从数据到业务,认识 Palantir 理念与实践

从数据到业务,认识 Palantir 理念与实践

数据存储前沿技术
发布于 2025-11-20 13:55:51
发布于 2025-11-20 13:55:51
全文概览
在AI大模型浪潮席卷企业运营的今天,技术从业者面临两大核心挑战:如何确保AI的输出不产生“幻觉”而脱离业务现实?以及,如何将AI安全、合规地嵌入到复杂的企业决策流程中?传统的BI和数据湖架构,在“洞察”与“行动”之间存在着难以逾越的鸿沟。
Palantir公司凭借其Foundry和AIP(人工智能平台)的独特组合,提供了一种颠覆性的解决方案。Foundry的核心——本体论(Ontology),为企业构建了一个动态、受治理的“数字孪生”,它不仅描述了业务的静态结构,更模拟了业务的动态运营流程。AIP则将LLM等模型“锚定”在这个数字孪生之上,通过“人在回路”机制,实现了从受治理数据到智能行动的闭环。
这种架构如何从根本上解决AI的“锚定问题”?它又如何将数据治理从AI的障碍转变为其安全、有效运行的前提?本文将深度解析Palantir Foundry与AIP的共生协同,揭示其如何重塑企业AI运营的未来。
阅读收获
- 理解“运营与语义层”的战略定位:Foundry并非与Databricks/Snowflake竞争,而是定位在它们之上的“运营与语义层”,通过本体论将底层数据与业务行动连接,提升整个数据栈的价值。
- 掌握AI“锚定”与治理机制:学习Foundry如何通过本体论和PBAC(基于目的的访问控制),为AIP提供安全、可信的上下文,从架构层面解决LLM的“幻觉”和合规性问题。
- 构建“闭环运营”的反馈机制:理解“人在回路”不仅是安全机制,更是数据捕获机制。决策结果被写回Foundry,形成“飞轮效应”,持续优化AI模型和本体论,实现组织自我完善。
- 数据治理的“预防性”架构:分析Foundry如何通过不可变的自动数据血缘和多模态安全传播,实现“事前预防”而非“事后侦测”的治理模式,为构建可解释AI(XAI)提供数据基础。
👉 划线高亮 观点批注

本报告旨在对 Palantir 公司的两大核心产品——Foundry 和人工智能平台(AIP)——进行全面而深入的分析。报告的核心论点是,Palantir 的主要价值主张并非仅仅在于提供数据集成或 AI 建模工具,而在于为企业构建一个闭环的、以决策为中心的操作系统。这一目标的实现,依赖于 Foundry 的本体论(Ontology)数据基础与 AIP 的受治理 AI 执行层之间独特的共生关系。
分析表明,Foundry 通过其核心的本体论,为企业构建了一个动态的、可操作的“数字孪生”(Digital Twin),将分散、原始的数据转化为对业务世界的结构化、语义化理解。(这和 Sean Falconer[9] 在Cube 专栏中提及的从业务到元数据感知的架构设计不谋而合)在此基础上,Foundry 实施了一套架构级的、预防性的数据治理框架,该框架通过多模态安全控制(角色、分类、目的)和不可变的自动数据血缘,确保了数据的可信、合规和安全。这为所有后续的分析和 AI 应用奠定了坚实的基础。
AIP 则构建于 Foundry 这一坚实基础之上,其设计初衷是解决企业 AI 面临的关键“最后一公里”问题——即如何将智能洞察安全、可靠地转化为可审计、可衡量的运营行动。AIP 通过将大型语言模型(LLM)及其他 AI 模型“锚定”在 Foundry 的本体论上,从根本上解决了 AI 的“幻觉”和“脱离现实”问题。同时,其“人在回路”(Human-in-the-Loop)的设计理念,不仅确保了 AI 部署的安全性和道德性,更创造了一个持续学习的反馈机制,将人类专家的决策经验重新捕获为数据,不断优化模型和运营流程。
综上所述,Foundry 和 AIP 的结合,形成了一个强大的“飞轮效应”。数据治理不再是 AI 应用的障碍,而是其安全、有效运行的前提。AI 的应用反过来又丰富了数据资产,提升了运营决策的质量。这种从受治理的数据到智能行动,再到捕获决策反馈的闭环系统,为企业在日益复杂的环境中实现真正的、由数据和 AI 驱动的运营转型,提供了独特的、战略性的解决方案。
第一部分:基石 – 用于数据运营的 Palantir Foundry 架构
本部分将解构 Foundry 的核心架构,阐述其如何创建一个稳定、集成且受治理的数据生态系统。这个生态系统是所有后续分析和人工智能应用赖以生存的基石。
1.1 本体论核心:定义企业数字孪生
Foundry 的核心竞争力与根本性差异化优势在于其本体论(Ontology)。它远非一个简单的数据目录或语义层,而是一个活跃的、动态的企业数字孪生 1。本体论的核心任务是将来自异构数据源的原始数据,映射为真实世界的业务概念,包括对象(如工厂、客户、产品)、对象的属性,以及对象之间的关系(链接)2。
这一模型不仅包含了企业的“语义”(semantics),即对象及其关系,还包含了企业的“动力学”(kinetics),即定义业务如何运转的函数(Functions)和行动(Actions)4。这意味着本体论不仅描述了业务的静态结构,更模拟了业务的动态运营流程。这种设计对于后续 AI 能够采取有意义的、符合业务逻辑的行动至关重要。例如,一个“更新库存”的行动,在本体论中被明确定义,它关联了“产品”对象、“仓库”对象,并包含了执行该行动所需的所有业务规则和权限检查。
在技术后端,本体论由一系列协同工作的服务提供支持,包括定义实体元数据的本体论元数据服务(Ontology Metadata Service, OMS)、用于存储和索引对象数据以实现快速查询的对象数据库(如 Object Storage V2),以及负责处理所有读取请求的对象集服务(Object Set Service, OSS)2。这套架构专为满足运营场景中对高性能和可扩展性的严苛要求而设计。
通过创建这一通用的业务逻辑层,本体论在数据团队、分析团队和运营团队之间架起了一座桥梁,打破了传统的组织孤岛,实现了决策的协调统一 3。它为整个企业提供了一个“类型系统”(type system),这对于将 AI 模型的能力“锚定”于业务现实,防止其产生脱离实际的输出,具有不可或替代的价值 4。
1.2 开放与自适应集成:连接企业数据经纬
Foundry 的设计哲学是与企业现有的数据基础设施集成,而非完全取代 5。Palantir 深刻认识到,企业在数据湖、数据仓库和各类应用系统中已经进行了大量投资。因此,“自适应集成”(Adaptive Integration)成为其平台架构的核心支柱之一 5。
为适应不同企业的数字化成熟度,Foundry 提供了多种灵活的部署模式:
- Foundry 扩展数据平台:这是最常见的模式。Foundry 部署在现有的数据湖或数据仓库之上,仅将运营工作所需的数据同步至平台,并将分析和决策产生的结果双向写回,从而保护了企业现有“单一事实来源”(sources of truth)的完整性 5。
- Foundry 驱动数据平台:利用 Foundry 超过 200 个开箱即用的数据连接器,企业可以加速构建新的数据平台。此模式下,Foundry 承诺使用开放标准和非专有数据格式,从根本上避免供应商锁定 4。
- 全栈式 Foundry:对于那些尚未建立成熟数据基础设施的组织,Foundry 也可以作为一套端到端的解决方案进行部署,提供从数据连接、集成到模型构建的全套能力 5。
在连接性方面,平台不仅提供了超过 200 个原生连接器 4,还广泛支持 REST 和 JDBC 等行业标准协议 6,并且能够无缝连接部署在云端、本地乃至边缘设备上的各类系统 6。这种广泛的连接能力确保了 Foundry 能够统一几乎所有来源的数据,包括通过 MQTT 和 Kafka 协议传输的实时流数据 7。
互操作性和避免供应商锁定是贯穿 Foundry 设计始终的主题。平台内的数据转换任务均使用开源计算引擎(如 Spark 和 Flink),并支持 Python 和 SQL 等主流编程语言。所有集成的数据都以开放的、行业标准的格式存储 5。近年来,Palantir 与 Databricks 和 Snowflake 等行业领导者建立的战略合作伙伴关系,进一步彰显了其对开放性的承诺,实现了平台间的双向、零拷贝数据互操作性,用户可以在不移动数据的情况下,利用各自平台的优势 9。
1.3 数据转换与流水线:从原始数据到可操作资产
Foundry 将“视数据为代码”(Treat Data Like Code)的理念引入数据工程领域,将软件开发的最佳实践应用于数据流水线的构建与管理 4。这包括对数据转换逻辑进行版本控制、分支、合并以及完整的变更管理。开发者可以在一个隔离的“沙箱”分支中进行开发和测试,并通过影响分析和严格的发布审查流程,充满信心地将变更部署到生产环境 11。
为了服务于不同技术背景的用户,Foundry 提供了一系列梯度化的工具。数据工程师可以使用功能强大的代码工作簿(Code Workbooks),在其中运用 PySpark、R 和 SQL 进行复杂的编程 4。数据分析师则可以利用低代码/无代码的图形化工具(如 Preparation、Contour)进行敏捷的数据准备和探索 4。此外,可视化的流水线构建器(Pipeline Builder)进一步降低了构建复杂数据处理流程的门槛 13。
平台内置了一个智能的、与计算引擎无关的构建系统,能够自动跟踪所有数据流水线的状态,并仅对发生变化的部分执行增量刷新,极大地提升了效率和资源利用率 4。数据健康监控是平台不可或缺的一部分,提供了丰富的预置检查规则和自定义检查能力。这些健康检查与平台的数据血缘系统深度集成,一旦发现数据质量问题,系统可以立即进行影响分析并向上游负责人发出警报,从而实现主动、高效的数据质量管理 4。
从更深层次分析,Palantir 的架构设计实现了一个根本性的转变:从以“数据”为中心,转向以“决策”为中心。传统的数据湖和数据仓库本质上是数据存储和处理的中心,业务逻辑需要在使用时被强加于数据之上。Palantir 则颠覆了这一模式。本体论的设计起点是业务流程本身——即企业需要做出何种决策,然后反向映射支撑这些决策所需的数据 2。这一看似微妙的差异,却带来了深远的架构影响。它意味着进入 Foundry 的每一份数据,都已经被赋予了运营场景下的业务上下文。这直接构成了 AIP 发挥效能的基础,因为 AI 无需从零开始“学习”业务,它直接继承了在本体论中被精确定义的、经过验证的业务模型 7。
同时,Palantir 对“开放性”的强调,可以被视为对其早期市场形象的一种战略性回应。过去,市场上存在对 Palantir 平台“黑箱”或导致“供应商锁定”的批评声音 8。如今,其官方文档中大量关于使用开源引擎 5、开放数据格式 5 以及支持将转换逻辑迁出平台 8 的详细说明,构成了对这一批评的有力反驳。与 Databricks 17 和 Snowflake 10 的合作,更是将这一开放战略推向了极致。这揭示了 Palantir 的更高层战略意图:它并非要与现代数据栈的其他组件直接竞争,而是要将 Foundry 定位为一个不可或缺的、位于现代数据栈之上的“运营与语义层”。通过将底层平台的数据与真实的业务行动联系起来,Foundry 提升了这些平台本身的价值。
Palantir 将原始的大数据处理升级到AI运营,融合早期大数据的工具链。
第二部分:强制信任与合规 – Foundry 中的数据治理
本部分将深入剖析 Foundry 的数据治理功能。 报告认为,治理在 Foundry 中并非一个附加模块,而是一项贯穿始终的基础性架构原则。
2.1 多层安全范式:角色、分类与目的驱动的访问控制
Foundry 的安全模型是多模态的,它超越了传统的基于角色的访问控制(Role-Based Access Control, RBAC)。该模型将 RBAC 与基于分类的控制(Classification-based,例如为数据打上“个人身份信息 PII”、“机密”等标记)以及一种更为关键的、基于目的的访问控制(Purpose-Based Access Control, PBAC)有机地结合在一起 4。
基于目的的访问控制(PBAC)是 Foundry 在数据治理领域的一大核心差异化特性。它允许数据治理管理员预先定义一系列合法的、经批准的数据使用“目的”(Purpose)。当用户需要访问敏感数据时,他们必须明确选择并提供访问数据的正当理由,即他们正在执行哪一项预先批准的业务任务 3。这一机制提供了一个极其精细且可全面审计的控制层,确保了数据访问行为与合法的业务需求严格对齐,这对于满足如 GDPR 等现代数据保护法规中的“目的限制”原则至关重要。
这些安全控制策略并非孤立或需要手动应用的。一旦在数据的源头定义,它们就会沿着整个数据血缘图谱被默认继承和传播 4。这意味着,如果一个新数据集是从一个受保护的敏感数据源派生而来的,它将自动继承所有必要的安全标记和访问限制。平台的安全引擎和血缘引擎协同工作,在架构的每一个层级上,持续、一致地强制执行这些治理策略,确保了治理的全面性和无死角 11。
2.2 不可变血缘与审计:实现端到端的数据透明度
与那些依赖定期爬取元数据来“猜测”数据血缘关系的系统不同,Foundry 的数据血缘是“主动的”(active)和“自动生成的”(automatically generated)11。平台上的每一次数据转换、查询、分析乃至最终的业务行动,都会被系统作为一个不可变的事件自动捕获。这个事件记录了所有相关的上下文信息,包括执行操作的用户、使用的代码、输入的数据集、运行时的环境等 4。
这个完整、可交互的数据血缘图谱赋予了企业强大的治理能力。首先是“影响分析”:在对上游数据或逻辑进行任何修改之前,开发者可以精确地预知该变更将对下游的所有数据资产和应用产生何种影响,从而避免意外的生产事故 4。其次是“精细化使用分析”:管理员可以准确地追溯任何数据被谁、在何时、出于何种目的所访问,这为实现 PBAC 和进行安全审计提供了坚实的技术基础。
平台提供了强大的安全审计日志功能,为所有在平台上的活动都创建了详尽的、不可篡改的历史记录 12。这对于满足监管机构的合规要求至关重要。更进一步,这种彻底的审计能力是构建可信 AI 系统的基石。因为 AIP 驱动的每一个行动,都可以通过血缘链条被追溯到其所依赖的源数据、处理逻辑以及 informing 它的模型,实现了从数据到决策的全链路透明 20。
2.3 主动式数据质量与生命周期管理
在 Foundry 中,数据质量管理并非一个独立于数据处理流程之外的步骤,而是一套深度集成的内置能力。用户可以通过简单的点击配置或编写代码的方式,为数据资产定义健康检查规则。这些规则会在数据更新时被自动、持续地执行 4。当检测到数据质量问题时,警报系统会与数据血缘系统联动,帮助用户快速定位问题的根源。
Foundry 还包含一系列工具,用于主动识别和保护敏感数据。例如,敏感数据扫描器可以自动检测数据集中潜在的个人身份信息(PII)或其他敏感信息。而 Cipher 等加密工具,则可以在不影响数据使用的情况下,对特定的数据列进行加密处理。这意味着,授权的应用可以在运行时解密数据进行计算,但数据在存储和传输过程中始终保持加密状态,从而在可用性和安全性之间取得了平衡 18。
平台还提供了精细化的数据生命周期管理功能。数据所有者可以根据业务规则或法规要求,配置灵活的数据保留和删除策略。这些策略可以被自动执行,确保数据不会被无限期保留,从而降低了数据泄露的风险并满足了合规要求 5。
表格 1:Palantir Foundry 核心数据治理能力一览
能力 (Capability) | 技术机制 (Mechanism) | 业务/合规成果 (Business/Compliance Outcome) |
|---|---|---|
基于目的的访问控制 (PBAC) | 用户在访问数据时,必须从预先批准的列表中选择一个“目的”作为理由。该选择被记录并可审计。 5 | 强制执行数据使用的“目的限制”原则(如 GDPR 要求);为监管机构提供访问合法性的可审计证据。 |
不可变的自动血缘 (Immutable Lineage) | 平台自动捕获每一次数据操作(转换、查询、应用)的元数据,构建一个完整的、不可篡改的血缘图谱。 4 | 实现完全的端到端可审计性;支持精确的变更影响分析;为 AI 决策提供可解释性的数据基础。 |
多模态安全传播 (Multi-Modal Security) | 将角色、分类标记和目的控制相结合。安全策略在定义后,会沿着数据血缘自动向下游传播和继承。 4 | 确保治理策略的一致性和全面性,防止安全漏洞;从架构层面降低数据治理的复杂性和人为错误。 |
集成的数据健康监控 (Embedded Data Health) | 允许用户通过代码或 UI 定义数据质量检查规则,这些规则与数据流水线绑定,并与血缘和警报系统集成。 11 | 将数据质量管理从被动响应转变为主动预防;加速问题根源的定位和修复,提升数据可信度。 |
敏感数据生命周期管理 (Lifecycle Management) | 提供工具扫描和识别敏感数据,并通过 Cipher 进行列级加密。支持配置自动化的数据保留和删除策略。 18 | 保护敏感数据,降低泄露风险;自动化合规流程,确保满足数据保留期限的法规要求。 |
深入分析 Foundry 的治理模型,可以发现其在架构设计上是“预防性”的,而非仅仅是“侦测性”的。许多传统的数据治理工具,其工作模式是在违规行为发生后,通过扫描日志等方式进行侦测和告警。Foundry 的架构则旨在从根本上防止违规行为的发生。其安全与血缘系统的紧密耦合 11,意味着访问控制规则不再是存储在某个独立系统中的策略,而是数据资产本身的一种内在属性,这种属性会随着数据的流动而自动传播。一个没有获得特定“目的”授权的用户,在架构层面就无法查询相关数据,系统甚至不会执行这个查询请求 4。与“事后侦测”模型相比,这种“事前预防”的模式从根本上降低了企业的合规风险。
此外,全面而自动化的数据血缘,是实现可信 AI 最为关键的技术前提。关于“可解释 AI”(XAI)的讨论,往往集中在模型内部的算法透明度上。然而,Palantir 的实践表明,真正的可解释性始于数据。正是因为 Foundry 提供了不可变的、端到端的数据血缘 4,任何由 AIP 模型产生的输出——无论是预测、建议还是行动——都可以被精确地追溯其信息来源。我们可以沿着血缘链条,回溯到每一个数据转换步骤、其所依赖的原始数据、编写这段逻辑的工程师,以及执行时的具体版本 20。这为驱动 AI 的信息提供了一条完整的、可审计的“监管链”(chain of custody)。对于企业治理而言,这种对数据来源和处理过程的确定性,其重要性甚至超过了对模型内部权重和偏置的数学解释。
第三部分:激活智能 – 人工智能平台 (AIP)
本部分将聚焦于用户查询的第二部分,阐述 AIP 如何在 Foundry 坚实的数据和治理基础之上,实现 AI 在企业运营场景中的安全、有效应用。
3.1 连接生成式 AI 与运营:AIP 的核心架构
AIP 的核心使命是“将生成式 AI 与运营连接起来” 1。它被设计成一个“AI 网格”(AI Mesh),能够交付从大型语言模型(LLM)驱动的 Web 应用,到部署在边缘设备上的视觉语言模型等全方位的 AI 产品 1。
AIP 的一个核心功能是提供了一个统一、安全的接口,用于集成和管理各种商业或开源的大型语言模型 12。它扮演着一个安全中间件的角色,确保企业数据在被发送给外部模型进行处理时,严格遵守 Foundry 中定义的各项安全和治理策略 20。AIP 的架构内置了安全护栏,例如,它可以根据数据的分类标记(如“机密”)来限制模型与特定数据的交互方式,从而保护敏感信息不被泄露 21。
为了满足生产级 AI 工作负载对稳定性和扩展性的要求,AIP 的后端构建在一个高可用、冗余的微服务架构之上。整个平台的部署、升级和运维由 Palantir 自主研发的 Apollo 软件交付系统进行自动化管理 1。这确保了平台能够实现零停机升级和根据负载自动伸缩,这对于保障关键业务中 AI 应用的连续性至关重要。
3.2 AI 构建者工具箱:从低代码逻辑到智能体工作流
AIP 提供了一套完整的工具,旨在降低 AI 应用的开发门槛,同时满足专业开发者对灵活性和控制力的需求。
- AIP Logic:这是一个专为构建、测试和发布由 LLM 驱动的函数而设计的无代码/低代码开发环境 1。它使得业务分析师等非技术用户也能够通过图形化界面,进行提示词工程(prompt engineering),并将 AI 模型与 Foundry 本体论中的对象和行动链接起来,而无需编写复杂的 API 调用代码。这极大地加速了 AI 功能的原型设计和迭代速度 20。
- AIP Agent Studio & Workflow Builder:这些工具用于创建更为复杂的 AI 智能体(Agent)和自动化工作流。开发者可以为 AI 智能体配备一系列“工具”,而这些工具就是 Foundry 本体论中定义的、能够对现实世界产生影响的“行动” 20。这使得 AI 的能力从简单的信息问答,跃升到了能够执行具体业务任务的、由行动驱动的逻辑和自动化。
- AIP Evals:这是将 AI 应用从实验推向生产的关键组件。它提供了一个严谨的评估框架,用于对不同 LLM 在特定任务上的表现进行基准测试和持续监控 12。组织可以利用 AIP Evals 来量化模型的性能、监控模型随时间推移可能出现的“漂移”(drift)现象,并充满信心地选择和部署最适合业务需求的 AI 模型 20。
- AIP Assist:这是一个由 LLM 驱动的、深度集成在整个 Palantir 平台中的“智能副驾”(copilot)。它在各种场景下为用户提供帮助,例如,在代码仓库中解释复杂的代码逻辑、在数据流水线构建器中自动生成转换步骤,或者在本体论管理器中为出现的错误提供修复建议,从而全面提升平台使用者的工作效率 13。
3.3 人在回路:确保安全、合规和受治理的 AI 部署
将人类置于“回路之中”(in-the-loop)或“回路之上”(on-the-loop)是 Palantir AI 哲学的核心原则 14。在该设计理念下,AI 系统不会在没有人类监督的情况下自主执行关键操作。
其实现机制通常是设计一种人机协同的工作流。在这种工作流中,AI 负责分析情况并“提议”(propose)解决方案或下一步行动,然后这些提议会被提交给相应的人类操作员进行审查和批准 24。这种协同模式确保了 AI 的智能分析能力能够被充分利用,同时最终的决策权仍然掌握在人类专家手中,保障了操作的安全性和可靠性。
为了实现有效的监督,平台为人类操作员提供了对 AI 驱动的自动化流程的完全透明度。他们可以清晰地看到自动化的执行规则、完整的历史记录以及其背后的决策逻辑 24。平台内置的详细活动监视器会捕获所有用户与 AI 的交互,包括输入的提示、模型的响应以及最终的决策。这使得每一个由 AI 驱动的行动,都能够无缝地映射回驱动它的数据和逻辑,Palantir 强调这对于“安全和合乎道德地使用大型语言模型”是“至关重要的” 21。
从架构层面看,AIP 的设计旨在系统性地解决 AI 领域的“锚定问题”(grounding problem)。大型语言模型的一个主要缺陷是“幻觉”(hallucination)——即生成看似合理但实际上不正确或凭空捏造的信息。其根本原因在于模型缺乏与可验证的、权威的事实来源的连接。AIP 的整体架构正是为了应对这一挑战。通过强制所有 AI 与业务的交互都必须通过本体论这一中介层 1,AIP 确保了 AI 的所有推理和行动都“锚定”在企业特定的、经过治理的、高度结构化的数字孪生之上。AI 不再是基于开放互联网的无边界信息进行回答,而是在一个精确的、反映企业真实运营状况的业务模型上进行推理。与简单的、基于文档的检索增强生成(RAG)技术相比,这是一种在鲁棒性和安全性上都远胜一筹的解决方案。
此外,“人在回路”的设计不仅仅是一项出于安全或道德考量的功能,它更是一种至关重要的数据收集机制,是构建学习型组织的技术基础。当一名经验丰富的操作员批准或否决了 AI 的某项建议时 24,这个决策本身就是一条极具价值的新数据。它蕴含了人类专家的隐性知识和判断。这个决策及其上下文会被平台捕获并写回 Foundry 3。这就创造了一个强大的反馈闭环。这些反馈数据不仅可以用于微调 AI 模型,使其未来的建议更加精准;更重要的是,它可以用来更新和完善本体论本身,用最新的运营知识来迭代企业的数字孪生。其产生的涟漪效应是,这个系统不仅提升了 AI 的智能,更提升了组织对其自身流程的编码化理解,从而创造了一个能够持续自我完善的、真正意义上的学习系统。
第四部分:Foundry 与 AIP 的共生协同:从受治理数据到智能行动
本部分将综合前述分析,阐述 Foundry 和 AIP 作为一个整体的集成价值主张,并论证为何这两个平台结合在一起的力量远大于它们各自独立作用的总和。
4.1 将 AI 锚定于现实:本体论如何驱动上下文感知的 AI
Foundry 与 AIP 之间的核心协同关系可以概括为:Foundry 提供了干净、受治理且富含业务上下文的数据基础(即数字孪生),而 AIP 则利用这个基础来构建和部署安全、有效且与运营深度融合的 AI 解决方案 26。这是一个相辅相成的关系。如果没有 Foundry 本体论提供的精确业务上下文,AIP 的模型将无法执行有意义的任务。例如,一个像“增加 A 工厂的产量”这样的自然语言指令,之所以能够被 AI 理解和执行,是因为本体论精确地定义了什么是“A 工厂”,什么是“产量”,以及可以用来影响产量的各种杠杆(如库存水平、人员排班、设备利用率等)及其相互关系 23。
一个关键的设计原则是,人类和 AI 必须在完全相同的决策模型上进行操作 14。本体论正是提供了这个共享的决策模型。它确保了当 AI 提出一个行动建议时,其所依据的数据、逻辑和约束条件,与一个人类专家在该场景下进行决策时所考虑的因素是完全一致的。这种设计从根本上防止了 AI 的“世界观”与物理世界的运营现实之间发生危险的脱节。
4.2 闭环系统:捕获决策以优化模型和运营
Palantir 平台的核心设计理念之一是支持“闭环运营”(closed-loop operations)3。当用户通过一个由 AIP 驱动的应用做出决策或执行一个行动时,这个决策本身以及其产生的后续结果,都会被系统作为新的数据捕获,并写回到 Foundry 的数据基础中 5。
这个反馈循环机制是实现“持续学习”(continuous learning)的引擎 3。首先,被捕获的决策数据可以被用来重新训练或微调 AI 模型,使它们随着时间的推移变得越来越精准,越来越贴近企业的最佳实践 12。其次,这些数据也丰富了本体论所描绘的运营全景图,为未来的人类决策和 AI 建议提供了更精确、更及时的信息。
Foundry 平台还提供了一个独特的“场景”(Scenario)功能。用户可以基于当前的本体论状态,创建一个隔离的“沙箱”分支,在这个虚拟环境中对潜在的决策进行模拟和推演,以评估其可能带来的各种下游影响,而不会对实际运营产生任何影响 12。AIP 可以充分利用这一能力,在向人类操作员提交建议之前,预先探索其提议行动的多种可能后果,从而提供一个远比单一建议更为丰富和深入的决策支持分析。
Foundry 与 AIP 的结合创造了一种强大的“飞轮效应”,这构成了 Palantir 一个重要的、难以复制的竞争护城河。这个过程是循环且自我增强的: 1)Foundry 集成并建模数据,构建企业本体论(数字孪生)。 2) AIP 利用本体论,提出具有上下文感知能力的运营建议。 3) 人类操作员批准或修正这些建议,执行行动。 4) 这些决策及其产生的业务结果被作为新数据捕获回 Foundry。 5) 这些新数据反过来又被用于优化本体论和 AI 模型。每一次循环都使整个系统变得更智能、更有价值。
随着客户使用平台的深入,系统编码的专有运营知识就越多,其与业务流程的集成也越紧密 23,这使得竞争对手越来越难以复制其为客户创造的核心价值。
这种深度集成的系统也正在重新定义 IT 和数据团队在企业中的角色。在传统模式下,数据团队通常扮演着后台支持的角色,他们提供数据集或仪表板,然后由业务团队基于这些信息尝试做出决策。在“洞察”与“行动”之间存在着一道明显的鸿沟。Palantir 的模式则将数据和 AI 直接嵌入到一线业务的核心工作流中 3。在这种模式下,构建一个本体论或一个 AIP 智能体,不再仅仅是一个技术活动,它要求技术专家与一线操作员之间进行前所未有的深度协作 27。其带来的组织性影响是,它迫使企业打破部门间的壁垒,将数据职能从一个成本中心提升为一个战略性的、能够直接影响收入和利润的核心业务伙伴。这一点在众多客户的成功案例中得到了印证,他们反复提及平台带来的利润提升和成本节约 28。
第五部分:真实世界应用与战略启示
本部分旨在将前述的技术分析与商业现实相结合,通过具体的案例展示平台的应用价值,并对 Palantir 在更广阔市场中的定位进行客观评估。
5.1 跨行业案例研究:展示可量化的业务成果
Palantir 的平台已在多个行业的关键业务场景中证明了其价值,并带来了可观的业务成果。
- 制造业与供应链:企业利用 Foundry 创建生产线的数字孪生,以优化良率和提升产品质量 29。平台被用于实施预测性维护,并通过模拟不同应对方案的影响来有效管理供应链中断 29。例如,富士通(Fujitsu)通过该平台改造其运营,在短短 3 个月内实现了 900 万美元的年化成本削减 28。全球食品巨头通用磨坊(General Mills)则通过优化其物流网络,每年节省约 1400 万美元 28。
- 医疗保健与生命科学:平台在加速癌症研究等前沿领域发挥着关键作用。美国国家级项目 NCATS 利用 Foundry 安全地聚合和协调来自数千家医院的去标识化患者数据,为“长新冠”(Long COVID)等复杂疾病的研究提供了强大的数据支持 3。坦帕综合医院(Tampa General Hospital)的 CEO 甚至表示,该平台将成为他们“所做一切事情的核心” 28。在生物制造领域,平台被用于减少生产过程中的变异性、优化产量,从而带来数亿美元的潜在收入增长 31。
- 金融服务:平台广泛应用于反洗钱(Anti-Money Laundering)3、欺诈侦测和风险建模等关键领域。在零售银行业务中,它被用来整合客户数据,以实现“单一客户细分”(segment of one)的极致个性化服务 32。一家大型瑞士银行利用该平台构建早期预警指标系统,以主动管理风险 30。
- 跨行业的 AI 快速采用:AIP 的引入进一步加速了价值创造。投资公司 CAZ Investments 利用 AIP,在资源投入不变的情况下,处理的潜在客户线索数量增加了 100 倍以上,同时处理时间缩短了 90% 以上 28。美国退休人员协会(AARP)在 45 天内就推出了第一个 AI 原型应用,展示了平台的敏捷开发能力 28。这些案例充分证明了平台将 AI 从概念转化为实际业务价值的强大能力。
5.2 竞争定位与核心差异化
在现代数据与 AI 平台市场中,对 Palantir 的定位进行分析需要一种更细致的视角,它与主流的现代数据栈玩家之间,既有竞争,更有互补。
- Palantir vs. 现代数据栈 (Databricks, Snowflake, Microsoft Fabric):
- 与 Databricks 对比:Databricks 是一个以代码为先(code-first)的平台,主要服务于数据科学家和数据工程师,其核心优势在于大规模数据处理和机器学习模型训练 33。相比之下,Palantir 更侧重于端到端的运营工作流,其用户群体除了技术人员外,还广泛覆盖了一线的业务用户 34。
- 与 Snowflake 对比:Snowflake 的核心优势在于其云原生的数据仓库架构、受治理的数据共享能力以及强大的 SQL 分析生态 35。Palantir 的强项并非数据仓储本身,而是在存储于仓库中的数据之上,构建一个活跃的、可操作的本体论层。
- 与 Microsoft Fabric 对比:Fabric 是一个一体化的 SaaS 平台,专为深度投资于微软生态系统的企业设计,与 Power BI 等工具进行了无缝集成 35。而 Palantir 是一个云无关(cloud-agnostic)的平台 8,其应用重点更多地在于解决高度复杂的、定制化的运营问题,而非标准化的商业智能(BI)报表。
- “竞合”(Coopetition)战略:Palantir 近期与 Databricks 17 和 Snowflake 10 建立的战略合作关系,清晰地表明了其市场战略并非简单的零和竞争。在这种合作模式下,Palantir 可以利用 Databricks 强大的计算和机器学习能力,以及 Snowflake 灵活的数据云服务,同时为其提供自身独特的本体论和运营应用层。这种组合使得客户能够获得“两全其美”的解决方案,将不同平台的优势整合在一起 17。
- 市场认知与行业认可:Palantir 已被 Forrester 评为 AI/ML 平台的领导者,并被 IDC 评为全球人工智能软件市场份额和收入的第一名 3。尽管在本次报告引用的 2025 年 Gartner 数据科学与机器学习平台魔力象限中未被明确提及 38,但其在政府、国防以及复杂商业场景中的长期领导地位是其一个明确的市场差异化因素 3。
表格 2:Palantir 与现代数据栈 – 战略定位比较分析
平台 (Platform) | 核心架构 (Core Architecture) | 主要用例 (Primary Use Case) | 数据治理模型 (Data Governance Model) | AI/ML 能力 (AI/ML Capabilities) | 目标用户 (Target User Persona) |
|---|---|---|---|---|---|
Palantir Foundry & AIP | 本体论驱动的数字孪生 (Ontology-driven Digital Twin) | 复杂的运营应用与决策自动化 33 | 嵌入式血缘与 PBAC 11 | 运营化 AI (AIP),人机协同 20 | 业务运营人员、分析师、工程师 33 |
Databricks | 开放的湖仓一体架构 (Open Lakehouse on Spark) | AI/ML 模型开发与大规模数据工程 33 | Unity Catalog (集中式元数据) 37 | 模型训练、部署与 MLOps 36 | 数据科学家、数据工程师 33 |
Snowflake | 存算分离的云数据仓库 (Separated Storage/Compute Cloud DW) | BI、企业级报表与受治理的数据共享 35 | 精细化的 RBAC 与安全共享 36 | Snowpark & Cortex AI (应用内 AI) 35 | 数据分析师、SQL 用户 35 |
Microsoft Fabric | 统一的 SaaS 分析平台 (Unified SaaS Analytics) | 微软生态内的 BI 与集成分析 35 | 与 Microsoft Purview 集成 41 | 与 Azure AI 服务深度集成 41 | 业务分析师、Power BI 用户 33 |
Palantir 的商业模式和目标市场从根本上不同于其“竞争对手”。Databricks 和 Snowflake 拥有数以万计的客户,而 Palantir 的客户数量要少得多(约 500 家),但其平均合同价值却非常高 15。这并非其市场拓展不力的表现,而是一种截然不同的市场战略。Palantir 专注于解决那些需要整合数十个遗留系统才能应对的、高价值的、复杂的“系统之系统”(system of systems)问题,例如空客 A350 的生产协调 29。这类问题需要一种更为深入的、顾问式的服务模式,即所谓的“前线部署工程师”(forward deployed engineer)模式 15。其结果是,Palantir 销售的不仅仅是一个工具,而是一个针对复杂业务转型问题的整体解决方案。因此,将其与其他平台进行简单的按计算资源付费的成本比较,可能会产生误导。
此外,生成式 AI 的崛起,从一个意想不到的角度极大地提升了 Palantir 既有架构(本体论)的价值。在最近的 AI 热潮之前,精心构建企业本体论的价值对某些人来说可能显得有些抽象。然而,随着功能强大但缺乏“现实锚定”的大型语言模型的出现,市场对于一个高保真的、安全的、富含上下文的数据基础的需求变得前所未有的迫切。可以说,Palantir 无需刻意“转向”AI,而是 AI 的发展趋势主动契合了 Palantir 的长期愿景。他们在构建企业语义模型方面的长期投资 3,如今恰好成为了安全、有效地部署生成式 AI 的完美基座 26。这使得 Palantir 在将 AI“运营化”(operationalize),而不仅仅是停留在实验阶段的竞赛中,占据了显著的先发优势。
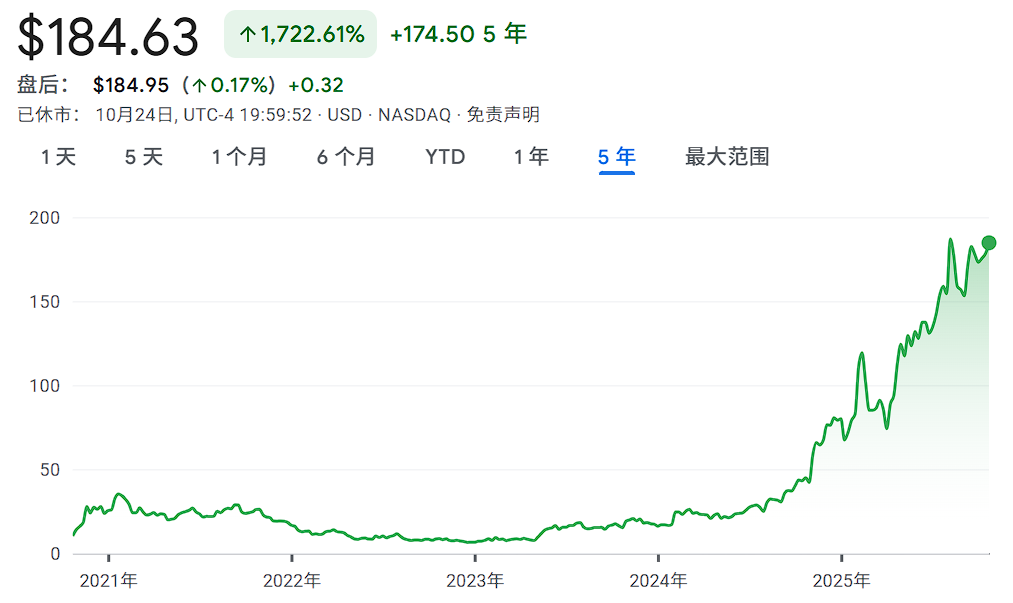
Palantir 在AI浪潮中的股价走势
Palantir 在AI浪潮中的股价走势
Palantir 公司发展历程
1. 创始人背景、创建时间
方面 | 描述 |
|---|---|
创建时间 | Palantir成立于2004年 [^2]。 |
核心创始人 | Peter Thiel:PayPal的联合创始人,硅谷著名风险投资家,是Palantir的创始人之一 ^1[1]。 |
其他创始人:包括现任首席执行官(CEO)Alex Karp、Joe Lonsdale、Stephen Cohen和Nathan Gettings [^9]。 | |
背景与初衷 | Peter Thiel创立Palantir的初衷是将PayPal打击欺诈的技术理念扩展到反恐和情报领域 [^3]。公司最初的资金来自美国中央情报局(CIA)的风险投资部门In-Q-Tel,旨在帮助美国情报机构进行数据分析 [^5]。 |
2. 投融资经历、市值规模
方面 | 描述 |
|---|---|
投融资经历 | 早期估值:Palantir在2010年估值约为7.37亿美元 [^6],到2017年估值已达213亿美元 [^6]。 |
上市方式 | 公司于2020年9月通过**直接上市(DPO)**的方式在纽约证券交易所(NYSE)公开交易 [^8]。 |
市值规模 | Palantir的市值波动较大,曾突破1900亿美元(基于2024年数据) [^4]。其市值规模反映了市场对其在政府和商业AI领域增长的巨大预期。 |
3. 竞品分析
Palantir的核心产品是Foundry(商业)和Gotham(政府),它们是决策操作系统,而非传统的数据仓库或BI工具,这使其竞争格局非常独特。
3.1 核心竞品与差异化
竞品类型 | 主要竞争对手 | Palantir的差异化优势 |
|---|---|---|
云数据平台 | Snowflake [^4]、Databricks、Google Cloud BigQuery | Palantir Foundry定位为**“运营与语义层”,位于这些底层数据平台之上。它专注于将数据转化为可执行的业务行动**,而非仅提供数据存储和分析能力。 |
AI/ML 平台 | AWS SageMaker、Google Cloud Vertex AI、Azure ML | Palantir AIP(AI Platform)提供了一个端到端的、受治理的环境,用于构建和部署AI模型,并将其直接集成到业务流程中,尤其擅长处理复杂、敏感的跨部门数据。 |
传统国防/情报技术 | 传统的国防和情报技术供应商 | Palantir提供的是软件驱动的解决方案,具有更强的灵活性、集成性和迭代能力,能够处理非结构化和高度分散的数据。 |
3.2 Foundry的战略定位与开放性
Palantir的战略核心在于其Foundry平台,它通过以下方式在竞争中脱颖而出:
- 定位“运营与语义层”:
- Foundry并非要与现代数据栈的其他组件直接竞争,而是要将自己定位为一个不可或缺的、位于现代数据栈之上的“运营与语义层”。
- 通过将底层平台的数据与真实的业务行动联系起来,Foundry提升了这些平台本身的价值。
- 战略性开放:
- Palantir通过与Databricks和Snowflake的合作,将这一开放战略推向了极致。
- 这种开放性,以及其官方文档中大量关于使用开源引擎、开放数据格式以及支持将转换逻辑迁出平台的详细说明,构成了对早期市场上关于平台“黑箱”或导致“供应商锁定”批评的有力反驳。
- 核心价值:
- Palantir的核心价值在于其能够整合企业内部和外部的复杂数据,构建一个统一的数字孪生(Digital Twin),并利用AI/ML模型驱动实时、可追溯的决策。
Sources
[^2]: Palantir 成立[2] [^3]: 彼得·泰尔初衷[3] [^4]: 市值与竞品[4] [^5]: 国防金融影响[5] [^6]: 早期估值[6] [^8]: 2020年上市[7] [^9]: 创始人列表[8]
结论与战略建议
本报告综合分析表明,Palantir 的 Foundry 和 AIP 平台为那些旨在超越传统数据分析和商业智能,致力于成为真正由 AI 驱动的运营型企业,提供了一套独特的、深度集成的解决方案。其核心价值在于,Foundry 的本体论能够创建一个受治理的、可操作的企业数字孪生,而这个数字孪生成为 AIP 执行安全、具备上下文感知能力且完全可审计的 AI 驱动行动的坚实基础。
对企业领导者的战略建议
- 基于运营复杂度,而非数据量进行评估:当面临的挑战是需要整合数十个异构系统以驱动一个单一、高价值的运营结果时,应优先考虑 Palantir。其价值在于解决流程的复杂性,而不仅仅是处理海量数据。
- 拥抱本体论方法论:成功实施 Palantir 平台需要的不仅仅是构建数据流水线,更是对核心业务流程进行精确建模的承诺。这要求 IT、数据团队和一线业务部门之间建立一种前所未有的、紧密的合作伙伴关系。
- 规划闭环系统:平台的真正威力在于将决策及其结果数据捕获回系统,形成学习闭环。在设计工作流之初,就应将这一反馈机制纳入考量,以构建一个能够持续自我优化的学习型组织。
- 善用生态系统:不应将 Palantir 视为替代整个数据技术栈的“银弹”。应充分利用其与 Databricks、Snowflake 等平台的互操作性,构建一个“物尽其用”的 AI 网格(AI Mesh),将每个组件的独特优势发挥到极致。
参考资料
- Palantir AIP – Data to Smart Decisions - Quantum-i, accessed on October 18, 2025, https://quantum-i.ai/palantir-aip/
- Ontology architecture - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/object-backend/overview/
- Palantir Foundry, accessed on October 18, 2025, https://www.palantir.com/platforms/foundry/
- Foundry Technical Overview | Palantir, accessed on October 18, 2025, https://www.palantir.com/assets/xrfr7uokpv1b/54mwrnjeu6Y55Lj24RS1Sx/2e2b7b7b4fe2f0ad9ee6a95e976c03c6/FfB_Technical_Overview_v4.pdf
- Open Architecture - Palantir Foundry, accessed on October 18, 2025, https://www.palantir.com/platforms/foundry/open-architecture/
- Palantir Foundry | Integration Solutions, accessed on October 18, 2025, https://www.palantir.com/platforms/foundry/integrations/
- How Palantir AIP Enables UNS for Industry AI, accessed on October 18, 2025, https://blog.palantir.com/industry-ai-8cd003a81be1
- Transforming IT with Palantir Foundry and AIP | by Dorian Smiley | Medium, accessed on October 18, 2025, https://dorians.medium.com/transforming-it-with-palantir-foundry-0f98f0cf70b5
- Available connectors • Databricks - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/available-connectors/databricks/
- Snowflake and Palantir join forces for AI data platform - Techzine Global, accessed on October 18, 2025, https://www.techzine.eu/news/analytics/135516/snowflake-and-palantir-join-forces-for-ai-data-platform/
- Palantir Data Integration Solutions, accessed on October 18, 2025, https://www.palantir.com/platforms/foundry/data-integration/
- Platform overview - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/platform-overview/overview/
- Palantir Foundry AIP - Unit8, accessed on October 18, 2025, https://unit8.com/resources/palantir-foundry-aip/
- Operationalizing AI: Embedding Palantir's AIP into Business Workflow - YouTube, accessed on October 18, 2025, https://www.youtube.com/watch?v=mH1GKN9LNLo
- Does Databricks compete with Palantir? Or, are they offering solutions that can be implemented within the same organization? - Reddit, accessed on October 18, 2025, https://www.reddit.com/r/databricks/comments/1bqqlo4/does_databricks_compete_with_palantir_or_are_they/
- Architecture - Platform overview - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/platform-overview/architecture/
- Palntir & Databricks Partnership — Has the $128 Billion Shark(Palantir) Decided to Share Its… - Medium, accessed on October 18, 2025, https://medium.com/@chandan.nandi/palntir-databricks-partnership-has-the-128-billion-shark-palantir-decided-to-share-its-42c8d18f16eb
- Data protection and governance • Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/security/data-protection-and-governance/
- Deep Dive: Data Protection Tools in Foundry - YouTube, accessed on October 18, 2025, https://www.youtube.com/watch?v=PgB0z8t9pXM
- Overview • AIP • Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/aip/overview/
- Palantir AIP | Defense and Military - YouTube, accessed on October 18, 2025, https://www.youtube.com/watch?v=XEM5qz__HOU
- Overview • Administration - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/administration/overview/
- Palantir's AIP: Why Operational AI Is Creating a Premium Tech Powerhouse, accessed on October 18, 2025, https://completeaitraining.com/news/palantirs-aip-why-operational-ai-is-creating-a-premium-tech/
- Palantir Artificial Intelligence Platform, accessed on October 18, 2025, https://www.palantir.com/platforms/aip/
- AIP Assist application integrations - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/assist/application-integrations/
- Helping enterprise teams deploy AI at scale with Palantir Foundry ..., accessed on October 18, 2025, https://spr.com/helping-enterprise-teams-deploy-ai-at-scale-with-palantir-foundry/
- Governance processes - Foundry adoption - Palantir, accessed on October 18, 2025, https://palantir.com/docs/foundry/foundry-adoption/governance-processes/
- Impact | Palantir, accessed on October 18, 2025, https://www.palantir.com/impact/
- Palantir Foundry for Manufacturing, accessed on October 18, 2025, https://www.palantir.com/explore/foundry-for-manufacturing/
- Empowering Business Decisions: Palantir Foundry Case Studies by Unit8, accessed on October 18, 2025, https://unit8.com/resources/palantir-foundry-case-studies-by-unit8/
- Palantir Foundry | Biomanufacturing, accessed on October 18, 2025, https://www.palantir.com/explore/biomanufacturing/
- Customer- Centric Banking - Palantir, accessed on October 18, 2025, https://www.palantir.com/assets/xrfr7uokpv1b/5WzUXzX6u89lsU3omgAR5p/36ed087996f049e8811e33e2395bfacd/Whitepaper_-_Palantir_Foundry_for_Customer-Centric_Banking.pdf
- Palantir Foundry Comparison: Data Transformation vs Market Leaders - Trackmind, accessed on October 18, 2025, https://www.trackmind.com/palantir-foundry-data-transformation-market-comparison/
- Databricks Workflows vs. Palantir Foundry: key differences 2024 - Orchestra, accessed on October 18, 2025, https://www.getorchestra.io/guides/databricks-workflows-vs-palantir-foundry-key-differences-2024
- Databricks vs. Snowflake vs. Microsoft Fabric: Which Fits Your Roadmap? - United Techno, accessed on October 18, 2025, https://www.unitedtechno.com/databricks-vs-snowflake-vs-microsoft-fabric/
- In-depth comparison - Microsoft Fabric vs Databricks vs Snowflake - Softweb Solutions, accessed on October 18, 2025, https://www.softwebsolutions.com/resources/microsoft-fabric-vs-databricks-vs-snowflake.html
- Microsoft Fabric vs. Databricks vs. Snowflake: A Modern Data Platform Comparison - MILL5, accessed on October 18, 2025, https://www.mill5.com/2025/06/13/fabric-databricks-snowflake/
- Gartner 2025 Magic Quadrant for Data Science and ML Platforms | Google Cloud Blog, accessed on October 18, 2025, https://cloud.google.com/blog/products/ai-machine-learning/gartner-2025-magic-quadrant-for-data-science-and-ml-platforms
- Gartner | 2025 Magic Quadrant for Data Science and Machine Learning Platforms - AWS, accessed on October 18, 2025, https://aws.amazon.com/resources/analyst-reports/gartner/magic-quadrant-for-data-science-and-machine-learning-platforms/
- Palantir Technologies - Wikipedia, accessed on October 18, 2025, https://en.wikipedia.org/wiki/Palantir_Technologies
- Databricks vs Snowflake vs Fabric: A Complete Comparison Guide - Kanerika, accessed on October 18, 2025, https://kanerika.com/blogs/databricks-vs-snowflake-vs-fabric/
- Switch Datbricks to Palantir? : r/dataengineering - Reddit, accessed on October 18, 2025, https://www.reddit.com/r/dataengineering/comments/1mog65z/switch_datbricks_to_palantir/
Notice:Human's prompt, Datasets by Gemini-2.5-Pro-DeepResearch
#智能数据平台
---【本文完】---
👇阅读原文,独立站提前更新🚀(测试中)🧪
- [彼得·泰尔](https://zh.wikipedia.org/zh-hans/%E5%BD%BC%E5%BE%97%C2%B7%E6%B3%B0%E7%88%BE) ↩
- https://www.epjike.com/hydt/127.html ↩
- https://time.geekbang.org/column/article/9327 ↩
- https://www.dapingtime.com/article/1219.html ↩
- https://www.huxiu.com/article/135292.html ↩
- https://www.scribd.com/document/837832659/%E5%B7%A8%E5%A4%B4%E5%90%AF%E7%A4%BA%E5%BD%95-Palantir-FBI%E7%9A%84%E7%A5%9E%E7%A7%98%E4%BE%8D%E5%8D%AB ↩
- https://www.twse.com.tw/rwd/staticFiles/product/publication/0002000191.pdf ↩
- https://www.gelonghui.com/p/61778 ↩
- https://www.linkedin.com/in/seanf/ ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号