IDEA研究院发布Rex-Omni:3B参数MLLM重塑目标检测,零样本性能超越DINO
原创
IDEA研究院发布Rex-Omni:3B参数MLLM重塑目标检测,零样本性能超越DINO
原创
CoovallyAIHub
发布于 2025-10-22 09:28:50
发布于 2025-10-22 09:28:50
把目标检测变成“下一个点预测”,用2200万数据+强化学习解决行业难题
目标检测技术正在迎来一场范式革命!传统方法如YOLO、DETR依赖复杂的坐标回归,而IDEA(粤港澳大湾区数字经济研究院)研究院的最新研究Rex-Omni通过巧妙的任务重构,将目标检测转化为更符合大语言模型思维的“下一个点预测”任务,在零样本设置下实现了对传统强手的超越。
论文标题:Detect Anything via Next Point Prediction 论文链接:https://arxiv.org/abs/2510.12798 代码仓库:https://github.com/idea-research/rex-omni
突破传统:从坐标回归到点预测
Rex-Omni的核心创新在于彻底改变了目标检测的问题定义。研究团队将图像坐标空间量化为1000个离散值,每个值对应一个专用token。这样,一个边界框只需4个token(x0, y0, x1, y1)即可表示,完美适配语言模型的生成范式。

图片1.png
这种设计带来双重优势:
- 降低学习难度:连续的坐标回归简化为有限集合的分类问题
- 提升推理效率:相比将坐标拆解为单个数字的方法,token使用效率大幅提升

图片2.png
三大支柱:架构创新的坚实基础
Rex-Omni的成功建立在三大核心设计之上:
任务范式创新:基于Qwen2.5-VL-3B架构,复用词汇表最后1000个token作为坐标专用token,无需大幅改动模型结构。

图片3.png
数据引擎支撑:团队构建自动化数据流水线,整合公共数据集与自产数据,最终形成2200万样本的训练集,覆盖定位、指代、指向等多种任务。
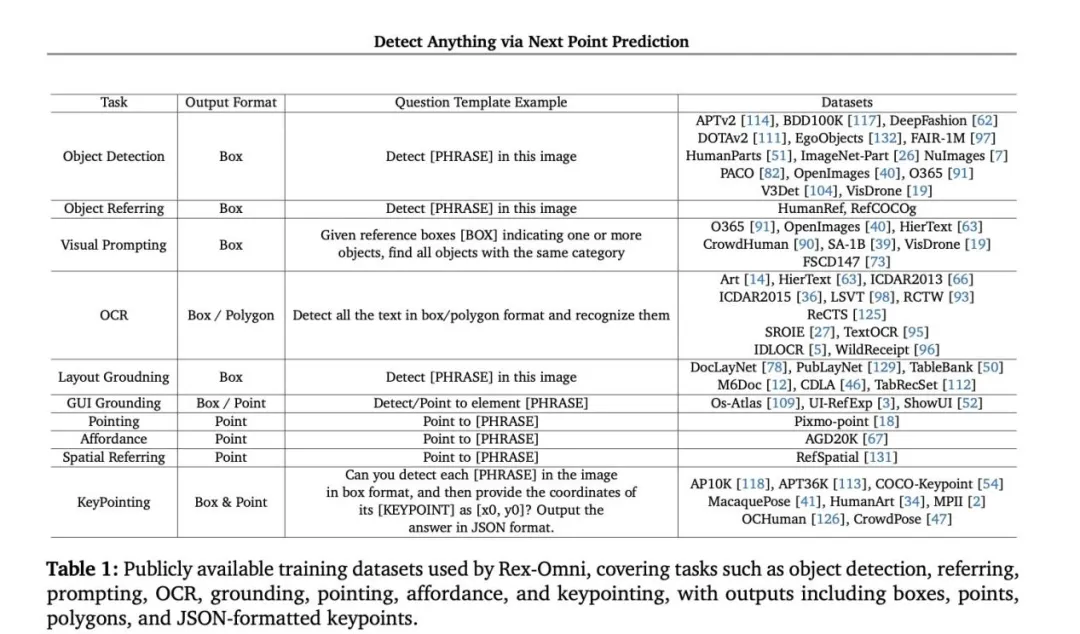
图片4.png
训练流程优化:采用两阶段训练策略——先通过监督微调打下基础,再引入GRPO强化学习方法,通过几何感知奖励函数精细调整模型行为。
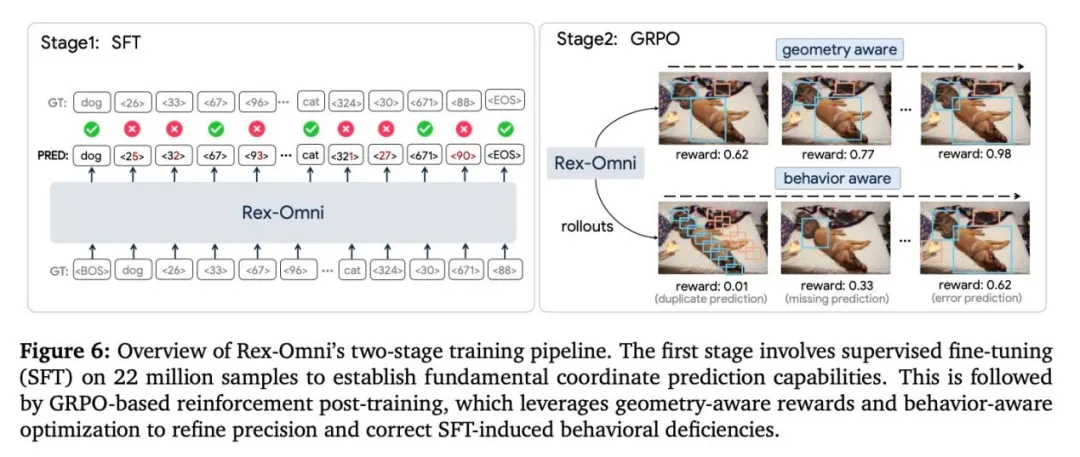
图片5.png
性能表现:零样本检测的新标杆
在权威基准测试中,Rex-Omni展现惊人实力:
COCO数据集:零样本设置下,IoU阈值为0.5时,性能不仅超越之前最强MLLM SEED1.5-VL,甚至超过了为COCO专门训练的传统检测器DINO-R50。
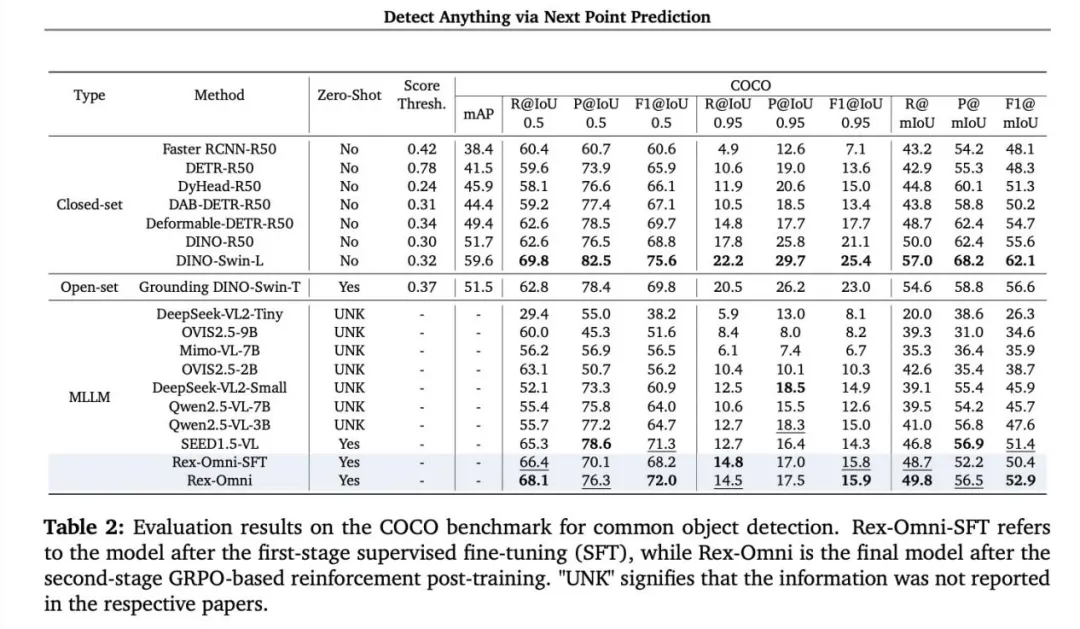
图片6.png
LVIS长尾检测:在更具挑战性的长尾任务中,mIoU指标达到46.9,证明其优秀泛化能力。
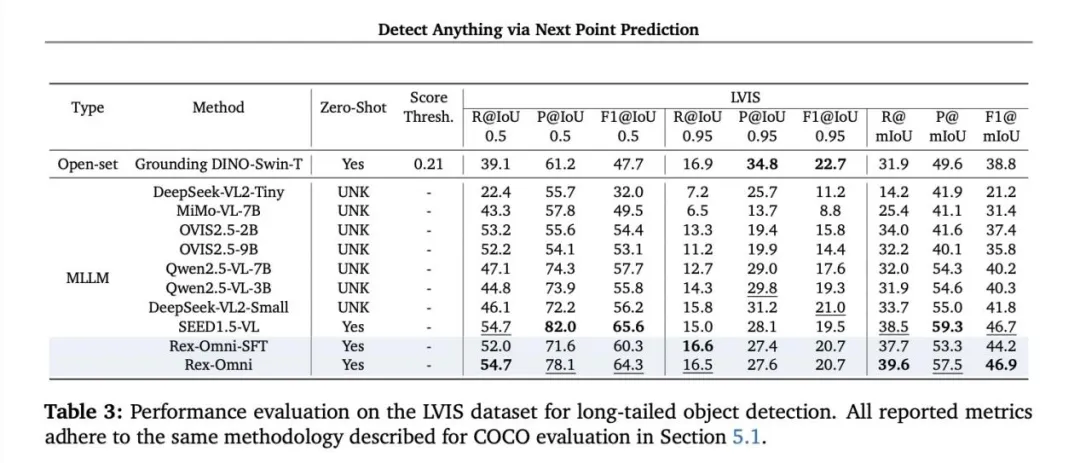
图片7.png

图片8.png
密集小目标检测:在Dense200数据集上取得78.4的F1@0.5分数,有效解决了MLLM在密集小目标上的传统弱点。
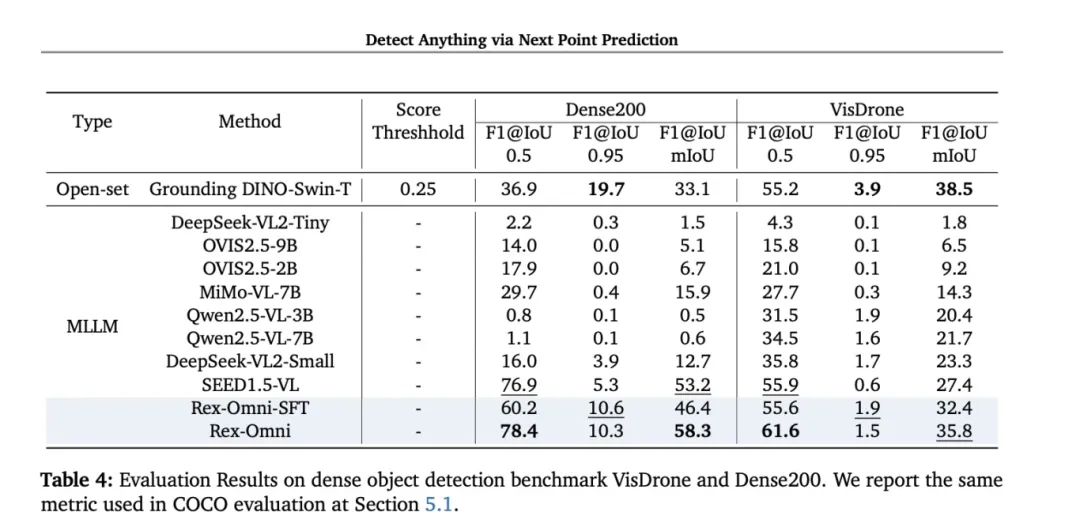
图片9.png

图片10.png
多任务能力:超越传统检测的边界
得益于语言模型的底层架构,Rex-Omni展现出全面的视觉感知能力:
- 指代性物体检测
- 视觉提示理解
- GUI界面定位
- OCR文字识别
- 关键点检测
这种统一的方法为开发通用视觉感知系统开辟了新路径。
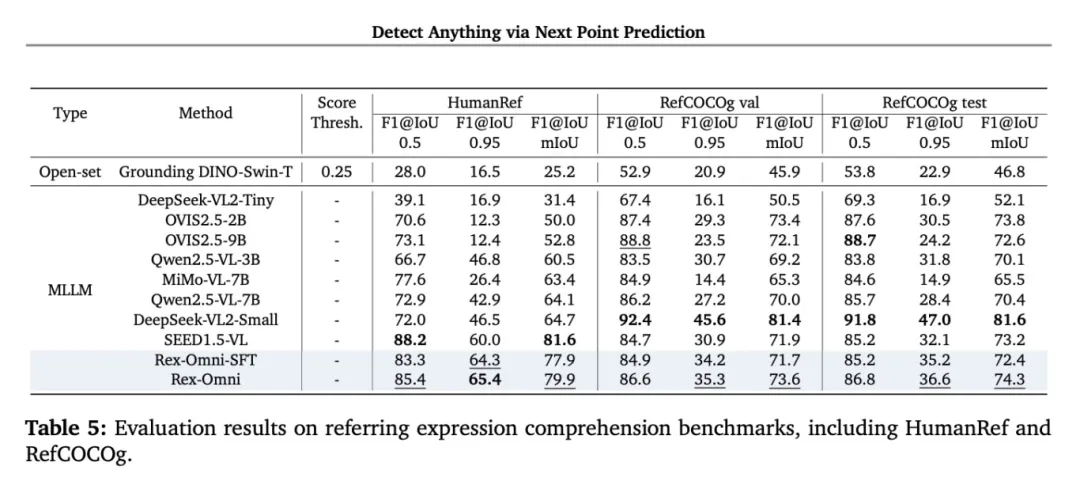
图片11.png
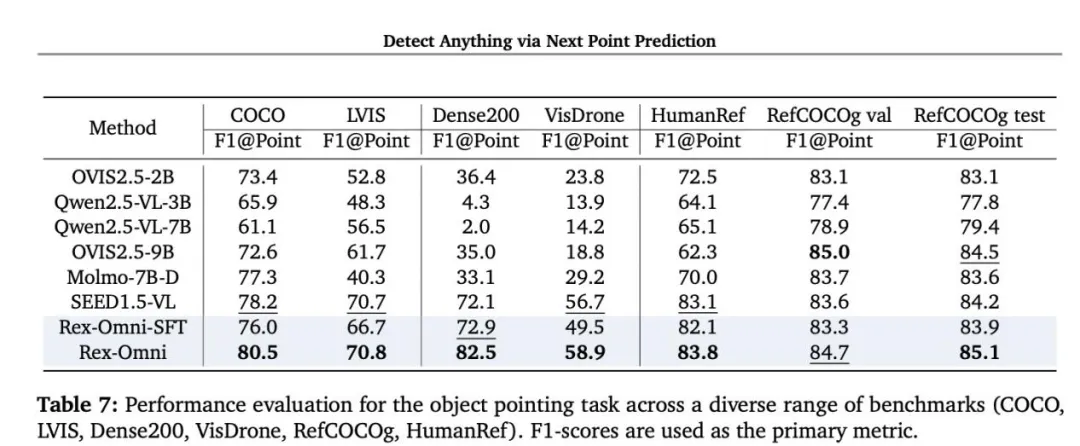
图片12.png

图片13.png
技术启示与未来展望
Rex-Omni的突破表明,通过巧妙的任务重构,MLLM不仅能够“理解”图像内容,更能“精准定位”视觉元素。这种将目标检测统一到生成框架下的思路,为多模态大模型在视觉任务中的应用提供了全新范式。
该研究已全面开源,包括论文、代码和演示,为社区进一步探索提供了坚实基础。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号