AMD:AI集群扩展架构技术总结



数据中心网络的传统层级由核心层(CORE)、汇聚层(AGGREGATION)和架顶层(TOR)构成,主要承载南北向数据流量;而AI集群的兴起催生了“东西向后端”新层级,该层级以高带宽、低延迟为核心需求,专门支撑GPU间密集的数据交互,成为Fabric技术扩展的核心场景。
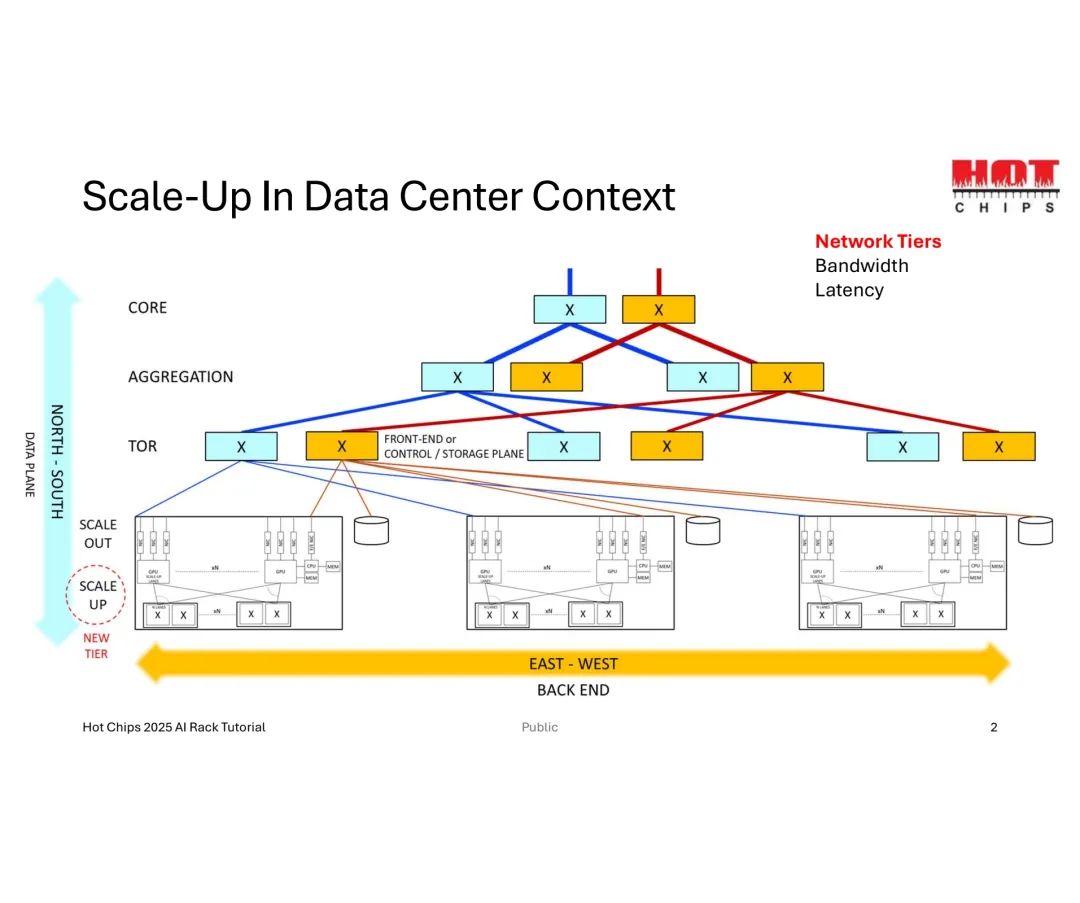
在此背景下,两种扩展模式形成鲜明对比:横向扩展(Scale-Out)依赖Clos层级、叶脊(Leaf-Spine)、网状(Mesh)等灵活的网络拓扑,通过增加节点数量实现规模扩张;纵向扩展(Scale-Up)则聚焦硬件直连性能,以GPU、CPU与内存间的链路(Lanes)优化为核心,通过提升单域带宽满足AI计算对数据传输的极致需求。
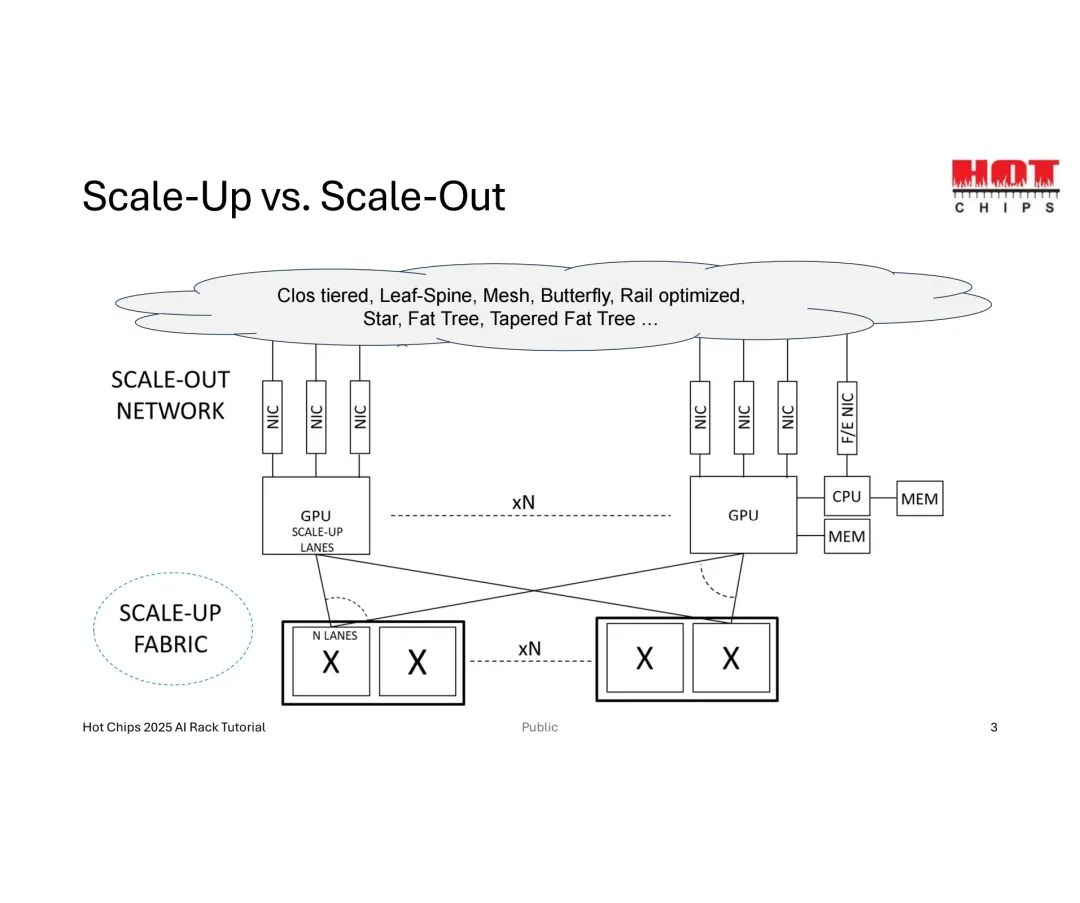
支撑Scale-Up的核心Fabric技术已形成多厂商布局:NVIDIA的NVLink及增强版NVLink Fusion是GPU间高速直连的主流方案,为多GPU协同提供基础;Celestial AI的Photonic Fabric™引入光子技术,突破传统电信号带宽瓶颈;Broadcom的SUE(Scale-Up Ethernet)则在以太网架构下构建纵向扩展框架;UALink联盟推出的UAL(Ultra Accelerator Link)则成为加速器专用的高速互联标准,这些技术共同构成了Scale-Up的技术底座。

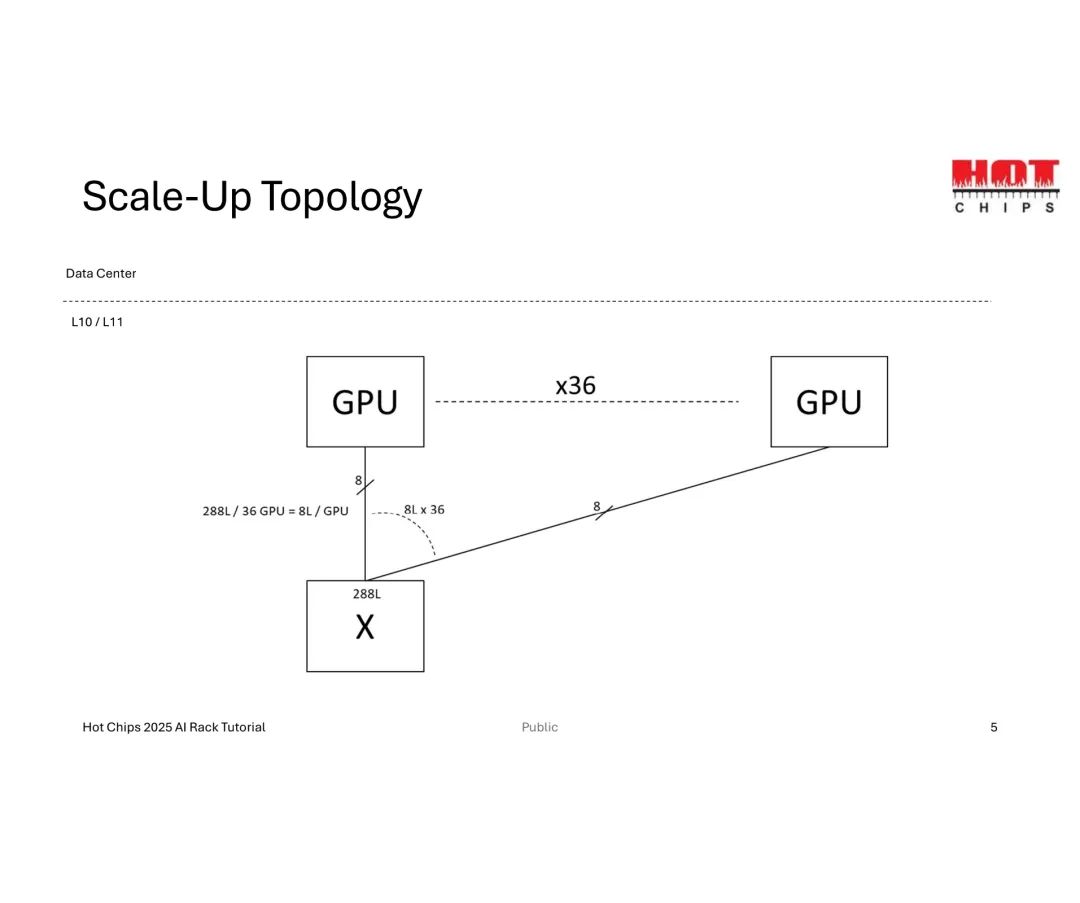
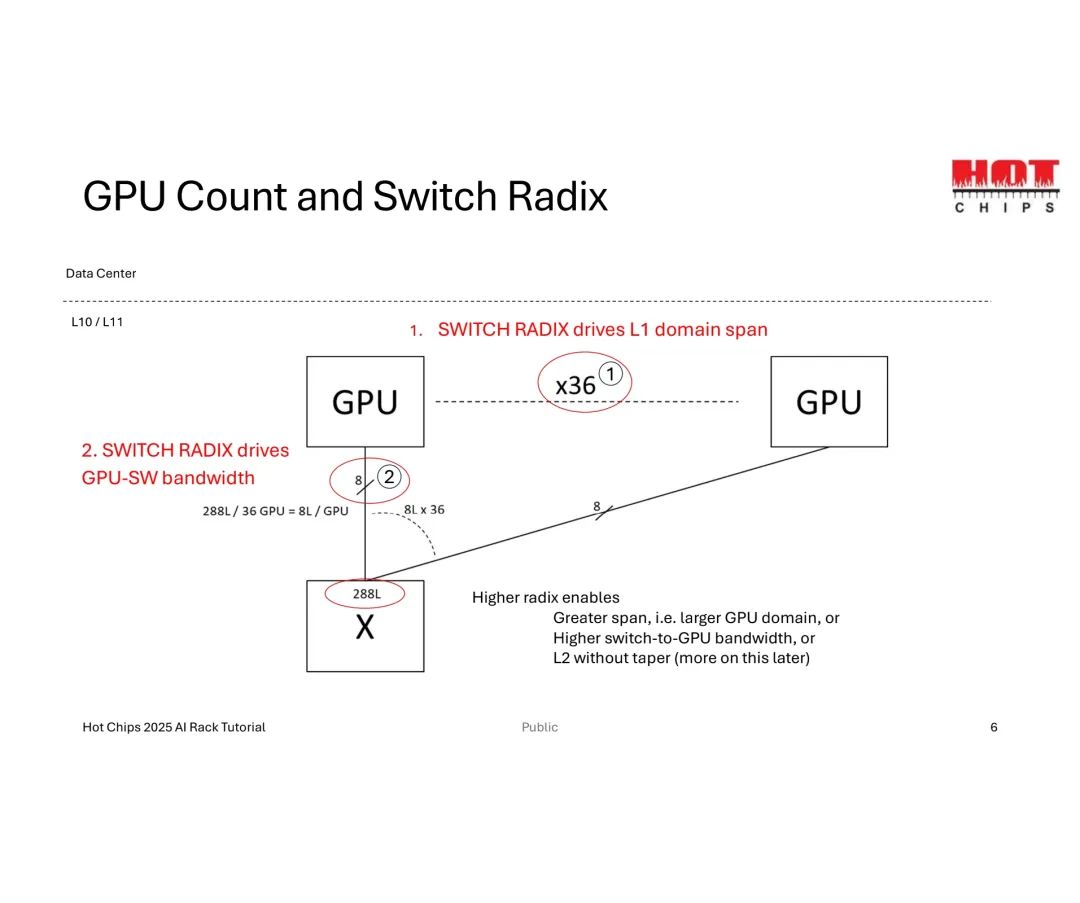
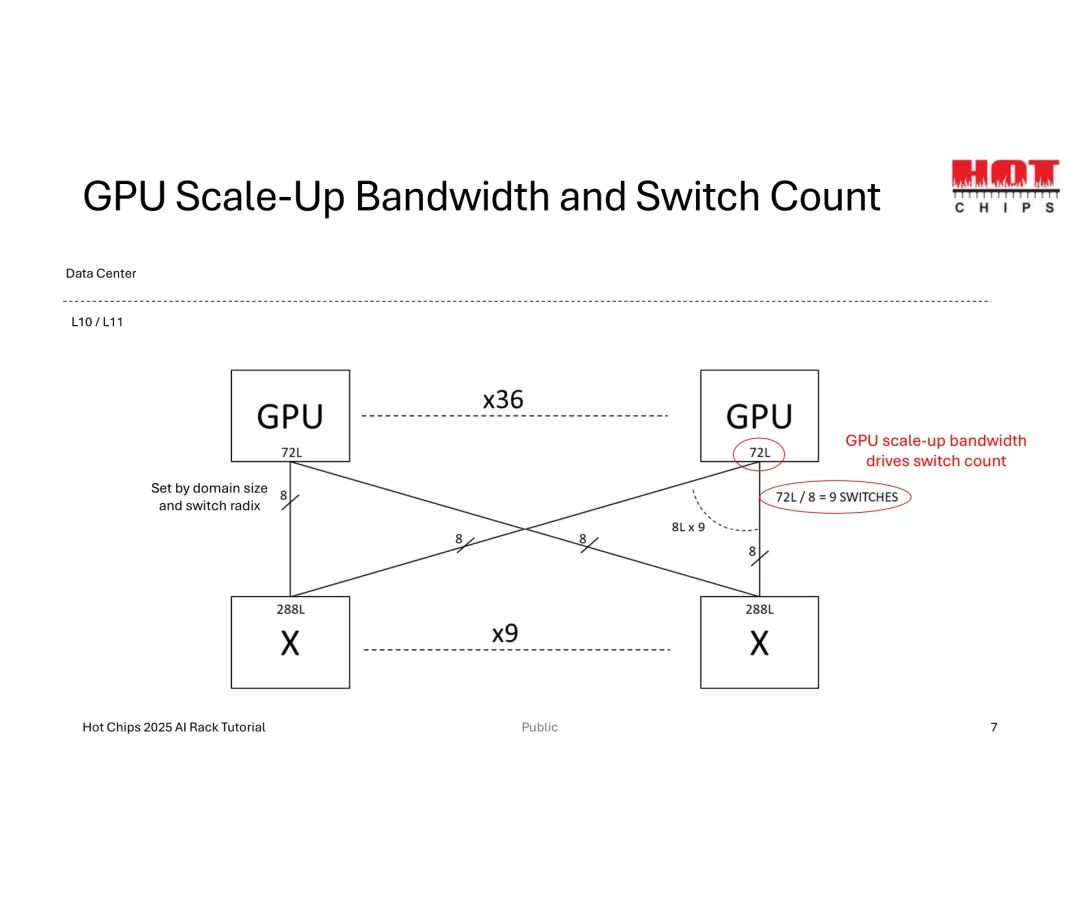
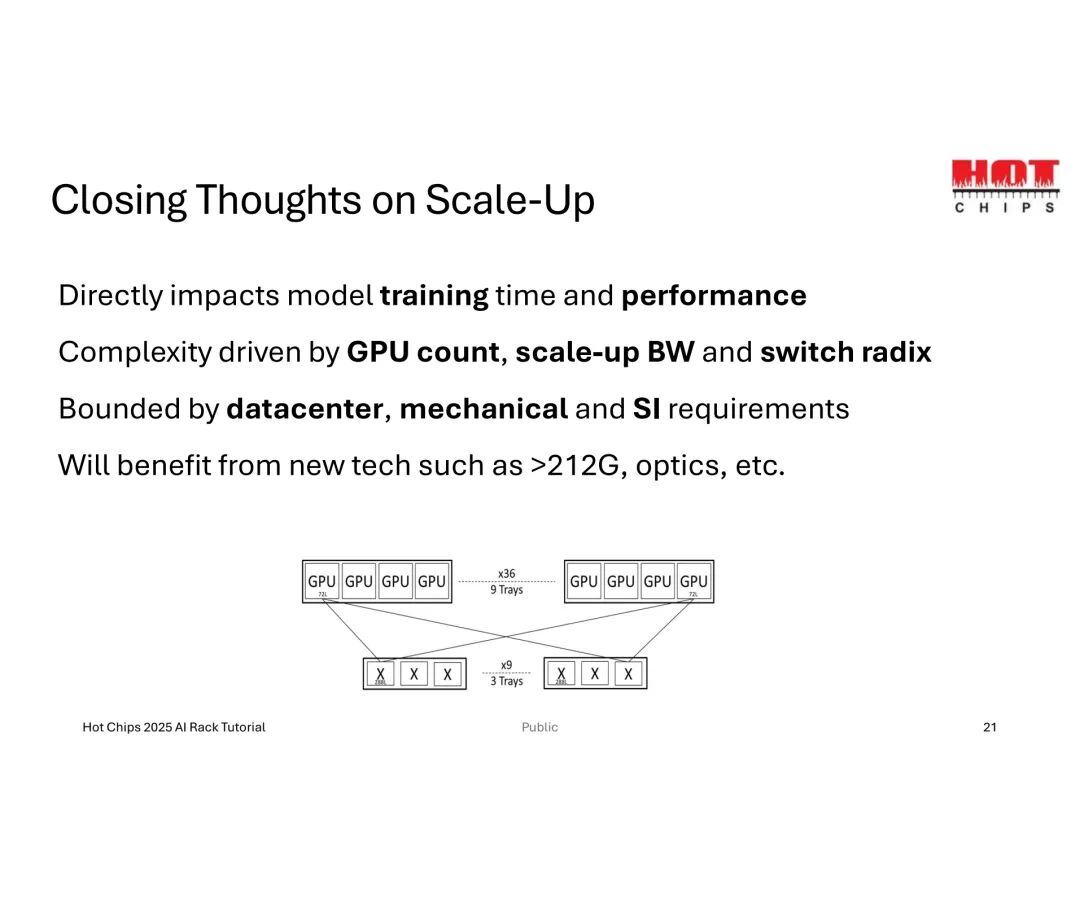
Scale-Up的拓扑设计需围绕“GPU数量-链路数-交换机基数”三者的平衡展开。以数据中心L10/L11层级的基础配置为例,36个GPU需分配288条总链路(即每GPU 8条链路),而交换机基数(单交换机支持的最大链路数)直接决定扩展能力——基数越高,单交换机可覆盖的GPU范围越广,GPU-交换机带宽也越高,甚至可避免后续扩展中的“带宽缩减(Taper)”问题。
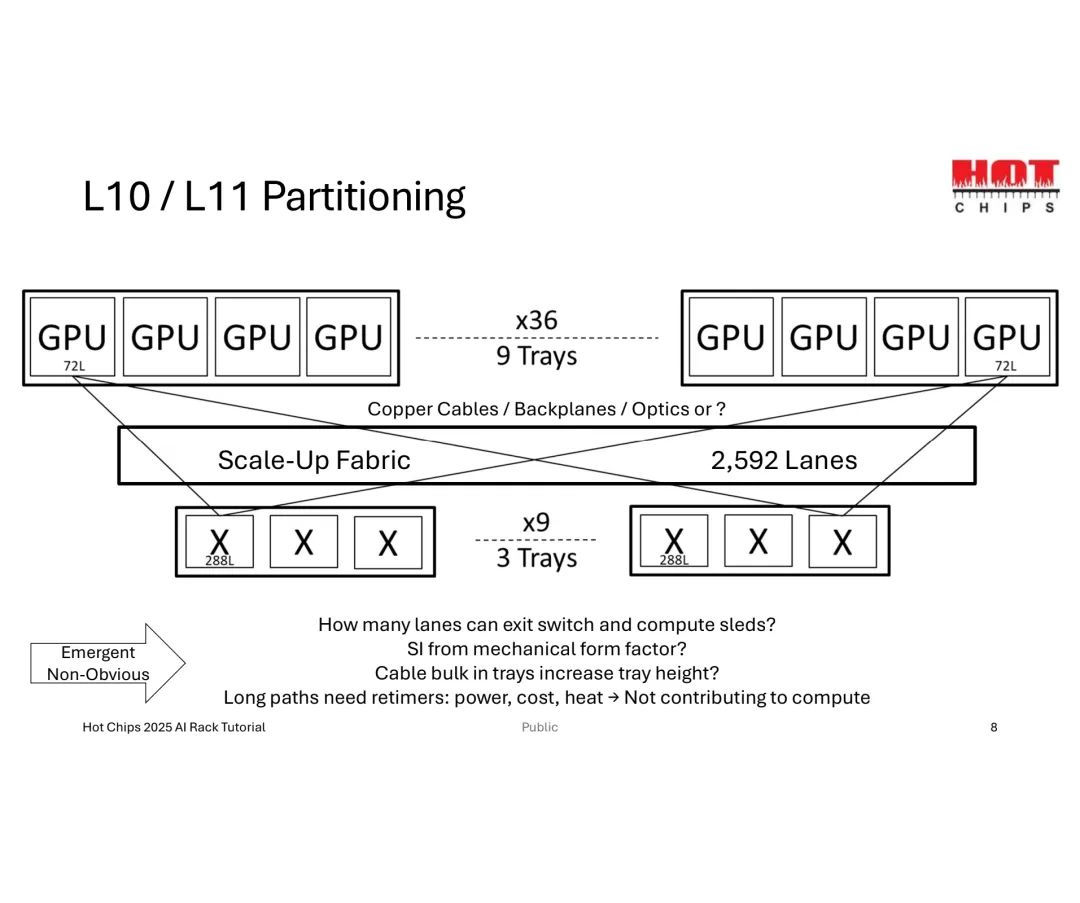
当GPU数量提升至144个时,总链路需求激增至10,368条,传统小基数交换机会导致托盘(Trays)数量过多,挤占机架空间并增加散热压力;此时采用大基数交换机,将单GPU链路分配调整为4条,可将托盘数量从12个缩减至6个,实现机架空间的高效适配。
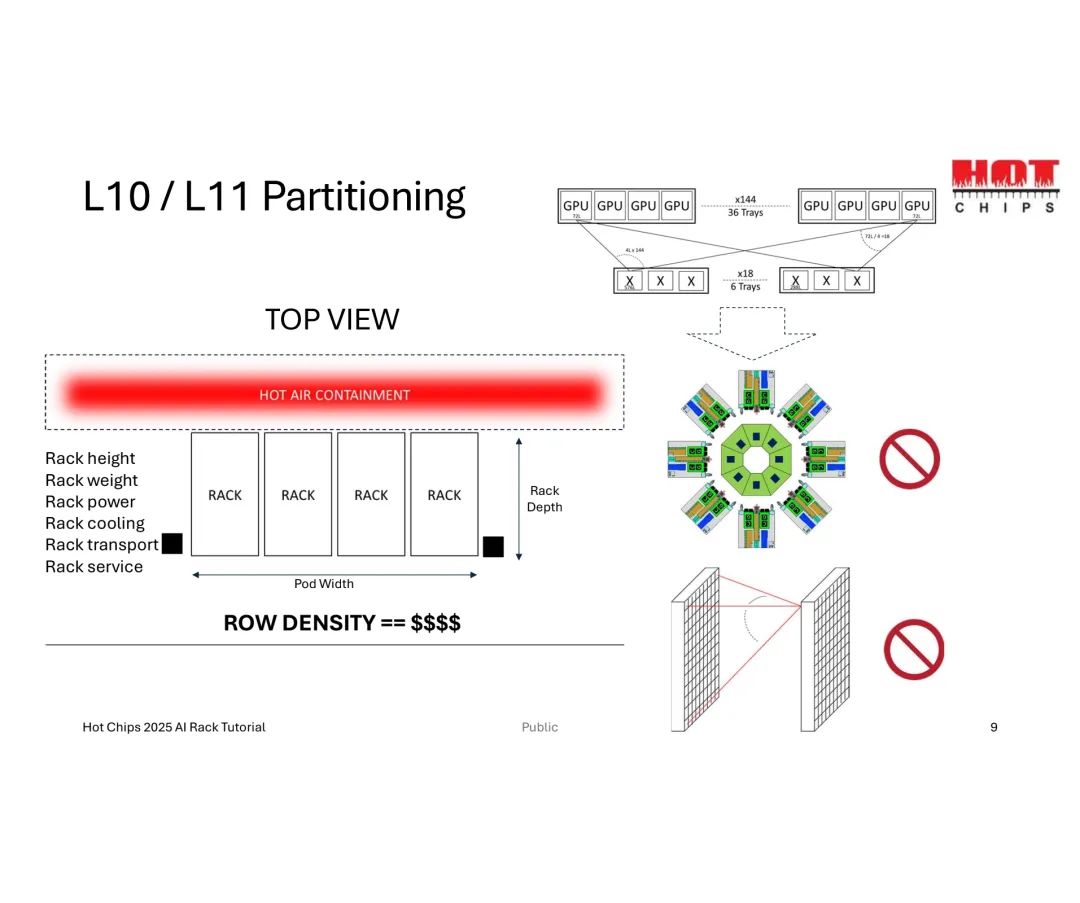
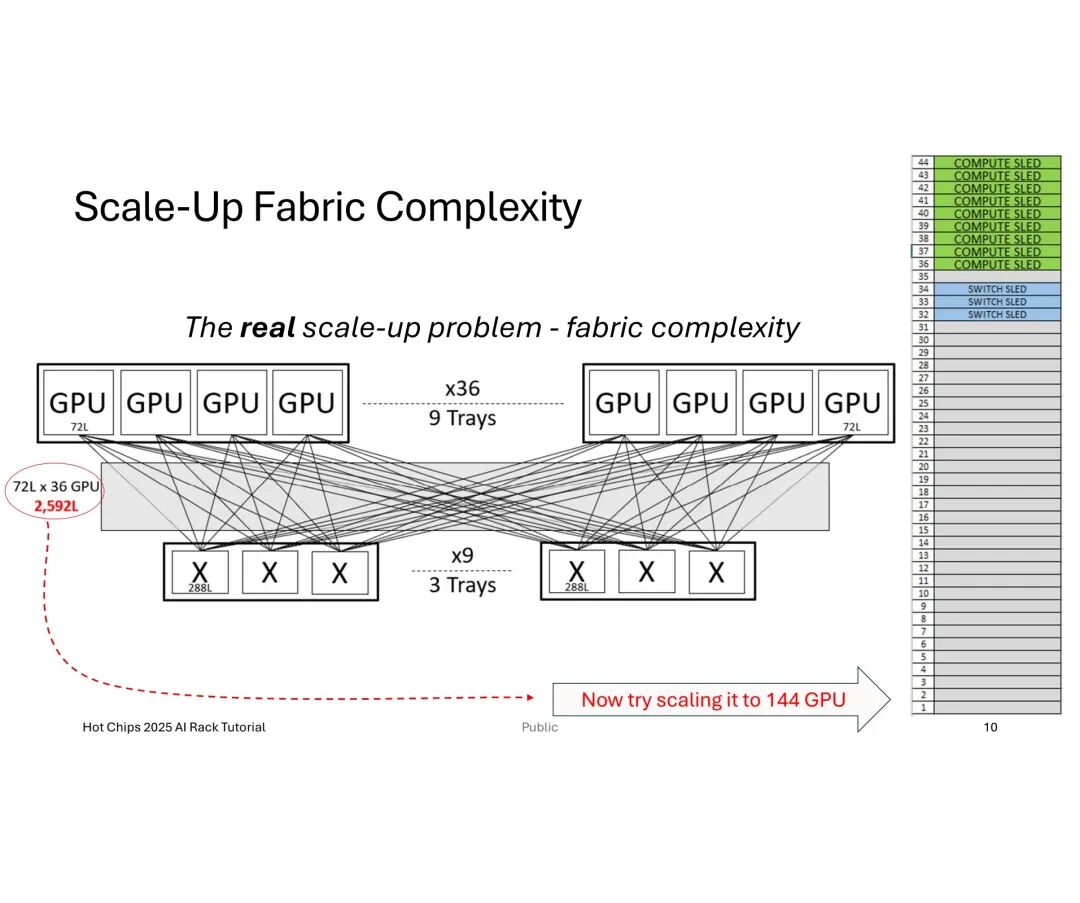
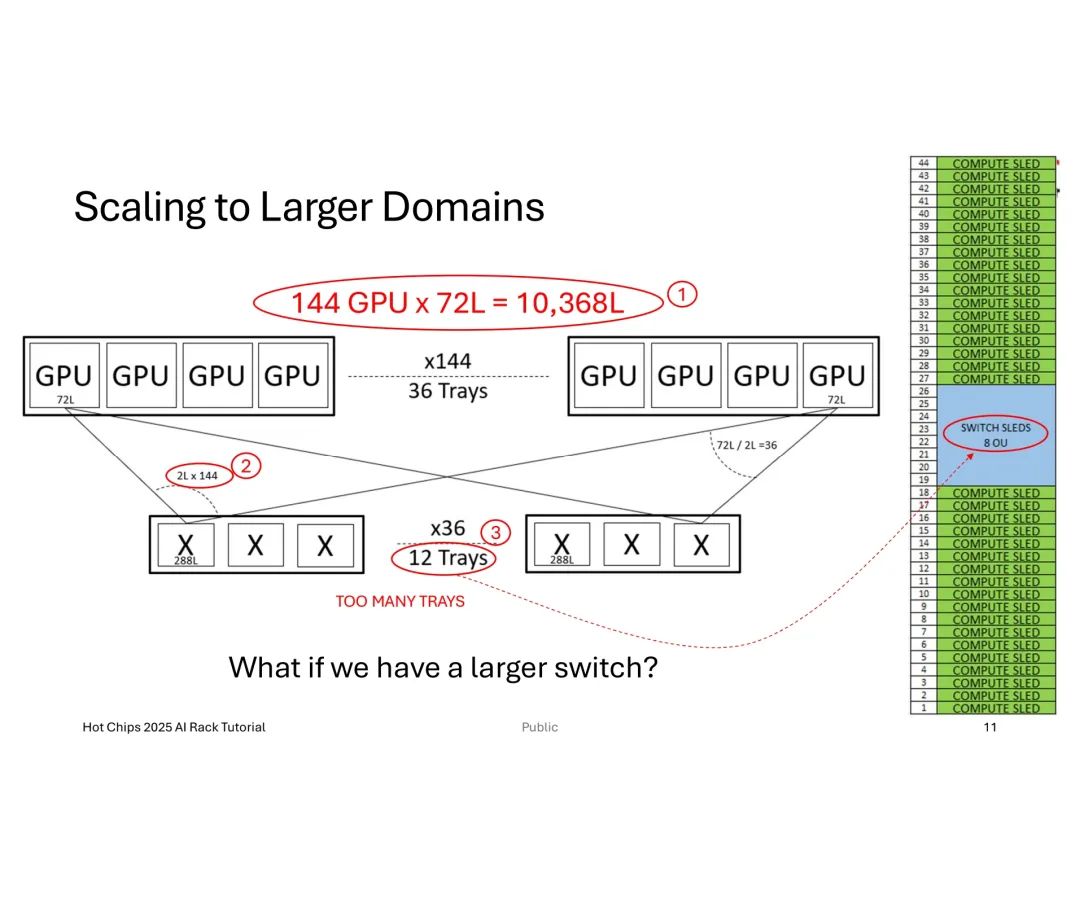
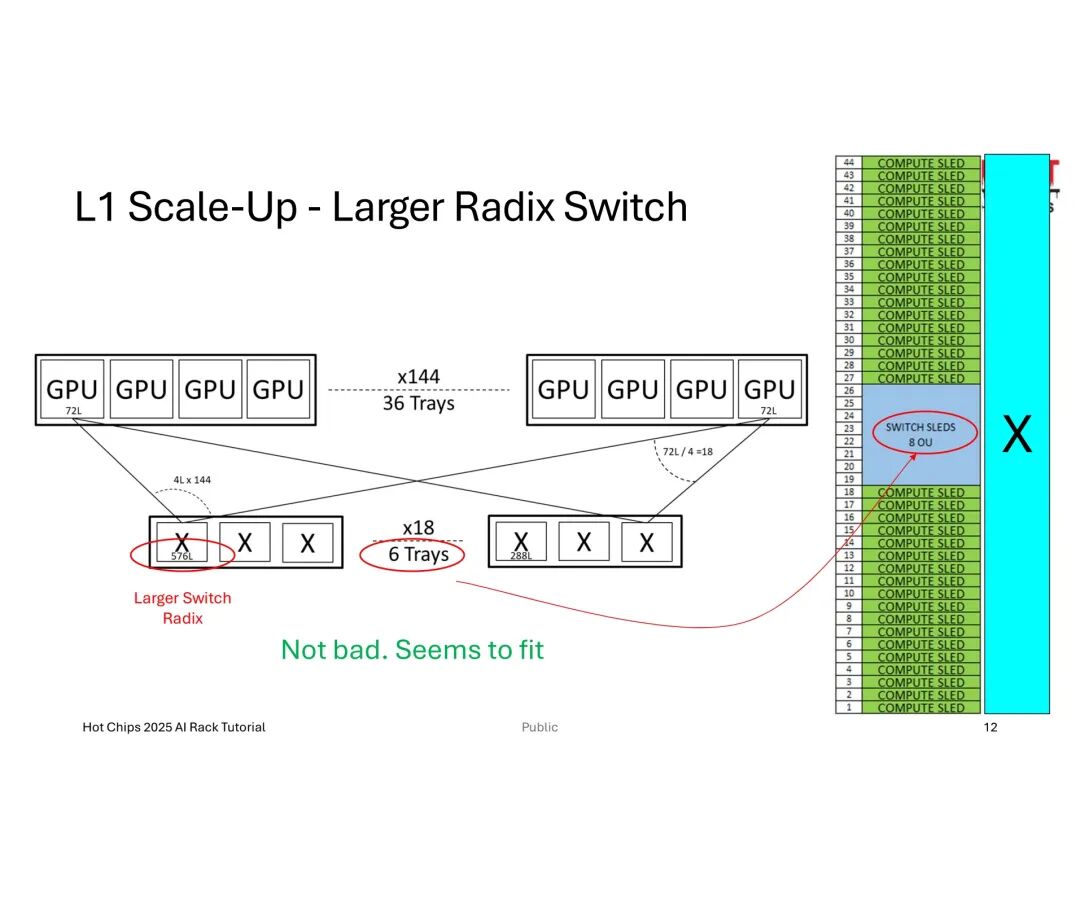
然而,工程落地中的挑战远超理论设计。机械层面,机架的高度、深度、重量及功耗限制直接约束链路密度,且托盘内线缆体积增加会推高托盘高度,长距离链路所需的重定时器(Retimer)虽能优化信号,却会额外消耗功耗、成本并产生热量,且不贡献计算能力。
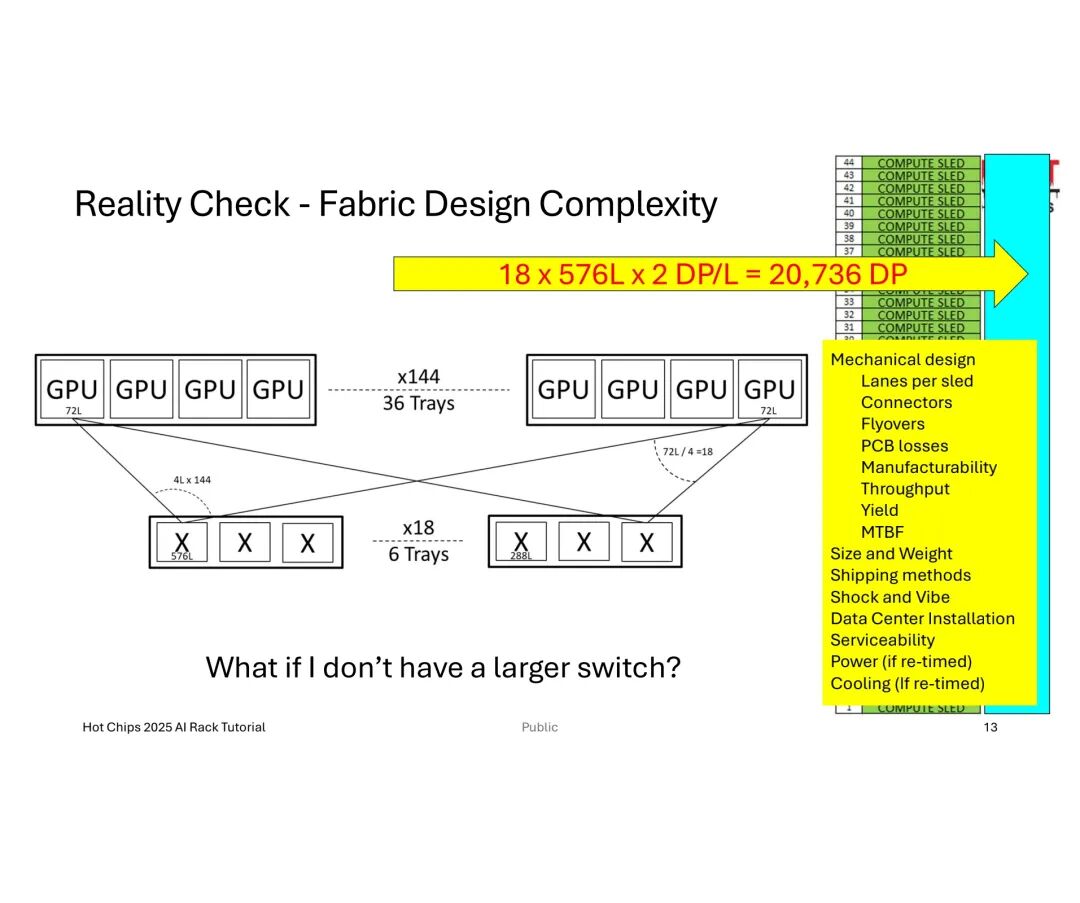
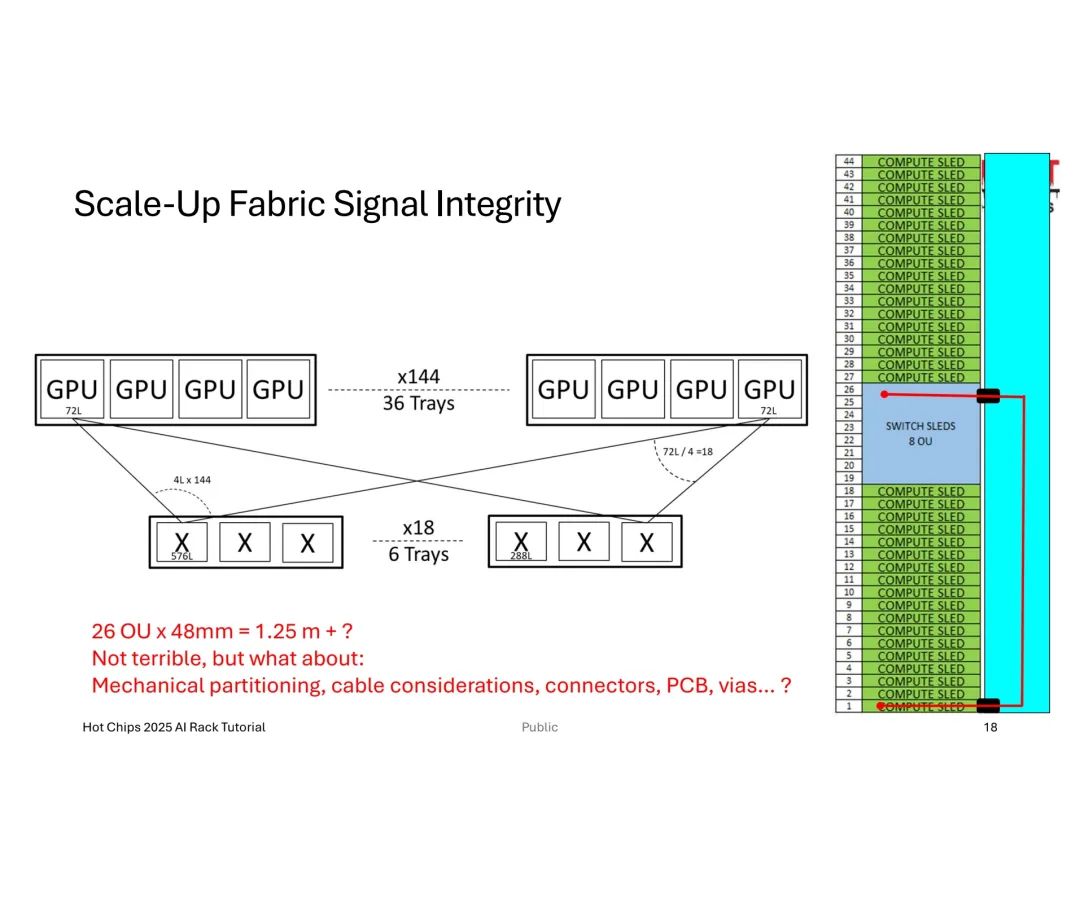
信号完整性(SI)是另一大瓶颈:212G PAM4信号在12英寸PCB上的损耗达15.24dB,2米27 AWG铜缆损耗达17.75dB,而光纤虽损耗极低(850nm多模光纤仅76×10⁻⁶dB/英寸),可插拔光模块(如OSFP)的成本与可靠性却难以平衡——以288 GPU集群为例,需4608个OSFP模块,总成本高达1800万美元,且平均无故障时间(MTBF)仅9天,远低于无源铜缆的500万小时。


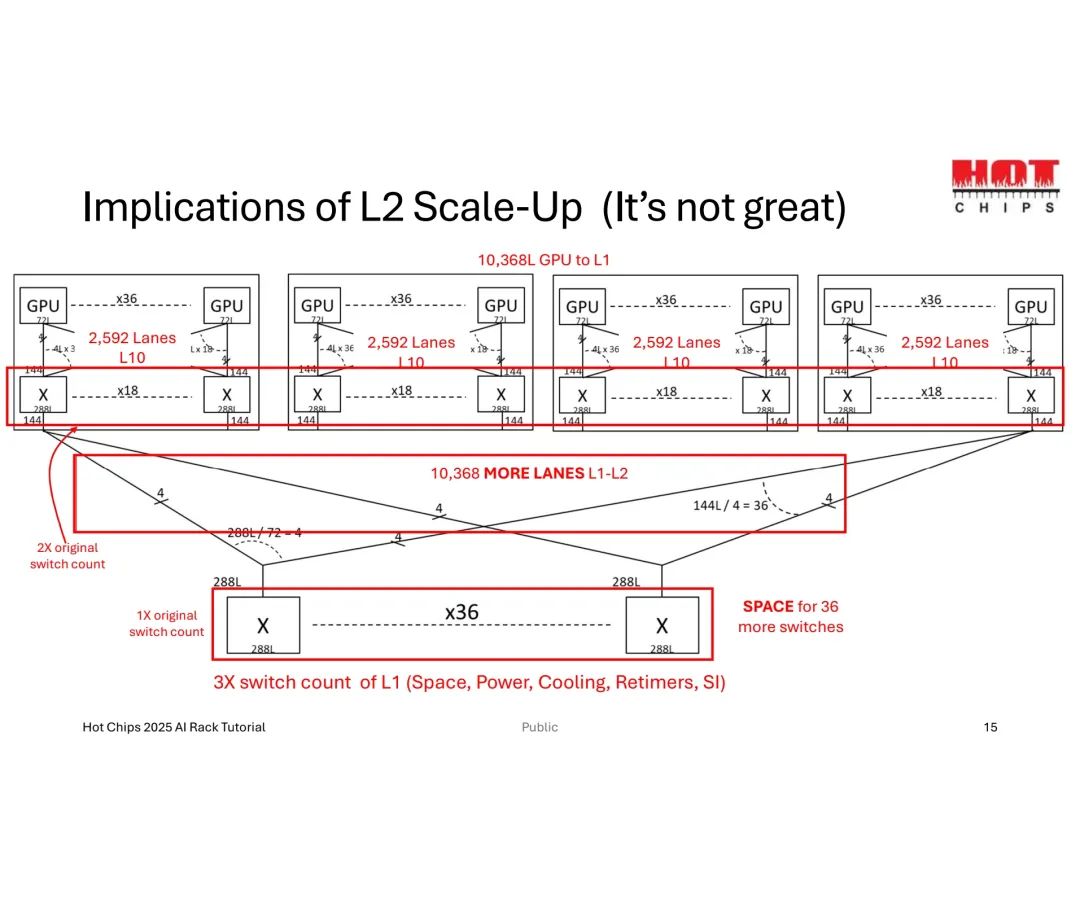
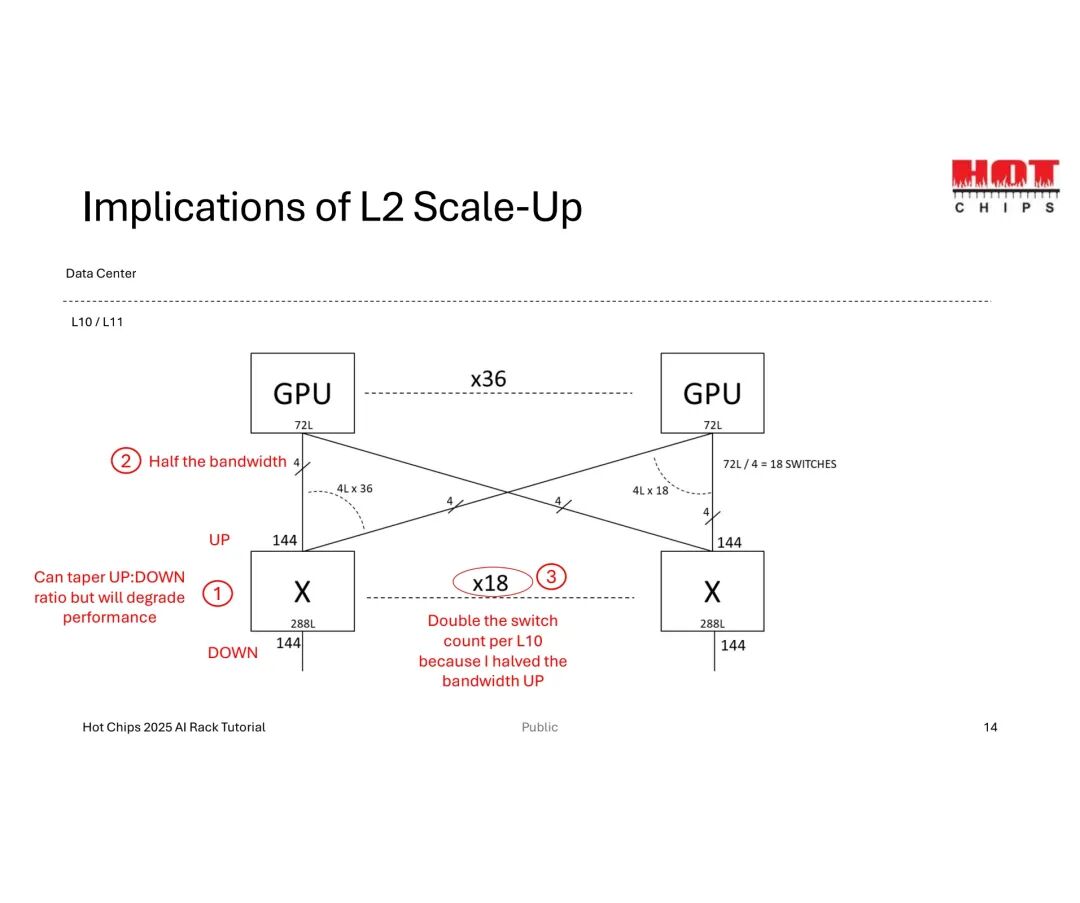
当Scale-Up向更高层级(L2)扩展时,新问题随之出现:L1到L2的上行带宽需压缩至原有的一半,虽可通过调整“上下行带宽比”缓解,却会导致性能降级;同时,交换机数量需增至L1层的3倍,额外占用大量空间、功耗及散热资源。
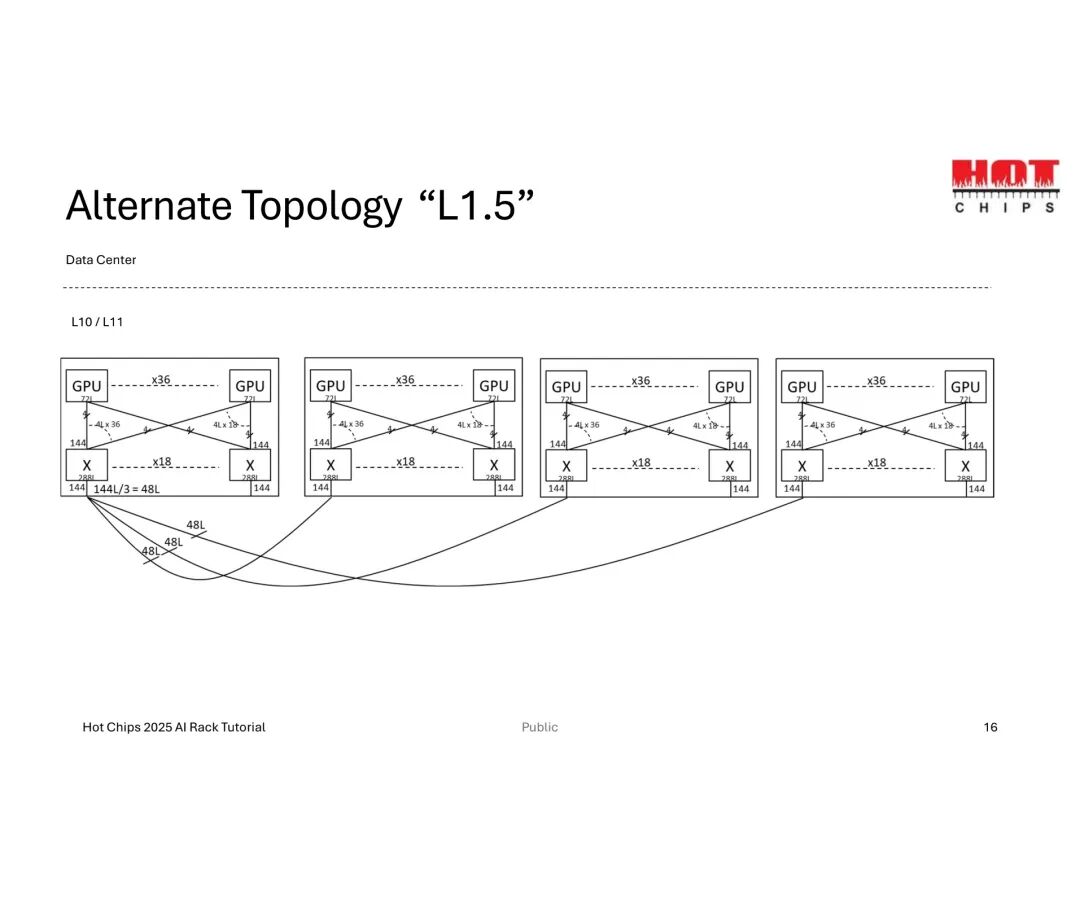
为此,“L1.5”替代拓扑成为折中方案——在L1与L2间增加中间层,构建“域间网状结构”,以3:1的带宽缩减为代价,实现144个GPU的高效互联,兼顾扩展能力与资源消耗。
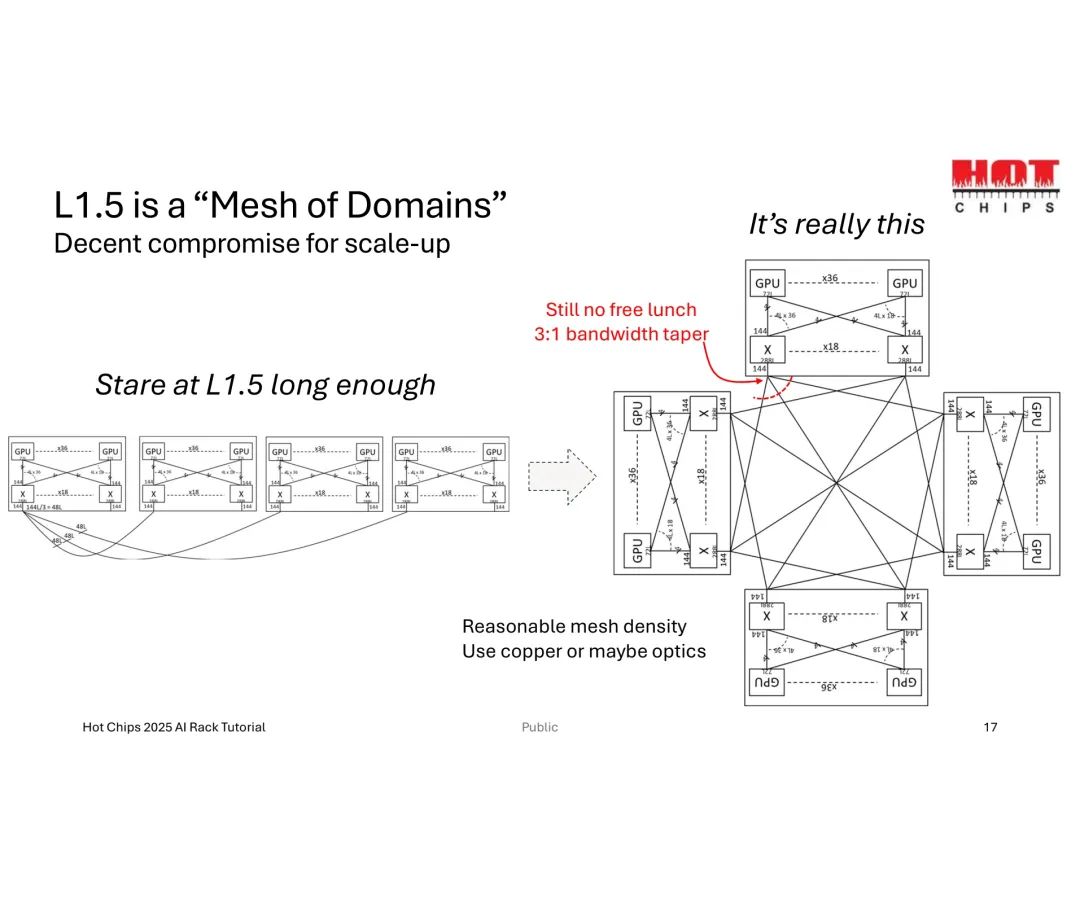
总体而言,Scale-Up技术的核心价值在于直接缩短AI模型训练时间、提升计算性能,但其复杂度由GPU数量、扩展带宽及交换机基数共同决定,且受限于数据中心基础设施、机械设计与信号完整性的物理边界。未来,更高带宽(>212G)技术、优化光模块方案及更大基数交换机的突破,将成为破解Scale-Up落地难题、推动AI集群高效扩展的关键方向。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号