OCP EMEA 2025:Oriole介绍光子网络(OCS)赋能AI的挑战、机遇和演进

OCP EMEA 2025:Oriole介绍光子网络(OCS)赋能AI的挑战、机遇和演进

光芯
发布于 2025-05-13 09:59:27
发布于 2025-05-13 09:59:27

Oriole Networks是一家由英国UCL孵化的初创公司,核心方向是研发端到端的光网络方案,解决分布式AI训练的通信延迟,助力数据中心降低80%网络功耗。目前已经获得了3500万美元的种子轮融资,其中A轮融资2200万美金。在OCP EMEA 2025大会上,其创始人George Zervas发表了题目为Photonic Networks for AI:Challenges and Opportunities的报告,介绍了训练和推理网络的不同需求,OCS的应用与挑战,以为未来OCS如何做到取代EPS的一些观点。
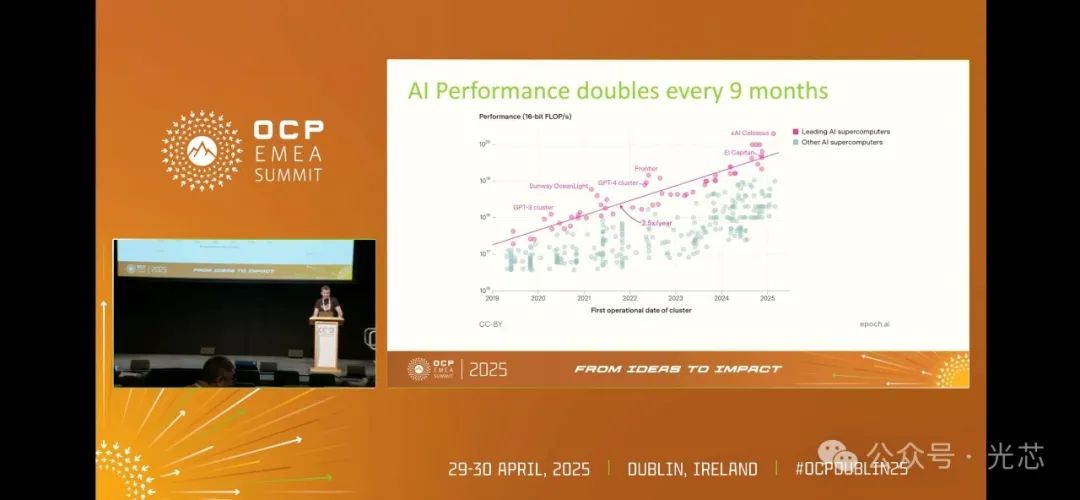
随着AI计算能力以每9个月翻倍的速度迅猛增长,其实际需求的增速远超技术本身,而英伟达等企业的实践已明确揭示:AI系统的规模扩展与商业价值正面临严格的功率限制——如何在单位建筑空间内最大化算力密度,同时实现更低的单位功耗token处理成本(tokens per second per watt),成为当前技术攻关的核心命题。

一、AI基础设施的双轨分化:训练与推理的技术分野

AI系统可划分为两个关键领域:训练(Training)与推理(Inference),二者在硬件架构、网络需求及工作负载特性上呈现显著差异: 1. 训练场景:算力密集型长周期任务 以Nvidia GB300、Amazon Trainium、AMD MI325X为代表的训练芯片,其网络IO能力已达3-7 Tb/s(单向),并正向10 Tb/s以上迈进。训练任务以分布式计算为主,核心指标为每兆瓦训练完成时间,即单位功耗下的模型训练速度与密度。 ◆ 工作负载特性
单次训练可持续数周乃至数月,涵盖全新模型开发(如大语言模型训练)及现有模型调优(如GPT-4针对金融预测、文本生成等垂直领域的适配)。 ◆ 网络架构挑战
依赖Scale Up实现系统级算力整合,但Scale Out时的通信瓶颈显著——后者仅能提供前者部分连接能力,导致跨数万计算单元的训练效率受限于边缘节点通信速率。

2. 推理场景:低延迟高动态性交互 推理系统(如Groq自研架构、Google/Amazon定制方案)的网络IO需求显著低于训练(约1-5 Tb/s),但更强调扁平连接(避免层级架构延迟)与实时响应能力,核心指标为每千瓦每秒token数(直接关联终端服务成本)。 ◆ 工作负载特性
单次任务耗时极短(用户输入到响应完成以毫秒计),数据交互模式高度动态——混合专家模型(MoE)需根据输入token动态调度多GPU并行计算,资源使用比例随语义分析结果实时变化,传统训练场景的确定性通信模式(如固定集体操作)不再适用。 二、网络协议的碎片化现状与标准化探索 当前AI基础设施呈现“协议丛林”格局: ◆ 专用协议主导
Google ICI、Nvidia NV Link等绕过传统Ethernet/InfiniBand,通过GPU直连拓扑(如全连接网格)实现低延迟通信,部分系统(如Google TPU集群)完全摒弃通用网络层,依赖ICI构建全域连接。 ◆ 标准化进程
尽管训练领域尝试推进接口统一(如PCIe 6.0、CXL协议),但推理场景因设备商自研架构(如Groq的专用ASIC集群)仍保持高度定制化,光交换OCS技术虽被广泛视为未来方向,但其配置机制与控制平面尚未形成行业规范。 三、光交换(OCS)的实践困境与突破方向 1. 谷歌的先驱实践:从数据中心核心到推理集群扩展
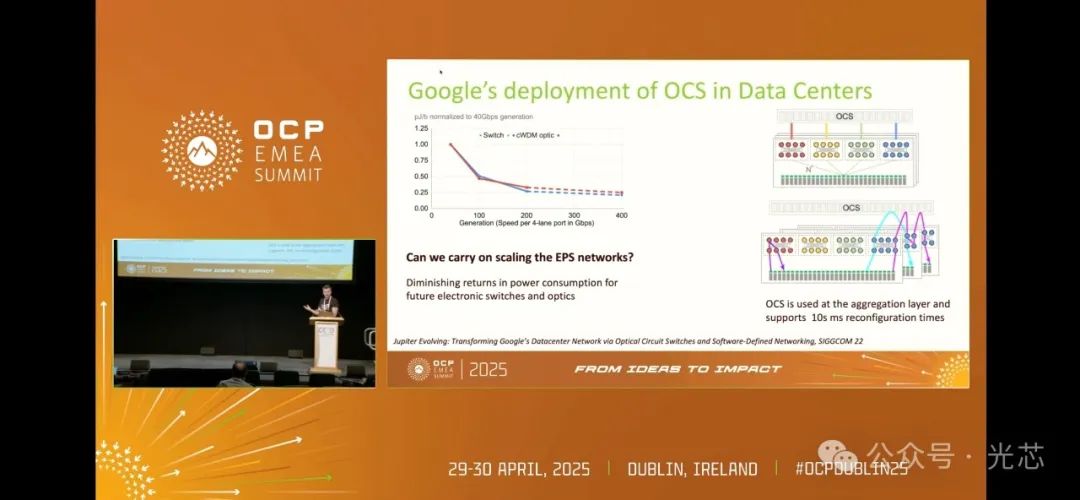
OCS技术在AI网络中有着重要的应用实践。谷歌早在数年前就已公开宣布部署OCS,这项工作至少已持续了五到八年。最初,谷歌利用OCS替换经典数据中心网络的核心部分,旨在解决网络扩展过程中EPS(交换设备相关概念,可能是某种交换功率指标)的缩放问题,以及控制EPS交换机和收发器的功耗。尽管收发器在每比特能耗方面有所优化,但随着规模的扩大,收发器数量的增加导致整体功耗依然上升。OCS在核心网络中主要起到类似可重构配线面板的作用,用于处理故障等问题。

随后,谷歌在ISCA会议上发表的论文显示,他们计划将TPU推理系统的规模从1000 - 2000扩展到4000。在功率和成本的限制下,他们采用了三维(3D)Torus结构,每个机架配备64个TPU,并通过3D MEMS连接各个机架。不过,这种3D MEMS构建的拓扑结构相对固定,难以快速调整以适应推理工作负载的动态变化,虽能降低功耗,但在灵活性方面存在不足。
2. 技术瓶颈:重配置速度与系统同步性挑战 OCS技术的研究已历经数十年。早期的OSA、Firefly和Helios项目为该领域奠定了基础。以谷歌的部署为例,其采用的3D MEMS技术实现了数十毫秒的重新配置。但在实际应用中,当谷歌对网络进行重新配置时,收发器需要花费一到几秒的时间重新训练,这导致网络在数秒内无法正常工作。因此,OCS技术仅适用于连接持续时间较长的场景,以保证足够的吞吐量,这在很大程度上限制了其应用范围。

为突破这一困境,研究人员致力于将OCS的重新配置速度提升至微秒甚至纳秒级别。创始人George Zervas之前与微软剑桥研究院的Sirius项目便是其中的代表,该项目利用可调谐激光器和awgr实现了纳秒级的交换和网络传输。然而,OCS技术仍存在一些问题,如重新配置速度较慢、计算调度不灵活,且标准收发器启动时间过长等。
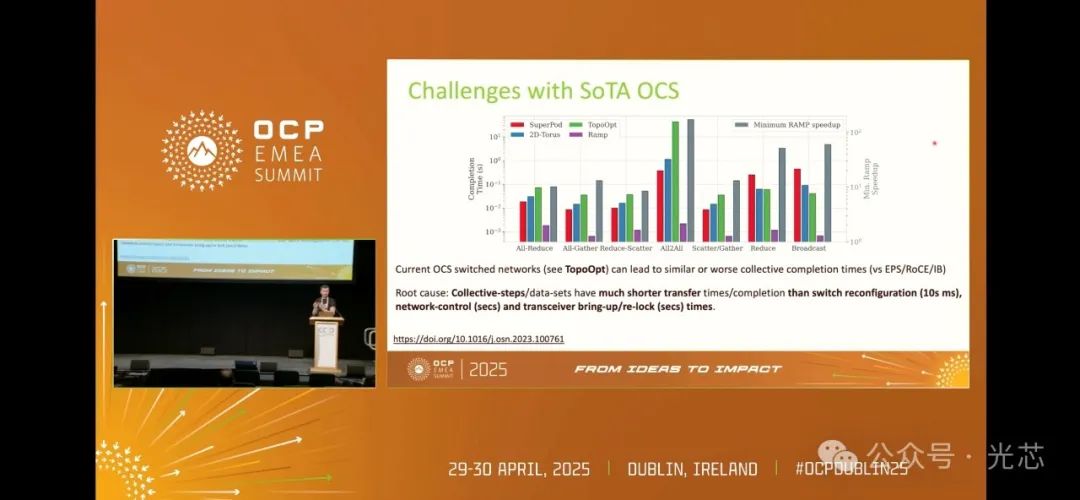
3. 性能对比:OCS vs 电分组交换(EPS)

OCS技术面临的另一大挑战是,在集体数据传输过程中,若数据传输时间远短于交换机的重新配置时间、网络控制重新配置时间以及收发器的启动时间,OCS系统的性能将不如快速电分组交换系统。这就引出了一个关键问题:基于OCS的网络能否展现出与传统电分组交换(EPS)系统相媲美的性能?
构建一个能够替代EPS系统的OCS网络,需要解决诸多技术难题。例如,交换机要实现纳秒级的重新配置,收发器需具备极快的重新锁定能力,网络要能够承受交换过程中产生的额外损耗,并且保证高度同步,使数据在网络重新配置时能精确传输。此外,网络控制系统的配置速度也要相应提升,同时还需与网络管理等全栈技术深度集成,以确保系统具备高度的可靠性和弹性。

若能攻克这些难题,OCS网络将具备显著优势,如在吞吐量、带宽和延迟方面实现高度确定性的性能表现,能够以极低的功耗运行,且可靠性大幅提升,有助于实现大规模、高带宽的网络架构,融合扩展和向外扩展网络的优势。在集体操作算法方面,目前多数系统采用的环形归约、Torus或脊柱 - 叶子等架构,在扩展时存在一定的局限性,而新的研究方向是基于GPU数量,采用亚对数级别的扩展方式,减少集体操作步骤。
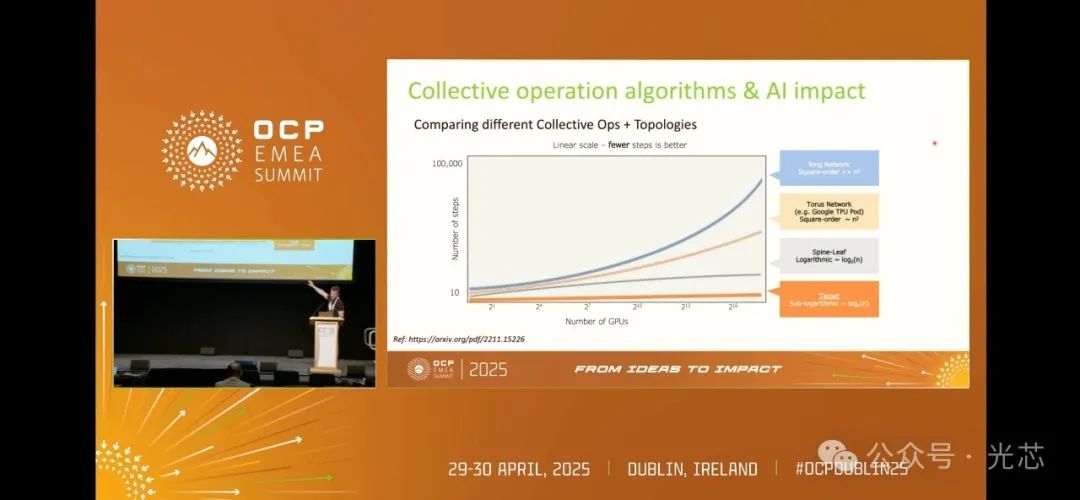
以8000 XPU系统为例,Oriole目标实现的纯OCS架构可完全移除传统多层网络中的核心/聚合交换机及配套收发器,使系统功耗降低77%。即使端点收发器因补偿光路损耗而提升2-3倍功耗,整体能耗仍可压缩至传统方案的80%以下。更关键的是,去除中间电子设备后,系统可靠性(平均无故障时间)与带宽一致性(消除队列拥塞)获得质的提升。

四、Oriole Networks的技术布局与行业协同

作为专注端到端光子解决方案的创新企业,Oriole Networks正致力于消除电子分组交换技术的固有局限,联合行业伙伴推进高容量CMOS光子集成技术,目前暂不透露技术细节,可能会在2025年9月OCP会议上再进行介绍。 结语:从技术验证到规模商用的关键跨越 光子网络能否替代传统电子架构,核心在于能否解决“重配置速度-动态负载-系统可靠性”的三角难题。随着AI从模型训练转向普惠推理,低功耗、高灵活的光子互联技术已从实验室走向商用前夜——尽管标准化与工程化挑战仍存,但其在能效与性能上的颠覆性优势,正驱动AI基础设施迎来新一轮架构革命。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号