ICML2025|视觉到行动:探索视频预测策略在智能机器人中的突破

ICML2025|视觉到行动:探索视频预测策略在智能机器人中的突破

一点人工一点智能
发布于 2025-08-11 12:06:20
发布于 2025-08-11 12:06:20

编辑:陈萍萍的公主@一点人工一点智能
入群邀请:10个专业方向交流群
导读:论文提出了一种名为VPP(Video Prediction Policy)的新型机器人策略框架,通过利用视频扩散模型内部的预测性视觉表示来指导机器人动作学习,在多项基准测试中实现了显著性能提升。文章揭示如何通过预测未来视觉场景来增强机器人策略的通用性和适应性。

论文地址:https://arxiv.org/abs/2412.14803
项目地址:https://video-prediction-policy.github.io/

简介
论文指出视觉表示在发展通用机器人策略中的核心作用,直指现有视觉编码器的关键局限——它们通常基于单图像重建或双图像对比学习进行预训练,倾向于捕捉静态信息而忽视对体现任务至关重要的动态方面。这一论断准确把握了当前机器人视觉表征学习的瓶颈,作者团队敏锐地观察到视频扩散模型(VDMs)展现出的未来帧预测能力及其对物理世界的深刻理解,进而提出创新假设:VDMs内在地产生包含当前静态信息和预测未来动态的视觉表示,这些表示能为机器人动作学习提供宝贵指导。
基于这一假设,论文提出的视频预测策略(VPP)具有两个显著特点:一是它学习以VDMs内部预测的未来表示为条件的隐式逆动力学模型;二是为了提升预测精度,作者在机器人数据集和互联网人类操作数据上对预训练的视频基础模型进行微调。实验结果令人印象深刻——在Calvin ABC-D泛化基准上相对先前最先进方法提升18.6%,在复杂的现实世界灵巧操作任务中成功率提高31.6%。这些数字不仅验证了方法的有效性,更暗示着预测性视觉表示在机器人学习中的巨大潜力。
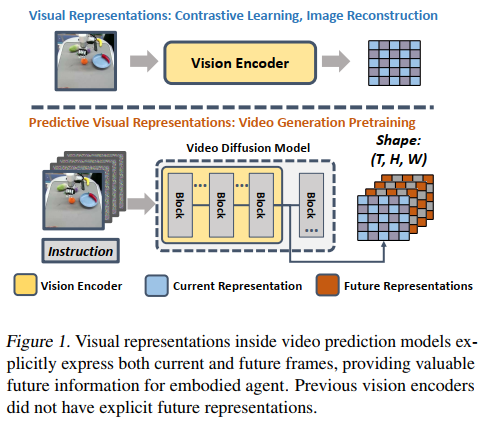
引言系统性地构建了研究背景和动机,作者首先强调构建能够解决多种任务的通用机器人策略是快速发展的研究领域,而视觉编码器作为从像素观察中捕获视觉信息的关键组件,其质量直接影响策略性能。现有研究大多利用互联网视频数据集和自监督技术(如单图像重建、双图像对比学习和图像-文本对比学习)来优化视觉表示,虽然这些方法在体现任务中展现出一定效果,但由于通常仅处理一个或两个采样图像,它们可能无法充分利用连续视频数据中编码的动态信息。
论文随后切入视频扩散模型(VDMs)这一新兴技术,指出其在视频生成任务中取得的显著成果。与传统方法不同,VDMs直接对整个视频序列进行建模,特别是文本引导的视频预测模型(TVPs)能够基于当前观察和指令预测未来帧,显示出对物理动态的良好理解。
作者团队深入观察发现,TVP模型内部的表示通常具有(T,H,W)的张量结构,明确表示1个当前步骤和(T-1)个预测的未来步骤,这与先前不显式捕捉未来表示的视觉编码器形成鲜明对比。
基于这一关键区别,作者将这些潜在变量称为"预测性视觉表示",并形成核心洞见:只要视频模型能准确预测多样化任务的未来场景,策略就可以通过在预测表示中隐式跟踪机械臂位置来生成适当动作,从而将视频预测模型的泛化能力迁移到机器人策略中。

相关工作
论文将现有研究划分为三大类别进行对比分析,清晰定位了本研究的创新位置。在"机器人视觉表示学习"部分,作者系统回顾了自监督学习(SSL)技术在视觉表示学习中的进展,包括对比学习、基于蒸馏的方法和重建方法等。这些技术使视觉编码器能够为体现AI任务生成有效表示,捕获高级语义和低级空间信息。
值得注意的是,作者专门分析了R3M、vip、VC-1和Voltron等方法,它们通过创新人类操作视频数据集的预训练方法,专门针对体现任务进行优化。然而,无论训练目标如何,这些学习到的视觉编码器主要专注于从当前观察中提取相关信息,而没有显式预测未来状态。与此形成鲜明对比的是,本文提出的视频预测策略利用视频预测模型内部的预测表示来显式封装当前和预测的未来帧。
在"体现控制任务的未来预测"部分,论文探讨了利用未来预测增强策略学习的现有研究。例如,SuSIE将其控制策略基于InstructPix2Pix生成的预测未来关键帧,而UniPi学习两个生成帧之间的逆动力学。作者犀利地指出这些方法的局限性——它们依赖于单一的未来预测步骤来确定动作,可能无法准确捕捉物理动态的复杂性。
此外,这些方法对最终未来图像的去噪过程耗时且导致控制频率低下。GR-1以自回归方式生成后续帧和动作,但每次前向传递仅生成一幅图像,其预测质量落后于基于扩散的方法,并且没有利用预训练的视频基础模型。相比之下,VPP利用了从视频基础模型微调得到的表示,并预测一系列未来帧以更有效地指导策略学习,这一对比凸显了VPP方法的优势。
关于"扩散模型内部的视觉表示",论文指出扩散模型在图像和视频生成任务中取得了显著成功。虽然扩散模型是作为去噪器训练的,但研究表明图像扩散模型也可以作为视觉编码器有效工作,生成对于判别任务可线性分离的有意义视觉表示,并且对语义分割极具价值。Gupta等人的工作也指出,图像扩散内部的表示对于体现任务具有多种用途。
然而,作者强调视频扩散模型(VDMs)内部的表示能力尚未得到充分探索,而本研究的发现表明VDMs内部的表示具有独特的预测特性,使其特别适用于顺序体现控制任务。这一分析不仅填补了文献空白,也为VPP方法的创新性提供了理论支撑。

方法 preliminaries
在方法 preliminaries部分,论文首先介绍了视频扩散模型的基础理论,为后续提出的VPP方法奠定数学基础。视频扩散模型的核心思想是通过连续添加高斯噪声使视频序列变为高斯分布,并利用去噪过程生成视频。设x₀表示真实视频样本,前向过程旨在添加高斯噪声并产生一组噪声数据,即
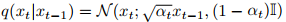
,其中xₜ和αₜ分别表示时间步t的噪声数据和噪声幅度。令
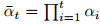
,该过程可简化为
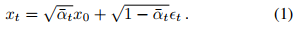
这一简洁的公式表达了噪声添加过程的本质,即随着时间步的增加,原始信号逐渐被噪声所掩盖。
反向过程从噪声最大的样本
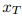
开始,可以用概率q(xₜ₋₁|xₜ)的变分近似来描述:
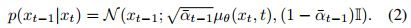
其中
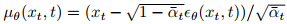
是可学习的神经网络,用于估计xₜ₋₁。进一步,在文本引导的视频生成中,去噪过程学习噪声估计器εθ(xₜ,c)以近似得分函数
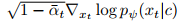
,基于初始帧和语言提示控制视频生成。这些公式构成了视频扩散模型的理论核心,展示了如何通过逐步去噪从随机噪声中生成有意义的视频内容。
论文随后介绍了扩散策略(Diffusion Policy)的概念,指出扩散模型在动作学习中也证明是有效的。扩散政策旨在基于观察si和指令对动作序列
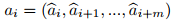
进行去噪。作者引用Chi等人的观点,指出扩散策略能够表达复杂的多模态动作分布并稳定训练。近期工作通过结合先进的扩散变压器(DiT)块进一步增强了扩散策略,这一技术也被VPP采用以提高性能。这些基础理论的阐述不仅展示了作者对领域技术的深刻理解,也为VPP方法的设计提供了理论依据和技术支撑。

视频预测策略方法详解
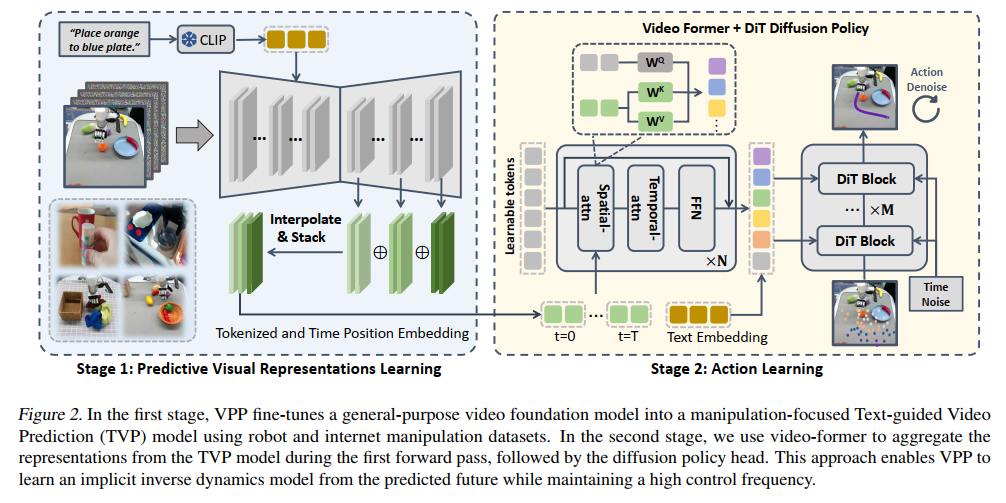
视频预测策略(VPP)是本文的核心创新,其方法部分详细阐述了一个两阶段学习过程,这一设计体现了作者对问题本质的深刻理解和创新性解决方案。
第一阶段将通用视频生成模型 fine-tune 为针对机器人操作的文本引导视频预测(TVP)模型,从互联网数据中获取物理知识;
第二阶段设计网络来聚合TVP模型内部的预测视觉表示并输出最终机器人动作。这种分阶段处理不仅保证了视频预测的准确性,也确保了策略学习的高效性。
文本引导视频预测(TVP)模型的构建过程展现了作者对现有技术的创造性改进。研究团队选择开源的Stable Video Diffusion(SVD)模型(15亿参数)作为基础,观察到开源SVD模型仅以初始帧图像s₀为条件,于是创新性地通过交叉注意力层引入CLIP语言特征lemb,增强了模型的语言理解能力。
同时,他们将输出视频分辨率调整为16x256x256以提高训练和推理效率,在保持原始预训练SVD框架其他组件不变的情况下,成功保留了其核心能力。这一改进后的版本被表示为Vθ,其中初始观察s₀与每个预测帧在通道维度上连接作为条件。模型Vθ通过扩散目标进行训练,从噪声样本
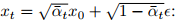
重建数据集D中的完整视频序列
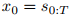
,损失函数为:
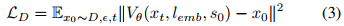
视频预测目标提供了一个统一的接口,可直接生成未来视觉序列,使TVP模型能够利用多样化数据集中的物理知识,包括互联网人类操作数据集DH、互联网机器人操作数据DR和自行收集的数据集DC。
考虑到这些数据集质量和规模的差异,作者创新性地引入特定系数λ来适当平衡不同类型数据集的影响:
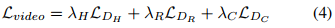
这种加权损失函数的设计体现了作者在处理多源异构数据方面的深思熟虑,为模型获取全面而平衡的知识提供了保障。在完成针对操作任务的TVP模型训练后,将其冻结用于下游动作学习,保证了预测模块的稳定性。
基于预测视觉表示的动作学习是VPP的第二阶段,也是最具创新性的部分。作者首先提出将TVP模型主要作为"视觉编码器"而非"去噪器"使用,仅执行单步前向传播。这一关键设计源于重要洞见:虽然第一步前向传播不会产生清晰的视频,但仍能提供未来状态的粗略轨迹和有价值的指导。
具体实现中,作者将当前图像s₀与最终噪声潜在
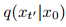
(通常是白噪声)连接起来输入TVP模型,然后直接利用潜在特征。基于先前研究指出扩散模型中的上采样层能产生更有效表示,作者提取第m个上采样层的特征(宽度Wm和高度Hm)表示为:
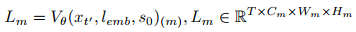
为了有效聚合来自不同上采样层的特征并消除手动选择层的需要,作者提出了一种跨层特征自动聚合方法。首先将每层的特征图线性插值到相同高度和宽度Wp×Hp:
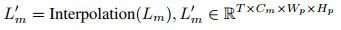
然后沿通道维度堆叠特征,得到最终的预测视觉表示
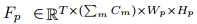
:
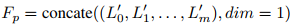
对于具有多摄像头视角的机器人(如第三视角和腕部摄像头),独立预测每个视角的未来,记为
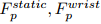
。这种多视角处理方式增强了系统对复杂操作场景的适应能力。
视频前导模块(Video Former)的设计体现了作者对高效特征提取的追求。TVP模型内部的预测表示仍然是高维的,因为它们表达了一系列图像特征。为了有效聚合跨空间、时间和多视角维度的表示,作者设计了Video Former将这些信息整合为固定数量的标记。Video Former初始化可学习标记
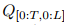
,对每一帧执行空间-时间注意力,然后是前馈层。这一分支可形式化表示为:
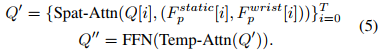
这种结构不仅降低了计算复杂度,也保留了关键的时空信息。
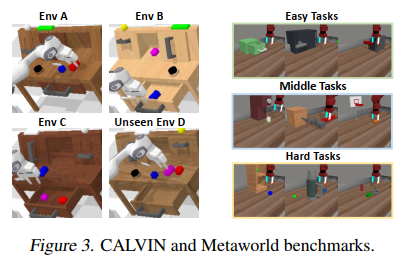
动作生成部分采用扩散策略作为动作头,基于Q''生成动作序列a₀∈A。作者将聚合表示Q''通过交叉注意力层整合到扩散变压器块中。扩散策略旨在从噪声动作
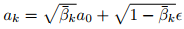
重建原始动作a₀,其中ε表示白噪声,
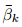
是步骤k的噪声系数。这一步可解释为学习去噪器Dψ来近似噪声ε并最小化以下损失函数:
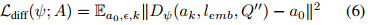
这种基于扩散的动作生成方法能够处理多模态动作分布,提高了策略的灵活性和鲁棒性。
整个VPP方法的设计体现了作者对视频扩散模型内部表示的深刻理解和对机器人学习需求的准确把握,通过创新的两阶段框架和精心设计的组件,成功地将视频预测能力转化为有效的机器人控制策略,为通用机器人学习开辟了新途径。

实验设计与结果分析
实验部分设计全面而深入,作者在模拟和真实世界机器人任务上进行了广泛实验,以评估视频预测策略(VPP)的性能,并设置了四个关键研究问题:
(1)VPP能否通过预测视觉表示在操作任务中获得更高成功率?
(2)视频预训练和互联网操作数据集如何提升VPP性能?
(3)预测表示与先前视觉表示相比如何?
(4)视频扩散模型的哪一层能提供最有效的预测视觉表示?
模拟实验设置包含两个主流基准测试。CALVIN基准旨在评估机器人策略在长视野操作任务中遵循指令的能力,作者专注于具有挑战性的ABC→D设置,其中智能体在ABC环境中训练,在未见过的D环境中评估,这一设置严格测试了策略的泛化能力。MetaWorld基准则以Sawyer机器人执行各种操作任务为特色,广泛用于评估机器人策略的精确性和灵活性,包含50个任务,操作对象丰富且难度各异。作者使用官方Oracle策略为每个任务收集50条轨迹作为训练数据集,确保了数据的质量和多样性。
VPP训练细节体现了方法的实用性和可复现性。采用两阶段训练过程:
第一阶段:将视频基础模型fine-tune为专注于操作的TVP模型,使用的视频包括193,690条人类操作轨迹和179,074条机器人操作轨迹,以及下游任务视频(如官方Calvin ABC视频、MetaWorld视频和真实世界视频)。考虑到这些数据集规模和质量的差异,作者应用不同采样比例,遵循Octo的方法,这种精细化处理确保了数据利用的合理性。
第二阶段:TVP模型的fine-tuning在8个NVIDIA A100 GPU上耗时2-3天,第二阶段使用Calvin或MetaWorld数据集训练通用策略,在4个A100 GPU上约需6-12小时,这些细节为后续研究者提供了宝贵的实施参考。
策略部署细节展现了作者对实际应用问题的关注。与之前工作选择去噪高精度视频(耗时且导致低频率甚至开环控制)不同,VPP将TVP模型作为编码器使用,确保每个观察仅通过TVP模型处理一次(耗时少于160ms),使下游策略基于预测表示生成动作。这一修改使得在消费级NVIDIA RTX 4090 GPU上能达到7-10Hz的较高频率。此外,作者实施了10步动作分块进一步提高了控制频率,这些优化显著增强了方法的实用性。
对比方法的选择全面而有代表性,包括:
· RT-1(集成语义信息的直接动作学习策略)
· Diffusion Policy(具有新型动作扩散器的直接学习策略)
· Robo-Flamingo(利用预训练LLM的策略)
· Uni-Pi(学习生成未来序列然后学习两帧间逆运动学模型)
· MDT(学习扩散变压器策略及重建掩码未来帧的辅助mac损失)
· Susie(使用fine-tuned InstructPix2Pix模型生成目标图像)
· GR-1(使用自回归变压器联合学习视频和动作序列)
· Robo-Uniview(学习具有3d占用损失的3d感知视觉编码器)
· Vidman(在OXE视频数据集上预训练)
这些基线方法涵盖了当前主流的技术路线,为公平比较奠定了基础。
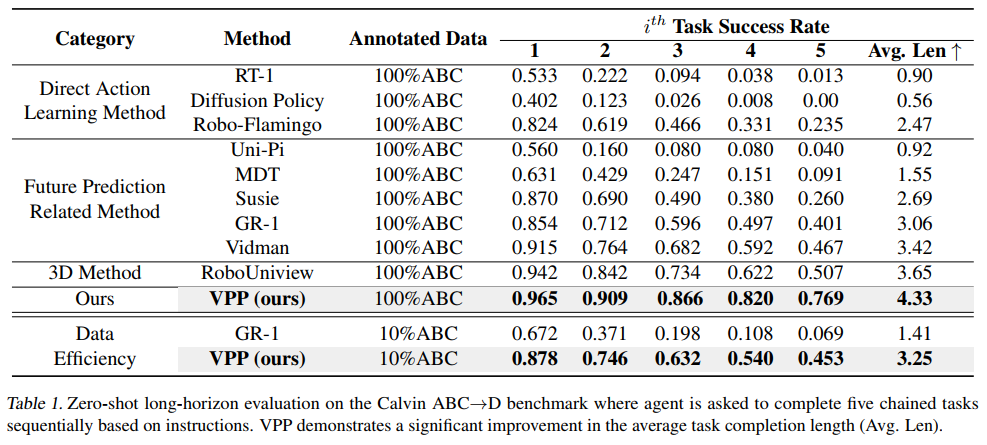
定量结果令人印象深刻。如表1所示,在Calvin基准测试中,VPP将先前最先进结果从平均任务完成长度3.35显著提高到4.33。即使仅使用10%的标注Calvin ABC数据进行训练,VPP仍能达到3.25的长度,超过相关方法使用全部数据的结果。在包含50个任务的MetaWorld基准测试中,VPP以68.2%的平均成功率超过最强GR-1基线10.8%。这些结果强有力地验证了VPP方法的优越性。
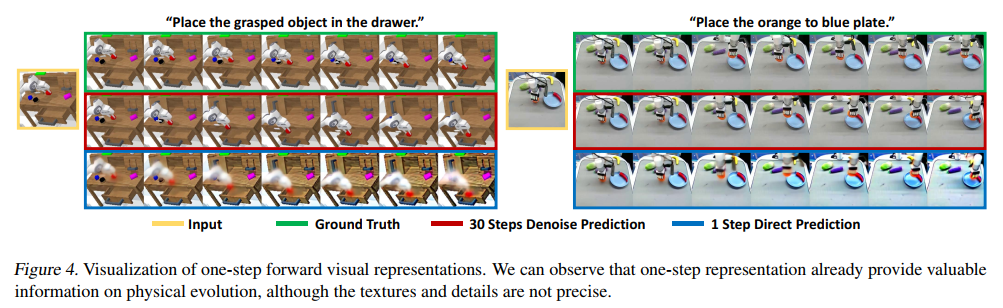
预测表示可视化提供了直观的见解。如图4所示,作者可视化真实未来、单步预测和30步去噪预测,发现单步表示已能传递有价值信息(如物体和机械臂的运动),有效支持下游动作学习。这一发现证明了单步前向传播的有效性,为方法的高效性提供了依据。
消融研究系统验证了VPP各组件的重要性。在预测视觉表示有效性验证中,将VDM视觉编码器替换为其他预训练视觉编码器(如Stable-VAE、VC-1和Voltron)导致性能明显下降,证实了预测表示的优越性。在视频预训练和互联网操作数据集有效性测试中,移除共同训练的互联网操作数据使性能从4.33降至3.97;进一步移除预训练SVD模型并从头开始在Calvin数据集上训练视频预测模型,则导致性能大幅下降。这些结果凸显了大规模预训练和多样化数据的重要性。

Video Former模块的消融研究表明,移除它会使得VPP分数从4.33降至3.86,而推理时间几乎增加两倍,证实了该模块在准确性和计算效率方面的关键作用。特征聚合机制的消融实验显示,使用最终层特征替代聚合特征会导致平均任务完成长度从4.33降至3.60,证明了多层级特征利用的价值。这些细致的消融研究为方法设计提供了充分依据,增强了结论的可信度。
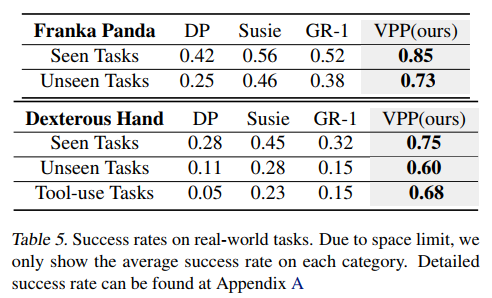
真实世界实验在Franka Panda机械臂和12自由度Xhand灵巧手上验证了VPP。在Franka Panda平台上收集了6类30多个任务的2000条轨迹,在灵巧手平台上收集了13类100多个任务的4000条轨迹,包括四个具有挑战性的工具使用任务(勺子、锤子、电钻和化学移液管)。
如表5所示,VPP在机械臂的已见任务和未见任务中分别达到85%和73%的成功率,在灵巧手的已见任务、未见任务和工具使用任务中分别达到75%、60%和68%的成功率,全面超越基线方法,展示了强大的泛化能力和实用性。
泛化分析通过三个未见任务(捡网球、倒可乐和使用勺子)的案例研究,揭示了VPP的泛化机制:
(1)由于互联网规模的预训练,视频模型即使在未见任务上也能做出正确的视觉预测;
(2)低级策略学习了鲁棒的逆动力学模型,只需隐式跟踪机器人在预测未来中的运动,无需关注新物体或背景。
这种将高级预测与低级控制分离的架构设计,使得VPP能够成功泛化到各种未见任务,如图6所示,实际执行轨迹与预测未来状态紧密对齐,直观展示了方法的有效性。


结论与未来展望
作者团队提出了一种学习通用机器人策略的新方法,通过以VDMs内部的预测表示为条件学习隐式逆动力学模型,在模拟和现实世界任务中实现了一致的性能提升。结尾处,作者前瞻性地指出随着视频生成模型日益强大,释放视频模型在构建物理智能方面的全部潜力将成为重要方向,强调了视频生成模型在体现任务中的应用前景。
创新点:
首先,它创新性地利用视频扩散模型内部的潜在表示作为预测性视觉表征,这些表征隐式编码了未来场景的演化信息;
其次,设计了两阶段学习框架,先fine-tune专用视频预测模型,再学习基于预测表征的策略,实现了视频预测与动作生成的有机结合;
最后,提出的Video Former模块和特征聚合机制有效处理了高维预测表征,平衡了性能与效率。
这些创新不仅解决了现有视觉编码器忽视动态信息的局限,也为机器人学习提供了新的思路。
理论意义:该研究深化了我们对视频扩散模型内部表示的理解,揭示了它们作为"世界模型"的潜力。研究表明,即使在不完全去噪的情况下,VDMs的中间表示已包含足够的环境动态信息,这对发展基于表示的机器人学习方法具有重要启示。同时,论文验证了将大规模生成模型作为感知系统的有效性,为构建通用机器人系统提供了新范式。
实际应用价值:VPP在多个基准测试中展现出的优越性能,特别是对未见任务的强泛化能力,使其在工业自动化、家庭服务等需要适应多样环境的机器人应用中具有广阔前景。方法对计算效率的优化(如单步前向、动作分块等)也增强了其在实际系统中的可行性。提供的详细训练部署细节(如数据配比、硬件需求、训练时间等)为实际应用提供了可靠参考。
未来研究方向:
首先,探索更大规模的视频基础模型(如Sora)对性能的影响;
其次,研究如何将物理引擎知识与数据驱动的预测模型结合,提升预测的物理合理性;
再次,优化多模态表征学习,更好地整合视觉、语言和动作信息;
最后,开发更高效的架构,进一步降低计算成本,实现实时控制。
此外,将VPP扩展到更复杂的任务场景(如移动操作、人机协作等)也是值得探索的方向。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号