第八章 AI模型质量-3

第八章 AI模型质量-3

bettermanlu
发布于 2025-04-15 11:12:17
发布于 2025-04-15 11:12:17
8.4 AI模型的灰盒精准测试
本节我们将首先介绍下AI模型的可解释性,我们以计算机视觉领域为例,介绍一种可解释性的方案,即Grad-CAM热力图,最后我们将介绍如何利用AI模型的可解释性进行模型的灰盒精准测试。
8.4.2 AI模型的可解释性
AI模型的可解释性是指我们能够理解和解释模型的决策过程和输出结果。这对于许多应用场景来说非常重要,尤其是在涉及关键决策和高风险领域,如医疗、金融和法律等。可解释性的重要性主要体现在以下几个方面:
- 建立信任:当用户能够理解AI模型的决策过程时,他们更容易信任这些模型。这对于AI技术的广泛应用和接受至关重要。
- 遵守法规:在某些行业,如金融和医疗,法规要求企业能够解释其算法的决策过程。这有助于确保算法的公平性、透明性和可靠性。
- 提高模型性能:通过分析模型的决策过程,我们可以发现模型的不足之处,从而优化模型以提高性能。
- 降低风险:可解释性有助于识别模型的潜在偏见和不公平现象,从而降低错误决策带来的风险。
- 促进人工智能和人类的协作:当人类能够理解AI模型的决策过程时,他们更容易与AI系统协作,从而提高工作效率。
比如:在我们参与的活体检测的项目中,如图10所示,图10中的(1)号样本被正确识别,但(2)和(3)均被误识别,(2)被识别为翻拍电脑屏幕,(3)被识别为脸部被遮挡。AI模型对我们来说就像个黑盒子,缺少可解释性,我们不知道对一张图模型关注什么信息,也不知道图10 中的(1)为什么成功、图10中的(2)和(3)为什么失败。对于(3)我们猜测可能是因为样本中抬起的人手导致算法误判,而真实的原因是因为眼镜框带来的干扰。

图10 活体检测样本检测结果
所以对测试来说,AI模型的可解释性是一个非常重要的诉求,然而,AI模型的可解释性也面临着一些挑战:
- 模型复杂性:许多先进的AI模型,如深度学习模型,具有高度复杂的结构,这使得理解其决策过程变得非常困难。
- 折衷权衡:在某些情况下,提高模型的可解释性可能会降低其性能。例如,简化模型结构可能会导致性能下降。
- 缺乏通用方法:目前尚无通用的方法来解释所有类型的AI模型。因此,针对不同类型的模型,可能需要采用不同的解释方法。
下面我们将以计算机视觉领域为例,介绍一种模型可解释性的方案,即Grad-CAM。
8.4.3 Grad-CAM热力图
Grad-CAM(Gradient-weighted Class Activation Mapping)[5]是一种可视化技术,用于解释卷积神经网络(CNN)的预测。它可以帮助我们理解模型在进行分类时关注的图像区域,从而提供模型决策的可解释性。Grad-CAM通过计算类别相对于特征图的梯度来生成热力图,突出显示对预测结果影响最大的区域。
Grad-CAM的主要步骤如下,参见图11:
- 选择一个卷积层:首先,我们需要选择一个卷积层作为Grad-CAM的目标层。通常,我们会选择网络中较深的层,因为它们捕捉到的特征更高级,更具判别性。
- 前向传播:将输入图像传递到CNN中,并计算所选卷积层的特征图。
- 计算梯度:计算目标类别相对于所选卷积层特征图的梯度。这些梯度值可以帮助我们了解每个特征图对目标类别的重要性。
- 计算权重:对每个特征图的梯度值求平均,得到权重。这些权重可以表示每个特征图对目标类别的贡献程度。
- 生成Grad-CAM热力图:将权重与特征图相乘,然后对结果求和。这将生成一个突出显示关键区域的粗糙热力图。为了使其与原始图像大小相同,可以对热力图进行上采样。
- 可视化:将热力图叠加到原始图像上,以便更直观地查看模型关注的区域。
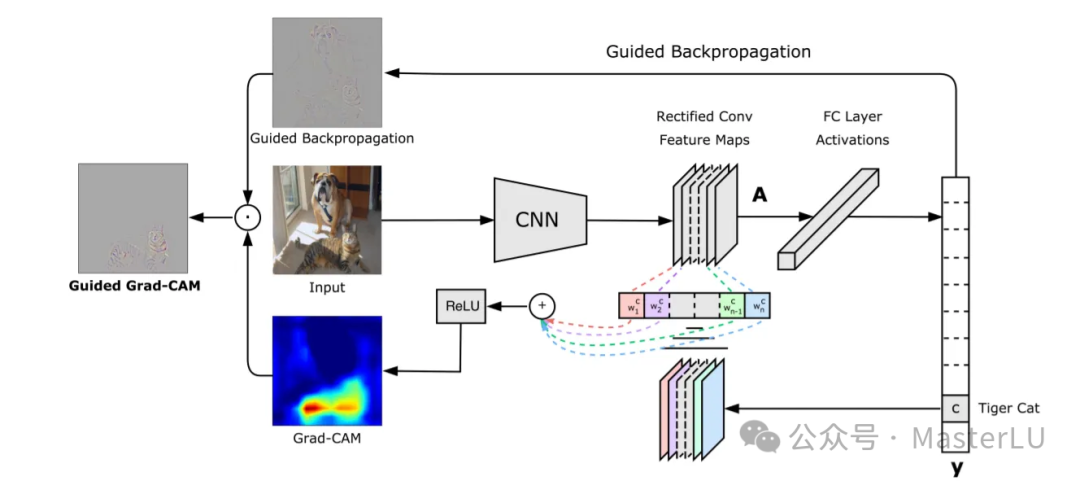
图11 Grad-CAM原理图
Grad-CAM代码实现参见代码段2。这个代码示例首先定义了一个GradCAM类,它接受一个模型和目标层作为输入。然后,它使用前向和后向钩子(hook)来捕获目标层的特征图和梯度。__call__方法计算Grad-CAM,并将其返回为一个热力图。
preprocess_image函数用于读取图像并将其转换为模型输入所需的格式。visualize_cam_on_image函数将Grad-CAM热力图叠加到原始图像上以进行可视化。
在__main__部分,我们使用预训练的ResNet-50模型作为示例,并选择最后一个残差块的第三个卷积层作为目标层。然后,我们使用Grad-CAM类计算热力图,并将其叠加到原始图像上。最后,我们将结果保存为grad_cam_result.jpg。
实际效果如下图12所示。
代码段2:Grad-CAM实现实例
import torchimport torch.nn.functional as Fimport torchvision.models as modelsimport torchvision.transforms as transformsimport cv2import numpy as npclass GradCAM: def __init__(self, model, target_layer): self.model = model self.target_layer = target_layer self.model.eval() self.feature_maps = None self.grads = None self.hook_layers() def hook_layers(self): def forward_hook(module, input, output): self.feature_maps = output.detach() def backward_hook(module, grad_in, grad_out): self.grads = grad_out[0].detach() self.target_layer.register_forward_hook(forward_hook) self.target_layer.register_backward_hook(backward_hook) def __call__(self, input_tensor, target_class=None): output = self.model(input_tensor) if target_class is None: target_class = torch.argmax(output) self.model.zero_grad() output[:, target_class].backward() weights = torch.mean(self.grads, dim=[2, 3], keepdim=True) cam = F.relu(torch.sum(weights * self.feature_maps, dim=1)).squeeze().cpu().numpy() return camdef preprocess_image(image_path): mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean, std) ]) img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = transform(img).unsqueeze(0) return imgdef visualize_cam_on_image(image_path, cam): img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) cam = cv2.resize(cam, (img.shape[1], img.shape[0])) cam = (cam - np.min(cam)) / (np.max(cam) - np.min(cam)) cam = np.uint8(255 * cam) heatmap = cv2.applyColorMap(cam, cv2.COLORMAP_JET) result = cv2.addWeighted(img, 0.5, heatmap, 0.5, 0) return resultif __name__ == "__main__": model = models.resnet50(pretrained=True) target_layer = model.layer4[-1].conv3 grad_cam = GradCAM(model, target_layer) image_path = "path/to/your/image.jpg" input_tensor = preprocess_image(image_path) cam = grad_cam(input_tensor) result = visualize_cam_on_image(image_path, cam) cv2.imwrite("grad_cam_result.jpg", cv2.cvtColor(result, cv2.COLOR_RGB2BGR))
图12 Grad-CAM效果示意图
基于Grad-cam,我们重新绘制了图10的活体检测样本的热力图,参见图13。对于(1)正样本,我看可以看到AI算法重点关注的是人的鼻子附近区域。对于(2)误判为翻拍电脑屏幕,我们可以看到AI算法关注到了人背后的玻璃窗户,导致了误判。对于(3)我们看到AI算法关注到了人脸上的眼镜框,导致了误判。

图13 活体检测样本的Grad-cam热力图
通过这个案例,我们可以看到热力图在帮助我们理解AI算法方面起到了很大的帮助。除此外,AI算法的可解释性还能有哪些用途呢?下面我们介绍一种基于可解释性的精准测试思路。
8.4.4 AI模型的精准测试
本节我们继续以活体检测项目为例,继续讨论如何利用AI模型的热力图进行精准测试。
通过AI模型的热力图,我们能够了解到AI模型关注点在图像的哪些区域,比如:活体检测算法主要聚焦在人脸上,那么其他区域的扰动应该不会影响AI模型的结果输出。
所以,我们可以通过如下三个思路来验证算法的健壮性和容错性。
(1)对图像的非关键区域的扰动,不应该影响算法的结果。
(2)对图像的关键区域的轻度扰动,算法应该能够容错。
(3)对图像的关键区域进行过度的扰动,算法应该会失败。
更精准的蜕变测试
传统的异常样本构造,一般是采用前文提到的数据增强的手段,通常是针对整张图片进行的。将热力图与异常构造结合起来,可以对一些特定区域进行数据增强,进行更精准的蜕变测试。
我们看下热力图的精准蜕变测试的整体流程,可以分为(1)热力图的生成;(2)根据阈值过滤,生成标记矩阵,将关键区域分组;(3)根据不同标记对图片不同部分进行增强。
该方案可以应用于任何CNN深度学习模型,进行异常样本的精准构造。例如图像分类(动物分类)、目标检测(证件检测等)。
(1) 热力图生成及根据阈值切割热力图.
我们首先使用上文提到的Grad-CAM算法生成样本对应的热力图。接着,我们采用设置不同阈值的方法对热力图进行分组,根据阈值过滤我们生成一个与原始图片大小相同的标记矩阵,阈值可以根据业务场景设置合理的值。比如,我们首先找出最大像素点的值,然后设定一组和最大像素值百分比的阈值,如:【0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1】,将热力图分成10组。
例如,图16左图为某一证件的热力图,根据上面的一组阈值过滤,生成标记矩阵并对标记矩阵进行染色,结果如图16的右图所示。
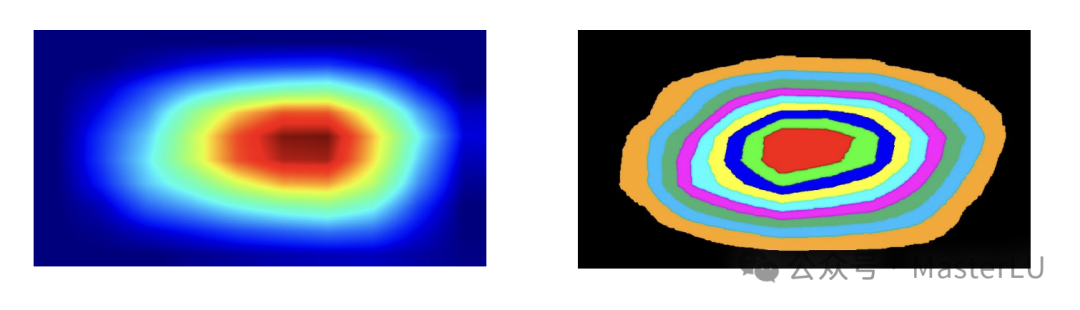
图16 热力图及其分组后的效果图
代码段3是对热力图进行分组的实例代码。cal_label函数接受两个参数 img_path 和 heatmap_path,分别表示原始图像和热力图的路径。函数的主要功能是根据热力图生成标签图像,并将其保存到指定的输出路径。
具体实现过程如下:
- 使用 OpenCV 的
cv2.imread函数读取原始图像,获取其行数、列数和通道数。 - 使用
imageio.imread函数读取热力图,并使用 OpenCV 的cv2.resize函数将其缩放到与原始图像相同的大小。 - 使用 OpenCV 的
cv2.minMaxLoc函数获取热力图中的最小值、最大值及其对应的位置。 - 创建一个与原始图像大小相同的三通道数组
labels,并根据热力图的像素值将其赋予不同的颜色,生成标签图像。 - 使用
imageio.imwrite函数将标签图像保存到指定的输出路径,并返回标签图像。
代码段3:热力图分组代码示例
import cv2import numpy as npimport osfrom skimage import color,ioimport imageio
def cal_label(img_path,heatmap_path): img_raw = cv2.imread(img_path) raws_row, raws_col, raws_channels = img_raw.shape
# 热力图 img = imageio.imread(heatmap_path) img = cv2.resize(img, (raws_col, raws_row)) name = os.path.basename(img_path) min_val, max_val, min_index, max_index = cv2.minMaxLoc(img) labels = np.zeros((raws_row,raws_col,3)) for i in range(raws_row): for j in range(raws_col): if img[i,j] > max_val*0.9: labels[i,j] = [255,0,0] #蓝 elif img[i,j] > max_val*0.8: labels[i,j] = [0,255,0] #绿 elif img[i,j] > max_val*0.7: labels[i,j] = [0,0,255] #红 elif img[i,j] > max_val*0.6: labels[i,j] = [255,255,0] #青 elif img[i,j] > max_val*0.5: labels[i,j] = [0,255,255] #黄 elif img[i,j]> max_val*0.4: labels[i,j] = [255,0,255] elif img[i,j] > max_val*0.3: labels[i,j] = [60,179,113] elif img[i,j] >max_val*0.2: labels[i,j] = [0,191,255] elif img[i,j] > max_val*0.1: labels[i,j] = [255,165,0] #粉 else: labels[i,j] = [0,0,0] imageio.imwrite('./output/label/'+ name, labels) return lables(2)对图片进行局部增强
生成标记矩阵之后,不同的标记则代表不同的部位,标记矩阵的位置与图片的位置一一对应。根据不同的标记对样本不同区域进行异常处理,包括高亮、高斯模糊、高斯噪点、椒盐噪点等。
以光照效果的局部增强为例,代码如代码段4所下,具体来说,它会在图像的中心位置添加一个光源,然后根据像素点到光源的距离来调整每个像素点的亮度。图17是其对应的效果图。
以下是代码的详细解释:
def add_light(img_path,label,label_index = 0):这是定义的函数,接受三个参数,分别是图像的路径,标签和标签索引。output_name = os.path.basename(img_path)获取图像文件的基本名称。img = cv2.imread(img_path)使用OpenCV库读取图像。rows, cols = img.shape[:2]获取图像的行数和列数。centerX = rows / 2和centerY = cols / 2计算图像的中心点。radius = min(centerX, centerY)计算光源的半径,取中心点的最小值。strength = 300设置光照强度。dst = np.zeros((rows, cols, 3), dtype="uint8")创建一个新的空白图像,用于存放处理后的图像。- 接下来的循环部分是对图像的每个像素进行处理。如果像素点的标签等于给定的标签索引,并且像素点到光源的距离小于光源的半径,那么就增加该像素点的亮度。亮度的增加量与像素点到光源的距离成反比。处理后的像素值存放在新的图像中。
output_dir = './output/lights'设置输出目录。cv2.imwrite(output_dir+'/'+output_name+'_%d.jpg' %label_index, dst)将处理后的图像保存到指定的目录。if __name__ == '__main__':这部分是代码的主入口。首先,它会计算图像的标签,然后对每个标签索引调用add_light函数,对图像进行光照效果的增强。
代码段4:光照效果的局部增强示例代码
def add_light(img_path,label,label_index = 0): output_name = os.path.basename(img_path) img = cv2.imread(img_path) rows, cols = img.shape[:2] # 设置中心点 centerX = rows / 2 centerY = cols / 2 radius = min(centerX, centerY) # 设置光照强度 strength = 300 # 新建目标图像 dst = np.zeros((rows, cols, 3), dtype="uint8") # 图像光照特效 for i in range(rows): for j in range(cols): B = img[i, j][0] G = img[i, j][1] R = img[i, j][2] if label[i,j] == label_index: # 计算当前点到光照中心距离(平面坐标系中两点之间的距离) distance = math.pow((centerY - j), 2) + math.pow((centerX - i), 2) if (distance < radius * radius): # 按照距离大小计算增强的光照值 result = (int)(strength * (1.0 - math.sqrt(distance) / radius)) B = img[i, j][0] + result G = img[i, j][1] + result R = img[i, j][2] + result # 判断边界 防止越界 B = min(255, max(0, B)) G = min(255, max(0, G)) R = min(255, max(0, R)) dst[i, j] = np.uint8((B, G, R)) else: dst[i, j] = np.uint8((B, G, R)) else: dst[i, j] = np.uint8((B, G, R)) # 显示图像 output_dir = './output/lights' if not os.path.exists(output_dir): os.makedirs(output_dir) cv2.imwrite(output_dir+'/'+output_name+'_%d.jpg' %label_index, dst) if __name__ == '__main__': image_path = "shenzhineng.jpeg" heatmap_path = "shenzhineng_heatmap.jpg" labels = cal_label(image_path, heatmap_path) if not os.path.exists('./output'): os.makedirs('./output') for i in range(10): add_light(image_path, labels,i)
图17 对照片特定区域添加光照效果图
代码段5是增加模糊指定区域示例代码,图18是其对应的效果图。
以下是对代码的详细解读。
GussianFunction2D(x, y): 这个函数计算了一个二维高斯函数的值,其中x和y是输入的坐标,sigma是标准差。函数返回了高斯函数的计算结果。cal_weight_matrix(kernel): 这个函数用于计算高斯权重矩阵。它创建了一个大小为(kernel+1, kernel+1)的零矩阵,并通过调用GussianFunction2D函数来计算每个位置的权重值。最后,将权重矩阵归一化后返回。gaussian_value(img, i, j, weight_matrix, kernel): 这个函数根据给定的权重矩阵,计算图像img中位置(i, j)的像素值。它首先从图像中提取一个大小为(kernel+1, kernel+1)的子图像,然后根据权重矩阵计算每个通道的像素值,并返回结果。add_blur(img_path, heatmap_path, labels, label_index): 这个函数用于给图像添加模糊效果。它首先读取原始图像和热力图,然后调用cal_weight_matrix函数计算权重矩阵。接下来,它遍历图像的每个像素,并根据标签矩阵中的值判断是否需要对该像素进行模糊处理。如果需要模糊处理,则调用gaussian_value函数计算新的像素值,并将其替换原始图像中的像素值。最后,将处理后的图像保存到输出目录中。if __name__ == '__main__'::入口函数,在这个代码块中,它读取图像和热力图,并调用add_blur函数来添加模糊效果,循环执行10次,每次使用不同的label_index参数。
代码段5:模糊效果的局部增强示例代码
def GussianFunction2D(x, y): sigma = 25 #sigma为标准差,sigma越大, 高斯函数图像越扁, 则模糊效果越明显; #sigma越小, 趋向0的话, 则模糊效果越差越接近真实图像 return (1/(2*math.pi*sigma**2)) * math.e**(-(x**2 + y**2)/(2*sigma**2)) def cal_weight_matrix(kernel=10): #计算高斯权重矩阵 weight_matrix = np.zeros((kernel+1,kernel+1)) pos = kernel/2 # weight_matrix = np.zeros((raws,cols)) for i in range(11): for j in range(11): weight_matrix[i,j] = GussianFunction2D(i-pos,j-pos) print (weight_matrix) weight_matrix /=weight_matrix.sum() return weight_matrix def gaussian_value(img,i,j,weight_matrix,kernel=10): gau_value = [] pos = int(kernel/2) print (pos) temp = img[i-pos:i+pos+1,j-pos:j+pos+1,:] #根据权重矩阵计算像素值 for k in range(3): value = np.multiply(weight_matrix,temp[:,:,k]) res = value.sum() gau_value.append(res) return gau_value
def add_blur(img_path,heatmap_path,labels,label_index): img_raw = cv2.imread(img_path) raws_row, raws_col, raws_channels = img_raw.shape # 热力图 img = cv2.imread(heatmap_path) img = cv2.resize(img, (raws_col, raws_row)) output_name = os.path.basename(img_path) kernel = 10 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) min_val, max_val, min_index, max_index = cv2.minMaxLoc(img_gray) print(max_val, min_val) raws, cols, channels = img.shape weight_matrix = cal_weight_matrix() pos = int(kernel / 2) cal_num = 0 for i in range(pos, raws - pos): for j in range(pos, cols - pos): if labels[i, j] == label_index: res = gaussian_value(img_raw, i, j, weight_matrix) img_raw[i, j] = np.array(res) cal_num+=1 output_dir = './output/blur/' if not os.path.exists(output_dir): os.makedirs(output_dir) cv2.imwrite(output_dir+output_name+'_%d.jpg' %label_index, img_raw)
if __name__ == '__main__': image_path = "gangao.jpeg" heatmap_path = "gangao_heatmap.jpg" labels = cal_label(image_path, heatmap_path) if not os.path.exists('./output'): os.makedirs('./output') for i in range(10): add_blur(image_path, heatmap_path, labels,i)
图18 对照片特定区域模糊化效果图
基于标注系统的精准测试
最后补充一种精准测试的思路:基于标注系统的精准测试。我们以证件OCR算法为例,对于证件OCR的标注系统,我们会对关键区域进行框选和标注,标注文件中会记录这些区域的坐标位置,有着这些坐标位置后,我们就可以对这些关键区域进行精准的蜕变。如图19中,我们可以依次对证件上每个文字区域,进行模糊、色彩变换、添加噪点等蜕变测试,验证算法的健壮性。


图19 基于标注系统的精准测试
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号