Lunima-OmniLV:多模态多Low-Level视觉框架,1K分辨率达佳效并助力系统构建 !

Lunima-OmniLV:多模态多Low-Level视觉框架,1K分辨率达佳效并助力系统构建 !

未来先知
发布于 2025-05-12 20:43:24
发布于 2025-05-12 20:43:24

作者提出了Lunima-OmniLV(简称OmniLV),这是一个通用的多模态多任务框架,用于Low-Level视觉,涵盖四个主要类别中的100多个子任务,包括图像修复、图像增强、弱语义密集预测和风格化。 OmniLV利用文本和视觉 Prompt ,提供灵活、用户友好的交互。 基于基于扩散Transformer(DiT)的生成先验,llm-Lumina-OmniLV_2504支持任意分辨率——在1K分辨率下达到最佳性能——同时保留细粒度细节和高保真度。通过广泛的实验,作者证明分别对文本和视觉指令进行编码,结合使用浅层特征控制进行协同训练,对于减少任务模糊性和增强多任务泛化至关重要。 作者的研究还揭示,将High-Level生成任务集成到Low-Level视觉模型中可能会损害对细节敏感的修复。 这些见解为构建更鲁棒和泛化的Low-Level视觉系统铺平了道路。该项目的页面在此。
1. 引言
大规模基础模型的快速演进革新了人工智能,展示了跨多个领域的卓越泛化能力和多任务处理能力。GPT-4V [3]、InternVL [25-27]、Flamingo [8]、OmniGen [98] 和 OneDiffusion [51] 等统一框架通过在多模态数据集上进行大规模预训练,展现了令人印象深刻的表现。这些模型在语义驱动的视觉High-Level任务中表现出色,例如图像分类、图像理解、视觉生成和编辑。相比之下,Low-Level视觉统一模型的发展仍然高度分散且探索不足。
低层视觉包含广泛的任务,包括图像恢复、图像增强、风格迁移[35, 39]以及弱语义密集预测(例如边缘检测、深度估计、法线图估计)。与依赖预定义语义理解的高层视觉任务不同,大多数低层视觉任务不需要显式的目标级推理。相反,它们专注于像素级保真度、细粒度纹理重建和特征提取。这种区别使得低层视觉任务的统一特别具有挑战性,因为不同的任务通常在不同的输出域中运行。
现有的Low-Level视觉方法在泛化性、可用性和可扩展性方面仍然有限。针对特定任务设计的模型[21, 53]仅能处理单一任务(例如去噪、去模糊、超分辨率),为了适应新任务需要大量重新设计模型并进行重新训练。
一体化修复模型,如AirNet [53]、PromptIR [75]和OneRestore [36],将多个修复任务集成在单一框架内,但仍然局限于领域内修复,无法泛化到跨领域任务,如特征提取或风格迁移。基于视觉 Prompt 的模型,如PromptGIP [63]和GenLV [23],通过图像 Prompt 对扩展到跨领域任务,但需要精心设计的 Prompt ,与文本驱动交互相比,它们不够直观和用户友好。此外,许多现有方法仅在固定分辨率图像上操作,严重限制了它们的灵活性和实际应用性。总而言之,高分辨率图像处理仍然具有挑战性,任务适应性方面仍有大量改进空间。
鉴于低层视觉的固有复杂性和多样性,开发一个真正通用的模型必须处理多个任务域,同时可靠地保留细粒度细节和高保真度。此类模型的一个关键要求是灵活的交互机制。
虽然基于文本的指令提供了一种方便直观的方式来指定任务(例如“从这张图像中去除噪声”、“增强亮度”和“估计Canny边缘”),但某些任务——如风格迁移——仅使用文本难以定义。以示例图像对形式提供的视觉 Prompt 通过允许模型通过视觉类比推理复杂、特定于任务的转换,提供了一种有效的替代方案。因此,理想的通用低层视觉模型应整合文本和视觉 Prompt ,以实现多功能和用户友好的任务执行。
为应对这些挑战,作者提出了OmniLV,一个用于Low-Level视觉的通用多模态多任务框架,能够通过文本和视觉 Prompt 处理超过100个子任务。该模型基于基于扩散Transformer(DiT)的生成先验,显著提升了跨任务的泛化能力和输出质量。图1展示了OmniLV的多功能能力。与受限于固定分辨率的先前模型不同,llm-Lumina-OmniLV_2504支持任意分辨率,在1K分辨率下达到最佳性能。
作者系统地探索了多模态融合策略,并提出了一种简单而有效的方案,以防止任务误解问题。

在OmniLv的开发过程中,作者获得了几个关键见解,这些见解塑造了鲁棒且可泛化的Low-Level视觉模型的设计。首先,作者发现分别对基于文本的指令和视觉指令进行编码对于防止任务模糊至关重要,因为简单的融合可能导致任务误解(第3.1.2节)。此外,使用浅层特征控制对基础模型进行协同训练被证明是增强多任务泛化的有效策略。此外,将High-Level生成或编辑任务纳入Low-Level视觉模型会显著降低保真度,特别是在对细节敏感的恢复任务中。这些发现突出了为Low-Level视觉任务量身定制多模态架构的必要性。
总之,作者的工作做出了以下主要贡献。
(1)作者提出了首个统一的跨模态框架,该框架能够通过文本和图像交互处理四种主要的Low-Level视觉类别(超过100个子任务)。
(2)作者引入了一种有效的跨模态融合机制,该机制对齐文本和图像 Prompt ,缓解了任务错位问题。
(3)作者提供了关于构建多任务Low-Level视觉通才所面临挑战的新实证见解,揭示了High-Level生成和编辑任务的集成如何对保真度关键恢复任务产生不利影响。
2. 相关工作 2.1. 基于生成先验的图像修复
基于扩散的方法已成为图像修复领域的一种稳健框架,通过逆向去噪将退化输入转换为高质量输出。多项关键工作展示了该方法的多样性。StableSR[88]利用预训练文本到图像扩散模型的生成先验进行盲超分辨率,采用时间感知编码器和特征封装来平衡质量与保真度,同时支持任意分辨率。DiffBIR[58]采用两阶段流程,第一阶段减少退化,第二阶段使用潜在扩散模型(IRControlNet)生成缺失细节,在去噪和面部修复方面证明有效。
PAsD[102]通过整合像素感知机制扩展Stable Diffusion框架,实现逼真超分辨率和个性化风格化,提升了分辨率精度和风格适应性。SUPIR[106]扩展了如StableDiffusion-XL等大型扩散模型,结合训练好的 Adapter 和大规模高分辨率数据集,支持复杂场景中的文本引导、照片级真实修复。然而这些方法的局限性在于仅限于图像修复任务,无法解决低层视觉中的其他挑战。
2.2. 集成式生成模型
开发一体化模型是一项既令人兴奋又充满挑战的任务。在图像生成领域,众多研究致力于构建多功能系统。例如,OmniGen[98]将文本和图像编码为统一张量,对文本 Token 使用因果注意力机制,对图像 Token 使用双向注意力机制。
Pixwizard[57]引入了针对图像编辑和理解的特定任务嵌入,而ACE[37, 70]提供了一种条件化模块,可接受多样化输入图像,并与Transformer并行处理。此外,UniReal[24]采用视频生成框架,将图像视为独立帧,为各类图像生成和编辑任务提供通用解决方案。
尽管取得了这些进展,但这些方法大多集中于图像生成和编辑,而Low-Level视觉的通用模型则相对未被充分探索。基于视觉 Prompt 的方法[23, 63]通过利用图像 Prompt 对来处理跨域任务。
然而,它们对精心设计的 Prompt 的依赖性使得它们与文本驱动的替代方案相比,不够直观和用户友好。此外,许多当前的方法仅限于固定分辨率的输出,限制了它们的实际应用。
3. 方法
3.1. OmniLV逐步构建
在本节中,作者详细阐述了在开发通用底层视觉模型过程中的关键设计选择和学习到的见解,概述了作者的逐步思考过程。
3.1.1. 选择基础模型
与大多数从头开始使用确定性回归目标训练的基础图像恢复模型不同,作者利用一个预训练的文生图扩散模型作为强大的初始化。在数十亿图像上训练的预训练扩散模型提供了丰富的视觉先验知识,这增强了泛化能力,支持多种分辨率和长宽比,并能有效捕捉多任务图像恢复中固有的不确定性。这些特性使作者能够构建一个更鲁棒和通用的底层视觉模型。
在作者的基础模型中,作者使用Lumina-Next [34, 117]进行初始化,这是一种基于流的扩散Transformer模型,在传统的DiT模型[74]的基础上引入了多项架构改进,包括二维旋转位置编码、QK归一化和三明治归一化。此外,Lumina-Next采用流匹配公式,提高了训练稳定性并加速了收敛。为了使该模型适用于通用Low-Level视觉任务,作者引入了一个条件 Adapter ,该 Adapter 集成低质量输入以实现有效的任务条件化,具体将在后续章节中说明。
修改后的模型使用流匹配损失进行训练,以学习条件时间依赖速度场,从而促进噪声图像分布和干净图像分布之间的转换。
3.1.2. 编码多模态信息
给定输入图像 ,作者的目标是利用文本指令和上下文视觉示例生成目标图像。作者探索了两种不同的编码策略:
(1) 分离编码,其中文本 Prompt 通过大语言模型(LLM)处理,而视觉示例独立编码。
(2) 统一编码,其中文本和视觉输入在多模态语言模型(MLLM)中融合。图2说明了这两种方法之间的架构差异。虽然统一编码受益于参数效率并利用跨模态相关性,但作者在密集预测任务中观察到它引入了关键限制。
具体来说,多模态编码器经常误解任务指令,导致生成输出不一致。为了更好地理解这个问题,作者在图3中可视化了编码特征分布。作者的研究结果表明,在单个编码器中混合文本和图像 Prompt 会导致严重的任务模糊。由于视觉 Token 主导共享特征空间,基于文本的指令经常被掩盖,导致错位和错误输出,如图10所示。

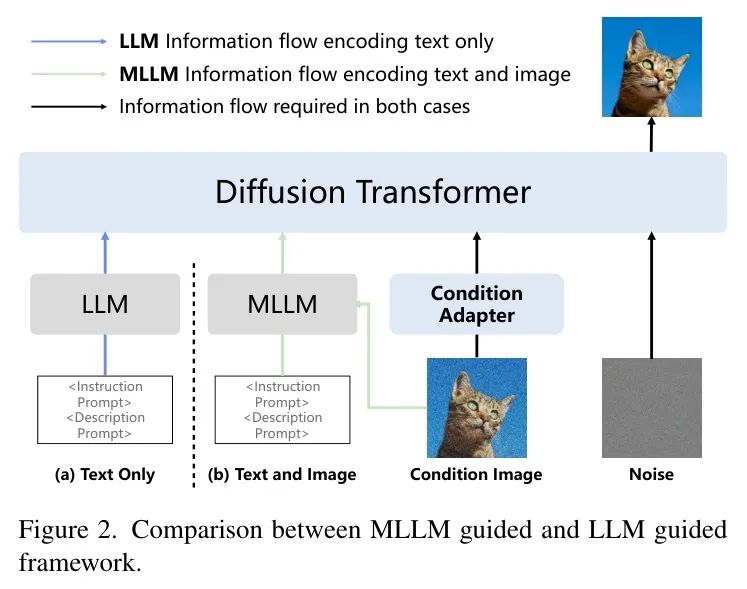
基于这些观察,作者采用了一种独立的编码策略:文本指令通过大语言模型进行处理,而图像示例则使用视觉变分自编码器进行编码。这确保了更清晰的任务分离,防止文本和视觉指导之间的干扰,并提高了在大量Low-Level视觉任务中的任务准确性。
3.1.3. 条件整合的设计选择
将条件图像集成到扩散模型中通常通过两种主要方法实现:
(1)特征注入:一个可训练的 Adapter 将特征图注入冻结的扩散模型[72, 113]。
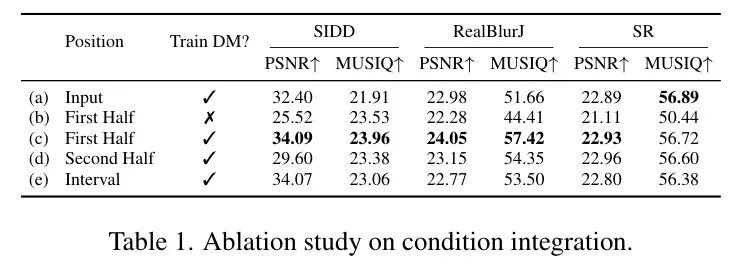
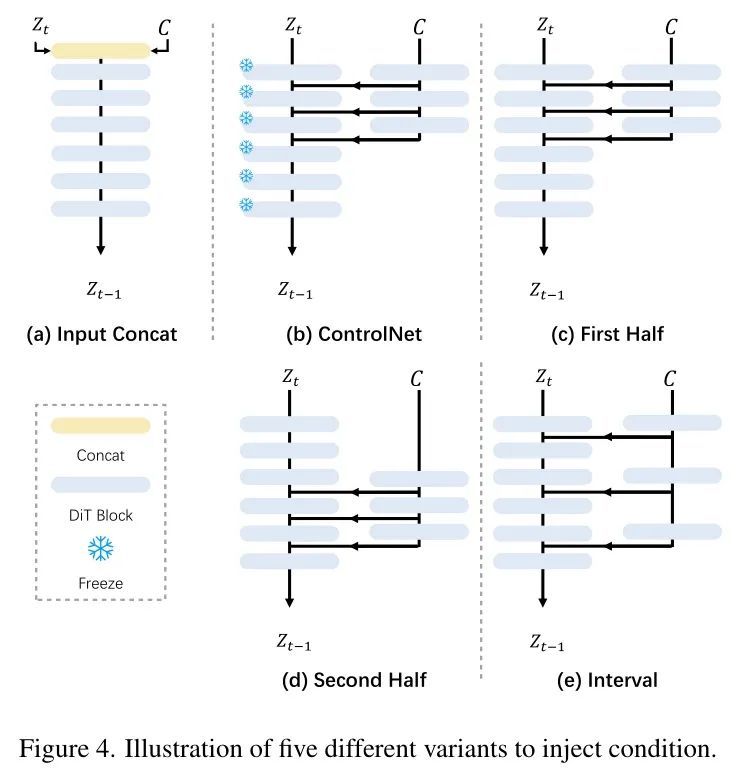
(2)输入拼接:条件图像与输入拼接,并对整个模型进行微调。这些设计已广泛应用于领域内单任务(例如图像修复、canny2image),取得了显著成果[58, 106]。为系统研究通用Low-Level视觉任务的条件集成策略,作者进行了比较实验,评估不同的设计选择(见图4)。
作者的发现总结于表1,如下:
(1)仅训练 Adapter 是不理想的(设置(b)和(c)),表明为了使生成先验适应不同的Low-Level任务,必须微调基础模型。
(2)虽然输入拼接效率较高(设置(a)),但为处理条件图像添加额外参数能提升性能(设置(c)),表明显式建模条件图像有助于提取更多相关的结构和上下文信息。
(3)注入位置显著影响性能(设置(c)、(d)和(e))。在网络前半部分集成条件信息能获得更好的结果,可能因为早期调制确保了整个过程中更强的特征引导。
基于这些发现,作者提出了一种协同训练条件 Adapter ,该 Adapter 联合优化 Adapter 和基础模型。与保持基础模型冻结的ControlNet类架构不同,llm-Lumina-OmniLV_2504确保了更深层次的特征对齐,从而提高了多任务泛化能力和保真度。
3.1.4. 支持情境学习
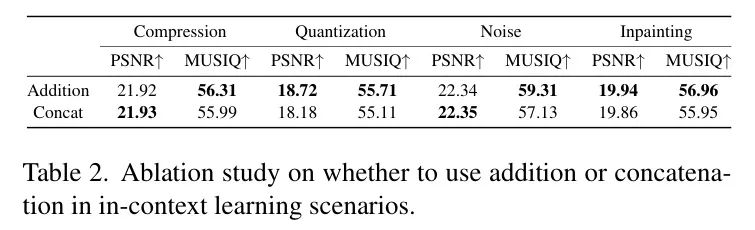
虽然文本 Prompt 能够有效指导任务,但许多Low-Level视觉任务(例如风格化)需要精确的视觉指令,而这些指令难以用语言表达。为此,作者比较了两种视觉 Prompt 集成的范式:(1)输入拼接[24, 96, 98],其中视觉 Prompt 沿token维度进行拼接:
其中 和 分别表示输入图像的潜在表示和第 个视觉 Prompt 的潜在表示,而 表示组合后的潜在表示。(2)投影加法 [95],该方法是使用轻量级 Projector 在求和前将视觉 Prompt 与潜在空间对齐:
其中 表示线性 Projector 。图5展示了这两种方法之间的架构差异,其中连接方法可以看作是一种变体,即将" Projector 相加"模块替换为连接操作。表2展示了定量比较结果,表明投影加法在不同任务上优于输入连接。这表明基于投影的校准更好地保留了任务相关信息。
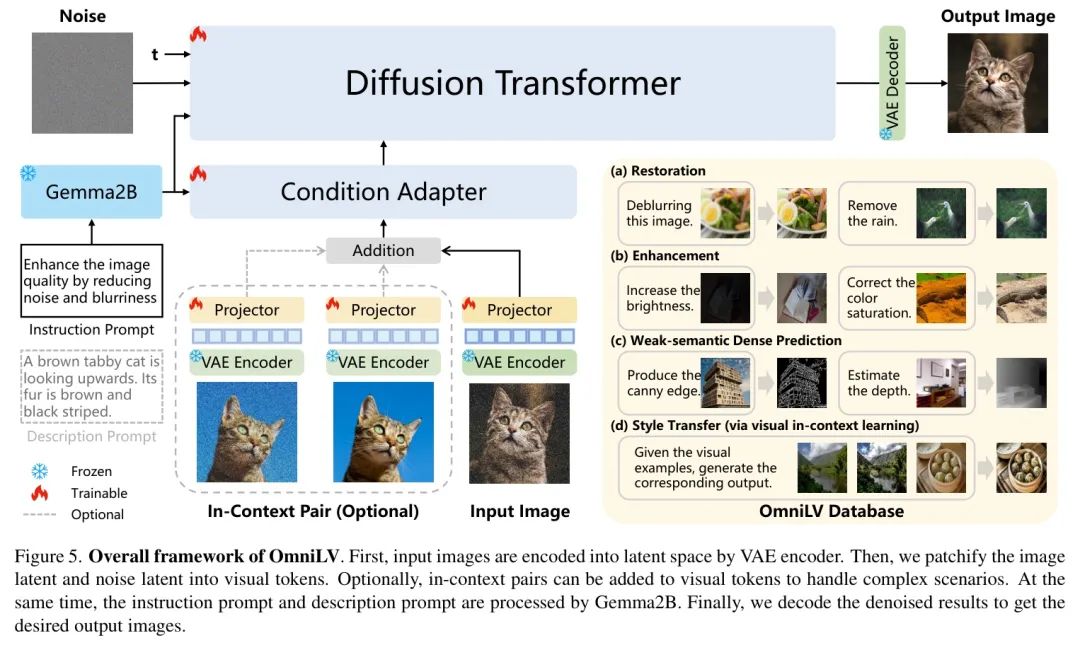
最终架构。基于这些见解,作者设计了OmniLV的最终架构,如图5所示。llm-Lumina-OmniLV_2504统一了多种Low-Level视觉任务,同时确保了强大的多模态条件化和情境学习能力。
3.2. 大规模全视场LV数据集
为构建一个通用的Low-Level视觉模型,作者构建了一个包含4000万个实例、跨越100个子任务、覆盖四个主要领域的超大规模多任务数据集:图像修复、图像增强、密集预测和风格化。OmniLV数据集的主要类别和分布如图6所示。该数据集来源于公开可用的数据集和合成生成的数据对,并通过内部流程创建了额外的优质数据。
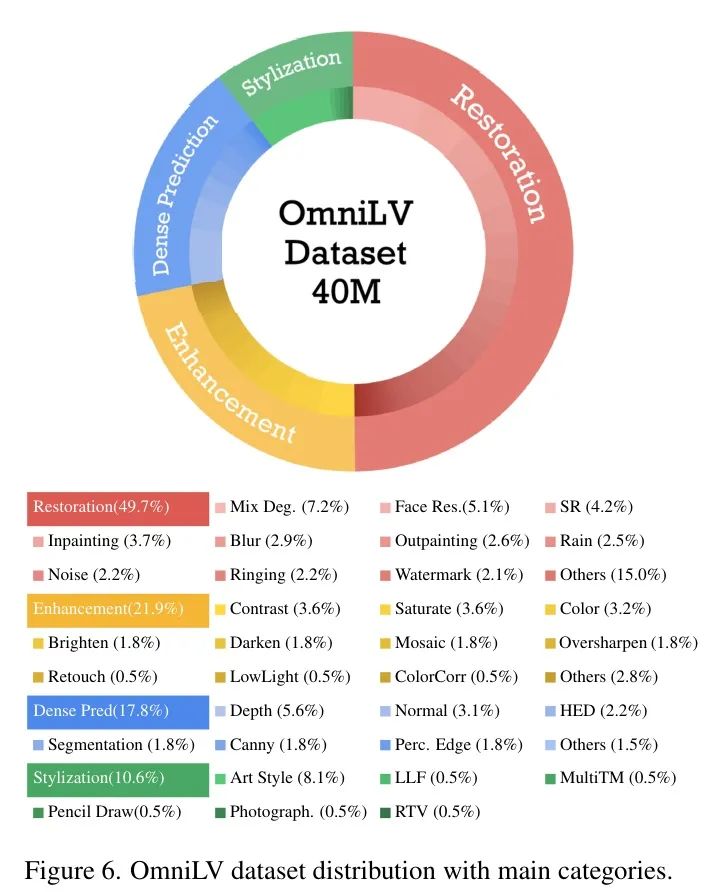
图像修复。修复数据集涵盖了23项主要任务,共计45个子任务,处理包括运动模糊、噪声以及天气引起的失真等多种退化类型。它由真实世界退化图像和合成退化对组成,并与高质量的地面真图像经过仔细处理,以确保真实性和多样性。
图像增强。增强数据集包含14项主要任务,共计25项子任务,涵盖低光照校正、对比度增强和饱和度细化等任务。该数据集由专业编辑的参考图像以及算法生成的增强对组成,确保可控的转换与感知质量一致。
弱语义密集预测。对于密集预测任务,作者编译了10项任务的标注数据集,包括边缘检测、深度估计和表面法线预测。每个样本包含像素级真实标注与描述性任务特定指令,以促进多模态学习。
图像风格化。风格化数据集涵盖20项任务,包括跨不同风格和技术的艺术转换。它包含真实世界的艺术作品以及由神经算法生成的风格迁移图像,确保多样化的风格效果。由于定义任务 Prompt 的难度,作者在图像风格化任务中实现了情境学习。
数据集概览与测试集构建。OmniLV数据集总共包含四个主要任务类别,超过100个子任务,以及大约4000万个训练实例。对于公开可用的数据集,作者直接采用其对应的测试集进行评估。对于作者合成的任务,作者基于DIV2K-val构建测试集,形成OmniLV-Test(OLV-T)。OLV-T测试集包含44个任务特定的测试集,每个测试集包含100张图像,总共产生4400张1k分辨率的测试图像。关于数据集划分和评估的更多细节,请参见补充材料。
3.3. 模型训练和采样设置
OmniLV的训练分为三个阶段:第一阶段,作者使用分辨率为的图像训练模型,仅专注于单图像任务。作者使用恒定学习率1e-4,以512的批处理大小训练100k步。第二阶段加入情境学习(ICL)任务。作者继续训练100k步,保持1e-4的学习率和512的批处理大小。最后,在第三阶段,作者将分辨率提高到,并在所有任务上进行训练。批处理大小减少到128,学习率保持在1e-4。这个最终阶段确保模型能够有效处理各种任务和图像尺寸。模型使用16个A100 GPU进行训练。
4. 实验
4.1. 与现有工作的比较
作为通用模型,OmniLV在各种Low-Level视觉任务中表现出卓越的能力,即使与现有的任务特定模型相比也是如此。作者将llm-Lumina-OmniLV_2504与任务特定方法[15, 22, 58, 87, 92, 101, 109, 110, 115]、一体化方法[22, 45, 69]、视觉 Prompt 方法[23, 63, 93]以及文本引导扩散方法[57, 107]进行比较。其中一些方法被限制在生成固定大小的图像。在作者的比较中,作者将生成的图像调整为目标图像大小以促进公平的比较。作者在合成数据和真实世界数据上进行了比较。作者选择了全参考指标PSNR和非参考指标MUSIQ[47]进行定量比较。
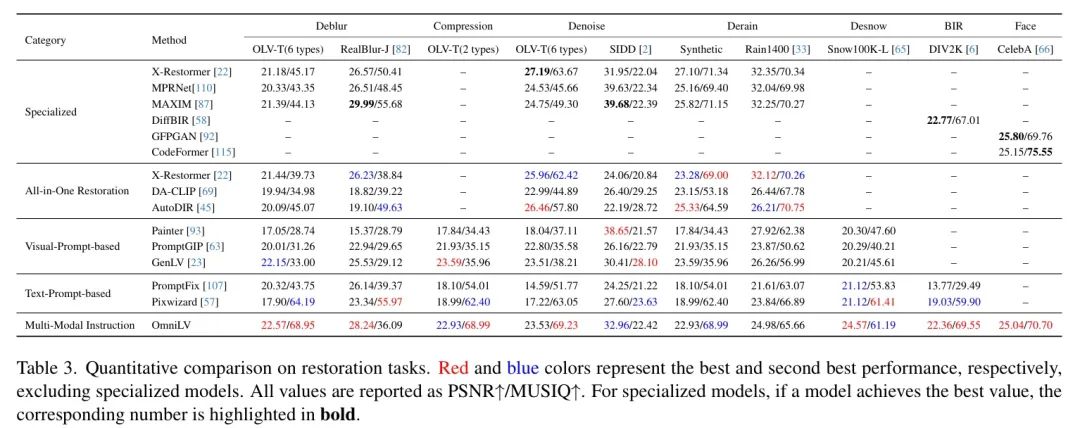
图像修复。表3表明,与基于扩散的模型相比,OmniLV在所有修复基准测试中均实现了最高的PSNR分数。作者在图7中展示了针对一般Low-Level任务的定性比较。此外,OmniLV的MUsIQ分数在大多数基准测试中具有很强的竞争力,进一步突显了其优异的性能。值得注意的是,在盲图像修复(BIR)和面部基准测试中,作为通用模型的OmniLV达到了与最先进的专业模型相当的性能水平,从而验证了其在处理多样化修复任务方面的有效性。
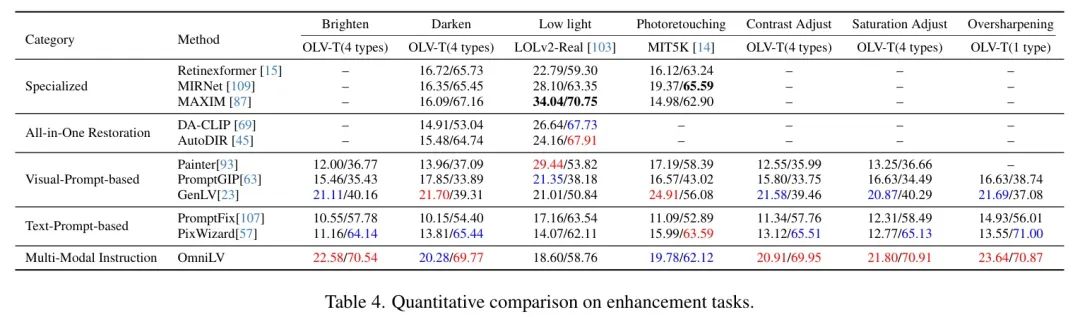
图像增强。如表4所示,OmniLV在现有增强方法上显著提升。这些改进突显了OmniLV在有效提升图像质量的同时保持自然的能力。
细节和色彩保真度
密集预测。表5b展示了各种方法在密集预测任务上的性能,包括深度估计、法线估计和边缘检测。尽管OmniLV的性能仍然落后于专用模型,但它相比 Baseline 方法表现出显著改进,突显了其作为通用框架在密集预测视觉任务中的潜力。
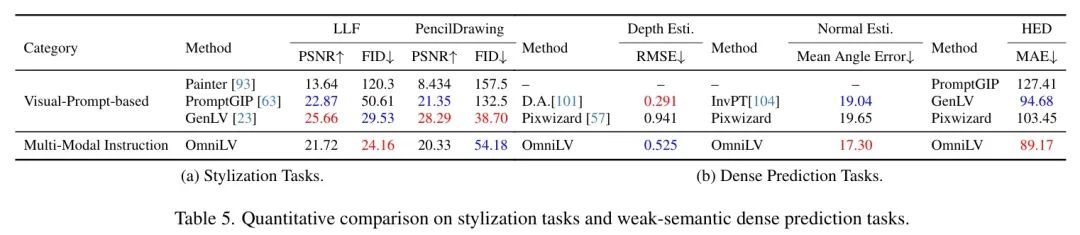
风格化。表5a表明OmniLV在风格化任务上表现良好,例如局部拉普拉斯滤波器(LLF)和铅笔绘画[67]。由于风格化任务难以用自然语言描述,作者采用视觉 Prompt 来指导模型处理图像。OmniLV在客观质量和感知质量方面取得了平衡的结果,从而验证了其在多样化Low-Level视觉任务中的多功能性。
4.2. 更多探索
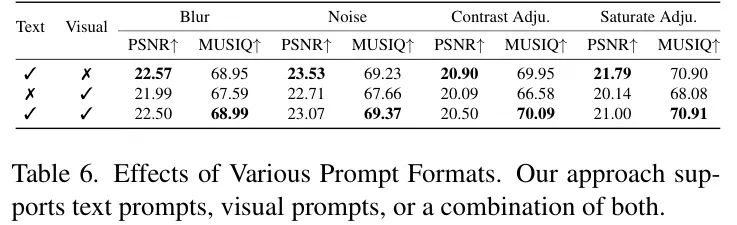
文本 Prompt 与视觉 Prompt 。llm-Lumina-OmniLV_2504支持文本 Prompt 和视觉 Prompt 来指导生成过程。在表6中,作者展示了这两种 Prompt 方法在多个Low-Level视觉任务(包括去模糊、去噪、对比度调整和饱和度调整)之间的详细比较。采用这两种 Prompt 可以获得更好的质量分数。
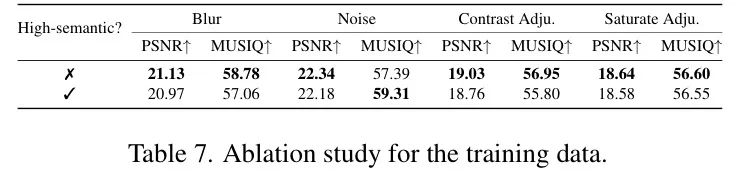
与高语义任务的关系。作者进一步研究了Low-Level视觉任务与高语义任务(如图像生成或图像编辑任务)之间的关系[12, 40, 84, 85, 105, 112, 114]。如表7所示,当高语义任务包含在训练数据中时,Low-Level视觉任务的性能会下降。具体来说,当引入高语义任务时,各种任务的性能始终较低。这种退化是因为高语义任务优先考虑概念一致性和结构抽象,而不是像素级精确重建,这与要求细粒度纹理恢复和精确细节保留的Low-Level视觉任务目标相冲突。
泛化探索。作者研究了OmniLV在特定领域适应性和现实世界鲁棒性方面的泛化能力。具体而言,作者选择了具有各种现实世界退化的图像,以全面评估模型的性能。如图8所示,OmniLV有效地恢复了在这些多样化条件下的图像,展示了其在处理复杂现实世界退化方面的鲁棒性和多功能性,例如现实世界恢复、去雨、去雪、水下图像增强和卫星图像增强。

(a) 样式化任务。 (b) 密集预测任务。
5. 结论
在这项工作中,作者介绍了OmniLV,一个用于Low-Level视觉的统一多模态框架,该框架成功处理了超过100个子任务,包括图像恢复、增强、弱语义密集预测和风格化。
通过利用文本和视觉 Prompt 以及生成先验,OmniLV展示了强大的泛化能力、高保真度结果以及在任意分辨率下的灵活性。OmniLV在多个Low-Level视觉任务中实现了最先进的性能,并在现实场景中展示了有前景的泛化能力。
局限性。尽管OmniLV在处理多种Low-Level视觉任务方面具有广泛的能力,但在某些特定场景中并不总是能达到最佳性能。未来的工作将集中于通过更精细的模型组件和训练策略来提升任务特定性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号