【deepseek用例生成平台-39】用例生成后去重功能实现

【deepseek用例生成平台-39】用例生成后去重功能实现

我去热饭
发布于 2025-11-12 17:15:38
发布于 2025-11-12 17:15:38
urls.py中新建这个链接映射:
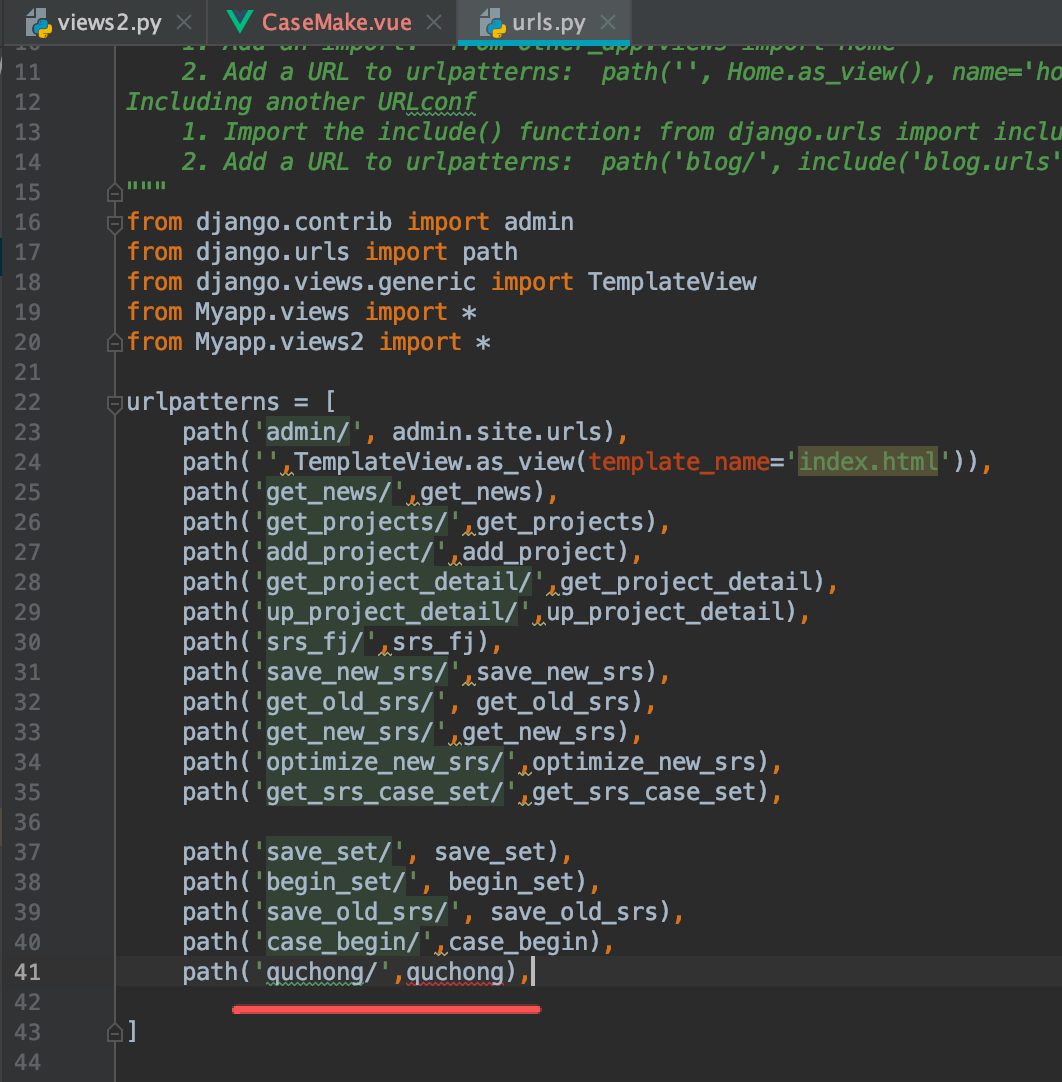
然后打开:views.py2 文件,写好这个算法。
注意,我们在排查重复的时候,是优先删除后面用例的哦~
就比如说 等价类出现了用例1 ,判定表也出现了用例1, 算法会删除判定表中的用例1 ,保留等价类的用例1
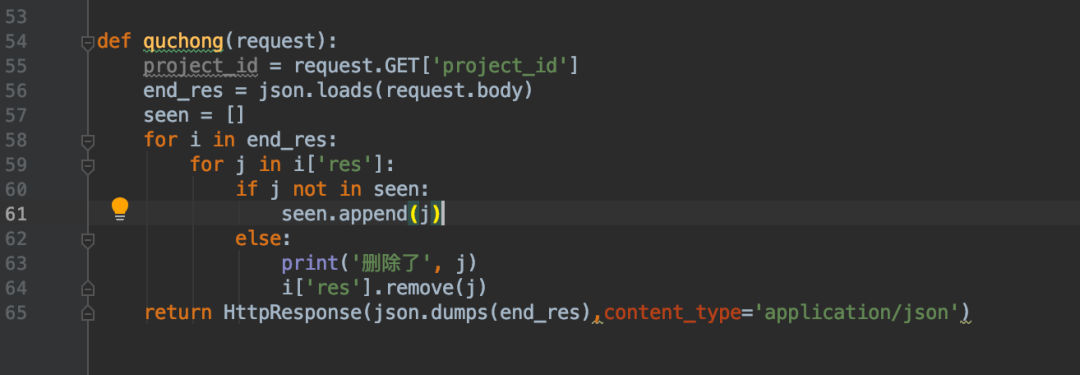
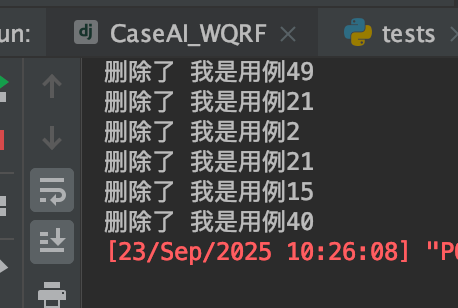
这里会提示删除了什么在后台控制台中:
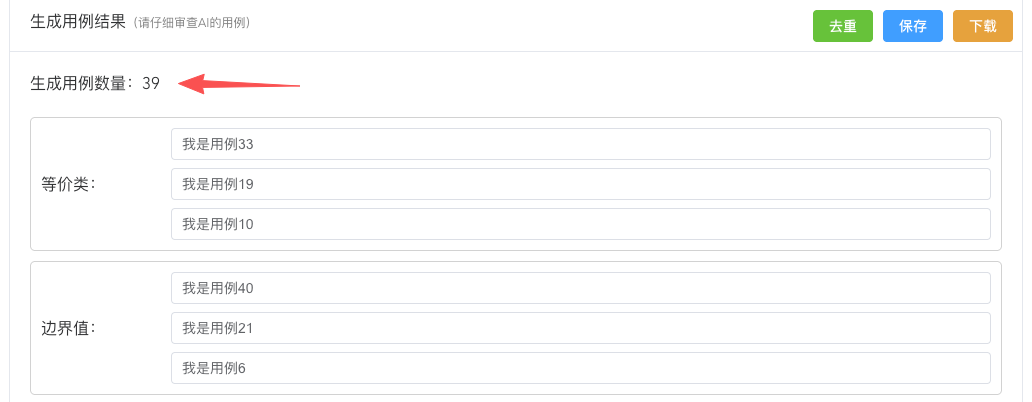
我们来做个测试,按照我写死的用例数量生成后,是固定的39条:
点击去重后:生下来33条:
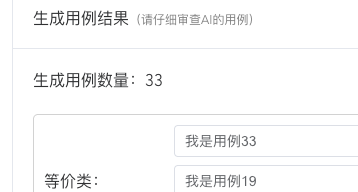
控制台显示删除了这6条重复的:
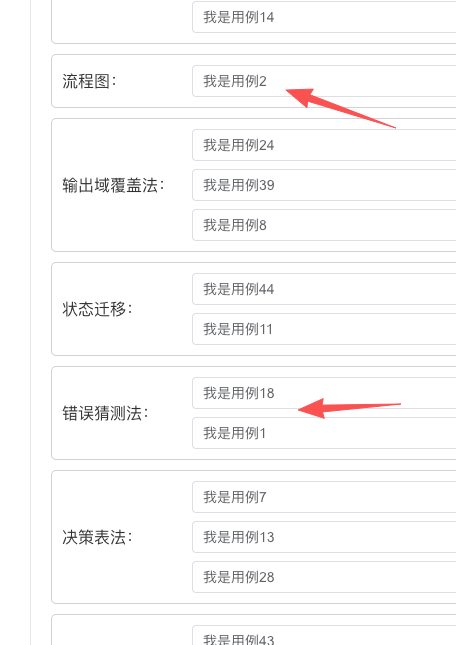
前端界面也可以看到,有些设计方法去重后不足3条了:
这个算法暂时算是完成了。
但是我们现在的判断很明显,是根据字符串完全相等来进行删除的,接下来,我们要把余铉相似的算法融合进去,让相似度大于多少分的才会删除:
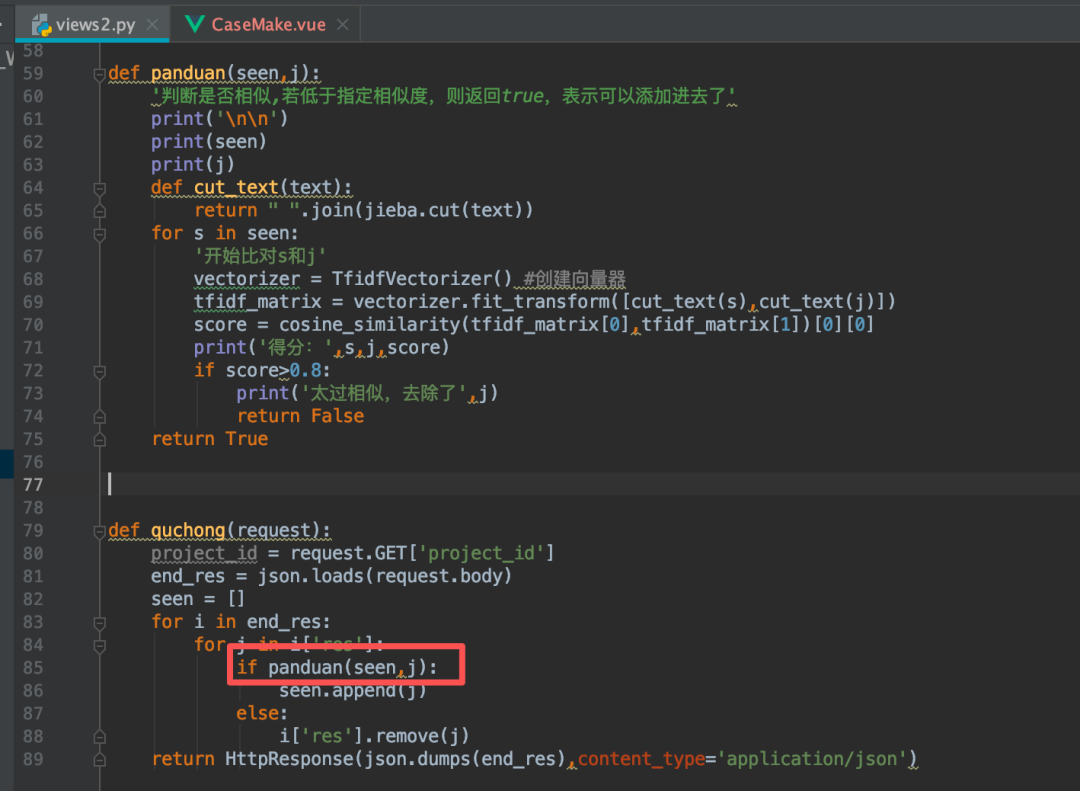
先在上面导入这三句:
from sklearn.feature_extraction.text import TfidfVectorizer import jieba from sklearn.metrics.pairwise import cosine_similarity
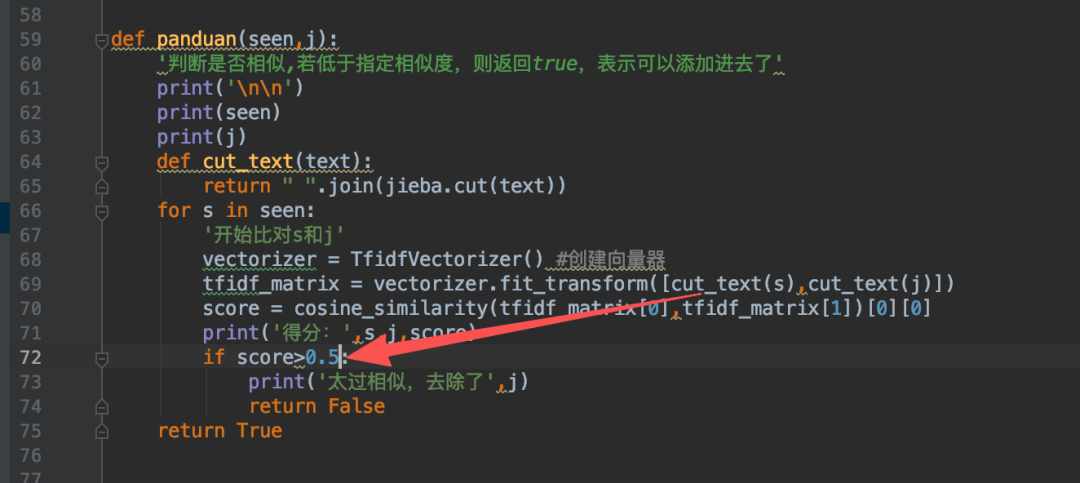
然后下面新建这个函数和修改红圈部分:注意,此时设置分数大于0.8
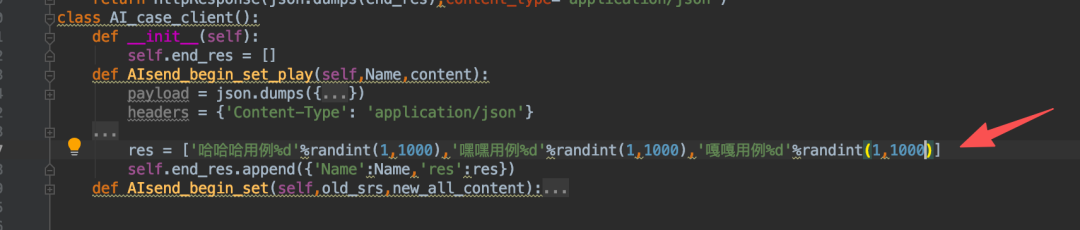
这里因为写死的用例都太过相似,所以我们改一下之前写死的生成代码:
现在开始测试一下,先点击生成:
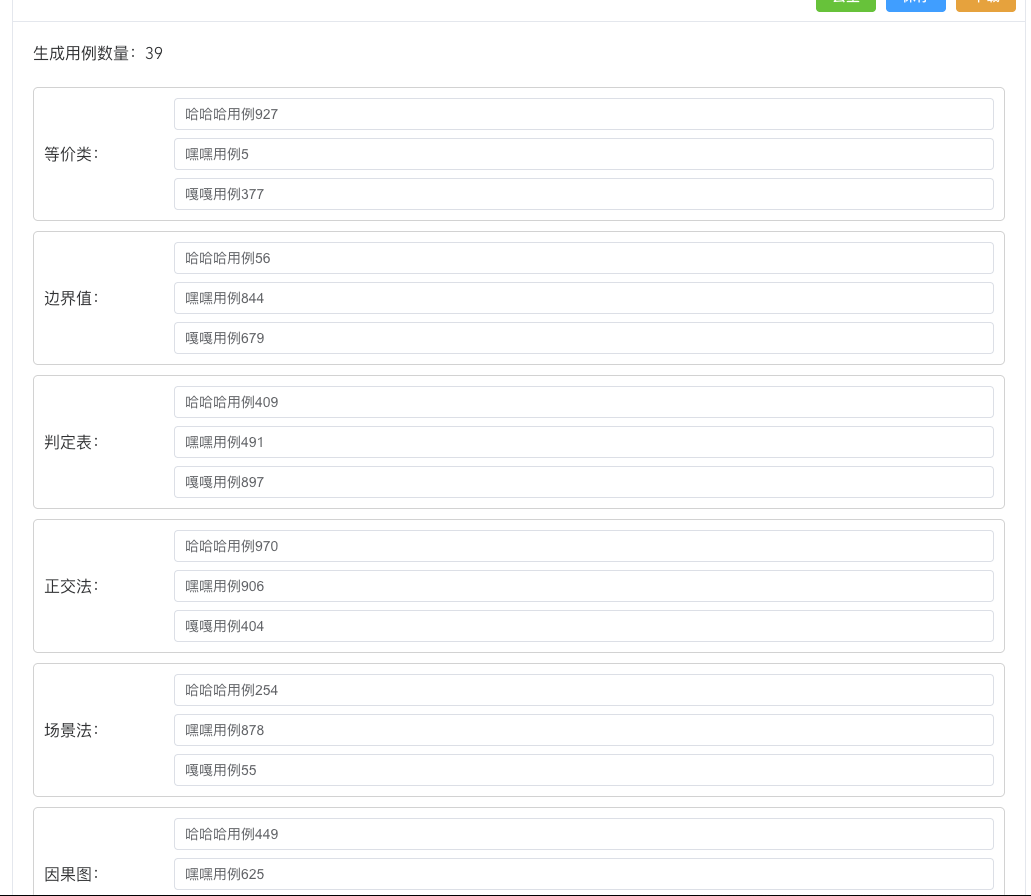
看下生成的用例:39条
然后点击去重按钮:
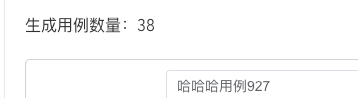
可以看到只去除了1条:
然后看看控制台日志:

可以发现,只有一条,因为只差了一个字不同,被去除了。
那么我们现在降低系数,从0.8变成0.5 ,不用点击生成了,直接点去重!
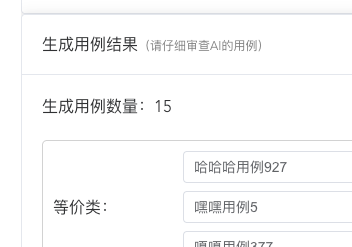
结果如下:只剩15条了
观察日志发现,很多都被去重了:大于0.5分的都没了
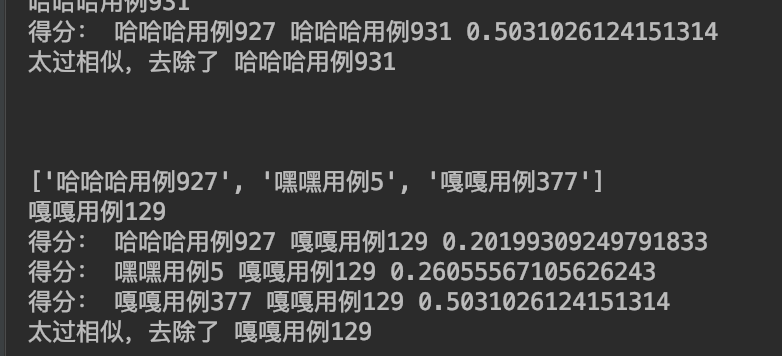
所以,我们认识到一个现象。就是这个相似系数,是直接关系到用例数量的。
那我们作为开发平台的人,是很难把控好这个系数的,连亲自测试的业务测试们,也不可能第一次就把握的好,不同的业务线,不同产品也不一样。
所以我打算把系数作为前端动态调节的。
就像我们刚刚的这个过程,觉得去除的不满意,那么就再次减小系数。
但这里就有个问题,这个过程是不可逆的,一旦弄的太小了,剩的用例太少了,想再返回就不太可能了。毕竟删掉了就是删掉 了。
所以我们下一节的任务就是,做好前端动态调节系数的同时,做一个可逆转的操作。
欢迎继续追更哦~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号