DETR、去噪与视觉Transformer目标检测的进化之路
原创
DETR、去噪与视觉Transformer目标检测的进化之路
原创
CoovallyAIHub
修改于 2025-06-30 09:52:47
修改于 2025-06-30 09:52:47
【导读】
自2020年DETR提出以来,基于Transformer的目标检测模型成为学界研究热点。虽然 DETR 展示了新范式的巨大潜力,但也暴露出诸如收敛慢、匹配机制不稳定等问题。随后的一系列改进方案(如Deformable DETR、DAB-DETR、DN-DETR、DINO等)正是在解决这些瓶颈。今天,我们带你一文了解Vision Transformer在目标检测上的演进逻辑,特别是“去噪机制(DN)”如何深刻改变了 Transformer 检测器的训练路径。
一、DETR:Transformer + 目标检测的开端
DETR(DEtection TRansformer)是 Carion 等人在 2020 年提出的首个端到端目标检测 Transformer 架构。它的核心设计是使用一组随机初始化的解码器查询(queries),直接从图像 token 中提取检测框和类别信息,而非传统的锚点机制。这些 queries 并没有被赋予空间含义,因此训练需要长达 500 个 epoch 才能收敛,效率极低。
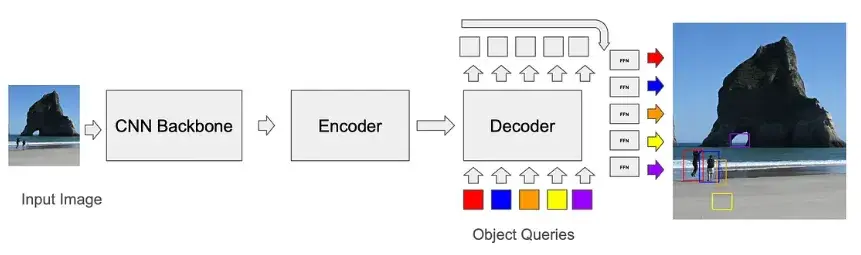
为了解决这一问题,后续研究引入了空间约束和结构先验——如:
- Deformable DETR:提出可变形注意力机制,让 queries 聚焦图像局部区域;
- DAB-DETR:引入空间锚点并将其编码进 queries,使其具备“锚点感知”能力。
这些方法在一定程度上提升了训练效率,但核心问题仍在于——Transformer 的查询机制训练不稳定,容易“飘忽不定”。
二、问题根源:匈牙利匹配算法
DETR 架构使用的是匈牙利算法来将模型预测与真实标签(GT)进行一一匹配。这种全局最优匹配机制虽然严谨,但存在两个问题:
- 时间复杂度高:匈牙利算法的复杂度为 O(n³),虽然可接受,但限制了大规模扩展;
- 结果不稳定:微小的预测变动可能造成完全不同的匹配结果,导致训练目标不一致,进而引发梯度震荡,使模型难以快速收敛。
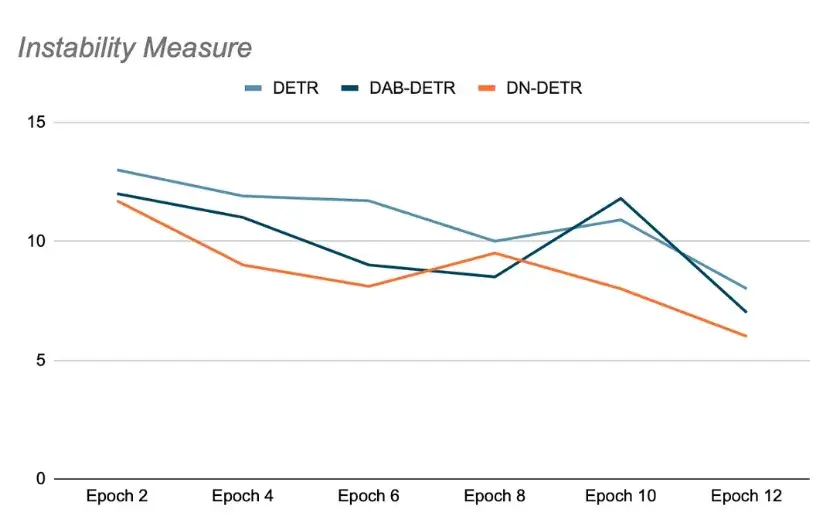
三、DN-DETR:用“去噪”绕过不稳定匹配
为解决上述问题,Li 等人提出了DN-DETR(Denoising DETR),其核心思路是:
绕过匈牙利匹配,直接给Transformer查询一个“热启动”目标。
具体做法是:
- 将 GT 框加上微量噪声,构造出“虚拟锚点”;
- 将这些锚点直接作为训练时的解码器输入查询;
- 设置遮罩机制,防止原始查询与这些 DN 查询发生交叉干扰;
- 匹配关系在构造时就确定,不再需要匈牙利匹配!
这样做的好处是:
- 提升了训练稳定性,避免了“跳来跳去”的训练目标;
- 显著加快收敛速度(训练 50 epoch 的性能就超过了原始 DETR 的最佳性能);
- 在 COCO 数据集上,ResNet-50 骨干的 AP 提升了 1.9 个点(相比 DAB-DETR 的 42.2%)。
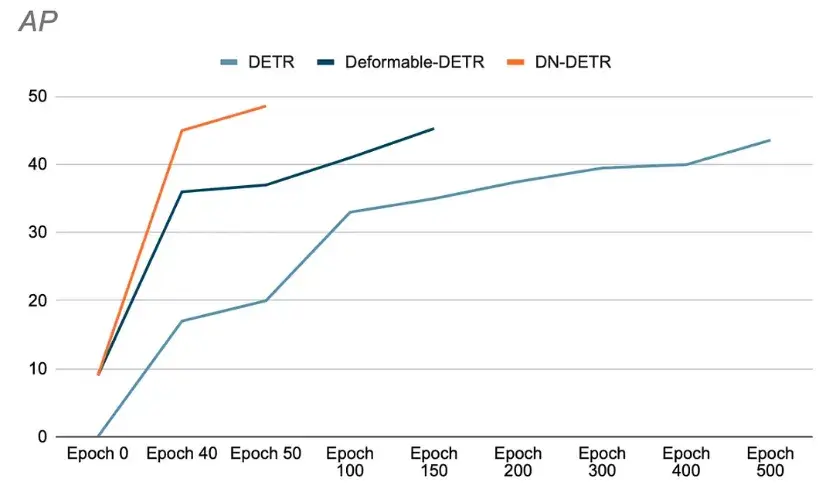
四、DINO:引入对比学习的去噪升级
DINO 模型进一步升级了去噪机制,通过加入对比学习(Contrastive Denoising)的思想增强学习信号:
- 除了加入正例噪声框,还构造了离 GT 框更远的负例(红色框),训练模型区分“更可信”和“不可信”的检测;
- 引入多个去噪组(CDN group),为每个 GT 框生成多个正负样本对,提高样本多样性;
- 显著提升检测效果,COCO val2017 上取得 49% AP。
这个过程中,“去噪”不仅仅是加速训练的辅助工具,更成为指导模型理解检测目标的“核心机制”。

训练过程快照。绿色框是当前锚点(从先前图像中学习或固定)。蓝色框是鸟类目标的地面实况 (GT) 框。黄色框是通过向 GT 框添加噪声(同时改变位置和尺寸)生成的正例。红色框是负例,保证其与 GT 的距离(在 x、y、w、h 空间中)比正例更远。
五、去噪的更深价值:多帧追踪
去噪机制的最大潜力,其实是在视频追踪模型中被真正释放出来。
例如在 Sparse4Dv3 等时序 Transformer 中,模型需要逐帧检测并跟踪物体,不只是输出框,还要保持物体 ID 的连续性。为了实现这一点:
- 模型会保留历史帧中的成功锚点;
- 下一帧的查询可以基于历史锚点回归,而非重新初始化;
- 去噪机制提供了更加灵活的监督信号,使得模型在时间维度上也能“稳住”目标。
这样,模型在跨帧保持一致性的能力大大增强。
六、去噪的边界与未来探索
不过,去噪机制的适用边界也逐渐被研究者提出挑战。例如:
- 如果我们使用了不可学习锚点(例如固定网格),是否还需要匈牙利算法?
- 在此基础上,去噪机制是否还会带来增益?
- 如果查询已具备空间信息,训练目标不再跳动,那去噪是否冗余?
Wang 等人在 Anchor-DETR 中对可学习锚点与不可学习锚点进行了比较,发现性能差距有限,但他们仍使用了匈牙利匹配,因此不能直接回答这些问题。
更进一步,如果在推理阶段我们不使用非极大值抑制(NMS),则训练时仍需要匈牙利匹配来保证预测与 GT 一一对应。这种生产需求也影响了设计的选择。
七、去噪不仅是技巧,更是一种范式
从 DETR 到 DINO,视觉 Transformer 的检测思路已发生显著变化:
“从随机学习,到目标指导;从全局匹配,到局部回归。”
而“去噪机制”的提出,则像是一把钥匙,打开了训练稳定性的大门,也重塑了我们对查询机制的理解。
未来,随着视频理解、跨模态识别等任务的发展,去噪机制很可能不只是加速训练的工具,而是时序建模中的关键桥梁。我们期待看到更多关于锚点、匹配与去噪机制交互作用的研究,继续推动视觉 Transformer 的发展边界。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号