Drut Technologies:CPO+OCS打破静态机架算力局限

Drut Technologies:CPO+OCS打破静态机架算力局限

光芯
发布于 2025-10-13 11:19:41
发布于 2025-10-13 11:19:41
Drut Technologies成立于2018年,总部位于美国新罕布什尔州纳舒厄,业务覆盖美国、印度及欧洲市场,是OCS光子解聚合技术领域的先驱企业之一。团队核心创始人之一的Jitender Miglani(现总裁兼董事长)曾任Calient Technologies工程副总裁,主导MEMS光开关技术研发,2018年创立Drut后初期任CEO。


在OCP研讨会上,Drut公司的Simon McCormack发表了题目为Break the Rack with Light的报告。报告指出当前AI数据中心面临的核心矛盾:传统机架架构中服务器与GPU的物理绑定导致资源利用率长期低于30%,而大语言模型参数从80亿到4050亿的指数级增长(如Llama3.1 405B),同时模型优化技术(如CPU层卸载、量化、动态量化)又推动小型化、专用化模型的普及,导致AI workload对硬件资源的需求始终处于动态变化中。
传统静态数据中心架构(CPU机架、GPU机架、存储机架独立分离,所有流量依赖ToR交换机)无法适配这种动态需求:一方面,GPU等核心资源被“绑定”在固定机架内,闲置时造成资源浪费;另一方面,当模型需要多类型、多数量资源组合时,静态架构难以快速响应,导致训练/推理效率低下。此外,GPU硬件生命周期仅2-3年,而服务器更新周期更长,固定架构下的“捆绑升级”进一步增加了企业的TCO(总拥有成本)。

◆ 服务器解耦:重构数据中心资源分配逻辑
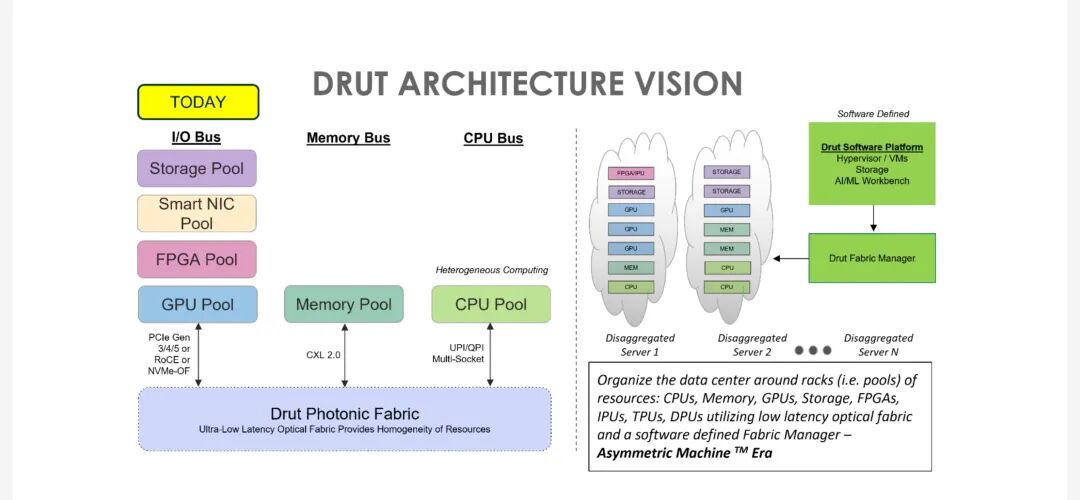
Drut将“服务器解耦”(Server Disaggregation)视为解决上述困境的核心方案——即打破传统服务器的“CPU-内存-GPU-存储”一体化结构,将硬件资源拆分为独立的资源池(CPU池、GPU池、存储池、FPGA池等),再通过动态互连技术,跨机架组合成“定制化机器”(Composed Compute System)。
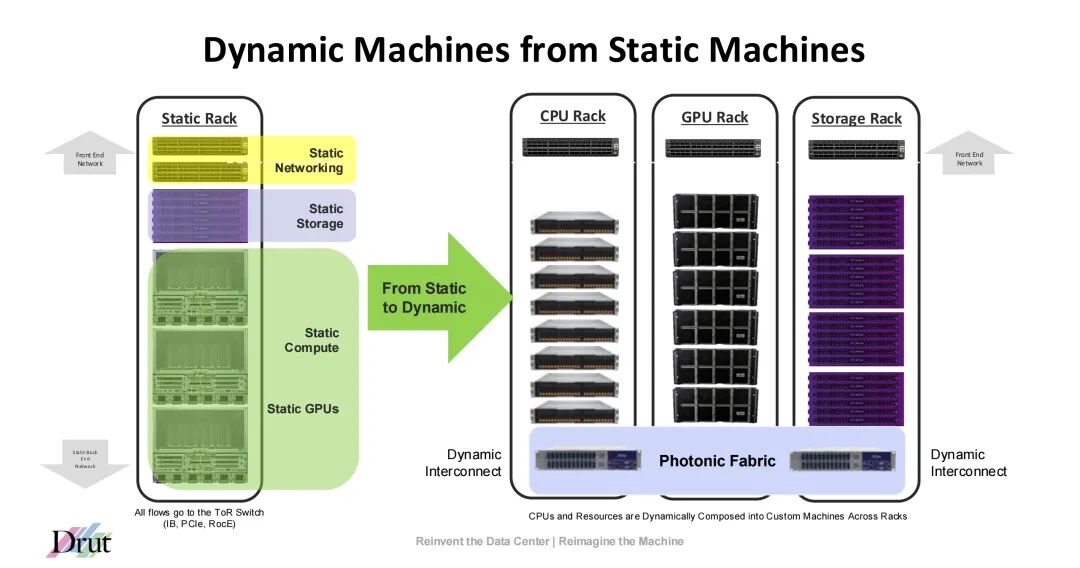
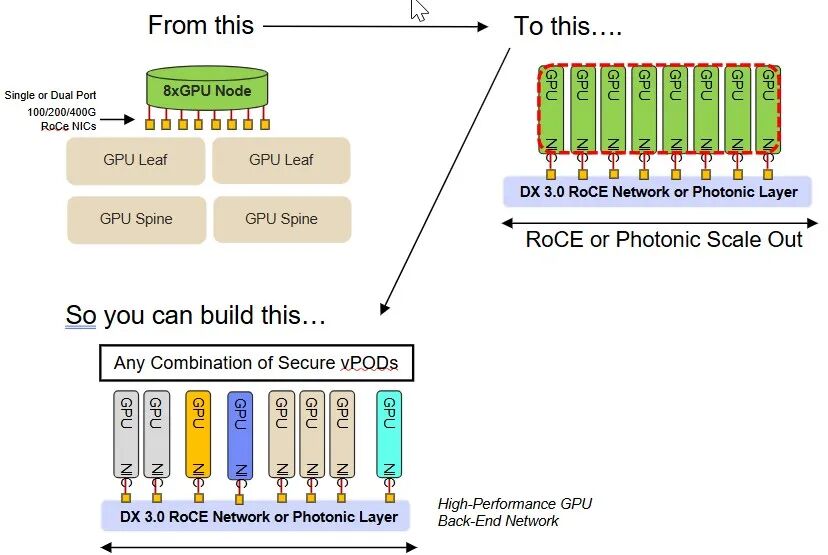
这种解耦架构的核心价值在于:
1. 资源弹性分配:根据AI workload需求,实时调配GPU、存储等资源,例如为大模型训练分配32路GPU,为轻量推理分配1-2路GPU,避免资源闲置;
2. 独立升级路径:GPU、服务器可分别升级,无需因GPU迭代而更换整台服务器,延长硬件生命周期,降低升级成本;
3. 跨机架扩展:突破物理机架的限制,实现资源的全局调度,满足大规模AI集群(如GPU Farms)的部署需求。
而实现服务器解耦的关键,在于低延迟、高带宽的动态互连技术——这正是Drut 2500系列光子架构与光交换(OCS)的核心应用场景。
◆ 核心硬件组件:2500系列的光子互连基石
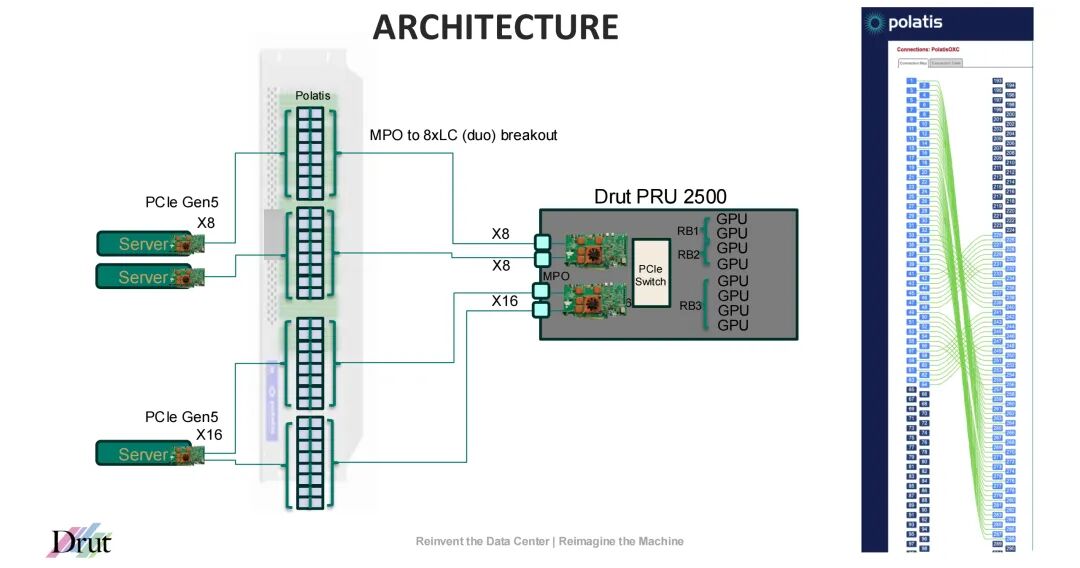
Drut 2500系列通过“Fabric Interface Card(FIC 2500)+ Photonic Resource Unit(PRU 2500)”的硬件组合,构建了服务器解耦的物理基础。
1. Fabric Interface Card(FIC 2500):服务器与光子 fabric 的桥梁

FIC 2500是插入服务器(主机)PCIe Gen5插槽的光纤接口卡,承担“连接主机与资源池”的核心角色,其关键技术参数与功能包括:

- 形态与兼容性:采用全高半长(FHHL)设计,适配标准PCIe Gen5 x16插槽,兼容市面上所有带可用PCIe插槽的现成服务器(Off-the-Shelf Servers),无需定制硬件;
- 互连能力:搭载2或4个CPO 2.0 光模块连接器,每个CPO引擎提供8个独立通道,支持16x100G(2个CPO)或32x100G(4个CPO)的fabric端口带宽;通过MPO16单模光纤电缆连接,单卡总吞吐量可达1.6 Tbps(2个CPO)或3.2 Tbps(4个CPO);
- 资源扩展:每台服务器可部署1-2张FIC 2500,支持最多32路GPU per主机(通过连接PRU 2500资源池实现),满足AI/ML对大规模GPU集群的需求;
- 软件协同:与Drut DynamicXcelerator软件深度集成,实现实时带宽分配、故障冗余与资源调度——例如动态调整PCIe通道为x8或x16模式,适配不同workload的带宽需求。
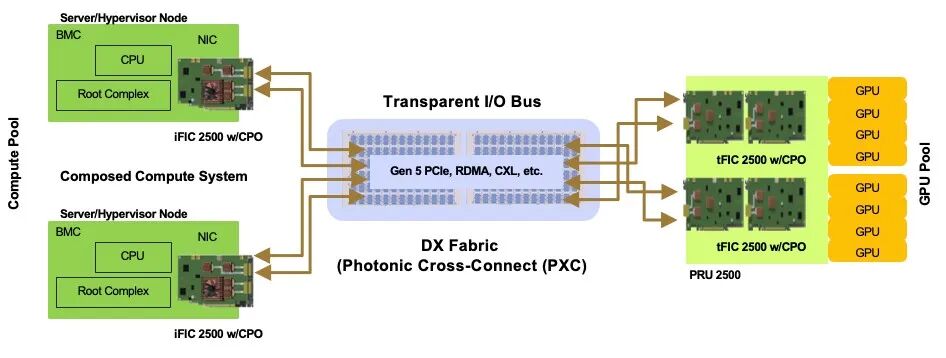
此外,FIC 2500分为“发起端”(iFIC 2500,部署于服务器)与“目标端”(tFIC 2500,部署于PRU 2500),两者通过光子fabric实现PCIe Gen5信号的远程传输, latency远低于传统电互连,确保GPU-to-GPU、GPU-to-storage的直接通信效率。
2. Photonic Resource Unit(PRU 2500):集中式资源池载体

PRU 2500集中承载GPU、FPGA、NVMe存储等PCIe资源的高密度 chassis,其核心特性包括:

- 插槽配置:共16个插槽,其中12个为PCIe Gen5 x16设备插槽(10个双宽插槽,支持高功率GPU;4个单宽插槽,支持FPGA、SmartNIC等),4个为主机插槽(用于部署tFIC 2500,连接外部服务器);
- 互连带宽:每个tFIC 2500支持16x100G或32x100G fabric带宽,4个tFIC 2500可连接4台主机(x16模式)或8台主机(x8模式),实现资源池与多服务器的灵活对接;
- 供电与散热:配备4个3000W热插拔电源,支持6个120mm x 38mm热插拔风扇,满足8路双宽GPU的高功率需求(单插槽功率可达600W+);
- 环境适应性:工作温度范围0°C~35°C,存储温度-20°C~70°C,符合数据中心标准环境要求,尺寸为深度650mm×宽度447mm×高度175mm,适配标准机架安装。
典型部署中,2台PRU 2500(每台8路GPU)可通过iFIC 2500连接4台服务器,形成“4服务器+16GPU”的资源集群,支持AI推理、HPC等场景的动态资源组合。
◆ OCS与CPO技术:实现低延迟光子互连的关键
Drut报告强调,“PCIe remoting over Optical Circuit Switch(OCS)”是服务器解耦的技术核心——即通过OCS(光电路交换机)构建动态光子fabric,实现PCIe信号的长距离、低延迟传输;而CPO技术则是提升光子互连密度、降低功耗的关键突破。
1. OCS的作用:动态光路由
Drut的光子fabric基于OCS实现“动态互连”:OCS作为Layer-1层交换机,可实时调整iFIC 2500与tFIC 2500之间的光子通路,无需依赖传统以太网或InfiniBand的协议转换,从而将latency降至亚毫秒级(满足AI/ML对低延迟的严苛要求)。例如,当Server A需要调用PRU 2500中的GPU资源时,OCS可直接建立Server A(iFIC)与PRU 2500(tFIC)的光子通路,数据传输无需经过多跳交换机,效率显著提升。
2. CPO技术:Drut与Ranovus的合作突破
Drut 2500系列是首批商用CPO解决方案之一,其核心在于集成了Ranovus的ODIN® CPO光学互连技术——该技术将激光器、调制器、光电探测器、驱动电路等关键模拟组件单片集成EPIC,相比传统可插拔光模块,具有三大优势:
- 更高密度:CPO 2.0连接器支持每端口8个通道,单卡可实现32x100G带宽,远超传统模块的密度;
- 更低功耗:省去了可插拔模块的独立封装与电-光转换环节,每100G带宽的功耗降低30%以上,缓解数据中心的供电压力;
- 更好的扩展性:支持PCIe Gen5/Gen6/Gen7及高速以太网,为未来更高带宽需求预留升级空间。
Ranovus:共封装光学(CPO)技术演进与AI计算生态的革新之路
DesignCon 2025: Ranovus/联发科/富士康的CPO方案
◆ 软件协同:DynamicXcelerator实现资源动态编排
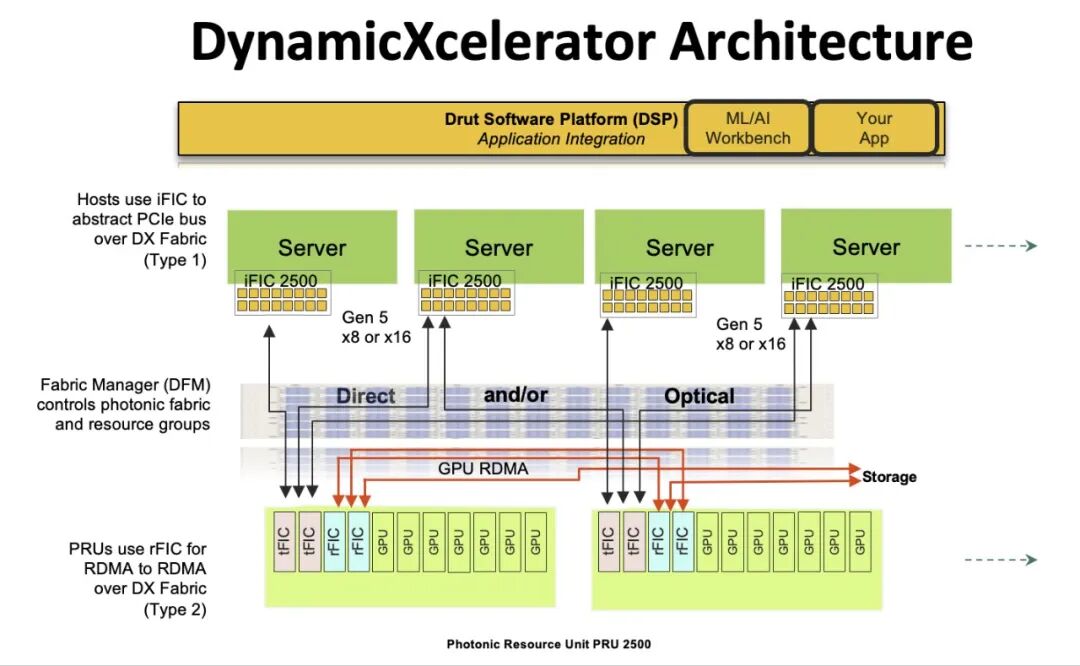
硬件层面的解耦与互连,需要软件层面的“编排大脑”——Drut DynamicXcelerator作为服务器软件栈,负责将硬件资源转化为“软件定义的资源池”,其核心功能包括:
1. vPOD创建与隔离:将CPU切片、内存切片、GPU、NIC等资源组合成虚拟资源单元(vPOD),vPOD可跨服务器、跨fabric(以太网、InfiniBand、光子fabric)部署,且物理隔离,确保不同用户/workload的资源安全;例如,8路GPU服务器可拆分为3个vPOD(5路GPU+2路GPU+1路GPU),分别分配给不同AI任务;
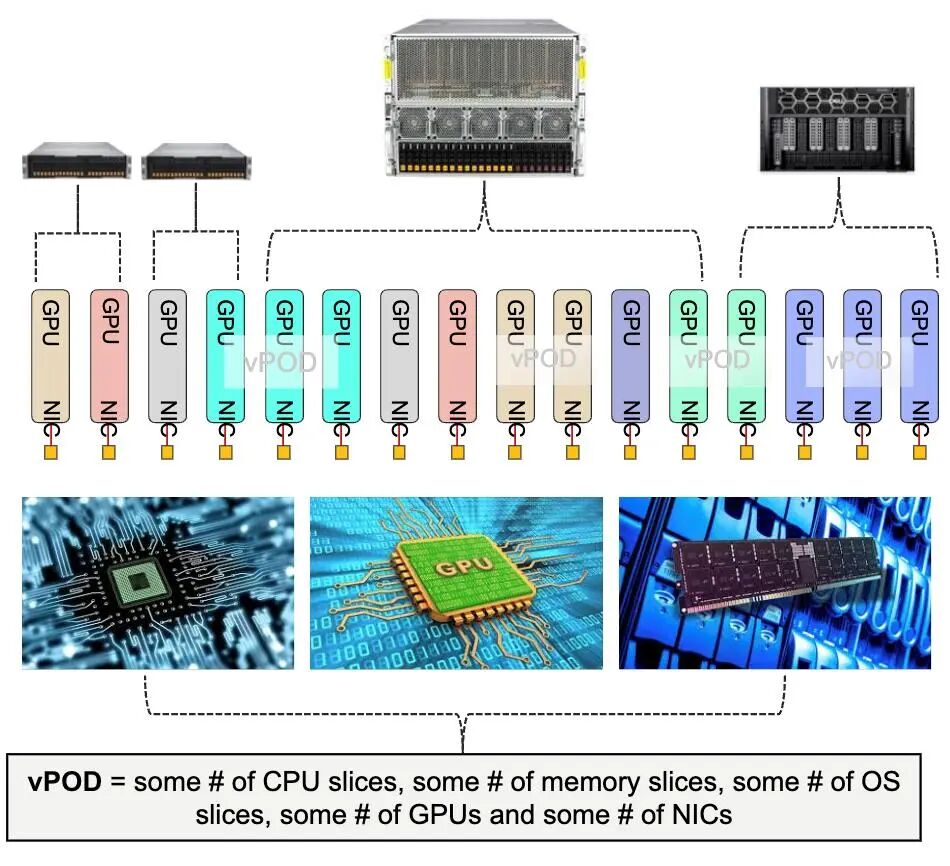
2. 实时资源调度:通过Drut Fabric Manager(DFM)实现GPU、存储等资源的实时分配与重分配——当某一vPOD的任务结束后,GPU可立即释放并分配给其他任务,资源利用率提升40%以上;
3. 兼容性与易用性:支持现成服务器、多厂商GPU(如NVIDIA、AMD)与RDMA-capable NIC,无需定制硬件;提供AI/ML工作bench,自动化配置模型环境,用户可直接调用vPOD资源,无需关注底层互连细节。
◆ 技术收益与应用场景:赋能AI/ML与HPC
Drut的解耦方案在AI/ML、HPC等场景中展现出显著价值:
- AI/ML推理加速:集中式GPU池通过光子fabric连接多服务器,模型推理时间最多缩短80%;支持多代GPU混合部署,旧GPU可用于轻量推理,延长硬件生命周期;
- HPC集群优化:亚毫秒级延迟与99.999% 正常运行时间,满足气象模拟、量子计算等 mission-critical 任务的需求;
- GPU-as-a-Service(GPUaaS):云服务商可通过vPOD实现GPU的精细化分配,按用户需求提供1路、4路、8路等不同规格的GPU资源,基础设施成本降低30%;
- 存储资源池化:将NVMe存储集中部署于PRU 2500,通过光子fabric实现服务器与存储的直接连接, 配置时间缩短60%,存储利用率提升40%。
◆ 结论:光子解耦架构重塑数据中心未来
Drut报告的核心观点——“固定容量基础设施浪费资源,解耦方案提供AI所需的灵活性”,在Drut 2500系列中得到了完整落地:通过FIC 2500与PRU 2500构建的硬件基础,结合OCS与CPO的光子互连技术,再以DynamicXcelerator实现软件编排,Drut成功将静态数据中心转变为“资源可动态组合、带宽可实时调整、升级可独立进行”的动态环境。

这种架构不仅解决了当前AI/ML的资源瓶颈,更通过“光子+软件定义”的技术路线,为未来PCIe Gen6/Gen7、高速以太网等更高带宽需求预留了扩展空间。正如Drut与Ranovus的合作所体现的,CPO等光子技术的商用化,将进一步推动数据中心从“铜缆时代”迈向“光子时代”,为AI算力的持续增长提供底层支撑。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号