
FFT去噪
我使用大胆产生一个10赫兹的音调,48千赫采样和1秒的持续时间。然后用下面的脚本加载它来绘制FFT图:
from scipy.io import wavfile
from scipy.fftpack import fft, fftfreq
import matplotlib.pyplot as plt
from pydub import AudioSegment
import numpy as np
wav_filename = "\\test\\10Hz.wav"
samplerate, data = wavfile.read(wav_filename)
total_samples = len(data)
limit = int((total_samples /2)-1)
fft_abs = abs(fft(data))*2/total_samples
fft_db = 20*np.log10(fft_abs/32760)
freqs = fftfreq(total_samples,1/samplerate)
# plot the frequencies
plt.plot(freqs[:limit], fft_db[:limit])
plt.xscale('log',basex=10)
plt.title("Frequency spectrum")
plt.xlabel('Hz')
plt.ylabel('amplitude')
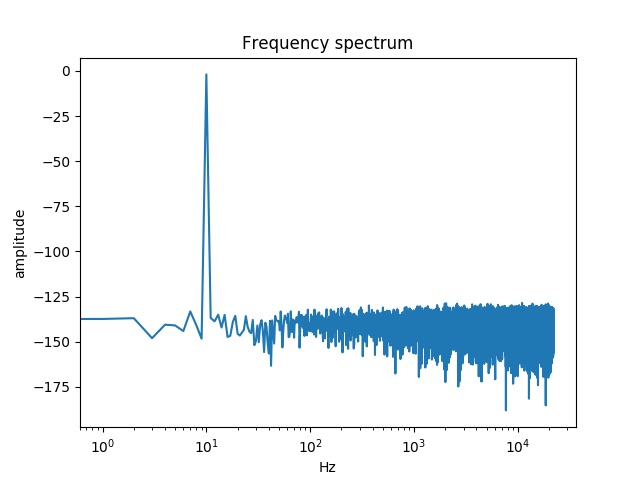
plt.show()下面是一张嘈杂的图表:
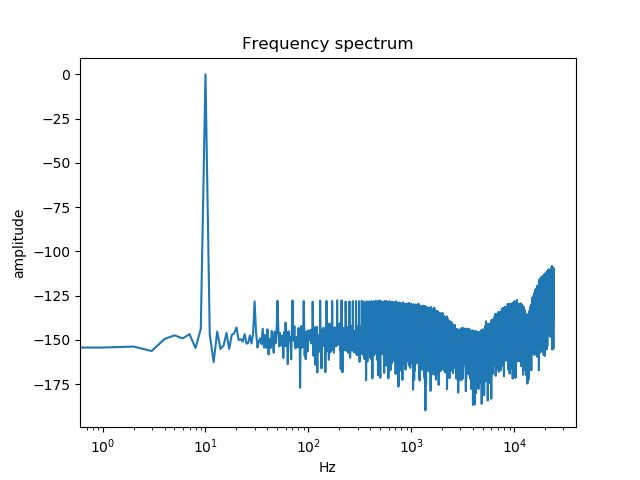
但如果我用胆量来看光谱图,那就很好了。
我应该如何改进我的脚本以获得更好的FFT绘图?
回答 1
Stack Overflow用户
发布于 2019-09-11 20:30:41
这种特殊的频谱模式的WAV文件是由噪声形状抖动应用于减少量化造成的失真。
将信号作为带符号的16位整数存储在WAV文件中.该 量子化 使信号具有相当高的:2^15为32768 : 0.5/32768的相对误差,计算出的可能会使其增加。大约是1e-5,或-96分贝。因此,如果不小心地将信号的值转换为最近的整数,则任何96 of以下的频率都可以被丢弃为量化噪声。
然而,输出的WAV文件的频谱看起来很好,因为所有频率的振幅都低于-100 0dB,唯一的例外是正弦波的频率,它的振幅接近0dB。问题是要重新表述的: Audacity如何才能为WAV文件提供如此精确的频谱?
对输出值进行了优化,以提高频谱的精度。实际上,单个输出值的精度低于将浮点值转换为整数值。我产生了一个幅值为0.8的正弦波,输出为WAV签署的16位PCM。量化误差可计算为:
x=np.linspace(0,1,len(data),endpoint=False)
data2=np.sin(10*2*np.pi*x)
data=data.astype(np.double)
plt.plot(x, data-0.8*32768*data2, label="data-sin(x)")
#plt.xscale('log',basex=10)
plt.title("signal")
plt.xlabel('time, s')
plt.ylabel('amplitude')
plt.show()生成的量化误差图:
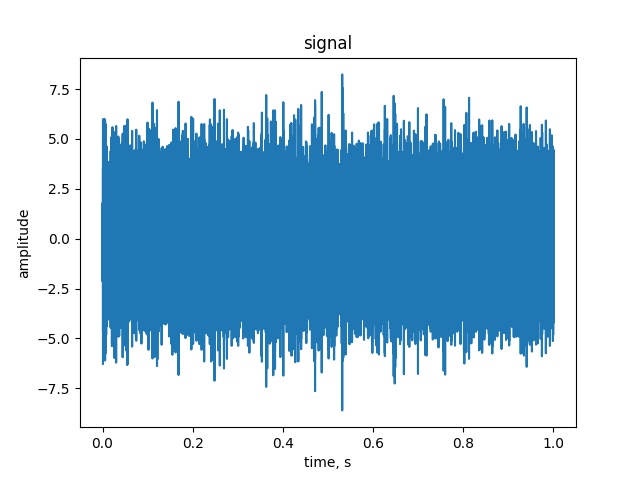
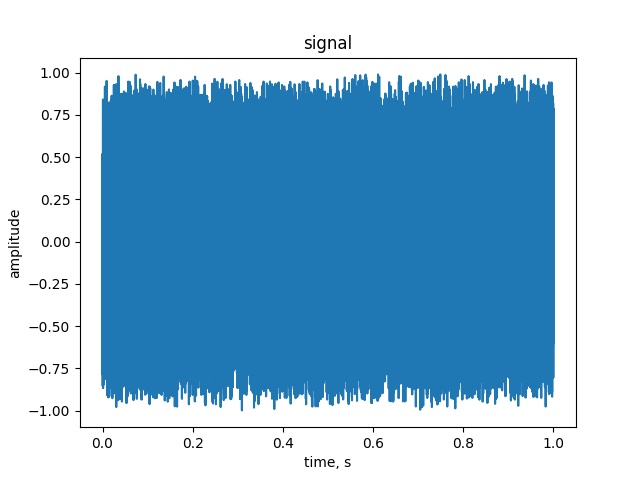
如果简单地将信号值转换为最近的整数并将其倒入WAV文件,则生成的错误将低于0.5。实际的点态误差约为5。
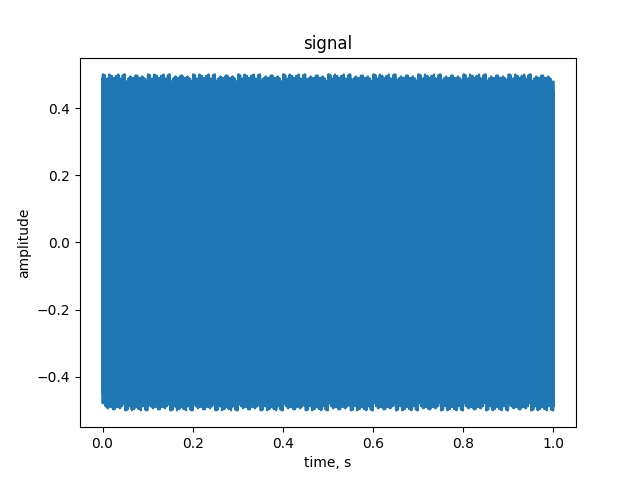
为了提高量化信号的动态范围,增加了一个很难被人类听到的高频噪声,奥迪公司考虑了一种噪声型抖动。那里,那里和那里。
,您可以 选择谨慎中的抖动,甚至禁用它。进入Preferences=>质量!如果不考虑抖动,则实际空间中的点态误差更小:
但是光谱上的量化误差更大:
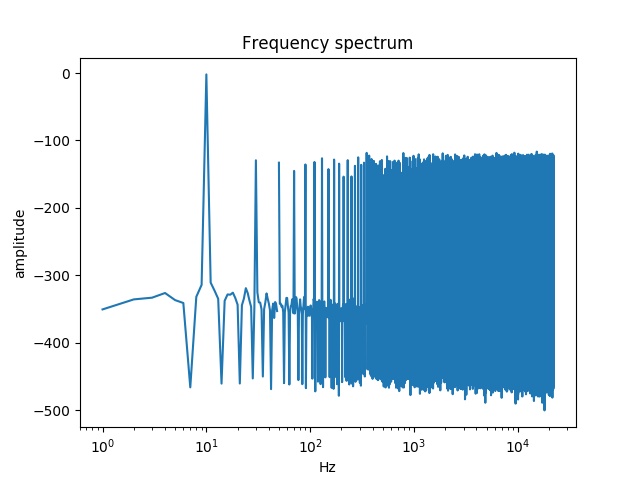
矩形抖动可以用来后退看起来像白噪声的东西:它可能是你使用的最佳选择,因为频谱上的误差约为-125 is,点态误差为+-1。
https://stackoverflow.com/questions/57892632
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号