【机器学习与实现】K近邻算法


一、KNN算法简介
想一想:下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类?

1968年,Cover和Hart提出了最初的近邻算法。
(一)KNN算法包括三个步骤
- 算距离:给定测试样本,计算它与训练集中的每个样本的距离;
- 找邻居:圈定距离最近的k个训练样本,作为测试样本的近邻;
- 做分类:根据这k个近邻归属的主要类别,来对测试样本分类。
k值的选择、距离度量和分类决策规则是KNN的3个基本要素。
(二)超参数K的影响
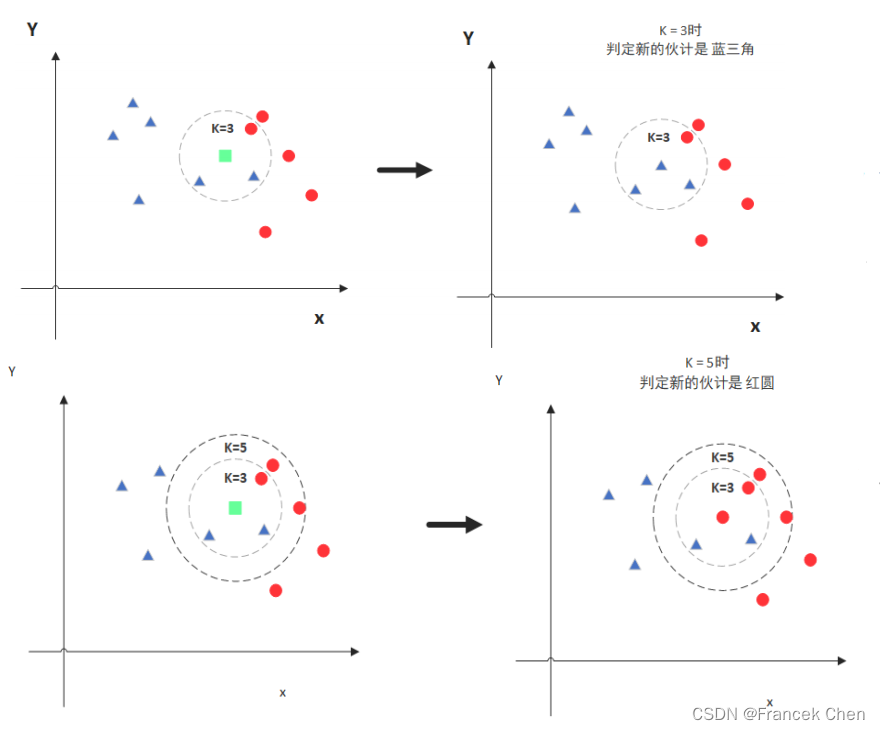
K值取3时,判断绿色点的类别为蓝色; K值取5时,判断绿色点的类别为红色为了能得到较优的K值,可以采用交叉验证和网格搜索的办法分别尝试不同K值下的分类准确性。
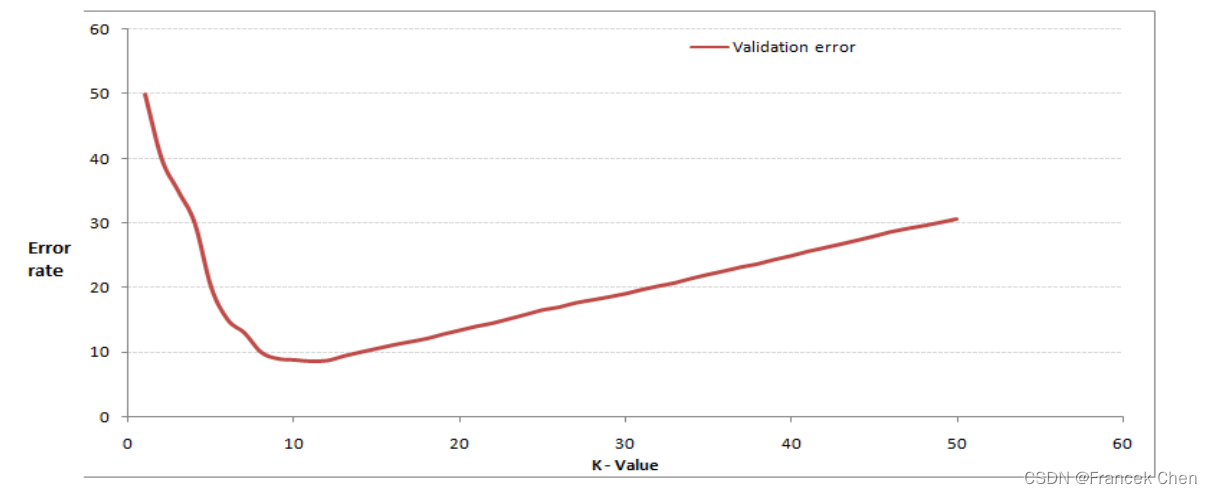
当增大k值时,一般错误率会先降低,因为有周围更多的样本可以借鉴了。但当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
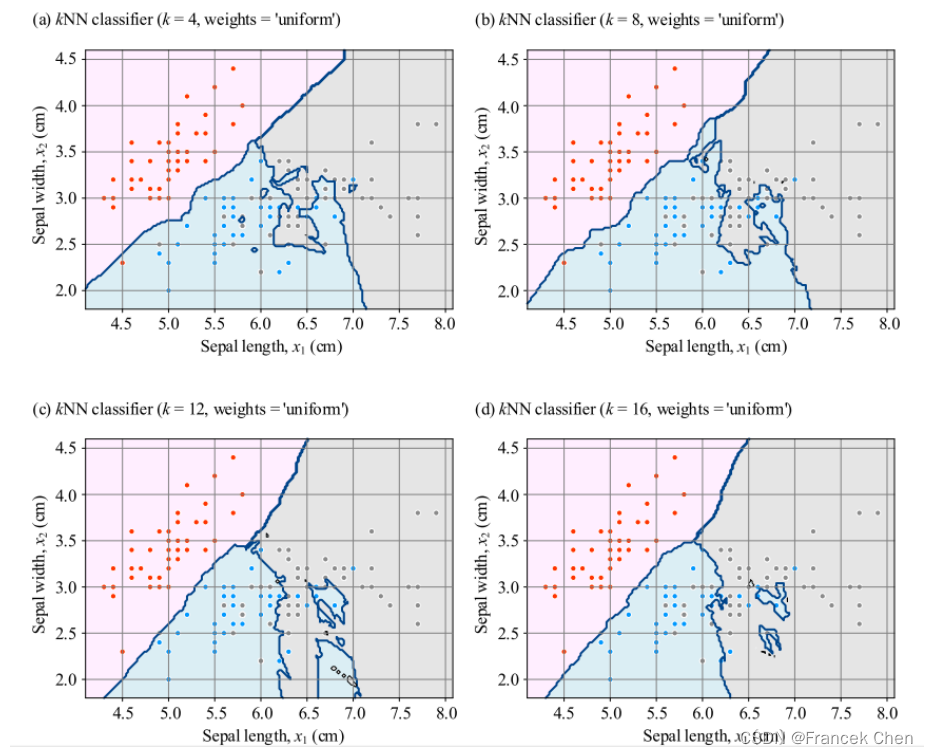
左图为k选取不同值时对鸢尾花分类影响。当k逐步增大时,局部噪音样本对边界的影响逐渐减小,边界形状趋于平滑。较大的k是会抑制噪声的影响,但是使得分类界限不明显。举个极端例子,如果选取k值为训练样本数量,即k=n,采用等权重投票,这种情况不管查询点q在任何位置,预测结果仅有一个(分类结果只能是样本数最多的那一类,kNN这一本来与空间位置相关的算法因此失去了作用)。这种训练得到的模型过于简化,忽略样本数据中有价值的信息。
二、距离度量
1、欧氏距离(Euclidean Distance)
维空间点
与
间的欧氏距离(两个
维向量):
2、曼哈顿距离(Manhattan Distance)
曼哈顿距离(Manhattan Distance)是指两点在南北方向上的距离加上在东西方向上的距离。
维空间点
与
的曼哈顿距离为
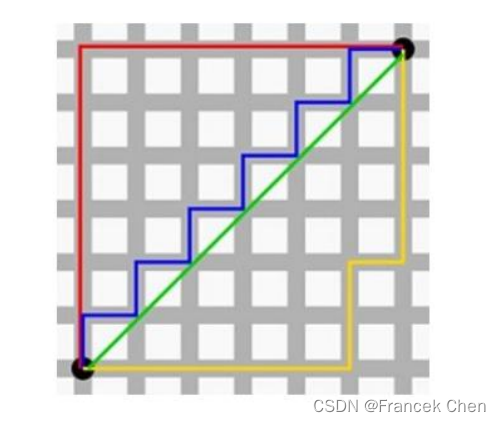
图中两点间的绿线代表的是欧式距离 。红线,蓝线和黄线代表的都是曼哈顿距离,由此可见在两点间曼哈顿距离相等的情况下,线路有多种情况。
3、余弦距离(Cosine Distance)
两个
维样本点
和
的夹角余弦为:
即
4、切比雪夫距离(Chebyshev Disatance)

切比雪夫距离(Chebyshev Disatance)是指二个点之间的距离定义是其各坐标数值差绝对值的最大值。
这也等于以下
度量的极限:
因此切比雪夫距离也称为
度量(无穷范数)。
国际象棋棋盘上二个位置间的切比雪夫距离是指王要从一个位子移至另一个位子需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率的到达目的的格子。上图是棋盘上所有位置距
位置的切比雪夫距离。
5、闵可夫斯基距离(Minkowski Distance)
闵氏距离的定义:两个
维变量
与
间的闵可夫斯基距离定义为:
其中
是一个变参数:
- 当
时,就是曼哈顿距离;
- 当
时,就是欧氏距离;
- 当
时,就是切比雪夫距离。
KNN算法默认使用闵可夫斯基距离。
三、邻近点的搜索算法
KNN算法需要在中搜索与x最临近的k个点,最直接的方法是逐个计算x与中所有点的距离,并排序选择最小的k个点,即线性扫描。 当训练数据集很大时,计算非常耗时,以至于不可行。实际应用中常用的是kd-tree (k-dimension tree) 和ball-tree这两种方法。ball-tree是对kd-tree的改进,在数据维度大于20时,kd-tree性能急剧下降,而ball-tree在高维数据情况下具有更好的性能。 kd-tree以空间换时间,利用训练样本集中的样本点,沿各维度依次对k维空间进行划分,建立二叉树,利用分治思想大大提高算法搜索效率。
样本集不平衡时的影响:
观察下面的例子,对于位置样本X,通过KNN算法,显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。
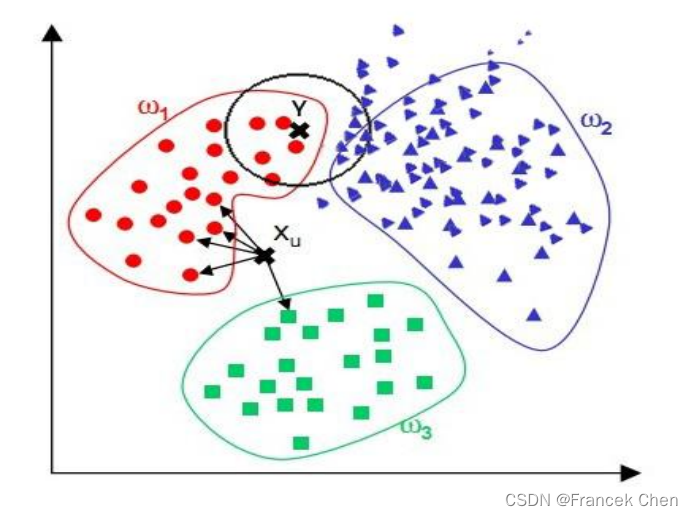
由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本容量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。
解决方法:采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,避免因一个类别的样本过多而导致误判。
四、KNN算法的特点
优点:
- KNN 理论简单,容易实现;
- 既可以用来做分类也可以用来做回归,还可以用于非线性分类;
- 新数据可以直接加入数据集而不必进行重新训练;
- 对离群点不敏感。
缺点:
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)效果差;
- 不适合高维数据,对于样本容量大的数据集计算量比较大(体现在距离计算上);
- KNN 每一次分类都会重新进行一次全局运算;
- K值不好确定;
- 各属性的权重相同,影响准确率。
五、KNN常用的参数及其说明
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None,n_jobs=1,**kwargs)参数名称 | 说明 |
|---|---|
n_neighbors | 接收int。表示近邻点的个数,即K值。默认为5。 |
weights | 接收str或callable,可选参数有“uniform”和“distance”。表示近邻点的权重,“uniform”表示所有的邻近点权重相等;“distance”表示距离近的点比距离远的点的权重大。默认为“uniform”。 |
algorithm | 接收str,可选参数有“auto”“ball_tree”“kd_tree”和“brute”。表示搜索近邻点的算法。默认为“auto”,即自动选择。 |
leaf_size | 接收int。表示kd树和ball树算法的叶尺寸,它会影响树构建的速度和搜索速度,以及存储树所需的内存大小。默认为30。 |
p | 接收int。表示距离度量公式,1是曼哈顿距离公式;2是欧式距离。默认为2。 |
metric | 接收str或callable。表示树算法的距离矩阵。默认为“minkowski”。 |
metric_params | 接收dict。表示metric参数中接收的自定义函数的参数。默认为None。 |
n_jobs | 接收int。表示并行运算的(CPU)数量,默认为1,-1则是使用全部的CPU。 |
六、分类算法的性能度量
(一)混淆矩阵及相关概念
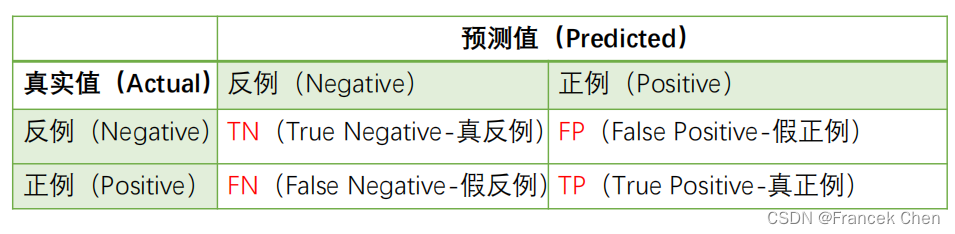
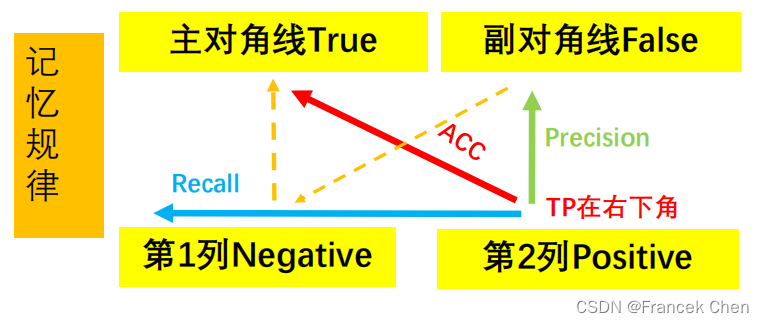
说明: (1)结论中的正例、反例以预测值为准,而前面的定语真、假以真实值为准; (2)预测值与真实值一致,则定语为真,预测值与真实值不一致则定语为假; (3)主对角线表示预测值与真实值相符,副对角线表示预测值与真实值不符。
相关概念:
- 准确率ACCuracy:全部预测中,预测正确的比例(即主对角线的占比)
- 查准率Precision :预测的正例中,预测正确(真正例)的比例
- 查全率或找回率Recall:真实正例中,预测正确(真正例)的比例
(二)F1_score和其他度量指标
y_true = [1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0]
y_pred = [1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0]
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往会偏低,查全率高时,查准率往往会偏低。而F1-Score指标综合了Precision与Recall的产出的结果,是F1是基于查准率与查重率的调和平均。F1-Score的取值范围从0到1,1代表模型的输出最好,0代表模型的输出结果最差。
此外,还有P-R曲线、ROC曲线、 AUC值等分类性能的指标。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号