CoRL 2025:如何教会机器人“扎马步”?揭秘人形机器人极致平衡的三大核心技术

CoRL 2025:如何教会机器人“扎马步”?揭秘人形机器人极致平衡的三大核心技术

一点人工一点智能
发布于 2025-11-26 16:42:28
发布于 2025-11-26 16:42:28
编辑:陈萍萍的公主@一点人工一点智能
摘要:论文聚焦于人形机器人在极端平衡任务中的控制问题。人类在执行单脚站立、高抬腿等动作时展现出卓越的平衡能力,而将其转化为机器人控制仍面临诸多挑战。
本文指出三个关键障碍:参考运动误差导致的控制不稳定、人机形态差异引发的学习困难,以及传感器噪声与未建模动力学造成的仿真-现实差异。为此,作者提出HuB,一个统一的框架,集成了参考运动优化、平衡感知的策略学习与仿真-现实鲁棒性训练三大模块。该框架在Unitree G1人形机器人上进行了验证,成功实现了如“燕子平衡”和“李小龙踢”等高难度准静态平衡任务。
实验表明,HuB在面对外部干扰时仍能保持稳定,而基线方法则无法完成这些任务。

论文地址:https://arxiv.org/pdf/2505.07294
项目地址:https://hub-robot.github.io/

引言
人形机器人在非结构化环境中实现人类水平的运动能力是机器人研究的核心目标之一。其中,平衡控制是实现这一目标的关键技术。人类平衡依赖于前庭系统、本体感觉与高层规划之间的复杂感觉运动回路,而将其复现到机器人系统中尤为困难。例如,燕子平衡任务要求机器人在单脚支撑的同时保持上身水平伸展,这对全身协调、质心控制与抗干扰能力提出了极高要求。

近年来,基于学习的人形控制方法常采用“跟踪参考运动”的范式,即从人类动作捕捉数据中提取姿态,经重定向后作为机器人参考运动,再通过强化学习训练跟踪策略。然而,该方法在复杂平衡任务中面临三大挑战:参考运动误差、形态不匹配导致的策略学习困难,以及仿真-现实差异。本文针对这些问题提出了相应的解决方案,并构建了HuB框架。

相关工作
2.1 人形平衡控制
传统方法多基于模型控制,如基于反馈的控制策略和优化方法,虽在结构化环境中有效,但对模型精度依赖强,且在不确定环境中表现不佳。近年来,强化学习被广泛应用于步态控制、抗推恢复、站起动作等任务,但多数研究聚焦于动态步态或瞬时稳定,而非极端条件下的持续准静态平衡。
2.2 基于学习的人形控制
学习型方法在人形运动控制中取得了显著进展,涵盖了行走、奔跑、跳跃、舞蹈等多种行为。然而,这些方法多侧重于动态稳定,未深入探讨准静态姿势所需的精确平衡控制。本文则专注于极端姿态下的持续平衡能力。
2.3 仿真-现实迁移
仿真-现实迁移是机器人学习中的经典难题。常见方法包括系统辨识、真实-仿真反馈与领域随机化。然而,在平衡任务中,即使微小的传感器或接触不一致也可能导致系统失稳,现有方法在此类任务中的有效性尚未充分探索。

极端人形平衡学习框架
HuB框架针对前述三大挑战,分别提出了相应的技术模块。整体流程包括从视频中提取人体姿态、重定向为机器人参考运动、基于师生架构的策略学习,以及最终在真实机器人上的部署。
3.1 背景
问题被建模为一个目标条件的马尔可夫决策过程(MDP),其状态空间包括本体感知观测与参考目标状态,动作空间为期望关节角度,由底层PD控制器执行。奖励函数鼓励准确跟踪与稳定控制。整体流程采用师生学习范式:教师策略使用PPO在特权观测下训练,学生策略则通过DAgger从教师中蒸馏,仅使用部署时可用的观测。
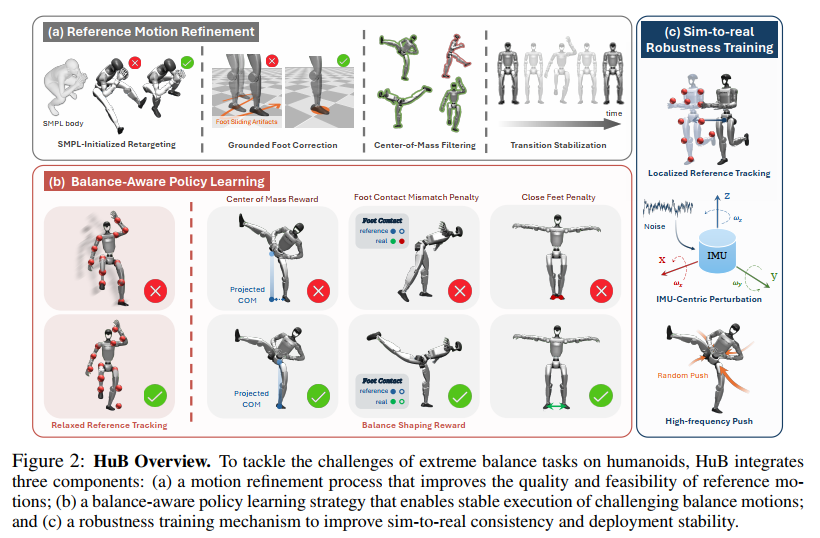
3.2 参考运动优化
参考运动的质量对平衡任务至关重要。本文提出四种优化策略:
· SMPL初始化的重定向:传统方法从零姿态初始化优化,易陷入局部最优。本文利用SMPL模型中的人体欧拉角初始化机器人关节,显著提升收敛速度与精度。
· 接地脚修正:假设在单脚支撑阶段,支撑脚应保持静止。通过调整全局根位置而保持局部关节角不变,消除脚部滑动现象。
· 质心滤波:基于URDF模型计算机器人质心,过滤掉质心投影偏离支撑脚中心超过0.2米的轨迹,确保运动可行性。
· 过渡稳定化:在平衡阶段前后延长双足支撑阶段,复制首尾帧以增加稳定时间,提升策略学习与部署时的过渡可靠性。
3.3 平衡感知的策略学习
为解决形态不匹配与平衡行为缺乏结构化指导的问题,本文提出松弛参考跟踪与平衡塑造奖励:
松弛参考跟踪:在奖励函数中设置较大容忍度(σ=0.6米),允许策略在必要时偏离参考轨迹以维持平衡。
平衡塑造奖励:包括三项设计:
• 质心奖励:鼓励质心垂直投影落在支撑多边形内;
• 脚部接触失配惩罚:防止非支撑脚意外触地;
• 脚部间距惩罚:避免双脚过近导致碰撞或稳定性下降。
3.4 仿真-现实鲁棒性训练
为应对传感器噪声与未建模动力学,本文提出三种训练机制:
· 局部参考跟踪训练:在训练与部署中均不使用里程计信息,将所有跟踪目标转换至机器人局部坐标系,避免VIO噪声带来的不一致性。
· IMU中心观测扰动:对IMU提供的根姿态(欧拉角)施加Ornstein-Uhlenbeck噪声。所有观测基于扰动后的姿态计算,模拟真实IMU噪声的时序相关性与结构依赖性。
· 高频推力扰动:在训练中每1秒对机器人根速度施加小幅度(最高0.5 m/s)、高频率的随机扰动,模拟现实中因未建模动力学引起的微小振荡,增强策略的抗干扰能力。

实验
实验旨在回答三个问题:HuB在极端平衡任务中的表现如何?各组件对其性能的贡献如何?方法能否成功迁移至现实世界并具备鲁棒性?
4.1 实验设置
环境与任务:在Unitree G1机器人上评估六种平衡任务,包括燕子平衡、李小龙踢、哪吒姿势等。仿真实验在IsaacGym中进行,测试时施加随机推力与IMU噪声。
评估指标:分为三类:
• 任务完成度:包括接触失配帧数、成功率;
• 稳定性:包括脚部滑动速度、双脚离地帧数、动作变化率;
• 跟踪误差:包括位置、速度、加速度的全局或局部误差。
· 基线方法:包括H2O与OmniH2O,均使用相同运动数据与关键点进行训练。
4.2 仿真结果
HuB在所有任务中均达到100%成功率,而基线方法因非支撑脚意外触地或失稳而失败。HuB在滑动、离地时间与动作变化率等稳定性指标上均优于基线。
· 松弛跟踪的消融实验:较小的σ(0.3米)导致跟踪误差小但稳定性差;过大的σ(1.2米)则导致跟踪误差显著上升。σ=0.6米在跟踪精度与稳定性之间取得最佳平衡。
· 塑造奖励的消融实验:移除质心奖励导致滑动与离地时间增加;移除接触惩罚导致接触失配显著上升;移除脚部间距惩罚则降低整体稳定性。
· 鲁棒性训练的消融实验:
☉ 使用全局跟踪训练会导致训练-部署不一致,性能下降;
☉ 移除IMU噪声注入使策略对噪声敏感;
☉ 移除高频推力或改用低频大推力(如每5秒1米/秒)均降低稳定性,尤其在可行区域狭窄的任务中。
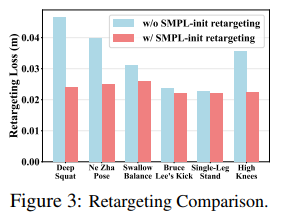
· 重定向效果验证:SMPL初始化在500步优化后损失显著低于零初始化,尤其在深蹲任务中表现突出。
4.3 现实世界结果
· 平衡性能:HuB成功完成所有任务,机器人姿态稳定、动作流畅。基线方法在燕子平衡中失稳,在李小龙踢中抖动严重,在哪吒姿势中放弃抬腿以降低风险。
· 鲁棒性评估:
☉ 外部扰动:在机器人执行平衡时用力踢足球撞击,HuB能快速恢复稳定;
☉ 长时任务执行:HuB在单次运行中连续完成10次李小龙踢动作,无需重置或干预。


结论
HuB是一个针对极端平衡任务的统一学习框架,通过系统解决参考运动不准确、平衡策略学习困难与仿真-现实差异三大挑战,使人形机器人能够稳定执行高难度平衡姿势。该方法在仿真与现实中均表现出色,并具备较强的抗干扰与长时任务执行能力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号