完美地预测世界的每一个细节(例如,天空中每一片云彩的运动)。因此,一个更高效的模型应该只预测与未来价值相关的信息。
“价值等价”(Value Equivalence)原则指出,一个好的状态抽象(即世界模型的核心表征)只需要保留区分不同最优Q值所需的信息。基于此,产生了如“后继表征”(Successor Representations, SR)和“后继特征”(Successor Features, SF)等概念。
SFs将Q函数分解为两个部分:一个代表环境动态(SFs, ψ)和一个代表任务目标(奖励权重, w)。即 。这种分解具有巨大的产品价值:智能体可以学习一个通用的、与任务无关的动态模型ψ,然后在面对新任务时,只需快速学习(甚至由人类指定)一个新的、低维的奖励权重w,即可立即泛化。这使得智能体能够“举一反三”,从根本上解决了对多任务的快速适应问题。
通向现实:现代AI产品的应用栈
接下来的重点是如何将上述理论工具组合起来解决构建实用AI产品时遇到的具体挑战,特别是如何处理数据、奖励和大模型。
奖励的困境与离线数据金矿
现实世界的首要难题是“奖励”。在许多应用中,奖励要么极其稀疏(例如,一个机器人只有在最终完成任务时才获得+1奖励),要么难以定义,容易导致“奖励黑客”(Reward Hacking)——智能体以意想不到的、有害的方式最大化了一个不完美的代理奖励。
该文件指出了两个解决方案。首先是分层强化学习(Hierarchical RL, HRL)。HRL将一个复杂的、长期稀疏奖励的任务,分解为一个高层策略(选择子目标)和一个低层策略(实现子目标)的层级结构。例如,“事后经验重放”(Hindsight Experience Relabeling, HER)技术,允许智能体在失败的尝试中也“假装”它实现了某个目标,从而极大地缓解了稀疏奖励问题。
其次是离线强化学习(Offline RL)。这是目前AI领域最具商业价值的方向之一。大多数企业(如电商、金融、制造业)都坐拥海量的历史日志数据,但它们无法承受让一个“在线”智能体在真实生产环境中自由探索的风险。离线RL的目标就是,仅从这些固定的、历史的(通常是次优的)数据集中学习一个高性能的策略。
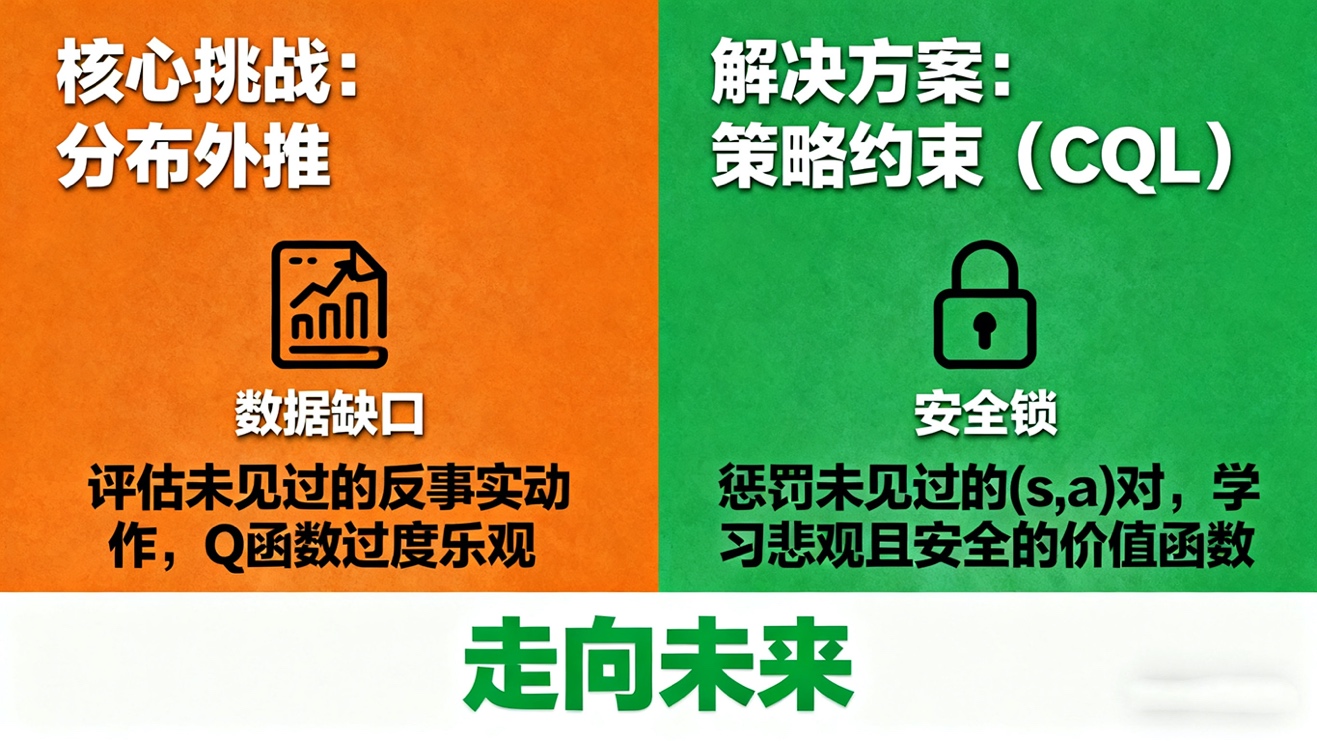
离线RL的核心挑战是“分布外推”(distributional extrapolation)。智能体可能会评估一个在数据集中从未见过的“反事实”动作,而Q函数很可能会错误地(通常是过度乐观地)估计其价值。因此,关键技术是“策略约束”(Policy Constraint)或“保守主义”(Conservatism)。例如,保守Q学习(CQL)通过一个正则化项,惩罚那些在数据集中未见过的(s,a)对的高Q值,迫使智能体学习一个“悲观”的、但更安全的价值函数。这使得从静态数据中提取可靠的决策策略成为可能。
6.jpg
最终的融合:大语言模型与强化学习
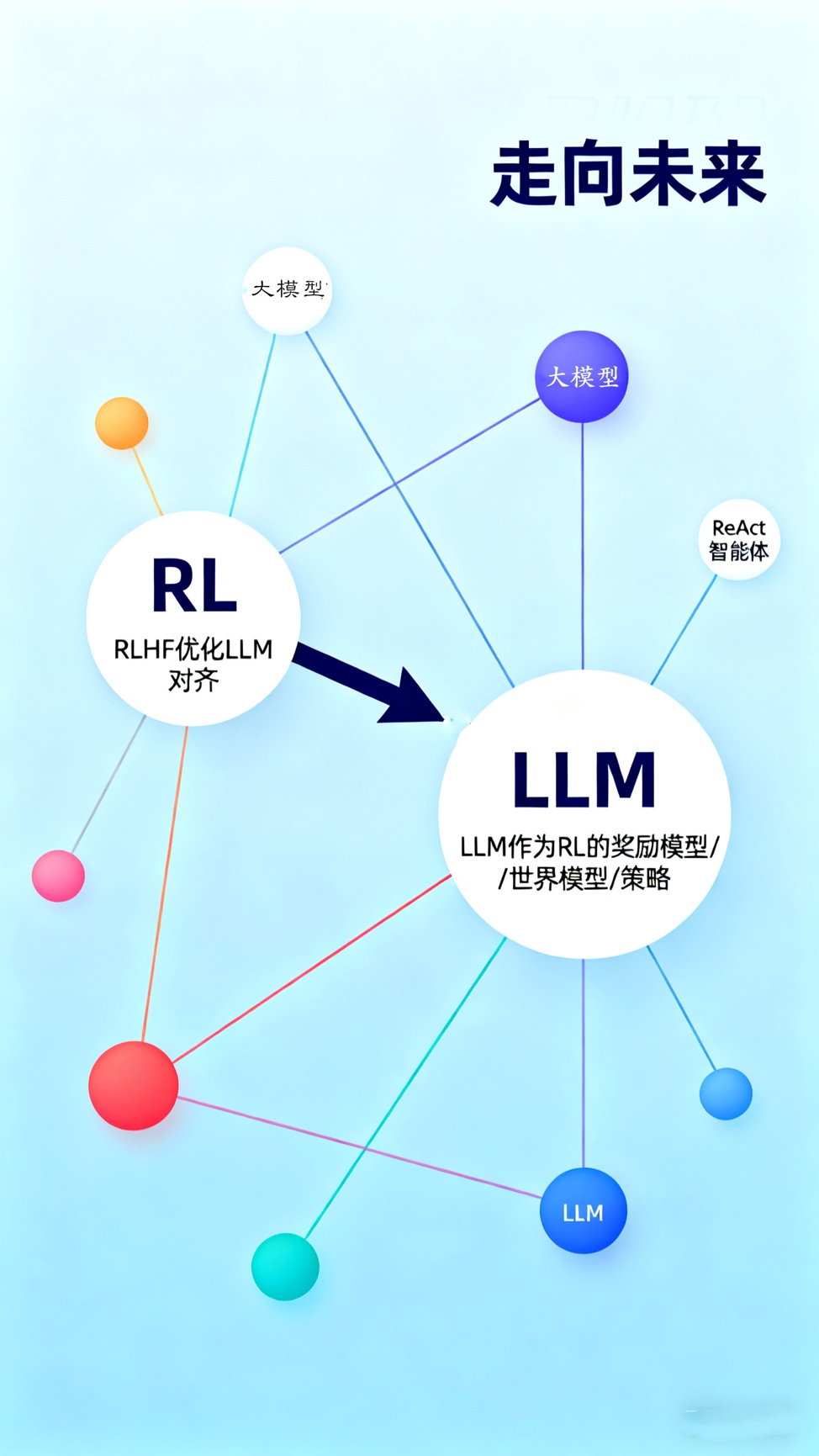
该文件的收尾部分,即“LLMs and RL”,预示了该领域的未来。强化学习与大语言模型的结合是双向的,并且正在定义下一代AI产品的形态。
7.jpg
1. RL for LLMs(用于LLM的RL):这是当今LLM产品(如ChatGPT)的核心技术之一。大模型在经过“行为克隆”(即监督学习)的预训练后,其输出虽然流畅,但并不能保证“有用”或“无害”。“人类反馈强化学习”(RLHF)正是解决这一“对齐”问题的关键。人类评估者对模型的不同输出进行偏好排序,RLHF以此来训练一个“奖励模型”。然后,使用这个奖励模型作为信号,通过PPO、GRPO等策略梯度算法来微调LLM。在这里,RL扮演的角色是一个优化工具,它将一个不可微的、基于人类偏好的复杂目标(“有用且无害”),转化为了一个可优化的策略梯度问题。
2. LLMs for RL(用于RL的LLM):这是构建通用智能体的希望所在。传统的RL智能体缺乏常识和语义理解。而LLM(或视觉语言模型VLM)正好弥补了这一点。该文件指出,LLM可以充当RL循环中的任何一个组件:
- LLM作为奖励模型:LLM可以基于对自然语言目标(例如“整理房间”)的理解,为RL智能体生成密集的、语义丰富的奖励信号。
- LLM作为世界模型:LLM可以利用其从海量文本中提取的因果知识,充当一个“常识性”的世界模型,预测动作在语义层面的后果。
- LLM作为策略:LLM可以直接充当高层策略(如HRL中的管理者)或元策略(metapolicy)。例如,在ReAct或Voyager等智能体系统中,LLM通过“思考”和“行动”的循环来推理,它生成计划,并调用工具(包括低级的RL策略)来执行,然后根据观测结果进行反思和调整。
这一双向融合的趋势,不仅是学术上的热点,更是通往高级AI产品的必由之路。一方面,正如本文所分析的,RLHF已成为优化大模型对齐问题的标准工具(灯塔书《知识增强大模型》第2.3.2节对此有深入论述)。但更具深远意义的,是LLM赋能RL的方向。然而,直接将预训练LLM用作策略或世界模型,会使其“幻觉”和“知识陈旧”(《知识增强大模型》第1.2节)的固有缺陷,在RL的序贯决策循环中被不断放大,这在需要高可靠性的产品中是不可接受的。
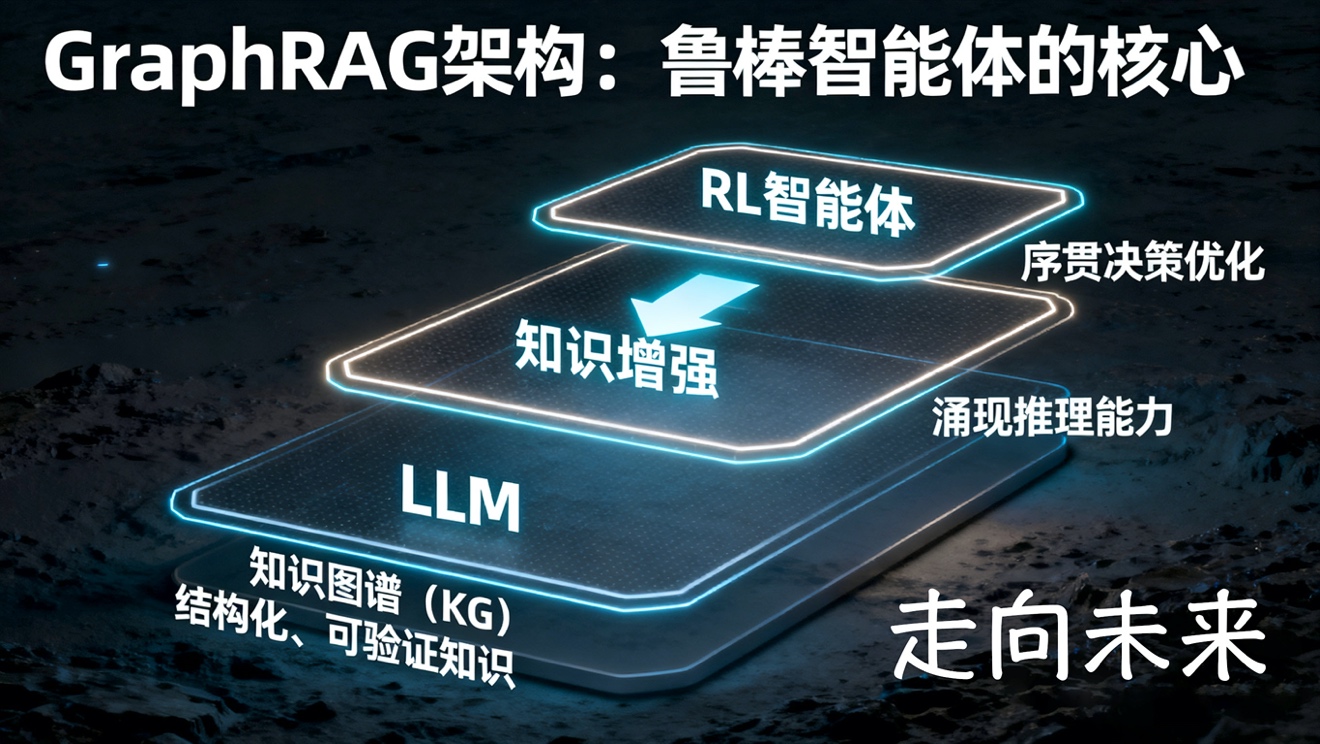
如何构建一个既具备LLM的常识推理能力,又拥有事实准确性和知识可更新性的智能体?高级工程师、AI著名学者专家王文广在其灯塔《知识增强大模型》一书中,为解决这一挑战提供了系统性的工程框架。王文广在书中(第8章)深入探讨了“图模互补”的理念,即必须将大模型强大的涌现推理能力,与知识图谱(KG)所代表的结构化、可解释和可验证的知识体系相结合。
8.jpg
构建一个鲁棒的“常识性”世界模型,不能仅仅依赖LLM的隐式知识,而必须通过知识图谱对其进行显式的“知识增强”(《知识增强大模型》第8.6节)。这种架构,例如GraphRAG(第9章),允许RL智能体在决策时,从一个可验证、可实时更新的知识库中检索精确信息,而不是依赖LLM的内部“幻觉”。这不仅是构建通用智能体的希望,更是确保智能体在金融、医疗等高风险领域安全、可靠运行的实践基石。这种深度融合将RL的优化能力、LLM的推理能力与KG的精确知识结合,构成了下一代智能体的核心技术栈。
这种技术栈的融合与演进,正是通往AGI的必经之路。对于这些前沿话题,包括生成式人工智能、大模型、AIGC、AI芯片和机器人等的产品、技术和应用实践,以及如何使用各种不同的人工智能大模型和智能体来为工作增效,为生活添彩,简单的概览已不足以覆盖其深度。欢迎加入最具价值知识星球“走向未来” (https://t.zsxq.com/xpWzq),与行业专家和同好者们一起深入探讨。立即加入“走向未来”知识星球,一起走向AGI的未来。

9.jpg
结论:一个通往通用智能的工程框架
强化学习已经从一个狭窄的算法领域,演变为一个宏大的、用于构建通用自主系统的工程框架。它的发展历程是一个不断克服核心障碍的旅程:从解决稳定性(如DQN中的致命三元组)和高方差(如Actor-Critic架构)的基础问题;到追求样本效率(如MBRL和世界模型);再到实现安全性和泛化性(如离线RL的保守主义和后继特征的解耦);最终,它与大语言模型相融合,开始解决语义理解和常识推理的问题。
对于AI产品和市场而言,这意味着“智能”不再是一个单一的黑盒。它是一个可以被分解、设计和优化的技术栈。我们可以选择用DQN或SAC训练反应式控制器,用MuZero构建审慎的规划器,用Dreamer训练高效的模拟器,用CQL从历史数据中挖掘策略,并用LLM来指挥和协调这一切。强化学习提供的,正是粘合所有这些组件,使其朝着一个共同目标优化的统一理论和工程实践。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号